S 公司的微服务“失败”之旅
背景介绍
S公司是一家数据服务公司,有 20 000 多名客户使用公司的软件,公司使用 API 收集和清理客户的数据。S 公司提供的产品如下图所示。


微服务是当今主流的架构模式之一。S 公司的系统进行了一次微服务改造,并取得了不错的效果。
(1)重构后的规模:400 private repos;70 different services(workers)。
(2)取得的收益:
- visibility(可见性)。在微服务架构中,非常方便对每个服务进行监控(sysdig、htop、iftop 等)。
- 微服务大大降低了配置和构建部署成本。
- 消除了在现有服务中附加不同功能的诱惑。
- 产生了很多对外依赖很少的服务:仅仅需要从队列里读取和处理数据,然后发送结果即可。
- 非常适合小团队协同工作。
(3)定位问题变得容易。可以对每一个 microworker 进行 Datadog 式的监控,如下图所示
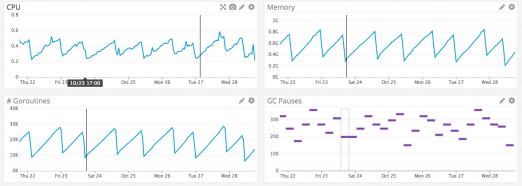
比如,类似于内存泄漏的问题,可以很容易将问题范围缩小到 50~100 行代码内。
简单地讲,微服务是一种面向服务的软件体系结构,其中服务端的应用程序是通过组合许多单一用途、低占用空间的网络服务而成的。其优点是改进的模块化减少了测试负担,可以更好地进行功能组合,环境隔离和开发团队具备自主权。经常与之拿来对比的是单体架构,在单体架构中,大量的功能存在于单个服务中,作为单个单元进行测试、部署和扩展。
另外,操作复杂度和负载都很高的产品一般都会选择微服务架构,它使基础结构更加灵活、可扩展性强,并且更易于监控。
但不幸的事情发生了,当重构完成两年以后,团队没有更快地交付,而是陷入了“爆炸性”的复杂性中,架构的优点变成了负担。随着速度的下降,失败率激增,团队也变得不堪重负。
系统处理流程概述
S公司的客户数据基础设施每秒可接收数十万个事件,并将它们转发给合作伙伴的 API,即服务端 destination。目前,有超过一百种类型的 destination,如 Google Analytics, Optimizely,或自定义 Webhook。
几年前,架构相对简单,一个API 即可接收事件并将其转发到分布式消息队列。事件是由 Web 或移动应用程序生成的 JSON 对象,其中包含有关用户及其操作的信息。
一旦请求失败,有时会尝试在稍后的时间再次发送该事件。有些失败可以安全重试,有些则不行。可重试错误是指那些 destination 不做任何更改就可以接受的错误,如 HTTP 500、速率限制和超时。不可重试错误是指可以确信 destination 永远不会接受的请求,如具有无效凭证或缺少必需字段的请求。
此时,单个队列既包含最新的事件,也包含跨越所有destination 的可能有多次重试的事件,这会导致“队头阻塞”。也就是说,在这种特殊情况下,如果一个 destination 变慢或下降,则重试将会导致队列拥挤,从而导致所有 destination 的延迟。
假设destinationX 遇到了一个临时问题,每个请求都由于超时而出错。现在,这不仅会创建大量尚未到达 destinationX 的积压请求,而且还会将每个失败事件放回队列中进行重试,如下图所示。虽然系统将自动伸缩以响应增加的负载,但队列深度的突然增加将超过系统的伸缩能力,从而导致最新事件的延迟。
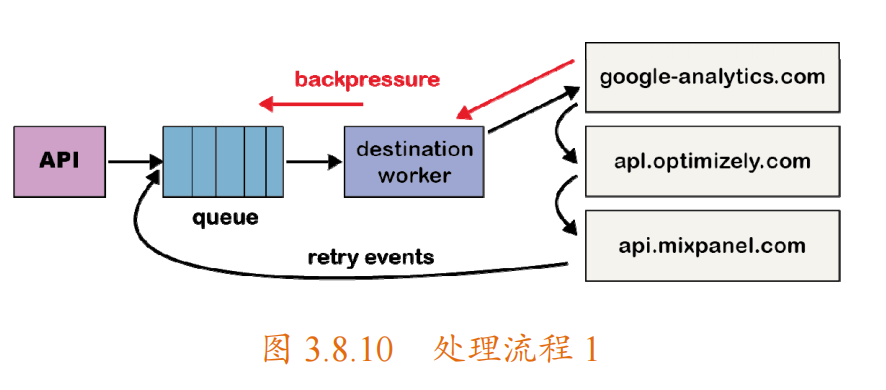
为了解决“队头阻塞”问题,该团队为每个 destination 都创建了单独的服务和队列。这个新的体系结构包括一个额外的路由器进程,该进程接收入站事件并将事件的副本分发到每个选定的 destination 中,如下图所示。现在,如果一个 destination 出现问题,则只有它的队列会阻塞,其他 destination 不会受到影响。这种微服务风格的体系结构将 destination 彼此隔离,这在 destination 经常发生问题时,至关重要。
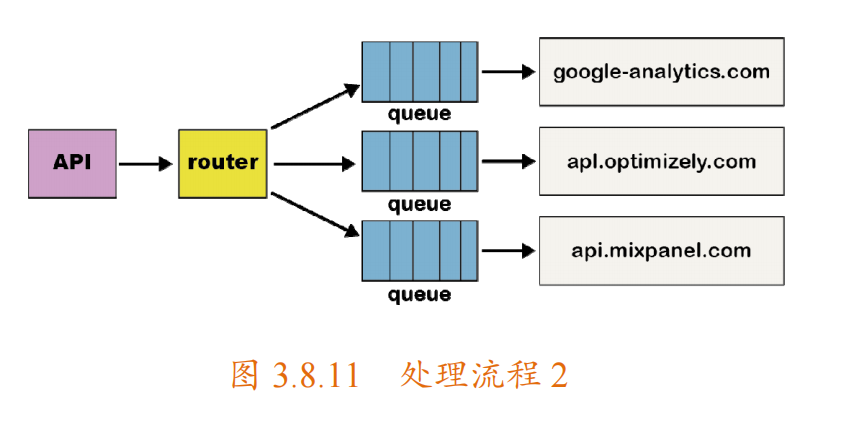
产生的问题
(1)共享库多版本问题。随后,系统又增加了 50 多个新的 destination,这就意味着有 50个新的 repo。为了减轻开发和维护这些代码库的负担,团队创建了共享库,来处理公共转换和功能(如 HTTP 请求处理)。然而,一个新的问题出现了。对这些共享库的测试和部署更改会影响所有的 destination,此时必须测试和部署几十个服务。在时间紧迫的情况下,工程师只会在单个目标的代码库中包含这些库的更新版本。这样一来,随着时间的推移,这些共享库的版本开始在不同的目标代码库中出现不同的分支版本,原本拥有的在每个目标代码库之间减少自定义的优势开始不复存在。最终,它们都使用了这些共享库的不同版本。本可以构建一些工具来自动进行更改,但此时,不仅开发人员的工作效率受到了影响,还遇到微服务架构的其他问题。
(2)负载模式问题。 每个服务都有不同的负载模式,其中一些服务每天处理少量事件,而另一些服务每秒处理数千个事件。对于处理少量事件的 destination,当出现意外的负载峰值时,操作员将不得不手动扩展服务,以满足需求。
(3)伸缩调优问题。 虽然确实实现了自动伸缩,但每个服务都有不同的 CPU 和内存资源组合,使得自动伸缩配置的调优更像是艺术而不是科学。destination 的数量继续快速增加,团队平均每个月增加三个 destination,这意味着有了更多的 repo、队列和服务。
(4)管理开销。当服务个数超过 140 个时,对团队来说管理所有服务是一笔巨大的开销。团队每天睡不好觉,最常见的场景就是线上工程师处理负载峰值。
退回到单体
最终,团队决定抛弃这些微服务和repo,并重新将服务并到一起。然而,退回到单体服务非常困难。如果所有 destination 都有一个单独的队列,那么所有工程师都必须检查每个队列的工作,这会给 destination 服务增加一层复杂性。为了解决这个问题,系统新增了一种“离心机(Centrifuge)”组件,并将所有 destination 进行了合并,如下图所示。



同时,还需要将所有repo 进行合并。一旦所有 destination 的代码存在于一个 repo 中,它们就可以合并为一个服务。这样,开发人员的生产率大大提高了,不再需要部署 140 多个服务来改变一个共享库,一个工程师在几分钟内就可以部署这项服务,这一变化也有利于运维。由于所有 destination 都位于一个服务中,因此很好地混合了 CPU 和内存密集型 destination,这使得利用扩展服务来满足需求变得非常容易。由于大型工作池可以吸收负载峰值,因此团队不必再为处理少量负载的 destination 进行分页。
一些牺牲
虽然已取得了巨大的改进,然而其中也有些“牺牲”。
(1)故障隔离困难。由于所有东西都在一个单体中运行,如果一个 destination 中引入了导致服务崩溃的 bug,那么所有 destination 的服务都会崩溃。虽然已经有全面的自动化测试,但是测试无法完全保障。后续演进的方向是设计一种更健壮的方法,以防止单个 destination导致整个服务瘫痪,同时仍将所有 destination 保持在一个单体中。
(2)缓存(内存中)效率变低。以前,由于每个 destination 都有一个服务,低流量 destination只有少数进程,这意味着它们控制平面数据的内存缓存将保持热度。现在,由于缓存分散在3000 多个进程中,因此命中率大大降低。最后,考虑到实际的运营收益,接受了效率的损失。
(3)更新一个依赖项的版本可能会破坏多个destination。虽然解决了之前多版本依赖的问题,但如果想使用库的最新版本,则必须更新其他 destination。目前,通过全面的自动化测试套件,可以快速看到新老依赖版本的不同。
总结
引入微服务架构,并通过将destination 彼此隔离解决了管道中的性能问题。然而,当需要批量更新时,由于缺乏适当的工具来测试和部署微服务,因此结果反而使开发人员的生产力迅速下降。
在进行架构选择时,并不存在绝对的好坏,是一个权衡的过程,需要从多个维度考虑。
- 新的架构是否能带来新的复杂性,带来的复杂性是否能被充分评估,以及如何应对,如上文提到的“共享多版本的问题”。
- 新架构下系统的运维成本是否增加,如果增加能否接受,如上文提到的“负载模式问题”。
- 在“享受”新架构带来的好处的同时,能否真正掌控新架构,如上文提到的“伸缩调优问题”。
- 新的架构是否带来管理开销,成本能否接受,如上文提到的“管理开销”问题。
架构设计的误区
(1) 盲目追求模式和原则的满足。并不是说模式和原则不重要,但它们不应该成为架构设计追求的唯一目标。盲目追求不必要的模式和原则的满足,往往会给系统带来不必要的复杂性,使其难以理解。
(2)追赶潮流。新的架构形态层出不穷,令人眼花缭乱,学习到一种新的、“炫酷”的架构设计很容易有直接拿来应用的冲动。这样做的后果往往是会与实际解决的问题脱节,为系统带来不必要的负担,甚至根本没有解决任何问题。
(3)面面俱到,没有重点。决定不要什么比要什么更难。你会看到当某些架构设计文档的模板时,高可用性、扩展性、可测试性……什么都想要,不做取舍。不同系统的侧重点不同,这样做的后果往往是顾此失彼,关键问题没有得到解决。
(4)忽视架构腐化。架构设计在整个软件生命周期内,都需要守护及持续演进,否则架构及整个系统都难以摆脱逐步恶化,直至消亡或重写的命运。