十多年前祖传代码重构——从25万到5万行
近期,我们接管并重构了十多年前的 Query 理解祖传代码,代码量减少80%,性能、稳定性、可观测性都得到大幅度提升。本文将介绍重构过程中系统实现、DIFF修复、coredump 修复等方面的优化经验。
1 背景
1.1 接手
7 月份组织架构调整后,我们组接手了搜索链路中的 Query 理解基础模块,包括本次重构对象 Query Optimizer,负责 query 的分词、词权、紧密度、意图识别。
1.2 为什么重构
面对一份10年+历史包袱较重的代码,部分开发者认为“老项目和人有一个能跑就行”,不愿意对其做较大的改动,而我们选择重构,主要有这些原因:
- 生产工具落后,无法使用现代 C++,多项监控和 TRACE 能力缺失
- 单进程内存消耗巨大——114G
- 服务不定期出现耗时毛刺
- 进程启动需要 18 分钟
- 研效低下,一个简单的功能需要开发 3 人天
基于上述原因,也缘于我们热爱挑战、勇于折腾,我们决定进行拆迁式的重构。
2 编码实现
2.1 重写与复用
我们对老 QO 的代码做分析,综合考虑三个因素:是否在使用、是否Query理解功能、是否高频迭代,将代码拆分为四种处理类型:1、删除;2、lib库引入;3、子仓库引入;4、重写引入。
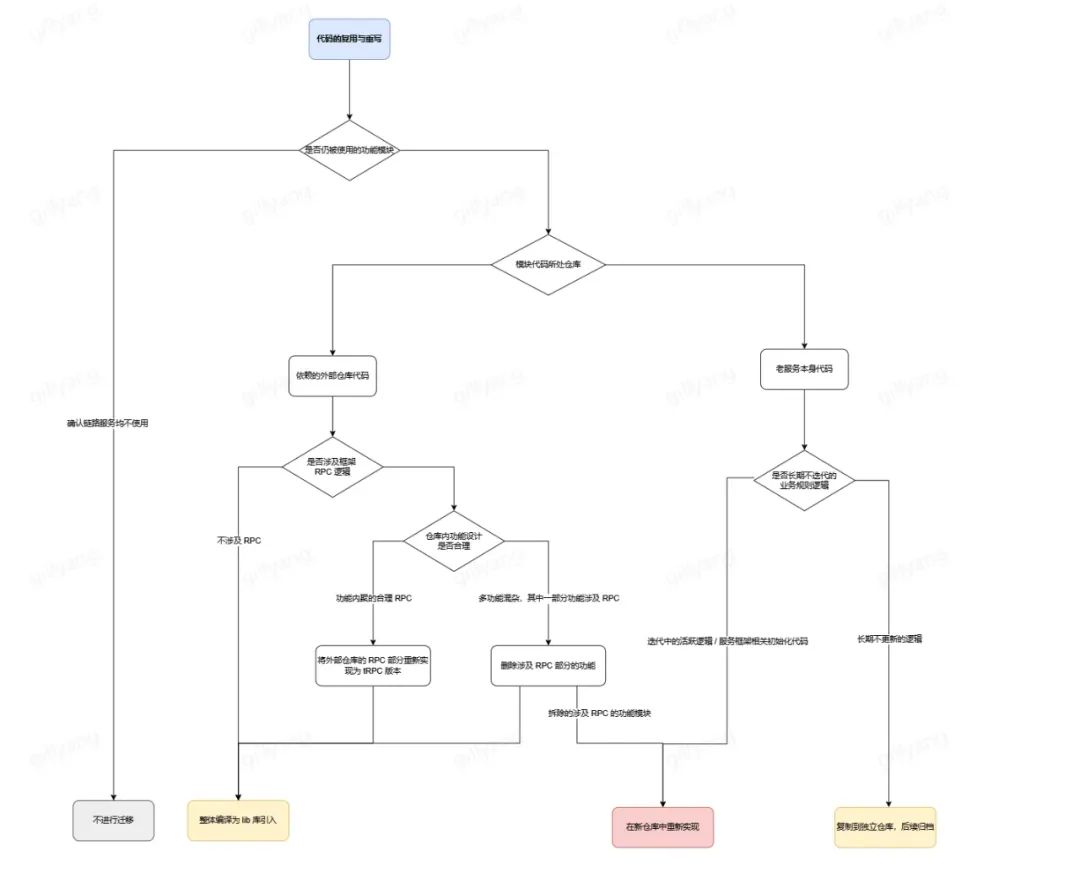
2.2 整体架构
老服务代码架构堪称灾难,整体遵守“想到哪就写到哪,需要啥就拷贝啥”的设计原则,完全不考虑单一职责、接口隔离、最少知识、模块化、封装复用等。下图介绍老服务的抽象架构:
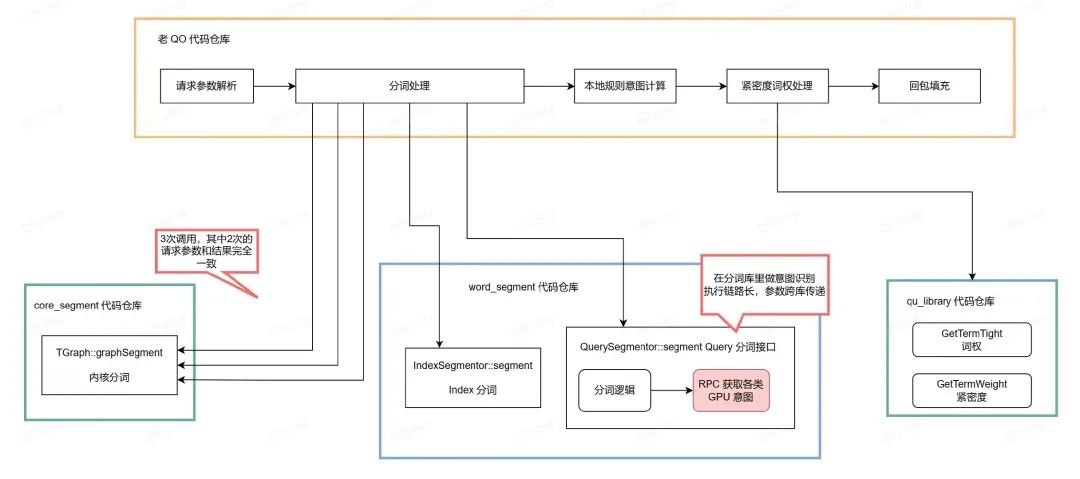
- 不带标点符号的分词结果,用于后续紧密度词权算子的计算输
- 带标点符号的分词结果,用于后续基于规则的意图算子的计算输入
- 不带标点符号的分词结果,用于最终结果 XML queryTokens 字段的输出
1 和 3 的唯一区别,就是调用内核分词的代码位置不同。
下一个环节,请求 Query 分词时,分词接口中竟然包含了 RPC 请求下游 GPU 模型服务获取意图。这是此服务迭代最频繁的功能块,当想要实验模型调整、增减意图时,需要在 QO 仓库进行实验参数解析,将参数万里长征传递到 word_segmentor 仓库的分词接口里,再根据参数修改 RPC 意图调用逻辑。一个简单参数实验,要修改 2个仓库中的多个模块。设计上不符合模块内聚的设计原理,会造成霰弹式代码修改,影响迭代效率,又因为 Query 分词是处理链路中的耗时最长步骤,不必要的串行增加了服务耗时,可谓一举三失。
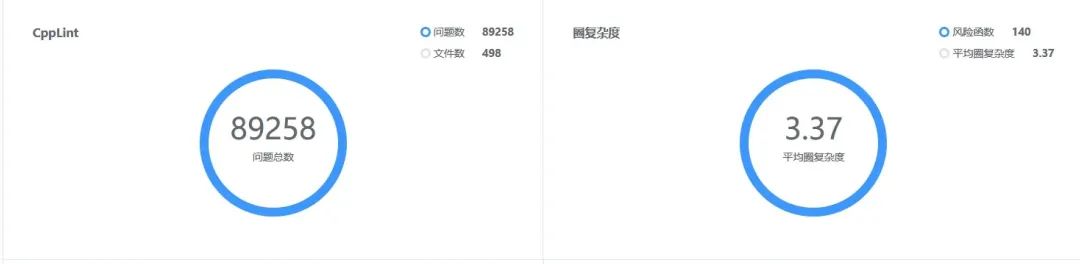
除此之外,老服务还有其他各类问题:多个函数超过一千行,圈复杂度破百,接口定义 50 多个参数并且毫无注释,代码满地随意拷贝,从以下 CodeCC 扫描结果可见一斑:

- 类和函数实现遵守单一职责原则,功能内聚;
- 接口设计符合最少知识原则,只传入所需数据;
- 每个类、接口都附上功能注释,可读性高。
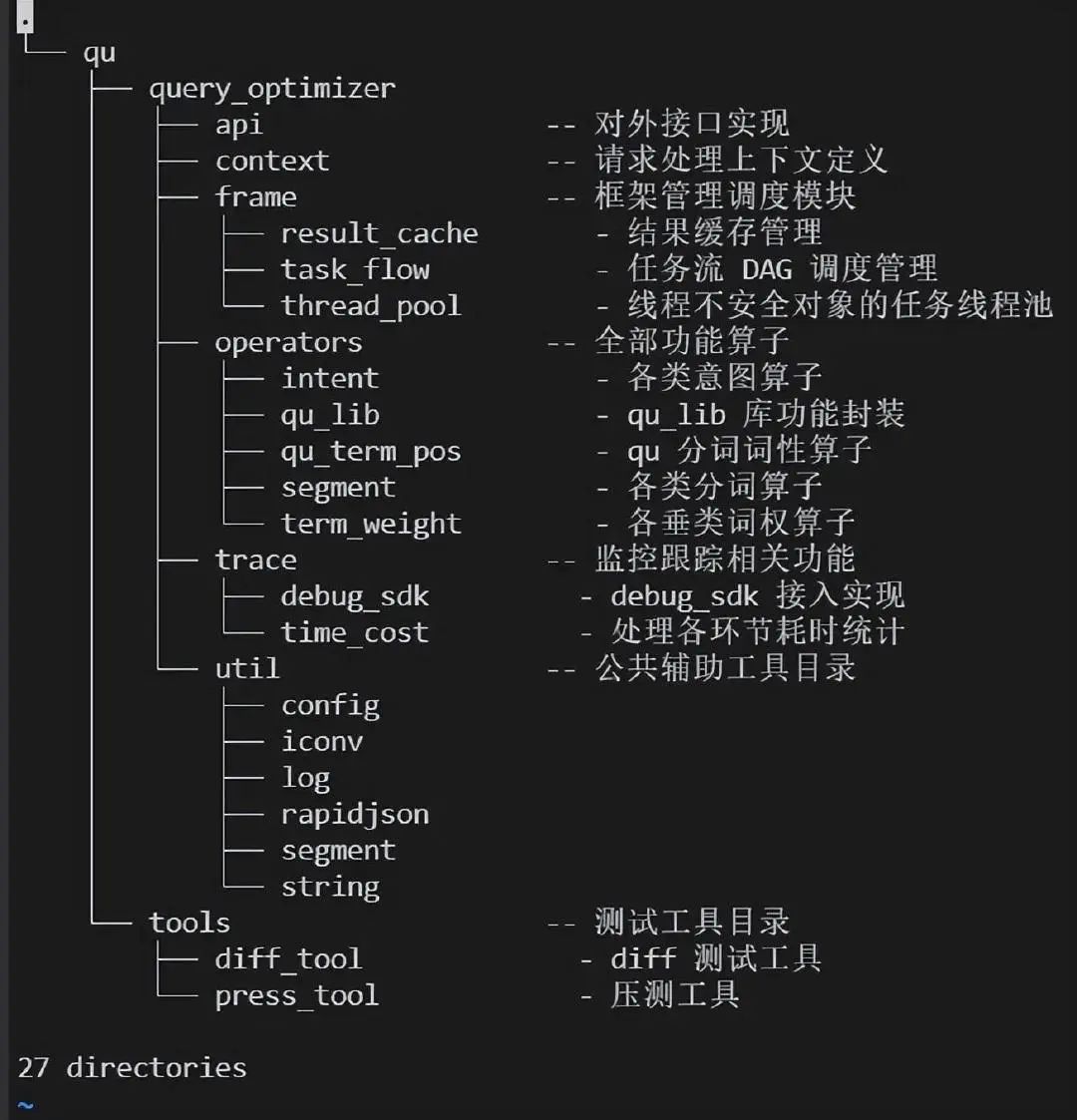
项目架构如下:

2.3 核心实现
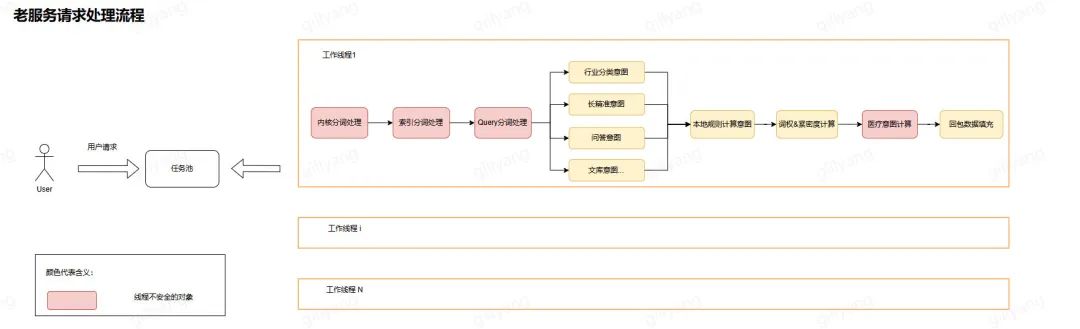
老服务的请求处理流程:
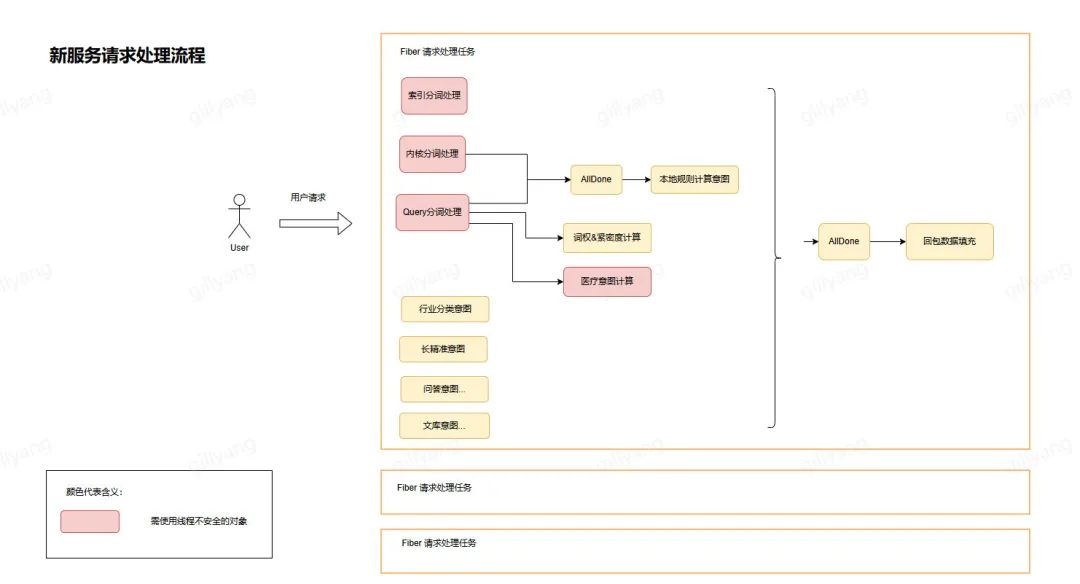
新服务中,我们实现了一套基于 tRPC Fiber 的简单 DAG 控制器:
- 用算子数初始化 FiberLatch,初始化算子任务间的依赖关系
- StartFiberDetached 启动无依赖的算子任务,FiberLatch Wait 等待全部算子完成
- 算子任务完成时,FiberLatch -1 并更新此算子的后置算子的前置依赖数
- 计算前置依赖数规 0 的任务,StartFiberDetached 启动任务
通过 DAG 调度,新服务的请求处理流程如下,最大化的提升了算子并行度,优化服务耗时:
3 DIFF 抹平
完成功能模块迁移开发后,我们进入 DIFF 测试修复期,确保新老模块产出的结果一致。原本预计一周的 DIFF 修复,实际花费三周。解决掉逻辑错误、功能缺失、字典遗漏、依赖版本不一致等问题。如何才能更快的修复 DIFF,我们总结了几个方面:DIFF 对比工具、DIFF 定位方法、常见 DIFF 原因。
3.1 DIFF 比对工具
工欲善其事必先利其器,通过比对工具找出存在 DIFF 的字段,再针对性地解决。由于老服务对外接口使用 XML 协议,我们开发基于 XML 比对的 DIFF 工具,并根据排查时遇到的问题,为工具增加了一些个性选项:基于XML解析的DIFF工具
我们根据排查时遇到的问题为工具增加了一些个性选项:
- 支持线程数量与 qps 设置(一些 DIFF 问题可能在多线程下才能复现)
- 支持单个 query 多轮比对(某些模块结果存在一定波动,譬如下游超时了或者每次计算浮点数都有一定差值,初期排查对每个query可重复请求 3-5 轮,任意一轮对上则认为无 DIFF ,待大块 DIFF 收敛后再执行单轮对比测试)
- 支持忽略浮点数漂移误差
- 在统计结果中打印出存在 DIFF 的字段名、字段值、原始 query 以便排查、手动跟踪复现
3.2 DIFF 定位方法
获取 DIFF 工具输出的统计结果后,接下来就是定位每个字段的 DIFF 原因。
3.2.1 逻辑流梳理确认
梳理计算该字段的处理流,确认是否有缺少处理步骤。对流程的梳理也有利于下面的排查。
3.2.2 对处理流的多阶段查看输入输出
一个字段的计算在处理流中一定是由多个阶段组成,检查各阶段的输入输出是否一致,以缩小排查范围,再针对性地到不一致的阶段排查细节。
例如原始的分词结果在 QO 上是调用分词库获得的,当发现最后返回的分词结果不一致时,首先查看该接口的输入与输出是否一致,如果输入输出都有 DIFF,那说明是请求处理逻辑有误,排查请求处理阶段;如果输出无 DIFF,但是最终结果有DIFF,那说明对结果的后处理中存在问题,再去排查后处理阶段。以此类推,采用二分法思想缩小排查范围,然后再到存在 DIFF 的阶段细致排查、检查代码。
查看 DIFF 常见有两种方式:日志打印比对, GDB 断点跟踪。采用日志打印的话,需要在新老服务同时加日志,发版启动服务,而老服务启动需要 18 分钟,排查效率较低。因此我们在排查过程中主要使用 GDB 深入到 so 库中打断点,对比变量值。
3.3 常见 DIFF 原因
3.3.1 外部库的请求一致,输出不一致
这是很头疼的 case,明明调用外部库接口输入的请求与老模块是完全一致的,但是从接口获取到的结果却是不一致,这种情况可能有以下原因:
- 初始化问题:遗漏关键变量初始化、遗漏字典加载、加载的字典有误,都有可能会造成该类DIFF,因为外部库不一定会因为遗漏初始化而返回错误,甚至外部库的初始化函数加载错字典都不一定会返回 false,所以对于依赖文件数据这块需要细致检查,保证需要的初始化函数及对应字典都是正确的。
有时可能知道是初始化有问题,但找不到是哪里初始化有误,此时可以用 DIFF 的 query,深入到外部库的代码中去,新老两模块一起单步调试,看看结果从哪里开始出现偏差,再根据那附近的代码推测出可能原因。
- 环境依赖:外部库往往也会有很多依赖库,如果这些依赖库版本有 DIFF,也有可能会造成计算结果 DIFF。
3.3.2 外部库的输出一致,处理后结果不一致
这种情况即是对结果的后处理存在问题,如果确认已有逻辑无误,那可能原因是老模块本地会有一些调整逻辑 或 屏蔽逻辑,把从外部库拿出来原始结果结合其他算子结果进行本地调整。例如老 QO 中的百科词权,它的原始值是分词库出的词权,结合老 QO 本地的老紧密度算子进行了 3 次结果调整才得到最终值。
3.3.3 将老模块代码重写后输出不一致
重构过程中对大量的过时写法做重写,如果怀疑是重写导致的 DIFF,可以将原始函数替代掉重写的函数测一下,确认是重写函数带来的 DIFF 后,再细致排查,实在看不出可以在原始函数上一小块一小块的重写。
3.3.4 请求输入不一致
可能原因包括:
- 缺少 query 预处理逻辑:例如 QO 输入分词库的 query 是将原始 query 的各短语经过空格分隔的,且去除了引号
- query 编码有误:例如 QO 输入分词库的 query 的编码流程经过了:utf16le → gb13080 → gchar_t (内部自定义类型) → utf16le → char16_t
- 缺少接口请求参数
3.3.5 预期内的随机 DIFF
某些库/业务逻辑自身存在预期内的不稳定,譬如排序时未使用 stable_sort,数组元素分数一致时,不能保证两次计算得出的 Top1 是同一个元素。遇到 DIFF 率较低的字段,需根据最终结果的输入值,结果计算逻辑排除业务逻辑预期内的 DIFF。
4 coredump 问题修复
在进行 DIFF 抹平测试时,我们的测试工具支持多线程并发请求测试,等于同时也在进行小规模稳定性测试。在这段期间,我们基本每天都能发现新的 coredump 问题,其中部分问题较为罕见。下面介绍我们遇到的一些典型 CASE。
4.1 栈内存被破坏,变量值随机异常
如第 2 章所述,分词库属于不涉及 RPC 且未来不迭代的模块,我们将其在 GCC 8.3.1 下编译成 so 引入。在稳定性测试时,进程会在此库的多个不同代码位置崩溃。没有修改一行代码挂载的 so,为什么老 QO 能稳定运行,而我们会花式 coredump?本质上是因为此代码历史上未重视编译告警,代码存在潜藏漏洞,升级 GCC 后才暴露出来,主要是如下两种漏洞:
- 定义了返回值的函数实际没有 return,栈内存数据异常
- sprintf 越界,栈内存数据异常
排查这类问题时,需要综合上下文检查。以下图老 QO 代码为例:
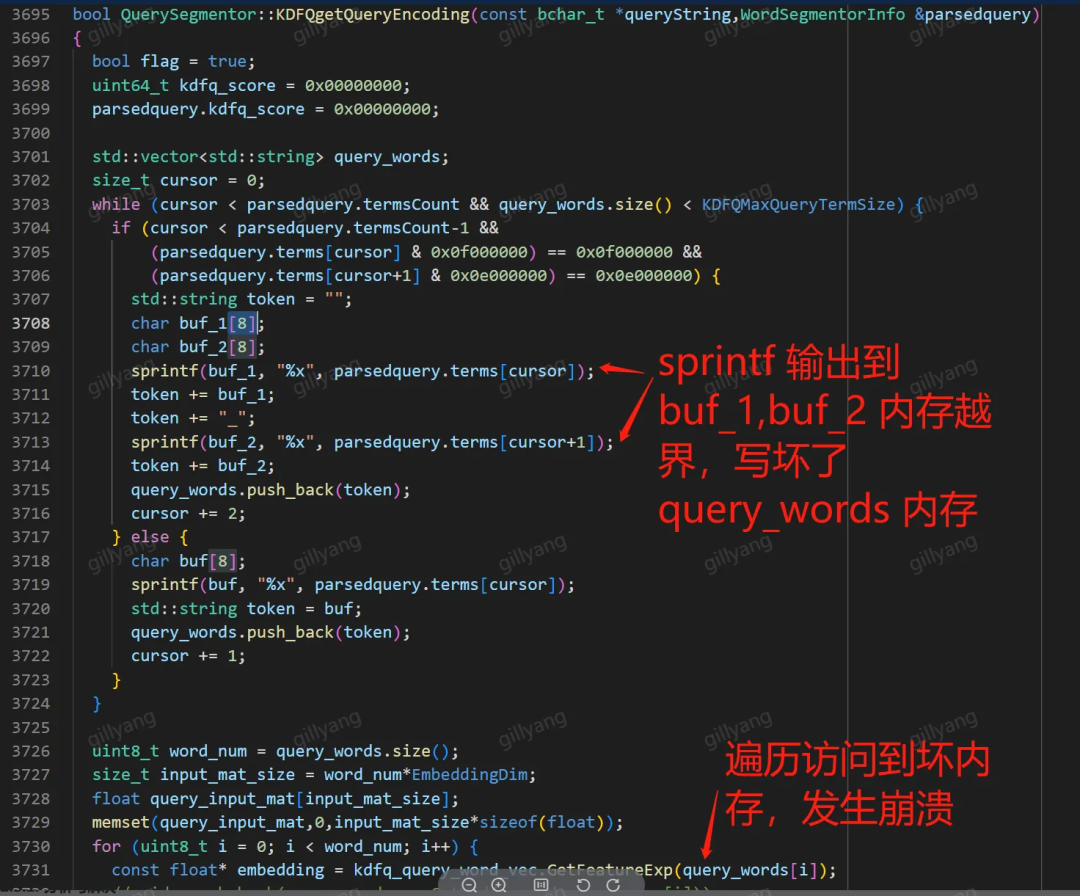
sprintf 将数字以 16 进制形式输出到 buf_1 ,输出内容占 8 个字节,加上 '\0' 实际需 9 个字节,但 buf_1 和 buf_2 都只申请了 8 个字节的空间,此处将栈内存破坏,栈上的变量 query_words 值就异常了。
异常的表现形式为,while 循环的第一轮,query_words 的数组大小是 x,下一轮 while 循环时,还没有 push 元素,数组大小就变成了 y,因内存被写坏,导致异常新增了 y - x 个不明物体。在后续逻辑中,只要访问到这几个异常元素,就会发生崩溃。
光盯着 query_words 数组,发现不了问题,因为数组的变幻直接不符合基本法。解决此类问题,需联系上下文分析,最好是将代码单独提取出来,在单元测试/本地客户端测试复现,缩小代码范围,可以更快定位问题。而当代码量较少,编译器的 warning 提示也会更加明显,辅助我们定位问题。
上段代码的编译器提示信息如下:(开启了 -Werror 编译选项)

4.2 请求处理中使用了线程不安全的对象
在代码接手时,我们看到了老的分词模块“怪异”的初始化姿势:一部分数据模型的初始化函数定义为 static 接口,在服务启动时全局调用一次;另一部分则定义为类的 public 接口,每个处理线程中构造一个对象去初始化,为什么不统一定义为 static,在服务启动时进行初始化?每个线程都持有一个对象,不是会浪费内存吗?没有深究这些问题,我们也就错过了问题的答案:因为老的分词模块是线程不安全的,一个分词对象只能同时处理一个请求。
新服务的请求处理实现是,定义全局管理器,管理器内挂载一个唯一分词对象;请求进来后统一调用此分词对象执行分词接口。当 QPS 稍高,两个请求同时进入到线程不安全的函数内部时,就可能把内存数据写坏,进而发生 coredump。
为解决此问题,我们引入了 tRPC 内支持任务窃取的 MQ 线程池,利用 c++11 的 thread_local 特性,为线程池中的每个线程都创建线程私有的分词对象。请求进入后,往线程池内抛入分词任务,单个线程同时只处理一个请求,解决了线程安全问题。
4.3 tRPC 框架使用问题
4.3.1 函数内局部变量较大 && v0.13.3 版 tRPC 无法正确设置栈大小
稳定性测试过程中,我们发现服务会概率性的 coredump 在老朋友分词 so 里,20 个字以内的 Query 可以稳定运行,超过 20 个字则有可能会崩溃,但老服务的 Query 最大长度是 40 个字。从代码来看,函数中根据 Query 长度定义了不同长度的字节数组,Query 越长,临时变量占据内存越大,那么可能是栈空间不足,引发的 coredump。
根据这个分析,我们首先尝试使用 ulimit -s 命令调整系统栈大小限制,毫无效果。经过在码客上搜寻,了解到 tRPC Fiber 模型有独立的 stack size 参数,我们又满怀希望的给框架配置加上了 fiber stack size 属性,然而还是毫无效果。
无计可施之下,我们将崩溃处相关的函数提取到本地,分别用纯粹客户端(不使用 tRPC), tRPC Future 模型, tRPC Fiber 模型承载这段代码逻辑,循环测试。结果只有 Fiber 模型的测试程序会崩溃,而 Future / 本地客户端的都可以稳定运行。
最后通过在码客咨询,得知我们选用的框架版本 Fiber Stack Size 设置功能恰好有问题,无法正确设置为业务配置值,升级版本后,问题解决。
4.3.2 Redis 连接池模式,不能同时使用一应一答和单向调用的接口
我们尝试打开结果缓存开关后,“惊喜”的发现新的 coredump,并且是 core 在了 tRPC 框架层。与 tRPC 框架开发同事协作排查,发现原因是 Redis 采取连接池模式连接时,不可同时使用一应一答接口和单向调用接口。而我们为了极致性能,在读取缓存执行 Get 命令时使用的是一应一答接口,在缓存更新执行 Set 命令时,采用的是单向调用方式,引发了 coredump。
快速解决此问题,我们将缓存更新执行 Set 命令也改为了应答调用,后续调优再改为异步 Detach 任务方式。
5 重构效果
最终,我们的成果如下:
【DIFF】
- 算子功能结果无 DIFF
【性能】
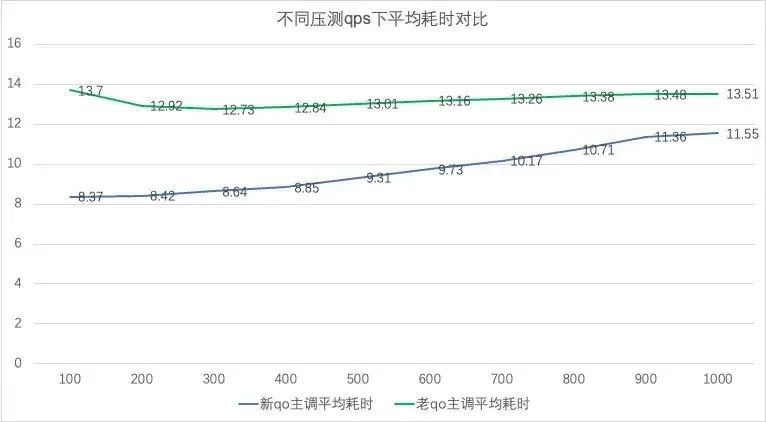
- 平均耗时:优化 28.4% (13.01 ms -> 9.31 ms)
- P99 耗时:优化 16.7%(30ms -> 25ms)
- 吞吐率:优化 12%(728qps—>832qps)
【稳定性】
- 上游主调成功率从 99.7% 提升至 99.99% ,消除不定期的 P99 毛刺问题
- 服务启动速度从 18 分钟 优化至 5 分钟
- 可观察可跟踪性提升:建设服务主调监控,缓存命中率监控,支持 trace
- 规范研发流程:单元测试覆盖率从 0% 提升至 60%+,建设完整的 CICD 流程
【成本】
- 内存使用下降 40 G(114 GB -> 76 GB)
- CPU 使用率:基本持平
- 代码量:减少 80%(25 万行—> 5万行)
【研发效率】
- 需求 LeadTime 由 3 天降低至 1 天内
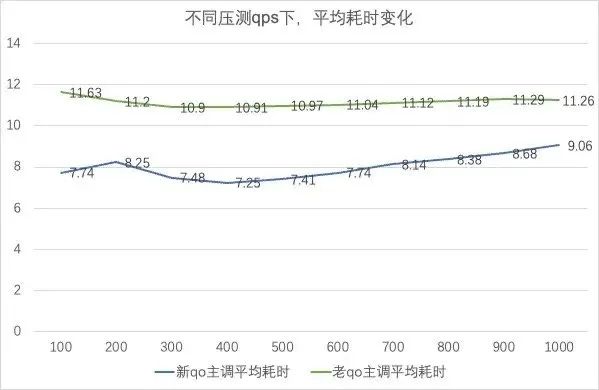
附-性能压测:
(1)不带cache:新 QO 优化平均耗时 26%(13.199ms->9.71ms),优化内存 32%(114.47G->76.7G),提高吞吐率 10%(695qps->775qps)
6 总结
重构过程中遇到的各类编码问题及解决方案的分享就到这里。如果觉得本文对您有帮助,记得收藏点赞。