高性能数据库集群设计方案:读写分离
今天和大家分享的是数据库领域的一些架构设计之 “读写分离”。
什么是读写分离
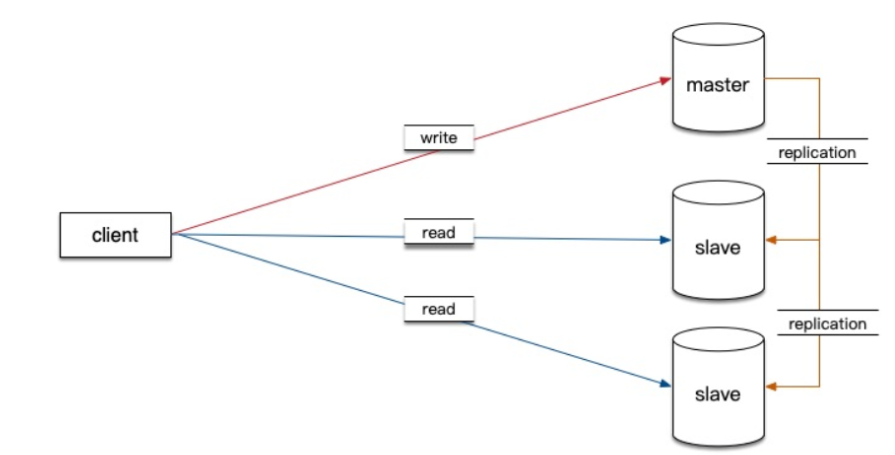
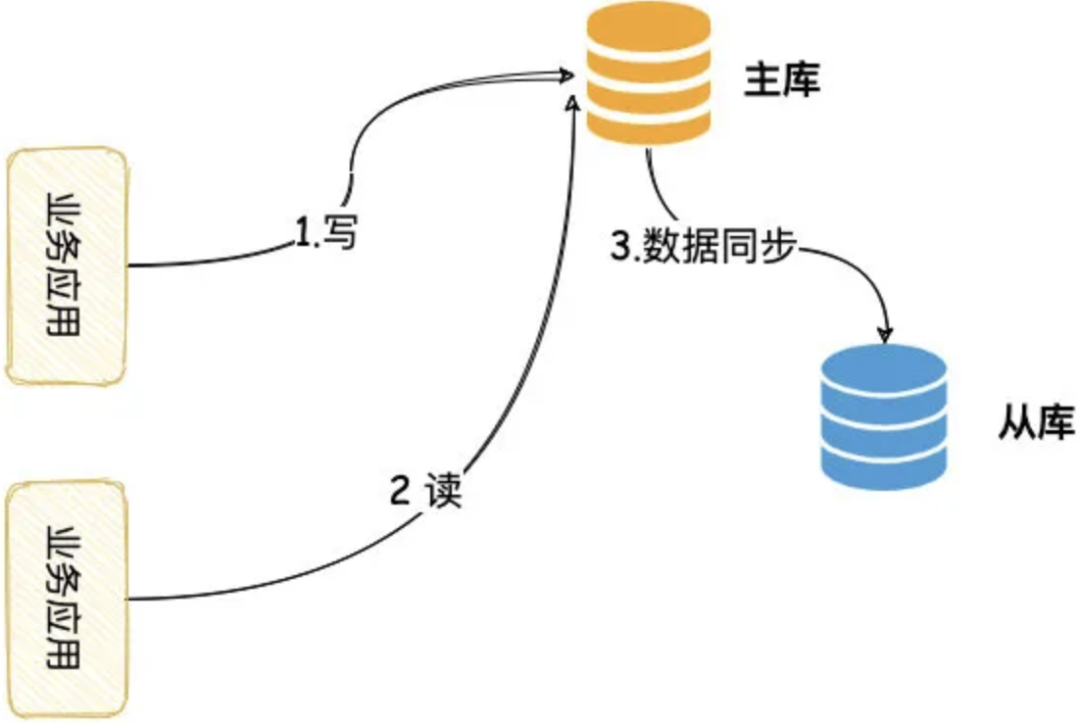
将数据库的请求按照写,读两种类型分发到不同的机器上,这种实施思路通常会被我们称呼为“读写分离”。如下图所示:
这类技术方案的实现方式通常为:
1.搭建一台主节点数据库,一台从节点数据库。
2.主节点数据库负责处理写请求,从节点负责读请求。
3.新写入的数据会从主节点同步给到从节点机器上,保证每台机器的数据都一致。
从架构的整体设计思路来看似乎并不复杂,但是在实际应用中却可能存在很多坑。下边我们通过一系列的实战案例进行学习研究:
主从延迟问题
这类问题在日常开发中经常可能会碰到。例如:用户注册了账户,然后接下来的步骤是立马查询账户信息。由于主从机器间存在一定的延迟时间(有可能是1秒左右),此时就会出现写入成功,但是查询为空的场景。面对这种情况,这里给出一些我常用的解决手段:
1.强制读写都走主库
这类解决方案最简单粗暴,也是实际工作中大家最常用的一种方案,但是这种手段会在无形中增大了主数据库的压力。并且有可能还需要对已经封装好读写分离的ORM框架进行改造,从可维护性方面来说并不是特别友好。
例如某天团队有新的开发加入,对这块对业务并不了解,没有强制读写都走主库从而导致相同的bug又发生了。
2.读失败后再读一次
如果读一次数据库不行,我们就读两次,读三次。这样的方式首先从代码实现角度来思考,相对难度较低,实现简单。但是依然存在不足之处:
- 如果有黑客进行恶意攻击相关接口,那么频繁的二次读会对DB造成压力。
- 另外如果主从节点之间延迟到底需要读几次,这个也没法很好的把控,有些场景下可能需要读3次,有些场景下可能只需要读2次,每次读取的间隔时间也没法很好的调控。
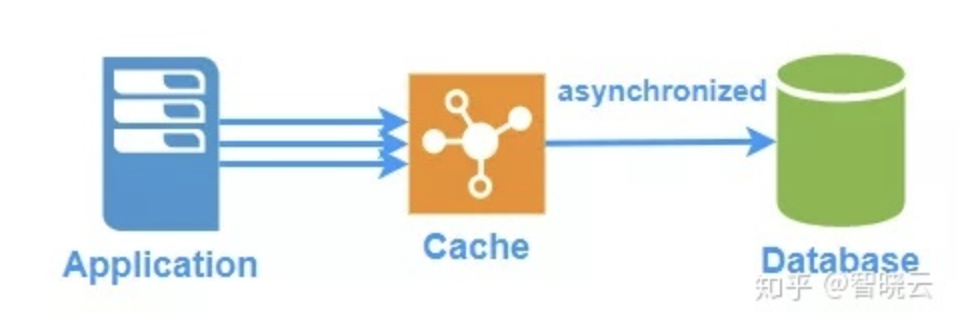
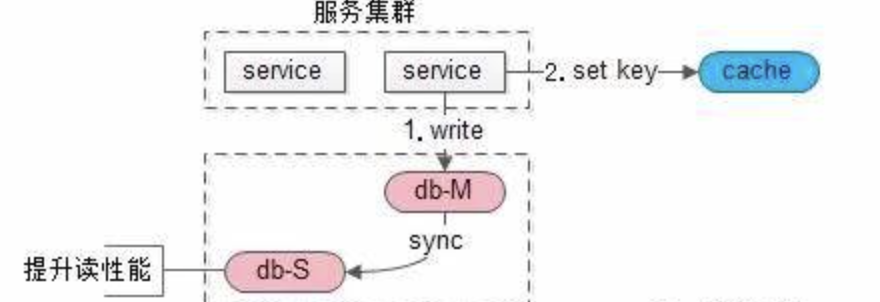
3.结合缓存来解决延迟问题
写入主数据库之后,顺便将数据写入到redis中,设置过期时间为10min,然后读的时候从redis中优先读取,如果redis过期了再从从数据库中读取。这种手段就很好的避免了主从延迟所带来的不一致性问题。
例如我们上边说的用户注册功能就可以用这类手段进行实现。这类方案其实比较灵活,我在工作中也比较偏向于使用该方案。
读写分离后,两边数据的存储引擎不一致
通常设置了读写分离后,通常主数据库负责写操作,从节点负责读操作,因此业界也有相关的说法:主机器使用innodb存储引擎,从机器使用myisam存储引擎。 MyIsam适合查询类业务,Innodb支持事务,对并发读写有很好支持。不过个还是需要结合具体的业务场景来分析,
例如说当前公司的内部规范就是统一使用innodb存储引擎,那么在这种大家都准守规范的情况下,如果为了追求技术的卓越而忽略了后期维护成本等其他因素的话,反倒不大推崇。
什么场景下适合用读写分离
单机数据库不能支持业务的读写规模,所以写和读分离。但写的规模不能高于单机数据库支持的规模;
读规模可以横向扩展,但也不是无限的,因为数据库复制工具也需要从数据复制数据到从库,复制工具复制频率根据业务决定。
读写分离是为了解决业务对数据库层面的读写压力,除了采用读写分离之外,我们也可以采用缓存+主节点的这种方式来替代。当然除了主机器节点之外,如果成本在考虑范围内,建议做一台主节点机器的备节点。
按照自己的实际工作经验来判断,通常能尽量选用简单的架构就尽可能简单。
面对写多读少类型的场景有什么优化手段
对于写多读少的应用场景,典型的类型例如:日志记录,监控记录,信息归档这类数据。除了我们常用的MySQL数据库之外,还可以参考下其他类型的一些存储结构,例如使用LSM数据结构设计的存储数据库相关产品,如LevelDB,HBase之类的。
LSM树的核心特点是利用顺序写来提高写性能,但因为分层(此处分层是指的分为内存和文件两部分)的设计会稍微降低读性能,但是通过牺牲小部分读性能换来高性能写,使得LSM树成为非常流行的存储结构。
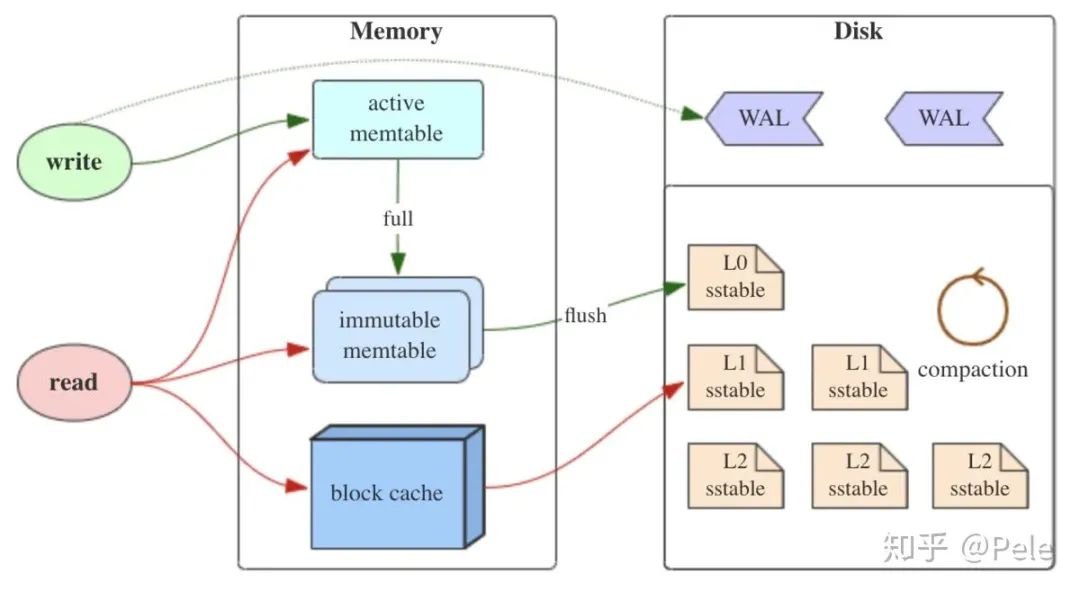
关于LSM更多的内容可以查看这篇文章:
https://zhuanlan.zhihu.com/p/181498475
读写分离之后,对于从节点延迟方面有什么优化手段?
关于这块可以说是一道比较棘手的问题了。因为主从延迟是一个无法避免的问题,所以没有绝对的银弹策略,只能说对一些常见的导致主从延迟现象进行规避。
- 主节点上执行大事务操作,导致从节点延迟,尽量避免这种场景发生
- 主从数据库采用不同的存储引擎,例如主节点使用innodb,从节点采用myisam。不过需要结合实际公司的运维能力进行判断。
- 主从节点的索引不一致策略。虽然说建立了索引之后可以加快他的读操作,但是对于写操作的性能会有所影响。因此可以尽量地减少主节点的索引,将索引建立在从节点上。这块也要结合公司的实际运维能力进行考虑。
有些业务场景中,需要关联许多章表进行查询,sql非常难以优化,该如何解决
这个问题其实在我实际工作中也会有碰到过,例如一些报表系统,一下子关联了6-7张表,加上一系列看着让人头疼的查询条件。如果要从sql方面进行优化的话,常规的解决手段是将sql分为多条单表查询的sql,最后在内存中做计算。
但是这样的实现难度可能非常大,一般遇到这种历史遗留大sql估计也是参杂了各种复杂业务场景,随意改动可能会适得其反。
所以不妨考虑下采用缓存的思路进行优化,按照2-8原则,选出占访问量80%的前20%的请求条件进行缓存。