包管理工具的演进
前言
通过 Node.js 官方内置可以看出,目前前端领域最火的包管理工具主要是 npm( Node.js 直接内置)、yarn (corepack 内置) 以及 pnpm (corepack 内置)。
因此,本文主要是围绕这三者来阐述包管理工具在迭代演进中提出的一些创新性特性以及其遇到困难是如何解决问题的。
npm
嵌套结构的依赖
npm 作为前端领域最早的包管理工具,其早期版本(v1/v2)的工作模式和现在还是有很大的区别,其中最典型的就是 node_modules 的目录管理。
拿以下依赖关系为例:
Application -> A -> B
-> C -> B则 node_modules 目录结构为:
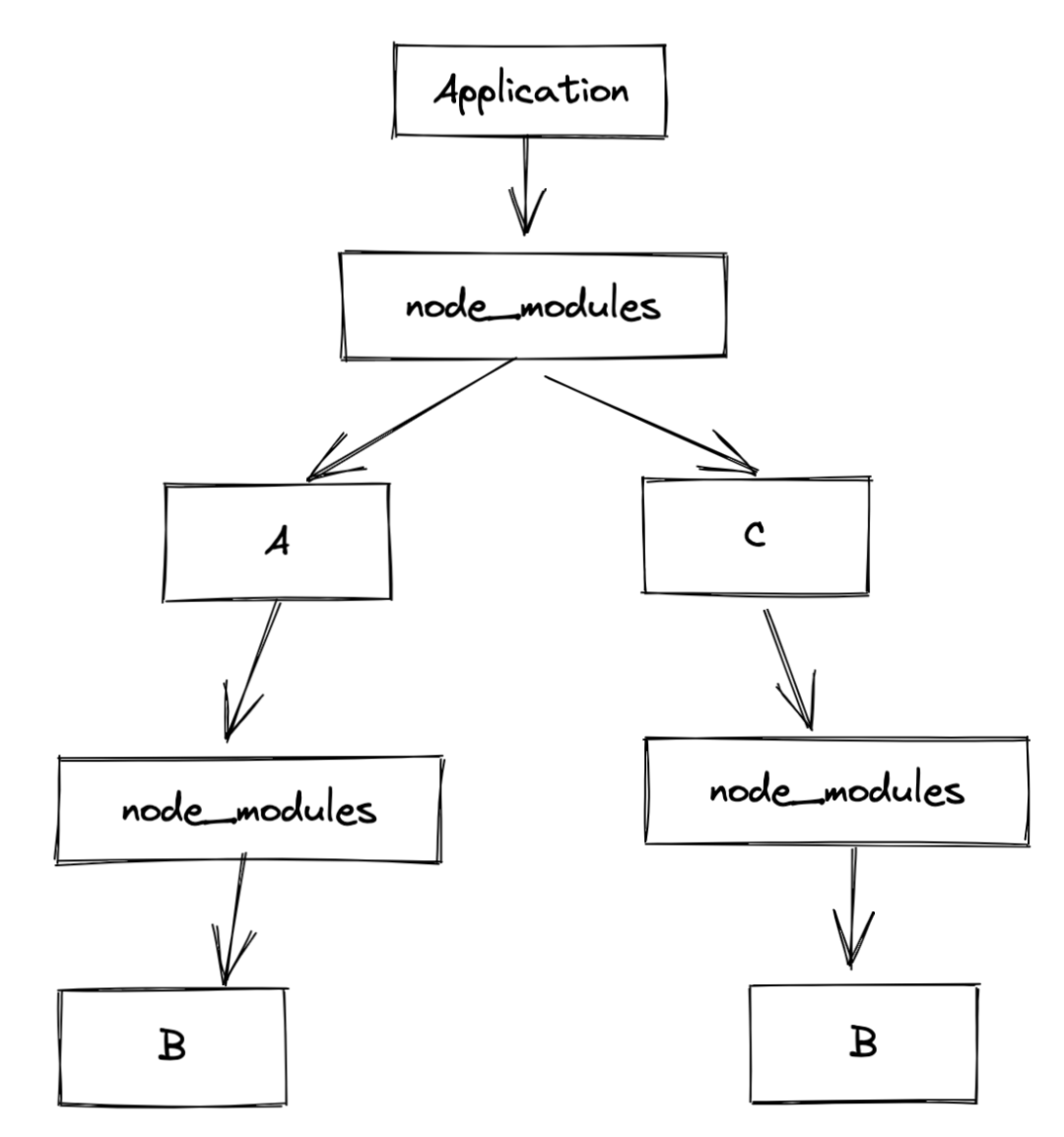
1 . 依赖包重复安装
这个问题在上图中就可以很明显的看出来,B 包被 A 依赖,同时也被 C 所依赖,因此 B 包就分别在 A 和 C 之下分别被安装了一次。这都是没有考虑包版本问题存在的情况下,依赖包都会被重复安装。此种设计结构直接导致了 node_modules 体积过度膨胀,这也是臭名昭著的 node_modules hell 问题。
2 . 嵌套层级太深
同样如上图所示,应用依赖 A 和 C,而 A 的 node_modules 中又安装了 B,如果 B 也依赖其他包,那么 B 又会存在一个 node_modules 中来存放其他依赖包,如此层层递进。
而 Windows 以及一些应用工具无法处理超过 260 个字符的文件和文件夹路径,嵌套层级过深则会导致相应包的路径名很容易就超出了能处理的范围 ,因此会导致一系列问题。比如在想删除相应的依赖包时,系统就无法处理了。(参见:Node's nested node_modules approach is basically incompatible with Windows[1])
除此之外,npm 还存在着一些问题被人诟病:
- SemVer 版本管理使得依赖的安装不确定
- 缓存能力存在问题,且无离线模式
因此面对上述问题,特别是 node_modules 的嵌套结构问题,经过社区的反复讨论,npm v3 几乎重写了安装程序,来试图给开发者带来更好的体验。
扁平化
针对之前 node_moduels 嵌套结构所产生的问题, npm v3 提出的解法就是目录扁平化。同样拿之前的依赖结构为例,npm v2 和 npm v3 的安装目录就完全不一致了。
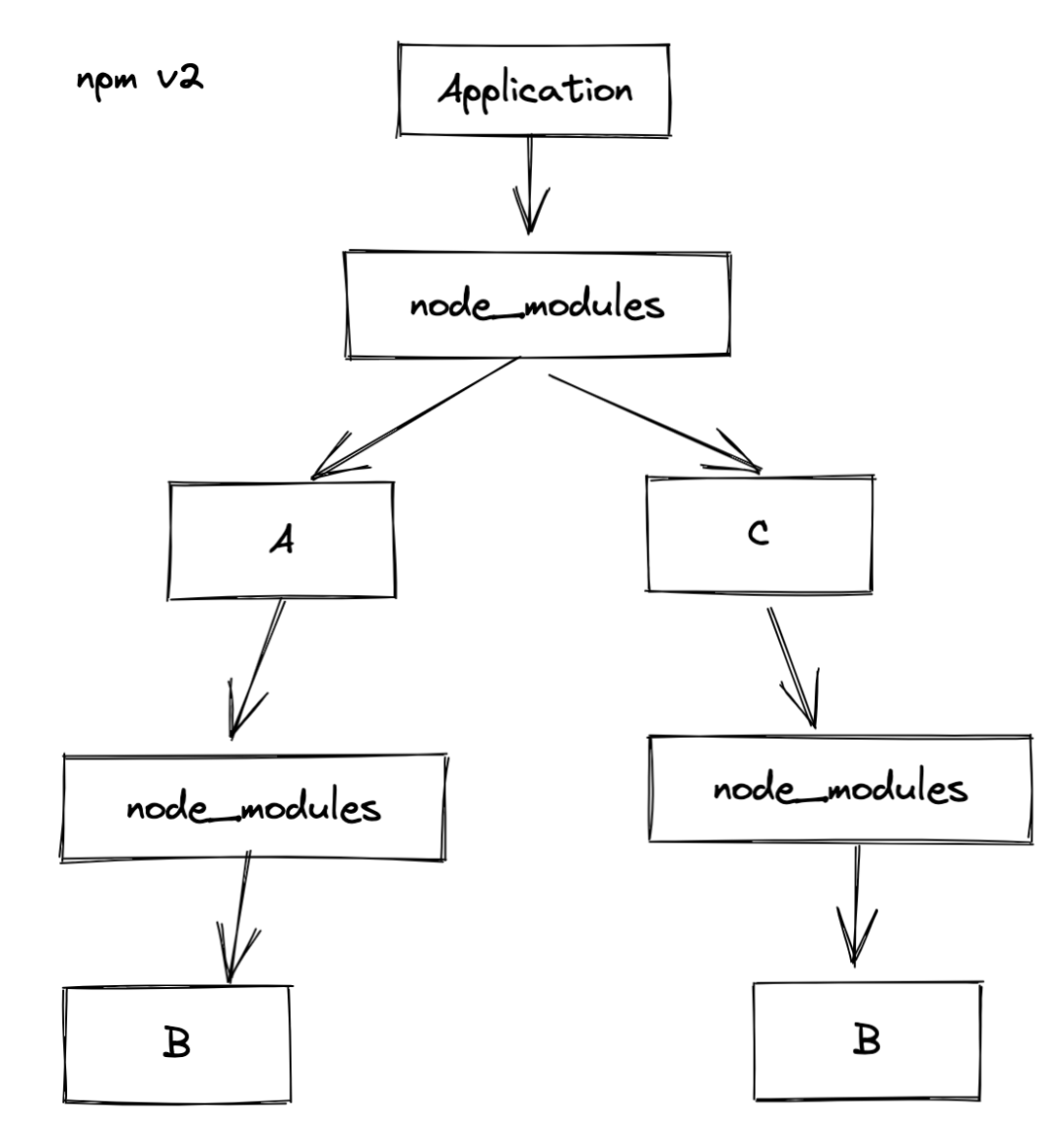
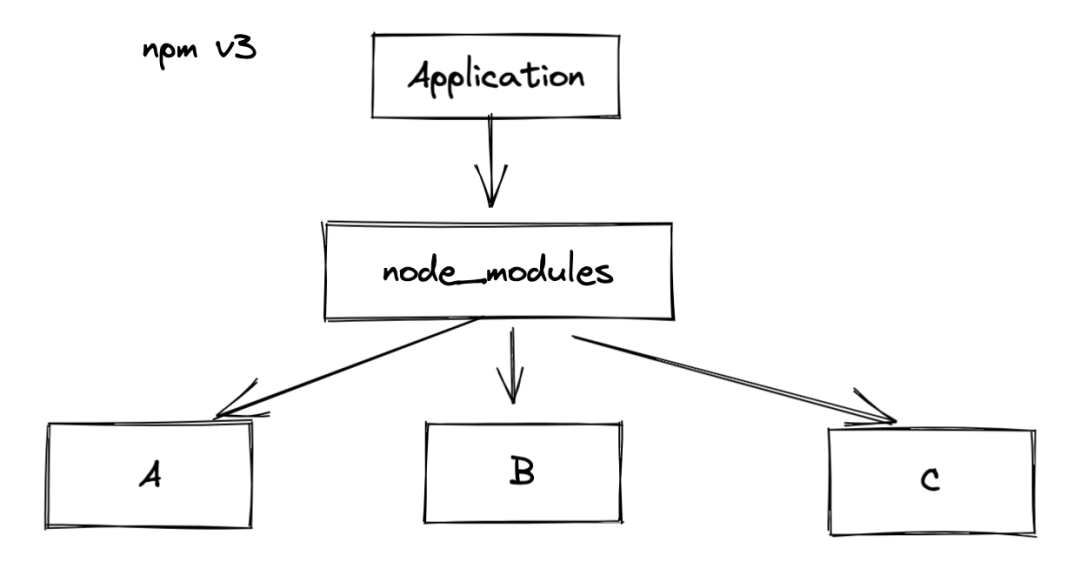
当然上面的举例只是一个理想化的简单 demo,现在考虑一下存在版本不同的情况。
依赖关系变为:
Application -> A_v1 -> B_v1
-> C_v1 -> B_v2则扁平化的目录结构为:
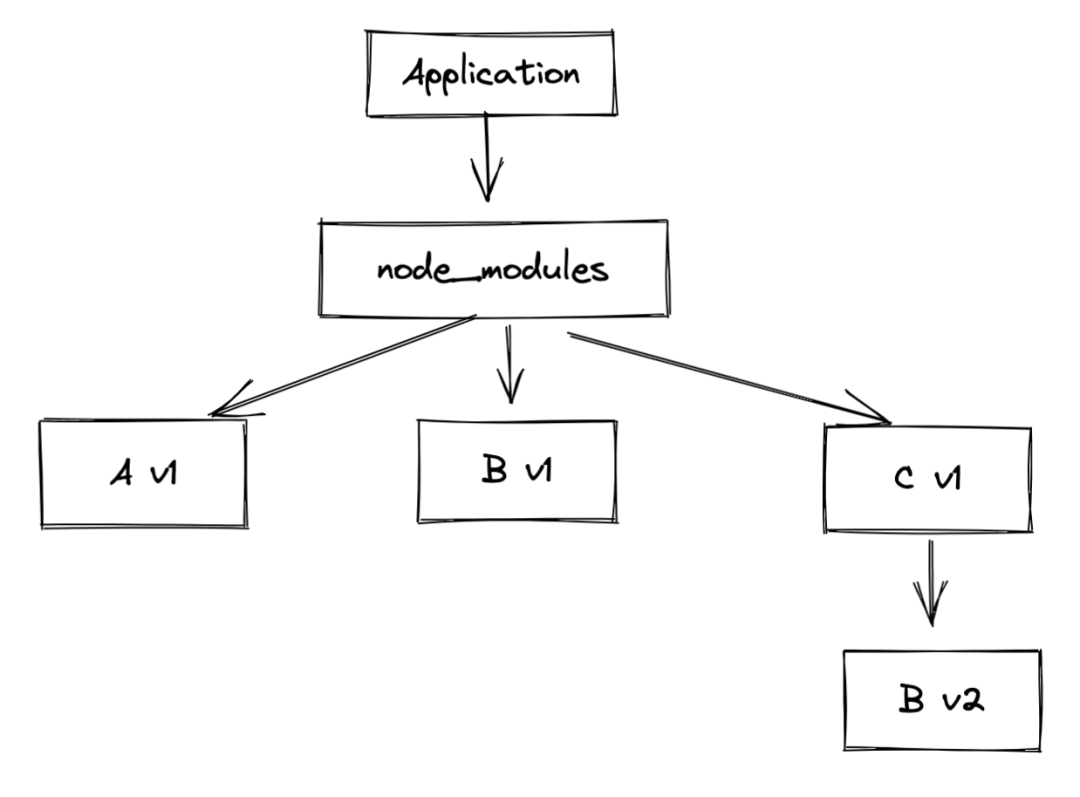
新的问题
上面提到了 npm v3 通过扁平化设计 node_modules 来尽量规避同一版本依赖包重复安装的问题和减少层级嵌套过深的问题。但是这个设计也不是十全十美的的,在解决旧有问题的同时也产生了新问题。
phantom dependencies
phantom dependencies 也称幽灵依赖,指的是业务代码中能够引用到 package.json 指定依赖以外的包。拿上面提到过的依赖关系为例:
doppelgangers
将上面提到的依赖关系中再加入一个 D v1 包,则依赖关系变为:
Application -> A_v1 -> B_v1
-> C_v1 -> B_v2
-> D_v1 -> B_v2那么 node_modules 目录结构变为:
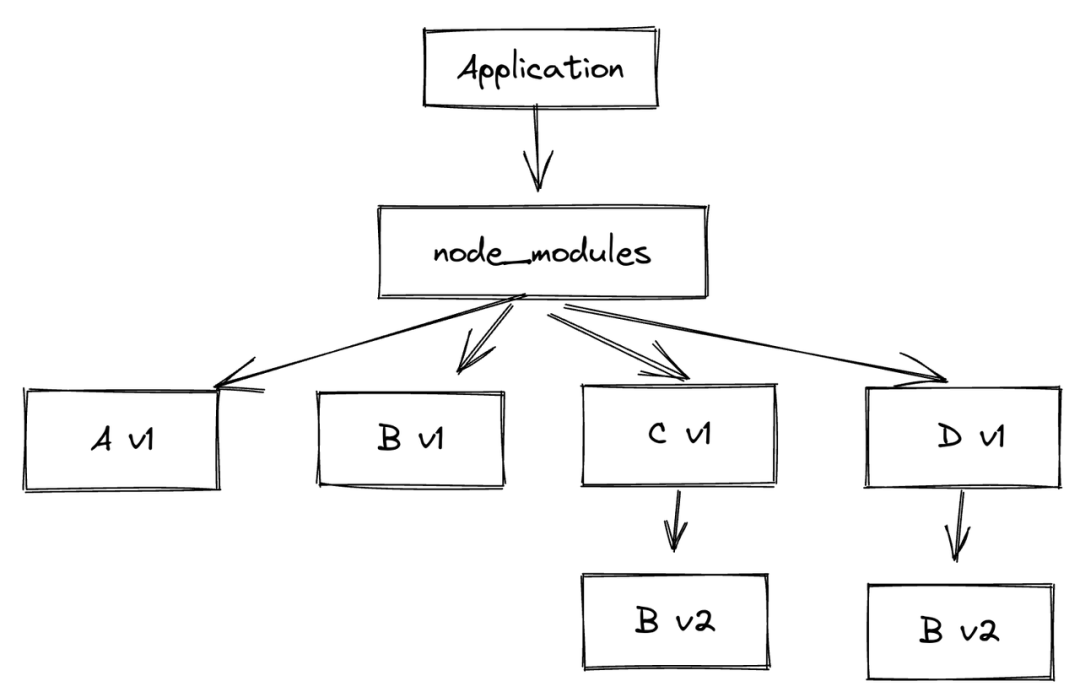
被加重的依赖不幂等
先不考虑 doppelgangers 的现象,可以转过来思考一下 B v2 明明有两个却没有提升到顶层,仍然还是 B v1 在顶层,是什么决定的这个关系呢。
安装顺序很重要!
正常来说,如果是 package.json 里面写好了依赖包,那么 npm install 安装的先后顺序则由依赖包的字母顺序进行排序,那如果是使用 npm install 对每个包进行单独安装,那就看手动的安装顺序了。
如果是先安装的 C v1 ,然后再安装的 A v1,那么提升到顶层的就是 B v2 了。
如果情况再复杂一点,即 Application 又依赖了 E v1 的包:
Application -> A_v1 -> B_v1
-> C_v1 -> B_v2
-> D_v1 -> B_v2
-> E_v1 -> B_v1那么目录结构就会变成

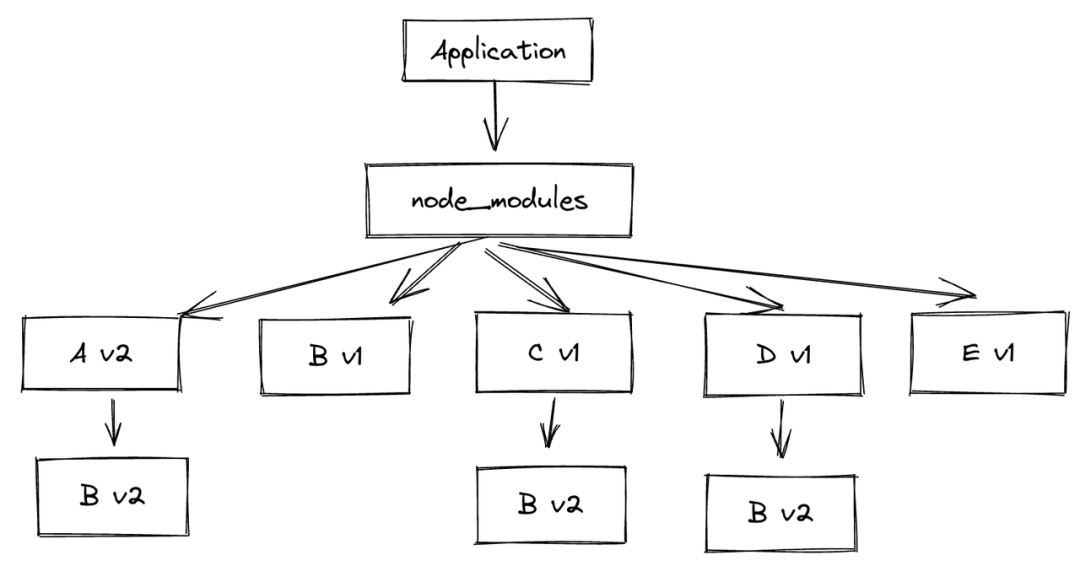
但是,当这版代码上传到服务器上进行部署时,依赖进行重新安装,由于 A v2 的依赖会被最先安装,所以服务器上的依赖树结构则为如下:
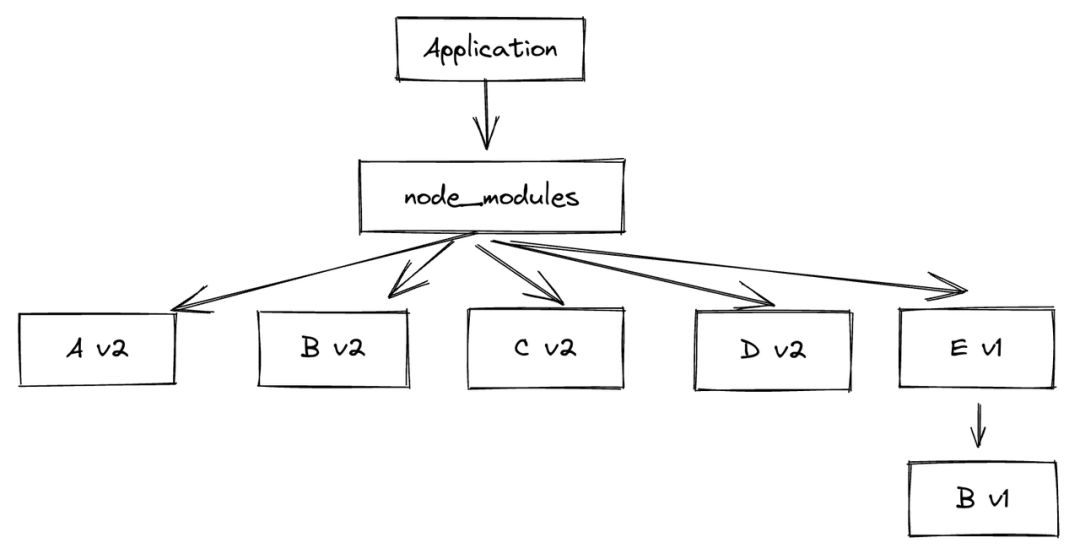
锁文件
上面提到三个典型问题,其中依赖不幂等的问题在 npm v3 中是提出了相应的解决方法的,那就是 npm-shrinkwrap.json 文件
在 npm v3 版本中,需要手动运行 npm shrinkwrap 才会生成 npm-shrinkwrap.json 文件,之后每次改动版本依赖,都无法自动更新 npm-shrinkwrap.json 文件,仍然需要手动运行更新,因此这个特性对于开发者来说有一定的成本(开发者可能不知道该特性,或者没有每次及时更新)。
之后受到 yarn.lock 的启发,npm 在 v5 版本中设计了我们现在比较熟悉的 package-lock.json 文件,此时锁文件就是自动生成和更新了。
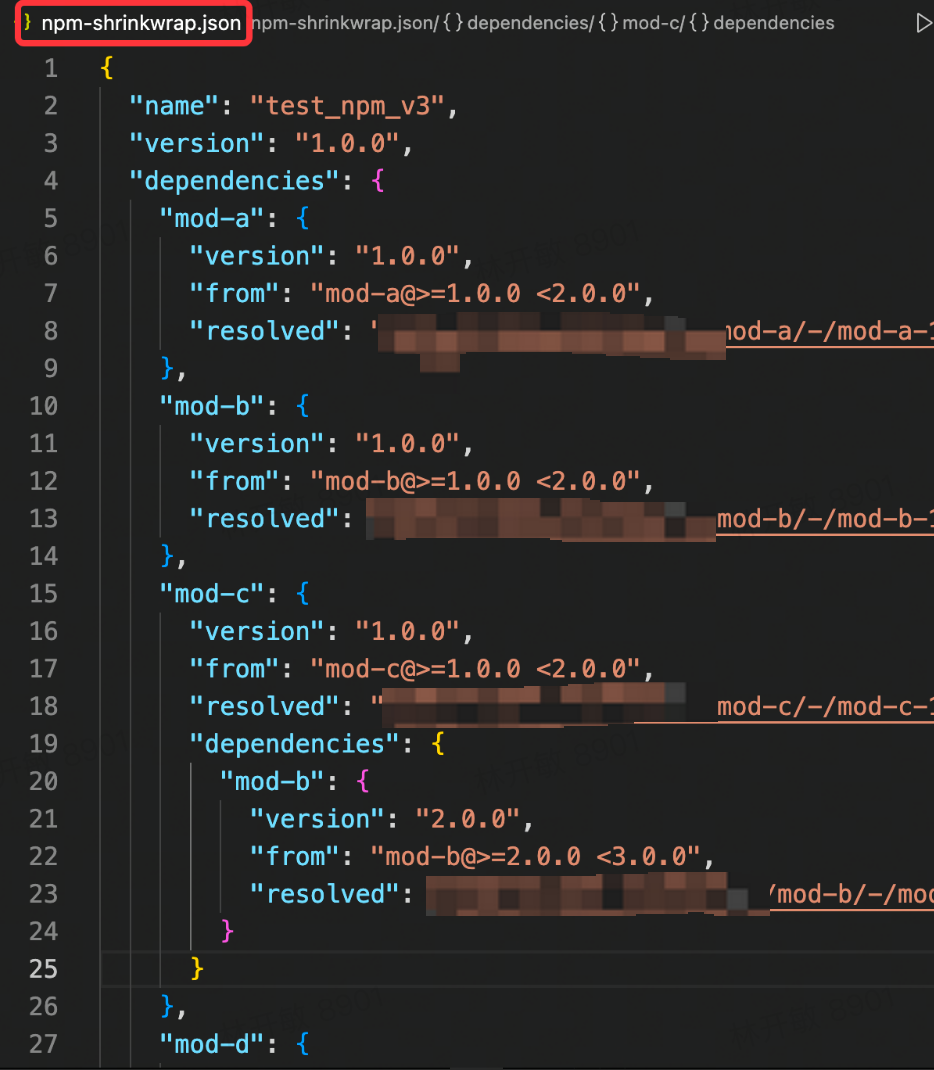
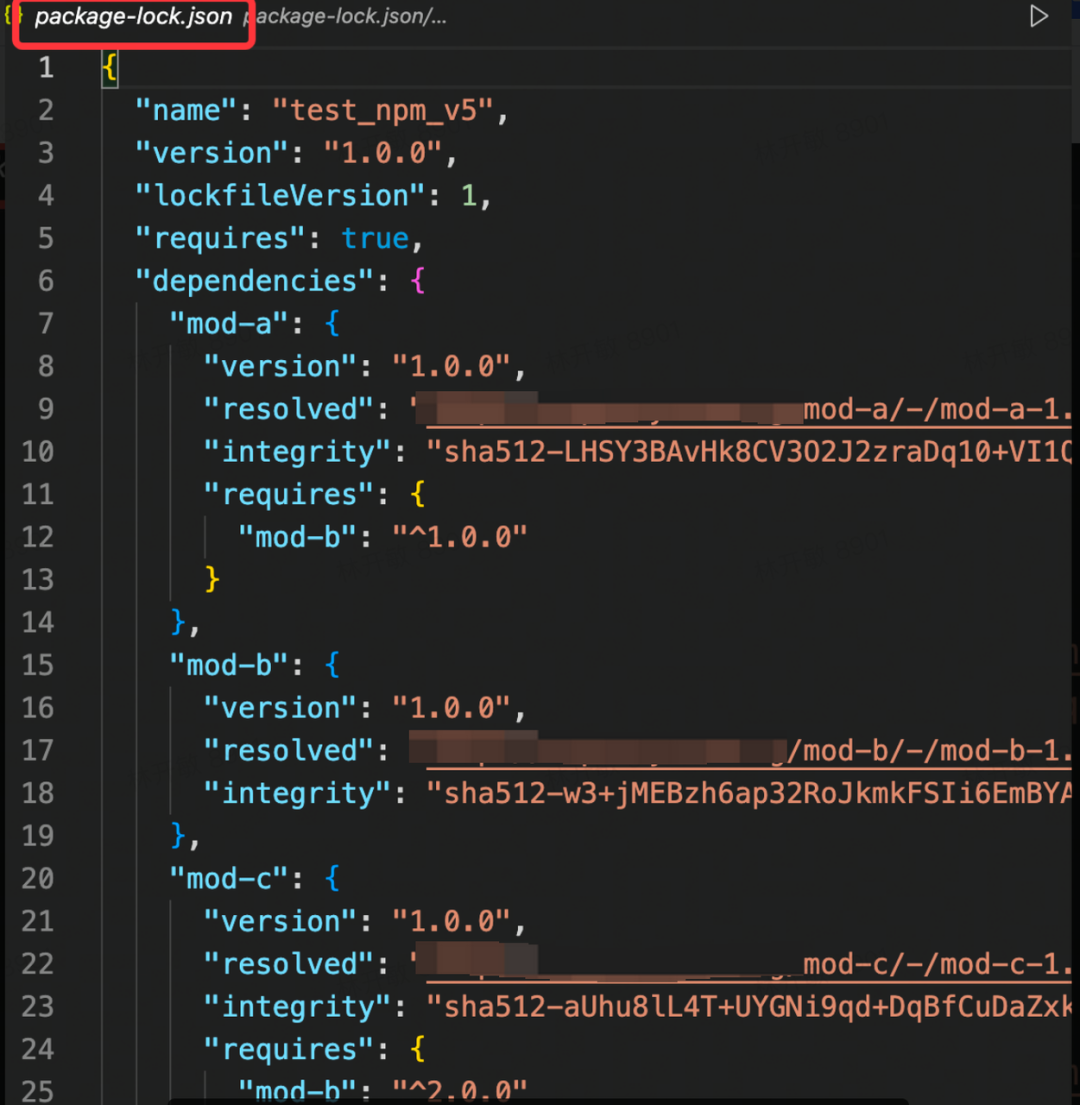
- package-lock.json 不会在发布包中出现
之前 npm-shrinkwrap.json 允许在发布包中进行版本控制,这样使得子依赖包的版本不容易被共享,从而增加依赖包的体积。
- package-lock.json 多了 integrity 参数,用来进行包的SRI[2]验证。
在本地存在 package-lock.json 文件的情况下,npm 就不需要再去请求查看依赖包的具体信息和满足要求的版本,而是直接通过 lock 文件中内容先去查找文件缓存。若发现没有缓存则直接下载并进行完整性校验,如若无误,则安装。
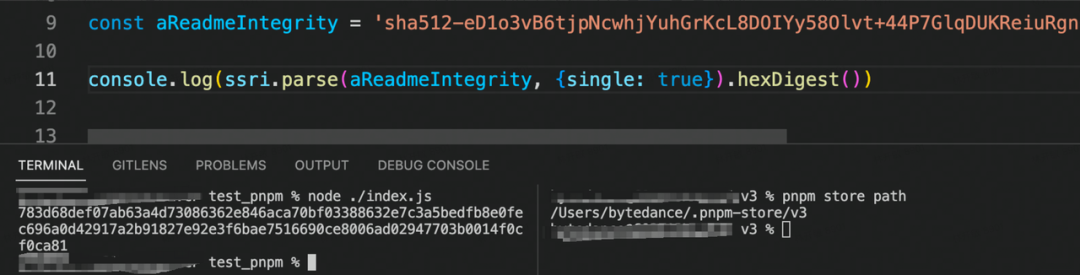
这边简单举例一下完整性校验的 demo,拿 mod-a 包为例,其 integrity 值为:
sha512-LHSY3BAvHk8CV3O2J2zraDq10+VI1QT1yCTildRW12JSWwFvsnzwLhdOdrJG2gaHHIya7N4GndK+ZFh1bTBjFw==
// 其格式为:(加密函数)-(摘要)那么先下载包,包路径为 resolved 值:http://bnpm.byted.org/mod-a/-/mod-a-1.0.0.tgz
然后对包进行 SHA512 加密并进行 base64 编码:

yarn
yarn 0.x 版本正式发布的时候,是在 2016 年,也就是 npm v4 还没有发布之前。Yarn 的诞生是由于当时 Facebook 的工程师不满足 npm 所存在的一系列问题,从而开发出来的一个新的包管理工具。由于后发优势,yarn 0.x 版本吸取了 npm v3 优点的同时,也作出了自己的创新:
- 扁平化目录结构
yarn 的扁平化结构和 npm 基本类似,但是对重复安装包计算上更加智能一些。
在上面锁文件小节中提到在将 A v1 升级到 A v2 时, npm 安装的时候会出现以下情况:
- 锁文件:yarn.lock
对比于当时 npm 的 npm-shrinkwrap,yarn.lock 不需要手动生成,而是自动生成和更新。这一点在 npm v5 中被借鉴。
- 并行安装,提升安装速度
- 缓存机制,支持离线安装
workspaces
之后随着 monorepo 的项目管理方式被逐渐推广,比如 babel 为了管理多包问题开发了 lerna。yarn 也顺势在 v1 版本也增加了相应的功能:yarn workspaces 。
对比早期的 lerna,yarn workspaces 有一个最主要的优势:
lerna bootstrap 是在每个子包内部进行依赖包的单独安装,而 yarn 对依赖包会尽量进行 hoist 处理,也就是在工程的最顶层安装依赖包,这样可以避免共同依赖被重复下载,同时也加快了安装的速度。
当然,后期 lerna 也支持了 hoist 特性,甚至也支持了配合 workspaces 使用,但是最后还是被 babel 官方给放弃并停止维护了。
可以阅读 Why babel remove lerna?[3] 来了解 babel 为什么放弃使用 lerna 来管理仓库
我们可以看到,yarn 虽然在 npm 之上做出了一定的创新和相应的改进,但是在依赖包管理方式上还是借鉴的 npm 的扁平化 node_modules 方式,并没有解决 npm 相应的痛点。也是基于此因素,使得社区部分开发者对其有点失望,pnpm 应运而生。
pnpm
pnpm 在依赖包管理方式上完全舍弃了 npm 的那一套,而是巧妙利用 symbol link 和 hard link 做出了自己的创新。
symbol link
上面提到过 npm 在扁平化 node_modules 之后带来了新的问题,而 pnpm 利用符号链接的方式重新设计了 node_modules 的结构来处理扁平化带来的问题。
复用之前提到过的依赖关系:
Application -> A_v1 -> B_v1
-> C_v1 -> B_v2
-> D_v1 -> B_v2那么目录结构则为:
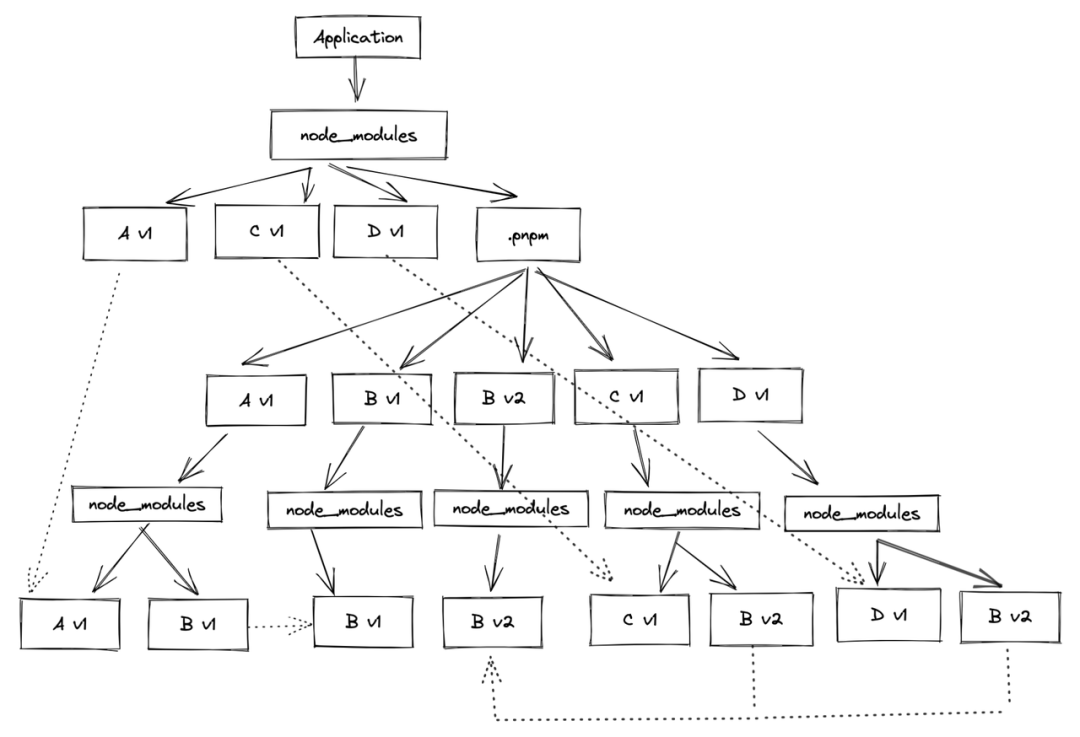
- 只有应用直接依赖的 A v1、C v1 以及 D v1 包在 node_modules 顶层中,而依赖的依赖,比如 B v1 和 B v2 都不在。那么如果在项目中直接引用 B 就无法找到相应的依赖包,直接报错。因此这点完全避免了 phantom dependencies 的发生。
- 顶层 node_module 中的 A v1、C v1 以及 D v1 包都是源文件依赖包的 symbol link,源文件依赖包还有其相应的子依赖包都放在了 .pnpm 目录中。
- 虽然表面上看起来 C v1 的依赖 B v2 以及 D v1 的依赖 B v2 也被重复的安装了两次,但是这两个 B v2 都是源文件 B v2 的 symbol link,因此这个设计也避免了 doppelgangers 的问题。
hard link
pnpm 在安装的过程中,会在全局的 store 目录中去存储依赖包,然后在项目对应的 node_modules 中创建相应的硬链接。由于不能对目录进行 hard link,因此不像 npm 一样缓存的是压缩包,pnpm 是将依赖包的每个文件都缓存到 store 中,然后创建相应文件的硬链。
我们可以简单看一下 demo 实例,下图为依赖关系和相应的 lock 文件:
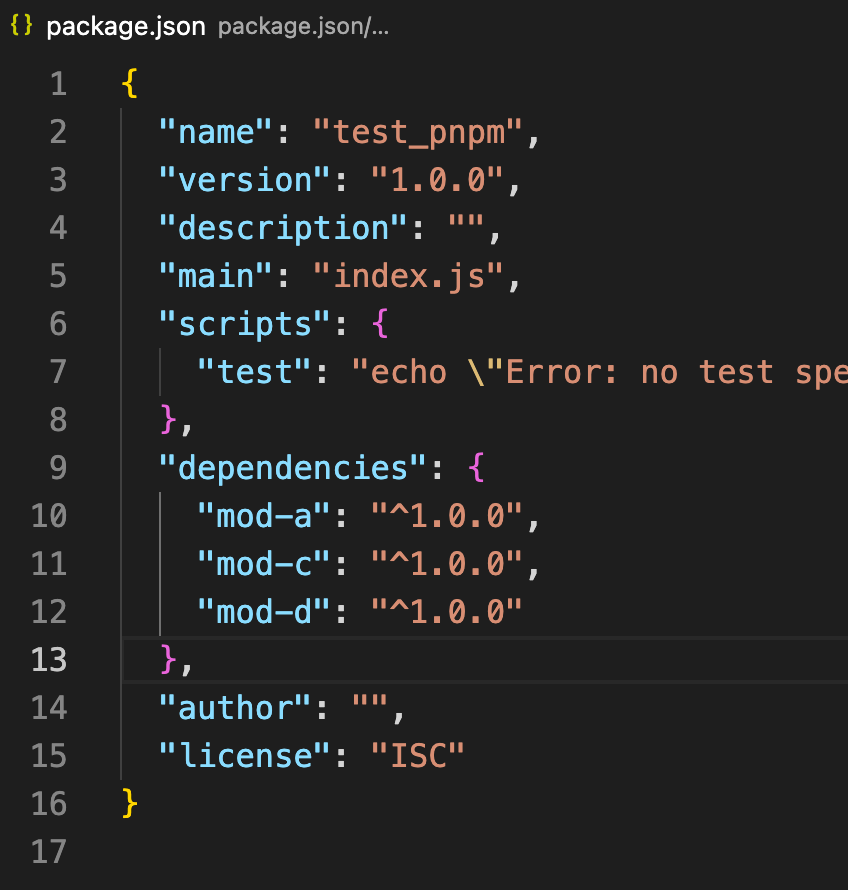
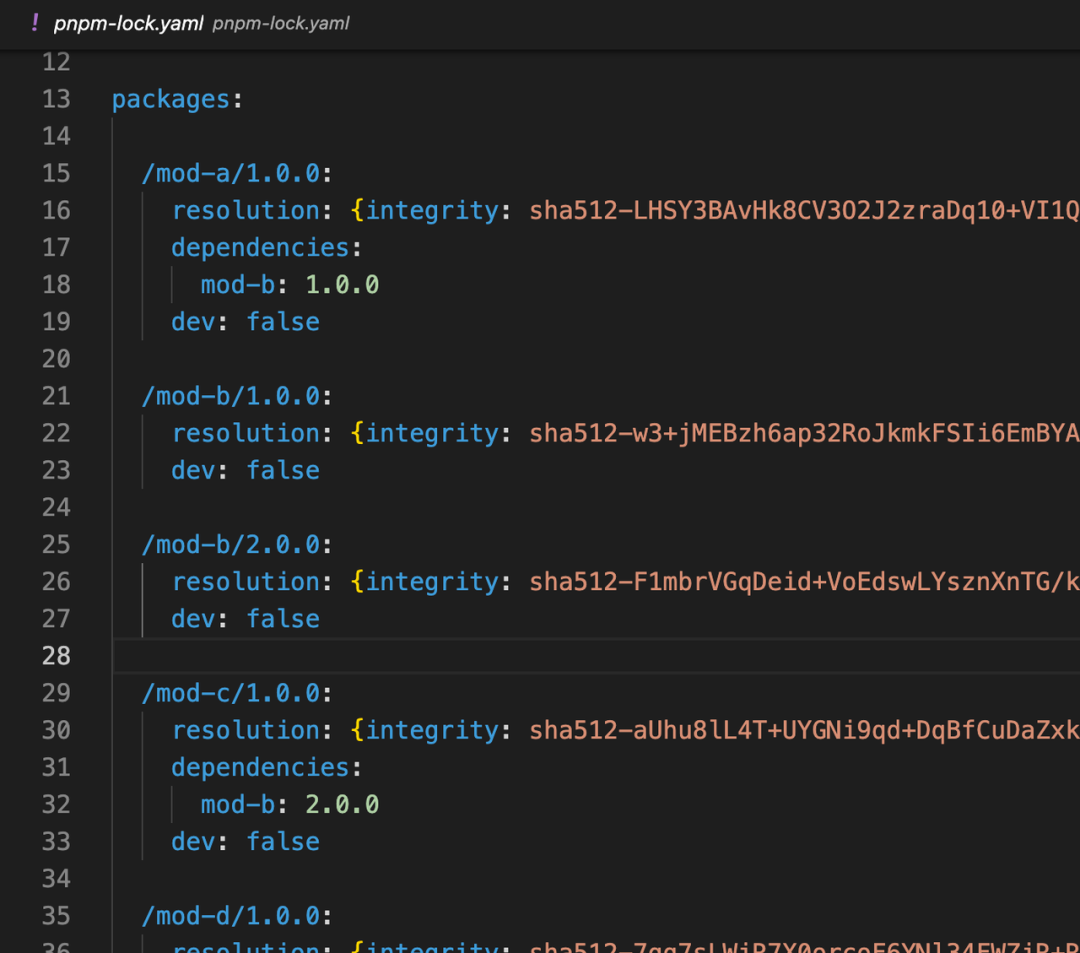
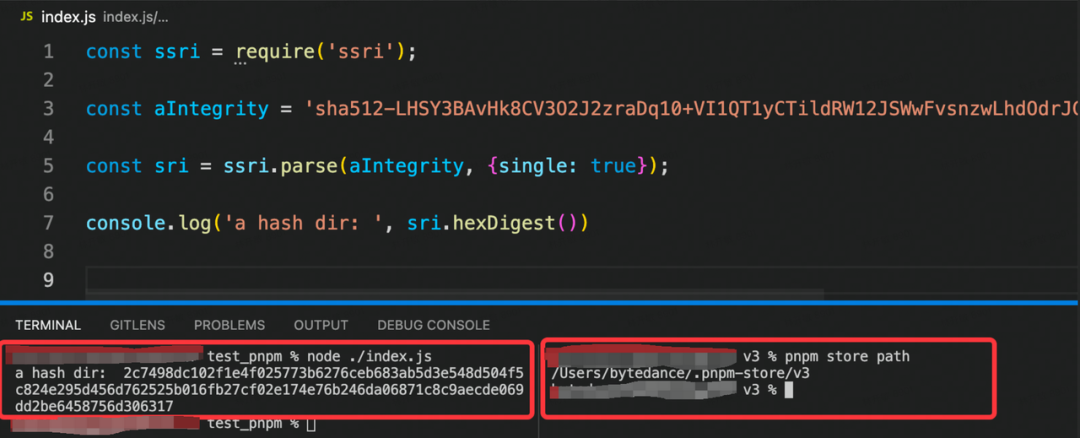
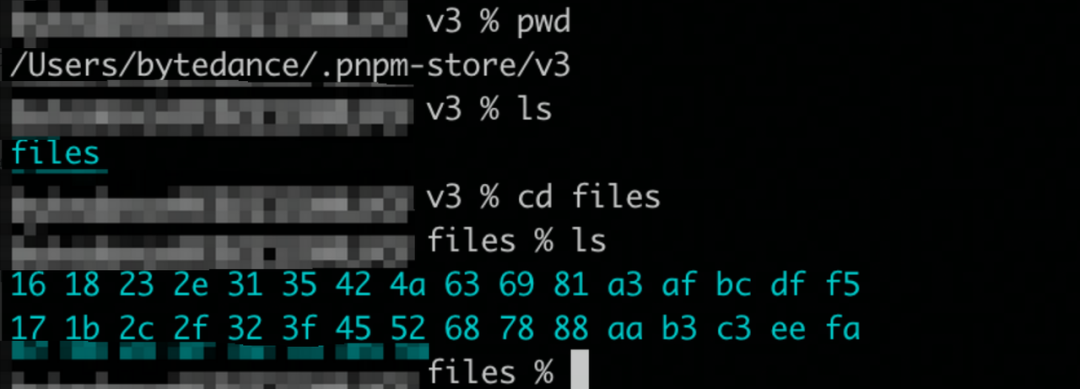
2c7498dc102f1e4f025773b6276ceb683ab5d3e548d504f5c824e295d456d762525b016fb27cf02e174e76b246da06871c8c9aecde069dd2be6458756d306317
因此进入 2c 目录下面,就可以发现 mod-a 包的信息了
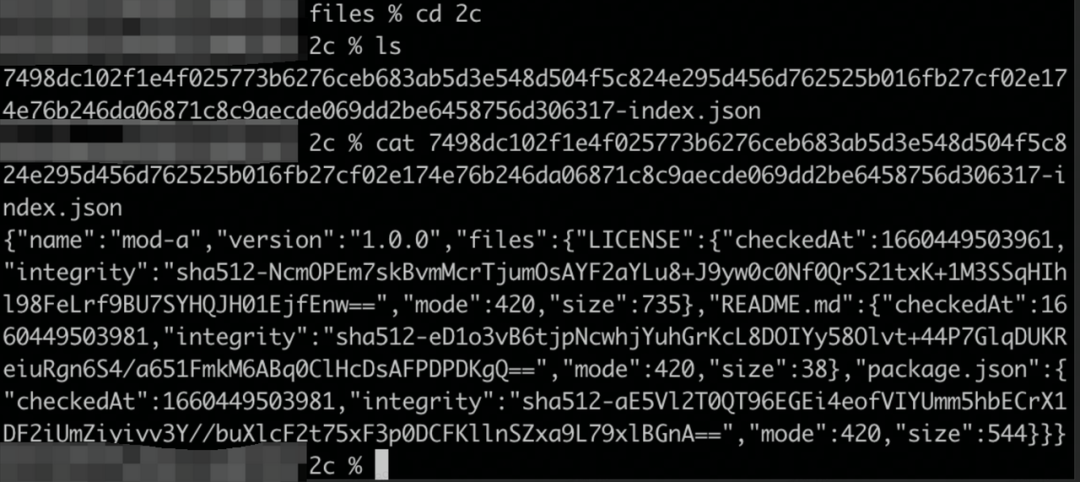

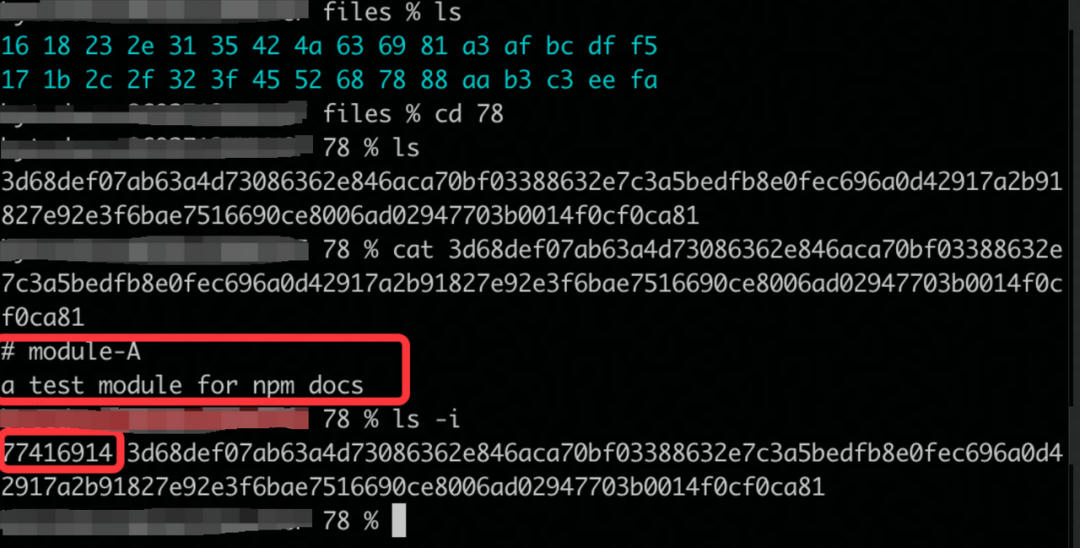
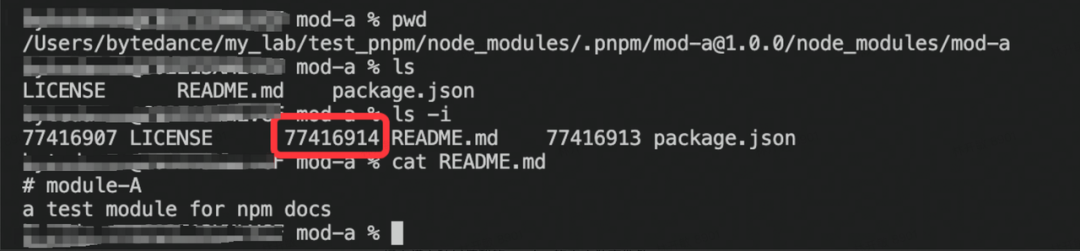
因此如果要下载的依赖包已经在 store 中存在了,就不需要重新下载,而是直接创建相应的硬链接即可,很大程度的节省了下载时间。
此外,在本地往往会有多个工程在开发,而每个工程的依赖项大多时候都是大同小异的,因此统一在 store 中管理存储并硬链出去的方式允许跨项目共享同一版本的依赖,从而也节省了大量的存储空间。
why hard link
有一点值得提出来思考一下,为什么 pnpm 既要用 symbol link,又要使用 hard link,为什么不能全部使用一种呢。
为了弄清楚这个问题,同时加深对此模式的理解,我们需要明白 symbol link 和 hard link 对 node 寻包的影响。
demo 如下
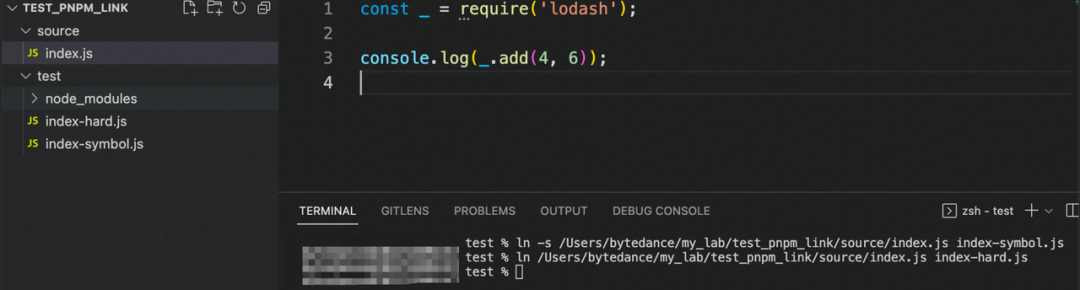
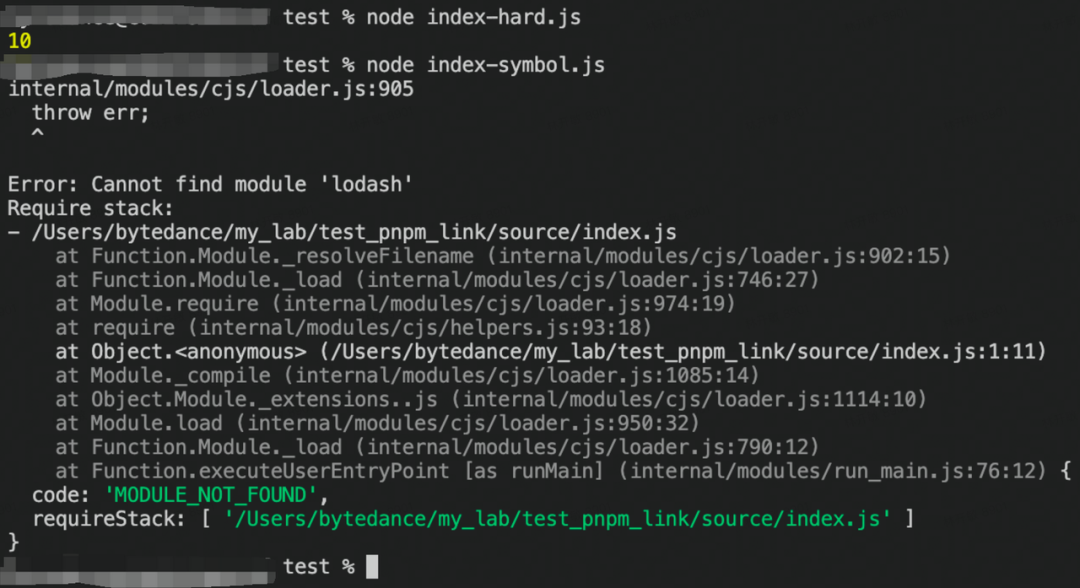
接着在 source 中也创建一个 node_modules,然后再次运行
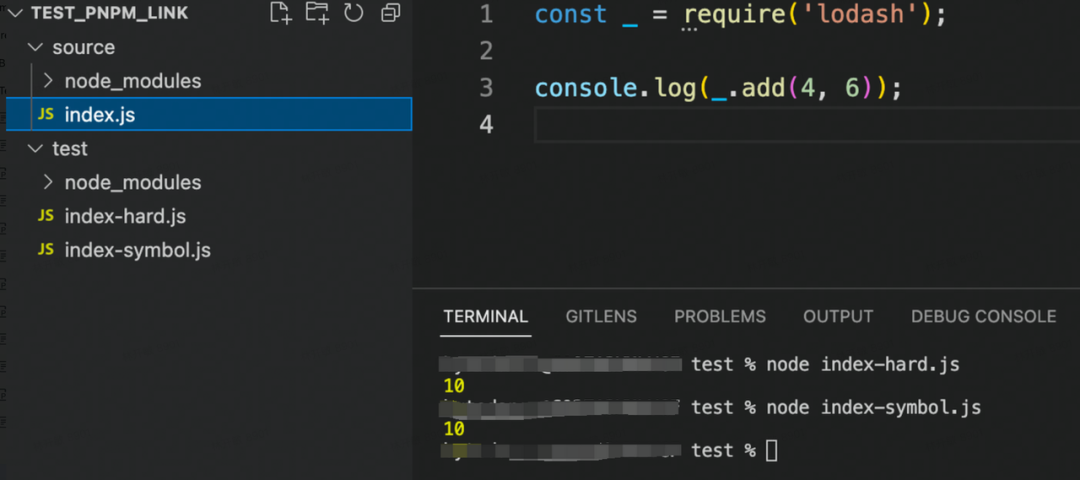
从这个 demo 可以看出,symbol link 的文件会回到源文件的目录去寻找依赖包,而 hard link 的文件则会在文件本来的目录下去寻找依赖包。
其实回过头来发现,.pnpm 目录的设计也正是利用 symbol link 的这一点去巧妙的与 node module resolution 机制结合才做到了规避 phantom dependencies 现象。而如果全部使用 symbol link 的话,那就会都去 store 中寻找子依赖了,这样就很难做到区分同个包的不同版本。
缺陷
很难有完美的设计,pnpm 解决了 npm 扁平化依赖带来的硬伤,但是同时也存在着一些小的问题:
- 兼容性问题,因为整体设计上使用了 symbol link 和 hard link, 如果所处的环境对其支持存在问题 或者某些 npm 包中写死了引用路径,就会导致使用出错。
- 因为依赖包会在 store 中全局维护,那么如果在开发中有调试 npm 的情况,修改 npm 包会导致所有工程引用的该包都发生修改。
yarn berry
上面提到 yarn 在正式发布的时候,虽然在 npm 之上做了一定的改进,但是在依赖包管理上还是借鉴了 npm 扁平化模式,没有解决依赖引用的核心问题。之后 pnpm 大胆创新的想法被提出,在设计思想层面,yarn 明显就处于了落后位置。在内卷的环境之下,yarn pnp 模式很快就被提出。之后,yarn 放弃了 yarn v1 版本的迭代,将 yarn v1 定性为 yarn classic,从而 yarn berry 诞生。
pnp 模式
yarn 认为目前包管理工具出现的各种问题很大程度上来自于 node_modules 本身:无论怎么样利用缓存,或者使用什么样的思路以及目录结构来设计 node_modules,只要你生成它,那么就需要知道 node_modules 要包含的内容并且执行繁重的 I/O 操作。
而为什么之前包管理工具一定要生成 node_modules 的依赖包呢,原因在于 node module resolution 的机制就是如此,即 node 会一层一层的依照目录层级顺序去 node_modules 中去寻找相应的依赖。
但是在安装依赖的过程中,包管理工具将会去获取并梳理项目依赖树的所有信息,那么在已知了项目依赖信息之后,为什么还要依靠 node 再去寻找一次依赖包呢,这个就是 pnp 特性要解决的问题。
在 pnp 模式下,安装项目依赖后根目录下将不会出现 node_modules 文件夹了,相应代替的则是 .pnp.cjs 文件。
使用 yarn berry 安装的项目依赖关系如下:
Application -> mod-a.v1 -> mod-b.v1
-> mod-c.v1 -> mod-b.v2
-> mod-d.v1 -> mod-b.v1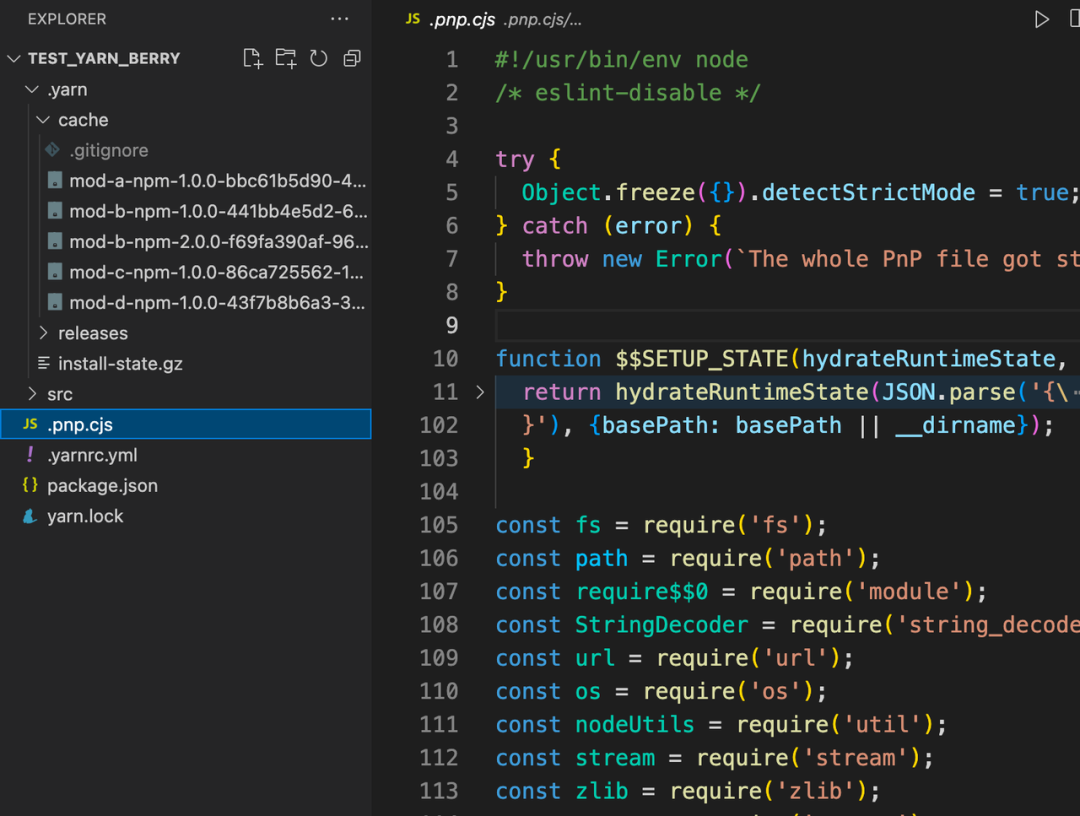
在 .pnp.cjs 文件中主要做了两件事情:
- 维护依赖包的版本、依赖包之间相互的依赖关系以及依赖包 zip 存储的位置
- 对 node 的文件解析模块打上 monkey patch,使得代码在引入依赖的时候不走原本的 node_modules 解析那一套,而是直接寻找依赖包所在的位置。
可以写一个 demo 来简单模拟一下 .pnp.cjs 的作用:
依赖包文件
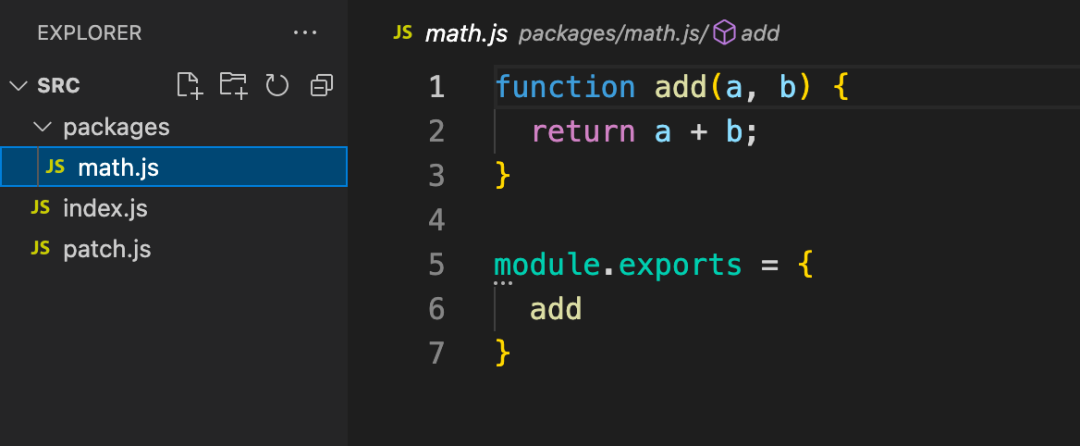
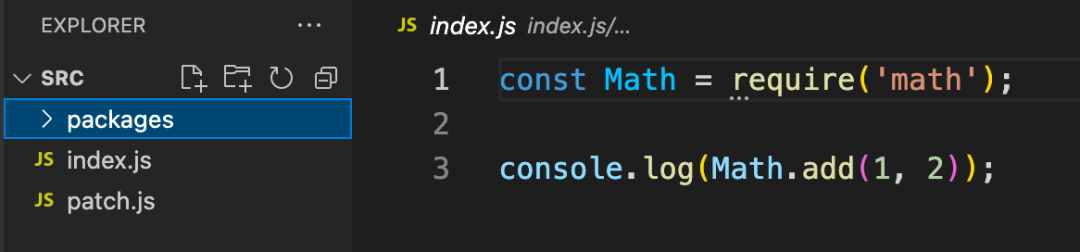

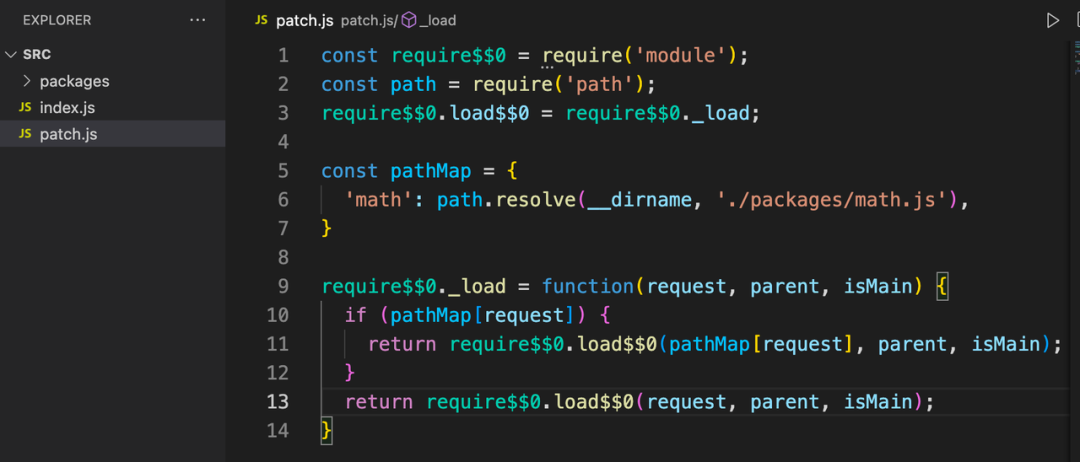

- 完全解决了 doppelgangers 和 phantom dependencies 等问题
- 减少了 I/O 操作,yarn 只需要生成 .pnp.cjs 文件和依赖包的 cache 文件,而不是像以前一样成千上万个文件,主要的瓶颈由原来的磁盘性能真正变成了依赖的数量,使得安装变得更加高效且稳定。
- 代码启动的速度更快,因为不需要使用 node 路径解析来遍历整个项目文件系统
- 如果将 cache 的 zip 文件纳入 git 管理,那么可以实现 zero-installs 能力
当然,相应的缺点也很明显,即完全脱离了 node_modules resolution 机制,步子迈得太大,因此在兼容性上有一定的问题,这个也就是 yarn berry 在刚刚推出之后不怎么受欢迎的原因。但是在后续的迭代中, yarn 在兼容性上做了很多的工作,现在主流的一些工具,比如 webpack、babel、esbuild 等都已支持 pnp 模式。
插件化
除了 pnp 模式以外, yarn berry 还提供了一种比较新颖的特性:插件扩展。从 yarn v1 到 yarn v2,yarn 将代码架构改成了支持插件化扩展的模式。通过插件扩展,我们可以实现很多增强性功能,比如为 yarn 添加新的命令、在生命周期钩子上做一些定制化的事情等。
拿一个比较有意思的官方插件 @yarnpkg/plugin-typescript 举例,通过在 afterWorkspaceDependencyAddition 生命周期钩子里面去查询安装的包是否存在有相应的 @types 的包,如果有并且没有被安装,那么就会顺便安装一下。
实验一下:


Yarn 除了提供的官方插件之外,同样也提供了 API 来鼓励用户来贡献第三方插件,可以看出从灵活性,定制化方面,yarn 插件化的设计目前是走在其他包管理工具的前面。
最后
其实关于 npm、yarn 以及 pnpm 的迭代演进远远不只是做了上面提到的工作,比如:
- npm 在 v5.x 版本中增加了 npx 命令,yarn v2 紧跟其后的 yarn dlx 命令,pnpm v6.x 也新增了 pnpm dlx 命令 以及在 v7 版本又增加了 pnpx
- pnpm 在 v5.x 版本中也支持了 pnp 模式
- yarn 在 v3.1 版本中支持了 pnpm 模式的 nodeLinker
- yarn 在 v3.1 版本中支持了 optionalDependencies 依赖分发
......
通过以上发现,包管理工具在自我创新的同时都在互相学习对方的优点,尤其是 pnpm 和 yarn,为 JavaScript 社区的发展注入了活力。而我们通过了解学习它们的演进历程,可以加深对依赖包管理的理解,从而在工程开发中更好的选型以及解决相应的问题。
参考资料
[1]Node's nested node_modules approach is basically incompatible with Windows: https://github.com/nodejs/node-v0.x-archive/issues/6960
[2]SRI: https://developer.mozilla.org/zh-CN/docs/Web/Security/Subresource_Integrity
[3]Why babel remove lerna: https://github.com/babel/babel/discussions/12622