由CPU高负载引发内核探索之旅
导语:**STGW(腾讯云CLB)**在腾讯云和自研业务中承担多种网络协议接入、请求加速、流量转发等功能,有着业务数量庞大、接入形式多样、流量规模巨大的特点,给产研团队带来了各种挑战,经常要深入剖析各种疑难杂症。本文介绍了STGW在实际运营过程中,一次没有造成业务影响的CPU高负载被发现后,团队进行深入分析从内核端口发现问题根源,在经过与内外部linux内核专家们共同协作,输出解决方案并最终修复问题。
一、问题起源
值班期间,运维同学偶然发现一台机器CPU消耗异常,从监控视图上看出现较多毛刺。而属于同一集群的其他机器在同一时间段CPU消耗相对稳定。
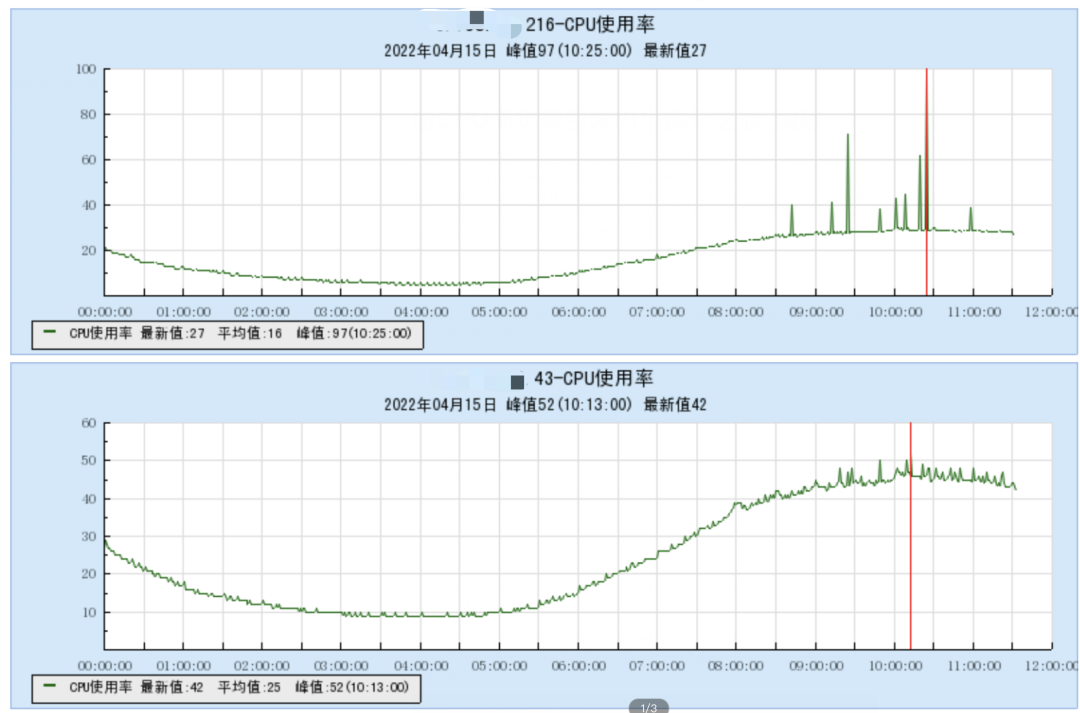
从机器维度的监控无法掌握更多的信息,通过自建的秒级监控系统,我们拿到了更多的性能数据。实际的消耗情况比机器监控上看到的更加严重,高负载来自于sys消耗,全核cpu都被内核彻底消耗掉了。
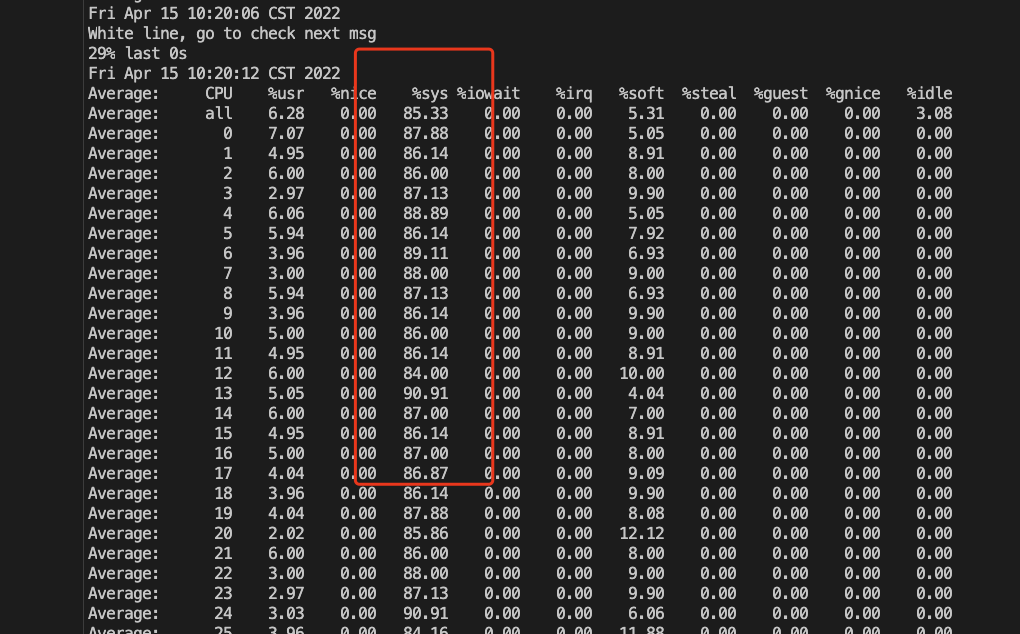
秒级监控除了会捕获细粒度的系统负载外,针对发生高负载场景,会触发分析工具进行分析。虽然高负载发生的时间很短,依靠这套系统我们先拿到了导致高负载的直接原因,发生在inet_hash_connect函数中。
inet_hash_connect这个函数是内核处理tcp连接的必经之路。我之前一篇关于高负载的文章也分析了tcp连接引发的该函数单核高负载的场景,详见:[从STGW流量下降探秘内核收包机制] ,当时引发问题的函数是inet_lookup_listener。
不同点在于,inet_lookup_listener是服务端收到新连接时寻找监听端口,而inet_hash_connect函数是主动建立tcp连接,对应到我们的场景,就是STGW服务器与后端RealServer(后面简称RS)建立连接。通过内核代码分析,该函数的简化流程如下,其作用是tcp连接主动选取一个端口,检查可用后,进行bind绑定操作,该端口即发起方用于收发连接数据的端口。
// 主动发起tcp连接
connect(fd, servaddr, addrlen);
-> sock->ops->connect() == inet_stream_connect
-> tcp_v4_connect()
-> inet_hash_connect()
-> __inet_hash_connect()
/*
如果指定了port,则使用指定的port作为客户端端口
否则,随机选取一个port
*/
// 端口可用性检查
-> check_established()
// bind端口
-> inet_bind_bucket_create
-> inet_bind_hash为什么inet_hash_connect会出现高负载?
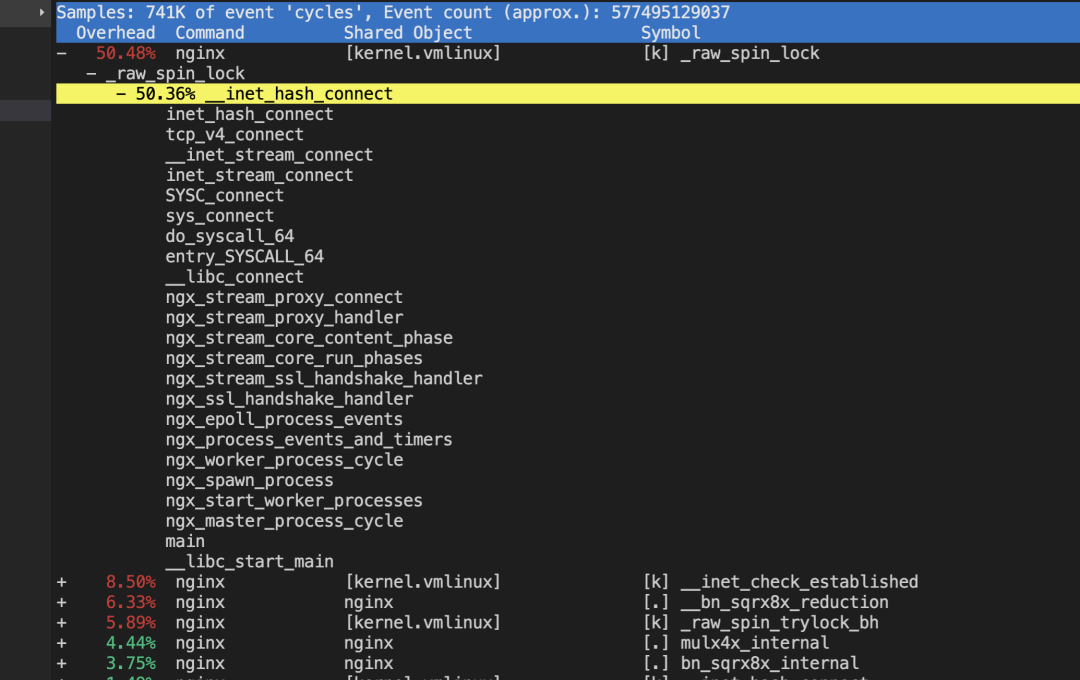
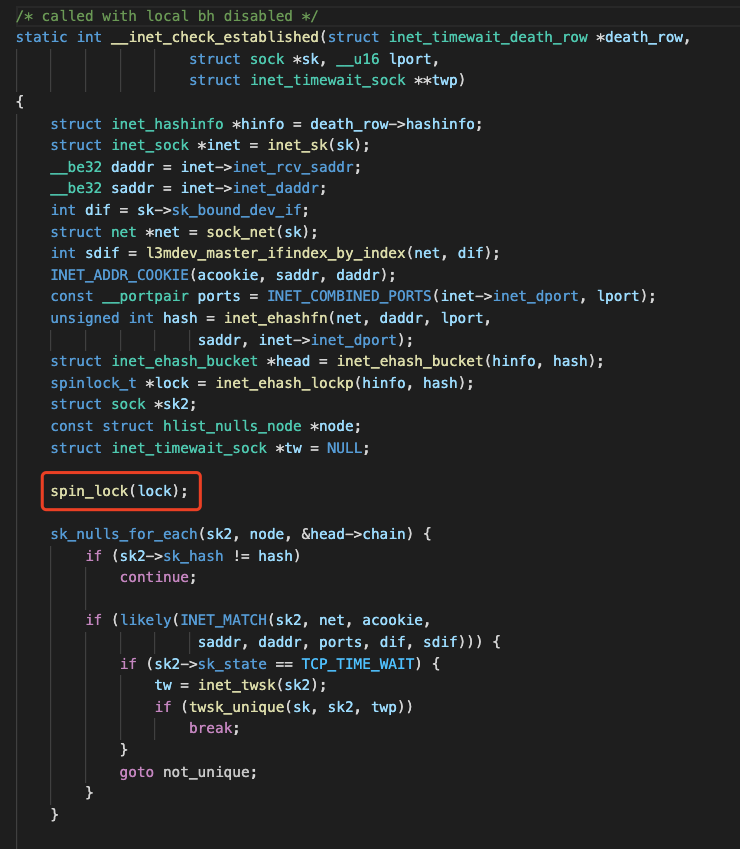
从perf看,直接原因是raw_spin_lock锁带来的剧烈消耗,我们先找到这个锁所在位置,根据对应内核源码找inet_hash_connect实现及内部调用中,发现只有inet_check_establish里会进行spin_lock(其他几处为spin_lock_bh,如果是其他地方,应该为raw_spin_lock_bh)。
三、前期排查
通常锁造成高负载我们会怀疑是否有死锁产生,从cpu现象来看只是短时间突增并非死锁。那么我们有另外两种猜想:
1. 锁覆盖的范围执行极慢,导致锁了很长时间。
2. 频繁执行该函数执行加锁导致高负载。
先看第一种情况,我们假设inet_check_establisted函数中加锁区域代码执行效率慢,导致高负载。分析代码容易看出,加锁部分是一个遍历哈希链表的操作,通过传入的参数计算一个哈希值,拿到哈希桶后遍历其中可用的节点,这种遍历操作确实值得怀疑,历史case告诉我们,哈希桶挂载的节点非常多导致遍历复杂度急剧上升,拖累整个cpu。例如[从STGW流量下降探秘内核收包机制] 中分析到,由于哈希桶数量太少,当监听端口足够多时,遍历效率太低导致高负载的案例。因此,这里合理怀疑是否是ehash(TCP Established hash table)桶遍历太久,导致加锁时间过长?根据之前的经验,我习惯性先找哈希桶初始化地方,尝试看这个问题是否如之前一般由哈希桶数量太少导致,在tcp.c文件的tcp_init函数中找到其初始化函数。
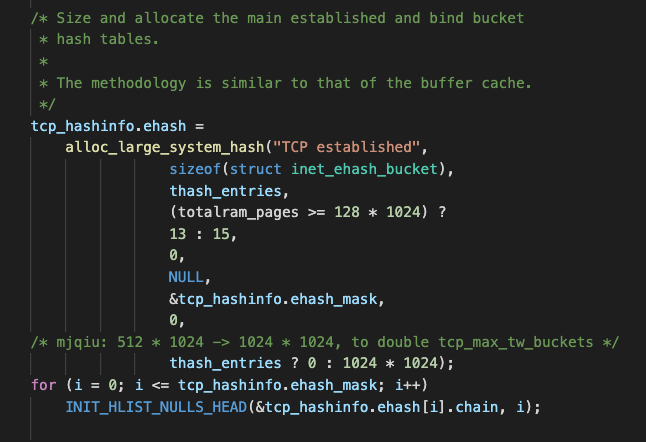
发现ehash的桶大小是由alloc_large_system_hash为其申请的空间,而该函数实现较为晦涩,引入了根据机器物理内存大小动态调整申请空间,很难通过代码直接看出到底分配了多大数量的哈希桶。好在函数最后会向系统日志打印出此次申请的哈希桶的大小。
pr_info("%s hash table entries: %ld (order: %d, %lu bytes)\n",
tablename, 1UL << log2qty, ilog2(size) - PAGE_SHIFT, size);根据代码中的打印方式在机器上果然找到对应日志,从而得知ehash table的桶超过了100w个。

这意味着在哈希均匀的情况下,ehash table可以容纳百万条establish状态的连接,不会出现遍历热点。而问题机器的连接数峰值大概50w左右,远没有达到阈值。
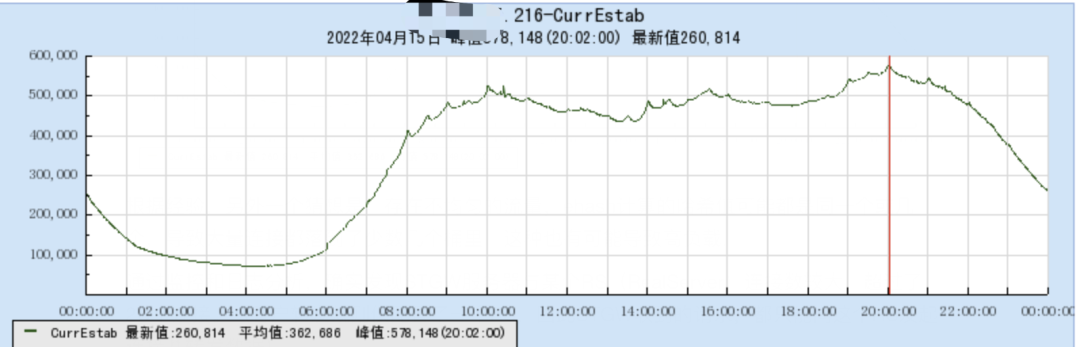
根据经验,另外一个猜想是:存在不均匀的流量,ehash计算的哈希值可能都是同一个或几个,导致大量连接都落到了少数几个桶里,这种也有可能导致高负载。
通过监控和日志分析,确实发现STGW服务器与某个RS(RealServer)连接数较大,超过了2w个连接。(客户转发规则仅配置了一个RS,因此STGW收到的请求,都只能向这个RS发起连接并转发数据)。那么往单个RS建立连接数过多会造成哈希桶使用不均匀吗?
static inline unsigned int __inet_ehashfn(const __be32 laddr,
const __u16 lport,
const __be32 faddr,
const __be16 fport,
u32 initval)
{
return jhash_3words((__force __u32) laddr,
(__force __u32) faddr,
((__u32) lport) << 16 | (__force __u32)fport,
initval);
}分析看,ehash table在查找和插入过程计算哈希值都是通过TCP四元组进行哈希,而至少源端口这里是足够散列的,因此理论上不存在往同一个桶插入过多节点的情况。
四、峰回路转
此时回过头看,我们一直在问题机器上折腾,但还有个关键信息一直没有被深入挖掘。

根据运维同学提醒,同集群有另外一种机型可以作为参照,高负载仅出现在其中一种代号为25G的机型上,也就是说,承担了同样的转发流量,另外一种10G机型却并没有高负载出现。
根据这个线索,我们排查对比了集群内两种机型的异同点,首先流量大小、请求成分这些都是一致的,而网卡型号、CPU型号、内核版本这些都是不一样的,根据上面的排查,CPU高负载的热点主要在内核协议栈函数中,于是我们主要对比不同内核版本的实现差异。
发现不同内核版本在inet_hash_connect函数实现上,确实有明显区别。
- 先来看不出问题的机型,其内核版本为基于linux 3.10.107
// Linux 3.10.107 x86_64 GNU/Linux
int __inet_hash_connect(struct inet_timewait_death_row *death_row,
struct sock *sk, u32 port_offset,
int (*check_established)(struct inet_timewait_death_row *,
struct sock *, __u16, struct inet_timewait_sock **),
int (*hash)(struct sock *sk, struct inet_timewait_sock *twp))
{
struct inet_hashinfo *hinfo = death_row->hashinfo;
const unsigned short snum = inet_sk(sk)->inet_num;
struct inet_bind_hashbucket *head;
struct inet_bind_bucket *tb;
int ret;
struct net *net = sock_net(sk);
int twrefcnt = 1;
if (!snum) { // 未指定端口
int i, remaining, low, high, port;
static u32 hint;
u32 offset = hint + port_offset;
struct inet_timewait_sock *tw = NULL;
// 获取本地可用端口范围
// 统一配置的10241 ~ 59999
inet_get_local_port_range(net, &low, &high);
remaining = (high - low) + 1;
local_bh_disable();
// remaining 即为 local_port_range规定的端口数量
for (i = 1; i <= remaining; i++) {
int ret;
// 注意:选取的port是逐次递增1,最多执行remaining次
port = low + (i + offset) % remaining;
if (inet_is_reserved_local_port(port))
continue;
head = &hinfo->bhash[inet_bhashfn(net, port,
hinfo->bhash_size)];
ret = spin_trylock(&head->lock);
if (!ret)
continue;
/* Does not bother with rcv_saddr checks,
* because the established check is already
* unique enough.
*/
inet_bind_bucket_for_each(tb, &head->chain) {
if (net_eq(ib_net(tb), net) &&
tb->port == port) {
if (tb->fastreuse >= 0 ||
tb->fastreuseport >= 0)
goto next_port;
WARN_ON(hlist_empty(&tb->owners));
// 检查端口是否可用
if (!check_established(death_row, sk,
port, &tw))
goto ok;
goto next_port;
}
}
tb = inet_bind_bucket_create(hinfo->bind_bucket_cachep,
net, head, port);
if (!tb) {
spin_unlock(&head->lock);
break;
}
tb->fastreuse = -1;
tb->fastreuseport = -1;
goto ok;
next_port:
spin_unlock(&head->lock);
}
local_bh_enable();
return -EADDRNOTAVAIL;
/* 省略部分问题无关代码 */
}- 问题机型的内核版本基于4.14.105版本,该版本相较于上述更先进,其中函数实现如下
// Linux 4.14.105-1 x86_64 GNU/Linux
int __inet_hash_connect(struct inet_timewait_death_row *death_row,
struct sock *sk, u32 port_offset,
int (*check_established)(struct inet_timewait_death_row *,
struct sock *, __u16, struct inet_timewait_sock **))
{
struct inet_hashinfo *hinfo = death_row->hashinfo;
struct inet_timewait_sock *tw = NULL;
struct inet_bind_hashbucket *head;
int port = inet_sk(sk)->inet_num;
struct net *net = sock_net(sk);
struct inet_bind_bucket *tb;
u32 remaining, offset;
int ret, i, low, high;
static u32 hint;
/*省略部分无关代码*/
inet_get_local_port_range(net, &low, &high);
high++; /* [32768, 60999] -> [32768, 61000[ */
// remaining为local_port_range规定的端口数量
remaining = high - low;
if (likely(remaining > 1))
remaining &= ~1U;
offset = (hint + port_offset) % remaining;
/* In first pass we try ports of @low parity.
* inet_csk_get_port() does the opposite choice.
*/
// 注意:这里意味着,如果offset为奇数,强制变成偶数
offset &= ~1U;
other_parity_scan:
// 注意:由于offset第一次必为偶数,port的奇偶性完全取决于low
// (注:下面会goto other_parity_scan,再次回到这里,奇偶性反转)
port = low + offset;
// 注意:该循环每次递增2,意味着只会查询remaining/2个端口,并且这些端口奇偶性与port初始值一致
for (i = 0; i < remaining; i += 2, port += 2) {
int ret;
if (unlikely(port >= high))
port -= remaining;
if (inet_is_local_reserved_port(net, port))
continue;
head = &hinfo->bhash[inet_bhashfn(net, port,
hinfo->bhash_size)];
ret = spin_trylock_bh(&head->lock);
if (!ret)
continue;
/* Does not bother with rcv_saddr checks, because
* the established check is already unique enough.
*/
inet_bind_bucket_for_each(tb, &head->chain) {
if (net_eq(ib_net(tb), net) && tb->port == port) {
if (tb->fastreuse >= 0 ||
tb->fastreuseport >= 0)
goto next_port;
WARN_ON(hlist_empty(&tb->owners));
if (!check_established(death_row, sk,
port, &tw))
goto ok;
goto next_port;
}
}
tb = inet_bind_bucket_create(hinfo->bind_bucket_cachep,
net, head, port);
if (!tb) {
spin_unlock_bh(&head->lock);
return -ENOMEM;
}
tb->fastreuse = -1;
tb->fastreuseport = -1;
goto ok;
next_port:
spin_unlock_bh(&head->lock);
cond_resched();
}
// 注意:循环结束后,走到这里意味着依然没有找到合适的端口
// 此时将offset的奇偶性改变,通过goto返回上面循环,重新查找可用端口
offset++;
if ((offset & 1) && remaining > 1)
goto other_parity_scan;
return -EADDRNOTAVAIL;
/*省略部分问题不相关代码*/
}从前面的内容交代过,inet_hash_connect的一个最重要的功能就是选取本地socket的端口并且检查其是否可用。从上述两段不同内核代码分析,很明显在端口选取实现两个内核差异很大。
-
3.10内核不出问题:其端口选取过程为for循环在port_offset基础上逐次递增1,直到找到可用端口为止,或者超过了local_port_range个数,则返回EADDRNOTAVAIL
-
4.14内核出现高负载问题:其端口选取过程为for循环在port_offset基础上逐次递增2,只把奇数范围(取决于local_port_range左边界)端口进行遍历,如果整个奇数范围都找不到可用端口,再遍历所有偶数端口,直到找到可用端口为止,或者超过了local_port_range个数,则返回EADDRNOTAVAIL。
4.14内核做了奇偶区分,每次递增2就是为了只找奇数或偶数的端口,这种遍历方式乍一看似乎没毛病,因为可用端口总数限定了(local_port_range),在port_offset初始值Z足够离散的情况下,遍历过程不管递增1还是递增2,应该是差不多的,都有概率在递增后碰到可用端口。
上面提到,我们的问题服务器,有一个业务只绑定了一个RS,在高负载的时候,服务器与这个RS建立的连接超过了2w条。结合这个现象,很快发现了问题所在,由于我们的local_port_range为10241~59999,总的可用端口数为49758个,其中奇数、偶数分别占2.4万多个。
所以,高负载期间,问题服务器与该RS建立了2w多条连接,实际上将inet_hash_connect中的奇数端口几乎耗尽,然而每次与该RS建立新连接,内核都要首先遍历奇数端口,进行2w多次无效的端口查找与检查(inet_check_establish进行spin_lock),才有可能开始遍历偶数端口,从而找到可用端口。相比之下,3.10内核的实现,在49758个端口内查找,即便是已经有2w多个端口不可用了,借助于port_offset足够分散的前提(port_offset基于源+目的地址进行散列),平均下来每次都可以较快找到可用的端口。
五、复现验证
为了最终确认这个问题,我们将现象及分析同步给了系统测试同学及tlinux研发,tlinux同学帮忙修改了4.14内核中的inet_hash_connect函数,使其不再按奇偶性选择端口,帮忙打包了一个4.14.105内核修复版。系统测试同学对比测试了 4.14.105原版本 vs 4.14.105修复版,结果如下:
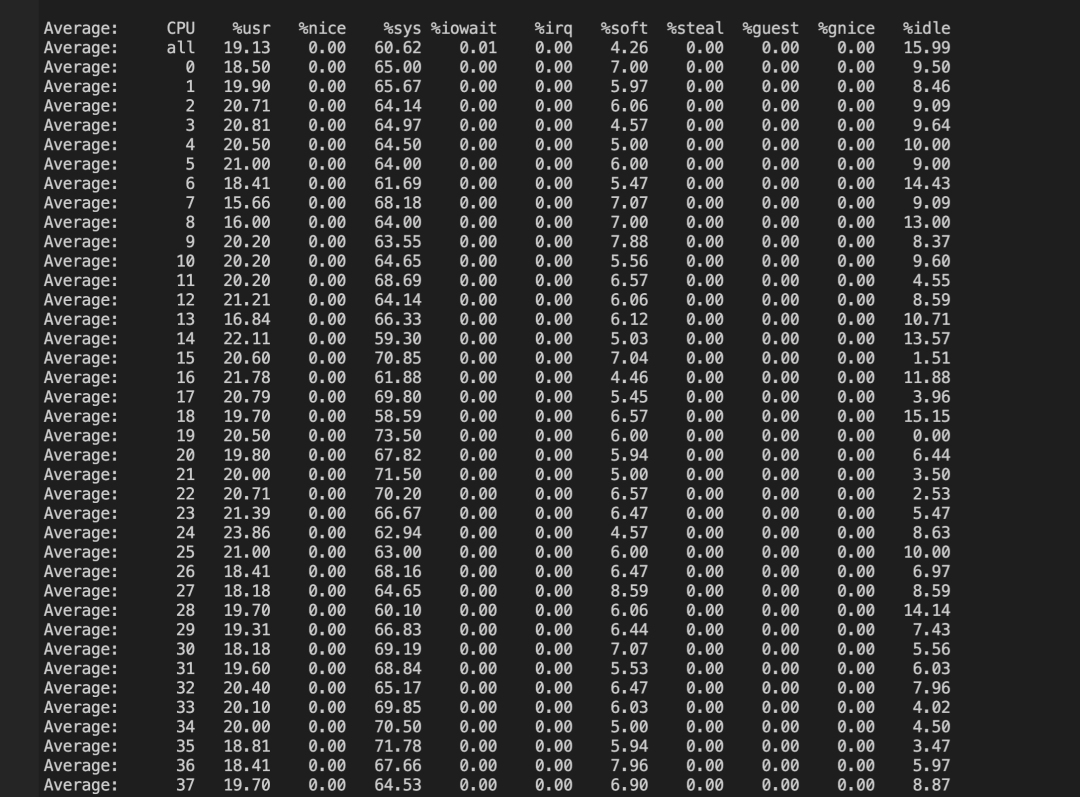
- 原版本向RS 172.16.0.1:20000建立2.8w条连接后,连接数很难继续上升,同时CPU全核出现sys高负载,perf发现就是inet_hash_connect导致

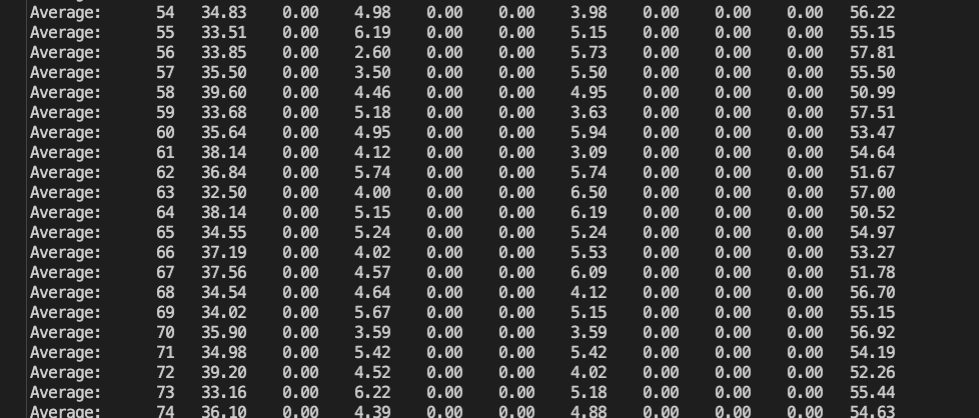
- 新内核版本,对于单个RS,可以打到4.3w条连接以上,CPU不出现高负载,消耗最大的是usr中SSL握手消耗

六、溯源
到这里,我们在理论上与实践上都证实了,问题是由于更先进的内核(4.14版本)修改了inet_hash_connect中选取端口的遍历逻辑,优先遍历奇数或者偶数端口,当服务器与单个RS建连数量超过local_port_range/2后就会导致无效遍历过多从而cpu高负载。
所以,为什么linux官方要将选端口逻辑改成奇偶遍历呢?通过git修改历史,很快定位到了提交点。
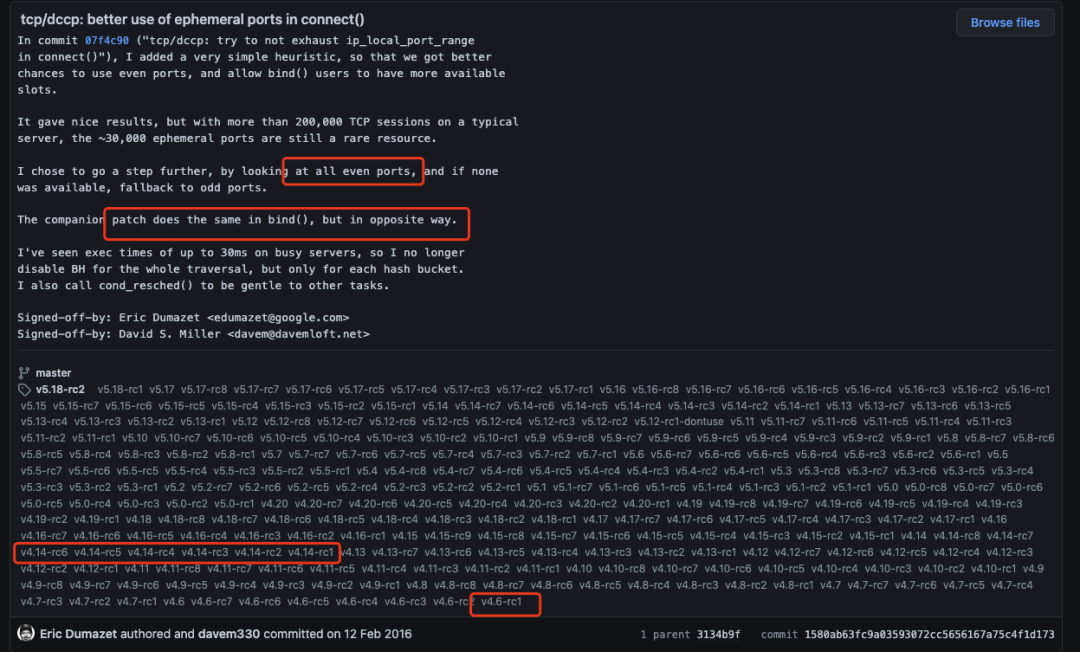
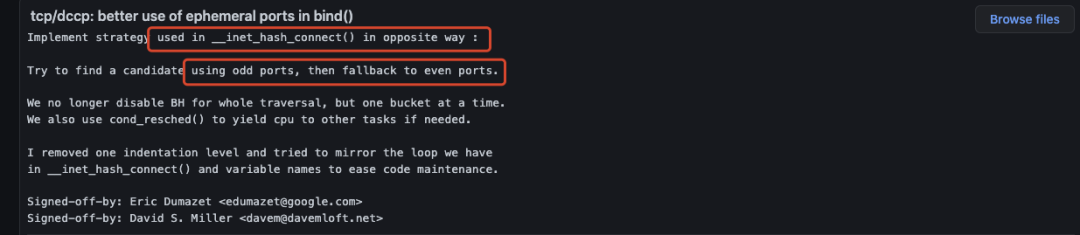
如图,在4.6版本开始,Google内核专家提交了两个commit,将可用端口按奇偶划分两部分,一部分给connect使用,另一部分给bind使用。我们追溯了一下bind的实现(细节可参见inet_csk_get_port)发现确实与inet_hash_connect做了类似的操作,只不过一个是取奇数另一个取偶数。
结合自身情况来看,我们并没有随机bind端口的场景(例如listen端口,一般都是指定端口进行监听,不存在随机的情况)。因此接下来进一步找了作者确认。
作者给我的回信明确了对于不需要bind()随机端口的用户,这个方式是有害的。同时只提到是google需要大量随机bind(),为了避免频繁发生事故加了这个功能,但google到底什么场景需要如此频繁的随机bind,作者没有给明确回应。
七、解决问题
即便找到了原作者反馈问题,他并不乐意进一步做方案优化,而是让我们自己按需解决。对于这个问题,我们从短期到长期给出的解决方案如下:
短期方案
通过增加四元组的数量缓解问题,该问题实际上是源地址+目的地址+目的端口都确定的情况下,新连接只能从本地端口这一个维度进行扩展。即便没有高负载问题(老版本内核)连接数也无法超过5w(受限于local_port_range)。因此,可以通过拓宽四元组的另外维度,来大幅度提升可建立的连接数,具体有三个办法:
- 增加后端RS数量:扩展目的地址数量
- 增加后端RS端口数:扩展目的端口数量
- 增加客户端机器本地地址数量:扩展源地址数量
最终方案
在腾讯的tlinux系统中,已进行优化内核奇偶遍历逻辑,给用户更自由的端口分配权限,彻底解决该问题。
总结
最后,总结整个问题和定位过程,我们从一次CPU高负载问题出发,从最开始在问题机器上猜想和分析,找不到确切答案。通过比较不同机型函数实现差异找到关键点。再通过代码分析、复现验证、社区求证这三个方面将问题的前因后果分析清楚,最终给出了解决方案。