图解Kafka消费组偏移量_consumer_offset的数据结构
-
1. 前言
-
2. 存储结构
-
2.1 GROUP_METADATA 消费组元信息
-
2.2 OFFSET_COMMIT 消费偏移量信息
-
3. 写入时机
-
3.1 Group元信息写入时机
-
3.2 Offset写入时机
1 . 前言
在之前的文章中, 我们有讲解过消息是如何从Producer存储到Broker中的, 也分析了消息的结构, 如果不清楚的话,可以看看 [图解Kafka的RecordBatch结构]
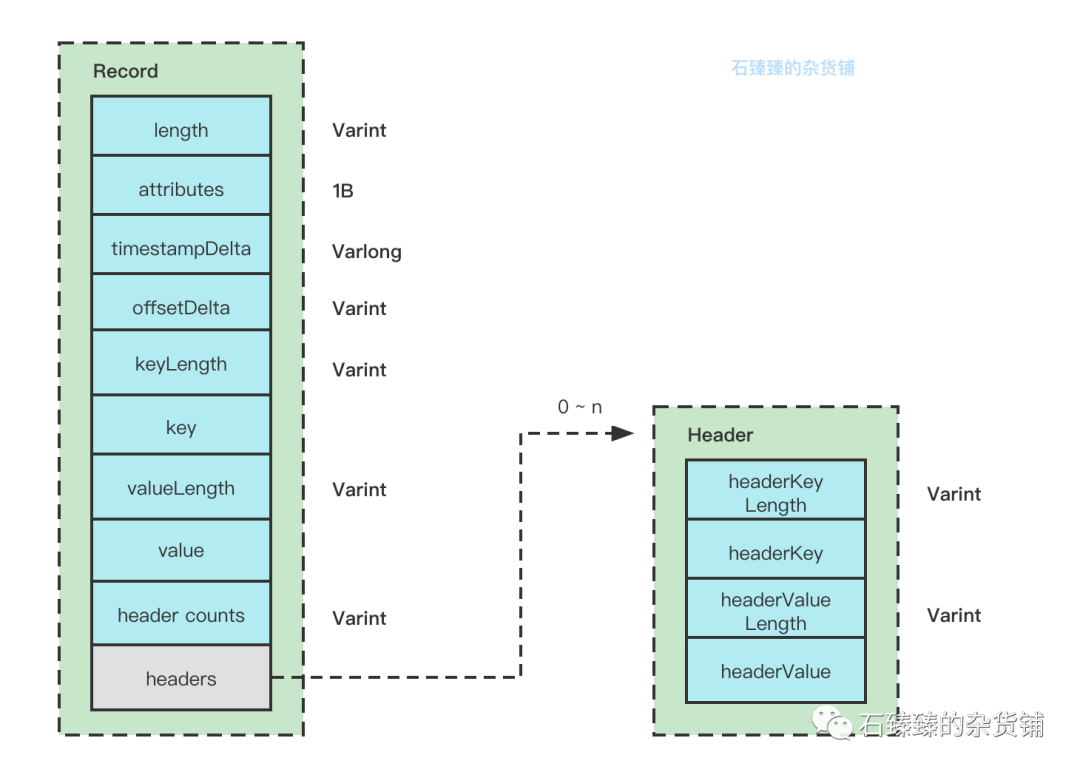
如果消费者重启了, 那么又是如何获知我上次消费到了哪个消息呢?
既然要解决上述的问题, 那么我们肯定要把我们已经消费的消息给记录下来, 不可能把整个Record给记录下来吧,那也太大了, 但是我们知道消息存储在具体的分区的时候都是有自己的Offset的, 并且是有序的offset, 所以我们只需要记录下当前消费到了哪个Offset就行了。
这个Offset保存在哪里呢?
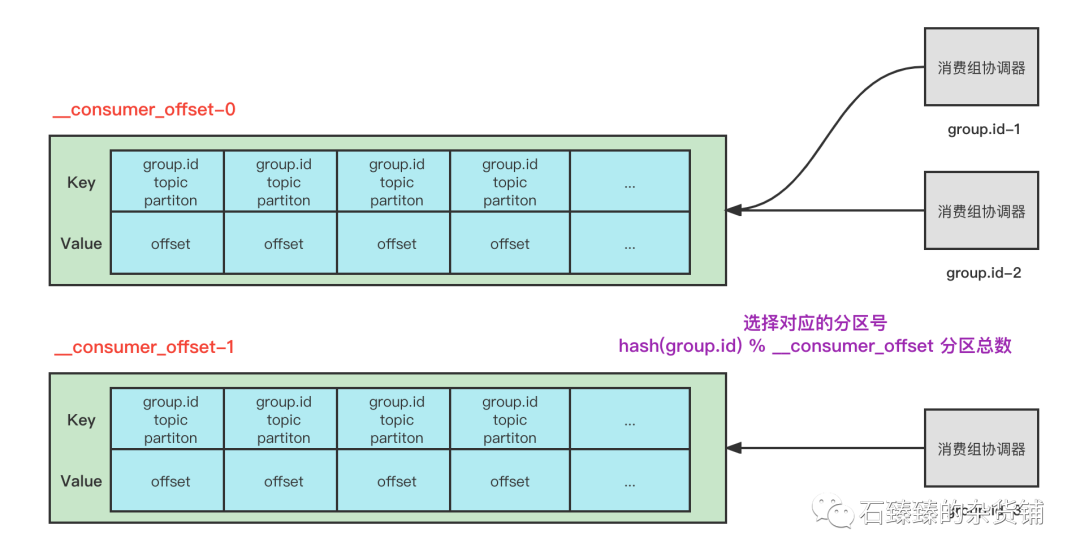
在 0.9 版本之前,这个信息是记录在zookeeper内的。但是因为频繁的对zookeeper进行读写,压力太大集群不稳 所以在0.9之后的版本,offset保存在__consumer_offsets 这个内部的Topic内了。
那么这个是怎么储存的呢?
因为本质上还是把消费的offset当做一条普通的消息发送到内部的Topic __consumer_offsets 中, 所以存储数据的时候, 也就是存到Record消息结构的 Key Value 中。
根据版本的迭代,存储的Key Value 的Schema也有一些略微不一样, 接下来我会把每个版本的Schema都讲解一下。
值得一提的是, 这个__consumer_offsets 保存的并不仅仅是offset的信息, 实际上它分为两种类型的数据
一种是 GROUP_METADATA
这种类型的数据, 存放的是消费组相关的元数据信息
一种是 OFFSET_COMMIT
这种类型的数据,存放的是就是上面说的Offset消费偏移量数据
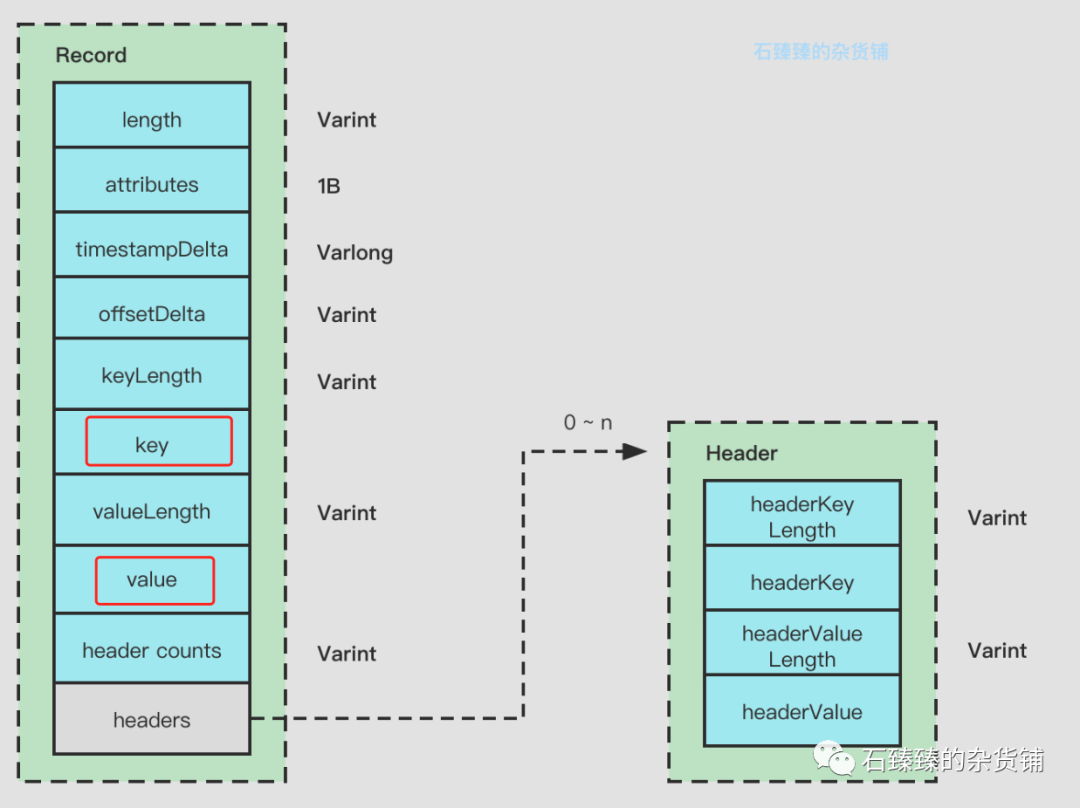
2 . 存储结构
我们下面要说的存储结构说的是Record数据结构里面的 Key Value
2.1 GROUP_METADATA 消费组元信息
GROUP_METADATA 存储的是消费组的元信息, 比如groupId 、protocol_type、protocol、leader、members 等等。
比如说有很多的消费组 , 每个消费组有很多消费者客户端member,每个member的 client.id、clien.host等等信息。
这个消息的Key Value数据如下
2.1.1 GROUP_METADATA_KEY
Key的结构
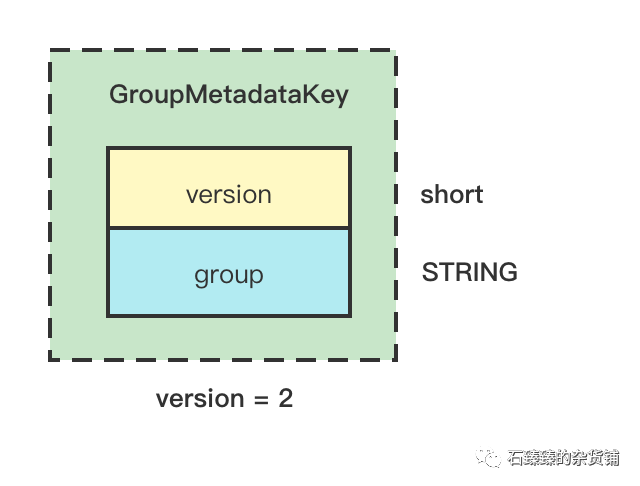
这里的GroupMetadataKey的最开始的2个字节存储的是version数据
- version=2 表示的是这个消息类型就是GROUP_METADATA类型
- version=0或1 表示的是OFFSET_COMMIT类型。
除了version,后面的数据才是Schema, 这个Schema只有一个字段就是 group。
注意: 在数据结构上 version 并不是属于Schema内的。
这里的key就是group.id
2.1.2 GROUP_METADATA_VALUE
GroupMetaDataValue 的数据结构变更的有点多, 有好几次升级, 版本信息存放在version里面,并且占用2个字节
特别注意的是: version跟其他的并不属于同一个Schema里面。
1 .Verion0 -- 基础版本,也是所有版本的共有属性
这个是最原始的版本,后续的版本都是在这个基础上做加法
Kafka版本:kafak version < 0.10.1Schema:
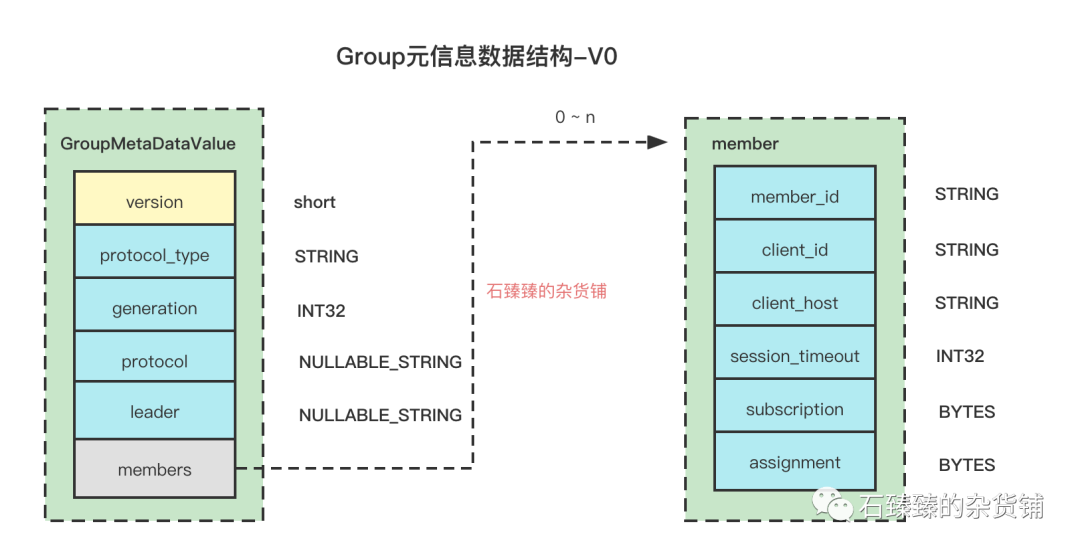
这里是每个结构的共有属性, 后面每个版本讲解的时候只会讲差异
| 属性 | 描述 |
|---|---|
| protocol_type | 协议类型,Consumer发起的协议是 comsumer , 另一个可选项为 connect |
| generation | 消费组协调器的年代标记,从0自增,每发生一次Rebalance就会增长一代 |
| protocol | 消费组分区分配策略, 比如range , 假如多个Member都配置很多策略, 那么会选择他们都支持的策略 |
| leader | 消费组协调器中总舵Member中的Leader Member, Leader Member有负责根据分区分配策略来计算新的分配方式并返回给组协调器的责任。这个值是Leader MemberId |
| members | 消费组下面的所有成员们的元信息,每个元信息的结构请看下面的表格 |
Member结构
| 属性 | 描述 |
|---|---|
| member_id | 每个成员的唯一标识 |
| client_id | 客户端的ID |
| client_host | 客户端host |
| session_timeout | 消费者向组协调器定期发送心跳证明自己的存活,如果在这个时间之内broker没收到,那broker就将此消费者从group中移除,进行一次reblance;默认10000(10 秒) |
| assignment | member对应的自己分配到的分区数据,具体请看下图SyncGroupRequest请求参数 |
| subscription | 这个是Member对应分配策略的订阅的元信息, 包含的数据有 1. 订阅的topics 2. userData自定义数据 3 ownedPartitions;这个userData,需要分区分配策略实现一个方法返回,;owned_partitons :这个记录着当前分配到的分区列表,平时是空列表。具体的结构请看下面JoinGroupRquest请求参数的红框起来的部分 |
SyncGroupRequest请求参数assignment属性的结构看下图虚线部分的assignment
private List<TopicPartition> partitions;
private ByteBuffer userData;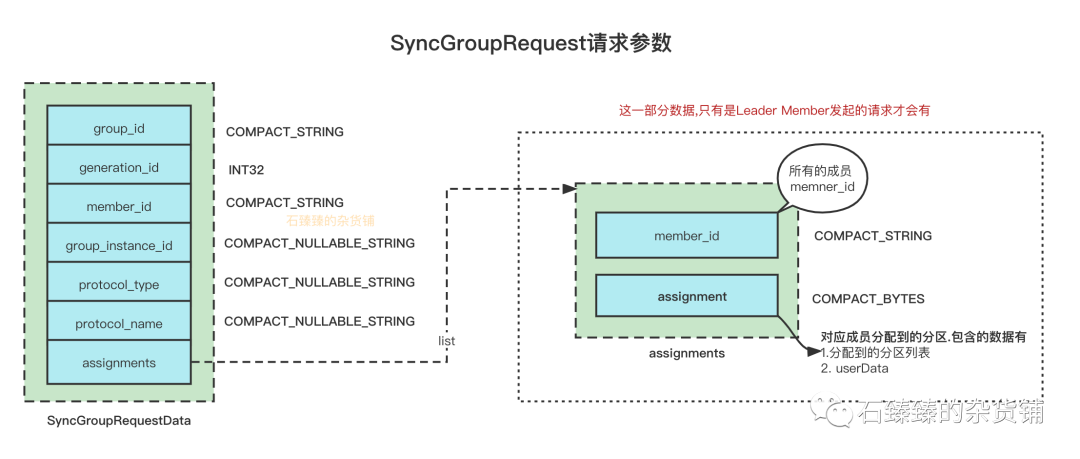
JoinGroupRquest请求参数
subscription属性的结构看下图红线框起来的部分 metadata
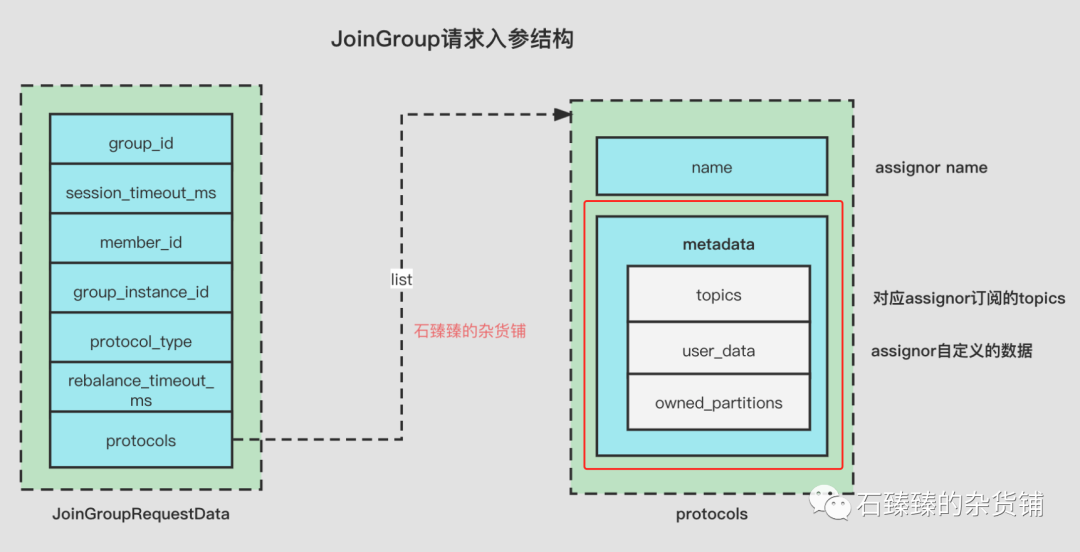
2 .Verion1
Kafka版本:0.10.1 < kafka version <2.1Schema:
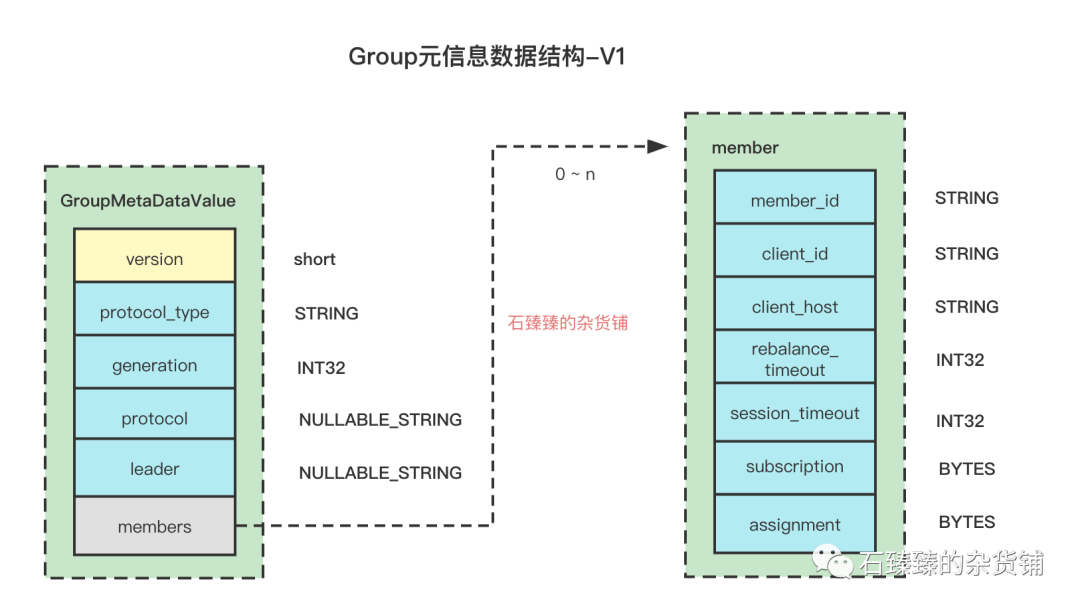
相比于version = 0 的版本,在member里面新增了一个字段rebalance_timeout
| 属性 | 描述 |
|---|---|
| rebalance_timeout | 重平衡的超时时间, 由配置max.poll.interval.ms控制,默认值300000(5 分钟),如果消费者两次poll的时间超过了此值,那就认为此消费者能力不足,将此消费者的commit标记为失败,并将此消费者从group移除,触发一次reblance,将该消费者消费的分区分配给其他人 |
2 .Verion2
Kafka版本:2.1 < kafka version <2.3Schema:
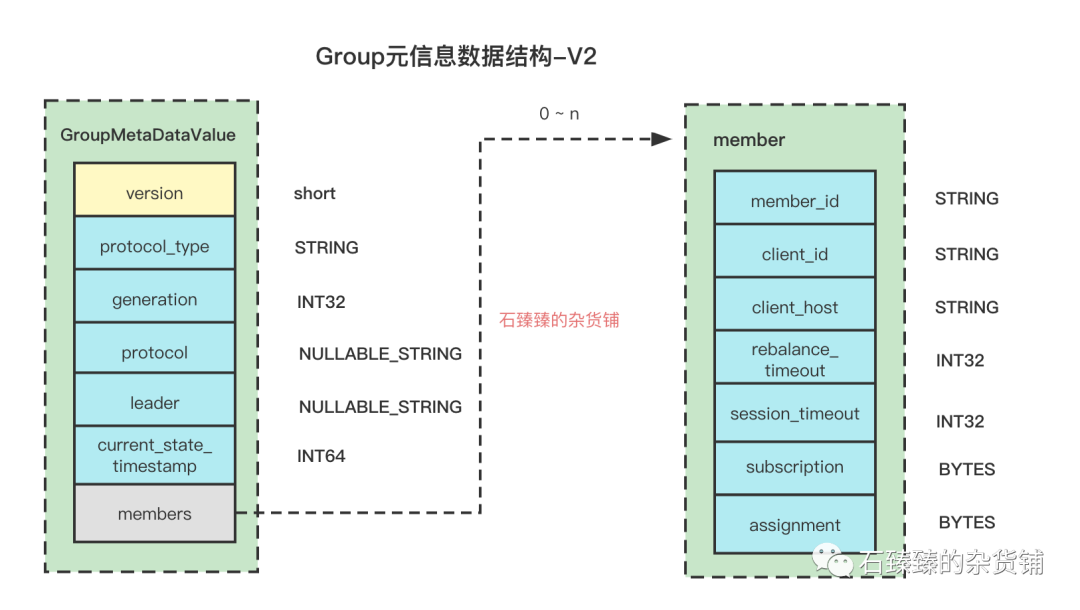
跟V1的版本区别是 新增了一个字段 current_state_timestamp
| 属性 | 描述 |
|---|---|
| current_state_timestamp | 当前Group状态流转的时间,从上一个状态流转到下一个状态的这个时间点。 |
2 .Verion3
Kafka版本:2.3 < kafka version Schema:
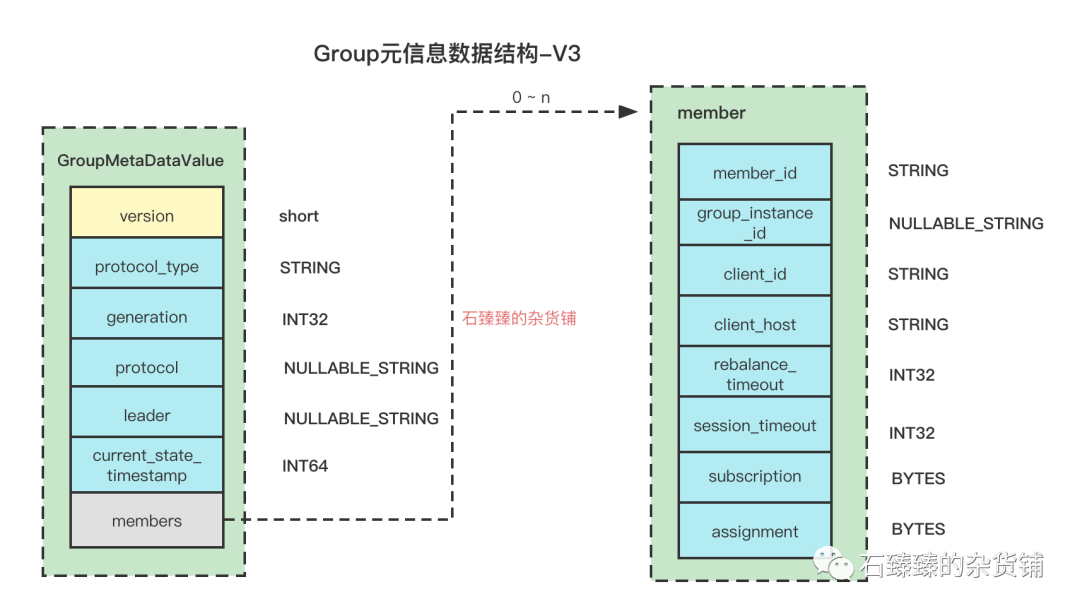
跟V2的版本区别是 member里面新增了一个字段 group_instance_id
| 属性 | 描述 |
|---|---|
| group_instance_id | 静态成员的实例ID,关于静态成员和动态成员请看 |
2.2 OFFSET_COMMIT 消费偏移量信息
这种类型的数据就是跟存储的每个消费组每个分区消费的offset的数据。
2.2.1 OFFSET_COMMIT_KEY
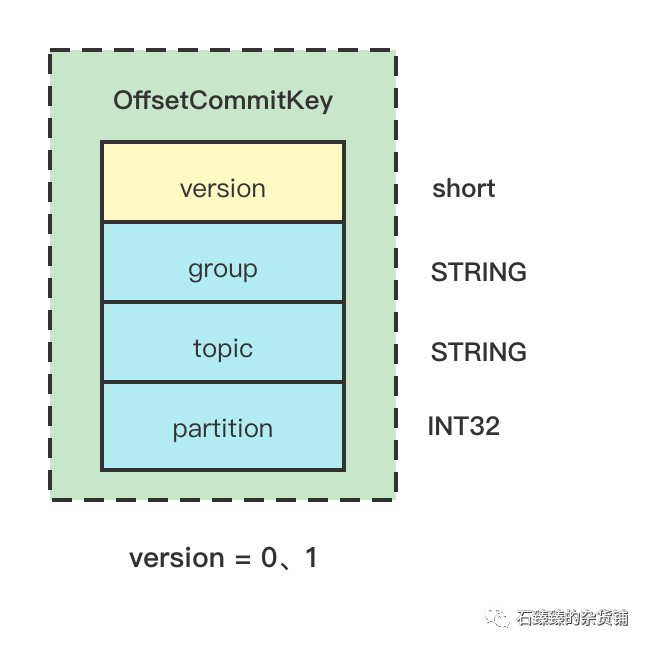
version=0或1 表示的是OFFSET_COMMIT类型。
version=2 表示的是上面提过的GROUP_METADATA类型
| 熟悉 | 描述 |
|---|---|
| group | 消费组ID, group.id |
| topic | 订阅的主题 |
| partition | 订阅的分区 |
因为可能会有很多个不同的消费组消费同一个分区, 并且他们直接是相互独立的, 所以为了区别他们,在存储消费组offset的时候, key的值实际上是 由group.id+topic+partition 组成的。
并且一个分区在同一个消费组内只会被其中一个消费者消费, 这样就不会出现多个消费者重复消费的问题了。
2.2.2 OFFSET_COMMIT_VALUE
Value是存储的消费组的消费偏移量Offset,这个Offset是针对每个group.id+topic+partition 维度的。
除了Offset信息,还存了其他的一些信息, 请看下图Value结构的变更历史
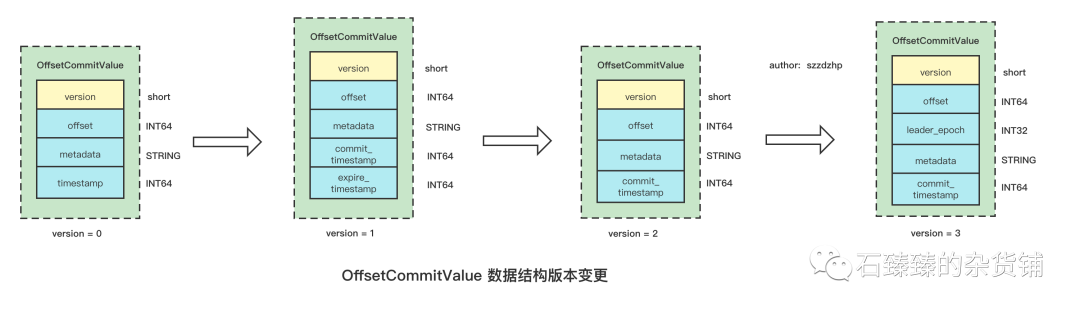
我们主要看Version=3的一个版本
| 属性 | 描述 |
|---|---|
| offset | 消费偏移量 |
| leader_epoch | Leader纪元,如果当前leader不存在为-1 |
| metadata | |
| commit_timestamp | 偏移量提交时间 |
3 . 写入时机
3.1 Group元信息写入时机
元信息的写入源码入口在
GroupMetadataManager#storeGroup
/**
* 公众号:石臻臻的杂货铺
* Vx: shiyanzu001
* 领取20万字《Kafka运维实战宝典》
**/
def storeGroup(group: GroupMetadata,
groupAssignment: Map[String, Array[Byte]],
responseCallback: Errors => Unit): Unit = {
//读取分区数据,获取消息的结构版本
getMagic(partitionFor(group.groupId)) match {
case Some(magicValue) =>
// We always use CREATE_TIME, like the producer. The conversion to LOG_APPEND_TIME (if necessary) happens automatically.
val timestampType = TimestampType.CREATE_TIME
val timestamp = time.milliseconds()
// 获取Group元信息的Key结构
val key = GroupMetadataManager.groupMetadataKey(group.groupId)
// 获取Group元信息的Value结构
val value = GroupMetadataManager.groupMetadataValue(group, groupAssignment, interBrokerProtocolVersion)
//构造消息体
val records = {
val buffer = ByteBuffer.allocate(AbstractRecords.estimateSizeInBytes(magicValue, compressionType,
Seq(new SimpleRecord(timestamp, key, value)).asJava))
val builder = MemoryRecords.builder(buffer, magicValue, compressionType, timestampType, 0L)
builder.append(timestamp, key, value)
builder.build()
}
//构造TopicPartition,消息将会发往这个分区
val groupMetadataPartition = new TopicPartition(Topic.GROUP_METADATA_TOPIC_NAME, partitionFor(group.groupId))
val groupMetadataRecords = Map(groupMetadataPartition -> records)
val generationId = group.generationId
//当日志写入成功之和调用这个回调函数,并将 创建的group插入缓存
def putCacheCallback(responseStatus: Map[TopicPartition, PartitionResponse]): Unit = {
// 省略很多代码..
}
responseCallback(responseError)
}
//将数据写入到Log中
appendForGroup(group, groupMetadataRecords, putCacheCallback)
case None =>
responseCallback(Errors.NOT_COORDINATOR)
None
}
}这段代码很简单, 就是构造一下GroupMetadata的消息体并写入__consumer_offset对应的分区中。我们主要还是要来了解一下在什么情况下才会写入
我们看调用链,发现有三个地方调用了它
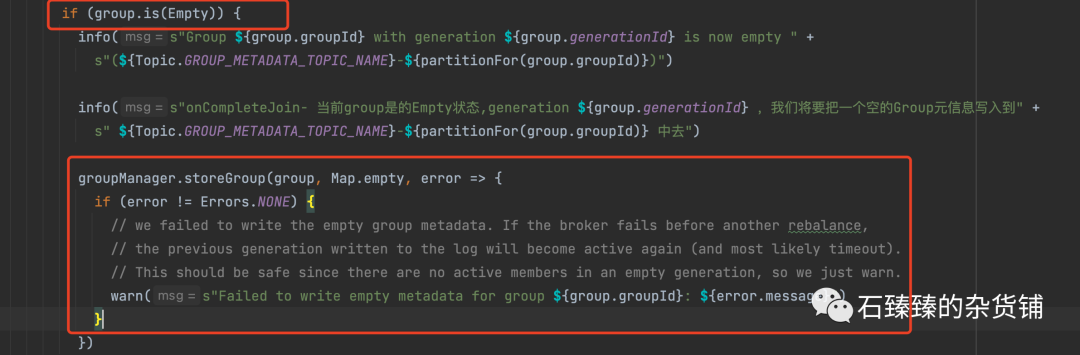
3.1.1 onCompleteJoin 当所有的Member都成功Join之后调用
这个的执行条件是: 当Group当前是Empty的状态,一个Member也没有,那么这个时候写入一个Group元信。
GroupCoordinator#onCompleteJoin
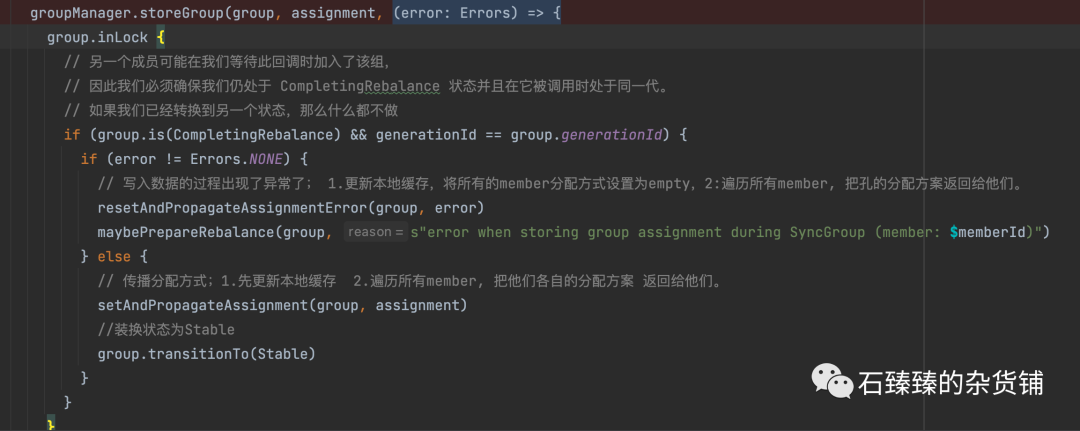
3.1.2 doSyncGroup 当Leader Member接收到SyncGroup请求
一般SyncGroup请求都是在JoinGroup完成了之后,所有的Member都会向组协调器发送SyncGroup。
但是Leader Member会带上计算好的新的分区分配方案给协调器
所以协调器当发现是Leader Member给自己发送SyncGroup请求之后,他会把相应的元数据给写入到_consumer_offset中。(因为Group的元信息有变更了)
GroupCoordinator#doSyncGroup
上面的一个入参assignments列表, 是SyncGroup请求带进来的,具体的结构请看下图右边虚线框;
上图虚线内的单个assignment的数据结构是
private List<TopicPartition> partitions;
private ByteBuffer userData;想了解 SyncGroupRequest请看:KafkaConsumer SyncGroupRequest详解
3.1.3 updateStaticMemberAndRebalance 更新静态成员
在静态成员JoinGroup的时候, 会走单独的静态成员更新流程
GroupCoordinator#updateStaticMemberAndRebalance
判断group的下一代的selectedProtocol(所有memmber都支持并排序最靠前)是否会改变
- 如果有变化,应该触发rebalance,让group的assignment和selectProtocol一致
- 如果没有,则简单地存储group来持久化更新的静态成员
就是这里的2的情况,去更新一下静态成员的相关信息,主要就是更新 memberId,其他的都没有什么好变更的。分配方案也不会有改变。
GROUP_METADATA_VALUE_SCHEMA版本选择
GroupMetadataManager#groupMetadataValue
def groupMetadataValue(groupMetadata: GroupMetadata,
assignment: Map[String, Array[Byte]],
apiVersion: ApiVersion): Array[Byte] = {
val (version, value) = {
if (apiVersion < KAFKA_0_10_1_IV0)
(0.toShort, new Struct(GROUP_METADATA_VALUE_SCHEMA_V0))
else if (apiVersion < KAFKA_2_1_IV0)
(1.toShort, new Struct(GROUP_METADATA_VALUE_SCHEMA_V1))
else if (apiVersion < KAFKA_2_3_IV0)
(2.toShort, new Struct(GROUP_METADATA_VALUE_SCHEMA_V2))
else
(3.toShort, new Struct(GROUP_METADATA_VALUE_SCHEMA_V3))
}
// 省略。。。
3.2 Offset写入时机
handleJoinGroupRequest
(略)