浅析数据库的历史
1、1960-IDS
让我们把时钟拨回到上世纪 60 年代,美国通用电气公司(General Electric Company,以下简称 GE)创造了早期的基于网状模型的数据库系统 Integrated Data Store,简称 IDS。
IDS 性能较好,在当时也被用于工业领域,在 1969 年,GE 将自己的计算机业务卖给了 Honeywell 这家公司。

IDS 的主要开发者是一个叫 Bachman 的人,因为其在数据库方向的发明,他在 1973 年获得了图灵奖。

当时的主要计算机开发语言叫做 COBOL(Common Business Oriented Language),于是 Bachman 和其他人参与制定了计算机访问数据系统的标准,叫做 CODASYL。
这个标准主要制定了网状模型,以及 tuple-at-a-time 的查询方式。
网状模型(Network Model)使用有向图来表示实体与实体之间的关系。
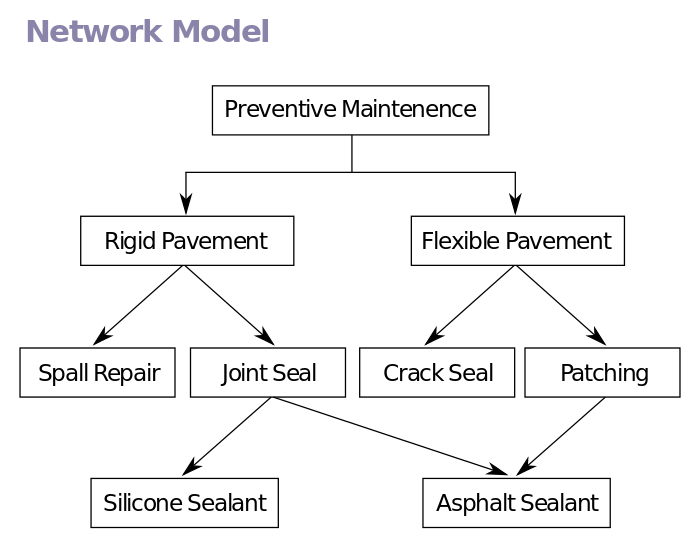
这种结构逻辑复杂,不利于查询数据,后来逐渐被关系型数据模型取代。
2、1960-IBM IMS
同样是在 60 年代,蓝色巨人 IBM 研发了基于层级结构模型的数据库系统 Information Management System,简称 IMS。

IMS 最初的研发目的是为了来自阿波罗登月计划的订单。
层次模型(Hierarchical Model)使用树形结构来表示实体之间的关系。
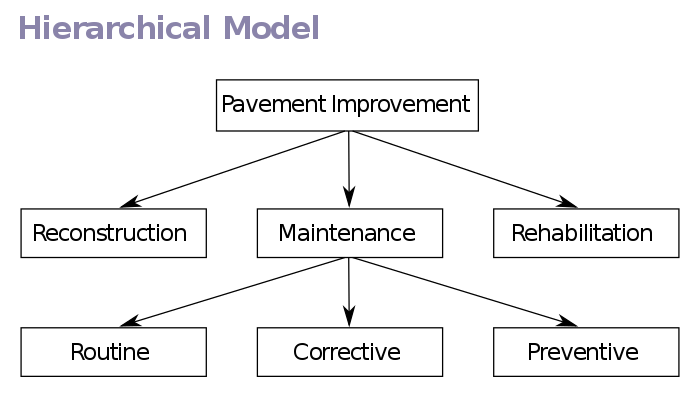
这种结构比较符合人的直观思维,从上至下,每个节点只能有向下的子节点。
3、1970-Relational Model
时间来到了 1970 年代,在层次和网状模型的标准下,IBM 的工作人员会因为数据库的结构表更而不断地重写代码,这非常的浪费人力。
一个名叫 Ted Codd,在 IBM Research 工作的人,提出了几个规范,来避免这种情况。
这几个规范分别是:
- 存储数据在简单的数据结构中
- 能够通过高级语言来访问数据
- 上层不用关心数据物理存储的细节

为了使数据库脱离应用,成为一个更加独立的系统,避免数据库的变更影响到上层应用,Codd 提出了关系型模型。
关系型模型(Relational Model)是沿用至今的数据库模型,已经事实上基本成为了行业标准。
关系模型基于二维表,每个实体都被映射为一张表,每个实体之间可以通过表中的记录进行关联。
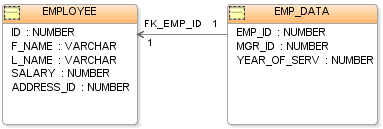
基于关系型模型,在 1970 年代诞生了三个主要的数据库系统,分别是由三位数据库界的远古大神开发的。
System R—来自 IBM Research 部门,主要开发者 Jim Gray
Ingres—这是 PostgreSQL 的前身,伯克利大学,主要开发者 Stonebraker
Oracle—拉里·埃里森(Larry Ellison),Oracle 公司的总裁

4、1980-Relational Model
到了 80 年代,数据库仍然是关系型模型及相关数据库蓬勃发展的阶段。
IBM 在 1983 年发表了至今仍广泛应用的数据库系统 DB2。 由于 IBM 在 System R 和 DB2 均使用了 SQL,于是他们将 SQL 制定成为了访问数据库的行业标准。
Oracle 和 Ingres 均完成了商业化,并且这时期还有很多其他的商业化数据库,例如 Informix、Sybase、Teradata 等,但是数据库市场主要被 Oracle 占据。

Stonebraker 回到了伯克利大学,并且创建了一个新的数据库系统 Postgres,其含义是 Ingres 之后(post)的系统。
5、1990-Boring Days
90 年代,在数据库设计方面并没有太大的变化,这段时期可能看起来比较的无聊(Boring),但是仍然有一些值得关注的事情。
微软进入了数据库市场,他们 fork 了 Sybase 系统,并且创造了自己的数据库系统 SQL Server。
MySQL 出现,主要由 Michael Widenius 开发,MySQL 这个名字主要源于他女儿(My)。
Postgres 系统支持了标准 SQL,于是它的名字也演化成了现在为人熟知的 PostgreSQL。
SQLite 也在在这个时期开始开发,并成为如今流行的嵌入式数据库系统。

6、2000-Data Warehouse
在 2000 年代,针对特殊的应用场景,OLAP 类型的数据库开始出现了。
这种类型的数据库主要用于构建数据分析类型的数据仓库(Warehouse),并且大多是分布式部署,以列存为主。
这时期主要的产品有 Greenplum、Vertica、MonetDB 等。

7、2000-NoSQL
同样是在 2000 年代,人们发现一些场景下,数据库的可扩展性、高可用特性更加的重要,而并不怎么依赖于关系型数据库(不需要事务,不需要标准 SQL),于是诞生了很多 NoSQL 数据库。
他们的主要特征有:
- 非关系型的数据模型,例如文档型、Key/Value,Graph 等
- 不提供 ACID 的事务保证
- 自定义的 API,没有标准的 SQL
- 通常是开源的
这时期 NoSQL 数据库的主要产品有 HBase、DynamoDB、MongoDB、Redis 等。

8、2010-NewSQL
到了 2010 年代,为了兼容 NoSQL 的高可用、高性能,同时又不丢弃传统数据库的 ACID 事务等特性,诞生了一批被称为 NewSQL 的数据库系统。
它们的特征主要是:
- 基于关系模型,支持标准 SQL
- 分布式
这类数据库的鼻祖应该是 Google Spanner,随后基于此,诞生了一些著名的分布式 NewSQL 数据库,例如 CockroachDB、YugaByte、TiDB。

9、2010-HTAP System
还是在 2010 年代,为了兼容 OLTP 和 OLAP 类型的数据库系统,出现了一种 HTAP(Hybrid Transactional-Analytical Processing) 类型的数据库。
这类数据库的特征是,既能兼容 OLTP 数据库的高性能,执行 SQL 查询,并且能够像数据仓库(Data Warehouse)那样进行大规模的数据分析。
其主要数据库有 HyPer、MemSQL、SAP HANA 等。

10、2010-Cloud System
在 2010 年代,还开始出现了一些运行在云上的数据库系统,这类数据库需要从一开始就适配云环境,提供类似 Database-as-a-service(DBaaS)的服务。
最著名的产品例如 snowflake、Amazon REDSHIFT 等。

11、2010-Graph&Timeseries Database
除了传统的关系型数据库,前面已经提到了一些 NoSQL 数据库,在大约 2010 年代,诞生了一些其他类型的 NoSQL 数据库。
例如 Graph Database(图数据库)、Timeseries Database(时序数据库)等。
图数据库比较知名的产品有 neo4j、TigerGraph、Nebula Graph 等。

时序数据库比价知名的产品有 InfluxDB、Timescale、TDengine 等。
12、Conclusion
随着硬件技术、应用场景等不断的变化,最近的这些年,在不同的领域,不同的应用方向,诞生了很多不同类型的数据库。例如多模数据库(Multi-Model)、区块链数据库(Blockchain)、流式处理数据库(Streaming)等等。
数据库行业呈现出了百花齐放的格局。

这也造就了这些年资本市场对于数据库行业的垂青,数据库创业也火的一塌糊涂。
未来数据库会朝着什么样的方向发展,会呈现出什么样的格局呢,让我们拭目以待吧。