DataWind 可视化查询数据流重构
背景
DataWind 使用 umi 脚手架,所以数据流一直绑在 dva 方案。由于 dva 本身语法较为陈旧,加上 DataWind 使用的比较粗旷,导致项目拆包时遇到模块间紧紧咬合的问题,牵一发而动全身。
上个双月正好在做模块架构升级,正好把数据流一并升级到新方案,同时解决可视化查询模块内、与其它模块间数据流使用不规范问题,也带来更好的开发体验。
问题
繁琐的初始化模版
排除掉具体内容,初始化数据流的模版代码非常繁琐:
export const getInitialState = (): IState => {...}
const model = combineModel({...}, analysisModels, dynamicFieldModels)
const undoableActionTypes = [...]
function withCancelable<T>(effect: [T, any]): [T, any]
function withCancelable<T>(effect: T): T
function withCancelable(effect) {...}
model.effects.init = withCancelable(model.effects.init)
function vizQueryEnhance<T extends IState>(model: Model): Model {
const { namespace, effects, reducers } = model
const modelActionTypes = Object.keys({...})
const enhancedReducer = getUndoEnhancer<T>(model as any, {...} as UndoableOptions<T>)
return {...}
}
const { dispatchAction, getLoading, putAction } = getModuleInfo(...)
const enhancedModel = vizQueryEnhance(model as any)
export default enhancedModel
export const myModel = {
action: dispatchAction,
innerAction: putAction,
getLoading,
getState: getModuleGetter<IMyModelState>(namespace)
}异步语法老旧

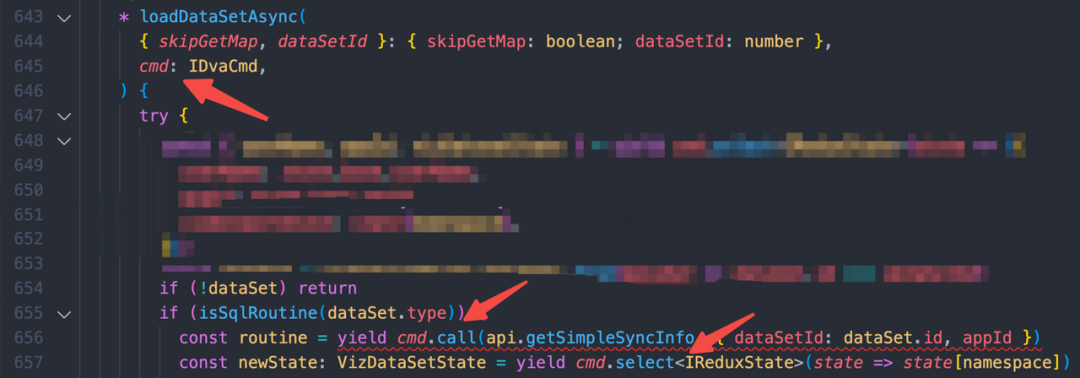
cmd.call(fn, args) 的语法,获取数据流的值要使用 cmd.select<IReduxState>(state => ..) 的语法,无疑都不符合简单清晰的直觉,同时要手动传入泛型也显得多此一举。
Effect 调用 reducer 繁琐
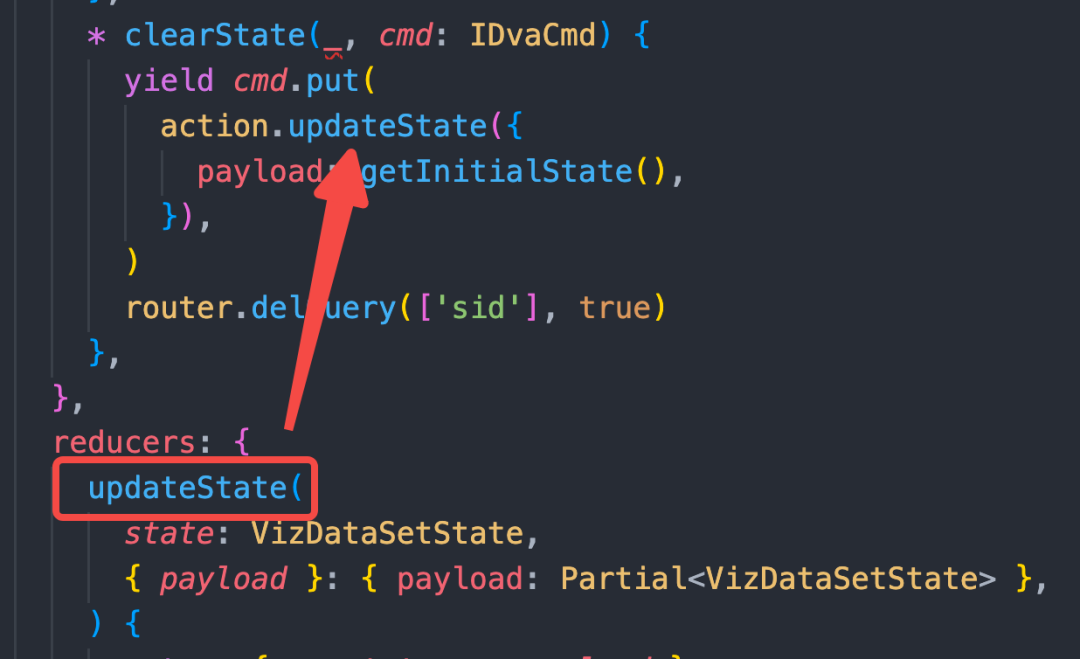
因为 reducer 仅支持同步,干净无副作用,所以 Effect 就被拓展出来干脏活。但调用的过于繁琐:
使用数据流方式繁琐
数据流调用是问题的核心,即使数据流写的再烂,用起来舒服也能把问题解决大半。但实际上存量代码里用的并不舒服,大部分采用 classComponent 的 connect 方法,需要手动申明类型。
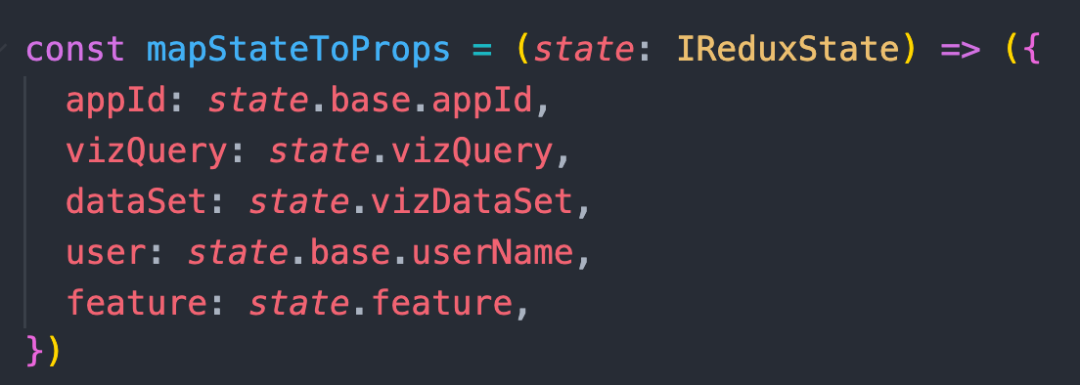
useStore 且类型都是 any,这会引发另一个问题,后面再说。
调用 action 也不是这么自然,需要为每个组件申明 dispatch 属性,且调用时必须引用到具体 model 才能 . 出具体 function:

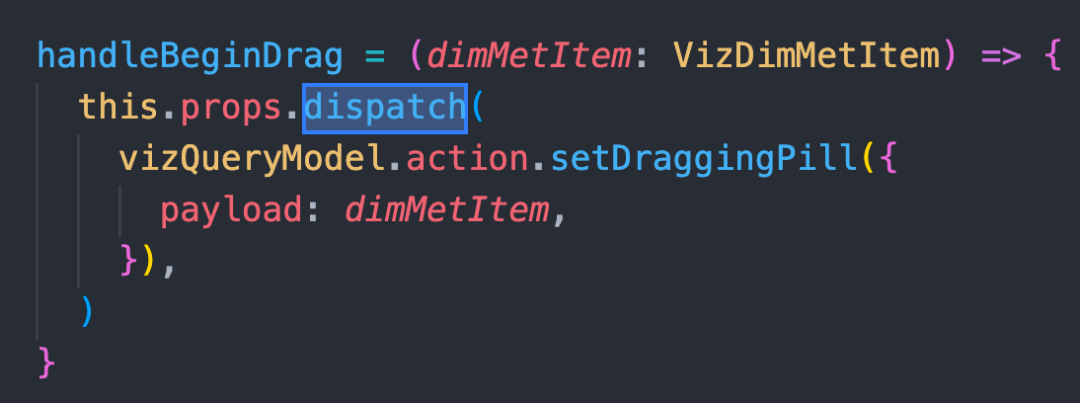
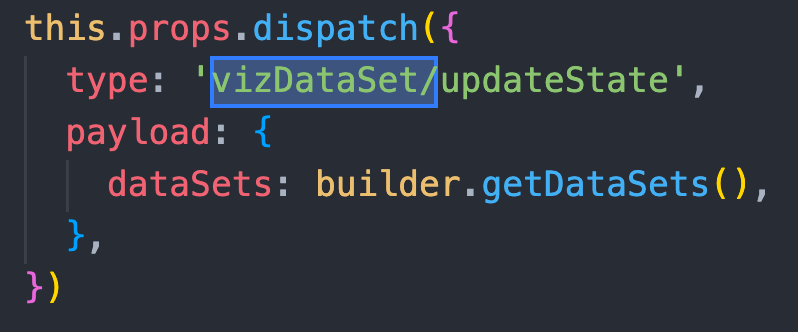
用到了就 connect
这句话用无奈的语气念出来。
无论用任何变量,都要 connect 才能拿到,似乎 connect 是唯一获取变量的方法。
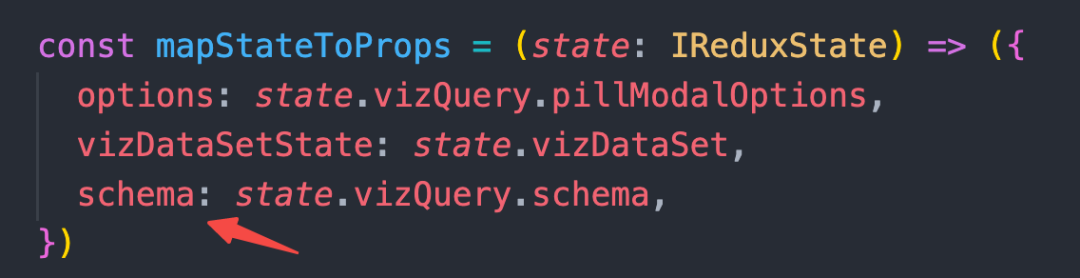
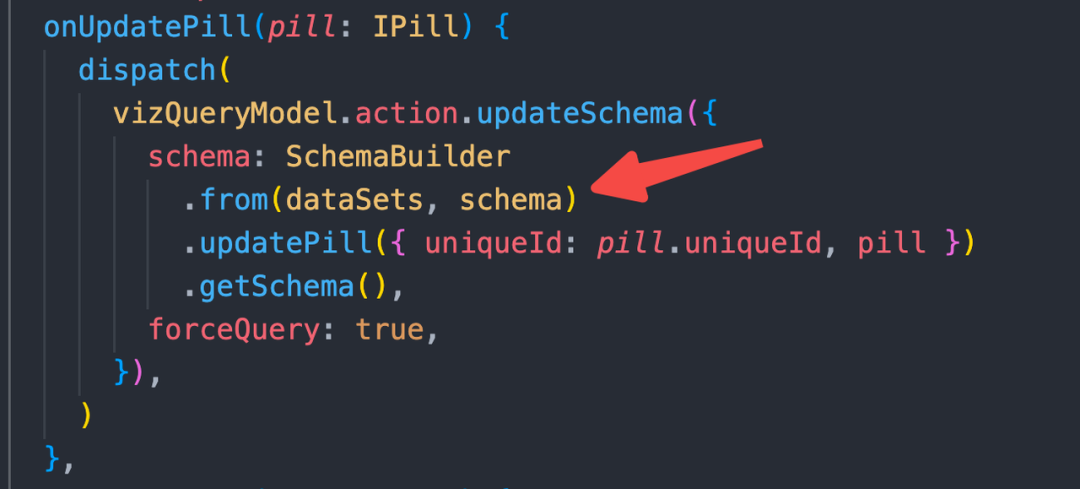
store.getState() 获取瞬时值,否则会带来无意义的重渲染,同时如果是 functionComponent,也会让函数无意义的重新实例化。
类似的例子还有很多,几乎所有代码都写错了,不止可视化查询,还包括旧版仪表盘,随便找个例子:
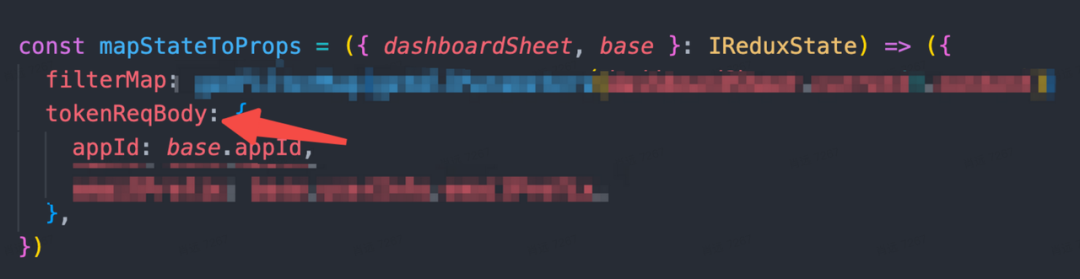
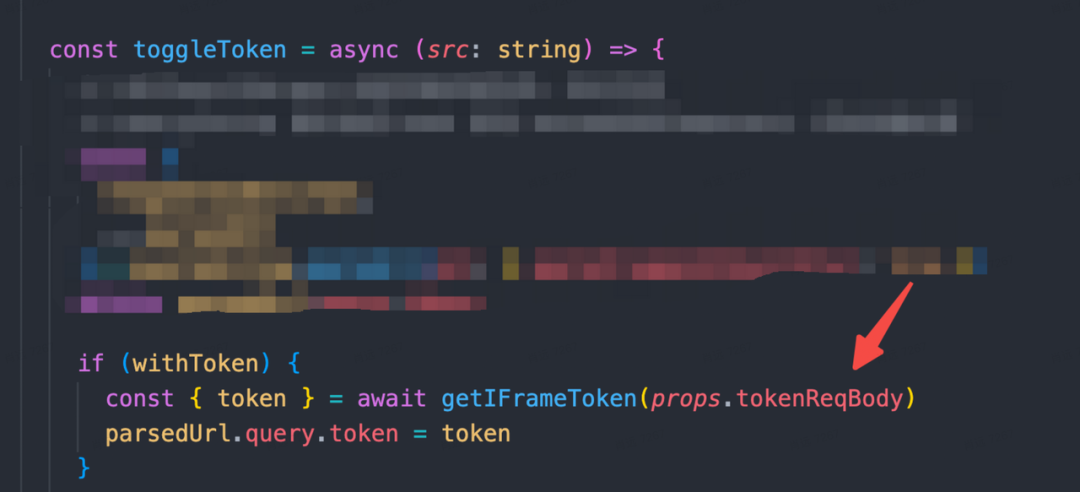
应用间耦合
这个问题分两部分看,首先是跨模块引用痛苦。下面是数字大屏为了复用可视化查询数据集选择组件时,需要付出的代价:
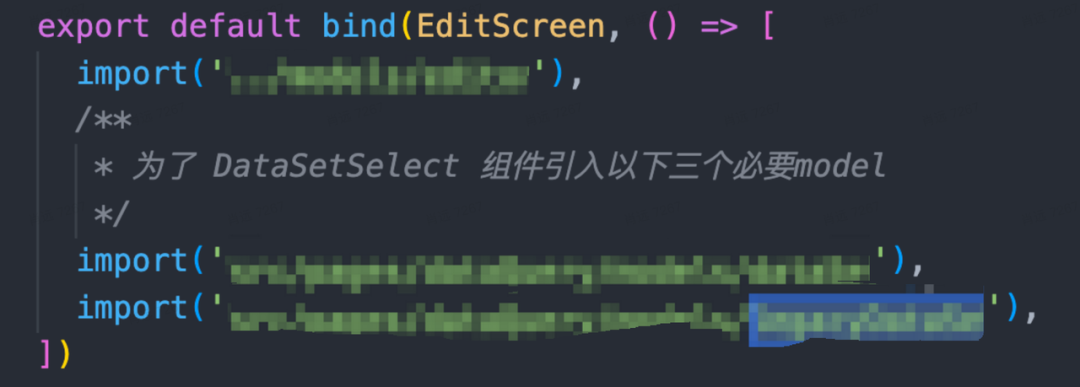
legacyDataSet 模块,不引用这个模块,这个组件就跑不起来。But,为什么要知道这个?
另一个是对 dva 的强依赖,即依赖的模块不去 dva,就去不了 dva,陷入死循环。
由于全局所有公共数据、仪表盘、可视化查询、大屏、数据集、数据问答等等都放在一个大 dva 里,所以一个模块基本别想自己单独去 dva,所有模块一起去,这个工程永远也不可能启动:
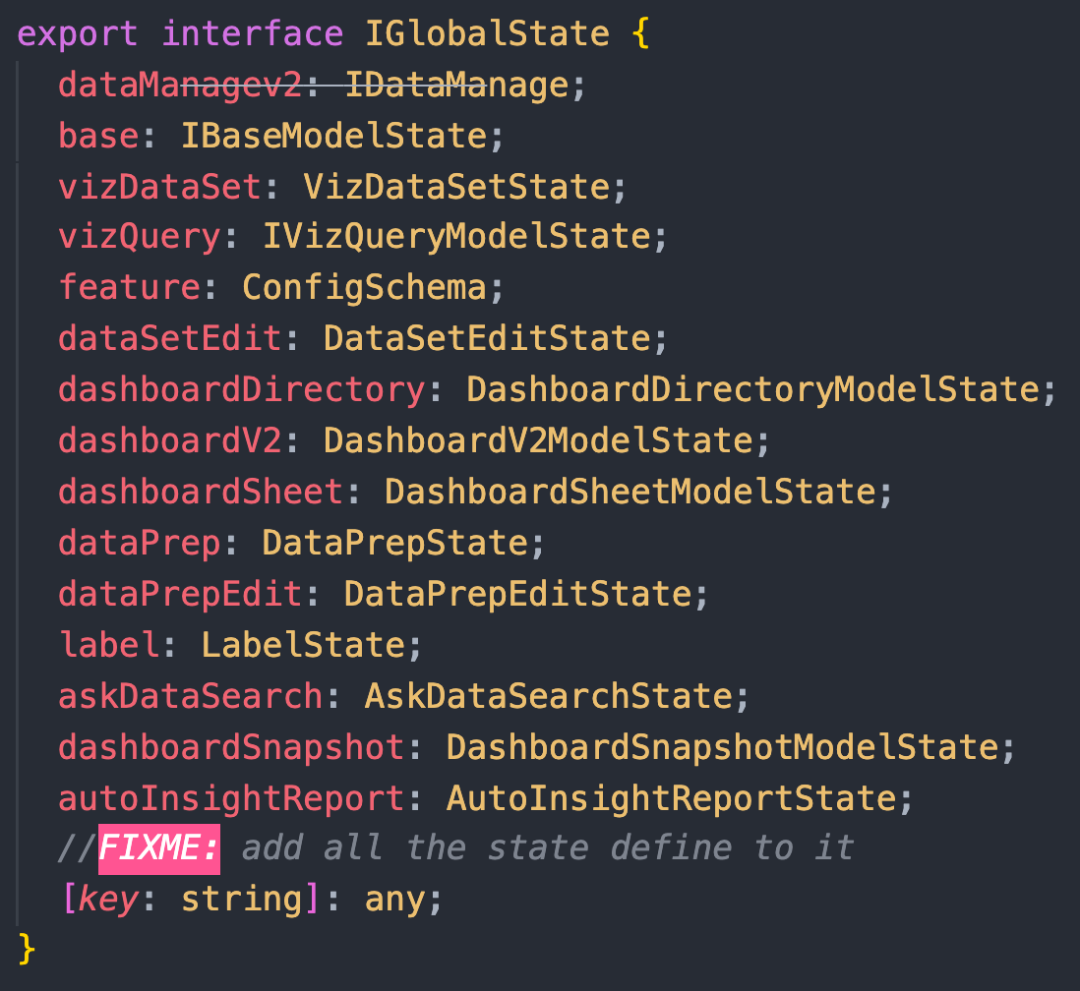
全局唯一实例的问题
下面是一段充满了无奈的代码:
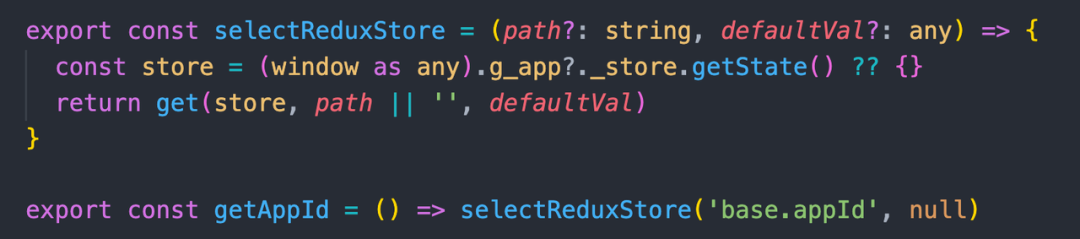
全局 g_app._store 打破了这个幻想,且不说没有类型,无法应对应用多实例问题,这个写法会导致逻辑调用链的错乱。
比如 A 模块依赖 B 模块,现在 “得益于” window 的状态管理,A 和 B 都可以相互调用了,这看上去是更灵活了,但等梳理逻辑时,会让人头皮发麻。
令我惊讶的是,这个秘诀还是挺广为人知的,很受欢迎:
OpenAPI 与应用关系倒置
“得益于” dva 数据流的全局地位,开放 API 也不得不因为 ROI 考虑,优先与 dva 做对接。

这看似一个小关系倒置,其实蛮影响维护成本的,为什么?OpenAPI 与应用在这套架构下就是平行关系了,如果我是 dva 小二,要同时给 OpenAPI 和应用端茶倒水,哪位爷没伺候好服务都得挂。
另一方面,直接依赖 dva 也容易导致代码实现变形,即直接依赖 dva 的 getState()、dispatch 做一些事情,其实 OpenAPI 应该不关心实现,只与应用约定接口,应用哪怕用 JQuery 写,用 window 做数据流也不妨碍 OpenAPI 的对接,所以一开始开放就不应关心数据流是什么,而是约定接口。
什么样的数据流是足够好的?
这个问题没有标准答案,但普遍认可的方向是以下几条:
- 概念少。最好不要有独创语法或规则。
- 强类型。最好不要有什么手段可以绕过类型系统写代码。
- 使用方便。最好调用函数只有一行,不要有五花八门的调用方式。
- 实现简单。就像 redux 一样实现简单才不容易出岔子。
- 支持副作用。仅支持 reducer 肯定不够,但别因此搞一堆 redux 中间件,头疼。
- 多实例抗干扰。可以多个数据流实例同时使用,而不会相互干扰。
- 可同时用于组件和项目。最好能伸能缩,复杂组件有时候也用得上数据流。
我们内部的数据产品搭建框架提供的数据流能力(底层是 @dp/hookstore 能力[1])就是尽力符合以上几点去做的,以下是我的几个思考:
- Action 部分利用 hooks 语法,除了与 react 框架绑定外,几乎没有新增概念。
- Typescript 泛型、重载能力足以支持大部分类型推导语法,除了 Partial Type Argument Inference[2]。
- 将 useSelector 与 store.getState 合并为一个函数。
- 本身基于 react-redux + context + hooks 实现,源码一共 300+ 行。
- Hooks 本身支持副作用,无需实现,且对 react 开发者来说 0 学习成本。
- 使用 react-redux 的
createSelectorHook实现多实例间互不干扰。 - 由于 4、5、6 的技术选型本身就可以同时用在组件与项目上。
解法
新的数据流方案基于 redux + hook,所以称为 hookStore,即基于 hook 方案的数据流。
初始化模版
首先引用 @dp/wind 包中两个 create 方法,分别创建数据流中间件与数据流:
import { createMiddleware, createWind } from '@dp/wind'
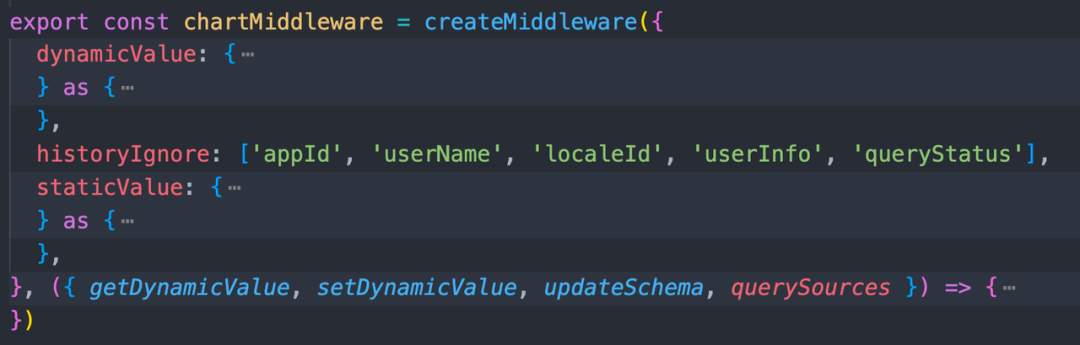
createWind 组装这些中间件:
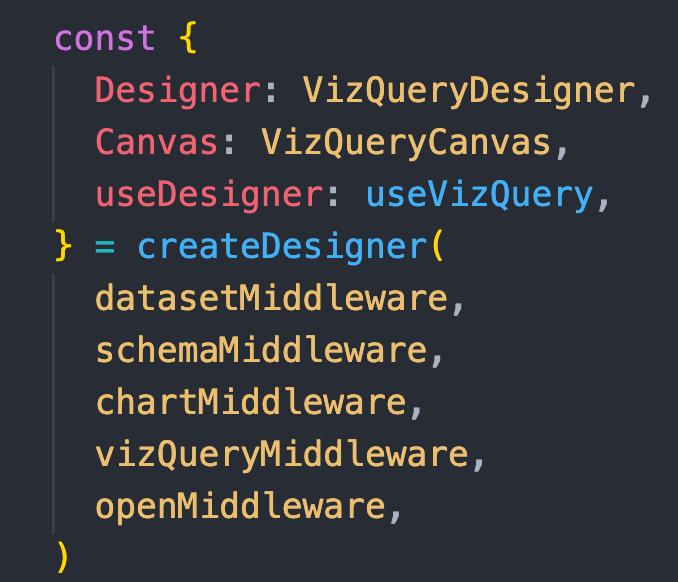
<VizQuery``Wind``/>标签包裹应用,就创造了一个数据流作用域,而这个 < VizQuery``Wind``/> 会写在每个模块内部,比如可视化查询 UI 里才会调用 < VizQuery``Wind``/>,所以即便实例化多套可视化查询应用,也可以同时跑起来。
useVizQuery 是 UI 组件使用数据流的方式,同时组合了获取变量与调用函数,具体用法放后面说。而且通过这种方式创建数据流,Provider 于 useState 是一一对应关系,不同 createWind 之间的数据可以叠加使用,不会串。(背后使用了 react-redux 新版 API createSelectorHook实现)
用 hooks 写 Action
不同于 dva,这个数据流方案不区分 reducer 和 effects,createMiddleware 第二个参数是个回调 Hook 函数,在里面可以使用任意 React Hooks 语法,所以不仅可以用来写 Action,也可以用来写组件生命周期相关的逻辑,所以异步也很自然的可以采用 async/await。
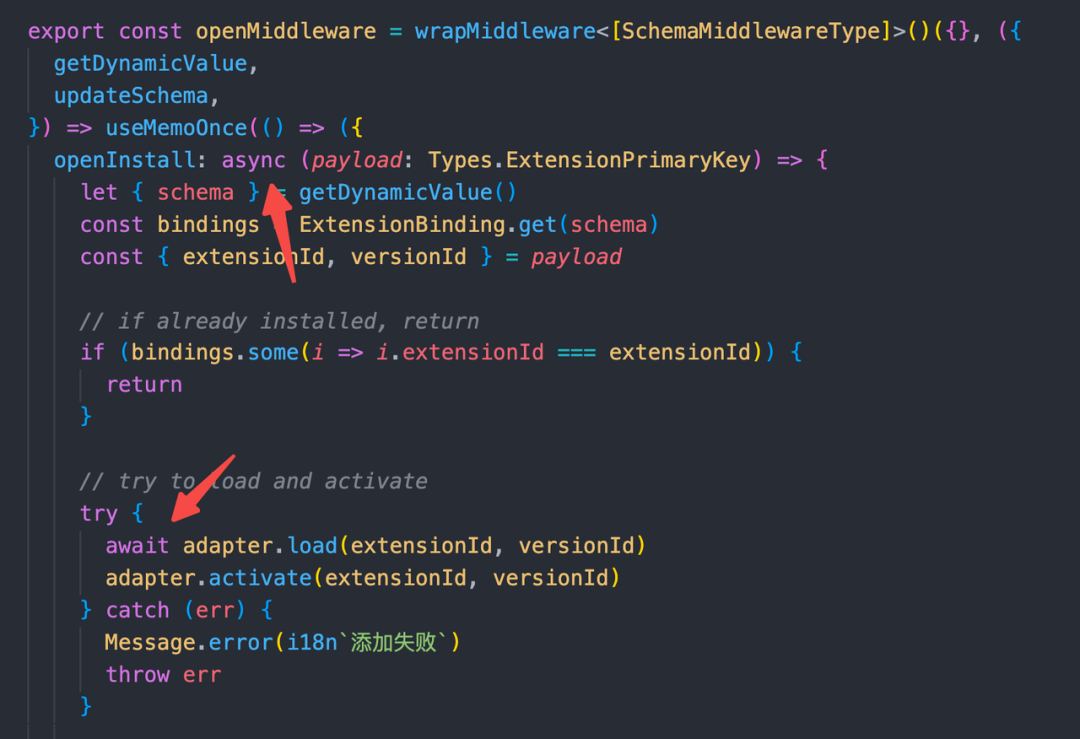
统一调用变量与方法
与 dva 甚至大部分现代数据流方案不同,这里只需要 useVizQuery 一个函数就可以同时获取数据、调用方法:

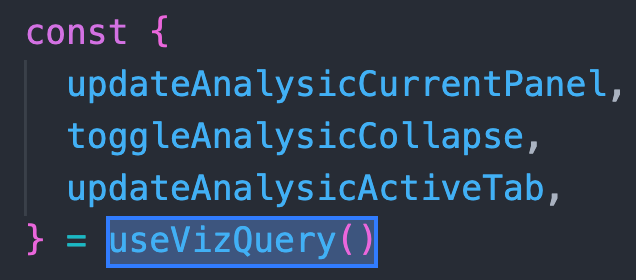

useVizQuery 记住这一个方法就可以了。同时 ts 类型也是自动推导,点击引用会直接跳转到对应中间件,中间件内查找 reference 可以找到使用处,且没有给业务字符串调用的口子,方便管理。
应对部分 ClassComponent 文件
大量 ClassComponent 无法使用 hooks 也是一个阻碍,重构时,简单的组件就改成 FunctionComponent,复杂的组件就包裹一层 FCWrapper。其实重构为 FunctionComponent 后代码清晰度得到了巨大的提升,下面是修改前:
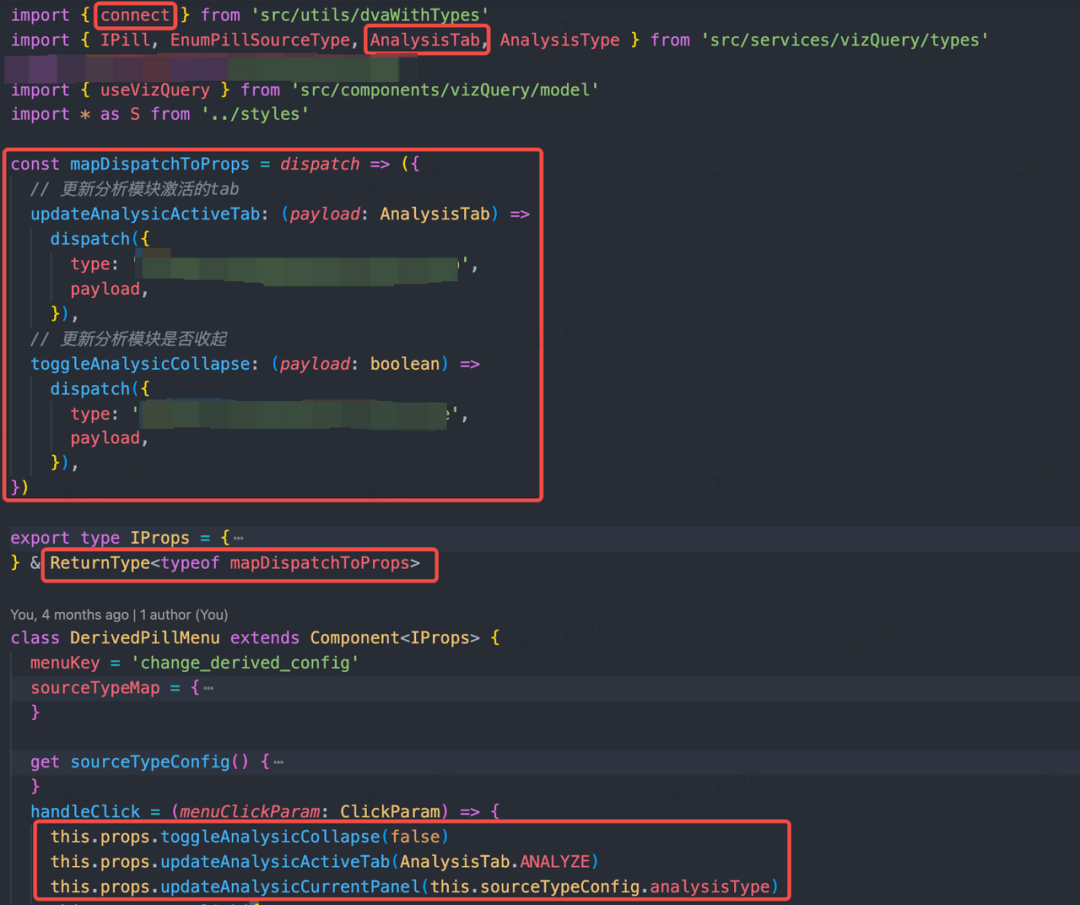
Connect(DerviedPillMenu),然而修改后简洁了不少:
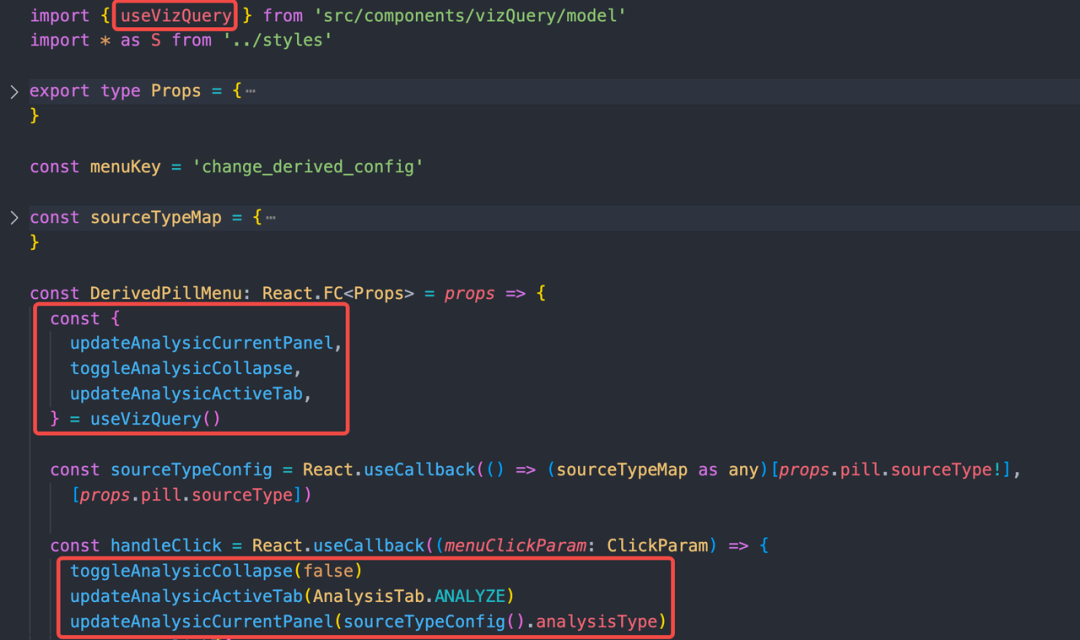
内置提供获取瞬时值函数
使用原生 react-redux 可以采用 useStore 方式在回调函数里获取瞬时值,但需要自定义一个绑定类型的 useStore:
const useStore = reduxUseStore as () => Store<IReduxStore>
function App() {
const store = useStore()
const onClick = useCallback(() => {
console.log(store.getState().userName)
}, [])
}在 wind 方案中,调用方式如下:
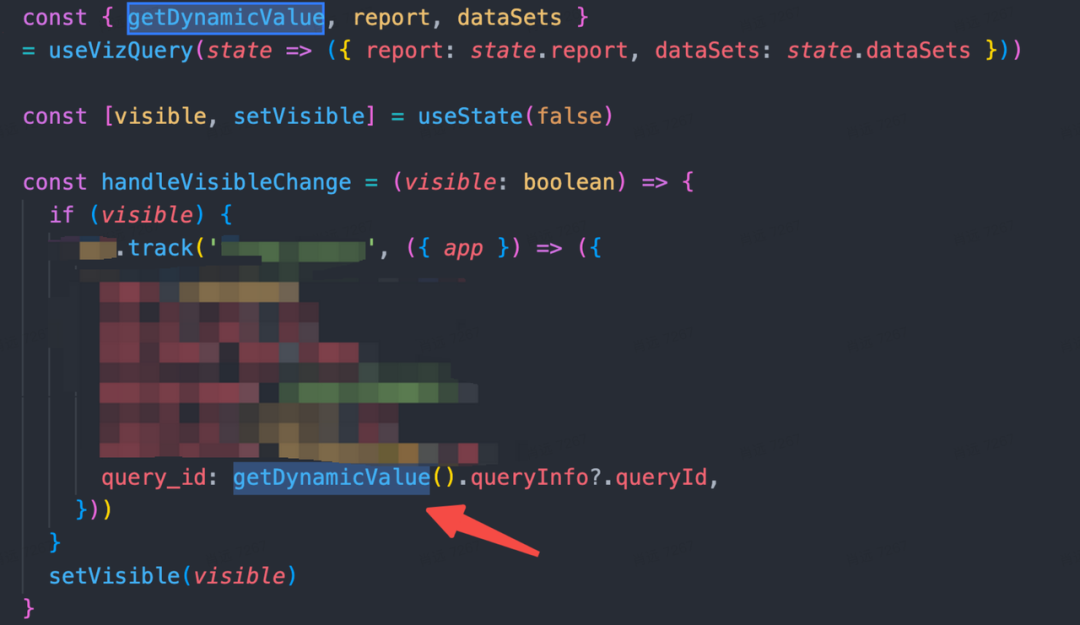
useVizQuery 就行了,不需要额外调用 useStore 方法。
应用内的数据流
改造后的数据流实例化在应用内,且应用如果生成了多份实例,数据流也会相应生成互不干扰的多份实例。最重要的是,可视化查询是仪表盘的基础,会整体作为一个组件被仪表盘调用,那么在这个数据流方案下,仪表盘把可视化查询当作一个普通组件即可,就和 Input 组件一样调用即可,否不需要关心对方用的数据流方案是什么。
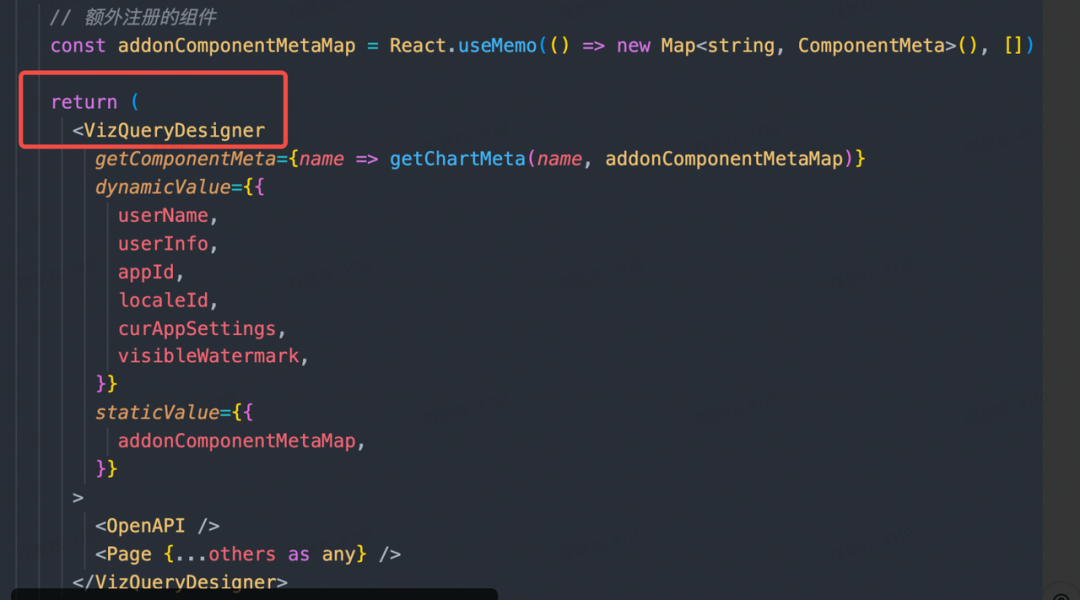
OpenAPI 与数据流解耦
经过大家的努力,可视化查询与 OpenAPI 的关系、调用方式逐渐变得正规了起来:OpenAPI 提供 useExternal 函数注册开放能力,应用只需要在合适的时机调用即可,且注册的函数以接口形式暴露,实现方式由应用决定,所以即便应用从 useVizQuery 直接取出函数对接,也不显得多此一举,因为这对解耦设计是值得的。
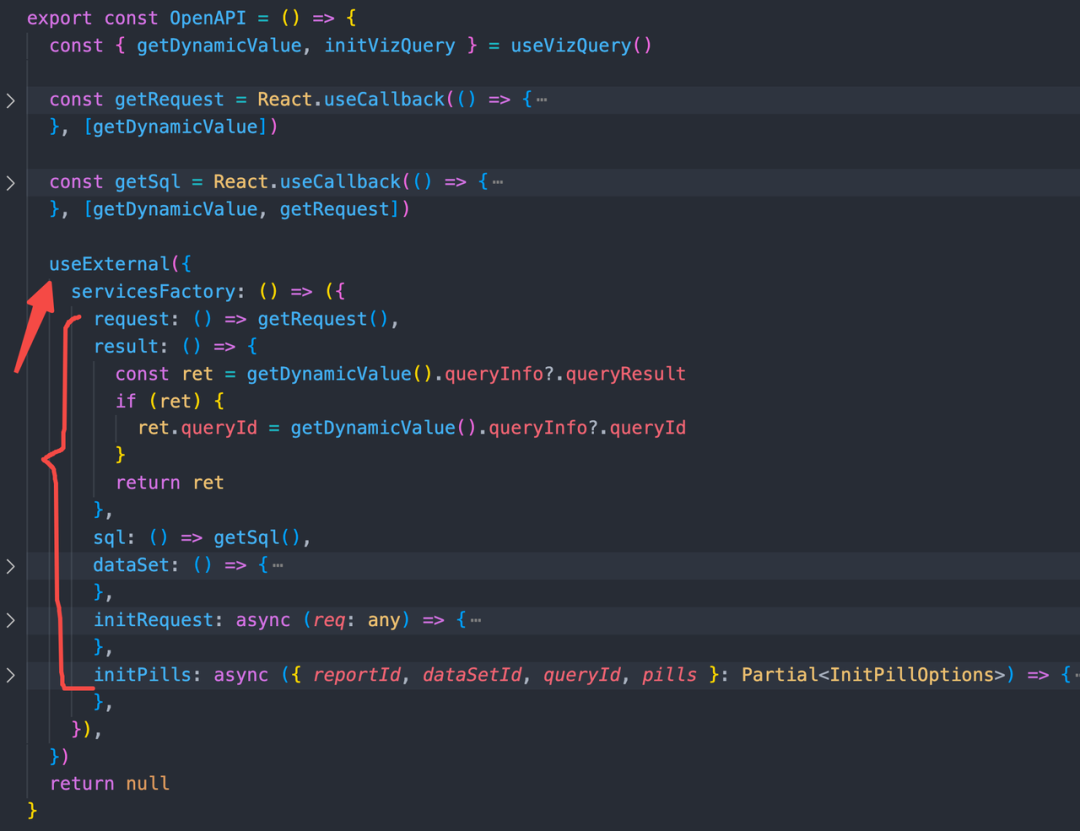
IVizDataset 绑定了,而是由应用决定如何实现。
遇到的挑战
这种类似方案几年前就已经被广泛讨论了,dva 其实已经过时好几年了,可能除了大家平时业务都比较忙以外,还一个重要原因是 dva 嵌入 DataWind 业务太深,依赖就像一张蜘蛛网,盘根错节,牵一发而动全身。
从一开始修改时就要做好把所有项目文件都改一遍的觉悟,这既是一件技术活,也是一件体力活,你得同时愿意付出脑力与体力,连续付出好几天重复劳动的时间,才能将你的思考落地。
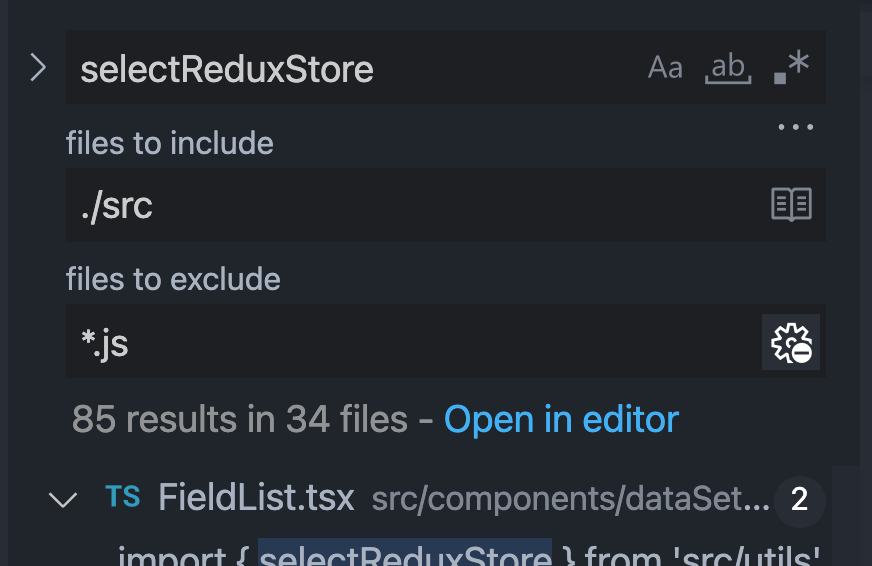
体力劳动最麻烦的地方是修改引用,使用最广泛的是 schema、vizData、vizQuery 这三个变量,即便搜索范围限定在可视化查询内(最后在全局也要搜索一遍,可能其它模块会调用),还是涉及几十个文件: