Scrapy 源码分析之 Engine 模块
目录
一、问题思考
二、文档查找
三、源码分析
四、流程展示
五、总结分享
趣味模块
娜娜是一名爬虫工程师,她一直痴迷于对 scrapy 源码的了解认识。虽然她知道 scrapy 的整个运行流程,但是从未阅读过 scrapy 作者的代码,她很好奇 scrapy 五大模块中的 engine 到底是如何运转的。今天为了满足娜娜的好奇心,我们进入 scrapy engine 模块源码分析环节吧!
一、问题思考
Question
①在 scrapy 框架中,engine 充当的角色是什么?
Question
②engine 是如何配合整个 scrapy 运行的?
Question
③scrapy engine 如何启动、停止和关闭?
Question
④现在还能否画出 scrapy 的运行流程图以及 engine 的具体位置?
前言:那么带着这些问题,接下来我们对 Scrapy engine 源码进行分析探索吧,我相信这篇文章会让大家受益匪浅!
二、文档查找
1、查看官网文档,搜索指定的模块 engine,搜索结果如下:
2、点击搜索结果,查看官方对当前模块的说明解释截图如下:

说明:观察上面的截图内容,我们发现文档里有关 engine 模块具体的功能还是不够清晰,接下来我们进入源码分析环节吧。
三、源码分析
engine.py 提供了 2 个类,Slot 和 ExecutionEngine,源码如下:
import logging
import warnings
from time import time
from typing import Callable, Iterable, Iterator, Optional, Set, Union
from twisted.internet.defer import Deferred, inlineCallbacks, succeed
from twisted.internet.task import LoopingCall
from twisted.python.failure import Failure
from scrapy import signals
from scrapy.core.scraper import Scraper
from scrapy.exceptions import (
CloseSpider,
DontCloseSpider,
ScrapyDeprecationWarning,
)
from scrapy.http import Response, Request
from scrapy.settings import BaseSettings
from scrapy.spiders import Spider
from scrapy.utils.log import logformatter_adapter, failure_to_exc_info
from scrapy.utils.misc import create_instance, load_object
from scrapy.utils.reactor import CallLaterOnce
logger = logging.getLogger(__name__)
class Slot:
def __init__(
self,
start_requests: Iterable,
close_if_idle: bool,
nextcall: CallLaterOnce,
scheduler,
) -> None:
self.closing: Optional[Deferred] = None
self.inprogress: Set[Request] = set()
self.start_requests: Optional[Iterator] = iter(start_requests)
self.close_if_idle = close_if_idle
self.nextcall = nextcall
self.scheduler = scheduler
self.heartbeat = LoopingCall(nextcall.schedule)
def add_request(self, request: Request) -> None:
self.inprogress.add(request)
def remove_request(self, request: Request) -> None:
self.inprogress.remove(request)
self._maybe_fire_closing()
def close(self) -> Deferred:
self.closing = Deferred()
self._maybe_fire_closing()
return self.closing
def _maybe_fire_closing(self) -> None:
if self.closing is not None and not self.inprogress:
if self.nextcall:
self.nextcall.cancel()
if self.heartbeat.running:
self.heartbeat.stop()
self.closing.callback(None)
class ExecutionEngine:
def __init__(self, crawler, spider_closed_callback: Callable) -> None:
self.crawler = crawler
self.settings = crawler.settings
self.signals = crawler.signals
self.logformatter = crawler.logformatter
self.slot: Optional[Slot] = None
self.spider: Optional[Spider] = None
self.running = False
self.paused = False
self.scheduler_cls = self._get_scheduler_class(crawler.settings)
downloader_cls = load_object(self.settings['DOWNLOADER'])
self.downloader = downloader_cls(crawler)
self.scraper = Scraper(crawler)
self._spider_closed_callback = spider_closed_callback
def _get_scheduler_class(self, settings: BaseSettings) -> type:
from scrapy.core.scheduler import BaseScheduler
scheduler_cls = load_object(settings["SCHEDULER"])
if not issubclass(scheduler_cls, BaseScheduler):
raise TypeError(
f"The provided scheduler class ({settings['SCHEDULER']})"
" does not fully implement the scheduler interface"
)
return scheduler_cls
@inlineCallbacks
def start(self) -> Deferred:
if self.running:
raise RuntimeError("Engine already running")
self.start_time = time()
yield self.signals.send_catch_log_deferred(signal=signals.engine_started)
self.running = True
self._closewait = Deferred()
yield self._closewait
def stop(self) -> Deferred:
"""Gracefully stop the execution engine"""
@inlineCallbacks
def _finish_stopping_engine(_) -> Deferred:
yield self.signals.send_catch_log_deferred(signal=signals.engine_stopped)
self._closewait.callback(None)
if not self.running:
raise RuntimeError("Engine not running")
self.running = False
dfd = self.close_spider(self.spider, reason="shutdown") if self.spider is not None else succeed(None)
return dfd.addBoth(_finish_stopping_engine)
def close(self) -> Deferred:
"""
Gracefully close the execution engine.
If it has already been started, stop it. In all cases, close the spider and the downloader.
"""
if self.running:
return self.stop() # will also close spider and downloader
if self.spider is not None:
return self.close_spider(self.spider, reason="shutdown") # will also close downloader
return succeed(self.downloader.close())
def pause(self) -> None:
self.paused = True
def unpause(self) -> None:
self.paused = False
def _next_request(self) -> None:
assert self.slot is not None # typing
assert self.spider is not None # typing
if self.paused:
return None
while not self._needs_backout() and self._next_request_from_scheduler() is not None:
pass
if self.slot.start_requests is not None and not self._needs_backout():
try:
request = next(self.slot.start_requests)
except StopIteration:
self.slot.start_requests = None
except Exception:
self.slot.start_requests = None
logger.error('Error while obtaining start requests', exc_info=True, extra={'spider': self.spider})
else:
self.crawl(request)
if self.spider_is_idle() and self.slot.close_if_idle:
self._spider_idle()
def _needs_backout(self) -> bool:
return (
not self.running
or self.slot.closing # type: ignore[union-attr]
or self.downloader.needs_backout()
or self.scraper.slot.needs_backout() # type: ignore[union-attr]
)
def _next_request_from_scheduler(self) -> Optional[Deferred]:
assert self.slot is not None # typing
assert self.spider is not None # typing
request = self.slot.scheduler.next_request()
if request is None:
return None
d = self._download(request, self.spider)
d.addBoth(self._handle_downloader_output, request)
d.addErrback(lambda f: logger.info('Error while handling downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': self.spider}))
d.addBoth(lambda _: self.slot.remove_request(request))
d.addErrback(lambda f: logger.info('Error while removing request from slot',
exc_info=failure_to_exc_info(f),
extra={'spider': self.spider}))
d.addBoth(lambda _: self.slot.nextcall.schedule())
d.addErrback(lambda f: logger.info('Error while scheduling new request',
exc_info=failure_to_exc_info(f),
extra={'spider': self.spider}))
return d
def _handle_downloader_output(
self, result: Union[Request, Response, Failure], request: Request
) -> Optional[Deferred]:
assert self.spider is not None # typing
if not isinstance(result, (Request, Response, Failure)):
raise TypeError(f"Incorrect type: expected Request, Response or Failure, got {type(result)}: {result!r}")
# downloader middleware can return requests (for example, redirects)
if isinstance(result, Request):
self.crawl(result)
return None
d = self.scraper.enqueue_scrape(result, request, self.spider)
d.addErrback(
lambda f: logger.error(
"Error while enqueuing downloader output",
exc_info=failure_to_exc_info(f),
extra={'spider': self.spider},
)
)
return d
def spider_is_idle(self, spider: Optional[Spider] = None) -> bool:
if spider is not None:
warnings.warn(
"Passing a 'spider' argument to ExecutionEngine.spider_is_idle is deprecated",
category=ScrapyDeprecationWarning,
stacklevel=2,
)
if self.slot is None:
raise RuntimeError("Engine slot not assigned")
if not self.scraper.slot.is_idle(): # type: ignore[union-attr]
return False
if self.downloader.active: # downloader has pending requests
return False
if self.slot.start_requests is not None: # not all start requests are handled
return False
if self.slot.scheduler.has_pending_requests():
return False
return True
def crawl(self, request: Request, spider: Optional[Spider] = None) -> None:
"""Inject the request into the spider <-> downloader pipeline"""
if spider is not None:
warnings.warn(
"Passing a 'spider' argument to ExecutionEngine.crawl is deprecated",
category=ScrapyDeprecationWarning,
stacklevel=2,
)
if spider is not self.spider:
raise RuntimeError(f"The spider {spider.name!r} does not match the open spider")
if self.spider is None:
raise RuntimeError(f"No open spider to crawl: {request}")
self._schedule_request(request, self.spider)
self.slot.nextcall.schedule() # type: ignore[union-attr]
def _schedule_request(self, request: Request, spider: Spider) -> None:
self.signals.send_catch_log(signals.request_scheduled, request=request, spider=spider)
if not self.slot.scheduler.enqueue_request(request): # type: ignore[union-attr]
self.signals.send_catch_log(signals.request_dropped, request=request, spider=spider)
def download(self, request: Request, spider: Optional[Spider] = None) -> Deferred:
"""Return a Deferred which fires with a Response as result, only downloader middlewares are applied"""
if spider is None:
spider = self.spider
else:
warnings.warn(
"Passing a 'spider' argument to ExecutionEngine.download is deprecated",
category=ScrapyDeprecationWarning,
stacklevel=2,
)
if spider is not self.spider:
logger.warning("The spider '%s' does not match the open spider", spider.name)
if spider is None:
raise RuntimeError(f"No open spider to crawl: {request}")
return self._download(request, spider).addBoth(self._downloaded, request, spider)
def _downloaded(
self, result: Union[Response, Request], request: Request, spider: Spider
) -> Union[Deferred, Response]:
assert self.slot is not None # typing
self.slot.remove_request(request)
return self.download(result, spider) if isinstance(result, Request) else result
def _download(self, request: Request, spider: Spider) -> Deferred:
assert self.slot is not None # typing
self.slot.add_request(request)
def _on_success(result: Union[Response, Request]) -> Union[Response, Request]:
if not isinstance(result, (Response, Request)):
raise TypeError(f"Incorrect type: expected Response or Request, got {type(result)}: {result!r}")
if isinstance(result, Response):
if result.request is None:
result.request = request
logkws = self.logformatter.crawled(result.request, result, spider)
if logkws is not None:
logger.log(*logformatter_adapter(logkws), extra={"spider": spider})
self.signals.send_catch_log(
signal=signals.response_received,
response=result,
request=result.request,
spider=spider,
)
return result
def _on_complete(_):
self.slot.nextcall.schedule()
return _
dwld = self.downloader.fetch(request, spider)
dwld.addCallbacks(_on_success)
dwld.addBoth(_on_complete)
return dwld
@inlineCallbacks
def open_spider(self, spider: Spider, start_requests: Iterable = (), close_if_idle: bool = True):
if self.slot is not None:
raise RuntimeError(f"No free spider slot when opening {spider.name!r}")
logger.info("Spider opened", extra={'spider': spider})
nextcall = CallLaterOnce(self._next_request)
scheduler = create_instance(self.scheduler_cls, settings=None, crawler=self.crawler)
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
self.slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.spider = spider
if hasattr(scheduler, "open"):
yield scheduler.open(spider)
yield self.scraper.open_spider(spider)
self.crawler.stats.open_spider(spider)
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
self.slot.nextcall.schedule()
self.slot.heartbeat.start(5)
def _spider_idle(self) -> None:
"""
Called when a spider gets idle, i.e. when there are no remaining requests to download or schedule.
It can be called multiple times. If a handler for the spider_idle signal raises a DontCloseSpider
exception, the spider is not closed until the next loop and this function is guaranteed to be called
(at least) once again. A handler can raise CloseSpider to provide a custom closing reason.
"""
assert self.spider is not None # typing
expected_ex = (DontCloseSpider, CloseSpider)
res = self.signals.send_catch_log(signals.spider_idle, spider=self.spider, dont_log=expected_ex)
detected_ex = {
ex: x.value
for _, x in res
for ex in expected_ex
if isinstance(x, Failure) and isinstance(x.value, ex)
}
if DontCloseSpider in detected_ex:
return None
if self.spider_is_idle():
ex = detected_ex.get(CloseSpider, CloseSpider(reason='finished'))
assert isinstance(ex, CloseSpider) # typing
self.close_spider(self.spider, reason=ex.reason)
def close_spider(self, spider: Spider, reason: str = "cancelled") -> Deferred:
"""Close (cancel) spider and clear all its outstanding requests"""
if self.slot is None:
raise RuntimeError("Engine slot not assigned")
if self.slot.closing is not None:
return self.slot.closing
logger.info("Closing spider (%(reason)s)", {'reason': reason}, extra={'spider': spider})
dfd = self.slot.close()
def log_failure(msg: str) -> Callable:
def errback(failure: Failure) -> None:
logger.error(msg, exc_info=failure_to_exc_info(failure), extra={'spider': spider})
return errback
dfd.addBoth(lambda _: self.downloader.close())
dfd.addErrback(log_failure('Downloader close failure'))
dfd.addBoth(lambda _: self.scraper.close_spider(spider))
dfd.addErrback(log_failure('Scraper close failure'))
if hasattr(self.slot.scheduler, "close"):
dfd.addBoth(lambda _: self.slot.scheduler.close(reason))
dfd.addErrback(log_failure("Scheduler close failure"))
dfd.addBoth(lambda _: self.signals.send_catch_log_deferred(
signal=signals.spider_closed, spider=spider, reason=reason,
))
dfd.addErrback(log_failure('Error while sending spider_close signal'))
dfd.addBoth(lambda _: self.crawler.stats.close_spider(spider, reason=reason))
dfd.addErrback(log_failure('Stats close failure'))
dfd.addBoth(lambda _: logger.info("Spider closed (%(reason)s)", {'reason': reason}, extra={'spider': spider}))
dfd.addBoth(lambda _: setattr(self, 'slot', None))
dfd.addErrback(log_failure('Error while unassigning slot'))
dfd.addBoth(lambda _: setattr(self, 'spider', None))
dfd.addErrback(log_failure('Error while unassigning spider'))
dfd.addBoth(lambda _: self._spider_closed_callback(spider))
return dfd
@property
def open_spiders(self) -> list:
warnings.warn(
"ExecutionEngine.open_spiders is deprecated, please use ExecutionEngine.spider instead",
category=ScrapyDeprecationWarning,
stacklevel=2,
)
return [self.spider] if self.spider is not None else []
def has_capacity(self) -> bool:
warnings.warn("ExecutionEngine.has_capacity is deprecated", ScrapyDeprecationWarning, stacklevel=2)
return not bool(self.slot)
def schedule(self, request: Request, spider: Spider) -> None:
warnings.warn(
"ExecutionEngine.schedule is deprecated, please use "
"ExecutionEngine.crawl or ExecutionEngine.download instead",
category=ScrapyDeprecationWarning,
stacklevel=2,
)
if self.slot is None:
raise RuntimeError("Engine slot not assigned")
self._schedule_request(request, spider)环节说明:代码一共也就413行,但是却在scrapy架构中起到了核心作用。在好奇心的驱使下,我们还是对源码进行一一讲解分析吧。
- Slot类源码分析
# slot代表一次nextcall的执行,实际上就是执行一次engine的_next_request。
# slot创建了一个hearbeat,即为一个心跳。通过twisted的task.LoopingCall实现。
# 每隔5s执行一次,尝试处理一个新的request,这属于被动执行。后面还会有主动执行的代码。
# slot可以理解为一个request的生命周期。
class Slot:
def __init__(
self,
start_requests: Iterable,
close_if_idle: bool,
nextcall: CallLaterOnce,
scheduler,
) -> None:
self.closing: Optional[Deferred] = None
self.inprogress: Set[Request] = set() # 请求正在处理set集合
self.start_requests: Optional[Iterator] = iter(start_requests)
self.close_if_idle = close_if_idle
self.nextcall = nextcall # 实际为执行engine的_next_request方法
self.scheduler = scheduler # 调度器对象
self.heartbeat = LoopingCall(nextcall.schedule) # 创建心跳
def add_request(self, request: Request) -> None:
self.inprogress.add(request) # 添加处理状态
def remove_request(self, request: Request) -> None:
self.inprogress.remove(request) # 移除请求
self._maybe_fire_closing()
def close(self) -> Deferred:
self.closing = Deferred()
self._maybe_fire_closing()
return self.closing
def _maybe_fire_closing(self) -> None:
# 关闭开关没有开启并且没有正在处理的请求,就执行调度
if self.closing is not None and not self.inprogress:
if self.nextcall:
self.nextcall.cancel()
if self.heartbeat.running:
self.heartbeat.stop() # 关闭心跳
self.closing.callback(None)
说明:Slot 模块提供了四个方法,分别是:添加请求、删除请求、关闭自己、触发关闭方法。它使用了 Twisted 的主循环 reactor 来不断的调度执行 Engine的"_next_request"方法,这个方法其实是 scrapy 的核心循环方法;另外 slot 也用于跟踪正在进行下载的 request。
- ExecutionEngine 类源码分析
class ExecutionEngine:
# 接受crawler爬虫,spider_close_callback 完成初始化工作
# 接受初始化的几个参数,设置、信号、日志格式、从crawler那里获取到,从设置中加载日志调度类,从设置加载下载类
# 其中的设置scheduler_cls, downloader_cls, 默认值可以从default_settings.py获取
# SCHEDULER = 'scrapy.core.scheduler.Scheduler'
# DOWNLOADER = 'scrapy.core.downloader.Downloader'
def __init__(self, crawler, spider_closed_callback: Callable) -> None:
self.crawler = crawler
self.settings = crawler.settings
self.signals = crawler.signals
self.logformatter = crawler.logformatter
self.slot: Optional[Slot] = None
self.spider: Optional[Spider] = None
self.running = False
self.paused = False
self.scheduler_cls = self._get_scheduler_class(crawler.settings)
downloader_cls = load_object(self.settings['DOWNLOADER'])
self.downloader = downloader_cls(crawler) # 下载器对象
self.scraper = Scraper(crawler)
self._spider_closed_callback = spider_closed_callback
# 加载settings.py中调度器的class类
def _get_scheduler_class(self, settings: BaseSettings) -> type:
from scrapy.core.scheduler import BaseScheduler
scheduler_cls = load_object(settings["SCHEDULER"])
if not issubclass(scheduler_cls, BaseScheduler):
raise TypeError(
f"The provided scheduler class ({settings['SCHEDULER']})"
" does not fully implement the scheduler interface"
)
return scheduler_cls
@inlineCallbacks
def start(self) -> Deferred:
# 启动爬虫引擎,方法上面带了个装饰器 @defer.inlineCallbacks
if self.running:
raise RuntimeError("Engine already running")
# 记录启动时间;发送一个"engine_started"消息;设置running标志;创建一个_closewait的Deferred对象并返回。
self.start_time = time()
yield self.signals.send_catch_log_deferred(signal=signals.engine_started)
self.running = True
# 这个Deferred在引擎结束时才会调用,因此用它来向CrawlerProcess通知一个Crawler已经爬取完毕。
self._closewait = Deferred()
# 这个_closewait会返回给CrawlerProcess类
yield self._closewait
def stop(self) -> Deferred: # 优雅的停止执行引擎
"""Gracefully stop the execution engine"""
@inlineCallbacks
def _finish_stopping_engine(_) -> Deferred:
yield self.signals.send_catch_log_deferred(signal=signals.engine_stopped)
self._closewait.callback(None) # 回调空信息
if not self.running: # 没有运行状态,抛出异常
raise RuntimeError("Engine not running")
# 标记状态running为false, 关闭所有的爬虫, 调用_finish_stopping_engine方法
self.running = False
dfd = self.close_spider(self.spider, reason="shutdown") if self.spider is not None else succeed(None)
return dfd.addBoth(_finish_stopping_engine)
def close(self) -> Deferred:
"""
Gracefully close the execution engine.
If it has already been started, stop it. In all cases, close the spider and the downloader.
"""
# 优雅的关闭执行引擎,完成引擎的关闭工作,其他情况下,关闭爬虫和下载器
if self.running:
return self.stop() # will also close spider and downloader
if self.spider is not None:
return self.close_spider(self.spider, reason="shutdown") # will also close downloader
return succeed(self.downloader.close())
def pause(self) -> None: # 暂停执行引擎
self.paused = True
# 解除引擎的暂停
def unpause(self) -> None:
self.paused = False
def _next_request(self) -> None:
# 执行下次请求
assert self.slot is not None # typing
assert self.spider is not None # typing
if self.paused: # 判断暂停状态
return None
# 爬虫没有处理完毕并且调度的请求不为空,等待请求处理
while not self._needs_backout() and self._next_request_from_scheduler() is not None:
pass
# start_requests请求不为空并且爬虫没有处理完毕
if self.slot.start_requests is not None and not self._needs_backout():
try:
# 调用next方法获取yield迭代器中请求对象
request = next(self.slot.start_requests)
except StopIteration:
self.slot.start_requests = None
except Exception:
self.slot.start_requests = None
logger.error('Error while obtaining start requests', exc_info=True, extra={'spider': self.spider})
else:
self.crawl(request) # 调用crawl方法去抓取
# 如果爬虫是空闲的,并且爬虫空闲为true,调用_spider_idle方法。
if self.spider_is_idle() and self.slot.close_if_idle:
self._spider_idle()
def _needs_backout(self) -> bool: # 返回一个布尔值
"""
# 如果引擎关闭则返回true, 或者slot关闭,或者下载器那里返回了true, 或者爬虫那里返回true,
# 后面的那2个needs_backout需要具体到downloader, scrper类里面去看。
# 我们可以对这个方法的理解为没有接下来的工作了就返回true
"""
return (
not self.running
or self.slot.closing # type: ignore[union-attr]
or self.downloader.needs_backout()
or self.scraper.slot.needs_backout() # type: ignore[union-attr]
)
# 从调度器获取下一个请求, 判断request,下载请求
def _next_request_from_scheduler(self) -> Optional[Deferred]:
assert self.slot is not None # typing
assert self.spider is not None # typing
request = self.slot.scheduler.next_request()
if request is None:
return None
d = self._download(request, self.spider)
d.addBoth(self._handle_downloader_output, request)
d.addErrback(lambda f: logger.info('Error while handling downloader output',
exc_info=failure_to_exc_info(f),
extra={'spider': self.spider}))
d.addBoth(lambda _: self.slot.remove_request(request))
d.addErrback(lambda f: logger.info('Error while removing request from slot',
exc_info=failure_to_exc_info(f),
extra={'spider': self.spider}))
d.addBoth(lambda _: self.slot.nextcall.schedule())
d.addErrback(lambda f: logger.info('Error while scheduling new request',
exc_info=failure_to_exc_info(f),
extra={'spider': self.spider}))
return d
# 处理下载的输出
def _handle_downloader_output(
self, result: Union[Request, Response, Failure], request: Request
) -> Optional[Deferred]:
assert self.spider is not None # typing
if not isinstance(result, (Request, Response, Failure)):
raise TypeError(f"Incorrect type: expected Request, Response or Failure, got {type(result)}: {result!r}")
# downloader middleware can return requests (for example, redirects)
# 如果result是Request对象,则调用crawl方法
if isinstance(result, Request):
self.crawl(result)
return None
# 否则调用enqueue_scrape方法处理下载结果
d = self.scraper.enqueue_scrape(result, request, self.spider)
d.addErrback(
lambda f: logger.error(
"Error while enqueuing downloader output",
exc_info=failure_to_exc_info(f),
extra={'spider': self.spider},
)
)
return d
# 判定slot空闲,判定下载空闲,判定请求为空,判定调度器没有要处理的请求
def spider_is_idle(self, spider: Optional[Spider] = None) -> bool:
if spider is not None:
warnings.warn(
"Passing a 'spider' argument to ExecutionEngine.spider_is_idle is deprecated",
category=ScrapyDeprecationWarning,
stacklevel=2,
)
if self.slot is None:
raise RuntimeError("Engine slot not assigned")
if not self.scraper.slot.is_idle(): # type: ignore[union-attr]
return False
if self.downloader.active: # downloader has pending requests
return False
if self.slot.start_requests is not None: # not all start requests are handled
return False
if self.slot.scheduler.has_pending_requests():
return False
return True
# 爬取,执行调度,执行回调的调度
def crawl(self, request: Request, spider: Optional[Spider] = None) -> None:
"""Inject the request into the spider <-> downloader pipeline"""
if spider is not None:
warnings.warn(
"Passing a 'spider' argument to ExecutionEngine.crawl is deprecated",
category=ScrapyDeprecationWarning,
stacklevel=2,
)
if spider is not self.spider:
raise RuntimeError(f"The spider {spider.name!r} does not match the open spider")
if self.spider is None:
raise RuntimeError(f"No open spider to crawl: {request}")
self._schedule_request(request, self.spider)
self.slot.nextcall.schedule() # type: ignore[union-attr]
# 开始调度请求,触发enqueue_request函数,则触发请求丢弃事件。
def _schedule_request(self, request: Request, spider: Spider) -> None:
self.signals.send_catch_log(signals.request_scheduled, request=request, spider=spider)
if not self.slot.scheduler.enqueue_request(request): # type: ignore[union-attr]
self.signals.send_catch_log(signals.request_dropped, request=request, spider=spider)
# 请求下载回调,调用内部方法_download
def download(self, request: Request, spider: Optional[Spider] = None) -> Deferred:
"""Return a Deferred which fires with a Response as result, only downloader middlewares are applied"""
if spider is None:
spider = self.spider
else:
warnings.warn(
"Passing a 'spider' argument to ExecutionEngine.download is deprecated",
category=ScrapyDeprecationWarning,
stacklevel=2,
)
if spider is not self.spider:
logger.warning("The spider '%s' does not match the open spider", spider.name)
if spider is None:
raise RuntimeError(f"No open spider to crawl: {request}")
return self._download(request, spider).addBoth(self._downloaded, request, spider)
# 内部方法
def _downloaded(
self, result: Union[Response, Request], request: Request, spider: Spider
) -> Union[Deferred, Response]:
assert self.slot is not None # typing
self.slot.remove_request(request)
return self.download(result, spider) if isinstance(result, Request) else result
"""
1. 添加请求,定义一个成功的方法、一个完成的方法,从下载器里面提取对象, getaway添加成功回调,添加完成。
2. addcallbacks 接受一个成功的回调方法, 一个失败的回调方法。
3. addBoth函数向callback与errback链中添加了相同的回调函数。
"""
def _download(self, request: Request, spider: Spider) -> Deferred:
assert self.slot is not None # typing
self.slot.add_request(request)
def _on_success(result: Union[Response, Request]) -> Union[Response, Request]:
if not isinstance(result, (Response, Request)):
raise TypeError(f"Incorrect type: expected Response or Request, got {type(result)}: {result!r}")
if isinstance(result, Response):
if result.request is None:
result.request = request
logkws = self.logformatter.crawled(result.request, result, spider)
if logkws is not None:
logger.log(*logformatter_adapter(logkws), extra={"spider": spider})
self.signals.send_catch_log(
signal=signals.response_received,
response=result,
request=result.request,
spider=spider,
)
return result
def _on_complete(_):
self.slot.nextcall.schedule()
return _
dwld = self.downloader.fetch(request, spider)
dwld.addCallbacks(_on_success)
dwld.addBoth(_on_complete)
return dwld
@inlineCallbacks # 打开爬虫执行的逻辑
def open_spider(self, spider: Spider, start_requests: Iterable = (), close_if_idle: bool = True):
# 通过crawler构造scheduler调度器,构造slot对象,调度器打开爬虫,爬虫打开,触发爬虫打开事件,启动心跳信息。
if self.slot is not None:
raise RuntimeError(f"No free spider slot when opening {spider.name!r}")
logger.info("Spider opened", extra={'spider': spider})
nextcall = CallLaterOnce(self._next_request)
scheduler = create_instance(self.scheduler_cls, settings=None, crawler=self.crawler)
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
self.slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.spider = spider
if hasattr(scheduler, "open"):
yield scheduler.open(spider)
yield self.scraper.open_spider(spider)
self.crawler.stats.open_spider(spider)
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
self.slot.nextcall.schedule()
self.slot.heartbeat.start(5) # 默认5秒
def _spider_idle(self) -> None:
"""
当爬虫空闲时调用。在没有剩余的页面可供下载或调度时,调用此函数。可以称之为
多次。如果某个扩展引发DontCloseSpider异常(在spider_idle信号处理器中)直到
下一个循环这个爬虫才关闭,这个函数保证爬虫被调用(至少)一次。
"""
assert self.spider is not None # typing
expected_ex = (DontCloseSpider, CloseSpider)
res = self.signals.send_catch_log(signals.spider_idle, spider=self.spider, dont_log=expected_ex)
detected_ex = {
ex: x.value
for _, x in res
for ex in expected_ex
if isinstance(x, Failure) and isinstance(x.value, ex)
}
if DontCloseSpider in detected_ex:
return None
if self.spider_is_idle():
ex = detected_ex.get(CloseSpider, CloseSpider(reason='finished'))
assert isinstance(ex, CloseSpider) # typing
self.close_spider(self.spider, reason=ex.reason)
# 关闭(取消)spider并清除所有未完成的请求
def close_spider(self, spider: Spider, reason: str = "cancelled") -> Deferred:
"""Close (cancel) spider and clear all its outstanding requests"""
if self.slot is None:
raise RuntimeError("Engine slot not assigned")
if self.slot.closing is not None:
return self.slot.closing
logger.info("Closing spider (%(reason)s)", {'reason': reason}, extra={'spider': spider})
dfd = self.slot.close()
def log_failure(msg: str) -> Callable:
def errback(failure: Failure) -> None:
logger.error(msg, exc_info=failure_to_exc_info(failure), extra={'spider': spider})
return errback
dfd.addBoth(lambda _: self.downloader.close())
dfd.addErrback(log_failure('Downloader close failure'))
dfd.addBoth(lambda _: self.scraper.close_spider(spider))
dfd.addErrback(log_failure('Scraper close failure'))
if hasattr(self.slot.scheduler, "close"):
dfd.addBoth(lambda _: self.slot.scheduler.close(reason))
dfd.addErrback(log_failure("Scheduler close failure"))
dfd.addBoth(lambda _: self.signals.send_catch_log_deferred(
signal=signals.spider_closed, spider=spider, reason=reason,
))
dfd.addErrback(log_failure('Error while sending spider_close signal'))
dfd.addBoth(lambda _: self.crawler.stats.close_spider(spider, reason=reason))
dfd.addErrback(log_failure('Stats close failure'))
dfd.addBoth(lambda _: logger.info("Spider closed (%(reason)s)", {'reason': reason}, extra={'spider': spider}))
dfd.addBoth(lambda _: setattr(self, 'slot', None))
dfd.addErrback(log_failure('Error while unassigning slot'))
dfd.addBoth(lambda _: setattr(self, 'spider', None))
dfd.addErrback(log_failure('Error while unassigning spider'))
dfd.addBoth(lambda _: self._spider_closed_callback(spider))
return dfd
@property # 打开爬虫
def open_spiders(self) -> list:
warnings.warn(
"ExecutionEngine.open_spiders is deprecated, please use ExecutionEngine.spider instead",
category=ScrapyDeprecationWarning,
stacklevel=2,
)
return [self.spider] if self.spider is not None else []
def has_capacity(self) -> bool: # 判断是否有能力处理更多的爬虫引擎
warnings.warn("ExecutionEngine.has_capacity is deprecated", ScrapyDeprecationWarning, stacklevel=2)
return not bool(self.slot)
def schedule(self, request: Request, spider: Spider) -> None:
# 发出请求调度事件,如果self.slot不为空, 则触发_schedule_request调度请求。
warnings.warn(
"ExecutionEngine.schedule is deprecated, please use "
"ExecutionEngine.crawl or ExecutionEngine.download instead",
category=ScrapyDeprecationWarning,
stacklevel=2,
)
if self.slot is None:
raise RuntimeError("Engine slot not assigned")
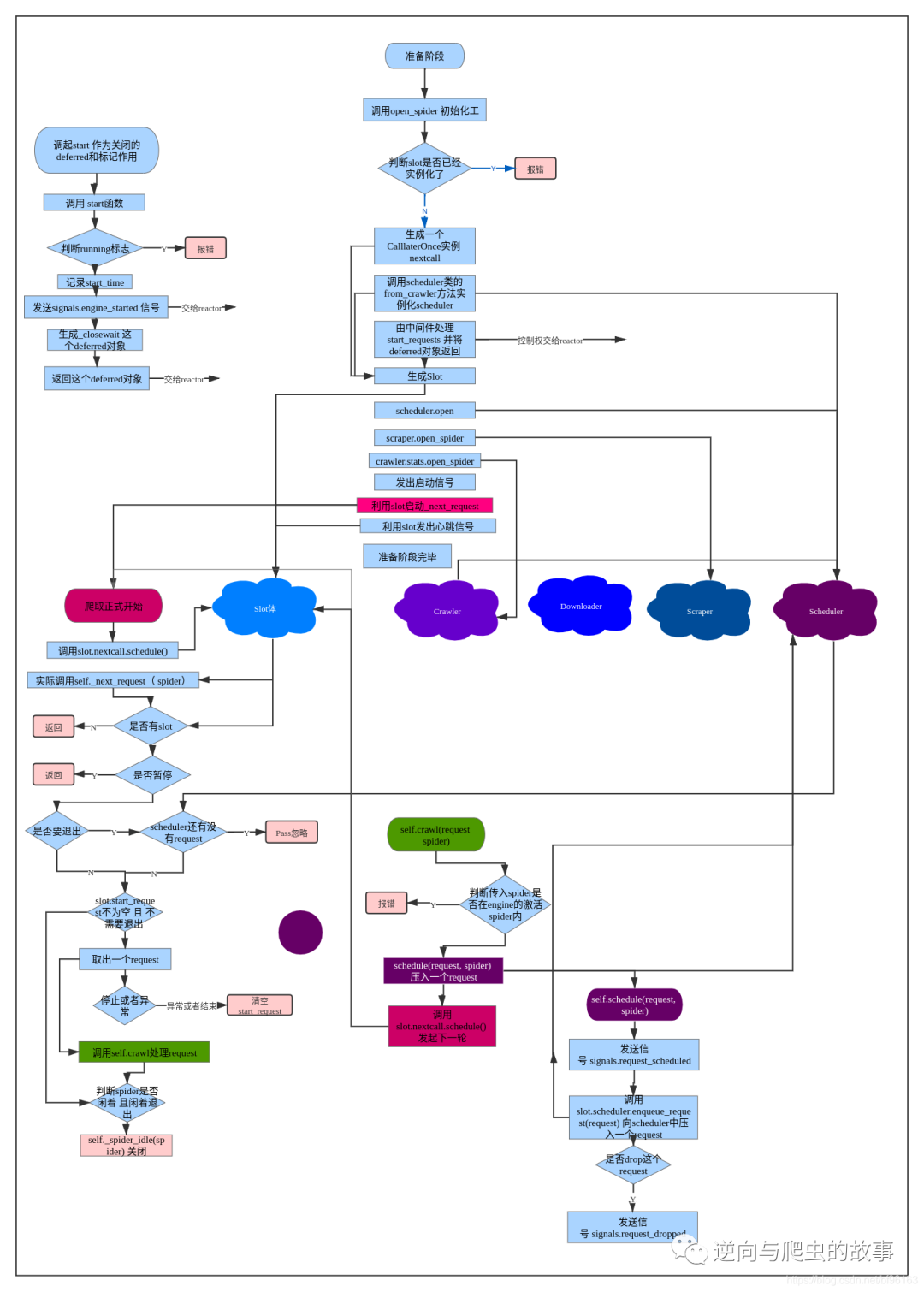
self._schedule_request(request, spider)总结:从上面的分析中,我们得出 ExecutionEngine 是 scrapy 的核心模块之一,顾名思义是执行引擎。它驱动了整个爬取的开始,进行,关闭,请求调度,请求下载;负责 Spider、itemPipeline、Downloader、Scheduler 中间的通讯,信息、数据传递等。接下里,我们对整个流程梳理一个架构图!
四、运行流程图解
五、总结分享
通过本次案例分析,上面的几个问题我们都已经得到了答案。本期分享没有源码重写环节,今天分享到这里就结束了,欢迎大家关注下期文章,我们不见不散⛽️。最后希望大家多多转发、点赞、在看支持一波