缓存热点,缓存穿透,终极解决方案看过来
背景
前不久,因为公司业务需要,需要解决在大促场景下后端业务的热点缓存问题,所以研究了下缓存热点解决方案。
很多公司的缓存都是基于redis来做的,redis的性能其实已经足以能应付大部分的场景,但是对于大促期间或者活动抢购期间的某个爆品,可能会出现在几秒时间内流入大量的流量,由于某个爆品的数据在redis cluster场景下会按照hash规则被存放在某个redis分片上,那么这几秒的流量都会压到这个redis分片,从而在瞬间会导致这个redis分片的瘫痪,也会影响后续的redis请求的阻塞。
还有个场景,就是公司并不是所有的服务端逻辑都有缓存。在流量起来的时候,这些热key还是会压到数据库层面。导致压力。
解决方案
一般常见的解决方案就是增加二级缓存,对于热点数据写到jvm里一份。设置过期时间。但是什么时候设置,热点如何探测,规则如何设置,过期时间设置多少。甚至于如何快速落地,这都是需要研究的问题。
我们希望有一个统一的方案来解决这些问题。
我们发现了Hotkey这款开源框架。
Hotkey源于京东,hotkey能自动地对任意突发性的无法预知的热点数据,按照配置的规则进行毫秒级别的探测,探测到的热数据会推送到所有的服务端JVM中,大幅减轻对后端数据层的冲击。这些热数据在整个微服务集群会保持一致性,当热点消失的时候,自动从jvm中进行移除。
Hotkey的特性能很好的实现我们的目标。并且京东内部也用Hotkey实战了618大促,稳定性有所保障。
Hotkey的架构图(以下图引用自Hotkey在Gitee的主页)
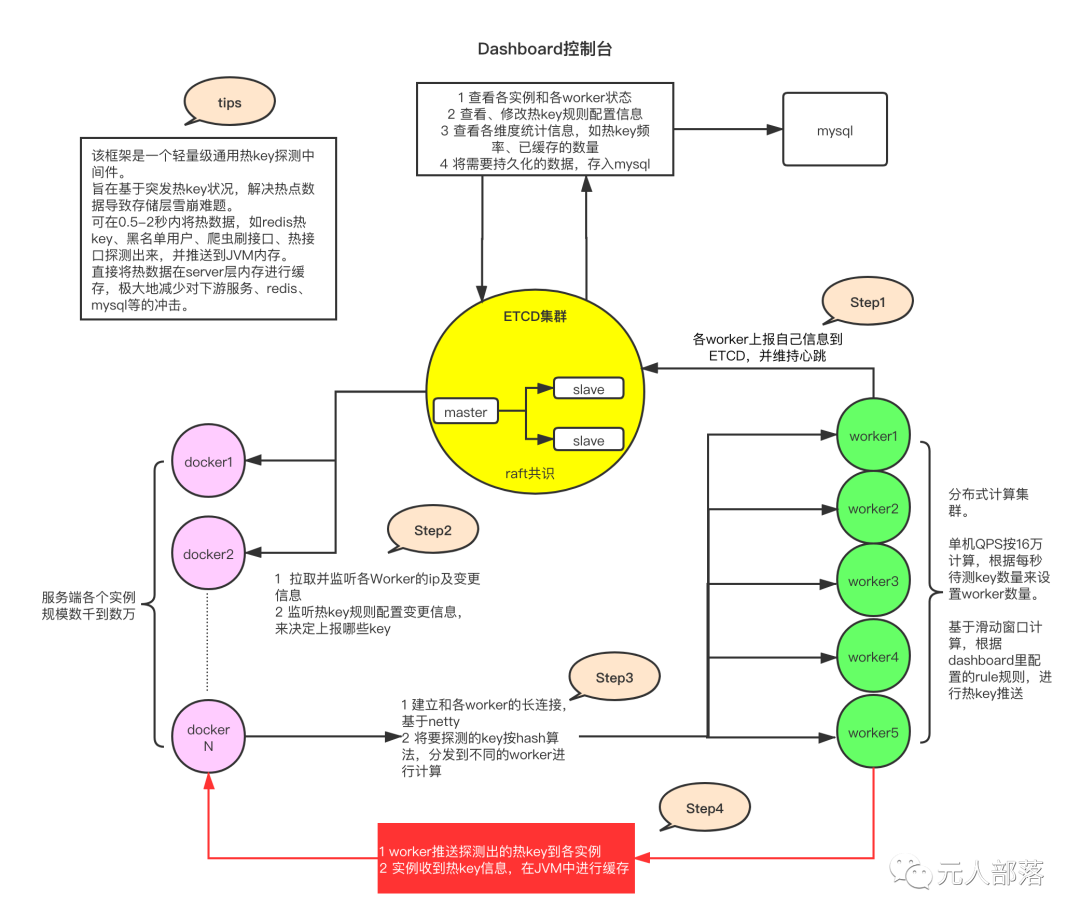
worker:负责采集上报信息,根据规则计算出热点信息,规则来自于etcd。热点信息推送到client里
client:每个client连接etcd,获取每个worker的ip和端口,和worker保持长链接,接受worker的热点信息推送
etcd:分布式的协调者,接受每个worker的心跳上报,并把worker的连接信息推送给client。监听规则的改变,推送给worker
dashboard:ui界面,查看实例以及worker的状态,查看以及修改规则数据。规则存到mysql,同时由etcd推送给worker
下面给出hotkey的项目地址
https://gitee.com/jd-platform-opensource/hotkey
关于Hotkey的介绍和如何搭建,大家可以看这篇文章来了解,这里就不多赘述。
[京东毫秒级热key探测框架设计与实践,已实战于618大促]
碰到的问题
我们在搭建hotkey环境和落地实施中,碰到2个问题:
- Hotkey虽然开源,但是相关client jar包并未上传中央仓库,dashboard和worker启动包也并未提供下载。需要下载源码进行编译,编译过程中也碰到一些包依赖的问题。
- Hotkey的client jar只提供了api级别的方法供程序使用,如果要落地到业务项目中,需要大规模的修改代码才能实施。
我们更希望提供一种侵入更少的方式,在RPC以及接口的层面进行代理包装。使用者无论使用什么RPC框架,只是在相关接口上打上标注,而无需动业务的任何代码。就可以在这个接口层面进行检测热点。如果该接口的某个参数为热点的话,就自动进行代理,走jvm的热点数据,等热点消除后,依旧走原来的调用。
如果你觉得上述的描述过于难以理解的话,那么直白点说就是:
比如某个活动大促期间有个商品S001进行抢购,有大量的流量进入了商品详情页面。这个商品详情RPC方式调用了商品服务的以下接口方法获取商品信息:
public interface ProductService{
SkuInfo getSkuInfo(String skuCode);
}那么我们希望只在这个接口上打上标注。就可以适配Hotkey框架进行探测热点,当商品S001被大量请求时,S001这个商品就可以成为热点,这时getSkuInfo这个接口就会被自动代理,从而只从Jvm中获取数据,而不会真正走RPC调用。等热点消除后,这个接口依旧调用RPC获取数据。
这样的方式无疑侵入性更小,更容易使Hotkey框架落地。
Hotlink客户端
为此我们基于Hotkey client研发了Hotlink客户端框架,该客户端框架能让Hotkey更完美的落地,增强了Hotkey客户端的能力。
Hotlink的项目地址:https://gitee.com/openbeast/hotlink
该客户端框架有以下特点:
- 业务接入简单,只需要一个标注,1分钟就能使你的RPC接口接入热点探测框架
- 启动时动态扫描所有Hotlink标注的接口,创建动态代理
- 基于动态代理去对接口做增强,理论上只要有接口,就支持任何RPC框架
- 本地方法只要有接口,也能使用热点探测
结合Hotkey的架构图,Hotlink在整个架构图中的位置如下图:
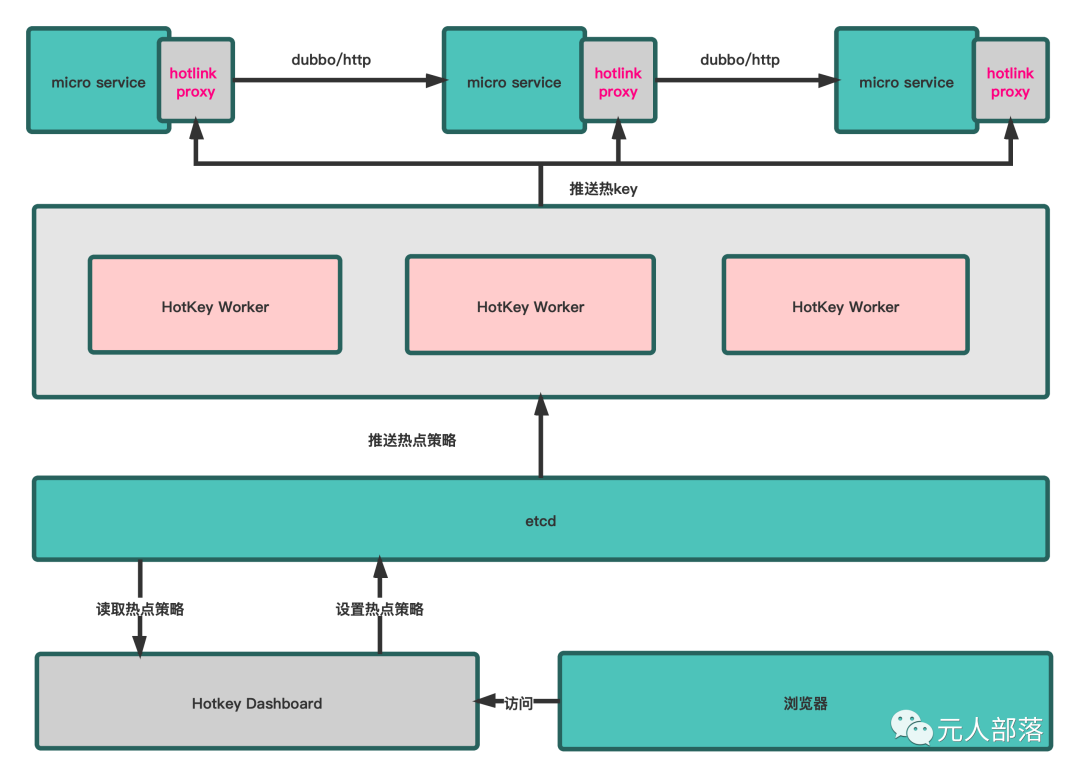
Hotlink如何使用
第一步
按照Hotkey的部署要求,搭建好worker和dashboard。具体方式请参照:
https://gitee.com/jd-platform-opensource/hotkey
同时为了方便大家搭建,我把编译好的worker和dashboard包也进行了上传
worker下载地址:
公网IP版本(适合调试用,本地能连上worker):
https://gitee.com/openbeast/hotlink/attach_files/813746/download/worker-0.0.4-SNAPSHOT-public.jar
内网IP版本:
https://gitee.com/openbeast/hotlink/attach_files/813747/download/worker-0.0.4-SNAPSHOT.jar
Dashboard:
https://gitee.com/openbeast/hotlink/attach_files/813749/download/dashboard-0.0.2-SNAPSHOT.jar
第二步
本地业务项目依赖jar包(此jar包并未上传到中央仓库,需要大家自己deploy到自己公司的私库)
<dependency>
<groupId>com.thebeastshop</groupId>
<artifactId>hotlink-spring-boot-starter</artifactId>
<version>1.0.12</version>
</dependency>hotlink需要的fastjson和groovy版本有点要求,如果你项目中的这2个包版本过低又同时覆盖了hotlink的传递依赖包时,需要额外指定版本:
<fastjson.version>1.2.70</fastjson.version>
<guava.version>29.0-jre</guava.version>第三步
本地springboot配置文件里加入参数
#此app-name不配置的话,会优先读取spring.application.name属性
hotlink.app-name=test
#etcd地址和端口
hotlink.etcd-url=http://xxx.xxx.xxx.xxx:2379第四步
在你的接口里加入标签@Hotlink
在接口上加:接口里所有的方法都会自动探测热点
在方法上加:只有这个方法会自动探测热点
比如:
public interface ProductService{
@Hotlink
SkuInfo getSkuInfo(String skuCode);
}那么当某一个SKU001成为热点时,那么传入参数SKU001会自动代理从JVM里取到数据,而SKU002则继续走RPC调用。
这样就完成了所有的配置。启动皆可。
使用Hotlink需要注意的事项
由于Hotlink的实现是用动态代理来实现,只要满足这两个条件,即可在启动时会扫描器扫到:
- 接口层面上标注
@Hotlink - 相关实现会被注入Spring上下文中
在标注接口的时候,尽量标注在一定时间范围内是幂等的接口。比如会员查询,sku信息查询,相关活动信息的查询,这些信息在一定时间范围内不会频繁变动,那么就适合做热点探测。
非幂等性的接口,即便是相同参数,每次返回也会不一样。那就不建议做热点探测。比如下单,库存的查询,余额的查询。这样的接口如果一旦被升级成热点。那会影响业务界面的正确性和后续逻辑的判断错误。
- END -