国际化翻译平台文档解析 2.0 技术原理解析
字节跳动国际化翻译平台为业务提供高效专业的【平台+服务】本地化一站式解决方案,简化本地化管理流程,提高多语言内容管理效率,助力产品出海。除文案管理外,国际化翻译平台 也提供文案、文档、视频等多模态翻译服务。目前不仅为公司内部大部分业务线提供服务,还通过火山引擎为外部客户提供服务,详见 https://www.volcengine.com/product/i18ntranslate。
一、背景
随着业务快速发展,国际化翻译平台文档翻译从最初仅支持 word 文档,到目前支持 8 种文档类型,其中核心 Node.js SDK(以下称为“文档解析 1.0”)变得越来越难以维护,究其根本,文档解析 1.0 对于每种文档类型的解析、还原、机器翻译、字数计算等能力,都单独维护一套逻辑,其优势是在文档解析开发的 0-1 阶段可以快速完成每种格式的能力建设,但随着后期优化需求以及新文档格式的增加,这种独立式架构的弊端会愈发凸显——改动某个逻辑需要同时修改 N 套代码、新接入一种文档格式需要重新编写几乎完全重复的业务逻辑。为了更好的支持文档翻译业务的高效维护与未来更多文档格式扩展的需求,有必要对现有架构进行一次彻底的重构升级。
二、重构收益
- SDK 核心逻辑代码量减少 70%+(6000+ 行 -> 2000 行)
- 受益于新架构的高可维护性与可扩展性:
a. lark 文档 2.0 还原效率提升 10 倍以上 b. 使用 SDK 的 Node BFF 项目文档解析相关逻辑代码量降低 80%+ c. 实现了基于 TS Decorator 与 FaaS 的 SDK 数据可视化
我们可以看到重构收益还是比较明显的,那么文档解析 2.0 的新架构具体是怎么样,以及是如何实现的呢?接下来的技术原理部分会进行详细解析。
三、技术原理
3.1 架构设计
让我们回到文档解析与还原的本质,解析的本质是将文档对应格式的文件转化为一套目标 DSL,而还原的本质则是将目标 DSL 转化为文件 DSL 然后生成文件。也就是说,所有类型文档的解析与还原流程都可以抽象为如下过程:
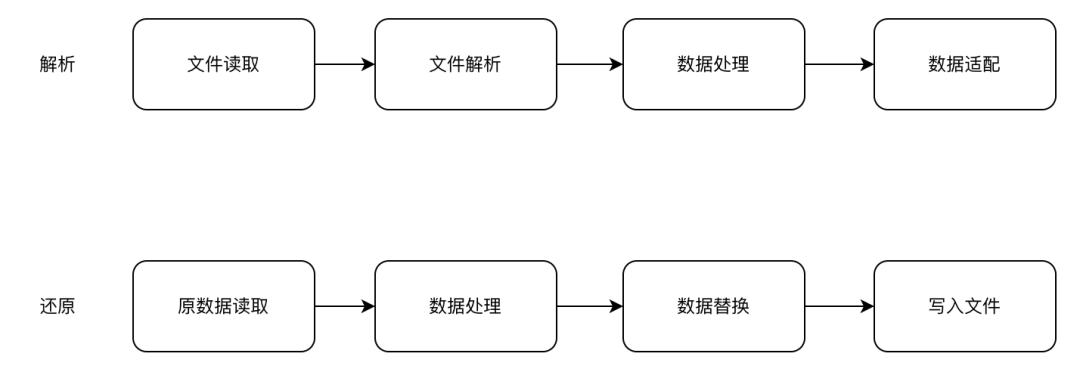

如此一来,国际化翻译平台文档解析 2.0 的三层架构便呼之欲出:
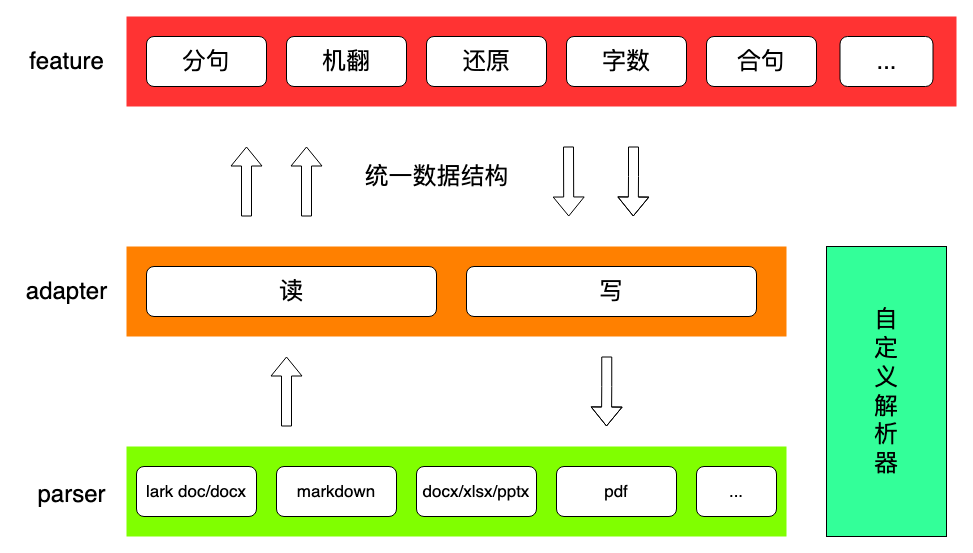
3.2 分层实现
解析完总体架构之后,我们可以继续往下深入,看看各层的具体实现。
其中 Parser 层设计如下:
class SomeTypeParser {
constructor(config) {}
@type2bridge
parse() {}
@bridge2type
restore() {}
}细心的读者可能发现了 parser 的实现借助了 ts decorator,这部分会在 3.3 SDK 数据可视化部分详解。这里可以先略过这部分。
Feature
这里需要前置说明一下 CAT 的含义,CAT 的意思是计算机辅助翻译(Computer aided translation,CAT),也是国际化翻译平台文档解析的目标,国际化翻译平台经过文档解析生成 segments,翻译人员在由 segments 所构成的 CAT 编辑器中进行翻译操作。
国际化翻译平台 CAT 编辑器目前如下图所示:
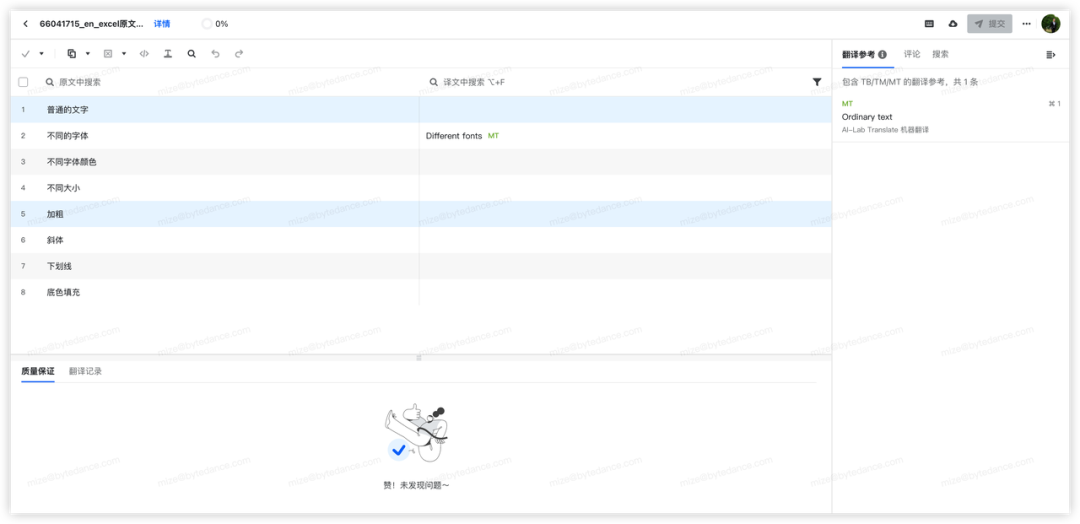
Feature 层设计如下:
class CAT {
// 文档解析,返回结果就是segments
adaptCAT(type, config) {}
// 机器翻译
adaptCATWithMT() {}
// 字数统计
countWords() {}
// 生成文档
genDoc() {}
// 自定义解析器
apply(type, parser) {}
}Adapter
Adapter 层主要是以下两个方法,分别是文档数据转中间层数据,与中间层数据转文档数据。
export const type2bridge = () => {
}
export const bridge2type = () => {
}统一 DSL
{
blockId: string
elements: {
type: string // 文本:text, 其他:other,对应着单、双标签
textRun?: {
style: Object // 样式
content: string // 文本
}
location: {
start: number
end: number
}
}[]
}以上便是国际化翻译平台文档解析 2.0 架构的设计过程与分层实现。接下来对 SDK 中 decorator 的使用做更详细的解析,有了它的帮助,SDK 底层的解析、还原与数据可视化的具体实现变得更加简洁。
3.3 Decorator 的使用与 SDK 数据可视化
Decorator 可以用来增强类中的方法,使其具备额外的功能,提供增强后的接口。
以国际化翻译平台 TXT 文档 parser 层的具体实现为例,
export default class TxtParser {
@txt2bridge
async parse(token: string | Buffer) {
const buffer = path2buffer(token)
return [buffer.toString()]
}
@bridge2txt
async restore(blocks: string[], _raw: string) {
return { buffer: Buffer.from(blocks.join()) }
}
}我们可以看到两个装饰器方法txt2bridge与bridge2txt,实现如下:
export const txt2bridge = proxyForReturnValue<string[], TxtParser>(function (blocks) {
const bridgeBlocks = blocks.map((block, index) => {
const bridgeBlock: Bridge.Block = {
style: {},
blockId: index + '',
elements: [
{
type: 'text',
textRun: {
content: block,
style: {}
},
location: {
start: 0,
end: block.length
}
}
]
}
return bridgeBlock
})
return { raw: JSON.stringify(blocks), blocks: bridgeBlocks }
})
export const bridge2txt = proxyForParam<string[], TxtParser>(function (blocks, _raw) {
return blocks.map(block => {
return block.elements.map(ele => ele.textRun.content).join()
})
})我们可以观察到这两个装饰器并不是直接实现的,是经过proxyForParam与proxyForReturnValue而间接实现,这里又涉及到了 proxy 设计模式的使用,用来对返回值与函数参数做一次转化。这两个代理方法的具体实现如下:
Proxy 被用于做访问控制(access control),对本身想要访问的对象做转化,并且对外提供相同的接口。
export function proxyForReturnValue<T, THIS, C = { [key: string]: any }>(
proxy: (this: THIS, data: T, config?: C) => Bridge.Data | Promise<Bridge.Data>
) {
return function (
_target: any,
_propertyName: string,
descriptor: TypedPropertyDescriptor<Function>
) {
const method = descriptor.value
descriptor.value = async function (token: string, config?: C) {
const data = await method.call(this, token, config)
return await proxy.call(this, data, config)
}
}
}
export function proxyForParam<T, THIS, C = { [key: string]: any }>(
proxy: (this: THIS, blocks: Bridge.Block[], raw: string | Buffer, config?: C) => T | Promise<T>
) {
return function (
_target: any,
_propertyName: string,
descriptor: TypedPropertyDescriptor<Function>
) {
const method = descriptor.value
descriptor.value = async function (blocks: Bridge.Block[], raw: string | Buffer, config?: C) {
return await method.call(this, await proxy.call(this, blocks, raw, config), raw, config)
}
}
}通过上述实现,我们可以看到 Decorator 真正起作用的语句(descriptor.value = () => {})在这两个 proxy 方法内实现。通过 proxy 设计模式的使用,我们可以将 Decorator 的实现与业务逻辑进行解耦,更加便于后续维护。
通过 Decorator,我们可以对方法做增强处理,使之具备更多的能力,因此,解析与还原过程中的数据收集也可以通过 Decorator 来实现。在 TxtParser 中,我们只需要增加一个trace装饰器即可:
export default class TxtParser {
@trace('txt', 'parse')
@txt2bridge
async parse(token: string | Buffer) {
const buffer = path2buffer(token)
return [buffer.toString()]
}
@trace('txt', 'restore')
@bridge2txt
async restore(blocks: string[], _raw: string) {
return { buffer: Buffer.from(blocks.join()) }
}
}trace装饰器实现如下:
export function trace ( docType: DocType, operateType: 'parse' | 'restore') {
return function (
_target: any,
_propertyName: string,
descriptor: TypedPropertyDescriptor<Function>
) {
// prepare
const method = descriptor.value
descriptor.value = async function (...args) {
try {
// ...
const res = await method.apply ( this, args)
// 信息收集,例如操作时间、CPU、内存等消耗情况
// 通过FaaS上报文档操作过程中的统计信息
return res
} catch (error) {
// 错误处理,通过FaaS上报错误信息
}
}
}
}我们在装饰器中进行信息收集,并把收集到的数据上报到 FaaS 平台之后,我们就可以开发一个运营后台来将这些数据进行可视化展现,这也是国际化翻译平台的文档分析后台的由来。
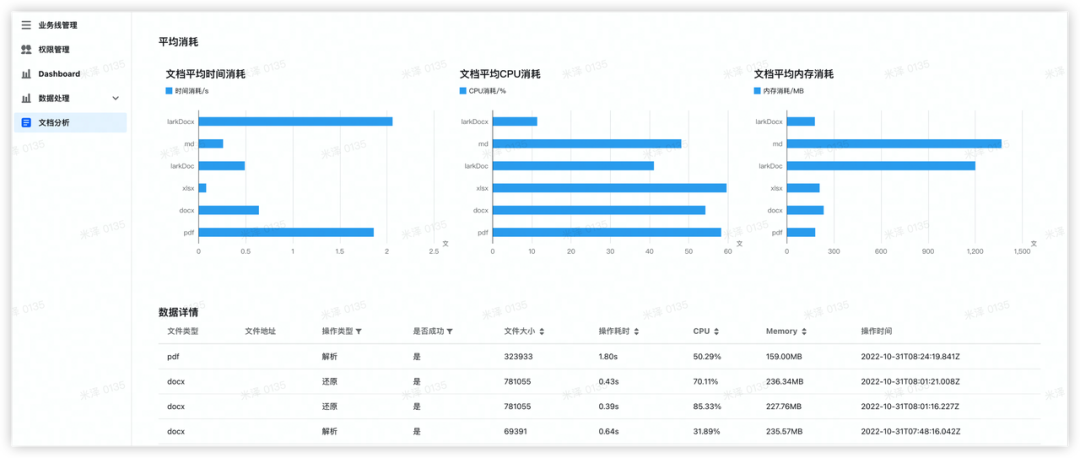
3.4 Larkdocx 批量更新关键实现
最后可以再分享一下国际化翻译平台文档解析 2.0 中 Larkdocx 批量更新实现的一个关键。起初,国际化翻译平台对飞书文档 2.0 的还原速度非常慢,对于大型文档来说,平台几乎无法正常导出,且飞书开放平台有同篇文档 QPS <= 3 的限制,如何提升还原速度,并满足 QPS 限制成为了又一个核心问题。
之前飞书文档 2.0 还原慢的主要原因在于每个 Block 的还原都需要调用一次 updateBlock[1],对于大文档来说,block 总数有上千个,更新请求可达上千次,自然很慢。经过调研,飞书开放平台在不久之前开放了批量更新块接口[2],正好可以解决请求过多的问题。另外,由于飞书开放平台有同篇文档同一接口 QPS <= 3 的限制,为了同时实现批量更新分块与限流,需要开发一个专用的限流调度器,在传统限流调度器的基础上需要增加错误重试的功能,具体实现如下:
async function concurrentFetch(poolLimit, iterable, iteratorFn) {
const result = [];
const retry = [];
const executing = new Set();
for (const item of iterable) {
const p = Promise.resolve().then(() => iteratorFn(item));
result.push(p);
executing.add(p);
const clean = () => executing.delete(p);
p.then((r) =>
r ? retry.push(Promise.resolve().then(() => iteratorFn(r))) : clean())
.catch(clean);
if (executing.size >= poolLimit) {
await Promise.race(executing);
}
}
return Promise.all(result).then(() => Promise.all(retry));
}
// Usage
async batchUpdateBlock(blocks: Lark.Block[], documentId: string) {
const blockUpdates = blocks.map(block => this.getUpdateForBlock(block)).filter(Boolean)
const chunkedBlockUpdates = chunk(blockUpdates, MAX_BATCH_SIZE)
const batchUpdateWithErrorHandle = async chunk => {
return await this.lark
.batchUpdateBlockForDocx(documentId, {
requests : chunk
})
.then(resp => {
// 如果遇到无权限报错,需要进行降级处理
if (resp?.data.code === LARK_BLOCK_UPDATE_ERROR_CODE.ForBidden) {
return this.downgradeUpdatesForBlocks(chunk)
}
// ...其余兜底处理操作
return null
})
}
// 3的QPS限制,用batchUpdateWithErrorHandle中的then条件判断决定是否降级处理与重试
await concurrentFetch(3, chunkedBlockUpdates, batchUpdateWithErrorHandle)
}四、总结
通过对国际化翻译平台文档解析当前所面临的问题分析,将 SDK 中解析与还原、各种翻译能力还原到本质,最终抽象出一套适配当前需求与未来发展的三层架构——文档解析 2.0。其中的具体实现使用了 Decorator 装饰器、Adapter 与 Proxy 设计模式、限流调度器等等,从中我们也可以看出平时似乎不太常用的语法、设计模式与热门面试题等等其实都有它们各自发挥作用的场合,这也是为什么我们要更加注重平时基础知识积累的原因——所有强大的上层实现,都离不开底层更强大的基础知识。