一文读懂|Linux系统平均负载
我们经常会使用 top 命令来查看系统的性能情况,在 top 命令的第一行可以看到 load average 这个数据,如下图所示:
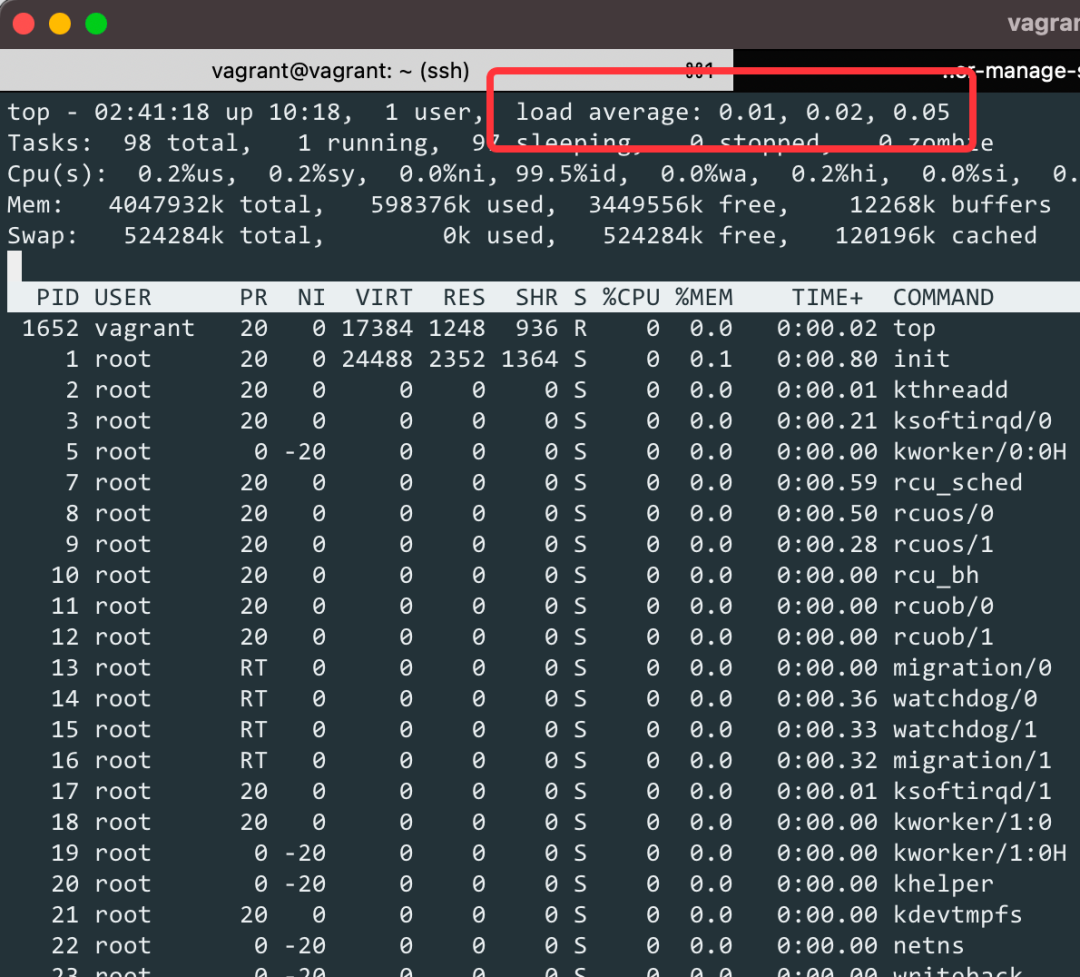
load average 包含 3 列,分别表示 1 分钟、5 分钟和 15 分钟的 系统平均负载。
对于系统平均负载这个数值,可能很多同学并不完全理解其意义,并不知道数值达到多少时才表示系统负载过高。本文将会以简单的语言来介绍系统平均负载这个概念,并且会介绍 Linux 内核是怎么计算这个数值。
系统平均负载
《Understanding Linux CPU Load(链接在文章最后)》这篇文章已经非常通俗的解释了什么是 系统平均负载,这里借用一下此文中的例子。
如果将 CPU 比作是桥梁,对于单核的 CPU 就好比是单车道的桥梁。每次桥梁只能让一辆汽车通过,并且要以规定的速度通过。那么:
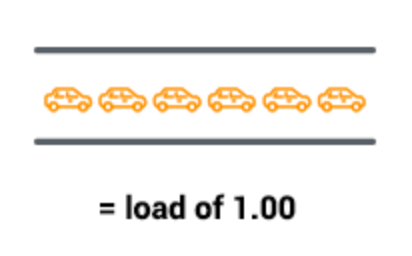
- 如果每个时刻都只有一辆汽车通过,那么所有汽车都不用排队,此时桥梁的使用率最高。以平均负载 1.0 表示,如下图所示:
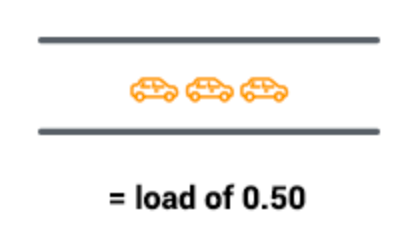
- 如果每隔一段时间才有一辆汽车通过,那么表示桥梁部分时间处于空闲的情况。并且间隔的时间越长,表示桥梁空闲率越高。此时的平均负载小于 1.0,如下图所示:
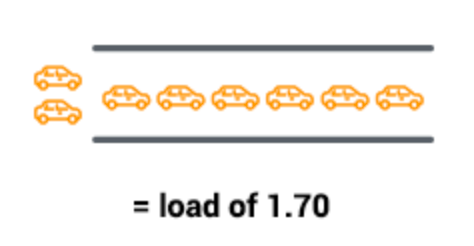
- 当有大量的汽车通过桥梁时,有些汽车需要等待其他车辆通过后才能继续通行,这时表示桥梁超负荷工作。此时平均负载大于1.0,如下图所示:
系统的平均负载与上面的例子一样,在单核 CPU 的环境下:
- 当平均负载等于 1.0 时,表示 CPU 使用率最高。
- 当平均负载小于 1.0 时,表示 CPU 使用率处于空闲状态。
- 当平均负载大于 1.0 时,表示 CPU 使用率已经超过负荷。
对于单核 CPU 来说,平均负载 1.0 表示使用率最高。但对于多核 CPU 来说,平均负载要乘以核心数。比如在 4 核 CPU 的系统中,当平均负载为 4.0 时,才表示 CPU 的使用率最高。
Linux 平均负载计算原理
在介绍系统平均负载的计算原理前,先要介绍一下什么是系统负载。在 Linux 系统中,系统负载表示 系统中当前正在运行的进程数量,其包括 可运行状态 的进程数和 不可中断休眠状态 的进程数的和。注意:不可中断休眠状态的进程一般是在等待 I/O 完成的进程。
系统负载 = 可运行状态进程数 + 不可中断休眠状态进程数
知道了什么是 系统负载,那么 系统平均负载 就容易理解了。比如每 5 秒统计一次系统负载,1 分钟内会统计 12 次。如下所示:
第5秒 -> 系统负载
第10秒 -> 系统负载
第15秒 -> 系统负载
...
第60秒 -> 系统负载然后把每次统计到的系统负载加起来,再除以统计次数,即可得出 系统平均负载。如下图所示:

但这种计算方式有些缺陷,就是预测系统负载的准确性不够高,因为越老的数据越不能反映现在的情况。打个比方,要预测某条公路今天的车流量,使用昨天的数据作为预测依据,会比使用一个月之前的数据作为依据要准确得多。
所以,时间越近的数据,对未来的预测准确性越高。
Linux 内核使用一种名为 指数平滑法 的算法来解决这个问题,指数平滑法的核心思想是对新老数据进行加权,越老的数据权重越低。
指数平滑法:是由 Robert G..Brown 提出的一种加权移动平均法,有兴趣了解其数学原理的可以搜索相关资料,本文不作详细介绍。
其计算公式如下(来源于 Linux 内核代码 kernel/sched/core.c):
load1 = load0 * e + active * (1 - e)
解释一下上面公式的意思:
- load1:表示时间 t + 1 的系统负载。
- load0:表示时间 t 的系统负载。
- e:表示衰减系数。
- active:表示系统中的活跃进程数(可运行状态进程数 + 不可中断休眠状态进程数)。
所以,我们就可以使用上面的公式来预测任何时间的系统平均负载了。比如,我们要预测时间点 n 的系统平均负载,那么可以这样来计算:
load1 = load0 * e + active * (1 - e)
load2 = load1 * e + active * (1 - e)
load3 = load2 * e + active * (1 - e)
...
loadn = loadn-1 * e + active * (1 - e)现在就只剩下 衰减系数 该如何计算了。
从 Linux 内核的注释可以了解到,计算 1 分钟内系统平均负载的 衰减系数 的计算方式如下:
1 / exp(5sec / 1min)
其中:
- 5sec:表示统计的时间间隔,5秒。
- 1min:表示统计的时长,1分钟。
- exp:表示以自然常数 e 为底的指数函数。
也就是说,要计算一分钟的系统平均负载时,需要使用上面的 衰减系数。对于 5 分钟和 15 分钟的 衰减系数 的计算方式分别为:
1 / exp(5sec / 5min)
1 / exp(5sec / 15min)Linux 内核已经把 1 分钟、5 分钟和 15 分钟的 衰减系数 结果计算出来,并且定义在 include/linux/sched.h 文件中,如下所示:
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */通过上述公式计算出来的 衰减系数 是个浮点数,而在内核中是不能进行浮点数运行的。解决方法是先对 衰减系数 进行扩大,然后在展示时最缩小。所以,上面的 衰减系数 数值是经过扩大 2048 倍后的结果。
Linux 平均负载计算实现
万事俱备,只欠东风。上面我们已经把所有的知识点介绍了,现在来分析一下 Linux 内核代码是怎样实现的。
1. 数据存储
在 Linux 内核中,使用了 avenrun 数组来存储 1 分钟、5 分钟和 15 分钟的系统平均负载,如下代码所示:
unsigned long avenrun[3];
如元素 avenrun[0] 用于存储 1 分钟内的系统平均负载,而元素 avenrun[1] 用于存储 5 分钟的系统平均负载,如此类推。
2. 统计过程
由于统计需要定时进行,所以内核把统计过程放置到 时钟中断 中进行。当 时钟中断 触发时,将会调用 do_timer() 函数,而 do_timer() 函数将会调用 calc_global_load() 来统计系统平均负载。
我们来看看 calc_global_load() 函数的实现:
void calc_global_load(unsigned long ticks)
{
long active, delta;
// 1. 如果还没到统计的时间间隔,那么将不进行统计(5秒统计一次)
if (time_before(jiffies, calc_load_update + 10))
return;
// 2. 获取活跃进程数
delta = calc_load_fold_idle();
if (delta)
atomic_long_add(delta, &calc_load_tasks);
active = atomic_long_read(&calc_load_tasks);
active = active > 0 ? active * FIXED_1 : 0;
// 3. 统计各个时间段系统平均负载
avenrun[0] = calc_load(avenrun[0], EXP_1, active);
avenrun[1] = calc_load(avenrun[1], EXP_5, active);
avenrun[2] = calc_load(avenrun[2], EXP_15, active);
// 4. 更新下次统计的时间(增加5秒)
calc_load_update += LOAD_FREQ;
...
}calc_global_load() 函数主要完成 4 件事情:
- 判断当前时间是否需要进行统计,如果还没到统计的时间间隔,那么将不进行统计(5秒统计一次)。
- 获取活跃进程数(可运行状态进程数 + 不可中断休眠状态进程数)。
- 统计各个时间段系统平均负载(1分钟、5分钟和15分钟)。
- 更新下次统计的时间(增加5秒)。
从上面的分析可知,calc_global_load() 函数将会调用 calc_load() 来计算系统平均负载。其代码如下:
/*
* a1 = a0 * e + a * (1 - e)
*/
static unsigned long
calc_load(unsigned long load, unsigned long exp, unsigned long active)
{
load *= exp;
load += active * (FIXED_1 - exp);
load += 1UL << (FSHIFT - 1);
return load >> FSHIFT;
}calc_load() 函数的各个参数意义如下:
- load:
t-1时间点的系统负载。 - exp:衰减系数。
- active:活跃进程数。
可以看出,calc_load() 函数的实现就是按照 指数平滑法 来计算的。
参考文献:
- 《Understanding Linux CPU Load》https://scoutapm.com/blog/unders> tanding-load-averages
- 《Linux系统平均负载是如何计算的》https://blog.csdn.net/rikeyone/article/details/108309665