Monorepo,大型前端项目管理模式实践
阅读本文您将了解到:什么是 monorepo、为什么要 monorepo、如何实践 monorepo。
项目管理模式
Monorepo 这个词您可能不是首次听说,在当下大型前端项目中基于 monorepo 的解决方案已经深入人心,无论是比如 Google、Facebook,社区内部知名的开源项目 Babel、Vue-next ,还是集团中 rax-components 等等,都使用了 monorepo 方案来管理他们的代码。
▐ 发展历程
仓库(repository,简称 repo),是我们用来管理项目代码的一个基本单元。通常每个仓库负责一个模块或包的编码、构建、测试和发布,代码规模相对较小,逻辑聚合,业务场景也比较收拢。
当我们在一整块业务域下进行研发时,代码的解耦和复用是一个非常重要的问题。
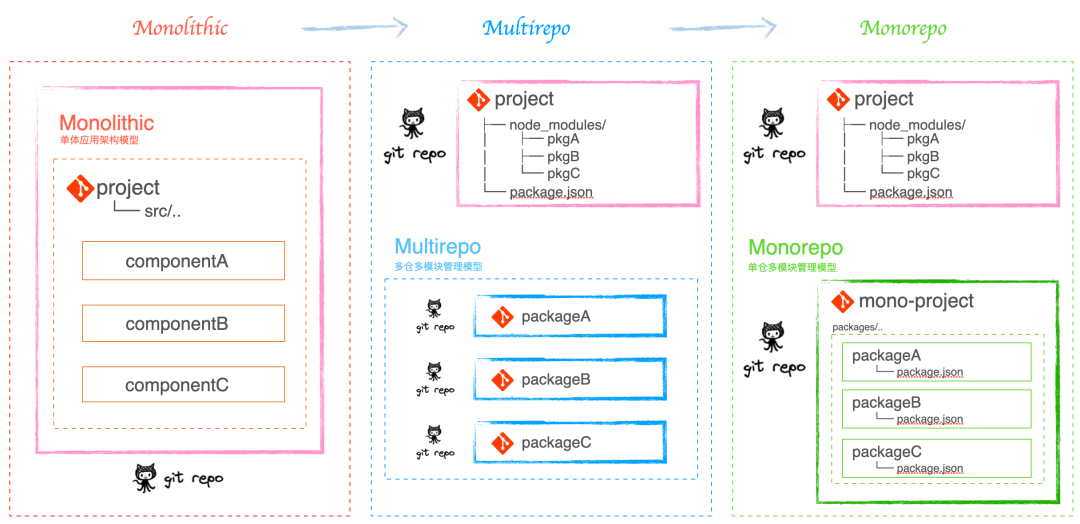
初期业务系统不复杂时,通常只用一个仓库来管理项目,项目为单体应用架构 Monolithic。这时我们会以合理划分目录,提取公共组件的方式来解决问题。由文件的层级划分和引入,来进行页面、组件和工具方法等的管理。此时其整个依赖和工作流都是统一的、单向的。
当业务复杂度的提升,项目的复杂性增长,由此就会导致一系列的问题:比如项目编译速度变慢(调试成本变大)、部署效率/频率低(非业务开发耗时增加)、单场景下加载内容冗余等等,技术债务会越积越多。同时又有了代码共享的需求,此时就需要按照业务和模块来拆分。那么组件化开发是一个不错的选择。这样每个仓库都能独立进行各模块的编码、测试和发版,又能实现多项目共享代码,研发效率提升也很明显(特别是调 UI 样式的时候)。同时在团队规模变大,人员分工开始明确,拆分的好处还带来不同开发人员关注点可按照域来分散研发,队员只需关心自己模块所在的仓库,对各自核心的业务场景关注思考更加集中和收拢。这种管理模式我们称之为多仓多模块管理 Multirepo(Polyrepo也是一个意思)。
再随着时间的沉淀,模块数量也在飞速增长。Multirepo 这种方式虽然从业务逻辑上解耦了,但也同时增加了项目的工程管理难度。组件化的前期可以忽略不计,当模块量到达一定体量程度下,这个问题会逐渐明显。比如:
- 代码和配置很难共享:每个仓库都需要做一些重复的工程化能力配置(如 eslint/test/ci 等)且无法统一维护,当有工程上的升级时,没能同步更新到所有涉及模块,就会一直存在一个过渡态的情况,对工程的不断优化非常不利。
- 依赖的治理复杂:模块越来越多,涉及多模块同时改动的可能性急剧增加。如何保障底层组件升级后,其引用到的组件也能同步更新到位。这点很难做到,如果没及时升级,各工程的依赖版本不一致,往往会引发一些意想不到的问题。
- 存储和构建消耗增加:假如多个工程依赖 pkg-a,那么每个工程下 node_modules 都会重复安装 pkg-a,对本地磁盘内存和本地启动都是个很大的挑战,增加了开发时调试的困难。而且每个模块的发布都是相对独立的,当一次迭代修改较多模块时,总体发布时效就是每个发布流程的串联。对发布者来说是一个非常大的负担。
有没有一种更好的管理模式,既能享受到 组件化多包管理 的收益,又能降轻工程复杂度引起的影响呢?这时就提出了单仓多模块管理 Monorepo 的概念。Monorepo 其实不是一个新的概念,在软件工程领域,它已经有着十多年的历史了。它是相对于 Multirepo 而言的一种模式,概念上非常好理解,就是把多个项目放在一个仓库里面。用统一的本地关联、构建、发布流程,来消费业务域下所有管理的组件模块。
▐ 单体应用架构 Monolithic
项目初期起步阶段,团队规模很小,此时适合「单体应用」,一个代码仓库承接一个应用,管理成本低,最简力度支撑业务快速落地。
此时目录架构大概长这样:
project
├── node_modules/
│ ├── lib@1.0.0
├── src/
│ ├── compA
│ ├── compB
│ └── compC
└── package.json优点:
- 代码管理成本低
- 代码能见度高(无需额外的学习成本)
- 发布简单,链路轻便
缺点:
- 代码量大了后,调试、构建效率显著下降
- 无法跨项目复用
▐ 多仓多模块管理 Multirepo
团队规模变大,人员分工明确,单体应用的缺点会愈发突出,此时 「Multirepo」就更适合。模块分工更明确,可拓展可复用性更强,调试构建发布能力也有一定提升。
此时目录架构大概长这样:
project
├── node_modules/
│ ├── lib@1.0.0
│ ├── lib@2.0.0
│ ├── pkgA
│ ├── pkgB
│ └── ..
├── src/
└── package.json
packageA
├── node_modules/
│ └── lib@1.0.0
├── src/
└── package.json
packageB
├── node_modules/
│ └── lib@2.0.0
├── src/
└── package.json优点:
- 便于代码复用
- 模块组件独立开发调试,业务理解清晰度高
- 人员编排分工更加明确
- 提高研发人员的公共抽取思维能力
- 源代码访问权限设置灵活
缺点:
- 模块划分力度不容易把握
- 共同引用的版本问题,容易导致重复安装相同依赖的多个版本
- 构建配置不复用,不好管理
- 串行构建,修改模块体量大时,发布成本急剧上升
- Code Review、Merge Request 从各自模块仓库执行,比较分散
▐ 单仓多模块管理 Monorepo
随着组件/模块越来越多, multirepo 维护成本越来越大,于是我们意识到我们的方案是时候改进了。
此时目录架构大概长这样:
project
├── node_modules/
│ ├── lib@2.0.0
│ ├── pkgA
│ ├── pkgB
│ └── ..
├── src/
└── package.json
mono-project
├── node_modules/
│ └── lib@2.0.0
├── packages/
│ ├── packageA
│ │ └── package.json
│ └── packageB
│ └── package.json
└── package.json优点:
- 所有源码在一个仓库内,分支管理与单体应用一样简单
- 公共依赖显示更清晰,更方便统一公共模块版本
- 统一的配置方案,统一的构建策略
- 并行构建,执行效率提升
- 保留 multirepo 的主要优势
- 代码复用
- 模块独立管理
- 分工明确,业务场景独立
- 代码耦合度降低
- 项目引入时,除去非必要组件代码
6 . CR、MR 由一个仓库发布,阅读和处理十分方便
缺点:
- git 服务根据目录进行访问权限划分,仓库内全部代码开发给所有开发成员(这种非特殊限制场景不用考虑)
- 当代码规模大到一定程度时,git 的操作速度达到瓶颈,影响 git 操作体验(中小型规模不用考虑,而且就算是 def 平台可并行量也为 500)
▐ 优缺点对比梳理
| 场景 | multirepo | monorepo |
|---|---|---|
| 项目代码维护 | ❌ 多个仓库需要分别download各自的node_modules,像这种上百个包的,多少内存都不够用 | ✅ 代码都只一个仓库中,相同依赖无需多分磁盘内存。 |
| 代码可见性 | ❌ 包管理按照各自owner划分,当出现问题时,需要到依赖包中进行判断并解决 ✅ 对需要代码隔离的情况友好,研发者只关注自己核心管理模块本身 | ✅ 每个人可以方便地阅读到其他人的代码,这个横向可以为团队带来更好的协作和跨团队贡献,不同开发者容易关注到代码问题本身 ❌ 但同时也会容易产生非owner管理者的改动风险 ❌ 不好进行代码可视隔离 |
| 代码一致性 | ❌ 需要收口eslint等配置包到统一的npm包,再到各自项目引用,这就允许每个包还能手动调整配置文件 | ✅ 当您将所有代码库放在一个地方时,执行代码质量标准和统一风格会更容易。 |
| 代码提交 | ❌ 底层组件升级,需要通知到所有项目依赖的相关方,并进行回归 ❌ 每个包的修改需要分别提交 | ✅ API 或共享库中的重大更改能够立即公开,迫使不同的开发者需要提前沟通并联合起来。每个人都必须跟上变化。 ✅ 提交使大规模重构更容易。开发人员可以在一次提交中更新多个包或项目。 |
| 唯一来源 | ❌ 子包引用的相同依赖的不同版本的包 | ✅ 每个依赖项的一个版本意味着没有版本冲突,也没有依赖地狱。 |
| 开发 | ✅ 仓库体积小,模块划分清晰。 ❌ 多仓库来回切换(编辑器及命令行),项目一多真的得晕。如果仓库之间存在依赖,还得各种 npm link。 | ✅ 只需在一个仓库中开发,编码会相当方便。 ✅ 代码复用高,方便进行代码重构。 ❌ 项目如果变的很庞大,那么 git clone、安装依赖、构建都会是一件耗时的事情。 |
| 工程配置 | ❌ 各个团队可能各自有一套标准,新建一个仓库又得重新配置一遍工程及 CI / CD 等内容。 | ✅ 工程统一标准化 |
| 依赖管理 | ❌ 依赖重复安装,多个依赖可能在多个仓库中存在不同的版本,npm link 时不同项目的依赖可能会存在冲突问题。 | ✅ 共同依赖可以提取至 root,版本控制更加容易,依赖管理会变的方便。 |
| 代码管理 | ✅ 各个团队可以控制代码权限,也几乎不会有项目太大的问题。 | ❌ 代码全在一个仓库,如果项目一大,几个 G 的话,用 Git 管理可能会存在问题。 ❌ 代码权限如果需要设置,暂时不支持 |
| 部署(这部分两者其实都存在问题) | ❌ multi repo 的话,如果各个包之间不存在依赖关系倒没事,一旦存在依赖关系的话,开发者就需要在不同的仓库按照依赖先后顺序去修改版本及进行部署。 | ❌ 而对于 mono repo 来说,有工具链支持的话,部署会很方便,但是没有工具链的话,存在的问题一样蛋疼。(社区推荐pnpm、lerna) |
| 持续集成 | ❌ 每个repo需要定制统一的构建部署过程,然后再各自执行 | ✅ 可以为 repo 中的每个项目使用相同的CI/CD部署过程。 ✅ 同时未来可以实现更自动化的部署方式,一次命令完成所有的部署 |
总体来说,当业务发展到一定规模时,monorepo 的升级相比 multirepo 来说,是利远大于弊的。
Monorepo 使用 or not
▐ 业务现状
天猫校园如意pos业务域场景丰富,整体的代码逻辑比较复杂,因此采取按照 app(项目入口)-bundle(业务域板块:可以理解为页面)-component/util(通用组件:base组件、biz组件、utils和sdk平铺,都属于这个) 的形式进行整个项目的管理。目前项目所涉及的 npm 业务模块数量已经超过了 100 个。
▐ 存在的制约
1 . 应用规模增长,构建依赖本地环境,构建效率低下,非业务投入成本不断上升
a 主应用需要频繁构建
b . 构建前依赖的模块需要单独构建,构建速度串行
c . 组件还在不断增长,愈加不利于工程的维护
2 . 组件类发布没有对接集团规范,无CR卡点,二级依赖凌乱
a . 代码 review 全靠 人工 diff 进行 cr
b . 每次的版本信息都是通过手动维护
c . 组件依赖的二级依赖不统一,package-conflict 非常多
▐ 优化目标
构建部署发布提效,全链路CR及需求管控,全代码卡点管控,后续代码质量,单测节点补充等等
- 降低构建部署成本,对于一次合理的多包改动,只需要进行1~2次的构建即可完成部署任务
- 降低每次迭代的应用发布的维护成本,对于一个应用及其包含的子应用(包括集成包和微应用模式),一次完整的研发流程只需要维护一个发布迭代。发布依赖关系通过自动化流程进行优化。
- 对于主子应用/组件可以进行合理的CR管控
- 每个有变更的子应用都可以关联到对应的aone需求(可多个)。
- 能将整个研发和发布流程统一到一个平台上进行操作,降低理解和操作成本。(更进一步的优化,将原来割裂的一些流程节点进行整合,以及版本迭代修改日志的统一维护。)
- 在流程节点上可以提供扩展方式,预留后续类似代码扫码,质量评估,灰度管控等体系。
▐ 选用结论
综上所述,不管是当应用规模发展到一定规模下普遍遇到的情况,还是历史包袱,如意pos现在已经是一个超级复杂的应用。以上的问题所带来的制约,只会愈加凸显。在这个大背景下,这个阶段,为了解决上面的问题,使用 monorepo 进行项目管理升级,是非常有价值的。
▐ 落地结果
落地过程参考后面的「最佳实践」
| 打包 | 开发 | 发布 | |
|---|---|---|---|
| 架构升级前 | 单组件打包时间70~90s,迭代 n 个包需要 *n 的时间 | 单个包启动开发需要~60s,同时开发多个包会拖慢速度,进入打包发布流程会打断开发 | 脱轨线上发布平台CR/测试无卡点,脱离管控 |
| 架构升级后 | 并行构建打包 n 个包只需要~90s | 本地开发不会被打断,节省重启时间 | 云平台构建模式,接入 CR 卡点,进一步提高质量稳定性 |
| 提效总结 | 组件打包成本降低90% | 启动成本降低100% | 发版提效80%,本地构建转云构建 |
Monorepo 生态
Monorepo 只是一个管理概念,实际上它并不代表某项具体的技术,更不是所谓的框架。开发人员需要根据不同场景、不同的研发习惯,使用相应的技术手段或者工具,来达到或者完善它的整个流程,从而达到更好的开发和管理体验。
目前前端领域的 Monorepo 生态有一个很显著的特点就是只有库,而没有大一统的框架或者完整的构建系统来支持。目前的工具形态上像是传统的 CMake 那样的辅助工具,而不是像 Gradle(构建语言 + 生态链)或 Cargo(包管理器自身集成) 那样统一的方式。可能未来的趋势是像 nx 或者 turborepo 这样的库要往完整的框架发展,或者包管理器自身就逐步支持相应的功能,不需要过多的三方依赖。以下介绍一下生态中的一些核心技术:
▐ 包管理方案
-
Npm
npm 在 v7 才支持了 workspaces,属于终于能用上了但是并不好用的情况,重点是比较慢,通常无法兼容存量的 monorepo 应用,出来的时间太晚了,不能像 yarn 支持自定义 nohoist 以应对某些依赖被 hoist 到 monorepo root 导致的问题,也没有做到像 pnpm 以 link 的方式共享依赖,能显著的减少磁盘占用,除了 npm 自带之外没有其他优点。
-
Yarn
yarn 1.x
最早支持 workspaces 模式的包管理器,配合 lerna 占据了大部分 monorepo,在比较长的一段时间里是 monorepo 的事实标准,缺点是 yarn 的共享包才会提升到 root node_modules 下,其他非共享库都会每个地方留一份,占用空间比较多,还有提升到 root 这一行为也会带来兼容性问题(有些包的 require 方式比较 hack)
yarn berry(2 ~ 3)
比较新的点就是 pnp 模式,pnp 模式是为了解决 node_modules 臃肿、复杂度过高的问题而来的,但是比较激进,所以很难支持现有的项目。不过 yarn 3 基本上把各个包管理的功能都支持了(nodeLinker 配置),从功能上可以算是最多,比较复杂,概念好多。吸收了部分竞争对手的优点,并开辟了许多有趣的功能特性。
-
Pnpm
全称是 “Performant NPM”,即高性能的 npm。
如它在官方文档介绍的所说:“Saving disk space and boosting installation speed”,Pnpm 是一个能够提高安装速度、节省磁盘空间的包管理工具,并天然支持 Monorepo 的解决方案。除此之外,它也解决了很多令人诟病的问题,其中,比较经典的就是 Phantom dependencies(幻影依赖)。
pnpm 的优势:
- 安装依赖速度快,软/硬链接结合
- 安装过的依赖缓存全局复用,缓存逻辑基于文件块,不同版本的依赖可以只缓存 diff
- 自身支持 workspaces 相关
推荐导读:
pnpm官网:https://pnpm.io/zh/
▐ 包版本方案
-
Lerna
Lerna 是一个管理工具,用于管理包含多个软件包(package)的 JavaScript 项目。它可以优化使用 git 和 npm 管理多包存储库的工作流程。Lerna 主流应用在处理版本、构建工作流以及发布包等方面都比较优秀,既兼顾版本管理,还支持全量发布和单独发布等功能。在前端领域,它是最早出现也是相当长一段时间 monorepo 方案的事实标准,具有统治地位,很多后来的工具的概念或者 workspaces 结构都借鉴了 lerna,是 lerna 的延续。在业界实践中,比较多的时间上,都是采用 Yarn 配合 lerna 组合完整的实现了 Monorepo 中项目的包管理、更新到发布的全流程。
后来停更了相当长一段时间,至今还是不支持 pnpm 的 workspaces(pnpm 下有 workspace:protocol,lerna 并没有支持),与 yarn 强绑定。
最近由 nx 的开发公司 nrwl 接手维护,不过新增的 features 都是围绕 nx 而加,nrwl 目前似乎还并没有其他方向的 bug fix 或者新增 features 的计划。不过社区也出现了 lerna-lite ,可以作为 lerna 长久停滞的补充和替代,主要的新 features 就是支持在 pnpm workspaces。
推荐导读:
- lerna:https://www.lernajs.cn/
- lerna-lite:https://github.com/ghiscoding/lerna-lite
-
Changesets
Changesets 是一个用于 Monorepo 项目下版本以及 Changelog 文件管理的工具。在 Changesets 的工作流会将开发者分为两类人,一类是项目的维护者,还有一类为项目的开发者,开发者在Monorepo项目下进行开发,开发完成后,给对应的子项目添加一个changeset文件。项目的维护者后面会通过changeset来消耗掉这些文件并自动修改掉对应包的版本以及生成CHANGELOG文件,最后将对应的包发布出去。
▐ 包构建方案
-
Turborepo
上述提到传统的 Monorepo 解决方案中,项目构建时如果基于多个应用程序存在依赖构建,耗时是非常可怕的。Turborepo 的出现,正是解决 Monorepo 慢的问题。
Turborepo 是一个用于 JavaScript 和 TypeScript 代码库的高性能构建系统。通过增量构建、智能远程缓存和优化的任务调度,Turborepo 可以将构建速度提高 85% 或更多,使各种规模的团队都能够维护一个快速有效的构建系统,该系统可以随着代码库和团队的成长而扩展。
推荐导读:https://vercel.com/blog/vercel-acquires-turborepo
-
Nx
定位上是 Smart, Fast and Extensible build system,出现得比较早,发展了挺久,功能特别多,基本上 cover 了各种应用场景,文档也比较详细,是现在几个 Monorepo 工具里比较接近完整的解决方案和框架的。
最近的话他们也接手了 lerna 的维护,不过给 lerna 加的东西都是围绕 nx 而来。
推荐导读:https://nx.dev/
▐ 其它生态工具
-
Bolt
和 lerna 类似,更像是一个 Task Runner,用于执行 workspaces 下的各种 script,用法上和 npm 的 workspaces 类似,已经停更一段时间。
-
Preconstruct
Monorepo 下统一的 Dev/Build 工具。亮点是 dev 模式使用了执行时的 require hook,直接引用源文件在运行时执行转译(babel),不需要在开发时 watch 产物实时构建,调试很方便。用法上比较像 parcel、microbundle 那样 zero-config bundler,使用统一的 package.json 字段来指定输出产物,缺点是比较死板,整个项目的配置都得按照这种配置方式,支持的选项目前还不多,不够灵活。
-
Rushstack
体感上比较像 Lerna + Turborepo + 各种东西的工具链,比较老牌,但是没用过,也很少见到有用这个的。
-
Lage
Microsoft 出的,定位上是一个 Task Runner in JS Monorepos ,亮点是 pipeline 的任务模式,构建产物缓存,远程缓存等。
Monorepo 工具链选用
最终我们选用了 pnpm + lerna-lite + turborepo
▐ Pnpm
pnpm 的依赖全局缓存(global store and hard link)与安装方式即是天然的依赖共享,相同版本的依赖只会安装一次,有效地节约空间以及节省安装时间,在 monorepo 场景下十分切合。
▐ Lerna-lite
pnpm 推荐的方案其实是 changesets,但是 changesets 的发版流程更贴近 Github Action Workflow,以及 打 changeset 然后 version 的概念和流程相对 lerna 会复杂一些。
不直接使用 lerna 的原因是 lerna 并不支持 pnpm 的 workspace protocol 。
同时 lerna 比较久没有更新,虽然最近被 nx 的组织 nrwl 接管了,但是 nrwl 只扩展了针对 nx + lerna 场景的功能,并没有对 lerna 的其他功能进行维护,所以社区里出现了 lerna-lite,真正意义上的延续了 lerna 的发展,目前比较有用的新功能是其 publish 命令支持了 pnpm 的 workspace protocol (workspace:),支持了 pnpm workspace 下 lerna 的发布流程。
▐ Turborepo
如果有高速构建缓存需求则使用 turborepo。Turborepo 的基本原则是从不重新计算以前完成的工作,Turborepo 会记住你构建的内容并跳过已经计算过的内容,把每次构建的产物与日志缓存起来,下次构建时只有文件发生变动的部分才会重新构建,没有变动的直接命中缓存并重现日志。在多次构建开发时,这也就意味更少的构建耗时。
天猫校园 Monorepo 最佳实践
▐ 前置准备
使用 pnpm 作为包管理器,全局安装 pnpm,命令如下:
$ tnpm i -g pnpm
▐ 创建 mono 仓库
初始化该仓库为 mono 仓库
# 初始化成功
$ tree ./your-mono-project
your-mono-project
├── packages
│ ├── bundles
│ │ └── bundle-a
│ │ └── package.json
│ └── components
│ └── util-a
│ └── package.json
├── .gitignore
├── .npmrc
├── abc.json
├── lerna.json
├── package.json
├── pnpm-workspace.yaml
├── README.md
└── turbo.json项目结构介绍:
packages/..
monorepo 各个 workspaces 的目录
abc.json
云构建 builder 配置,与 def 平台相关联
lerna.json
lerna 配置,管理多个包的发布版本,变更日志生成的工具
package.json
monorepo 主目录 package 文件,
pnpm-lock.yaml,
pnpm-workspace.yaml
pnpm lockfile(执行 pnpm i 后生成),pnpm workspace 声明文件
turbo.json
Turborepo 配置,主要用于产物缓存,构建加速,构建流配置。
Turborepo 地址:https://turborepo.org/
▐ 基础 mono 配置设置
这里是使用 def 云构建 builder 配置,默认是 @ali/builder-xpos
{
"builder": "@ali/builder-xpos"
}lerna 的配置,包括 packages 的范围,publish,version 的命令配置,还有指定 npmClient 为 pnpm,这里需要使用 @lerna-lite/cli
{
"packages": [
"packages/*/*"
],
"command": {
"publish": {
"conventionalCommits": true,
},
"version": {
"conventionalCommits": true,
"syncWorkspaceLock": true
}
},
"version": "independent",
"npmClient": "pnpm"
}
配置简要说明:
packages:指定组件包所在文件夹,限定了packages的管理范围。我们这里调整为「packages/*/*」。
需要配置为二级目录。因为我们按照类型区分各种包,然后相同类型的收纳到该类型的目录下,方便研发人员阅读和理解,可以看到初始创建后,packages目录下有二级目录 bundles 和 components
version:配置组件包版本号管理方式,默认是版本号。我们这里调整为「independent」。
注意 lerna 默认使用的是集中版本,所有的package共用一个version,如果需要packages下不同的模块 使用不同的版本号,需要配置Independent模式
command:command主要是配置各种lerna指令的参数,这些命令可以通过命令行配置,也可以在配置文件中配
更多配置参考,https://github.com/lerna/lerna#lernajson
pnpm-workspace.yaml 的配置
packages:
- packages/*/*同lerna配置说明
turborepo 主要用于产物缓存,构建加速
{
"$schema": "https://turborepo.org/schema.json",
"pipeline": {
"build": {
"dependsOn": ["^build"],
"inputs": [
"src/**/*"
],
"outputs": [
"es/**",
"lib/**",
"build/**"
]
}
}
}▐ 入驻组件
- 选择需要入驻的组件
- 判断该组件属于哪个mono分类(如 bundles、components 等)
- 切换到相应的分类目录,如 /packages/components
- 入驻组件代码到该目录下
a . 通过手动复制代码,或者 git clone 方式都可以
5 . 清除入驻组件的 .git
a . 在其目录 /packages/components/your-component 下执行,rm -rf .git
b . 只保留 mono 的 git 管理能力即可(重点注意!如果没有清除,则无法被mono的gitdiff检测到)
6 . 增加/替换 入驻组件中 package.json 中 build script 为 gulp build
a . "build": "gulp build"
b . 注意同时请保证 组件的构建使用的是相同版本的 gulp,如如意pos统一使用的是 gulp@4
7 . 在 mono目录下(或者 /packages/components/your-component 目录下,或者mono中任意位置都可),执行 pnpm i
a . 执行成功后,pnpm-lock.yaml 文件有对应的更新,即入驻成功
8 . 不需要特别关注相互依赖问题
a . 入驻之后 pnpm 将会自动识别本地的 package 变动
b . 仔细查看 pnpm-lock.yaml 中,本仓库依赖的组件的版本号,会变成 link: ../xxx
▐ 本地开发关联
入驻好组件后,就可以尽情地开发编码了。
正常情况下,组件通过 npm link(tnpm link、pnpm link 相似)方式进行本地开发关联。组件体量大时,这样就非常的麻烦,因此我们升级了本地关联的方式,通过webpack alias 方式,将应用的依赖路径与本地mono仓库中的组件进行替换,然后通过选择的方式实现关联。
操作步骤:
1 . 应用中配置依赖的mono组件库(构建器中实现)
module.exports = {
'monorepo': 'xpos-ruyi-mono'
}2 . 启动本地构建
$ def dev --mono
3 . 选择需要关联的本地 mono 组件(构建器CLI自行实现即可)
4 . 启动完成,就可以开心编码了
5 . 不再需要进行手动 link 的操作
核心代码简要如下:
// relateLocalMonoLinks.js
module.exports = async function relateLocalMonoLinks(def) {
try {
const localLinks = await getAppDepsLocalMainJsPath() // 获取app中的依赖项,获取本地mono中的组件,匹配存在的组件,并将包名映射为本地组件入口文件的路径
const cacheLinks = await getCacheLinks() // 获取缓存过的关联中的本地依赖
const chosenLinks = await getChosenLinks(localLinks, cacheLinks) // 用户自行选择需要关联的本地依赖
await updateChosenLinks(chosenLinks) // 编写 local-links.js 依赖文件,供 webpack 构建时 alias 使用
} catch (e) {}
}// webpack.config.js
const baseConfig = {
resolve: {
alias: getAliasMap()
}
}
// lib/util.js
function getAliasMap() {
let aliasMap = {
'@': path.resolve(cwd, './src')
}
const pjson = require(path.resolve(cwd, 'package.json'))
Object.keys(pjson.dependencies || {})
.map(packageName => {
return {
key: packageName,
value: path.resolve(cwd, 'node_modules', packageName)
}
})
.forEach(({ key, value }) => (aliasMap[key] = value))
const isLocalDev = process.env.IS_LOCAL_DEV
if (isLocalDev) {
try {
let links = require(path.resolve(cwd, 'local-links')) || {}
aliasMap = Object.assign({}, aliasMap, links)
} catch (e) {
console.log('invalid local links')
}
}
return aliasMap
}▐ 构建 && 发布组件
1 . 如果有引入新的依赖,请先执行 pnpm i
2 . 开发完成后,正常在 mono 仓库下,进行 git 提交
3 . 通过上述工具链实现的构建器进行发布
4 . 发布成功后,会根据代码提交,进行增量改动判断,产出对应改动的组件升级包
5 . 将相应的包的版本号,配置到应用的项目中使用即可
结语
本文分析的是我们在面对天猫校园业务-如意pos,这样一个复杂应用场景下的一些项目管理模式的思考探索和落地实践,monorepo 本质上不是一种框架,而是面对一个项目发展阶段,寻求满足当下最适合自己的方案的一个解决思路策略。在探索的过程中,我们可以感悟到,选方案并不是为了追逐「潮流」,而是追逐「收益」。在不同情景下,各种方案的思想并不是完全相对独立的,相互结合往往会发挥奇效。