redis 性能这么好,你不完全知道
redis 有多快
curd 的工程师的梗,大多数程序员都是业务的开发,大量业务有没有让你心乱如麻,有时学些底层的知识感觉也是蛮不错的。

完全基于内存实现
磁盘调用栈图
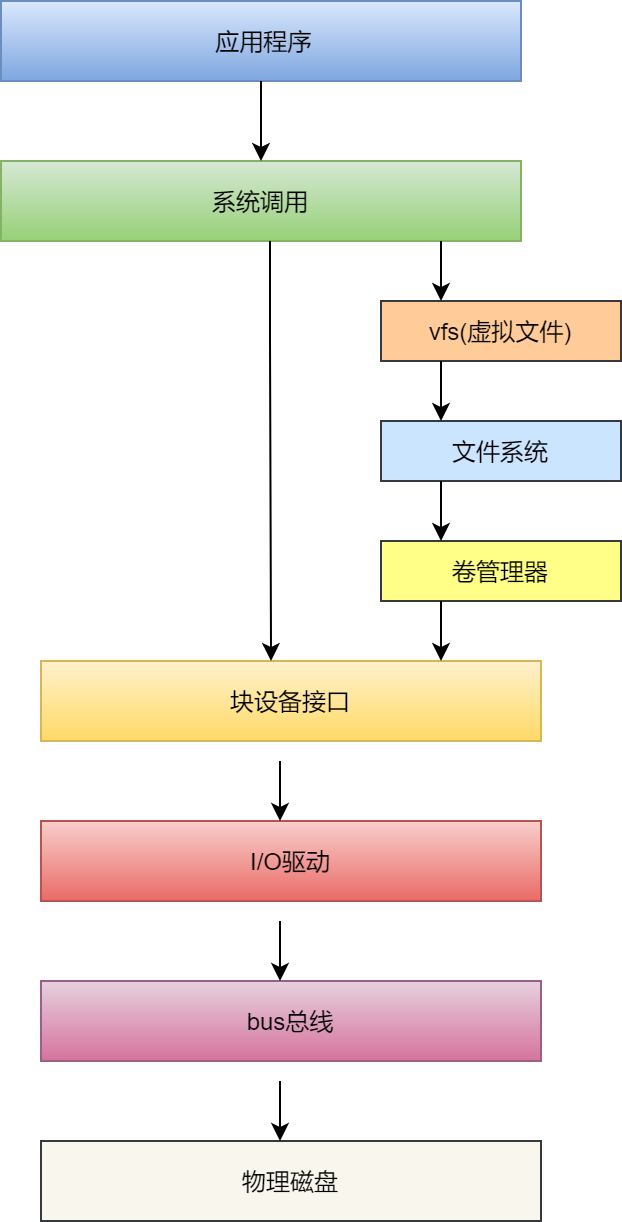
内存操作
可能大家对数量级没有什么该概念。那可是整整 1000 倍啊!现在大家知道了吧。
高效的数据结构
1、简单动态字符串 SDS 是对 C 语言字符数组的封装,类似 GO 语言中的切片,也是对应底层数组的封装,在其中增加一些额外的参数,方便加速字符串操作。
字符串长度处理
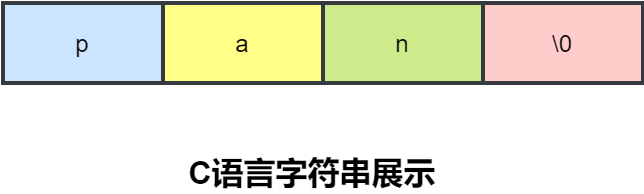
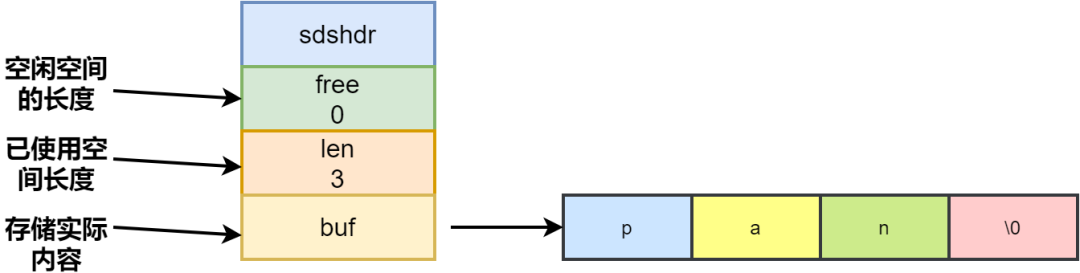
内存重新分配
C 语言中涉及到修改字符串的时候会重新分配内存。修改地越频繁,内存分配也就越频繁。而内存分配是会消耗性能的,那么性能下降在所难免。
而 Redis 中会涉及到字符串频繁的修改操作,这种内存分配方式显然就不适合了。于是 SDS 实现了两种优化策略:
空间预分配
对 SDS 修改及空间扩充时,除了分配所必须的空间外,还会额外分配未使用的空间。GO语言中的切片也会分配预留空间,防止空间频繁分配。
具体分配规则是这样的:SDS 修改后,len 长度小于 1M,那么将会额外分配与 len 相同长度的未使用空间。如果修改后长度大于 1M,那么将分配1M的使用空间。
惰性空间释放
当然,有空间分配对应的就有空间释放。
SDS 缩短时,并不会回收多余的内存空间,而是使用 free 字段将多出来的空间记录下来。如果后续有变更操作,直接使用 free 中记录的空间,减少了内存的分配。
二进制安全
你已经知道了 Redis 可以存储各种数据类型,那么二进制数据肯定也不例外。但二进制数据并不是规则的字符串格式,可能会包含一些特殊的字符,比如 '\0' 等。
前面我们提到过,C 中字符串遇到 '\0' 会结束,那 '\0' 之后的数据就读取不上了。但在 SDS 中,是根据 len 长度来判断字符串结束的。
2、双端链表
列表 List 更多是被当作队列或栈来使用的。队列和栈的特性一个先进先出,一个先进后出。双端链表很好的支持了这些特性。
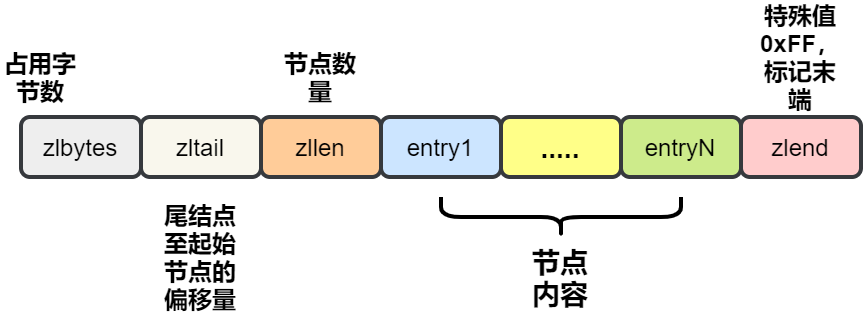
链表里每个节点都带有两个指针,prev 指向前节点,next 指向后节点。这样在时间复杂度为 O(1) 内就能获取到前后节点。
头尾节点
你可能注意到了,头节点里有 head 和 tail 两个参数,分别指向头节点和尾节点。这样的设计能够对双端节点的处理时间复杂度降至 O(1) ,对于队列和栈来说再适合不过。同时链表迭代时从两端都可以进行。
链表长度
头节点里同时还有一个参数 len,和上边提到的 SDS 里类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到 len 值就可以了,这个时间复杂度是 O(1)。不用每次遍历获取长度。
3、压缩列表
双端链表我们已经熟悉了。不知道你有没有注意到一个问题:如果在一个链表节点中存储一个小数据,比如一个字节。那么对应的就要保存头节点,前后指针等额外的数据。
这样就浪费了空间,同时由于反复申请与释放也容易导致内存碎片化。这样内存的使用效率就太低了。
于是,压缩列表上场了!
并且压缩列表的内存是连续分配的,遍历的速度很快。
4、字典
Redis 作为 K-V 型数据库,所有的键值都是用字典来存储的。
字典又称为哈希表,这点没什么可说的。哈希表的特性大家都很清楚,能够在 O(1) 时间复杂度内取出和插入关联的值。
5、跳跃表
作为 Redis 中特有的数据结构-跳跃表,其在链表的基础上增加了多级索引来提升查找效率。
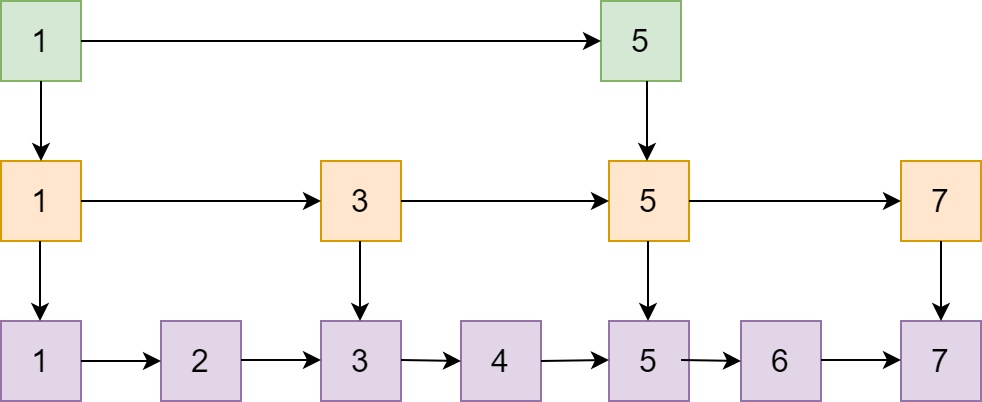
这是跳跃表的简单原理图,每一层都有一条有序的链表,最底层的链表包含了所有的元素。这样跳跃表就可以支持在 O(logN) 的时间复杂度里查找到对应的节点。
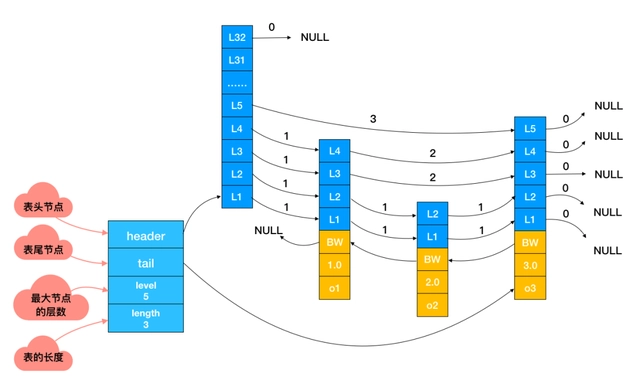
下面这张是跳表真实的存储结构,和其它数据结构一样,都在头节点里记录了相应的信息,减少了一些不必要的系统开销。
单线程模型
单线程指的是 Redis 键值对读写指令的执行是单线程。
Redis 的单线程指的是 Redis 的网络 IO (6.x 版本后网络 IO 使用多线程)以及键值对指令读写是由一个线程来执行的。
单线程有什么好处?
- 不会因为线程创建导致的性能消耗。
- 避免上下文切换引起的 CPU 消耗,没有多线程切换的开销。
- 避免了线程之间的竞争问题,比如添加锁、释放锁、死锁等,不需要考虑各种锁问题。
- 代码更清晰,处理逻辑简单。
多线程的弊端
- 使用多线程后,没有良好的系统设计,,增加了线程数量,前期吞吐量会增加,再进一步新增线程的时候,系统吞吐量几乎不再新增,甚至会下降 2 .切换上下文时,我们需要完成一系列工作,这是非常消耗资源的操作。
- redis 操作都是基于内存操作,很少有一些耗费CPU 的计算操作,对于 redis 操作来说,CPU 计算不是瓶颈,瓶颈在于 redis 操作内存的速度。
从网络 IO 来说,redis 的 网络 IO 接收事件,确实是一个很需要去提升的点 因为所有客户端对 redis 的操作 最终都会由 redis 的网络模块接受 ,所以对于 redis 来说 提升网络 IO 的利用率很有必要。
redis在4.0版本的时候就已经引入了多线程来做一些异步操作,此举主要针对那些非常耗时的命令,通过将这些命令的执行异步化,避免阻塞单线程的事件循环(增加了一些的非阻塞命令如 UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC)。
redis v6.0版本的时候引入了多线程IO,只是用来处理网络数据的读写和协议的解析,而执行命令依旧是单线程。
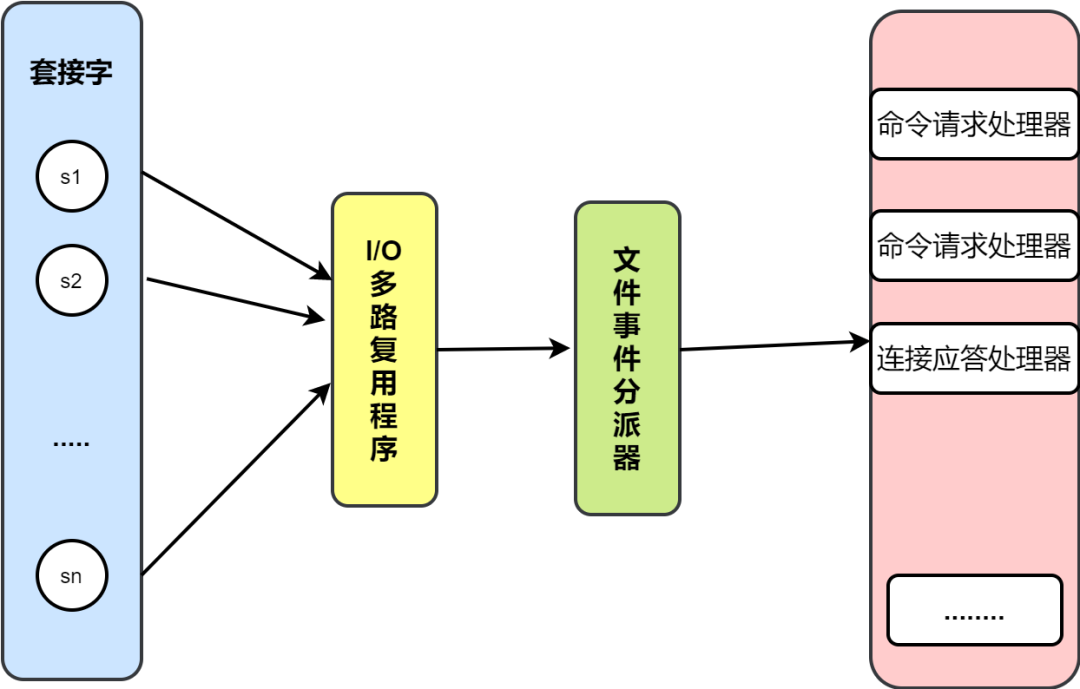
I/O 多路复用
Redis 采用 I/O 多路复用技术,并发处理连接。采用了 epoll + 自己实现的简单的事件框架。
epoll 中的读、写、关闭、连接都转化成了事件,然后利用 epoll 的多路复用特性,绝不在 IO 上浪费一点时间。
合理的数据编码方式
对于每一种数据类型来说,底层的支持可能是多种数据结构,什么时候使用哪种数据结构,这就涉及到了编码转化的问题。
那我们就来看看,不同的数据类型是如何进行编码转化的:
String:存储数字的话,采用int类型的编码,如果是非数字的话,采用 raw 编码。
List:字符串长度及元素个数小于一定范围使用 ziplist 编码,任意条件不满足,则转化为 linkedlist 编码。
Hash:hash 对象保存的键值对内的键和值字符串长度小于一定值及键值对。
Set:保存元素为整数及元素个数小于一定范围使用 intset 编码,任意条件不满足,则使用 hashtable 编码。
Zset:zset 对象中保存的元素个数小于及成员长度小于一定值使用 ziplist 编码,任意条件不满足,则使用 skiplist 编码。
总结
- 纯内存操作,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在 IO 上,所以读取速度快。
- 整个 Redis 就是一个全局 哈希表,他的时间复杂度是 O(1)。
- Redis 使用的是非阻塞 IO:IO 多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,Redis 采用自己实现的事件分离器,效率比较高。
- 采用单线程模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
- Redis 全程使用 hash 结构,读取速度快,还有一些特殊的数据结构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。
- 根据实际存储的数据类型选择不同编码
最后
Redis 6.0中的多线程,也只是针对处理网络请求过程采用了多线程,而数据的读写命令,仍然是单线程处理的。
期待后期版本 redis 数据的读写命令使用多线程,大家认为这是否合适?