代码在内存中的'形状'
前言
众所周知,js 的基本数据类型有 number 、 string 、 boolean 、null 、 undefined 等。那么问题来了 typeof null 和 typeof undefined 分别是什么呢?var 、 const 、 let 变量提升?暂时性死区又是什么东西?以前刚学 js 的时候有人跟我说 === 相比于 == 不仅比较值还要比较类型,难道不是这样的?
js 引擎与 V8
通常我们说的浏览器的内核一般是指支持浏览器运行的最核心的程序,分为两个部分,也就是渲染引擎和 JS 引擎。渲染引擎负责解析 HTML,然后进行布局,渲染等工作。而 js 引擎顾名思义就是解析并且执行 js 代码的。
一些常见浏览器 js 引擎,比方说老版本 IE 使用 Jscript 引擎,而 IE9 之后使用的 Chakra 引擎。safari 使用的是 SquirrelFish 系列引擎。firefox 使用 monkey 系列引擎。chrome 使用 V8 引擎,而且 nodeJs 其实上就是基于 V8 引擎做了进一步封装。我们今天讨论的内容也都是基于 V8 引擎的。
我们知道 js 引擎(V8)在拿到代码之后,会进行词法分析,将 js 代码拆分成对应的 Token,然后再根据 Token 继续生成对应的 AST,也就是语法分析的过程。而在这一过程中肯定也伴随着很多的优化策略。有兴趣的同学可以阅读下我们之前的一篇非常不错的文章《[V8 执行 JavaScript 的过程] 》。在这里呢,笔者将从 V8 执行代码过程中实际操作内存的角度来进行进一步的分享。
首先,我们先认识下这个模型:
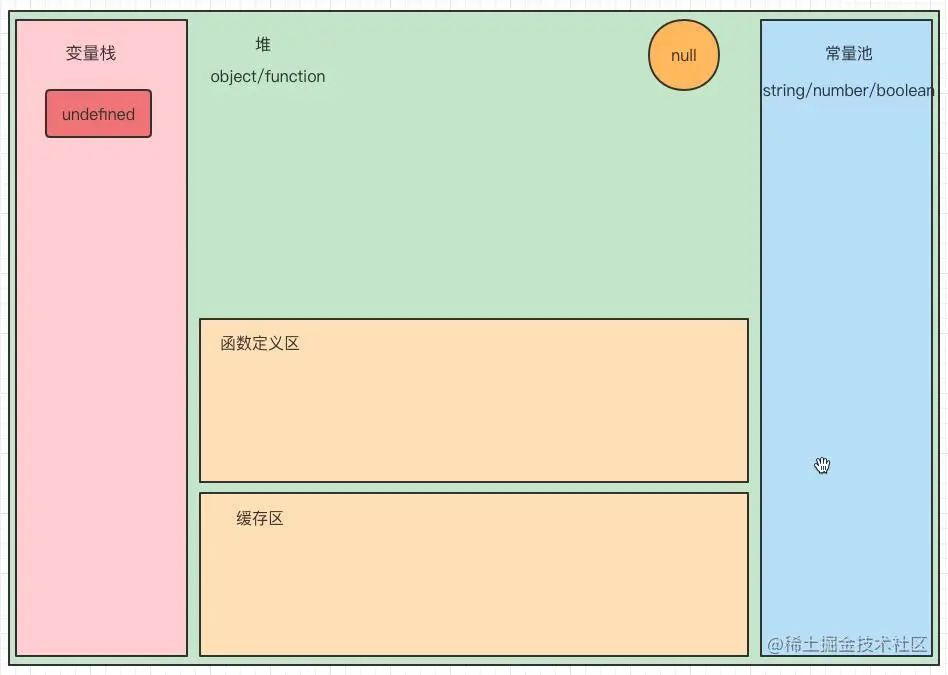
栈、堆、常量池这三大区域,当然其他的一些(甚至比方说 buffer 模块需要调配更加底层的 C++ 内存)模块不在本次讨论范围所以没有体现。图中清晰的体现了 js 基本数据类型在内存中的存储情况。
1.栈
栈内存结构最大的特点就是小且存储连续,操作起来简单方便。在 js 中,变量名是用来保存内存中某块内存区的地址的,而栈区就是用来保存变量名和内存地址的键值对的,所以我们就可以通过变量名获取或者操作某一内存地址上的内容。而 undefined 正是栈空间中表示未定义含义的一块特殊的固定的内存区域。
console.log(b); // undefined
var a;
var b = '政采云前端团队';然而,js 引擎在实际执行代码之前,会先从上往下依次处理变量提升和函数定义,然后再按序执行。拿以上代码块为例,这一过程在内存中的具体体现就是:
- 先会在栈空间中定义好 a 、 b ,并且在变量提升阶段 a 和 b 的指针会指向到 undefined。
- 然后会从上往下依次执行代码。
- 执行到赋值(=)语句时,则会将变量b指向的内存地址修改为常量池中1对应的物理地址。
2.常量池
顾名思义,常量池就是用来存储常量的,包括 string、number、boolean 这三个基本类型的数据。常量池最大的特点就是:
- 它在整个内存中是唯一的。
- 常量池区域是唯一的。
- 并且常量也是唯一的。
所以这也就是为什么 a===b 是 true,因为 === 比较的是变量 a 和 b 在内存中的指针指向的物理地址是否相等。
var a = '政采云前端团队';
var b = '政采云前端团队';3.堆
相对于栈和池来说,堆的存储形态会更加复杂。但是从另一个抽象的角度来说,堆区域却又是最单一的,因为存放在堆区域的都是 object。
typeof {}; // object
typeof []; // object
typeof null; // object
typeof new Date(); // object
typeof new RegExp(); // object那么就有人要问了,null 不是基本类型么,为什么 typeof null 又是 object 呢?
其实正如上文对 undefined 的定义那样,js 引擎对于 null 的基本定义其实是,在堆内存空间中的具有固定内存地址且唯一存在的一个内置对象。所以这就是 null 和 undefined 本质上的区别所在。
name = '政采云前端团队'
var a = {
name: '政采云前端团队'
}
console.log(name === a.name); // true实际上,堆内存中的情况是非常复杂但又是非常精妙的。比方,上面这小段代码,执行过程中会在栈中创建 a 和 name 两个变量。针对于给 a 赋值的这个对象,v8 会在堆区中分配一块内存区域。并且区域内部依然会有内部的栈区和堆区,这就是精妙的分型思想。而 name === a.name 也侧面引证了常量的唯一。
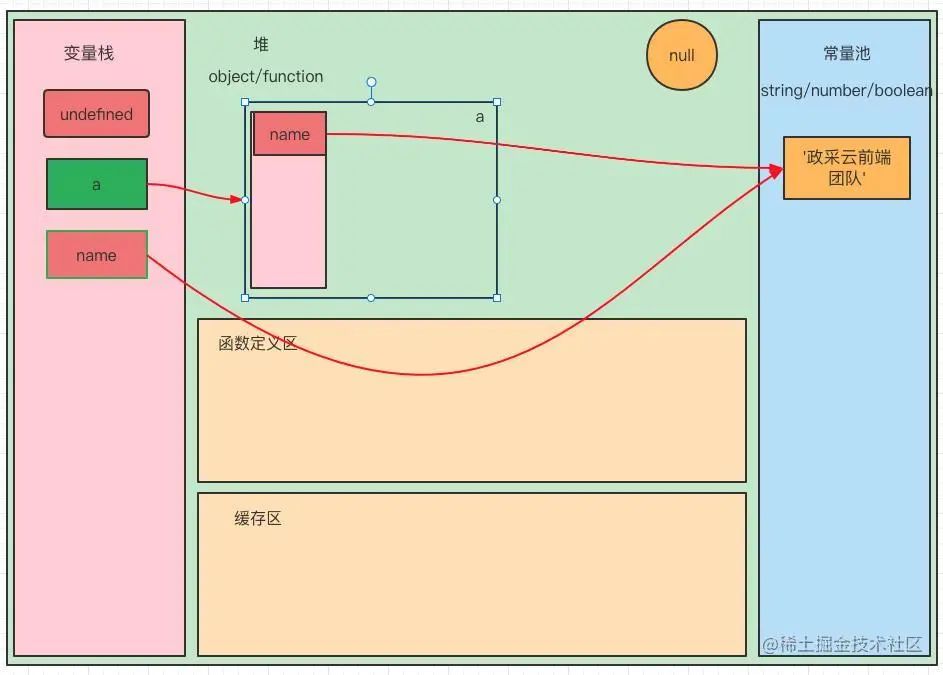

object ?也可能会有一些大佬看到此处会微微一笑,这个人接下来肯定要开始扯什么 new Function() 。所以 function 从定义的抽象上来说也是 object 了。
4.函数
是的,在介绍完基础且常用的三大区域后,接下来我们来聊一聊函数。但是,我们换个角度,还是回到这个模型上来尝试去理解一下函数的执行、函数的继承以及闭包。
上代码:
function Animal(name) {
this.name = name;
}
Animal.prototype.eat = function () {
console.log('Animal eat');
};
function Dog(name) {
Animal.apply(this, arguments);
}
var animal = new Animal();
Dog.prototype = animal;
Dog.prototype.constructor = Dog;
var dog = new Dog();
dog.eat();
console.log(Animal.prototype === animal.__proto__); // true这是一段比较标准的组合继承的例子,相信这种代码片段对大家来说应该再熟悉不过了。那么这样的一段代码的运行过程在实际内存中是什么样的一个过程呢?
首先,如下左图,在代码执行之前会进行变量提升和函数定义,所以会在变量栈和函数定义区中准备好 obj 、 Animal 、 dog 以及一个不容发现的匿名函数。这里要注意一个点,就是 var a = function() {} 和 function a(){} 是两个完全不同的概念,给个眼神自己体会。
并且在函数定义时会,就会创建一个对象空间。函数的 prototype 属性指向到这个地址,这就是函数的原型对象。同时对象内存空间的内部又将会划分出栈结构空间和堆结构空间。娃,又套上了~
后续会在赋值语句时,将 Animal.proptotype.eat 指向到匿名函数。
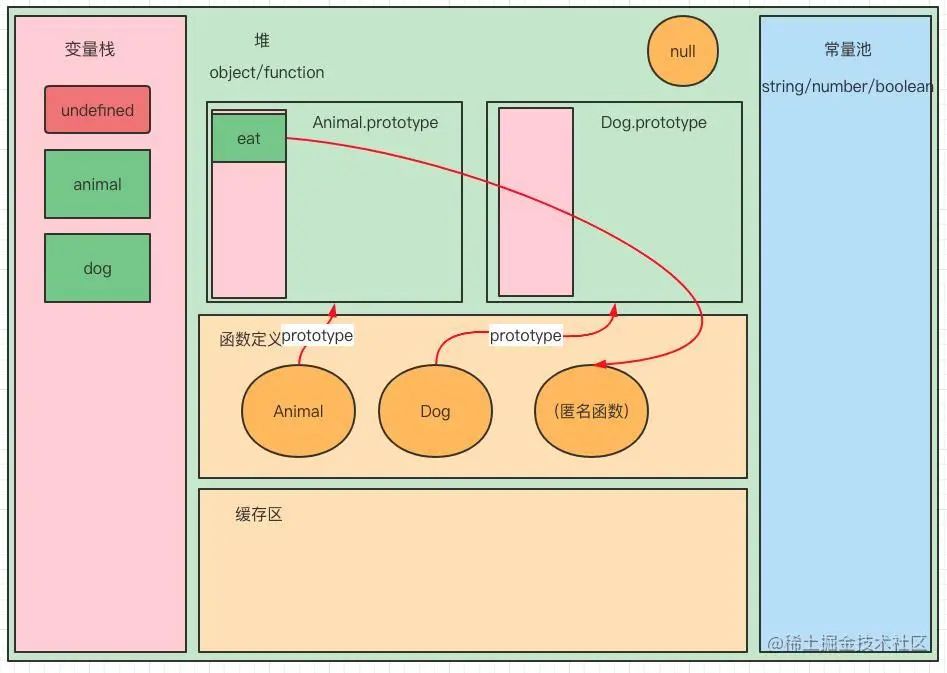
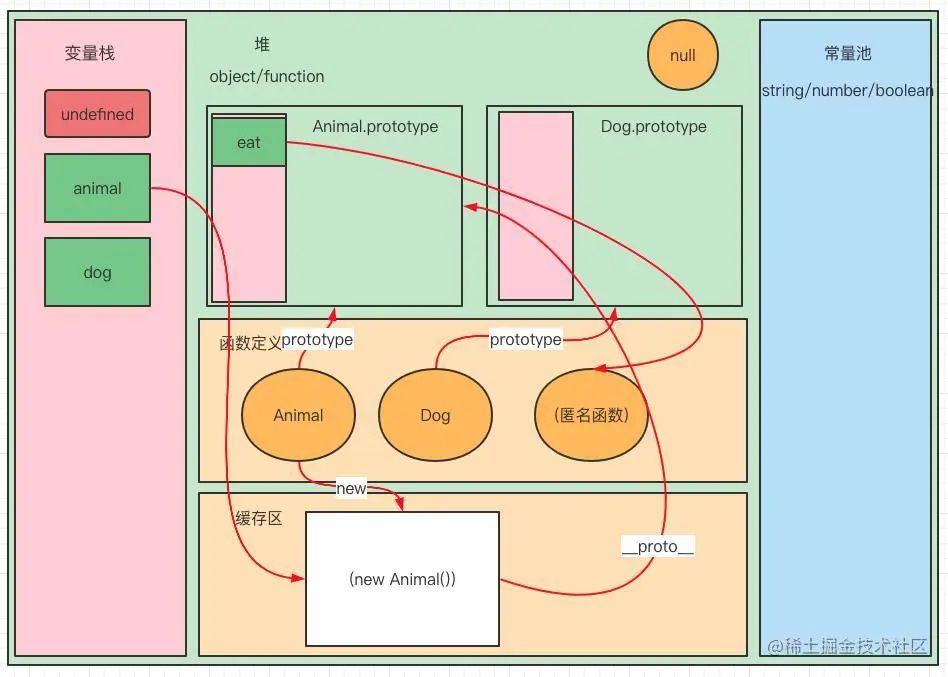
我们发现,new Animal() 、new Dog() 的这部分刚刚并没有提到。因为它们还要特殊,我们继续深入。
如上右图,其实,js 在执行 var animal = new Animal(); 这种 new 操作符的时候,js 引擎会在栈空间的函数缓存区中创建一块空间用于保存该函数运行所需要存储的状态和变量。空间中有一个 __proto__ 属性指向到构造函数的 prototype ,也就是图中的 Animal.prototype。这也就从内存的角度解释了为什么 Animal.prototype === animal.__proto__ 会是 true 。
实际上,在 new Animal() 执行完之后,本来 GC 就会清除掉函数的缓存区内存,释放空间。但是由于我们定义了一个 obj 变量,这个变量的内存地址是指向到这块缓存区,所以阻止了 GC 对这块内存的回收。这种问题在闭包问题中尤为典型。我们可以通过定义一个变量来阻止 GC 回收已经运行完的闭包函数的缓存区内存块,从而达到保护闭包内部的状态。然后在我们希望释放闭包空间的时候,将该变量置为 null ,从而在下一个 GC 周期时释放该内存区域。
function fn() {
var a = 1;
return function () {
console.log(a);
};
}
var onj = fn();最后,我们通过 Dog.prototype = animal; ,将 Dog 的原型指向到了缓存区中的白色区域。我们可以通过打印 Dog.prototype === animal 和 Dog.prototype.__proto__ ===Animal.prototype以及 dog.__proto__ === animal 的方式来验证图中的指向关系。这也就是原型继承在具体内存模型中的过程。

总结
在代码的学习过程中,难免会觉得枯燥,而且有很多内容抽象难懂。强行死记硬背,不去知其所以然的话容易了解片面甚至理解错误,更何况也非常没有乐趣。借助于这种看得见摸得着的模型去理解和分析代码实际运行的情况会帮助理解,并且能够发现其中的设计精妙之处。
文中最后部分多次提及到 GC,其实 GC 的模型设计的也是非常巧妙,非常有意思的。可以移步至《[V8 引擎垃圾回收与内存分配] 》继续阅读。有兴趣的同学可以尝试将 GC 的模型和这个 V8 内存模型结合在一起去思考下代码运行和回收的全过程。而且 GC 还只是管理堆空间的垃圾回收,那么栈空间又是以什么方式进行自我回收的呢?还有很多很多有趣的东西值得我们思考~
参考文档
- [浏览器内核、排版引擎、js引擎](https://zhuanlan.zhihu.com/p/446584471)