「Go工具箱」一文读懂主流web框架中路由的实现原理
一、什么是路由
路由,就是url地址到业务处理代码的映射。当用户输入一个url地址时,服务器该知道该用户返回什么内容。比如,当用户点击登录时,服务器应该做登录相关的事情,并给用户返回登录成功或失败的页面。当用户点击退出时,服务器应该做和退出相关的事情(比如清理用户登录的数据),并返回给用户退出之后的页面。
一个url到一个具体的处理函数之间的映射叫做一条路由。

多条路由组成路由表。路由表主要用于路由查找,根据不同的路由表的组织形式,可以有不同的查找方法。最简单的路由表就是使用map。直接以key-value的形式进行匹配即可。

给定一个url,找到对应的处理函数的过程叫做路由查找。路由器就是用来管理路由表以及进行路由查找的。

所以,在web系统中一个路由系统由路由、路由表、路由匹配三部分功能组成。
二、基于映射表的路由实现
go内建标准包net/http中路由的实现是基于映射表实现的。也是最简单的路由实现。本节我们就来看来http请求的处理流程以及内建包默认的路由实现原理。
2.1 http的处理流程
首先,我们来看下http包是如何处理请求的。通过以下代码我们就能启动一个http服务,并处理请求:
import (
"net/http"
)
func main() {
// 指定路由
http.Handle("/", &HomeHandler{})
// 启动http服务
http.ListenAndServe(":8000", nil)
}
type HomeHandler struct {}
// 实现ServeHTTP
func (h *HomeHandler) ServeHTTP(response http.ResponseWriter, request *http.Request) {
response.Write([]byte("Hello World"))
}当我们输入http://localhost:8000/的时候,就会走到HomeHandler的ServeHTTP方法,并返回Hello World。
那这里为什么要给HomeHandler定义ServeHTTP方法呢?或者说为什么会走到ServeHTTP方法中呢?
我们顺着http.ListenAndServe方法的定义:
func ListenAndServe(addr string, handler Handler) error
发现第二个参数是个Handler类型,而Handler是一个定义了ServeHTTP方法的接口类型:
type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}似乎有了一点点关联,HomeHandler类型也实现了ServeHTTP方法。但我们在main函数中调用http.ListenAndServe(":8000", nil)的时候第二个参数传递的是nil,那HomeHandler里的ServeHTTP方法又是如何被找到的呢?
我们接着再顺着源码一层一层的找下去可以发现,在/src/net/http/server.go的第1930行有这么一段代码:
serverHandler{c.server}.ServeHTTP(w, w.req)
有个serverHandler结构体,包装了c.server。这里的c是建立的http连接,而c.server就是在http.ListenAndServe(":8000", nil)函数中创建的server对象:
func ListenAndServe(addr string, handler Handler) error {
server := &Server{Addr: addr, Handler: handler}
return server.ListenAndServe()
}server中的Handler就是http.ListenAndServe(":8000", nil)传递进来的nil。
好,我们进入 serverHandler{c.server}.ServeHTTP(w, w.req)函数中再次查看,就可以发现如下代码:
func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) {
handler := sh.srv.Handler
if handler == nil {
handler = DefaultServeMux
}
...
handler.ServeHTTP(rw, req)
}/src/net/http/server.go的第2859行到2862行,就是获取到server中的Handler,如果是nil,则使用默认的DefaultServeMux,然后调用了hander.ServeHTTP方法。
继续再看DefaultServeMux中的ServeHTTP方法,在/src/net/http/server.go中的第2416行,发现有一行h,_ := mux.Handler(r)和h.ServeHTTP方法。这就是通过请求的路径查找到对应的handler,然后调用该handler的ServeHTTP方法。
func (mux *ServeMux) ServeHTTP(w ResponseWriter, r *Request) {
if r.RequestURI == "*" {
if r.ProtoAtLeast(1, 1) {
w.Header().Set("Connection", "close")
}
w.WriteHeader(StatusBadRequest)
return
}
h, _ := mux.Handler(r)
h.ServeHTTP(w, r)
}在一开始的实例中,就是我们的HomeHandler的ServeHTTP方法。也就是说ServeHTTP方法是net/http包中规定好了要调用的,所以每一个页面处理函数都必须实现ServeHTTP方法。

同时也说明,net/http包中的路由是在DefaultServeMux对象中实现的,该对象是一个ServeMux结构体类型,接下来我们看ServeMux路由的具体实现。
2.2 net/http包中路由的实现
在net/http包中实现路由的机构提是ServeMux,其结构定义如下。
type ServeMux struct {
mu sync.RWMutex
m map[string]muxEntry
es []muxEntry // slice of entries sorted from longest to shortest.
hosts bool // whether any patterns contain hostnames
}结构体字段很简单,我们重点看m变量,是一个map类型,即key-value结构,就是我们所说的路由表。key就是路由的路径,value是一个muxEntry对象,muxEntry结构如下:
type muxEntry struct {
h Handler
pattern string
}pattern是对应的路径,h就是对应的处理函数。当我们调用http.Handle("/", &HomeHandler{})�进行路由注册时候,实质上就是将路径和HomeHandler对象构建成一个muxEntry对象,然后加入到ServeMux的m中。

接下来我们再看路由的查找,既然路由表是有map实现的,那么路由的查找过程自然就是通过路径从map中查找对应的muxEntry,然后获取对应的handler即可。该实现就是在/src/net/http/server.go中的第2416行的mux.Handler(r)进行的。
以上就是net/http包中自己路由的实现。非常简单,同时也意味着功能有限。比如不能对路由进行分组、不能限定路由的请求方法(GET、POST或其他)、不能对路由加中间件等等。 这也就给第三方包提供了再次实现的机会。
三、基于正则表达式的路由实现
3.1 gorilla/mux包简介
该包是基于正则表达式实现的路由。该路由支持分组、restful风格路径的定义、绑定路由请求的方法(GET、POST等)、限定路径使用http还是https协议等功能。我们看下其基本情况。
| gorilla/mux小档案 | |||
|---|---|---|---|
| star | 17.8k | used by | 88.7k |
| contributors | 97 | 作者 | gorilla |
| 功能简介 | 一个强大的http路由。支持路由分组、restful风格路径定义、限定请求方法及http协议、处理静态文件等功能。 | ||
| 项目地址 | https://github.com/gorilla/mux | . |
3.2 基本使用
由于该包支持的路由规则比较多,所以我们先从最简单的例子开始看一下基本使用,然后再通过分析其实现原理看各种规则是如何支持的。
package main
import (
"fmt"
"net/http"
"github.com/gorilla/mux"
)
func main() {
r := mux.NewRouter()
r.HandleFunc("/", HomeHandler)
r.HandleFunc("/products", ProductsHandler)
//定义restful风格的路径,例如/product/12345
r.HandleFunc("/product/{id:[0-9]+}", ProductHandler)
http.ListenAndServe(":8000", r)
}
func HomeHandler(response http.ResponseWriter, request *http.Request) {
response.Write([]byte("Hi, this is Home page"))
}
func ProductsHandler(response http.ResponseWriter, request *http.Request) {
response.Write([]byte("Hi, this is Product page"))
}
func ProductHandler(response http.ResponseWriter, request *http.Request) {
vars := mux.Vars(request)
// 获取产品的ID值。
id := vars["id"]
response.Write([]byte("Hi, this is product:" + id))
}3.3 实现原理分析
首先我们通过mux.NewRouter()方法返回了一个Router结构体对象。该结构体对象也实现了ServeHTTP方法,在该方法中实现了对路由的匹配和转发。所以覆盖作为http.ListenAndServe的第二个参数,替代了默认的路由分发对象DefaultServeMux。以下展示了Router的ServeHTTP方法对路由的匹配和分发部分的代码,其他代码省略。
func (r *Router) ServeHTTP(w http.ResponseWriter, req *http.Request) {
...
var match RouteMatch
var handler http.Handler
// 路由匹配
if r.Match(req, &match) {
handler = match.Handler
req = requestWithVars(req, match.Vars)
req = requestWithRoute(req, match.Route)
}
...
// 路由分发
handler.ServeHTTP(w, req)
}本质上是和默认的路由分发器DefaultServeMux的实现是一样的。不同的是路由的管理以及匹配上。
接下来我们看下Router结构体。如下:
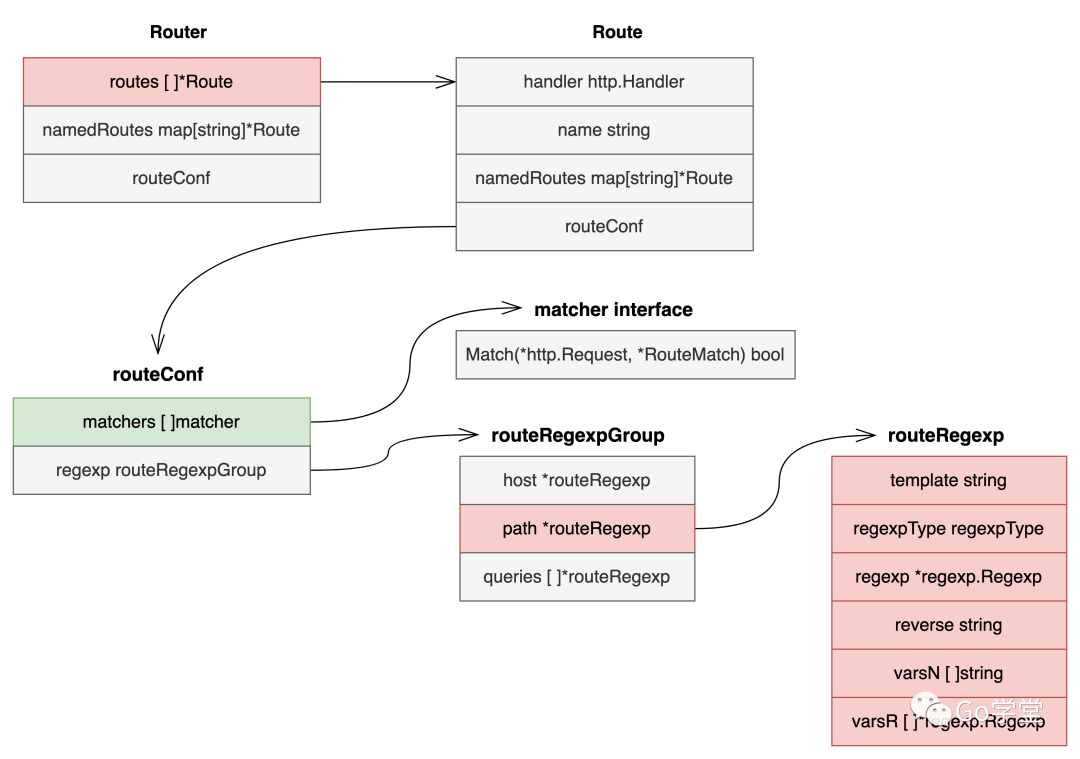
这里我们只列出来核心的字段,省略了一些辅助字段。这里有几个主要的字段:
- Router中的routes:Route切片类型,角色是路由表,存储所有的路由。
- Route:一个具体的路由,handler字段存储的是具体的处理函数,同时每个路由的路径是在最后的routeRegexp结构体中的。
- matchers字段:切片类型,存储了该路由下的所有要匹配的规则。matchers的类型是一个matcher接口,定义了Match方法。其中routeRegexp结构体实现了该方法,所以一个routeRegexp实例就是一个matcher。
- routeRegexp结构体:该结构体代表了路由中具体的路径的匹配规则。将路由中的路径转换成对应的正则表达式,存储与regexp字段中。
routeRegexp结构体中的主要字段分别如下:
- template:保存的是路由的路径模版。比如
r.HandleFunc("/product/{id:[0-9]+}", ProductHandler)中,则是"/product/{id:[0-9]+}" - regexpType:正则类型,目前支持regexpTypePath、regexpTypeHost、regexpTypePrefix、regexpTypeQuery四种类型。比如
r.HandleFunc("/product/{id:[0-9]+}", ProductHandler)就是路径匹配regexpTypePath。而r.Host("www.example.com")就是域名匹配regexpTypeHost。稍后我们会一一介绍。 - regexp:是根据路由中的模版路径构造出来的正则表达式。以
"/product/{id:[0-9]+}"为例,最终构造的正则表达式是^/product/(?P<v0>[0-9]+)$� - reverse:
- varsN:是路径模式中花括号{}中的变量个数。以
"/product/{id:[0-9]+}"为例,varsN则等于[]{"id"}。 - varsR:是路径模式中每个花括号{}对应的正则表达式。以"/product/{id:[0-9]+}"为例,varsR则等于[]{"^[0-9]+$"}。如果路由中是设置r.HandleFunc("/product/{id}", ProductHandler),varsR的元素则是
[]{"^[^/]+�"}的正则表达式。
根据路由表及路由的结构,具体的路由匹配查找基本过程如下: 第一步,从Router.routes开始依次循环 第二步,从每个路由中的matchers中循环,看请求的路径是否符合matchers中的每一项规则,如果都匹配,则说明找到了该路由,否则继续步骤1。
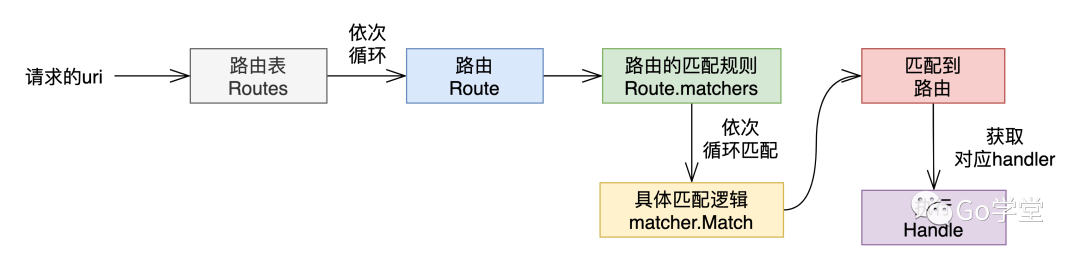
接下来,我们看看该路由是如何支持各种功能的。
3.4 路由支持的功能及对应的正则
3.4.1 匹配特定域名或子域名
r := mux.NewRouter()
// Only matches if domain is "www.example.com".
r.Host("www.example.com")
// Matches a dynamic subdomain.
r.Host("{subdomain:[a-z]+}.example.com")我们先看r.Host("www.example.com")的路由。在routeRegexp结构体中,regexp值会是正则表达式"^www\.example\.com$,regexpType字段是regexpTypeHost。同时赋值给routeRegexpGroup中的host字段。
从路由表Router.routes中依次匹配本次请求的时候,发现route.regexpType字段是域名的正则,则从请求中获取当前的host,然后跟routeRegexp.regexp正则表达式进行匹配。如果匹配成功则继续匹配后面的路由,否则直接匹配失败。
再来看匹配子域名r.Host("{subdomain:[a-z]+}.example.com")的情况。在routeRegexp结构体中,regexp值会是正则表达式"^(?P<v0>[a-z]+)\.example\.com$,regexpType字段是regexpTypeHost。同时赋值给routeRegexpGroup中的host字段。匹配过程和上述过程一样,不再重复介绍。
3.4.2 给路径增加前缀
r.PathPrefix("/products/")
顾名思义,就是只有路径中是以/products为前缀的才能匹配到该路由。该路由的设置最终编译成的正则表达式是^/products。这里注意该表达式中结尾并没有结尾符号 $。其匹配过程和上述一致。
3.4.3 限制路由的请求方法(GET、POST等)
r.Methods("GET", "POST")
对请求方法的限制 是不经过正则,而是将允许的方法(GET、POST)转换成一个methodMatcher�类型,该类型本质上是一个字符串切片,并且实现了Match方法,也就是matcher接口。然后将其加入到该路由的matchers中,在路由匹配时看当前的请求是否满足该路由的这条规则。其定义如下:
type methodMatcher []string
func (m methodMatcher) Match(r *http.Request, match *RouteMatch) bool {
return matchInArray(m, r.Method)
}3.4.4 支持路由分组
userRouter := r.PathPrefix("/user").Subrouter()
userRouter.HandleFunc("/info", HomeHandler)通过.Subrouter()函数就能实现一个子路由表,在该子路由表下注册的所有路由都会遵循子路由上的公共设置,比如前缀。如上述例子/info的完整路径就是/user/info指向HomeHandler。
我们查看Subrouter函数的源码,实际上是新建了一个Router结构体,而Router结构体实现了Match函数,即matcher,所以也会将该matcher加入到r.PathPrefix这个路由的matchers中。相当于在路由中有建了一个专属的路由表。以下是Router的Match函数实现,我们看到循环到该matcher时,循环子路由表的routes,再对每个子路由依次进行匹配:
func (r *Router) Match(req *http.Request, match *RouteMatch) bool {
for _, route := range r.routes {
if route.Match(req, match) {
// Build middleware chain if no error was found
if match.MatchErr == nil {
for i := len(r.middlewares) - 1; i >= 0; i-- {
match.Handler = r.middlewares[i].Middleware(match.Handler)
}
}
return true
}
}
...//省略代码
}
3.4.5 支持中间件
// 定义中间件
func loggingMiddleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// Do stuff here
log.Println(r.RequestURI)
// Call the next handler, which can be another middleware in the chain, or the final handler.
next.ServeHTTP(w, r)
})
}
r := mux.NewRouter()
r.HandleFunc("/", HomeHandler)
// 使用中间件
r.Use(loggingMiddleware)
func HomeHandler(response http.ResponseWriter, request *http.Request) {
response.Write([]byte("Hi, this is Home page"))
}在该示例中,首先定义了一个中间件loggingMIddleware,然后使用Use函数将中间件加入到了Router中。
中间件的实现原理实际上是将原本要执行的handler包装到中间件的handler中。先执行中间件的handler逻辑,然后再执行原本的handler。以上述代码为例,会将HomeHandler传递给loggingMiddleware的next参数。执行的时候从第4行开始执行,最后才是第7行,即HomeHandler的代码逻辑。如下图:
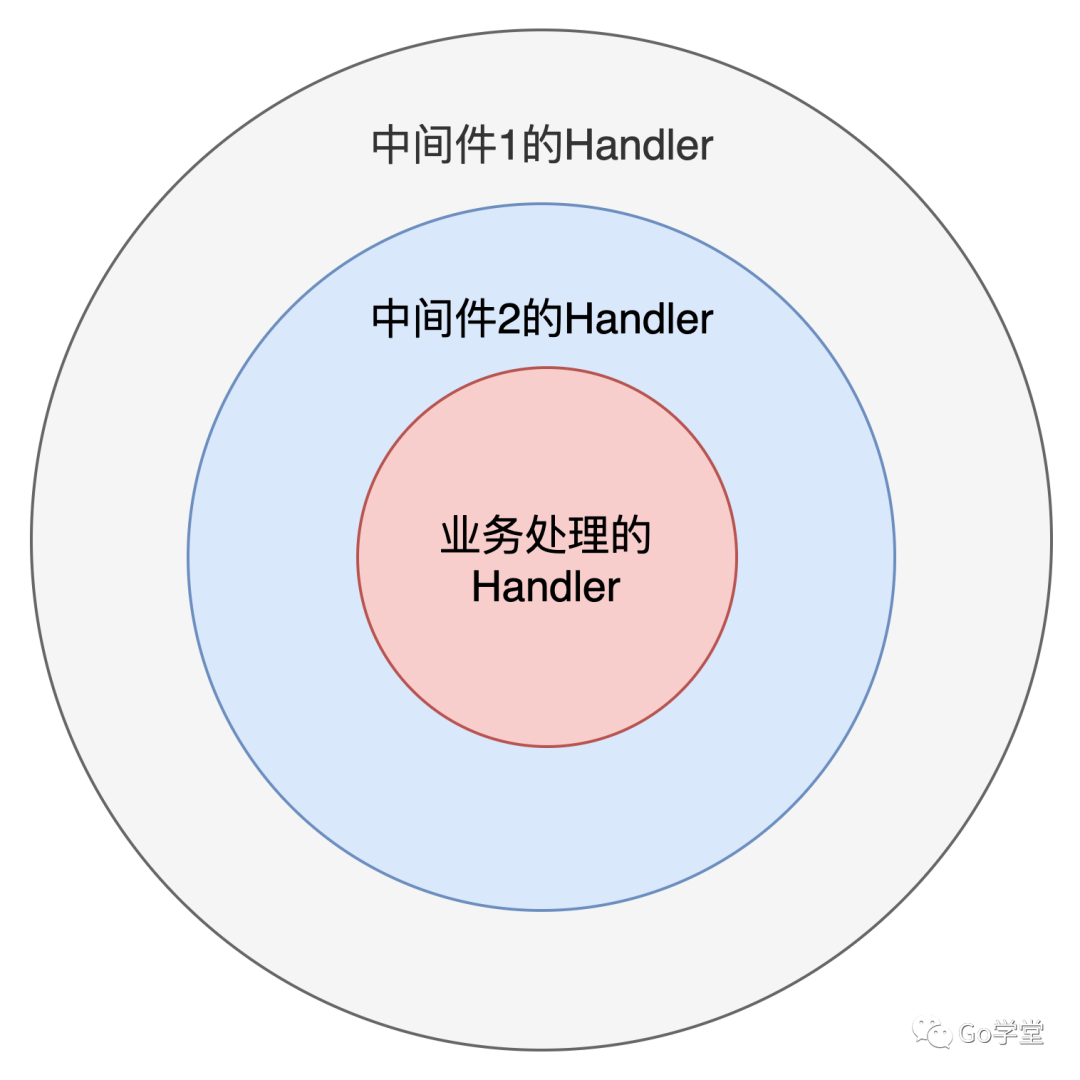
接下来我们看看中间件是如何实现一层层包裹的。
我们先看r.Use函数的定义:
func (r *Router) Use(mwf ...MiddlewareFunc) {
for _, fn := range mwf {
r.middlewares = append(r.middlewares, fn)
}
}发现中间件的类型是MiddlewareFunc,该类型的定义如下:
type MiddlewareFunc func(http.Handler) http.Handler
中间件本质上是一个函数类型,输入和输出都是一个http.Handler,同时MiddlewareFunc中实现了一个Middleware的方法:
func (mw MiddlewareFunc) Middleware(handler http.Handler) http.Handler {
return mw(handler)
}我们再看路由匹配时,执行中间件的逻辑:
func (r *Router) Match(req *http.Request, match *RouteMatch) bool {
for _, route := range r.routes {
if route.Match(req, match) {
// Build middleware chain if no error was found
if match.MatchErr == nil {
for i := len(r.middlewares) - 1; i >= 0; i-- {
match.Handler = r.middlewares[i].Middleware(match.Handler)
}
}
return true
}
}
...//省略代码
}在第7行,执行中间件的Middleware函数。以r.HandleFunc("/", HomeHandler)使用loggingMiddleware中间件为例,match.Handler是HomeHandler,loggingMiddleware.Middleware即为loogingMIddleware(HomeHandler),该函数返回的是一个新的handler:
http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// Do stuff here
log.Println(r.RequestURI)
// Call the next handler, which can be another middleware in the chain, or the final handler.
next.ServeHTTP(w, r)
})那么,在具体执行的时候,就是先执行该handler的业务逻辑,即log.Println(r.RequestURI),然后执行next.ServerHTTP逻辑,即HomeHandler.ServeHTTP的逻辑。
这就是中间件对handler的包装及执行过程。其他更多功能可自行查看gorilla/mux包的源码。
4 基于tries结构的路由实现
4.1 gin框架中的路由
大名鼎鼎的gin框架采用的就是前缀树结构实现的路由。我们先来看一下gin框架中路由是如何定义的。
package main
import (
"github.com/gin-gonic/gin"
)
func main() {
g := gin.New()
g.POST("/abc/info", InfoHandler)
g.POST("/abc/info/detail", InfoHandler)
g.POST("/abc/list", HomeHandler)
g.Run(":8000")
}
func HomeHandler(ctx *gin.Context) {
ctx.Writer.Write([]byte("Hi, this is Home page"))
}
func InfoHandler(ctx *gin.Context) {
ctx.Writer.Write([]byte("Hi, this is info"))
}很简单,首先通过gin.New()初始化一个gin对象g,然后通过g.POST或g.GET等方法就可以注册路由。很明显,路由注册过程也限制了请求的方法。 当然,还有一个方法是允许任何请求方法都能访问该路径的,就是Any:
g.Any("/", HomeHandler)
Any方法本质上是定义了一组方法名,然后依次调用对应的方法将该路由进行注册,如下:
var anyMethods = []string{
http.MethodGet, http.MethodPost, http.MethodPut, http.MethodPatch,
http.MethodHead, http.MethodOptions, http.MethodDelete, http.MethodConnect,
http.MethodTrace,
}
// Any registers a route that matches all the HTTP methods.
// GET, POST, PUT, PATCH, HEAD, OPTIONS, DELETE, CONNECT, TRACE.
func (group *RouterGroup) Any(relativePath string, handlers ...HandlerFunc) IRoutes {
for _, method := range anyMethods {
group.handle(method, relativePath, handlers)
}
return group.returnObj()
}接下来,我们分析下路由实现以及匹配的过程。
4.2 前缀树路由的实现原理
相比较map/hash字典实现的优点:利用字符串公共前缀来减少查询时间,减少无谓的字符串比较
4.2.1 路由中限制请求方法的实现
我们先看gin框架中的路由是如何对请求方法做限制的。 在gin框架中,路由树的构建是基于方法的。每种方法一棵路由树。如下:
type methodTree struct {
method string
root *node
}
type methodTrees []methodTree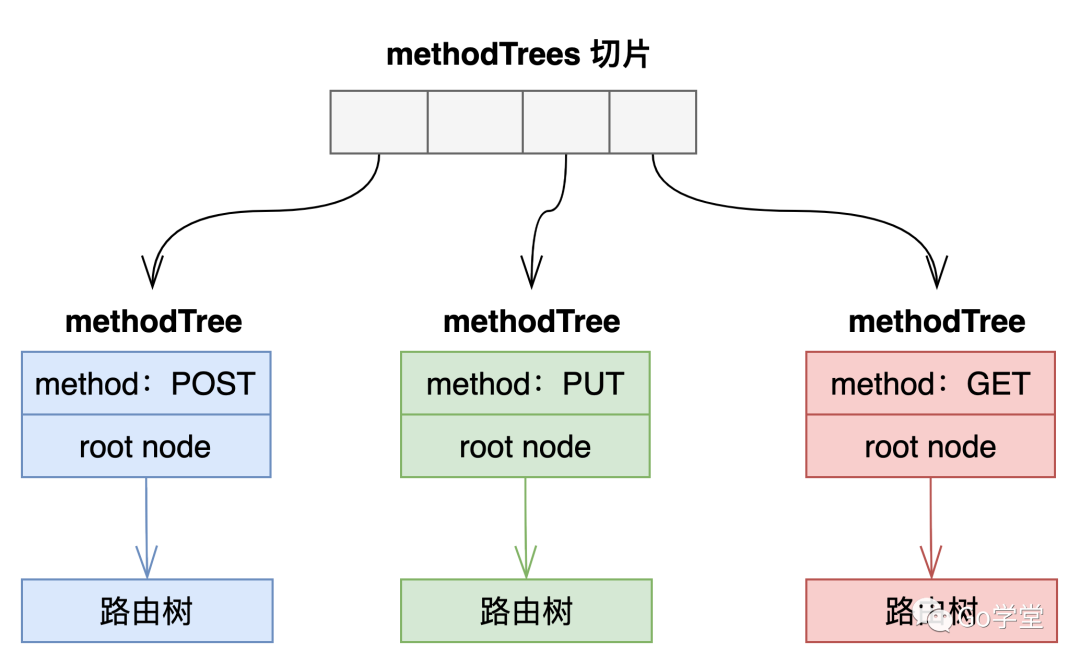
g.POST("/abc/info", InfoHandler)路由,只会注册到POST方法的路由树中。若通过GET方法请求该路径,则在搜索的时候,在GET方法的路由树中就找不到该路由。这样就起到了通过路由限制请求方法的作用。
而g.Any方法注册的路由,相当于在所有的方法路由中都注册了一遍,因此,使用任何方法都能找到对应的路由。
4.2.2 路由树节点的数据结构
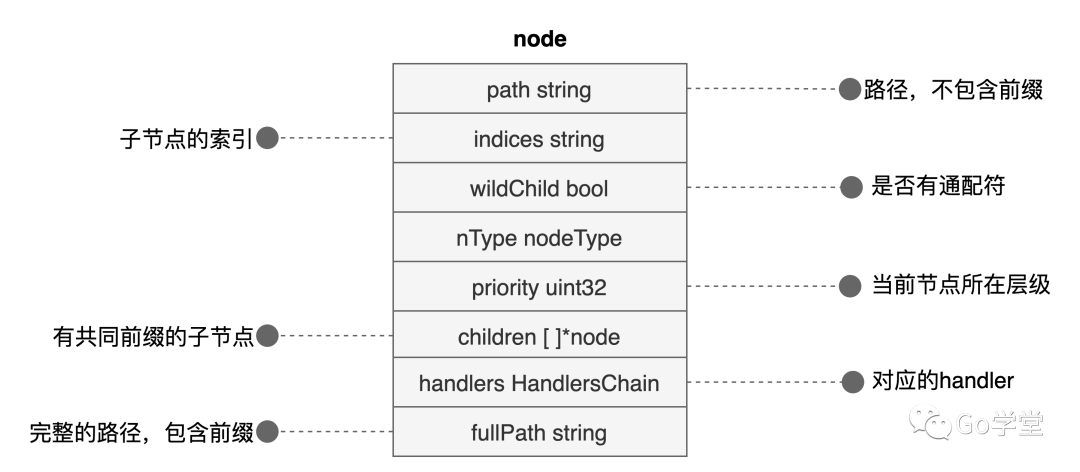
另外一个关键字段是children,具有相同路径前缀的子节点通过children节点来构成父、子关系。
接下来我们路由树是如何基于node节点进行构建的。
4.2.3 路由树的构建
首先,我们看第一个路由的注册。
g.POST("/abc/info", InfoHandler)
因为是第一个路由注册,路由树是空的。所以直接构建一个node节点,然后将该node节点作为POST方法路由树的根节点插入即可。如下图:

好,我们接着看接着注册第二个路由:
g.POST("/abc/info/detail", DetailHandler)
我们发现,这个路由的特点是和路由"/abc/info"有共同的前缀,所以会将该路由作为第一个路由的子节点放到children中。如下图:

这里主要有三个变化:一个是根节点的priority由1变成了2;一个是children中多了一个子节点路由;最后一个是indices字段的值变成了"/",这个是第一个子节点的path字段的第一个字符,用于匹配时索引使用。在子节点中,要注意的是path的值,因为前缀是"/abc/info"了,所以这里path是"/detail"。但fullPath依然是注册时完整的路径。
接下来,我们再注册第三个路由:
g.POST("/abc/list", ListHandler)
这个路由的特点是和前两个路由有共同的前缀"/abc/",所以首先会将现在的根节点进行拆分,拆分成"/abc/" 和"info"。而info和原来的"/abc/info/detail" 又有共同的前缀info,所以原来的"/abc/info/detail"就变成了info的子节点。而"/abc/list"除去前缀"/abc/"后,剩余"list"子节点,作为"/abc/"的子节点。如下:
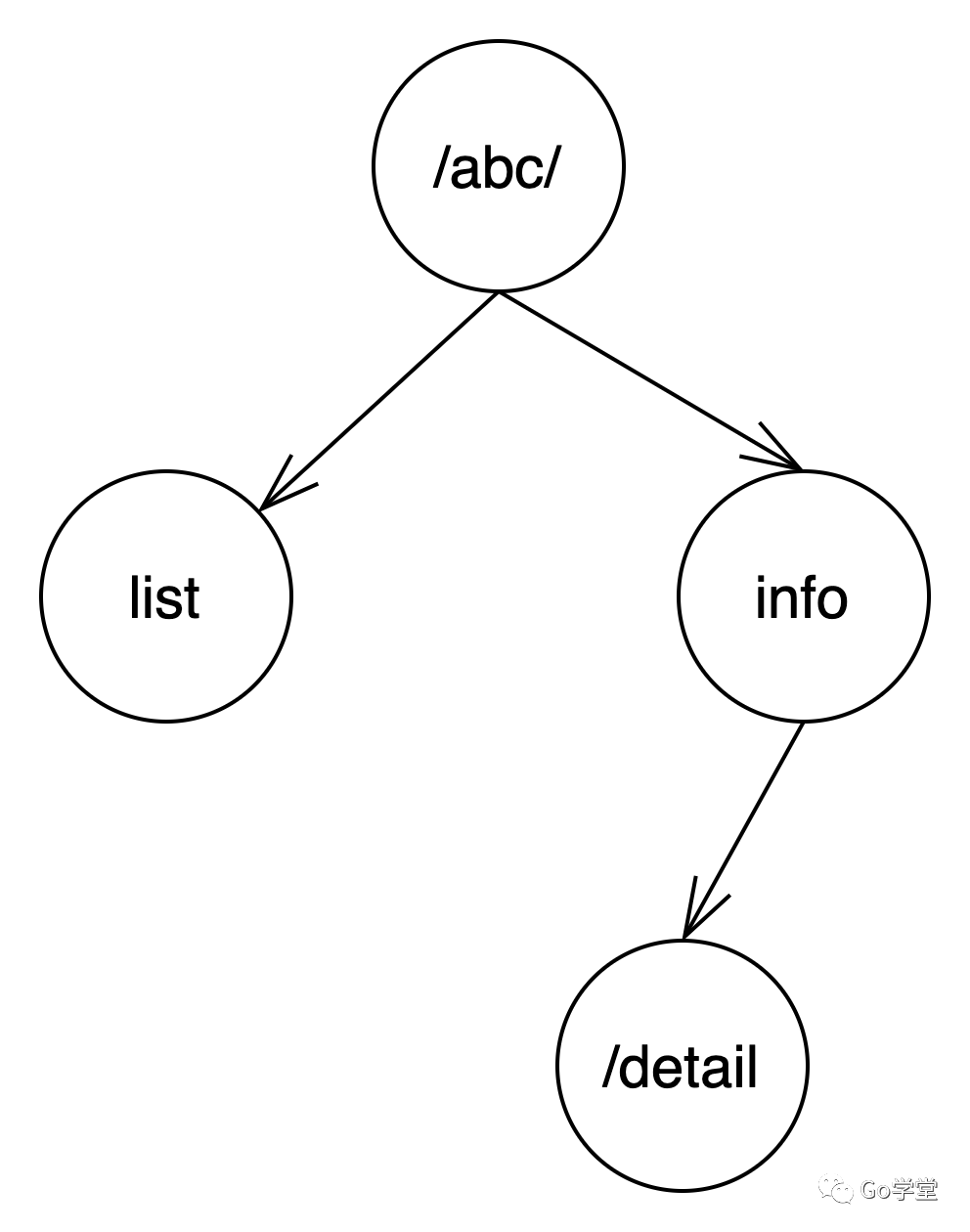
那么,按节点组成的路由树就如下所示:

这里,我们首先看根节点的变化:
- handlers变为nil。因为该节点不是一个具体的路径,只是一个前缀,所以具体的handler下移到了子节点info节点。
- path变为了前缀"/abc/"。
- indices字段值变为了"il",其中i是第一个子节点中path字段的第一个字符,l是第二个子节点中path字段的第一个字符。
- priority字段变成3:代表从自身开始及子节点共有4个。
- children字段变成了两个直接子节点。
- fullPath字段变为了"/abc/"。
其次,是从原根节点中拆分出一个info节点。最后是detail节点成为info节点的子节点。
以上就是路由树的构建过程。更细节的构造,有兴趣的同学可以查看源码进一步了解。
总结
本文总结了3中路由的实现。路由本质上就是将请求的路径和对应的处理函数一一对应。通过路径查找到处理函数的过程。不同框架基于不同的数据结构实现了路由表以及匹配过程。希望本文对大家理解web框架的路由有所帮助。