揭秘 OpenTelemetry-Collector 源码内幕
signoz 是一个开源的 APM 产品,希望从开源的角度来取代 datadog 目前在监控领域的地位,它的上报接入层是基于 OpenTelemetry 的接入层进行二次构建的,本篇文章是我学习 signoz 上报接入层的学习心得。
OpenTelemetry 提供了 API,SDK 和一系列工具对监控领域 Metrics,Log,Trace 三驾马车进行标准化,非常值得我们学习。
那让我们直入正题,以下内容并非对于 OpenTelemetry-Collector 源码的逐行解析,而是笔者读过源码后挑选了一些比较有意思值得学习的点进行讲述:
Command as EntryPoint
OpenTelemetry Collector 严格来说,它是一个专门处理遥测数据的框架,因为用户上报的环境在实际情况下会非常复杂多变,因此 OpenTelemetry Collector 允许自己编写对应的插件组件,并配置到服务框架中去。
但是区别于常见的服务框架,OpenTelemetry Collector 暴露出来的并不是一个可继承的服务实例,而是一个命令实例:

可以看到拓展代码里面,是通过 newCommand 来新建一个服务,然后执行 Execute 方式启动服务。这种形式还是比较少见的,OpeanTelemetry-Collector 是出于什么考量使用这种方式呢?
个人思考是与 Collector 的使用方式有关,Collector 支持多种使用方式,分别是使用 Agent 方式部署,gateway 方式部署,或者两者结合的方式。
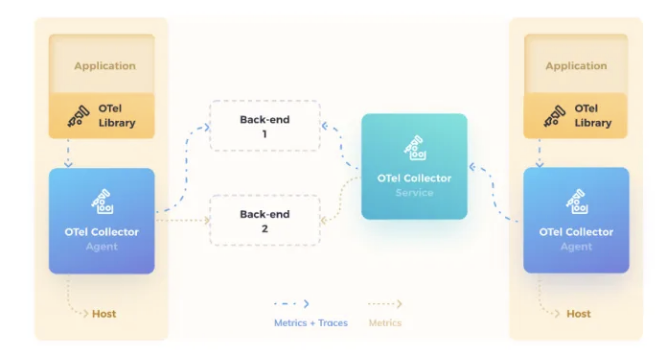
基础监控产品一般都需要 agent 来安装到用户的机器或者使用 sidecar 的方式就近部署,以获取到用户的机器指标,collector 也是考虑到这种方式,提供了多种部署方式。个人理解为了统一两种方式的使用直觉,所以 collector 采取了暴露 Command 的方式,这样会更加语义。
此外 collector 的启动参数是通过命令行的 Flag 值传入的,设计为 Command 进行暴露更加符合使用直觉,减轻用户的心智负担。

配置中心插件化
Collector 在设计实现上,也有很多地方值得我们借鉴学习,比如配置中心的实现。
其实不仅 collector,我们平时开发服务的时候,也需要设计属于自己服务的配置中心,而一个好用的配置中心需要符合拓展性强这个特性以应对不同的配置存放点与部署环境:
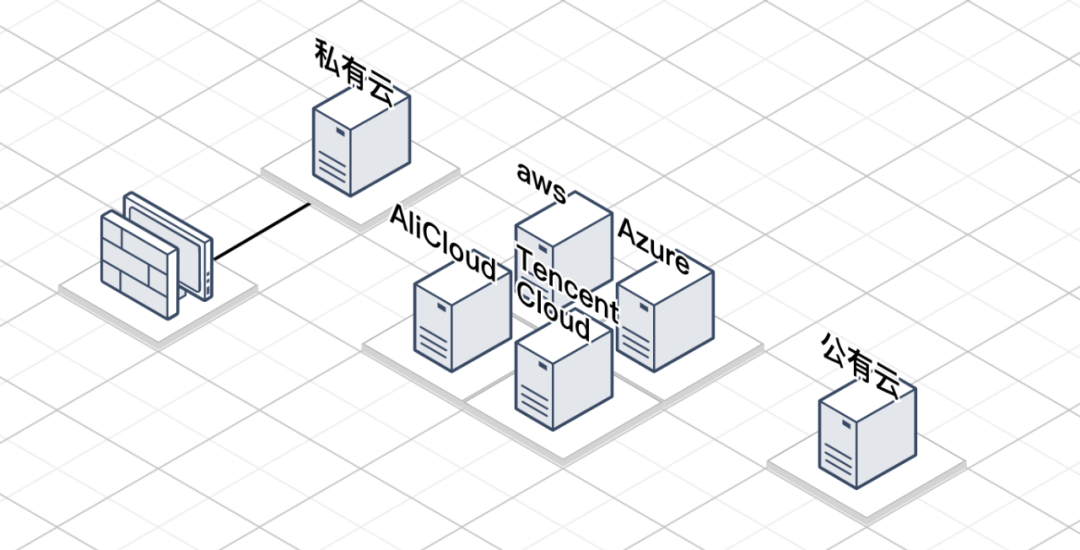
特别是监控领域,用户的述求是多样的,可能需要部署在公有云,可能需要部署在私有云,甚至部署多云架构,此时如果作为一个上报接入点没有支持多种方式拉取自有配置(比如同时支持从本地磁盘读取和远程 HTTP 协议拉取等方式),那么可能会无法启动 agent 监控到某些云上资源。
此外,配置文件本身语法对于 Collector 来说是特别重要的,Collector 是希望做成一个通用的数据上报处理层,因此设计了三类组件,分别是 Receiver, Processor, Exporter:
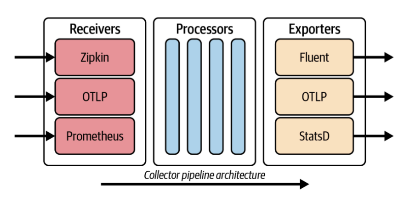
Receiver 负责接收数据,Processor 负责清洗数据,Exporter 负责导出数据,三类组件通过 Pipeline 暴露为一个服务,Collector 为了保证逻辑的通用性,基于 YAML 语法设计了一个内部 DSL 语法,通过配置将各类组件任意组合。
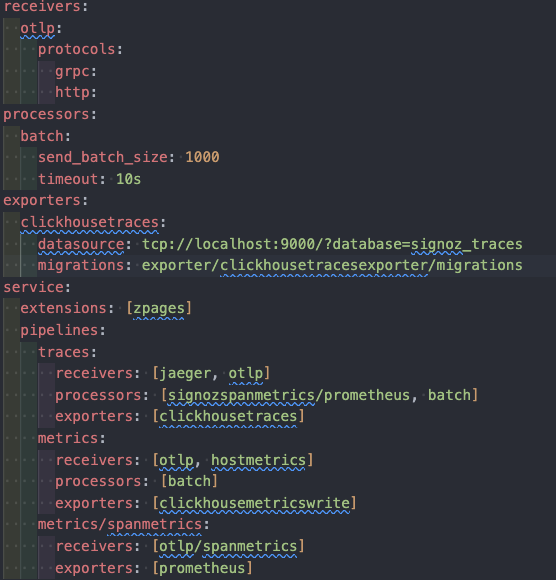
因此配置中心插件化的必要性在混云部署场景与组件通用性高两个要求下凸显得尤为明显。
配置中心插件化实现
实现一个足够好用的插件化的配置中心,往往需要考虑足够多的因素,下面我挑选了 Collector 在配置中心中一些比较好的实践来讲解:
URI 设计
首先第一步,配置中心的插件化需要优先考虑多种加载情况,比如从磁盘加载,或者从远端的 HTTP 接口拉取配置,那从哪里拉取,本质上就是对于某份资源的定位描述,也就是我们常说的 URI,那么我们在实现一个插件化的配置中心的时候,需不需要统一这个 URI 的形式呢?
我认为是必要的,假设每一份配置的 URI 描述没有统一规范与配置,而是交由每个插件自治的话,有两个缺点:
1 . 配置的加载地址不够明显,上层用户很难看出配置文件是从什么地方通过什么形式加载进来的。
这里参考一下之前司内微服务框架源码框架 CR 的经验,作为一个配置中心,不应该有包级别的配置文件路径引用的形式,因为这样意味着用户查看配置来源是比较困难的,应当将配置权完全交给用户来决定。
2 . 不能通过一个方便的方式来修改某个配置插件的加载路径。
因为一旦插件自治,引用路径的形式和位置就会不受控制,这样没有办法通过统一的位置来修改配置引用来源。
Collector 在配置中心的设计上,遵循了 uri 规范,是类似下面的形式:
形如: file:/path/to/file?fileETag&fileExt=conf
file 为协议名 /path/to/file?fileETag&fileExt=conf 是传递到插件内的参数,插件自由使用
也就是 : 之前的是协议类型名,在配置中心也就是 Provider 插件的名字,通过 uri 的形式,统一了配置文件资源标志,也给配置插件提供了自由传参的能力。
Provider
上面提到的 Provider,就是配置中心加载能力的插件。Collector 已经内置实现了 file 类型的 Provider,可以从磁盘或其他文件系统中读取配置。而所有的 Provider 只需要实现几个规定的方法即可:
type Provider interface { Retrieve(ctx context.Context, uri string, watcher WatcherFunc) (Retrieved, error) Scheme() string Shutdown(ctx context.Context) error }
其中 Scheme 方法是返回 provider 的名字,这个名字也就是配置加载 uri 的协议名,比如 FileProvider 返回的就是 file,配置中心模块会根据返回的协议名将所有 provider 存放在一个 Map 结构里面,然后遍历传入的 uri 数组,取到对应的 scheme 名,根据 scheme 名加载对应 provider 的 Retrieve 方法。
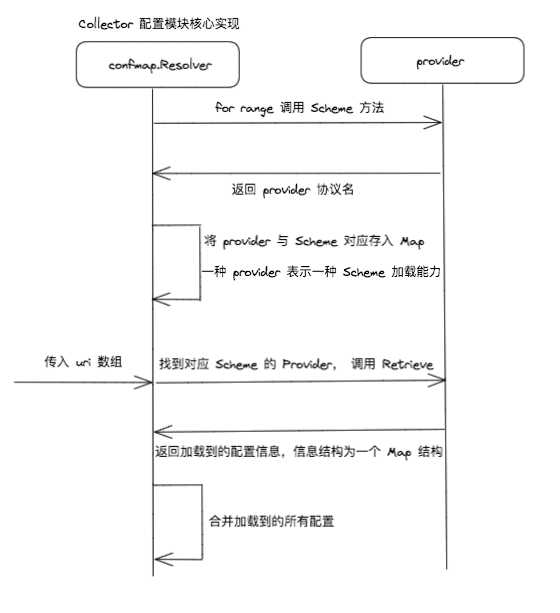
最终会将所有加载到的数据放在内存的一个 Map 中存放。
Converter
当然,配置加载完可能需要对一些配置字段进行一些动态处理或者特殊处理,配置模块提供了一个 Converter 的概念,会在所有 provider 加载完配置之后执行:
type Converter interface { Convert(ctx context.Context, conf *Conf) error }
配置热更新
配置热更新是一个非常必要的功能,因为配置文件的更改不应该引起服务的重启,因为配置文件的变更可能是非常频繁的,如果服务频繁重启可能会使得上报不稳定,因此,Collector 在设计配置模块的时候,设计了一个基于信道的事件通知机制:
func (cm *configProvider) Watch() <-chan error { return cm.mapResolver.Watch() }
服务会监听这个信道,如果监听到有变更事件,那么就会直接再次执行上面 provider 获取配置的逻辑。其他语言比如在 Node.js 环境中可以直接使用事件回调的方式来实现类似的热更新机制。
有细心的同学可能会发现,这里会有一个问题,即任何一个 provider 触发这个变更事件都会使得配置模块将所有的 provider 加载过程再执行一遍,为什么 collector 做这个设计?
个人觉得这是因为所有的 provider 加载的配置是拍平(flatten)之后存放在一起的一份配置,collector 不想做且也没必要做过于复杂的 diff 机制,所以直接所有 provider 执行一次加载机制即可。
但需要提醒的是,一旦配置错误,可能会因此服务挂掉并重启。个人认为这里 Collector 的配置容忍度做得不是特别好,因为热更新配置错误就导致现有的服务挂掉,并不是一个高可用的方案,特别是在监控业务,做好自监控和警告或错误级别日志输出可能会是一个更好的选择。
防御性编程
以上就是对于 Collector 配置中心的插件化实现的介绍,除此之外笔者在阅读的过程中发现配置模块一个比较好的编程实现,就是配置中心会将传入的参数重新复制一遍:
urisCopy := make([]string, len(set.URIs)) copy(urisCopy, set.URIs) providersCopy := make(map[string]Provider, len(set.Providers)) for k, v := range set.Providers { providersCopy[k] = v } convertersCopy := make([]Converter, len(set.Converters)) copy(convertersCopy, set.Converters)
这是一个很好的实践,这样能有效防止外部的代码对于传入的参数进行动态修改而导致代码发生一些不可预测的错误,是代码安全性的一种表现。
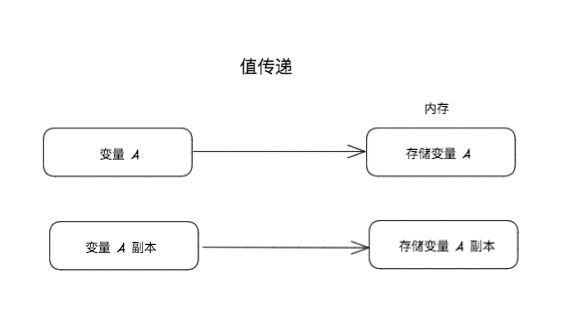
不过在实践之前,需要先对自己使用的语言特性进行了解,参数的传递是值传递还是引用传递,比如 Go 里面对于参数传递都是值传递,JS 里面 Array,Function, Object 这些是引用传递:
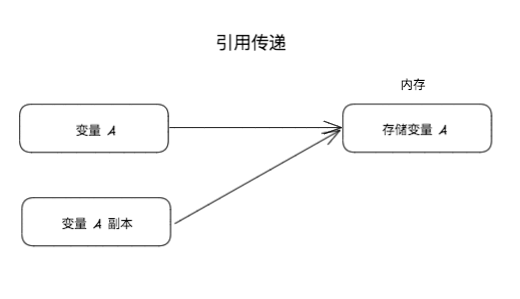
插件化总结
如果大家在业务代码中实现自己的插件化机制,按照上面 Collector 的启示总结有三点:
- 程序的主体(加载机制与热更新机制)
- 插件的接口声明
- 插件的实现
Pipeline 实现
在构建完 collector 的配置语言之后,其实 Collector 的数据处理能力就上了一个台阶,因为可以通过配置化实现任意组合,而这里说的组合其实就是 Pipeline 实现。
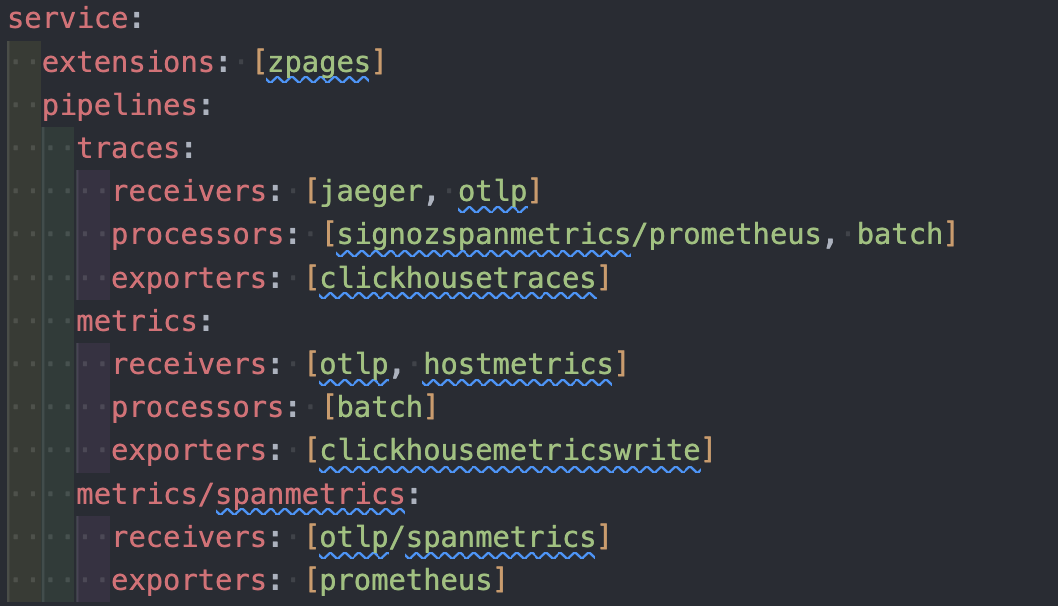
pipeline 是分为三类的,traces,metrics,log,每一类 pipeline 都需要配置三类组件,分别是 Receiver,Processor,Exporter。
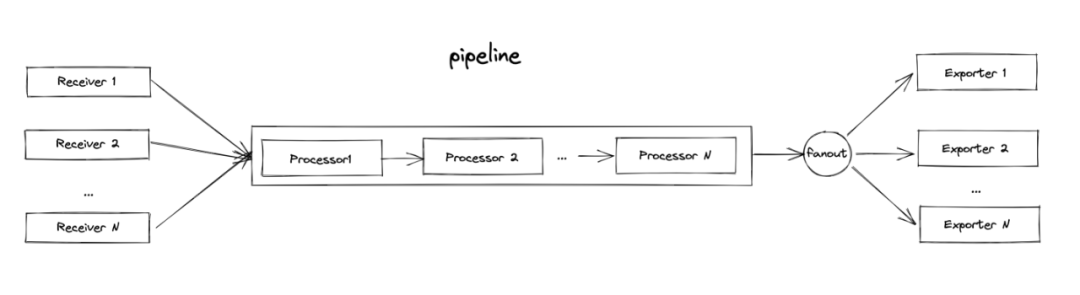
上报数据的处理流程如上图所示,一个 Receiver 代表着暴露出的一种协议(或一种接口格式),Collector 支持同时接受多种协议,然后底层转化为 opentelemetry 协议格式,然后就可以统一做数据处理。
pipeline 的责任链模型与协议统一
那么实际上 pipeline 是通过什么方式将三类组件串联起来的呢?答案是使用责任链模型。
我们先来看一下,collector 是怎么将多个 processor 串联起来的:
for i := len(pipeline.Processors) - 1; i >= 0; i-- { procID := pipeline.Processors[i]
proc, err :\= buildProcessor(ctx, set.Telemetry, set.BuildInfo, set.ProcessorConfigs, set.ProcessorFactories, procID, pipelineID, bp.lastConsumer)
if err != nil {
return nil, err
}
bp.processors\[i\] \= builtComponent{id: procID, comp: proc}
bp.lastConsumer \= proc.(baseConsumer)
mutatesConsumedData \= mutatesConsumedData || bp.lastConsumer.Capabilities().MutatesData}
有些同学看到这段代码,也许会有一种熟悉的感觉,这段代码实现上和 node 框架 koa1 的中间件实现基本一模一样,在 node 还没有 async/await 这两个语法糖的时候,是使用生成器语法来实现异步流程控制的,生成器需要先执行一次生成器函数返回一个生成器对象,而基于生成器的中间件语法,为了能够实现按照数组先后顺序执行代码逻辑,也是需要从后往前去构建一遍中间件模型:
function compose(middleware){
return function *(next){ // 解释一下传入的 next, 这个传入的 next 函数是在所有中间件执行后的"最后"一个函数, 这里的"最后"并不是真正的最后, // 而是像上面那个图中的圆心, 执行完圆心之后, 会返回去执行上一个中间件函数(middleware[length - 1])剩下的逻辑 // 简称圆心函数 // 如果没有传入那就就赋值为一个空函数 if (!next) next = noop();
var i \= middleware.length;
// 从后往前加载中间件
while (i\--) {
// 将后面一个函数传给前面的函数作为 next 函数, 前面函数中的 next 参数其实就是下一个中间件函数
next \= middleware\[i\].call(this, next);
// 这里可以知道 next 函数都是 generator 函数
console.log('isGenerator:', (typeof next.next \=== 'function' && typeof next.throw \=== 'function')); // true
}
// 使用 yield 委托执行生成器函数
return yield \*next;} }
function *noop(){}
两者最终都是生成一个函数,执行这个函数就会自动执行构建的顺序任务流程。
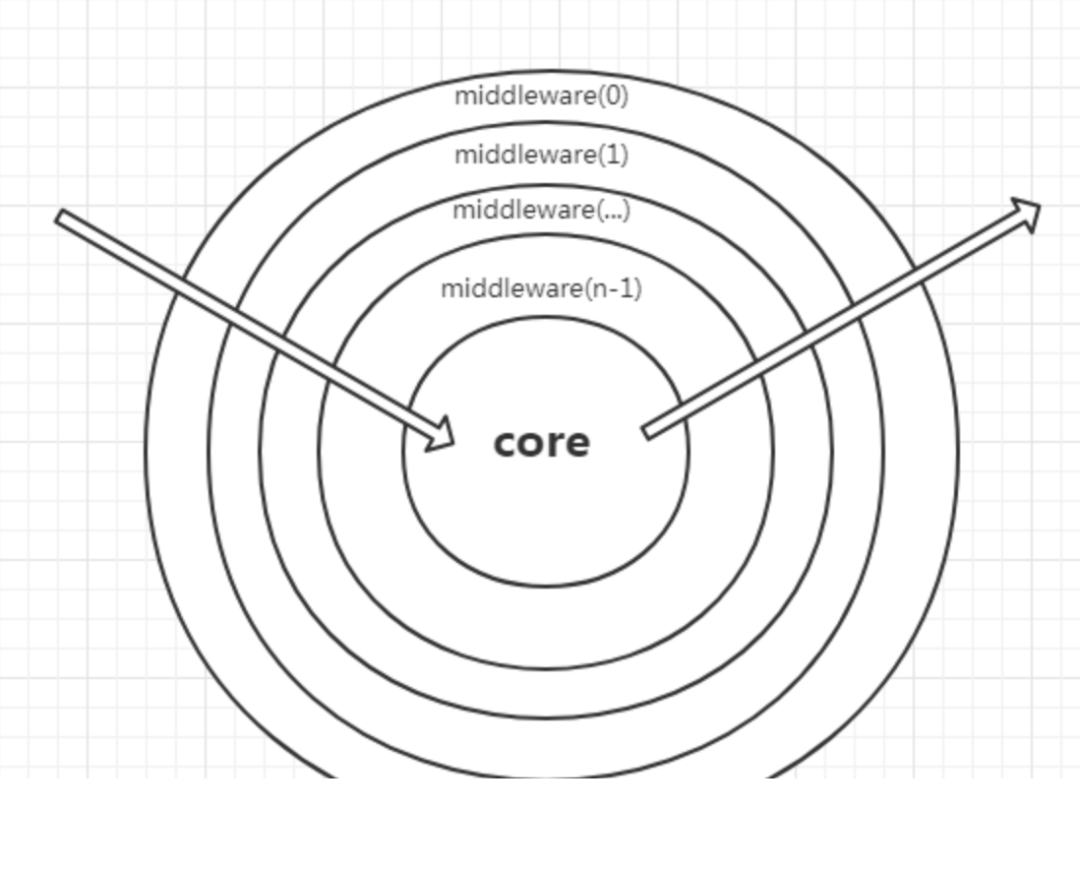
然后 Exporter 会将所有的 exporter 放在一个数组中,构建出一个 fanout 函数,这个 fanout 函数也是责任链模型的最后一环,可以理解为 fanout 函数也是一种中间件函数:
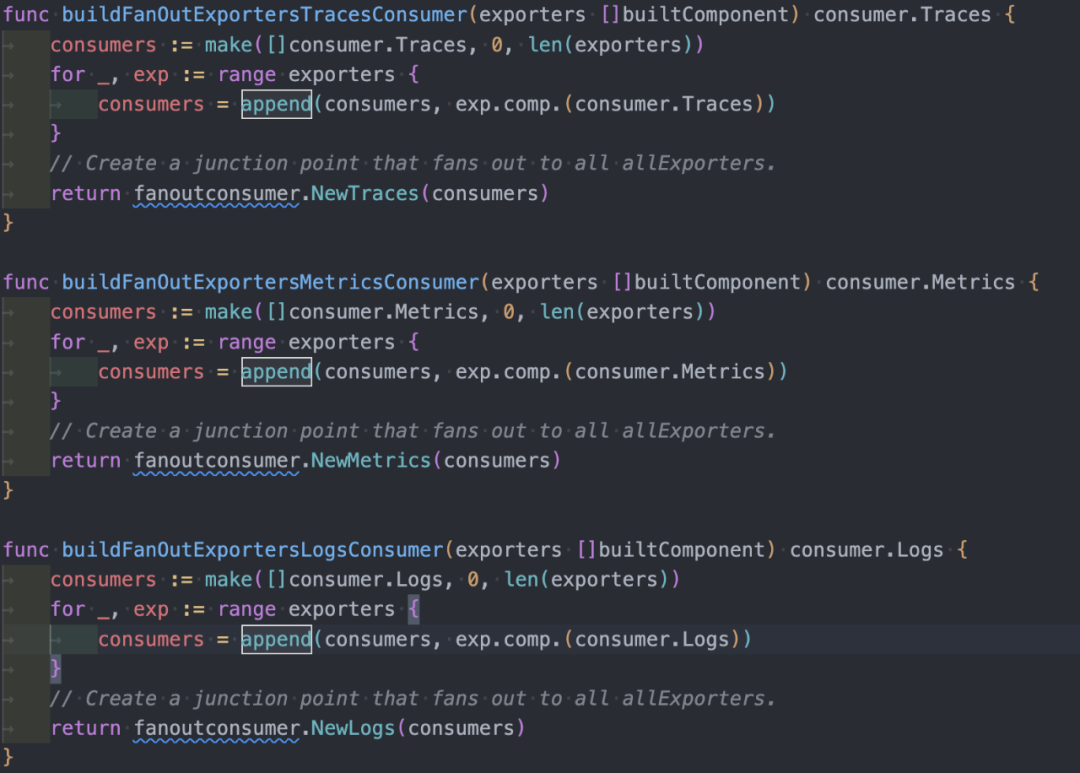
这里我提出一个小意见,exporter 的执行完成可以改造成异步执行的形式,collector 目前是使用的是顺序执行的逻辑,多个 exporter 可能会出现相互阻塞的情况。
当然责任链模型构建的前提需要先统一内部传递的数据格式,因为 opentelemtry 本身就需要规范上报格式,所以 pipeline 内部处理的格式都需要转化成 pdata 对应的数据格式。
pipeline 与 extension
有些同学可能会注意到,service 配置里面,除了 pipeline 以外,还有一个 extension 组件,extension 的作用是什么?
监控上报服务除了数据处理之外,其他的功能都交由 extension 来实现,比如 pprof 和 health_check 等等。
pipeline 和 extension 两类组件组成了 collector 上报服务的插件化机制,这里我提出一个个人小小的见解,在设计框架时,尽量不要使用中间件形式的插件提供给第三方,因为中间件函数过多会影响接口请求时延和复杂度,如果以中间件的形式暴露,最好是通过可配置化的形式,让用户可选地去执行一些中间件函数,collector 这里的实践我觉得是比较值得借鉴的。
featuregate 与特性生命周期
什么是 featuregate ?实际上这是 kubernetes 里面的一个概念,也就是特性门控,通过服务启动时传入的 Flag 值,控制是否启动服务中的某一些特性。
相信大家平时在写代码的时候肯定会遇到需要更换底层实现或者新增特性的情况,如果在服务代码里面,每个人都有一个自己的判断方式,比如 A 同学使用某一个变量来判断,B 同学使用配置来判断,那么代码会越来越不可控,且不具有可维护性,因此所谓的特性门控就是为了统一这里的判断逻辑。
实现上非常简单,就是将取到的 Flag 数组,加载到 featuregate 内存的 Map 结构中:
--feature-gates=gate1,-gate2,+gate3
这里意思是开启 gate1, gate3 功能,关闭 gate2 功能
那为什么 featuregate 需要使用 Flag 值来实现传递参数而不是使用配置文件?或者说为什么需要一个 featuregate 而不是直接使用配置文件呢?
原因有两点:
- 配置文件是需要解析的,featuregate 更有利于实现拓展能力
- 有些特性在实现上比较依赖于服务的生命周期,如果能在配置文件解析之前,会有更大的自由性。
featuregate 实现接口上也比较简单:
type Gate struct { ID string Description string Enabled bool }
type FeatureGateRegistry interface { Apply(cfg map[string]bool) IsEnbaled(id string) bool Register(g Gate) error List() []Gate }
实际代码中判断使用 IsEnabled 即可判断是否开启某个特性。
此外,还规范了特性的生命周期,这里的特性生命周期和 kubernets 是保持一致的,分为 Alpha,Beat,GA:
- Alpha 阶段,默认禁用,短期测试用,可能会导致错误
- Beta 阶段,默认启用,已经过良好测试,是一个安全的特性
- GA - General Availability 也就是稳定特性,表示一直启用且不能禁用。
个人觉得这是一个很好的编程实践,添加的特性代码如果能够跟随着这样的生命周期管理,那么整体代码肯定会更加可控,并且出现问题的时候能更快地定位到对应的问题。
削峰与重试
作为一个监控上报的 gateway,可能会瞬时接收到大量业务方上报的数据,可能会上报大量的监控数据,这个上报的监控数据会对监控服务本身以及下游造成巨大的压力,因此上报服务层本身需要做一些策略来保护自身服务的可用性。
那面对流量激增,第一反应就是削峰填谷,但是 collector 本身作为一个通用框架,并且本身既作为 agent 又作为网关的方案,预置的实现是不会实现过重的策略。
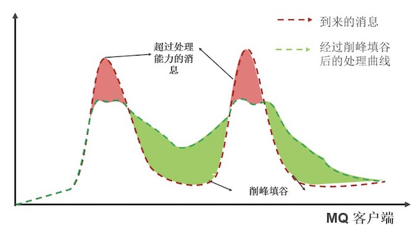
内存批处理队列
因此 Collector 会在内存里面做一个比较简单的批处理策略。也就是将上报的数据,先暂放在内存的消息队列中,以缓解对于下游服务的压力。
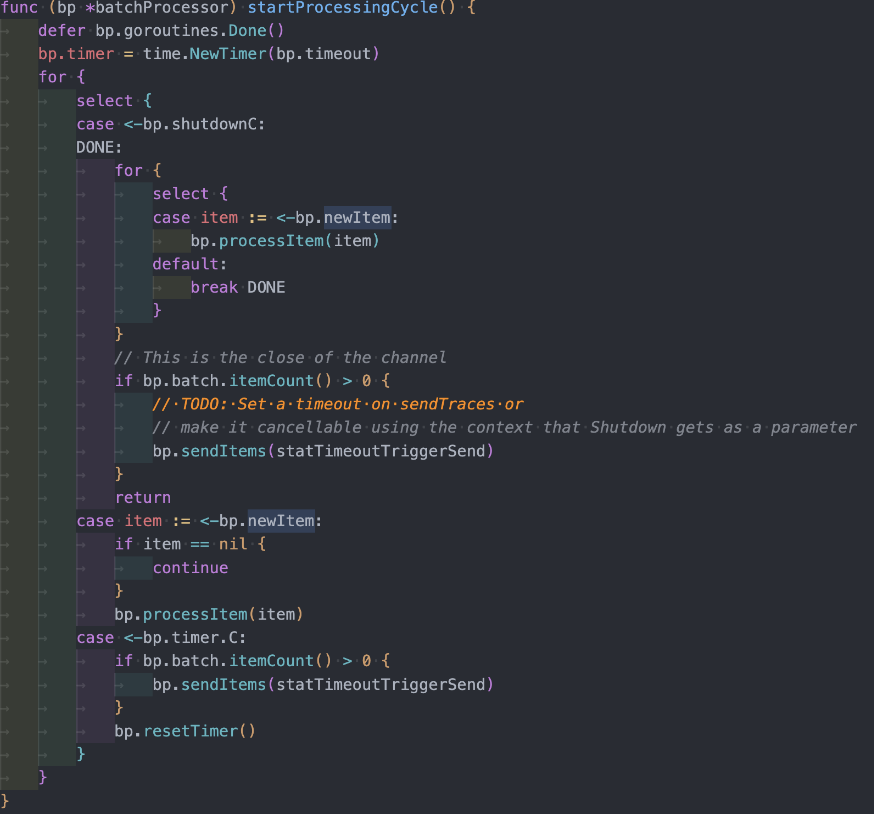
这个批处理队列会在设定的时间间隔内或者到达设定的最大队列长度时,将数据发到下游数据端点并清空队列。
失败对冲
监控上报服务一般来说都不会是一个单体服务,特别是 Exporter,如果数据落库的逻辑执行失败比如数据端点写入失败,那么对应的日志上报就会失败,用户可能有些关键日志丢失会比较难接受。
opentelemetry-collector 提供了失败重试的策略供用户选择。
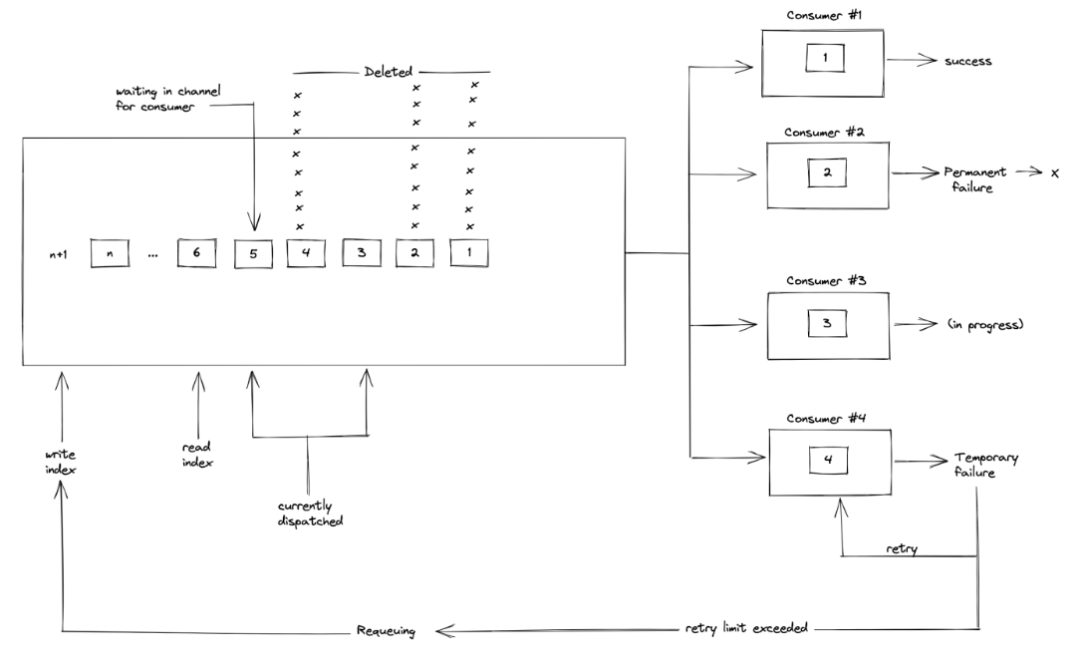
如上图所示,collector 会在内部维护一个生产消费者模式的重试队列,使用双指针,读指针从队头不断取出需要重试的请求数据,然后重试,如果成功或者请求返回一个无法重试的错误(比如业务错误),那么就从队列中删除这个数据,如果这个错误是可重试的(比如超时),会一直重试到最大重试次数,若还不成功则重新添加到队尾,等待下一次消费者取出重试。
而重试的数据 collector 提供了两种方式来存放,一种是放在内存中,一种是放在磁盘中,两个方案各有优劣,存放内存速度快但是会使得内存不断增大,存放磁盘不会影响服务运行但是文件 IO 读写性能会拖慢接口响应时间。
总结
当然,opentelemetry-collector 组件里面还有很多很好的编程实践和理念值得学习的,比如 opentelemetry 的头部连贯采样策略与尾部连贯采样策略,和 opentelemetry transformation language,这些在本篇文章没有涉及,本篇文章只是挑选了一些大家在平时写业务代码就能借鉴使用的通用实践,欢迎大家私下和我继续讨论 opentelemetry 的具体实现。