从Linux零拷贝深入了解Linux-I/O
本文将从文件传输场景以及零拷贝技术深究 Linux I/O 的发展过程、优化手段以及实际应用。
前言
存储器是计算机的核心部件之一,在完全理想的状态下,存储器应该要同时具备以下三种特性:
- 速度足够快:存储器的存取速度应当快于 CPU 执行一条指令,这样 CPU 的效率才不会受限于存储器;
- 容量足够大:容量能够存储计算机所需的全部数据;
- 价格足够便宜:价格低廉,所有类型的计算机都能配备。
但是现实往往是残酷的,我们目前的计算机技术无法同时满足上述的三个条件,于是现代计算机的存储器设计采用了一种分层次的结构:
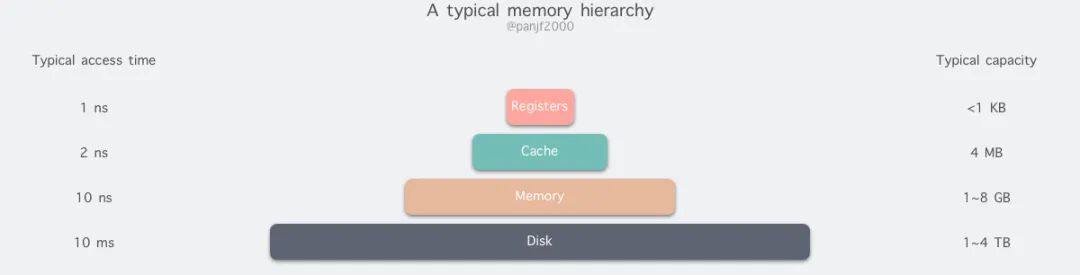
存取速度最快的是寄存器,因为寄存器的制作材料和 CPU 是相同的,所以速度和 CPU 一样快,CPU 访问寄存器是没有时延的,然而因为价格昂贵,因此容量也极小,一般 32 位的 CPU 配备的寄存器容量是 32✖️32 Bit,64 位的 CPU 则是 64✖️64 Bit,不管是 32 位还是 64 位,寄存器容量都小于 1 KB,且寄存器也必须通过软件自行管理。
第二层是高速缓存,也即我们平时了解的 CPU 高速缓存 L1、L2、L3,一般 L1 是每个 CPU 独享,L3 是全部 CPU 共享,而 L2 则根据不同的架构设计会被设计成独享或者共享两种模式之一,比如 Intel 的多核芯片采用的是共享 L2 模式而 AMD 的多核芯片则采用的是独享 L2 模式。
第三层则是主存,也即主内存,通常称作随机访问存储器(Random Access Memory, RAM)。是与 CPU 直接交换数据的内部存储器。它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时资料存储介质。
至于磁盘则是图中离用户最远的一层了,读写速度相差内存上百倍;另一方面自然针对磁盘操作的优化也非常多,如零拷贝、direct I/O、异步 I/O 等等,这些优化的目的都是为了提高系统的吞吐量;另外操作系统内核中也有磁盘高速缓存区、PageCache、TLB等,可以有效的减少磁盘的访问次数。
现实情况中,大部分系统在由小变大的过程中,最先出现瓶颈的就是I/O,尤其是在现代网络应用从 CPU 密集型转向了 I/O 密集型的大背景下,I/O越发成为大多数应用的性能瓶颈。
传统的 Linux 操作系统的标准 I/O 接口是基于数据拷贝操作的,即 I/O 操作会导致数据在操作系统内核地址空间的缓冲区和用户进程地址空间定义的缓冲区之间进行传输。设置缓冲区最大的好处是可以减少磁盘 I/O 的操作,如果所请求的数据已经存放在操作系统的高速缓冲存储器中,那么就不需要再进行实际的物理磁盘 I/O 操作;然而传统的 Linux I/O 在数据传输过程中的数据拷贝操作深度依赖 CPU,也就是说 I/O 过程需要 CPU 去执行数据拷贝的操作,因此导致了极大的系统开销,限制了操作系统有效进行数据传输操作的能力。
这篇文章就从文件传输场景以及零拷贝技术深究 Linux I/O的发展过程、优化手段以及实际应用。
需要了解的词
-
DMADMA,全称 Direct Memory Access,即直接存储器访问,是为了避免 CPU 在磁盘操作时承担过多的中断负载而设计的;在磁盘操作中,CPU 可将总线控制权交给 DMA 控制器,由 DMA 输出读写命令,直接控制 RAM 与 I/O 接口进行 DMA 传输,无需 CPU 直接控制传输,也没有中断处理方式那样保留现场和恢复现场过程,使得 CPU 的效率大大提高。
-
MMUMemory Management Unit—内存管理单元,主要实现:
-
竞争访问保护管理需求:需要严格的访问保护,动态管理哪些内存页/段或区,为哪些应用程序所用。这属于资源的竞争访问管理需求;
-
高效的翻译转换管理需求:需要实现快速高效的映射翻译转换,否则系统的运行效率将会低下;
-
高效的虚实内存交换需求:需要在实际的虚拟内存与物理内存进行内存页/段交换过程中快速高效。
-
Page Cache为了避免每次读写文件时,都需要对硬盘进行读写操作,Linux 内核使用
页缓存(Page Cache)机制来对文件中的数据进行缓存。此外,由于读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了「预读功能」。
比如,假设 read 方法每次只会读
32 KB的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32 ~ 64 KB 也读取到 PageCache,这样后面读取 32 ~ 64 KB 的成本就很低,如果在 32 ~ 64 KB 淘汰出 PageCache 前,有进程读取到它了,收益就非常大。 -
虚拟内存
在计算机领域有一句如同摩西十诫般神圣的哲言:"计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决",从内存管理、网络模型、并发调度甚至是硬件架构,都能看到这句哲言在闪烁着光芒,而虚拟内存则是这一哲言的完美实践之一。
虚拟内存为每个进程提供了一个一致的、私有且连续完整的内存空间;所有现代操作系统都使用虚拟内存,使用虚拟地址取代物理地址,主要有以下几点好处:
利用上述的第一条特性可以优化,可以把内核空间和用户空间的虚拟地址映射到同一个物理地址,这样在 I/O 操作时就不需要来回复制了。
-
多个虚拟内存可以指向同一个物理地址;
-
虚拟内存空间可以远远大于物理内存空间;
-
应用层面可管理连续的内存空间,减少出错。
-
NFS文件系统 网络文件系统是 FreeBSD 支持的文件系统中的一种,也被称为 NFS;NFS 允许一个系统在网络上与它人共享目录和文件,通过使用 NFS,用户和程序可以象访问本地文件 一样访问远端系统上的文件。
-
Copy-on-write写入时复制(Copy-on-write,COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
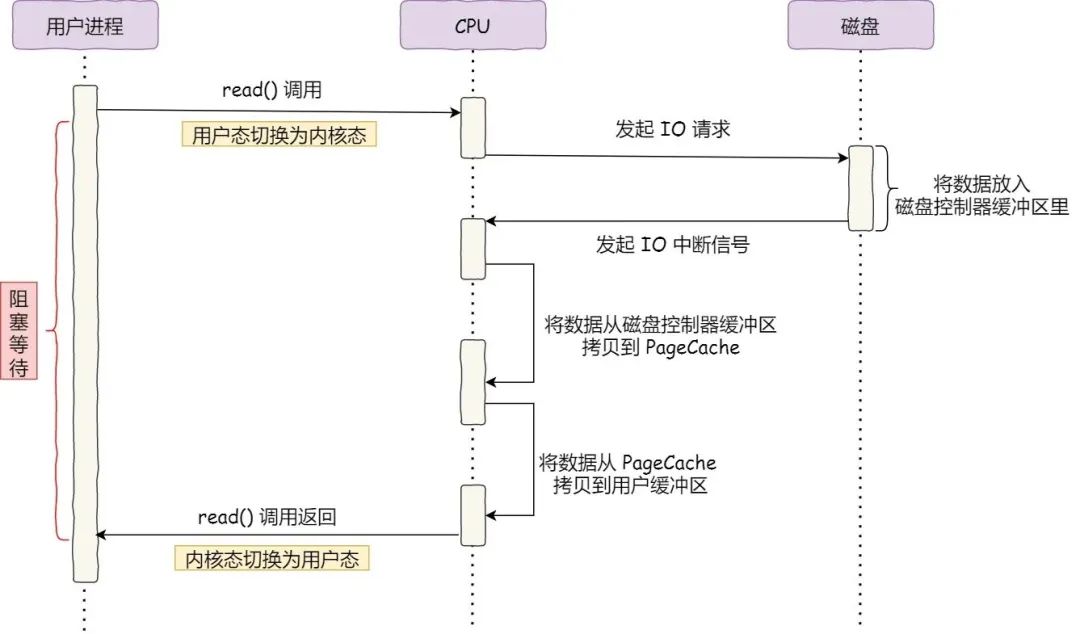
为什么要有 DMA
在没有 DMA 技术前,I/O 的过程是这样的:
- CPU 发出对应的指令给磁盘控制器,然后返回;
- 磁盘控制器收到指令后,于是就开始准备数据,会把数据放入到磁盘控制器的内部缓冲区中,然后产生一个中断;
- CPU 收到中断信号后,停下手头的工作,接着把磁盘控制器的缓冲区的数据一次一个字节地读进自己的寄存器,然后再把寄存器里的数据写入到内存,而在数据传输的期间 CPU 是被阻塞的状态,无法执行其他任务。
计算机科学家们发现了事情的严重性后,于是就发明了 DMA 技术,也就是直接内存访问(Direct Memory Access) 技术。
简单理解就是,在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务。
具体流程如下图:
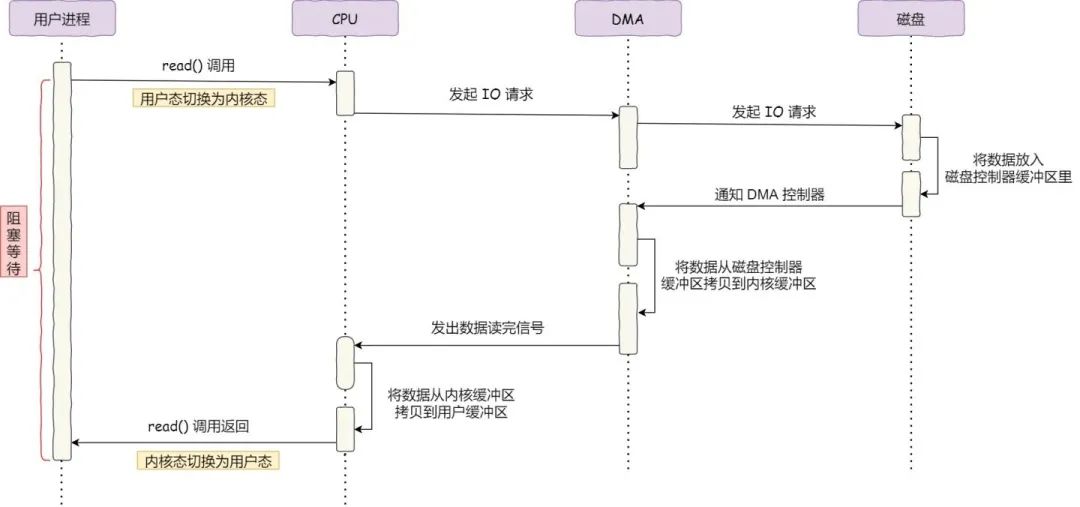
- 用户进程调用 read 方法,向操作系统发出 I/O 请求,请求读取数据到自己的内存缓冲区中,进程进入阻塞状态;
- 操作系统收到请求后,进一步将 I/O 请求发送 DMA,释放 CPU;
- DMA 进一步将 I/O 请求发送给磁盘;
- 磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满;
- DMA 收到磁盘的信号,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 依然可以执行其它事务;
- 当 DMA 读取了足够多的数据,就会发送中断信号给 CPU;
- CPU 收到 中断信号,将数据从内核拷贝到用户空间,系统调用返回。
在有了 DMA 后,整个数据传输的过程,CPU 不再参与与磁盘交互的数据搬运工作,而是全程由 DMA 完成,但是 CPU 在这个过程中也是必不可少的,因为传输什么数据,从哪里传输到哪里,都需要 CPU 来告诉 DMA 控制器。
早期 DMA 只存在在主板上,如今由于 I/O 设备越来越多,数据传输的需求也不尽相同,所以每个 I/O 设备里面都有自己的 DMA 控制器。
传统文件传输的缺陷
有了 DMA 后,我们的磁盘 I/O 就一劳永逸了吗?并不是的;拿我们比较熟悉的下载文件举例,服务端要提供此功能,比较直观的方式就是:将磁盘中的文件读出到内存,再通过网络协议发送给客户端。
具体的 I/O 工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
代码通常如下,一般会需要两个系统调用:
read(file, tmp_buf, len)
write(socket, tmp_buf, len)代码很简单,虽然就两行代码,但是这里面发生了不少的事情:
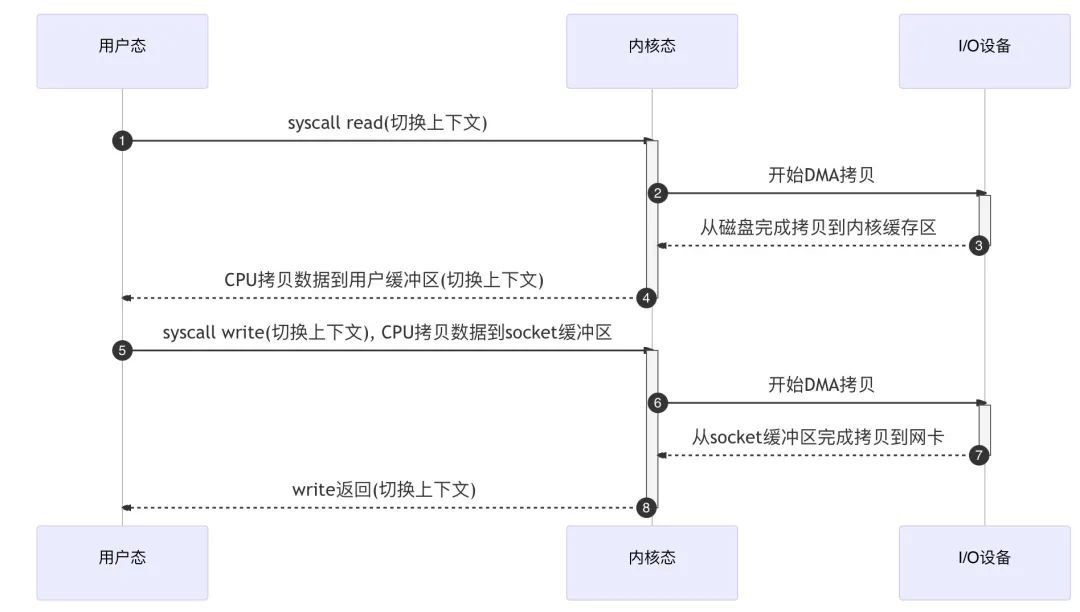
- 4 次用户态与内核态的上下文切换两次系统调用
read()和write()中,每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态;上下文切换的成本并不小,一次切换需要耗时几十纳秒到几微秒,在高并发场景下很容易成为性能瓶颈(参考线程切换和协程切换的成本差别)。 - 4 次数据拷贝两次由 DMA 完成拷贝,另外两次则是由 CPU 完成拷贝;我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 额外的资源,大大降低了系统性能。
所以,要想提高文件传输的性能,就需要减少用户态与内核态的上下文切换和内存拷贝的次数。
如何优化传统文件传输
减少「用户态与内核态的上下文切换」
读取磁盘数据的时候,之所以要发生上下文切换,这是因为用户空间没有权限操作磁盘或网卡,内核的权限最高,这些操作设备的过程都需要交由操作系统内核来完成,所以一般要通过内核去完成某些任务的时候,就需要使用操作系统提供的系统调用函数。
而一次系统调用必然会发生 2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
减少「数据拷贝」次数
前面提到,传统的文件传输方式会历经 4 次数据拷贝;但很明显的可以看到:从内核的读缓冲区拷贝到用户的缓冲区和从用户的缓冲区里拷贝到 socket 的缓冲区」这两步是没有必要的。
因为在下载文件,或者说广义的文件传输场景中,我们并不需要在用户空间对数据进行再加工,所以数据并不需要回到用户空间中。
零拷贝
那么零拷贝技术就应运而生了,它就是为了解决我们在上面提到的场景——跨过与用户态交互的过程,直接将数据从文件系统移动到网络接口而产生的技术。
零拷贝实现原理
零拷贝技术实现的方式通常有 3 种:
- mmap + write
- sendfile
- splice
mmap + write
在前面我们知道,read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了省去这一步,我们可以用 mmap() 替换 read() 系统调用函数,伪代码如下:
buf = mmap(file, len)
write(sockfd, buf, len)mmap的函数原型如下:
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
mmap() 系统调用函数会在调用进程的虚拟地址空间中创建一个新映射,直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
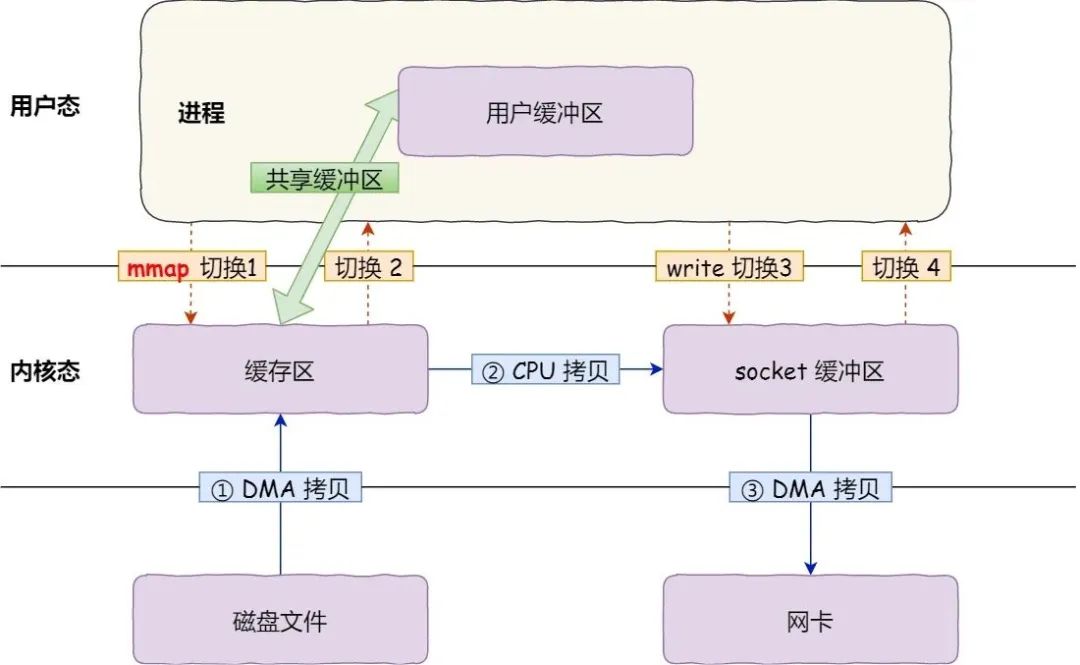
- 应用进程调用了
mmap()后,DMA 会把磁盘的数据拷贝到内核的缓冲区里,应用进程跟操作系统内核「共享」这个缓冲区; - 应用进程再调用
write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据; - 最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
我们可以看到,通过使用 mmap() 来代替 read(), 可以减少一次数据拷贝的过程。
但这还不是最理想的零拷贝,因为仍然需要通过 CPU 把内核缓冲区的数据拷贝到 socket 缓冲区里,且仍然需要 4 次上下文切换,因为系统调用还是 2 次。
sendfile
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile()如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
首先,它可以替代前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。
其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。如下图:
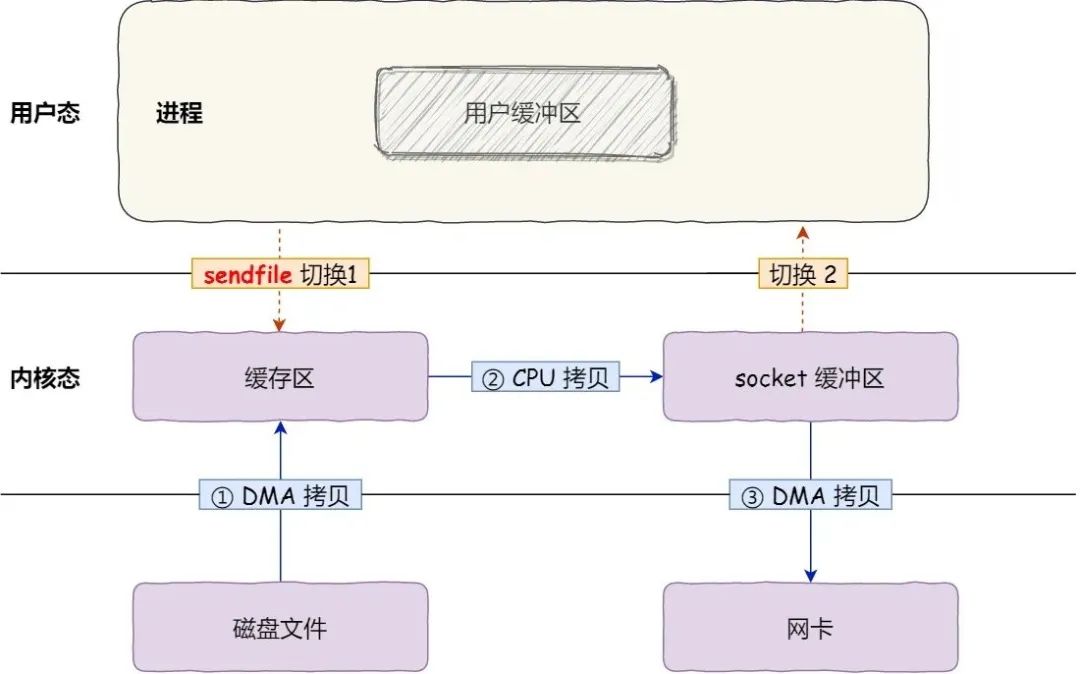
带有 scatter/gather 的 sendfile 方式
Linux 2.4 内核进行了优化,提供了带有 scatter/gather 的 sendfile 操作,这个操作可以把最后一次 CPU COPY 去除。其原理就是在内核空间 Read BUffer 和 Socket Buffer 不做数据复制,而是将 Read Buffer 的内存地址、偏移量记录到相应的 Socket Buffer 中,这样就不需要复制。其本质和虚拟内存的解决方法思路一致,就是内存地址的记录。
你可以在你的 Linux 系统通过下面这个命令,查看网卡是否支持 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
所以,这个过程之中,只进行了 2 次数据拷贝,如下图:
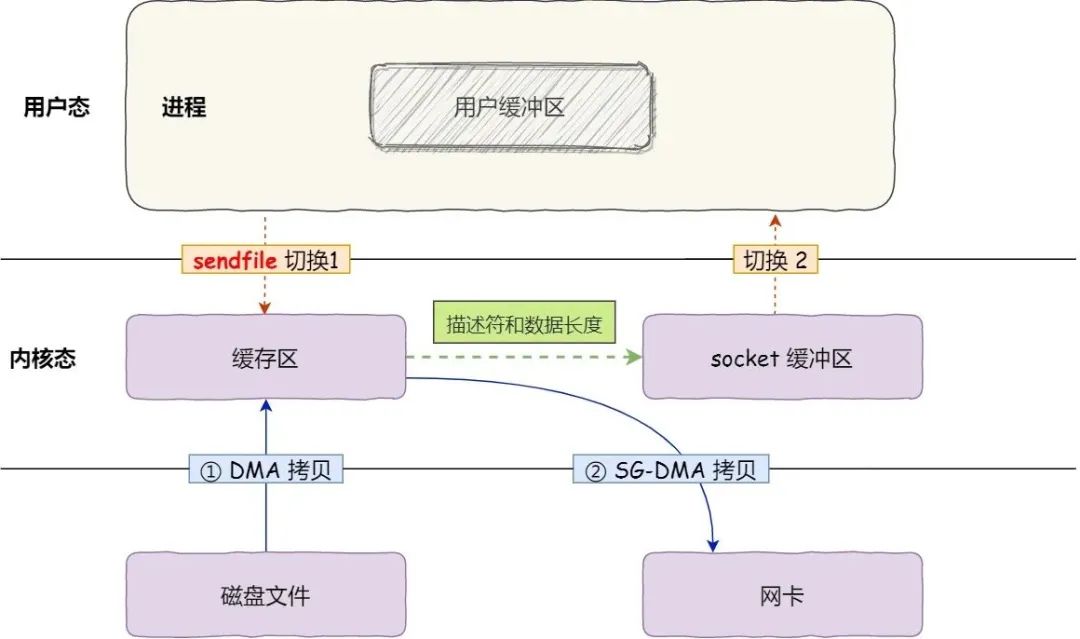
splice 方式
splice 调用和sendfile 非常相似,用户应用程序必须拥有两个已经打开的文件描述符,一个表示输入设备,一个表示输出设备。与sendfile不同的是,splice允许任意两个文件互相连接,而并不只是文件与socket进行数据传输。对于从一个文件描述符发送数据到socket这种特例来说,一直都是使用sendfile系统调用,而splice一直以来就只是一种机制,它并不仅限于sendfile的功能。也就是说 sendfile 是 splice 的一个子集。
splice() 是基于 Linux 的管道缓冲区 (pipe buffer) 机制实现的,所以splice()的两个入参文件描述符要求必须有一个是管道设备。
使用 splice() 完成一次磁盘文件到网卡的读写过程如下:
- 用户进程调用
pipe(),从用户态陷入内核态;创建匿名单向管道,pipe()返回,上下文从内核态切换回用户态; - 用户进程调用
splice(),从用户态陷入内核态; DMA控制器将数据从硬盘拷贝到内核缓冲区,从管道的写入端"拷贝"进管道,splice()返回,上下文从内核态回到用户态;- 用户进程再次调用
splice(),从用户态陷入内核态; - 内核把数据从管道的读取端拷贝到
socket缓冲区,DMA控制器将数据从socket缓冲区拷贝到网卡; splice()返回,上下文从内核态切换回用户态。
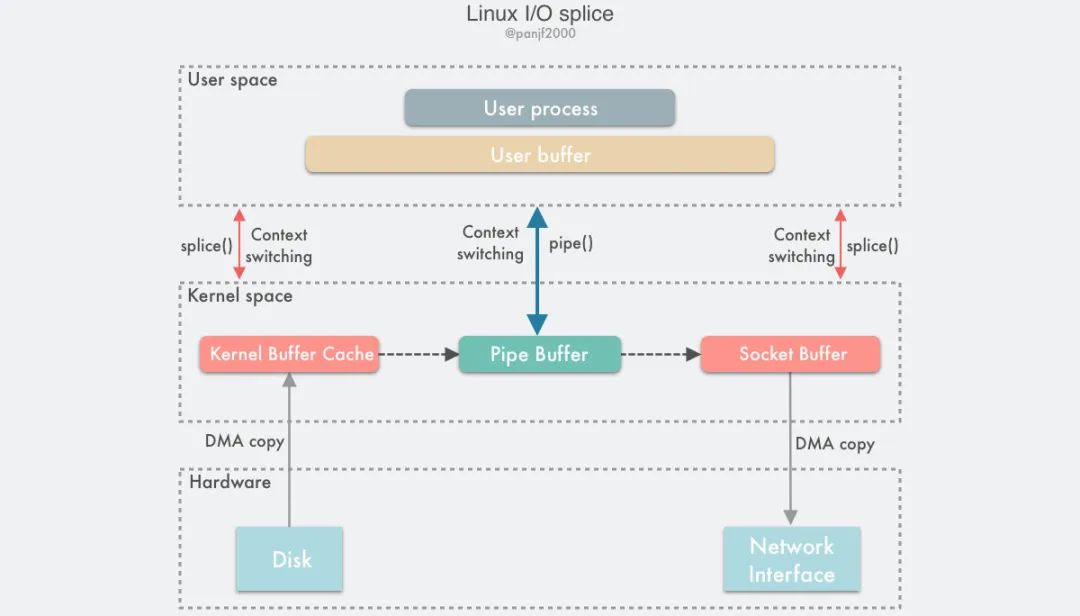
splice,而在 Linux 2.6.23 版本中, sendfile 机制的实现已经没有了,但是其 API 及相应的功能还在,只不过 API 及相应的功能是利用了 splice 机制来实现的。
和 sendfile 不同的是,splice 不需要硬件支持。
零拷贝的实际应用
Kafka
事实上,Kafka 这个开源项目,就利用了「零拷贝」技术,从而大幅提升了 I/O 的吞吐率,这也是 Kafka 在处理海量数据为什么这么快的原因之一。
如果你追溯 Kafka 文件传输的代码,你会发现,最终它调用了 Java NIO 库里的 transferTo 方法:
@Overridepublic
long transferFrom(FileChannel fileChannel, long position, long count) throws IOException {
return fileChannel.transferTo(position, count, socketChannel);
}如果 Linux 系统支持 sendfile() 系统调用,那么 transferTo() 实际上最后就会使用到 sendfile() 系统调用函数。
Nginx
Nginx 也支持零拷贝技术,一般默认是开启零拷贝技术,这样有利于提高文件传输的效率,是否开启零拷贝技术的配置如下:
http {
...
sendfile on
...
}大文件传输场景
零拷贝还是最优选吗
在大文件传输的场景下,零拷贝技术并不是最优选择;因为在零拷贝的任何一种实现中,都会有「DMA 将数据从磁盘拷贝到内核缓存区——Page Cache」这一步,但是,在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费 DMA 多做的一次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能。
这是因为在大文件传输场景下,每当用户访问这些大文件的时候,内核就会把它们载入 PageCache 中,PageCache 空间很快被这些大文件占满;且由于文件太大,可能某些部分的文件数据被再次访问的概率比较低,这样就会带来 2 个问题:
- PageCache 由于长时间被大文件占据,其他「热点」的小文件可能就无法充分使用到 PageCache,于是这样磁盘读写的性能就会下降了;
- PageCache 中的大文件数据,由于没有享受到缓存带来的好处,但却耗费 DMA 多拷贝到 PageCache 一次。
异步 I/O + direct I/O
那么大文件传输场景下我们该选择什么方案呢?让我们先来回顾一下我们在文章开头介绍 DMA 时最早提到过的同步 I/O:
I/O 来解决,即:
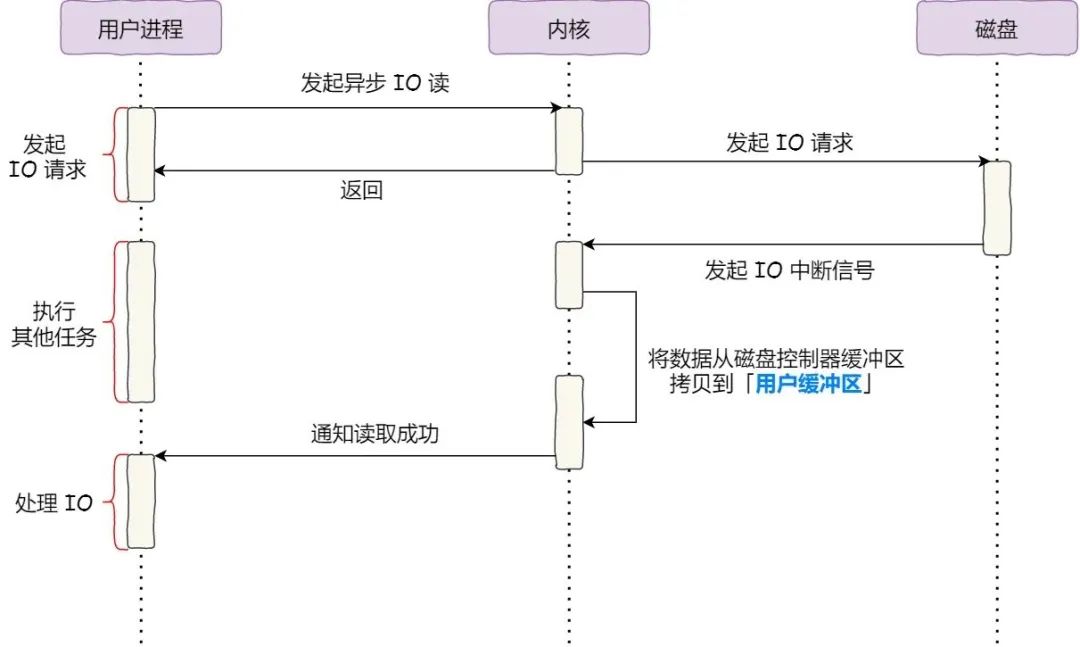
- 前半部分,内核向磁盘发起读请求,但是可以不等待数据就位就返回,于是进程此时可以处理其他任务;
- 后半部分,当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知,再去处理数据;
而且,我们可以发现,异步 I/O 并没有涉及到 PageCache;使用异步 I/O 就意味着要绕开 PageCache,因为填充 PageCache 的过程在内核中必须阻塞。
所以异步 I/O 中使用的是direct I/O(对比使用 PageCache 的buffer I/O),这样才能不阻塞进程,立即返回。
direct I/O 应用场景常见的两种:
- 应用程序已经实现了磁盘数据的缓存,那么可以不需要 PageCache 再次缓存,减少额外的性能损耗。在 MySQL 数据库中,可以通过参数设置开启
direct I/O,默认是不开启; - 传输大文件的时候,由于大文件难以命中 PageCache 缓存,而且会占满 PageCache 导致「热点」文件无法充分利用缓存,从而增大了性能开销,因此,这时应该使用`direct I/O;;
当然,由于direct I/O 绕过了 PageCache,就无法享受内核的这两点的优化:
- 内核的 I/O 调度算法会缓存尽可能多的 I/O 请求在 PageCache 中,最后「合并」成一个更大的 I/O 请求再发给磁盘,这样做是为了减少磁盘的寻址操作;
- 内核也会「预读」后续的 I/O 请求放在 PageCache 中,一样是为了减少对磁盘的操作;
实际应用中也有类似的配置,在 nginx 中,我们可以用如下配置,来根据文件的大小来使用不同的方式传输:
location /video/ {
sendfile on;
aio on;
directio 1024m;
}当文件大小大于 directio 值后,使用「异步 I/O + 直接 I/O」,否则使用「零拷贝技术」。
使用 direct I/O 需要注意的点
首先,贴一下我们的Linus(Linus Torvalds)对O_DIRECT的评价:
"The thing that has always disturbed me about O_DIRECT is that the whole interface is just stupid, and was probably designed by a deranged monkey on some serious mind-controlling substances." —Linus
一般来说能引得Linus开骂的东西,那是一定有很多坑的。
在 Linux 的man page中我们可以看到O_DIRECT下有一个 Note,还挺长的,这里我就不贴出来了。
总结一下其中需要注意的点如下:
地址对齐限制
O_DIRECT会带来强制的地址对齐限制,这个对齐的大小也跟文件系统/存储介质相关,并且当前没有不依赖文件系统自身的接口提供指定文件/文件系统是否有这些限制的信息
-
Linux 2.6 以前 总传输大小、用户的对齐缓冲区起始地址、文件偏移量必须都是逻辑文件系统的数据块大小的倍数,这里说的数据块(block)是一个逻辑概念,是文件系统捆绑一定数量的连续扇区而来,因此通常称为 “文件系统逻辑块”,可通过以下命令获取:
blockdev --getss -
Linux2.6以后对齐的基数变为物理上的存储介质的
sector size扇区大小,对应物理存储介质的最小存储粒度,可通过以下命令获取:blockdev --getpbsz
带来这个限制的原因也很简单,内存对齐这件小事通常是内核来处理的,而O_DIRECT绕过了内核空间,那么内核处理的所有事情都需要用户自己来处理,这里贴一篇详细解释。
O_DIRECT 平台不兼容
这应该是大部分跨平台应用需要注意到的点,O_DIRECT本身就是Linux中才有的东西,在语言层面 / 应用层面需要考虑这里的兼容性保证,比如在Windows下其实也有类似的机制FILE_FLAG_NO_BUFFERIN用法类似,参考微软的[官方文档] ;再比如macOS下的F_NOCACHE虽然类似O_DIRECT,但实际使用中也有差距(参考这个[issue] )。
不要并发地运行 fork 和 O_DIRECT I/O
如果O_DIRECT I/O中使用到的内存buffer是一段私有的映射(虚拟内存),如任何使用上文中提到过的mmap并以MAP_PRIVATE flag 声明的虚拟内存,那么相关的O_DIRECT I/O(不管是异步 I/O / 其它子线程中的 I/O)都必须在调用fork系统调用前执行完毕;否则会造成数据污染或产生未定义的行为(实例可参考这个[Page] )。
以下情况这个限制不存在:
- 相关的内存
buffer是使用shmat分配或是使用mmap以MAP_SHARED flag 声明的; - 相关的内存
buffer是使用madvise以MADV_DONTFORK声明的(注意这种方式下该内存buffer在子进程中不可用)。
避免对同一文件混合使用 O_DIRECT 和普通 I/O
在应用层需要避免对同一文件(尤其是对同一文件的相同偏移区间内)混合使用O_DIRECT和普通I/O;即使我们的文件系统能够帮我们处理和保证这里的一致性问题,总体来说整个I/O吞吐量也会比单独使用某一种I/O方式要小。
同样的,应用层也要避免对同一文件混合使用direct I/O和mmap。
NFS 协议下的 O_DIRECT
虽然NFS文件系统就是为了让用户像访问本地文件一样去访问网络文件,但O_DIRECT在NFS文件系统中的表现和本地文件系统不同,比较老版本的内核或是魔改过的内核可能并不支持这种组合。
这是因为在NFS协议中并不支持传递flag 参数到服务器,所以O_DIRECT I/O实际上只绕过了本地客户端的Page Cache,但服务端/同步客户端仍然会对这些I/O进行cache。
当客户端请求服务端进行I/O同步来保证O_DIRECT的同步语义时,一些服务器的性能表现不佳(尤其是当这些I/O很小时);还有一些服务器干脆设置为欺骗客户端,直接返回客户端「数据已写入存储介质」,这样就可以一定程度上避免I/O同步带来的性能损失,但另一方面,当服务端断电时就无法保证未完成I/O同步的数据的数据完整性了。
Linux的NFS客户端也没有上面说过的地址对齐的限制。
在 Golang 中使用 direct I/O
direct io 必须要满足 3 种对齐规则:io 偏移扇区对齐,长度扇区对齐,内存 buffer 地址扇区对齐;前两个还比较好满足,但是分配的内存地址仅凭原生的手段是无法直接达成的。
先对比一下 c 语言,libc 库是调用 posix_memalign 直接分配出符合要求的内存块,但Golang中要怎么实现呢?
在Golang中,io 的 buffer 其实就是字节数组,自然是用 make 来分配,如下:
buffer := make([]byte, 4096)
但buffer中的data字节数组首地址并不一定是对齐的。
方法也很简单,就是先分配一个比预期要大的内存块,然后在这个内存块里找对齐位置 ;这是一个任何语言皆通用的方法,在 Go 里也是可用的。
比如,我现在需要一个 4096 大小的内存块,要求地址按照 512 对齐,可以这样做:
- 先分配 4096 + 512 大小的内存块,假设得到的内存块首地址是 p1;
- 然后在 [ p1, p1+512 ] 这个地址范围找,一定能找到 512 对齐的地址 p2;
- 返回 p2 ,用户能正常使用 [ p2, p2 + 4096 ] 这个范围的内存块而不越界。
以上就是基本原理了,具体实现如下:
// 从 block 首地址往后找到符合 AlignSize 对齐的地址并返回
// 这里很巧妙的使用了位运算,性能upup
func alignment(block []byte, AlignSize int) int {
return int(uintptr(unsafe.Pointer(&block[0])) & uintptr(AlignSize-1))
}
// 分配 BlockSize 大小的内存块
// 地址按 AlignSize 对齐
func AlignedBlock(BlockSize int) []byte {
// 分配一个大小比实际需要的稍大
block := make([]byte, BlockSize+AlignSize)
// 计算到下一个地址对齐点的偏移量
a := alignment(block, AlignSize)
offset := 0
if a != 0 {
offset = AlignSize - a
}
// 偏移指定位置,生成一个新的 block,这个 block 就满足地址对齐了
block = block[offset : offset+BlockSize]
if BlockSize != 0 {
// 最后做一次地址对齐校验
a = alignment(block, AlignSize)
if a != 0 {
log.Fatal("Failed to align block")
}
}
return block
}所以,通过以上 AlignedBlock 函数分配出来的内存一定是 512 地址对齐的,唯一的一点点缺点就是在分配较小内存块时对齐的额外开销显得比较大。
开源实现
Github 上就有开源的Golang direct I/O实现:ncw/directio
使用也很简单:
-
O_DIRECT 模式打开文件:
// 创建句柄 fp, err := directio.OpenFile(file, os.O_RDONLY, 0666) -
读数据
// 创建地址按照 4k 对齐的内存块 buffer := directio.AlignedBlock(directio.BlockSize) // 把文件数据读到内存块中 _, err := io.ReadFull(fp, buffer)
内核缓冲区和用户缓冲区之间的传输优化
到目前为止,我们讨论的 zero-copy技术都是基于减少甚至是避免用户空间和内核空间之间的 CPU 数据拷贝的,虽然有一些技术非常高效,但是大多都有适用性很窄的问题,比如 sendfile()、splice() 这些,效率很高,但是都只适用于那些用户进程不需要再处理数据的场景,比如静态文件服务器或者是直接转发数据的代理服务器。
前面提到过的虚拟内存机制和mmap等都表明,通过在不同的虚拟地址上重新映射页面可以实现在用户进程和内核之间虚拟复制和共享内存;因此如果要在实现在用户进程内处理数据(这种场景比直接转发数据更加常见)之后再发送出去的话,用户空间和内核空间的数据传输就是不可避免的,既然避无可避,那就只能选择优化了。
两种优化用户空间和内核空间数据传输的技术:
- 动态重映射与写时拷贝 (
Copy-on-Write) - 缓冲区共享 (
Buffer Sharing)
写时拷贝 (Copy-on-Write)
前面提到过过利用内存映射(mmap)来减少数据在用户空间和内核空间之间的复制,通常用户进程是对共享的缓冲区进行同步阻塞读写的,这样不会有线程安全问题,但是很明显这种模式下效率并不高,而提升效率的一种方法就是异步地对共享缓冲区进行读写,而这样的话就必须引入保护机制来避免数据冲突问题,COW (Copy on Write) 就是这样的一种技术。
COW 是一种建立在虚拟内存重映射技术之上的技术,因此它需要 MMU 的硬件支持,MMU 会记录当前哪些内存页被标记成只读,当有进程尝试往这些内存页中写数据的时候,MMU 就会抛一个异常给操作系统内核,内核处理该异常时为该进程分配一份物理内存并复制数据到此内存地址,重新向 MMU 发出执行该进程的写操作。
下图为COW在Linux中的应用之一: fork / clone,fork出的子进程共享父进程的物理空间,当父子进程有内存写入操作时,read-only内存页发生中断,将触发的异常的内存页复制一份(其余的页还是共享父进程的)。

局限性
COW 这种零拷贝技术比较适用于那种多读少写从而使得 COW 事件发生较少的场景,而在其它场景下反而可能造成负优化,因为 COW事件所带来的系统开销要远远高于一次 CPU 拷贝所产生的。
此外,在实际应用的过程中,为了避免频繁的内存映射,可以重复使用同一段内存缓冲区,因此,你不需要在只用过一次共享缓冲区之后就解除掉内存页的映射关系,而是重复循环使用,从而提升性能。
但这种内存页映射的持久化并不会减少由于页表往返移动/换页和 TLB flush所带来的系统开销,因为每次接收到 COW 事件之后对内存页而进行加锁或者解锁的时候,内存页的只读标志 (read-ony) 都要被更改为 (write-only)。
COW 的实际应用
Redis 的持久化机制
Redis 作为典型的内存型应用,一定是有内核缓冲区和用户缓冲区之间的传输优化的。
Redis 的持久化机制中,如果采用 bgsave 或者 bgrewriteaof 命令,那么会 fork 一个子进程来将数据存到磁盘中;总体来说Redis 的读操作是比写操作多的(在正确的使用场景下),因此这种情况下使用 COW 可以减少 fork() 操作的阻塞时间。
语言层面的应用
写时复制的思想在很多语言中也有应用,相比于传统的深层复制,能带来很大性能提升;比如 C++ 98 标准下的 std::string 就采用了写时复制的实现:
std::string x("Hello");
std::string y = x; // x、y 共享相同的 buffer
y += ", World!"; // 写时复制,此时 y 使用一个新的 buffer
// x 依然使用旧的 bufferGolang中的string, slice也使用了类似的思想,在复制 / 切片等操作时都不会改变底层数组的指向,变量共享同一个底层数组,仅当进行append / 修改等操作时才可能进行真正的copy(append时如果超过了当前切片的容量,就需要分配新的内存)。
缓冲区共享 (Buffer Sharing)
从前面的介绍可以看出,传统的 Linux I/O接口,都是基于复制/拷贝的:数据需要在操作系统内核空间和用户空间的缓冲区之间进行拷贝。在进行 I/O 操作之前,用户进程需要预先分配好一个内存缓冲区,使用 read() 系统调用时,内核会将从存储器或者网卡等设备读入的数据拷贝到这个用户缓冲区里;而使用 write() 系统调用时,则是把用户内存缓冲区的数据拷贝至内核缓冲区。
为了实现这种传统的 I/O 模式,Linux 必须要在每一个 I/O 操作时都进行内存虚拟映射和解除。这种内存页重映射的机制的效率严重受限于缓存体系结构、MMU 地址转换速度和 TLB 命中率。如果能够避免处理 I/O 请求的虚拟地址转换和 TLB 刷新所带来的开销,则有可能极大地提升 I/O 性能。而缓冲区共享就是用来解决上述问题的一种技术(说实话我觉得有些套娃的味道了)。
操作系统内核开发者们实现了一种叫 fbufs 的缓冲区共享的框架,也即快速缓冲区( Fast Buffers ),使用一个 fbuf 缓冲区作为数据传输的最小单位,使用这种技术需要调用新的操作系统 API,用户区和内核区、内核区之间的数据都必须严格地在 fbufs 这个体系下进行通信。fbufs 为每一个用户进程分配一个 buffer pool,里面会储存预分配 (也可以使用的时候再分配) 好的 buffers,这些 buffers 会被同时映射到用户内存空间和内核内存空间。fbufs 只需通过一次虚拟内存映射操作即可创建缓冲区,有效地消除那些由存储一致性维护所引发的大多数性能损耗。
共享缓冲区技术的实现需要依赖于用户进程、操作系统内核、以及 I/O 子系统 (设备驱动程序,文件系统等)之间协同工作。比如,设计得不好的用户进程容易就会修改已经发送出去的 fbuf 从而污染数据,更要命的是这种问题很难 debug。虽然这个技术的设计方案非常精彩,但是它的门槛和限制却不比前面介绍的其他技术少:首先会对操作系统 API 造成变动,需要使用新的一些 API 调用,其次还需要设备驱动程序配合改动,还有由于是内存共享,内核需要很小心谨慎地实现对这部分共享的内存进行数据保护和同步的机制,而这种并发的同步机制是非常容易出 bug 的从而又增加了内核的代码复杂度,等等。因此这一类的技术还远远没有到发展成熟和广泛应用的阶段,目前大多数的实现都还处于实验阶段。
总结
从早期的I/O到DMA,解决了阻塞CPU的问题;而为了省去I/O过程中不必要的上下文切换和数据拷贝过程,零拷贝技术就出现了。
所谓的零拷贝(Zero-copy)技术,就是完完全全不需要在内存层面拷贝数据,省去CPU搬运数据的过程。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
总体来看,零拷贝技术至少可以把文件传输的性能提高一倍以上,以下是各方案详细的成本对比:
| CPU 拷贝 | DMA 拷贝 | 系统调用 | 上下文切换 | 硬件依赖 | 支持任意类型输入/输出描述符 | |
|---|---|---|---|---|---|---|
| 传统方法 | 2 | 2 | read/write | 4 | 否 | 是 |
| 内存映射 | 1 | 2 | mmap/write | 4 | 否 | 是 |
| sendfile | 1 | 2 | sendfile | 2 | 否 | 否 |
| sendfile(scatter/gather copy) | 0 | 2 | sendfile | 2 | 是 | 否 |
| splice | 0 | 2 | splice | 2 | 否 | 是 |
零拷贝技术是基于 PageCache 的,PageCache 会缓存最近访问的数据,提升了访问缓存数据的性能,同时,为了解决机械硬盘寻址慢的问题,它还协助 I/O 调度算法实现了 I/O 合并与预读,这也是顺序读比随机读性能好的原因之一;这些优势,进一步提升了零拷贝的性能。
但当面对大文件传输时,不能使用零拷贝,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache的问题,并且大文件的缓存命中率不高,这时就需要使用「异步 I/O + direct I/O 」的方式;在使用direct I/O时也需要注意许多的坑点,毕竟连Linus也会被 O_DIRECT 'disturbed' 到。
而在更广泛的场景下,我们还需要注意到内核缓冲区和用户缓冲区之间的传输优化,这种方式侧重于在用户进程的缓冲区和操作系统的页缓存之间的 CPU 拷贝的优化,延续了以往那种传统的通信方式,但更灵活。
I/O相关的各类优化自然也已经深入到了日常我们接触到的语言、中间件以及数据库的方方面面,通过了解和学习这些技术和思想,也能对日后自己的程序设计以及性能优化上有所启发。