大规模 Node.js 网关架构设计与工程实践
今天来开门见山地讲讲网关是一个怎么样的组件,网关在做什么事情。网关这个词其实到处都在用,它可以工作在硬件层面,也可以工作在网络层,还可以工作在应用层。
网关快速入门
网关在做什么?
我们今天讲的实际上是一个工作在 HTTP 七层协议的网关,它主要做的有几件事情:
第一,公网入口。它作为我们公有云服务的一个入口,可以把公有云过来的请求定向到用户的资源上面去。
第二,对接后端资源。我们云开发有很多内部的资源,像云函数、容器引擎这样的资源,便可以把请求对接到这样的云资源上面去。
第三,身份鉴权。云开发有自己的一套账号身份体系,请求里如果是带有身份信息的,那么网关会对身份进行鉴权。
所以网关这个东西听起来好像是很底层的一个组件,大家可能会觉得很复杂,实际上并没有。我们就花几行代码,就可以实现一个非常简单的 HTTP 网关的逻辑。
import express from 'express'
import { requestUpstream, resolveUpstream } from './upstream'
const app = express()
app.all('*', (req, res) => {
console.log(req.method, req.path, req.headers)
const upstream = await resolveUpstream(req.method, req.path, req.headers)
const response = await requestUpstream(upstream, req.body)
console.log(response.statusCode, response.headers)
res.send(response)
})
const port = 3000
app.listen(port, () => {
console.log(`App listening at ${port}`)
})这段示例代码在做的事情很简单,即我们收到一个请求之后,会根据请求的方法或者路径进行解析,找出它的上游是什么,然后再去请求上游,这样就完成一个网关的逻辑。
当然这是最简的一个代码了,实际上里面有很多东西是没有考虑到的,比如技术框架以及内部架构模块的治理,比如性能优化、海量的日志系统、高可用保障、DevOps 等等。当然这样展开就非常大了,所以我今天也不会面面俱到,会选其中几个方向来讲的比较深一点,这样我觉得会对大家比较有收获。
云开发 CloudBase(TCB) 是个啥?
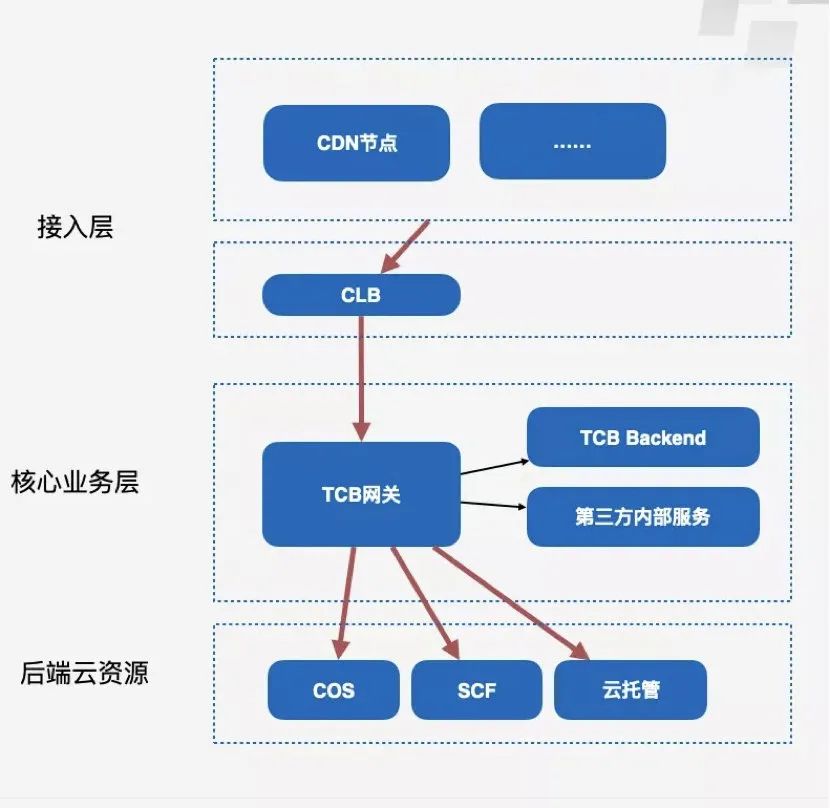
说到这个,顺便介绍一下我们云开发 CloudBase 是什么,要介绍我们网关肯定要知道我们业务,像小程序·云开发、Web 应用托管、微搭低代码平台,还有微信云托管这样的服务都是在我们体系内的。
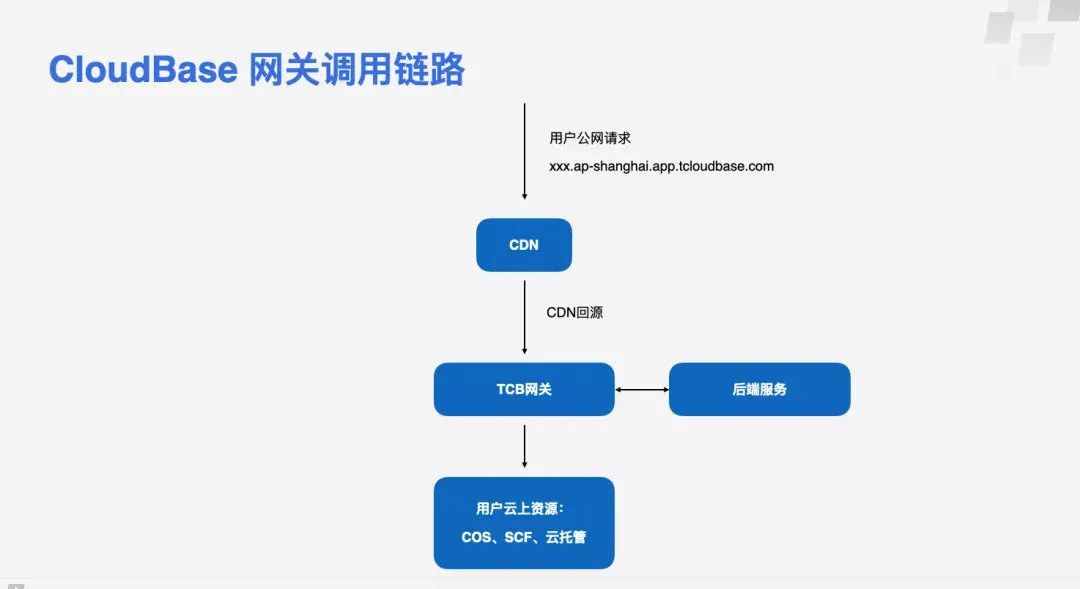
网关的后面就是用户自己的云上资源了,你在云开发用到任何资源几乎都可以通过这样的链路来进行访问。
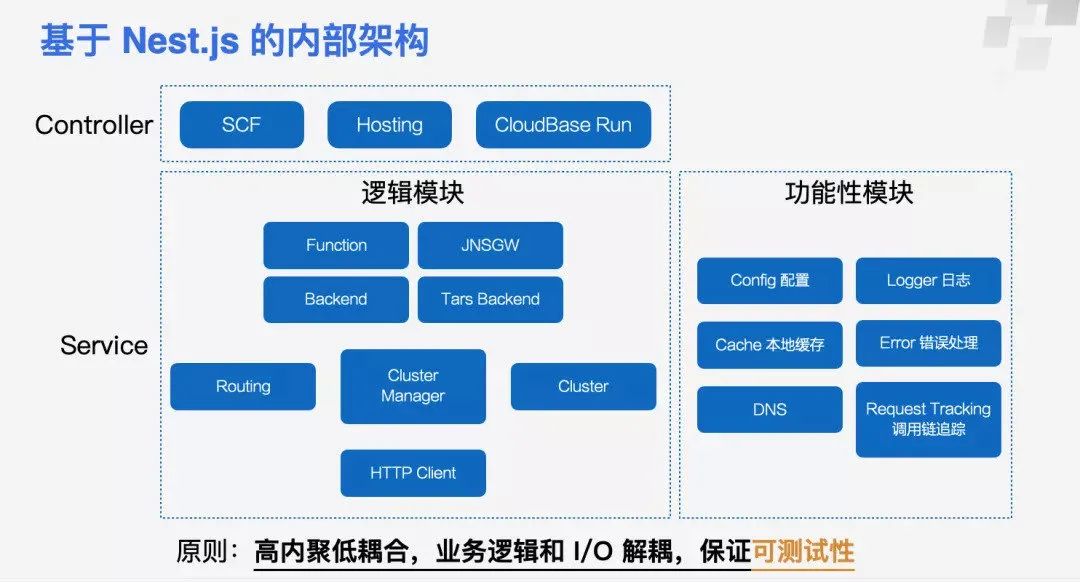
从上图可以看到,我们把它的内部架构分成了两层,一层是 Controller,一层是 Service。Controller 主要是控制各种访问资源的逻辑。比如说你去访问一个云函数(SCF),和你去访问一个静态托管的资源,它所需要的访问信息肯定是不一样的,所以这也就是分成了几种 Controller 来实现。
底层的话 Service 这一层是非常“厚”的,Service 内部又分成逻辑模块和功能性模块。
首先第一大块是我们的逻辑模块,逻辑模块主要是处理我们内部服务模块的很多东西,最上面这一层主要就是处理跟资源访问相关的一些请求的逻辑,跟各种资源使用不同的协议、方法来对接。然后中间这一层,更多的是做我们内部的一些集群的逻辑。比如集群管理,作为一个公有云的服务,我们对于客户也是会分等级的,像 VIP 客户可能就需要最后来发布,我们肯定是先验证一些灰度的流量,像这块逻辑就属于中间这一层来管理。最下面这一层就会有各种负责 I/O 的 Client,我这一次只画了一个 HTTP 的 Client,实际上还会有一些别的 Client。
除此之外还有一些旁路的功能性模块,包括像怎么打日志、配置、本地缓存的管理、错误处理,还有本地配置管理 DNS、调用链追踪等这些旁路的服务。
这一套设计其实就是老生常谈的高内聚低耦合,业务逻辑和真正的 I/O 实现要解耦开。因为只有解耦开,你才能够针对你的业务逻辑进行单元化的测试,可以很方便的把它底层的这种 I/O 读写逻辑给 Mook 起来,保证核心业务逻辑模块的可测试性。
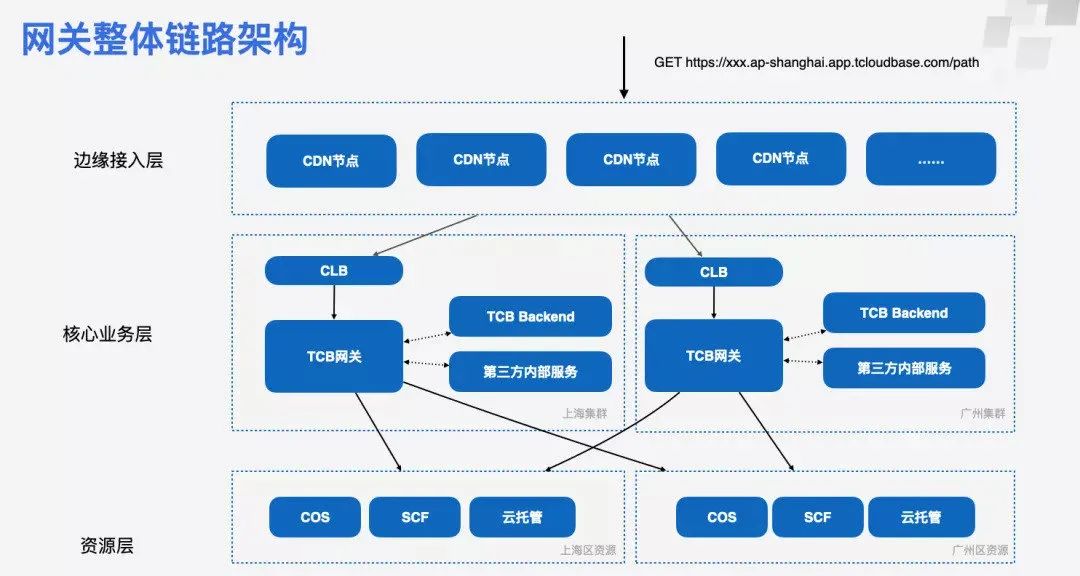
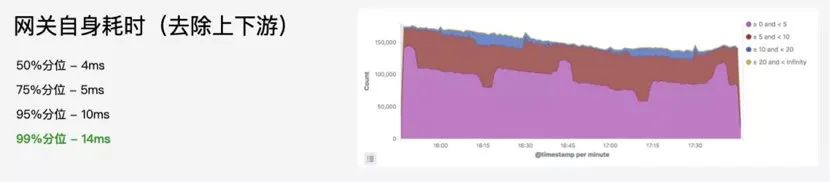
首先作为一个网关肯定是要快的,因为网关作为 CloudBase 云函数、云托管、静态资源的公网出口,性能要求极高,需要承接 C 端流量,应对各种地域、各种设备的终端接入场景。如果说过你网关这一层就可能就花了几百毫秒甚至一两秒钟的时间,对于客户来讲是不可接受的。因为客户他自己的一个函数可能只跑了 20 毫秒,如果网关也引入 20 毫秒的延迟,对于客户来讲他就觉得你这条链路不行。
其次就是要稳,我们是大租户模式,要扛住海量的 C 端请求,我们需要极高的可用性。作为数据面的核心组件,需要极高的可用性,任何故障将会直接影响下游客户的业务稳定性。如果在座的有四川或者云南的同学,你回家每次打开健康码扫码,其实请求都会经过我这个网关的。
所以今天主要就讲两个部分,既然是快和稳,分别对应性能优化和可用性,所以我现在从性能优化开始讲起。
性能优化
网关性能优化思路
性能优化的思路,首先是看时间都花在哪个地方了,网关是一个网络的组件,大部分时间都是耗在 I/O 上,而不是本身的计算,所以它是一个高 I/O、低计算的一个组件。
网关有几个技术特点:首先,它的自身业务逻辑多,是重 I/O、轻计算的一个组件;其次它的请求模式是比较固定的,模式固定我们可以理解为,你的一个客户他发送过来的请求实际上就是那么几种,它的路径、包体大小、请求头等这些都是比较趋向于固定的,很难会有一个客户他的请求是完全随机生成的,这对我们后面针对这种情况做缓存设计会有一些帮助。最后,网关的核心链路很长,涉及到多个网络平面。
那么我们就找到了我们的一些优化方向:减少整个 IO 的消耗,并且优化核心链路。所以优化部分我就分成了两块内容来讲,第一块是网关自身核心服务优化,第二块是整体架构链路优化。
核心服务性能优化
第一部分,核心的服务怎么做优化?先提几个方向。
第一,网关自身的业务逻辑很多,调用很多外部服务,其中有一些是不需要同步阻塞调用的,因此我们会把部分业务逻辑做异步化,让到后台去异步运行。比如说自定义域名来源的请求,我们要先确定这个域名是不是合法绑定的,这里的校验就会放到后台异步来进行,网关只是读取校验的结果。
第二,网关类似代理,转发请求响应体,这里我们使用了流式的传输方式。其实 Node 原生的 HTTP 模块里,HTTP Body 已经是一个流对象了(Stream),并不需要额外的引入类似 body-parser 这样的组件把 Stream 转成一个 JavaScript 对象。为此我们在网关的设计上就尽量避免把请求相关的元数据放到 Body 里,于是网关就可以只解析请求头,而不解析用户的请求体,原封不动地流式转给后端就可以了。
第三,我们请求后端资源的时候,改用长连接,减少短连接带来的握手消耗。像 Nginx 这样的组件,它通常都是短连接的模式,因为我们这些业务情况比较特殊一点,是一个大租户的模式,类似于所有用户共用同个 Nginx,那么你再启用短连接模式的话,就会有一个 TCP TIME_WAIT 的问题,下面会详细讨论。
最后,我们的请求模式比较固定,我们会针对实际情况设计一些比较合理的缓存的机制。
优化点:启用长连接机制
首先,为什么短连接会有问题?
我们去请求用户资源的时候,网关所在的网络平面是内部服务的平面,但是每个用户的公有云资源实际上是另一个网络平面。那么这两个网络平面之间是需要通过一个穿透网关来通信的。这个穿透网关可以理解为是一种网络层虚拟设备,或者你可以理解为它就是一个四层转发的 Nginx,作为代理客户端,单个实例可以最大承载 6.5W 的 TCP 的连接数。
如果做过一些传输层协议的同学应该会知道,一个 TCP 连接断开之后,客户端会进入一个 TIME_WAIT 的阶段,然后在 Linux 内核里面它会等待两倍的时间,默认是 60 秒,两倍是 120 秒,120 秒之后才会释放这个连接,也就是说在 120 秒内,客户端的端口实际上都是处于被占用的状态的。所以我们很容易能算出来单个传统网关它能够承载的最大的额定 QPS 大概就是不到 600 的样子,这个肯定是不能满足用户需求的。
那么我们怎么去解决短连接 TIME_WAIT 这个问题?其实有好几种方法。
第一种是修改 Linux 的 TCP 传输层的内核参数,去启用重用、快速回收等机制。但对于我们的服务来说并不合适,这需要定制这样一个系统内核,维护成本会非常高。
第二种,云上类似的组件怎么解决?比如腾讯内部的负载均衡,其实很简单,就是直接扩张集群内的 VM 数量。比如一台反向代理服务器加上 TIME_WAIT 快速回收,可以承载 5000 多 QPS,但想要二十万 QPS 怎么办,做 40 个虚拟实例就行了。但这种做法,一是需要内核定制,二是需要我们付出很大的虚拟实例成本,就没有选择这种经典方案。
最后一种就是我们改成长连接的机制,类似 Nginx 的 Upstream Keepalive 这样的机制。改成这样一个机制之后,其实效果还挺好的,单个穿透网关就可以最大承载 6.5W 个连接数,相当于几乎 6.5W 个并发。对于同一个目标 IP PORT,它可以直接复用连接,所以它穿透网关的连接数限制就不再是瓶颈了。
长连接的问题
那么是不是长连接就是完美的?其实并不是。长连接会导致另外一个问题,竞态问题(keep-alive race condition),如果在座里有用 HTTP 长连接的方式做 RPC 调用的同学,应该经常会看到这个问题。
客户端与服务端成功建立了长连接连接静默一段时间(无 HTTP 请求)服务端因为在一段时间内没有收到任何数据,主动关闭了 TCP 连接客户端在收到 TCP 关闭的信息前,发送了一个新的 HTTP 请求服务端收到请求后拒绝,客户端报错 ECONNRESET
所以怎么解决?
第一种方案,就是把客户端的 keep-alive 超时时间设置得短一些(短于服务端即可)。这样就可以保证永远是客户端这边超时关闭的 TCP 连接,消除了错误的暂态。
但这样在实际生产环境中是没法 100% 解决问题的,因为无论把客户端超时时间如何设置到多少,因为网络延迟的存在,始终无法保证所有的服务端的 keep-alive 超时时间都长于客户端的值;如果把客户端超时时间设置得太小(比如 1 秒),又失去了意义。
那么正确方法就是用短连接去重新试一次。遇到这个错误,并且它是长连接的,那么你就用短连接来发起一次重试。这个也是参考了 Chrome 的做法,Chromium 自己的内核里面处理了这样一种情况,浏览器里它其实这种长连接也是时刻存在的,下图是一段它自己里面的内核的代码。
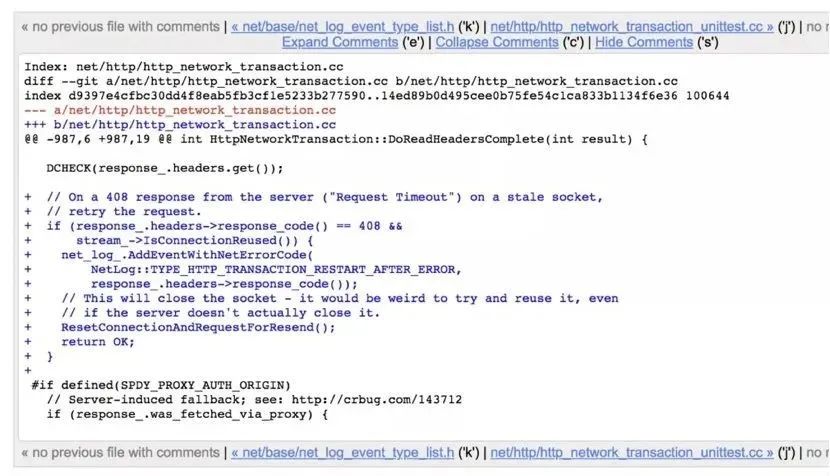

小结
1、非必要情况,不要用 HTTP 协议作为 RPC 底层协议。因为 HTTP 本身最适合的场景是浏览器跟服务端来做的,而不是一个服务端和服务端之间的一个 IPC 协议,尽量使用 gRPC 或者类似的这样的协议来做。
2、如果不得已使用 HTTP,你的后端可能非常老旧,开启长连接是一种较好的方案。
3、长连接需要解决 Keep Alive 的竞态问题。如果你用长连接,记得一定要处理这个问题,不然这个问题会成为一个幽灵一样存在。像刚才说的,万分之 1.3 非常难复现,但是这个错误又会不停地出现在你业务里。
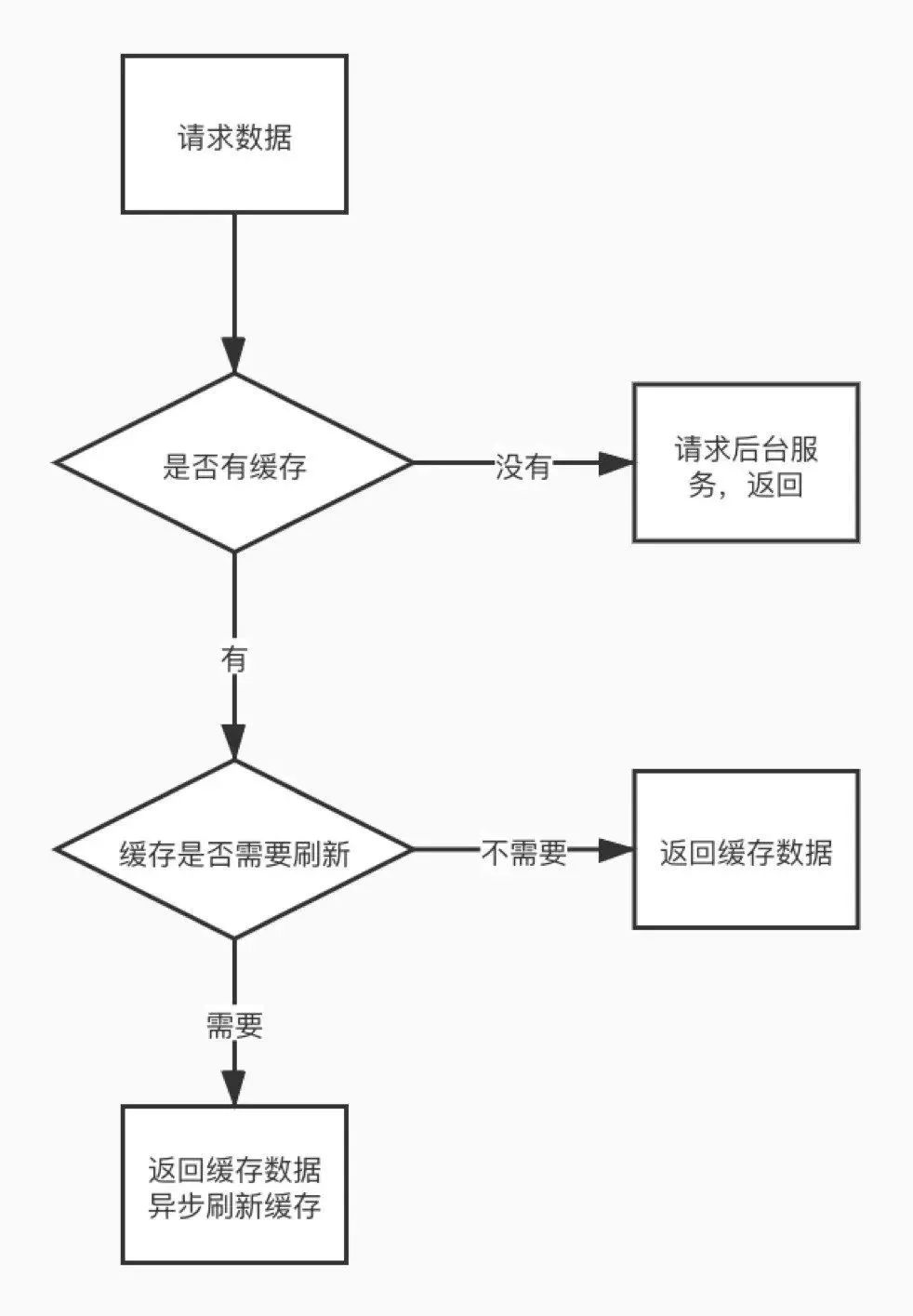
优化点:设计缓存机制
缓存在后台设计里是个万金油,“哪里慢了抹哪里”,但是如何设计缓存其实也是一门学问。
前面提到我们的请求模式都是非常固定的,我们可以根据请求模式来决定缓存数据。缓存都是些什么东西呢?是路由配置,像域名配置、环境信息、临时密钥等这些信息。
这些数据有哪些特点?首先是活跃数据占比小,这确实也是现状。假设我们全量的用户里面每天只有大概 5%~10% 的用户才是活跃的,这个数据才是真的会经过你的网关。其次是模式比较固定。第三是对实时性的要求不高。比如说变更了路由之后,客户通常是能够接受有 1~3 分钟不定的延迟的,并不要求说变更了路由之后就即刻生效。
因此我们可以针对以上这些特点来设计缓存。第一是因为我们的活跃数据占比很小,所以我们是缓存局部数据,从来不会缓存全量的数据。第二是我们会选取域名、环境这种几乎是固定的信息作为缓存 Key,这样缓存的覆盖面就可以得到保证。第三是读时缓存要大于写时缓存,这个后续会提到为什么会选用读时缓存,而不是写入数据的时候把缓存推到我们的网关里。
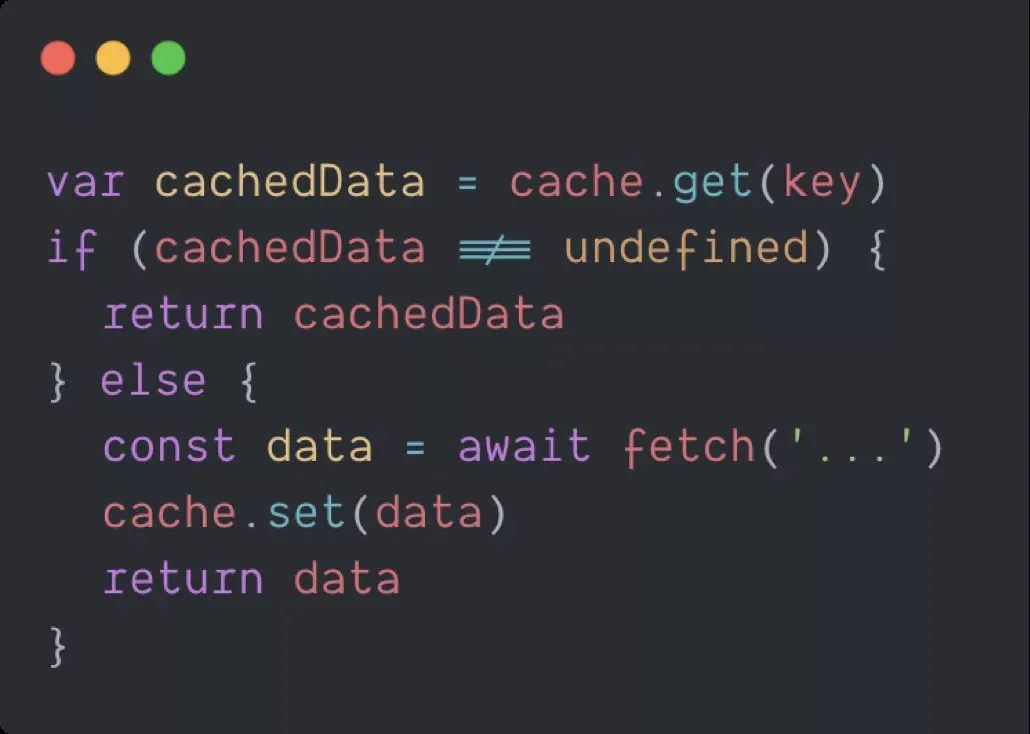
本地缓存的局限性
最早的时候,实际上我们是有一个最简单的设计,就是加了一个非常简单的本地缓存,它可能就是以域名或以路径作为缓存的 Key,这样实现简单但有很多局限性:
首先,要写大量这样的代码,要去先读本地有没有缓存,有缓存就缓存,没缓存去后台要数据。
其次,因为网关不是一个单独的实例,它不是一个单进程的 Node,单进程的 Node 是扛不了这么多量的,我们是有很多很多实例,大概是有几千核,也就是说有几千个 Node 进程,如果这些进程它本身都有一份自己独有的内存,也就导致它这个缓存没有办法在所有实例上生效。因此当我们的网关规模变得越来越大的时候,缓存也就永远都只能出现在局部。
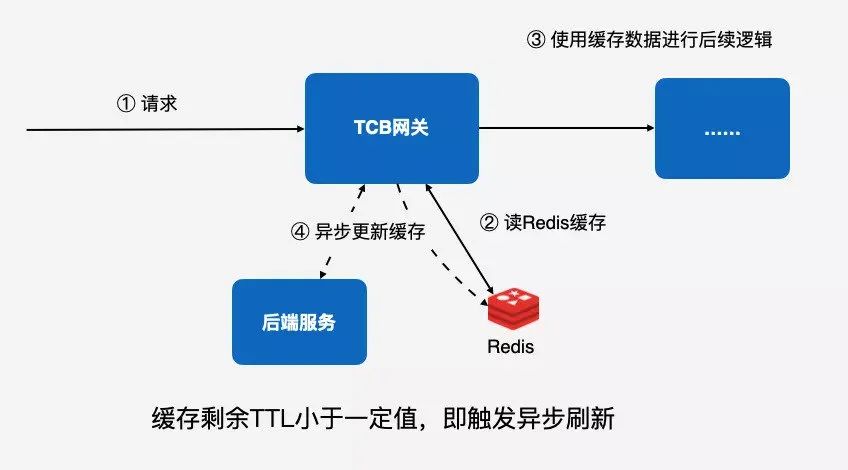
为了解决这样的问题,我们加入了 Redis 中心化的缓存。我们是本地内存 +Redis 两层缓存,本地内存主要是为了降低 Redis 负载。当 Redis 故障的时候也可以降级到本地缓存,这样可以避免缓存击穿问题。Redis 作为一个中心化的缓存,使缓存可以在所有实例上生效,也就是说只要请求过了一次网关,Redis 缓存就会生效,并且所有的网关实例上都会读到这样一个缓存。
既然有了缓存,那必然有缓存淘汰的机制,怎么样合理地淘汰你的缓存?这里是用了 TTL + LRU 两重的机制来保证,针对不同的数据类别,单独设置参数,为什么是 TTL + LRU?后面在容灾部分会进行解释。
最后就是抽象出数据加载层,它是专门用来封装读操作,包括缓存的管理、请求、刷新、容灾这样一套机制,我们内部会有一个专门模块来处理。
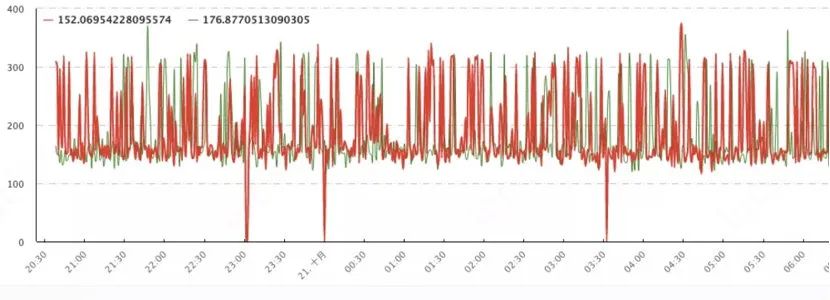
有了 Redis 之后,我们的缓存是中心化的了,只要你的请求经过了我们之后,你的东西就可以在所有的实例上生效。但是这样会引来另一个问题,因为淘汰机制是 TTL 的,必然遇到缓存过期。假设是每秒钟都会回头发起一次请求,那么缓存是一定是会过期的,一分钟或两分钟之后你的缓存就过期了,在过期之后的请求一定是不会命中缓存的,这导致了请求毛刺的问题。这对于在持续流量的下游业务上,体现非常明显,下图是我们的一个截图。
Refresh-Ahead 其实非常简单,字面意义就是说提前去刷新缓存,缓存数据快到 TTL 了,那么就去提前更新一下。
下图是我们加入了 Refresh-Ahead 之后的一个效果,红色箭头处是上线时间,上线完之后发现毛刺就明显变少了。但是为什么还会有一点毛刺?因为有一些数据它可能真的就是很长的时间,刷新了之后它也依然过期了,依然会产生这样的毛刺。

这其实有几个考量点,第一,因为是数据局部缓存,所以我们全量数据完全推过来体积很大,大概有几十个 G,而活跃占比很小,如果完全存在内存里,其实也是一种反模式的做法,不太经济。
第二,后台能不能只推局部活跃的数据给到网关呢?其实也是不太合适的,后台很难去识别哪些数据是活跃的,哪些数据不是活跃的,这样实现复杂,难度很大。
第三,网关和它的持久化的后台之间会产生一个缓存 Key 上的耦合,所谓的 Key 上的耦合就是说双方要约定一组 Key,我这个数据是在 Key 上面去读,然后你后台要把数据推到 Key 上面。那么就会带来另一个问题,一旦 Key 写错了,或者说出现了一些不可预料的问题,那就会产生一些比较灾难性的后果,所以我们就没有使用“推”这样一种方式。
小结
1、在现代大规模服务里,缓存是必选项,不是可选项。
2、缓存系统本质是一个小型的分布式系统,无法逾越 CAP 理论。
3、根据业务场景,合理地权衡性能、一致性和可用性。
架构、链路性能优化
前面讲的是服务跟服务自己核心的优化,接下来讲一讲架构和链路上的一些性能优化。
首先链路很长,涉及边缘节点、核心业务、后端资源。其次网关是承接 C 端流量的,它其实对终端的性能是很敏感的。第三个就是网络环境复杂,它涉及到数个网络平面的打通。因此我们就有了优化方向,第一个是让链路更快更短。第二个是核心服务 Set 化,便于多地域铺设,终端用户可以就近接入。第三个就是我们在网络平面之间会做一些针对性的优化,针对性优化怎么做,后面会提。
前置链路:CDN 就近回源
首先先讲一下我们就近接入是怎么做的,在网关最开始上线的时候,其实会存在一个问题,你的 CDN 节点它其实是通过公网回源的,那为什么是公网回源?
其实这涉及到国内这几家大厂的一个网络架构,简单地说就是,诸多的 CDN 节点中,有部分可能不是腾讯自建的,所处的网络可能不是腾讯的内网,它可能是某个运营商,比如说电信、联通或者网通这样的边缘节点,然后它是要走公网回源到腾讯的入口的,这里的公网回源就非常慢。
比如说广州的节点回源到上海,并且走 HTTPS 协议,那就是 60~100 毫秒,但问题在于 CDN 节点是有很多的,HTTPS 握手之后,这个链接还是没有办法复用的,等于说每次请求都要跟源站之间进行一次 HTTPS 握手,这个延迟是不可接受的。
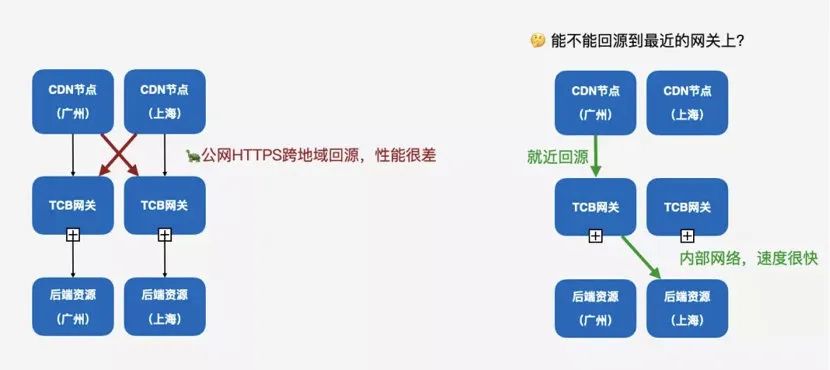
为了能更好地铺设网关多地接入点,我们就把网关改造成了地域无感的,即业务逻辑和它所在的地域是解耦的。其次,网关支持跨地域访问后端资源。最后,配置收归统一,所有地域用同样的后端资源配置,减少了我们不同地域的配置发散的问题。
服务本体:SET 化部署
把这些事情做了之后,网关其实达到了“SET 化部署”的概念,降低就近接入成本,任意集群能访问任意地域的后端资源。相当于网关在所有地域的集群,服务能力都是一模一样的。你可以使用任意域名去任意网关访问,获得到结果都是一样,这样 SET 化部署带来很多好处:
1、新地域接入点的部署、维护成本极大下降
2、便于铺设就近接入点,加速 CDN 接入
3、不同地域的集群之间服务能力完全等价,带来容灾能力上的提升:流量拆分、故障隔离
也就是说全网只要只剩一个地域的网关可用,我们的服务就可以正常的运行。
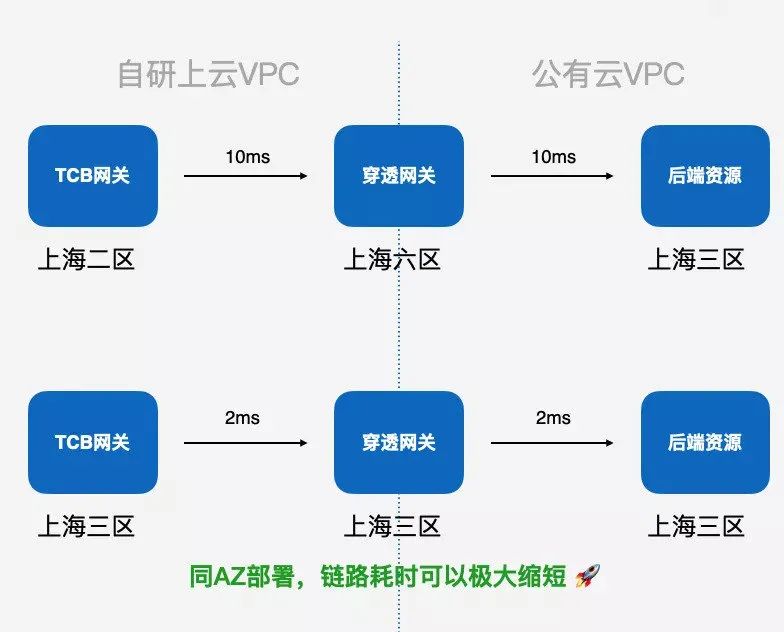
底层组件同可用区部署
接下来涉及到网络平面之间的部署,刚才提到了我们在访问用户的资源的时候,其实会经过一个穿透网关,这个是不可避免的,因为它涉及到两个网络平面的打通,在穿透网关的这一条链路也是可以优化的。
我们可以看一个数据,就是像这种穿透网关和我们云上的资源,它通常是部署在不同的机房的。
小结
1、大规模服务不能只考虑自身性能,前置 / 后置链路都可能成为性能瓶颈。
2、前置 / 后置链路通常与公司基建、网络架构密切相关,服务研发团队需要深刻理解。
3、Node.js 受限于自身异步模型,很难精细化地控制、调度异步 IO,并非万金油。
高可用保障
讲完性能优化,最后一个部分就是可用性保障,那么我们通常的服务怎么来做可用性保障?
第一,不要出事故。服务的健壮性,你本身服务要足够的健壮,这里有很多机制,包括灰度发布、热更新、流量管理、限流、熔断、防缓存击穿,还有缓存容灾、特性开关、柔性降级……这些东西。
第二,出事故了能感知到。事故永远是不可避免的,每天都会发生乱七八糟的各种事故,出了事故的时候你是要能够感知到,并且能够让你的系统自修复,或者说你自己人员上来修复。这就涉及到监控告警系统,还有像外部的拨测,用户反馈监控,社群里面的一些监控。
第三,能立刻修复事故。出了事故的时候,能够有机制去立刻修复,比如快速扩容,当然最好的是整个系统它能够自愈。比如说有个节点它出问题了,你的系统可以自动剔除它,但如果做不到的话,你可以去做一些人工介入的故障隔离,还有多实例灾备切换、逻辑降级等。
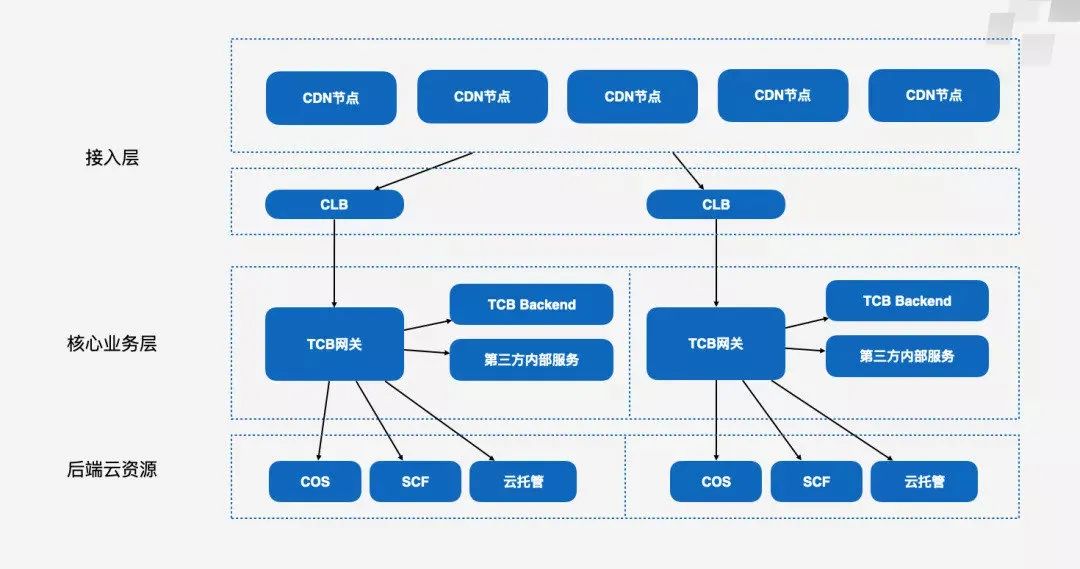
核心业务层
先讲讲我们核心业务层面临的一些挑战。
1、下游客户业务随时有突发大流量,要能抗住冲击。因为我们是承载公有云流量的,大概有上万的客户他的服务是部署在这里的,我们永远不知道这些客户什么时候会突然来一个秒杀活动,他可能也从来不给我们报备,这个客户的流量可能随时就会翻个几千倍甚至几万倍,所以这时候我们要能扛住这样一个冲击。
2、网关本身依赖服务多,稳定性差异大,要有足够的自动容错兜底机制。
3、能应对多个可用区故障,需要流量调度、灾备、多地多活等机制。
4、我们能先于客户发现问题,需要业务维度的监控告警机制。
核心业务层:应对大流量冲击
那我们怎么样去应对一个大流量的冲击?实际上对于一个系统来讲,它其实是非常具有破坏性的,它有可能直接把你的缓存还有你的 DB 击穿,导致你的 DB 直接就夯住了,CPU 被打满。下图是我们一次真实的例子,我也不是很排斥说出来。

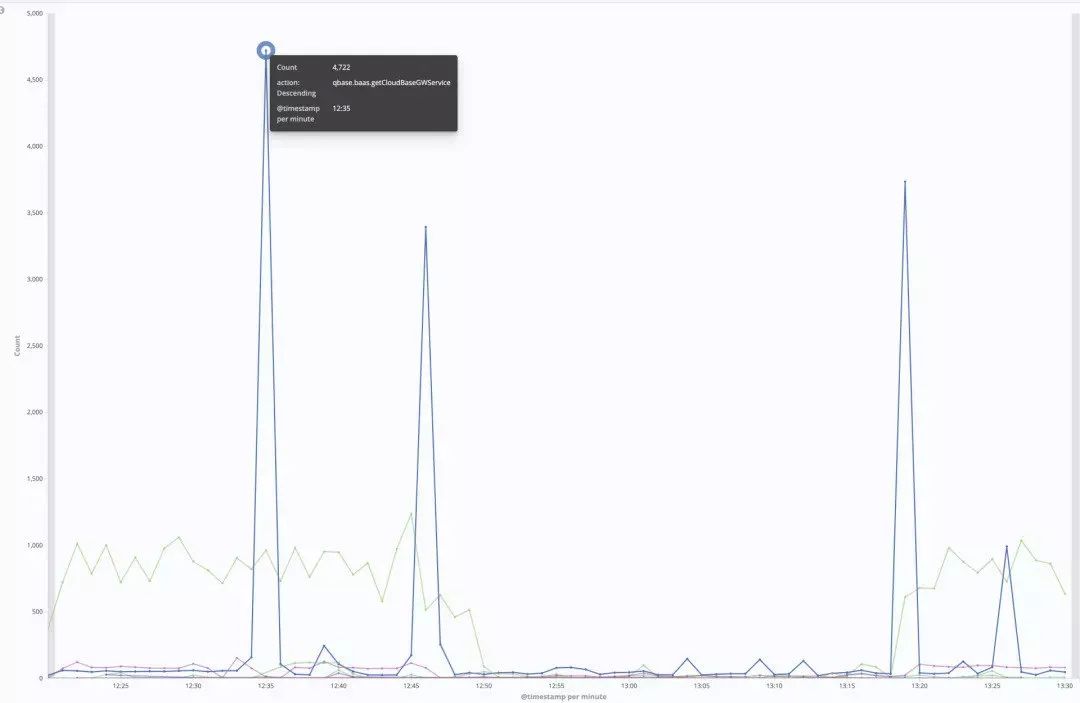
这是我们今年年初 1 月份的时候,有一个客户他的流量突然翻了 100 多倍,你可以看到图上它的量就突然提升,这造成一个什么问题?它的缓存都是冷的,也就是说访问量突然提升 100 倍,这 100 倍的请求,可能都要去后台读它的一些数据,导致直接把后台数据库的 CPU 打满了,也导致这个灾难进一步扩散,扩散到到所有用户的数据都读不出来了。
后来我们就反思了一下这个是不是有问题的?对,是有问题。我们要做什么事情来防止这样的问题出现的?
1、提升服务承载能力
大流量来了,你自己本身要能扛得住,这个时候要去提升你整个服务快速扩容的能力。我们的网关实际上当时已经是完全容器化的,所以这一点还好,它可以快速做到横向扩容,瞬间扩出几百核几千核的资源,可以在几分钟之内完成。
其次,我们是使用了单 POD 多 Node 进程,就是我们 1 个 POD 会带有 8 核,每个核心跑一个进程。这个在 Kubernetes 里面实际上是一个反模式,因为 Kubernetes 要求 POD 要尽量得小,然后里面就只跑 Node 一个进程。但在工程实践的时候,我们发现这样跑虽然没有问题,但是它扩容速度非常慢,因为每次实例扩出来,都是批量的。比如说我们内部的容器系统,只能说一次扩 100 个实例,也就是说一批也就扩 100 核,并且这 100 核都要分配内部的虚拟 IP,可能会导致内部的 IP 池被耗尽了。最后我们做了合并,起码一个 POD 能扩出 8 核的资源出来。
2、保证服务健壮性,不被打垮
当然,除了提升自己抗冲击的能力以外,还要保证你的后端,保护好你后面的服务。
比如说我们要保证服务的健壮性,在大量冲击的时候不会被打垮。首先单个实例会做一个限频限流,防止雪崩,流量限频是说你一个实例最多可能只能承载 1000QPS 的流量,再多你这个实例就直接放弃掉,就不请求了,这样可以防止你的整个后台雪崩,不至于说一个 POD 崩了,然后其他 POD 请求又更多,把其他 POD 全部带崩。
其次,我们要做 DB 的旁路化,网关它读的永远是缓存,缓存里面读不到,那就是读不到,它永远不会直接把请求请求到 DB 里面去。当有数据写入或者说数据变更的时候,后台同学会先落 DB,然后再把 DB 的数据推送到缓存里面,大概就是下图这样一个逻辑,防止缓存击穿问题。
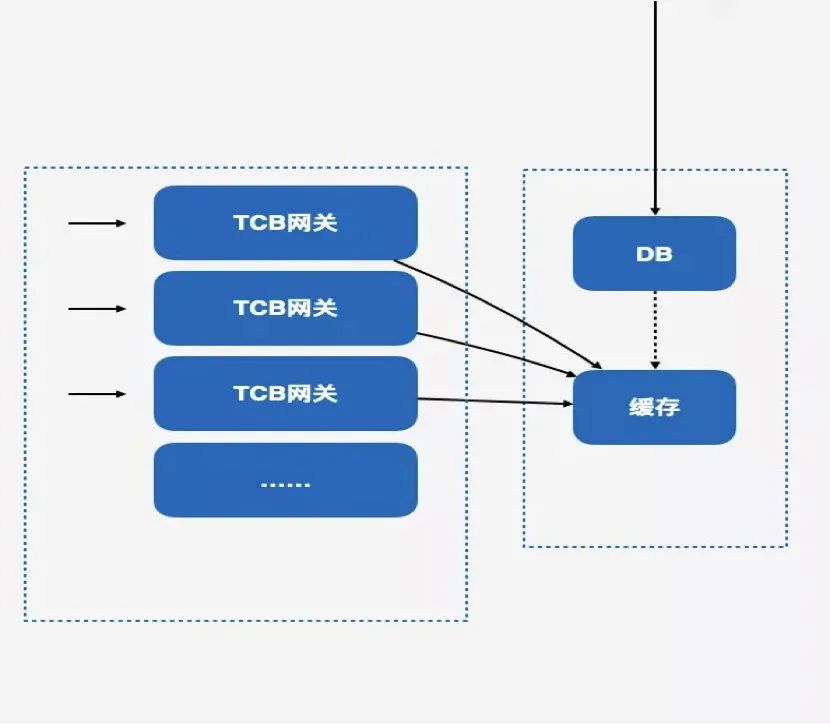
核心业务层:应对外部事故
本身服务构建状态是没有用的,依赖的外部组件服务也一定会出问题,而且它们的可用性说不定远远比你想象的要低,那要怎么做?
首先,我们内部是有一套集群控制系统的,我们内部分成了主机群、VIP 集群和灰度集群这三个集群。每次发布的时候永远是会先发灰度集群,验证一段时间之后才会全让到其他集群上。这样的集群隔离也给我们带来另一个好处,一旦其中有一个集群出现了问题,比如说灰度集群的 DB 挂了,或者 DB 被写满了等其他的事故,我们可以很快速地把流量切换到主机群和 VIP 集群上面去,这得益于我们内部其实有一套集群管理的快速切换机制。
服务降级:容灾缓存
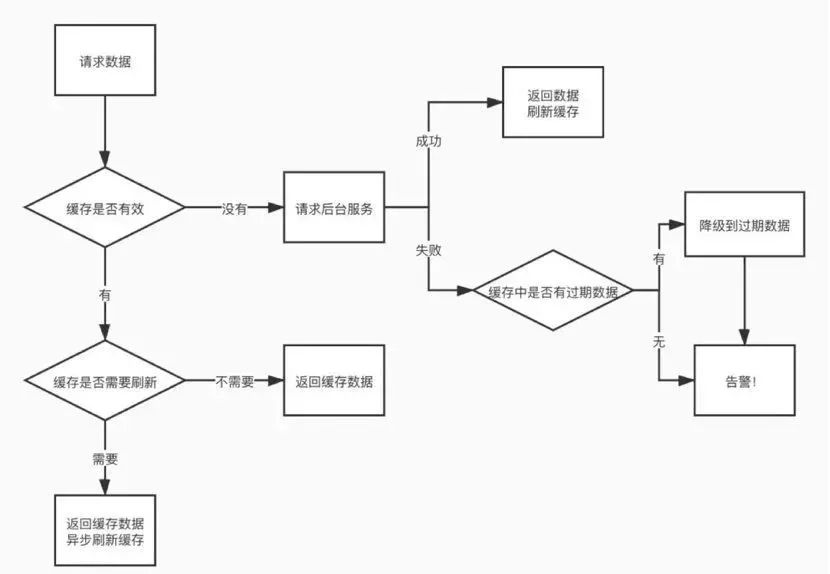
其次,做容灾缓存,假设依赖的服务全挂,服务自动启用容灾缓存,使用旧数据保证基本的可用性。
年初我们有一次这样的事故,整个机房停电,机房就相当于消失了,导致后台服务全部都没有了,这种情况怎么做?这时候就只能是启用缓存容灾。我们网关本地的缓存是永远不会主动清除的,因为你使用旧数据也比直接报错要好,这时候我们就会使用一个旧数据来保证它的可用性。
这个怎么理解呢?我们网关内部的数据它永远不会被清理,它只会说通过 LRU 的形式被清理掉,比如说我的内存里有可能会有很老的数据,昨天或者前天的数据,但是你在灾难发生的时候,即使是昨天还是前天数据它依然是有用的,它依然可以拿出来保证你最基本的可用性,下面是我们一个逻辑图,大家可以了解。
你的服务有可能会降级,我刚提到我们网关有鉴权的功能,鉴权功能其实依赖我们腾讯内部的一个组件。这样一个组件,它其实也是不稳定的,有时候会出问题,那么遇到这种问题怎么办?鉴权都没有办法鉴权了。这个时候我们在一些场景允许的情况下,会直接把鉴权的逻辑给跳过,我们不鉴权了,先放过一段时间,总比说我直接拒绝掉,直接报错这个请求要好得多。
核心业务层:网关自身灾备、异地多活
最后一点就是我刚刚提到的,因为我们网关做了服务 SET 化改造、部署后,天然获得了跨 AZ、跨地域热切换的能力。简单来讲,只要全网还剩一个网关可用区,业务流量就可以切换,网关的服务就不会宕机,当然切换现在还没有做到完全自动化,因为涉及到跨地域的切换,这个是需要人工介入的,不过说实话我们还没有遇到过这么大的灾难。
做个小结,我们做了多集群切换、缓存容灾、柔性降级这些事情之后可以达到怎样一个效果:
1、容许后台最多 (N-1) 个集群长时间故障
2、容许后台全部集群短时间故障
3、容许内部 DNS 全网故障
核心业务层:还有什么能做的?
我们还有什么能做的?如果某天,容器平台全网故障,怎么办?其实也是我们现在构思的一个东西,我们是不是可以做到一个异构部署这样一个形态。
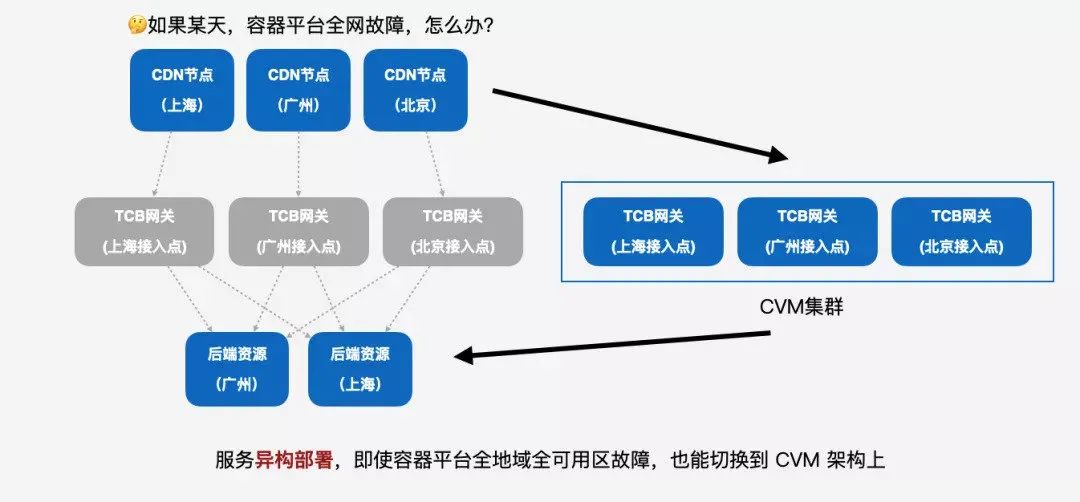
服务异构部署,即使容器平台全地域全可用区故障,也能切换到基于虚拟机的架构上,这也是我们正在筹划的一个事情。
最后说完了容灾,接下来说怎么做监控告警?做监控告警其实比较老生常谈了,但是也可以在这里稍微扫个盲,我们的所有网关,它会把自己所有的访问日志推送到我们的 ES(elasticsearch)的集群上,然后我们会有一个专门的 TCB Alarm 这样一个模块,它会去定期的轮询这样的日志,去检查这些日志里面有没有一些异常,比如说某个用户的流量突然高了,或者某个错误码突然增多,它会把这样的信息通过电话或者企业微信推送给我们。
因为是基于 ES 的,所以监控可以做得非常精细,甚至可以做到感知到某个接口,今天的耗时比昨天要高超过 50%,那这个接口是不是今天做什么变更让它变慢了?
我们也可以做针对下游重点客户、业务的一些监控,比如说几个省的健康码,都可以做重点的监控。
总结
其实我只是选取了整个 Node 服务里面非常小的两个切面来讲,性能优化和高可用保障。可能很难覆盖到很全面,但是我想讲的稍微深一点,能够让大家有些足够的益处。
首先,服务核心优化这里讲了长连接和缓存机制,可能是大部分服务或多或少都会遇到的问题。然后,链路架构优化这里讲了就近接入和 Set 化部署这样一个机制。高可用保障我主要是介绍了核心业务层的一些高可用保障,包括应对大流量冲击,怎么做缓存容灾,柔性降级,多可用区、多地域切换,监控告警这些东西。
最后我想就今天的演讲做一个总结。
第一,Node.js 服务与其它后台服务并无二致,遵循同一套方法论。
Node.js 服务本质上也是做后台开发的,与其它后台服务并无二致,遵循同一套方法论。我今天的演讲如果把 Node.js 改成 Golang 改成 Java,我就不站在这里了,可能我就去 Golang 的会上讲,实际上是一样的。
第二,Node.js 足以承载核心大规模服务,无须妄自菲薄。
我们这套网关其实也现网验证两年了,它跟别的技术栈的这种后台服务来讲,其实并没有太大的缺点。所以大家在拿 Node.js 做这种海量服务的时候,可以不用觉得 Node.js 好像只是个前端的小玩具,好像不是很适合这种成熟的业务,成熟业务是不是还是用 Java 来写,拿 C++ 来写,其实是没有必要的。
当然,如果你真的需要对你的 IO 调度非常精细的时候,那么你可能得选用 C++ 或者 Rust,这样可以直接调度 IO 的方案。
第三,前端处在技术的十字路口,不应自我局限于“Web 前端”领域。
最后一个也是我今天想提的,可能我讲这么多,大家觉得我不是一个前端工程师对不对?但实际上我在公司内部的职级确实是个前端工程师。我一直觉得前端它是站在一个技术的十字路口的,所以大家工作中也好,还是学习中也好,不用把自己局限在“Web 前端”这样一个领域。这次 GMTC 大会也可以看到,前端现在也不只是大家传统意义上的可能就是写页面这样一个领域。

那么我的演讲就到此结束,谢谢大家。