记一次“雪花算法”造成的生产事故的排查记录
本文主要内容如下:
前言
最近生产环境遇到一个问题:
现象:创建工单、订单等地方,全都创建数据失败。
初步排查:报错信息为duplicate key,意思是保存数据的时候,报主键 id 重复,而这些 id 都是由雪花算法生成的,按道理来说,雪花算法生成的 ID 是唯一 ID,不应该出现重复的 ID。
大家可以先猜猜是什么原因。
有的同学可能对雪花算法不熟悉,这里做个简单的说明。(熟悉的同学可以跳到第二个段落)
一、雪花算法
snowflake(雪花算法):Twitter 开源的分布式 id 生成算法,64 位的 long 型的 id,分为 4 部分:

- 1 bit:不用,统一为 0
- 41 bits:
毫秒时间戳,可以表示 69 年的时间。 - 10 bits:5 bits 代表机房 id,5 个 bits 代表机器 id。最多代表 32 个机房,每个机房最多代表 32 台机器。
- 12 bits:同一毫秒内的 id,最多 4096 个不同 id,自增模式
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨(可以搜索 2017 年闰秒 7:59:60找到相关问题),会导致发号重复或者服务会处于不可用状态。
闰秒就是通过给“世界标准时间”加(或减)1秒,让它更接近“太阳时”。例如,两者相差超过0.9秒时,就在23点59分59秒与00点00分00秒之间,插入一个原本不存在的“23点59分60秒”,来将时间调慢一秒钟。看了上面的关于雪花算法的简短介绍,想必大家能猜出个一二了。
雪花算法和时间是强关联的,其中有 41 位是当前时间的时间戳,那么会不会和时间有关?
二、排查
2.1 雪花算法有什么问题?
既然是雪花算法的问题,那我们就来看下雪花算法出了什么问题:
(1)What:雪花算法生成了重复的 ID,这些 ID 是什么样的?
(2)Why:雪花算法为什么生成了重复的 key
第一个问题,我们可以通过报错信息发现,这个重复的 ID 是 -1,这个就很奇怪了。一般雪花算法生成的唯一 ID 如下所示,我分别用二进制和十进制来表示:
十进制表示:2097167233578045440
二进制表示:0001 1101 0001 1010 1010 0010 0111 1100 1101 1000 0000 0010 0001 0000 0000 0000找到项目中使用雪花算法的工具类,生成 ID 的时候有个判断逻辑:
当
当前时间小于上次的生成时间就会返回-1,所以问题就出在这个逻辑上面。(有的雪花算法是直接抛异常)
if (timestamp < this.lastTimestamp) {
return -1;
}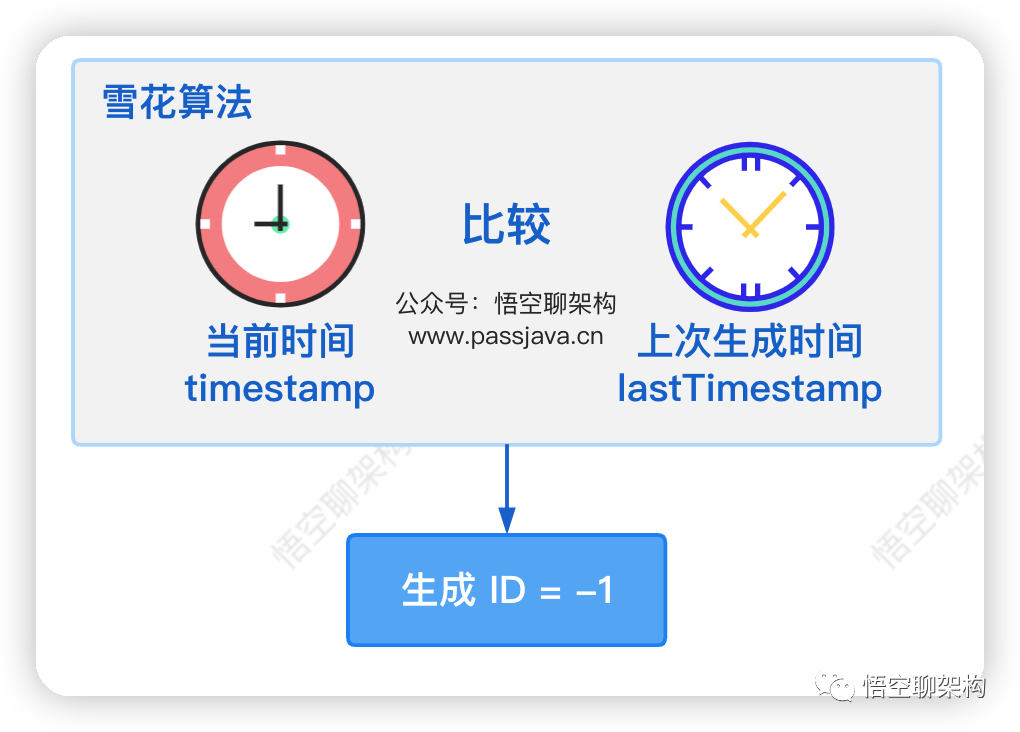
timestamp 都是小于lastTimeStamp,所以每次都返回了 -1,这也解释了为什么生成了重复的 key。
2.2 时钟回拨或跳跃
那么问题就聚焦在为什么当前时间还会小于上次的生成时间。
下面有种场景可能发生这种情况:
首先假定当前的北京时间是 9:00:00。另外上次生成 ID 的时候,服务器获取的时间 lastTimestamp=10:00:00,而现在服务器获取的当前时间 timestamp=09:00:00,这就相当于服务器之前是获取了一个未来时间,现在突然跳跃到当前时间。
而这种场景我们称之为时钟回拨或时钟跳跃。
时钟回拨:服务器时钟可能会因为各种原因发生不准,而网络中会提供 NTP 服务来做时间校准,因此在做校准的时候,服务器时钟就会发生时钟的跳跃或者回拨问题。
2.3 时钟同步
那么服务器为什么会发生时钟回拨或跳跃呢?
我们猜测是不是服务器上的时钟不同步后,又自动进行同步了,前后时间不一致。
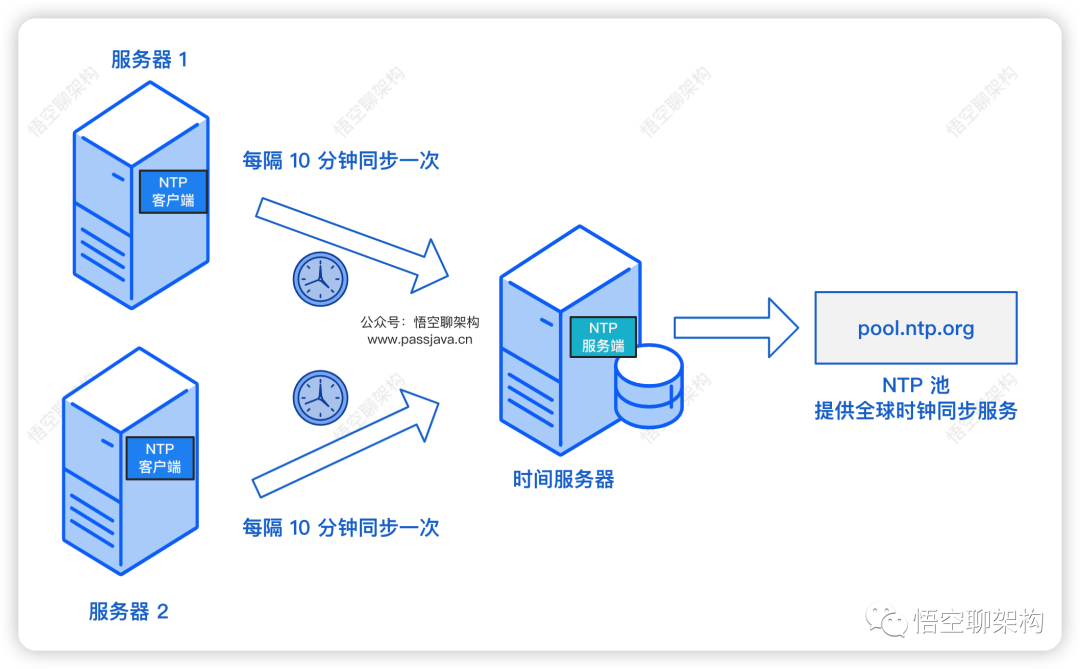
首先我们的每台服务器上都安装了 ntpdate 软件,作为 NTP 客户端,会每隔 10 分钟向 NTP 时间服务器同步一次时间。
如下图所示,服务器 1 和 服务器 2 部署了应用服务,每隔 10 分钟向时间服务器同步一次时间,来保证服务器 1 和服务器 2 的时间和时间服务器的时间一致。
*/10 * * * * /usr/sbin/ntpdate <ip>
另外时间服务器会向 NTP Pool同步时间,NTP Pool 正在为世界各地成百上千万的系统提供服务。它是绝大多数主流Linux发行版和许多网络设备的默认“时间服务器”。(参考ntppool.org)
那问题就是 NTP 同步出了问题??
2.4 时钟不同步
我们到服务器上查看了下时间,确实和时钟服务器不同步,早了几分钟。
当我们执行 NTP 同步的命令后,时钟又同步了,也就是说时间回拨了。同步的命令如下:
ntpdate <时钟服务器 IP>
在产生事故之前,我们重启过服务器 1。我们推测服务器重启后,服务器因网络问题没有正常同步。而在下一次定时同步操作到来之前的这个时间段,我们的后端服务已经出现了因 ID 重复导致的大量异常问题。
这个 NTP 时钟回拨的偶发现象并不常见,但时钟回拨确实会带了很多问题,比如润秒 问题也会带来 1s 时间的回拨。
为了预防这种情况的发生,网上也有一些开源解决方案。
三、解决方案
(1)方式一:使用美团 Leaf方案,基于雪花算法。
(2)方式二:使用百度 UidGenerator,基于雪花算法。
(3)方式三:用 Redis 生成自增的分布式 ID。弊端是 ID 容易被猜到,有安全风险。
3.1 美团的 Leaf 方案
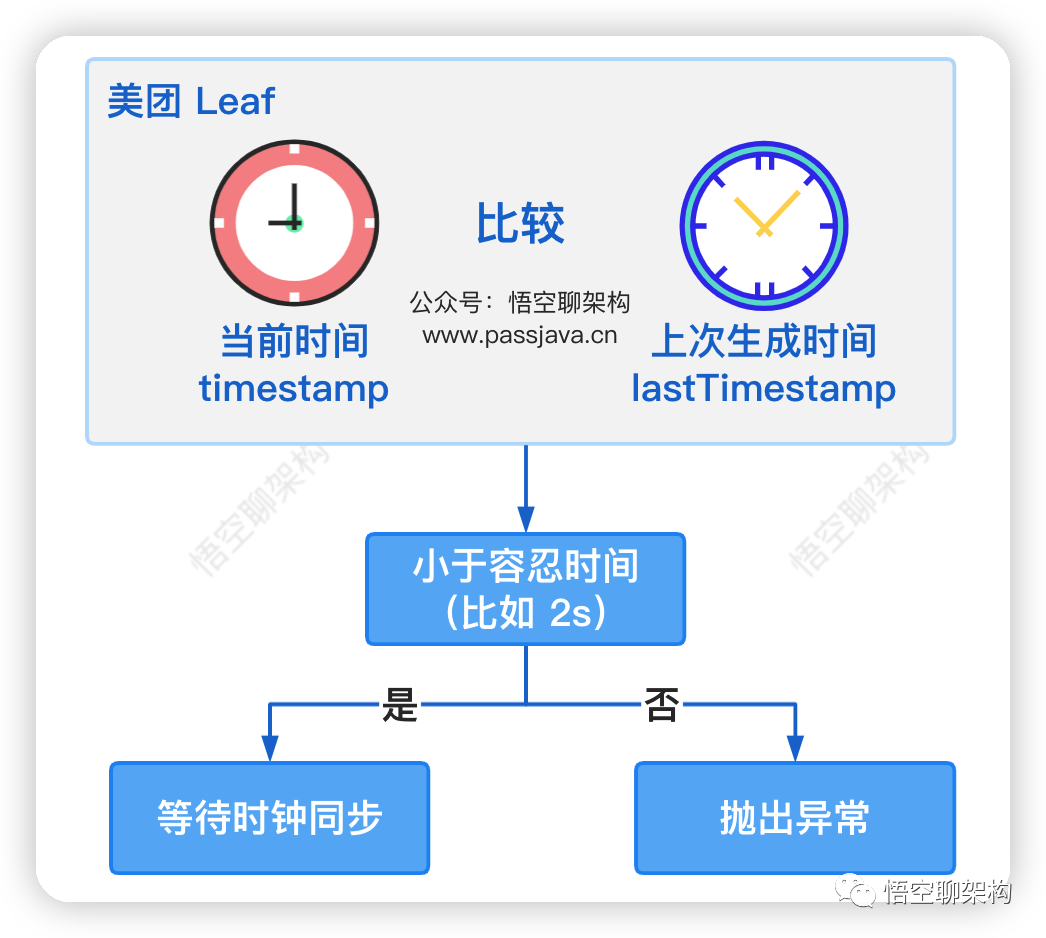
美团的开源项目 Leaf 的方案:采用依赖 ZooKeeper 的数据存储。如果时钟回拨的时间超过最大容忍的毫秒数阈值,则程序报错;如果在可容忍的范围内,Leaf 会等待时钟同步到最后一次主键生成的时间后再继续工作。
重点就是需要等待时钟同步!
3.2 百度 UidGenerator 方案
百度UidGenerator方案不在每次获取 ID 时都实时计算分布式 ID,而是利用 RingBuffer 数据结构,通过缓存的方式预生成一批唯一 ID 列表,然后通过 incrementAndGet() 方法获取下一次的时间,从而脱离了对服务器时间的依赖,也就不会有时钟回拨的问题。
重点就是预生成一批 ID!
Github地址:
https://github.com/baidu/uid-generator
四、总结
本篇通过一次偶发的生产事故,引出了雪花算法的原理、雪花算法的不足、对应的开源解决方案。
雪花算法因强依赖服务器的时钟,如果时钟产生了回拨,就会造成很多问题。
我们的系统虽然做了 NTP 时钟同步,但也不是 100% 可靠,而且润秒这种场景也是出现过很多次。鉴于此,美团和百度也有对应的解决方案。
最后,我们的生产环境也是第一次遇到因 NTP 导致的时钟回拨,而且系统中用到雪花算法的地方并不多,所以目前并没有采取以上的替换方案。
雪花算法的代码已经上传到 Gitlab:
https://github.com/Jackson0714/PassJava-Platform/blob/master/passjava-common/src/main/java/com/jackson0714/passjava/common/utils/SnowflakeUtilV2.java
参考资料:
https://time.geekbang.org/dailylesson/detail/100075739
https://blog.csdn.net/liangcsdn111/article/details/126103041
https://www.jianshu.com/p/291110ca60fc