前端质量之灰度监控的有效实践
本文将介绍更聚焦灰度监控的报警配置。
背景
回顾过去3年,前端故障总量并不算太大,但背后的数据反映出经济体前端的安全生产,特别是高可用这个子域,正处于一个相对比较低的水位:
经济体故障监控发现率46.8%,但其中前端故障的监控发现率仅为22.7%,与期望的监控水平相去甚远!
因此我们开始专门起项治理前端质量,主要抓手通过监控报警,进行一段时间也取得了一定成效。
在分析遗漏的几个线上问题,尤其是报警没有报出来的,且较为严重(白屏、跳转故障等),都有以下共同点:
- 新变更导致的
- 非全量,只有部分流量 某些特定情况才会出问题
- 发布阶段本可发现,但遗留到线上一段时间
因此在报警已经配置的比较全面的下一阶段,我们更需要聚焦于灰度监控
▐ 灰度监控的重要性

从保稳定看
- 预发测试的局限性:不能全面覆盖到线上用户场景(包括多样的用户行为,丰富的客户端设备,海量的业务数据等)
- 发布时间节点时效性:技术同学对问题更为关注,更有积极性
- 及时止损:小范围的试错阶段及时发现,避免到全量发布造成较大影响后
从提效看
- 多端测试提效:某些多端导购页面,10%的时间就能cover掉80%以上的测试点,而剩下90%时间都可能在测多端个别异常场景,这里可以尝试用灰度方式替代
- 灰度验证:灰度发现的问题,修复后,除了预发测试外,某些非主流程场景可以继续小比例灰度测试
灰度监控的效果非常明显:
以我们detail详情页为例,接入监控4个月共发布27次,在灰度阶段共发现5个问题,遗漏1个问题但不影响主流程
灰度阶段如何监控
▐ 灰度阶段的日志监控过程
灰度监控主要从开始灰度到灰度99%阶段保持一定频率的监控发送报告
为什么是发送分析结果报告?
- 现在报警太多且噪音太多,相关技术人员很容易下意识的忽略掉,
- 发送监控分析报告的是增加一种仪式感,让大家能重视这个报告结果内容,
- 部分问题通过报警发现比较难,而通过分析报告能明显发现
- arms系统已具有成熟报警能力~已经配置上了相关告警,我们重点做分析报告
具体步骤可见下图
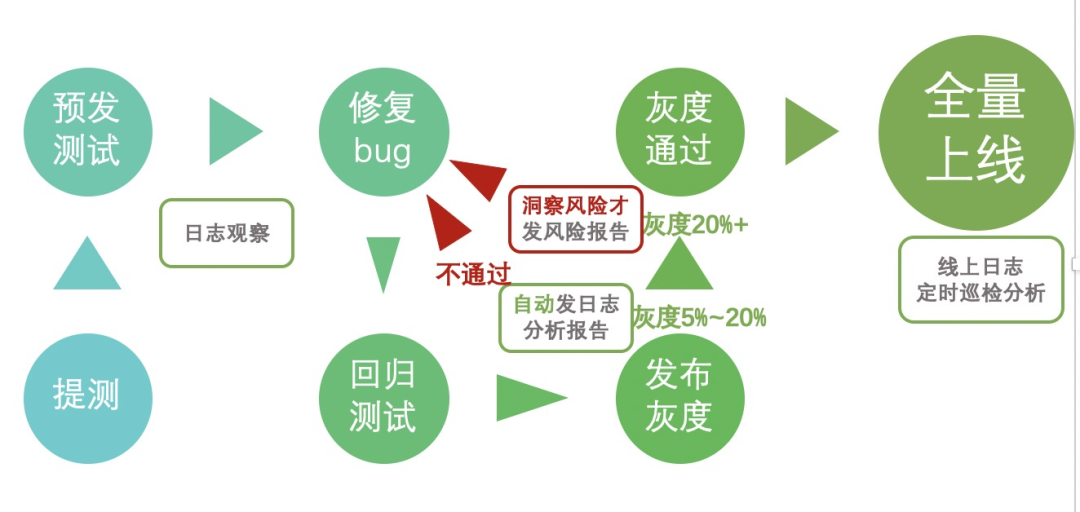
- 灰度发布会触发日志监控,先灰度5%
- 在10min(一般保持在灰度5%~20%)后自动发出日志分析报告,列出各项数据,以及分析后的异常(具体见图2)
- 如确认为风险,则退回灰度0%,修复bug-》回归测试-》发布灰度,如此循环
- 如确认无异常风险,继续扩大灰度,并继续保持高频监控
- 灰度到99%前保持通过,发布上线
▐ 监控指标和异常分析
我们捞取sls日志,分别对api错误,js错误,流量,业务埋点,性能埋点的各项异常数据进行分析,而在灰度阶段新增错误尤为重要,存量错误和总计数据会进行环比、日同比、周同比这类的比较分析
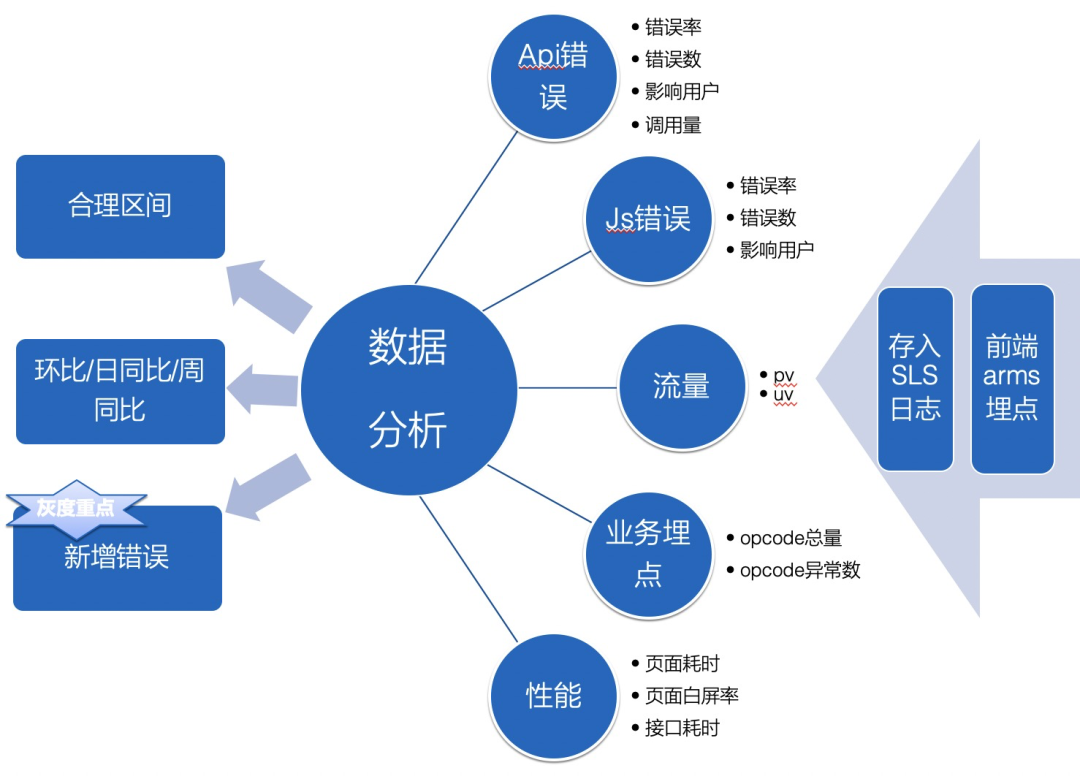
以下进行具体数据拆解
-
api错误
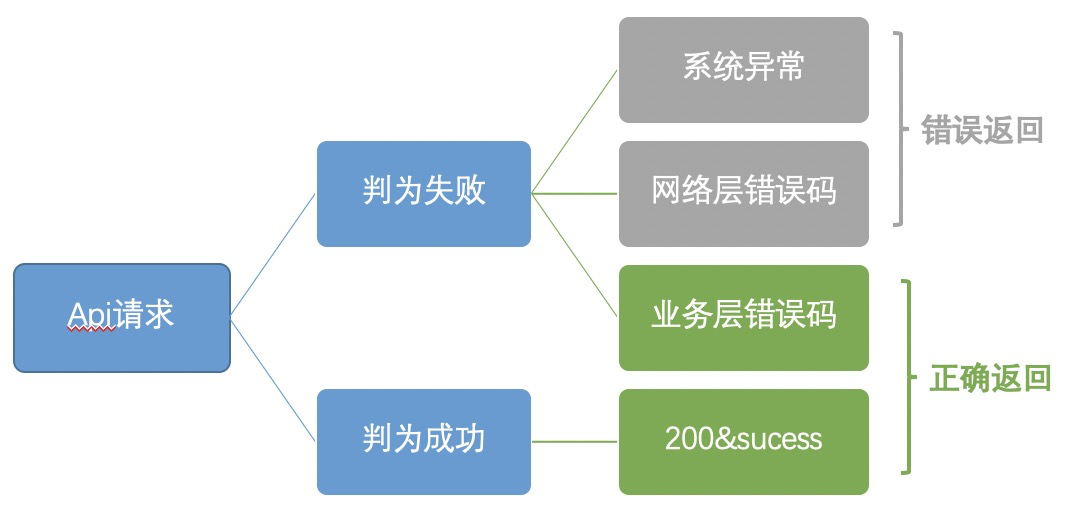
因为api错误的统计标准与我们的实际需求有出入(见下图)我们主要看新增错误、同比环比数据
-
错误率:主要统计同比环比。为什么不看api成功率?成功率99.5%下降到99%(下降了0.5%)数据非常不明显,失败率0.5%提升到1%(上升100%)很明显,才更能发现问题。比如我们有个detail页接口成功率常年维持在99.5%,有次发布前端bug成功率仅仅掉到99.3%,但影响了1w+用户一天
-
错误数:(某api新增错误信息)错误数,1~2(每10分钟)是warn级别
-
影响用户数:(某api新增错误信息)影响用户数,
-
a.会结合错误数一起看,辅助分析大量错误是否集中在个别用户上,
-
b.影响用户数权重大于错误数,说明影响面更广
-
调用量:调用量异常也能反映前端bug,0一般是错误导致无调用,异常高一般是多次调用
-
案例:2020.12.01 - 异常日志排查到订单结果轮询的 bug
-
-
观察日志时发现有个接口突然调用量相对平日大涨,排查日志发现有同一个用户一直重复请求同一个接口,猜测可能是轮询逻辑有问题,通过排查代码发现一个取数逻辑有误引起的 bug
-
js错误
-
错误率:同比/环比的大幅度提升,需要着重关注
-
案例:2020.07.29 - 珍品 detail灰度中,监控发现报错率激增到10%,报错数激增到 5.6w,
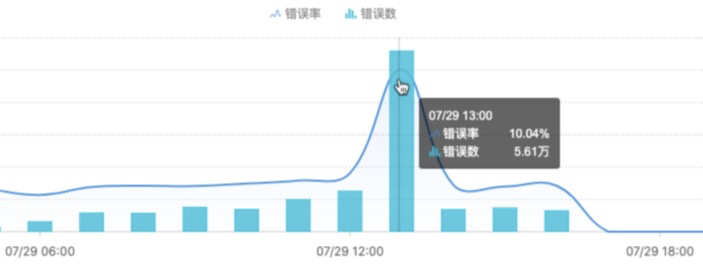
-
错误数:(新增错误信息)错误数,1~2(每10分钟)是warn级别
-
影响用户数:(新增错误信息)影响错误数,
-
a. 会结合错误数一起看,辅助分析大量错误是否集中在个别用户上,
-
b. 影响用户数权重大于错误数,说明影响面更广
-
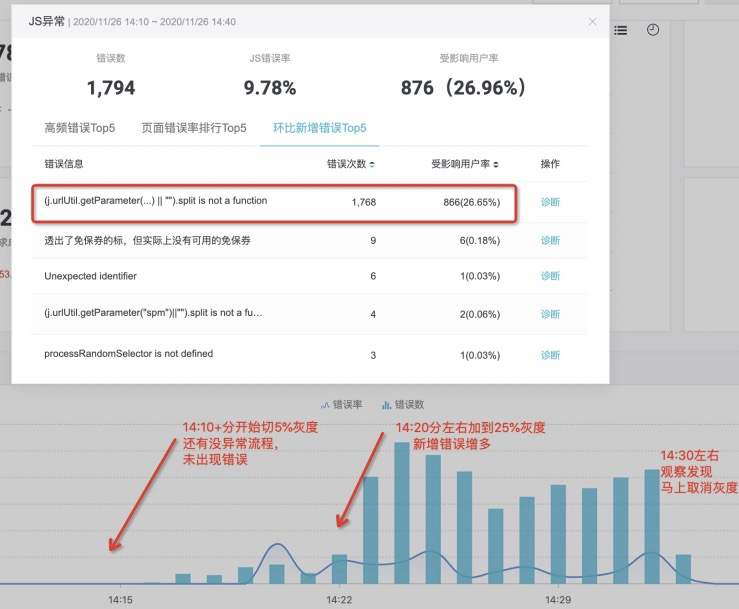
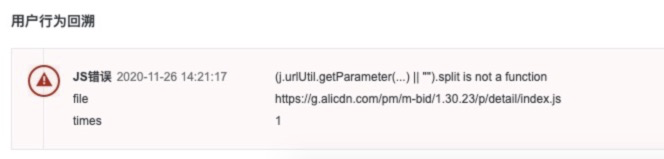
案例:2020.11.26 发布珍品详情页,在灰度25%时,发现
-
-
-
报错原因:部分拍品url上的spm存在数组引起split 方法不存在。
-
流量异常
-
主要看pv和uv,但需要排除大促活动、手淘大量引流等非常规因素对同比环比数据带来的影响,需要同时结合日同比、周同比、环比的各项数据都有大量偏离了才会判为异常(具体见后面的杂音处理)
-
业务埋点异常
用于业务自定义的埋点,方便做含有业务属性的统计
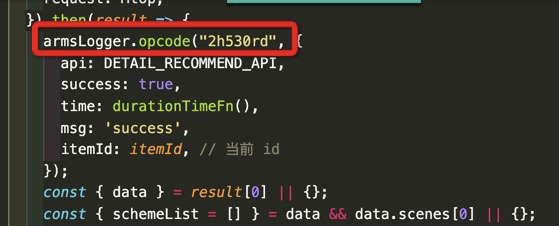
- 成功总量埋点:需要同时结合日同比、周同比、环比的各项数据都有大量偏离了才会判为异常(具体见后面的杂音处理)
- 案例:2012.12.1发现apush连接100%挂,以下是发送apush的opcode统计,可见12.2修复问题前它的样本量一直为0
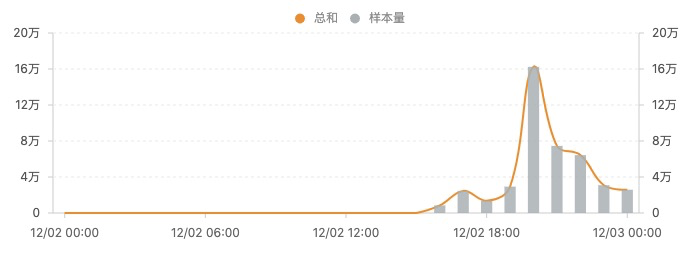
- 异常总量埋点:专门对异常数据进行了埋点,结合具体业务场景分析异常
-
性能监控
前端在各个环节加上埋点上报,然后做数据统计,性能的变化建议多点时间观察
(这里给的图是每日的趋势图,只为举例说明,灰度阶段是看灰度时间段和灰度前的数据,整个周期最好2天以上)
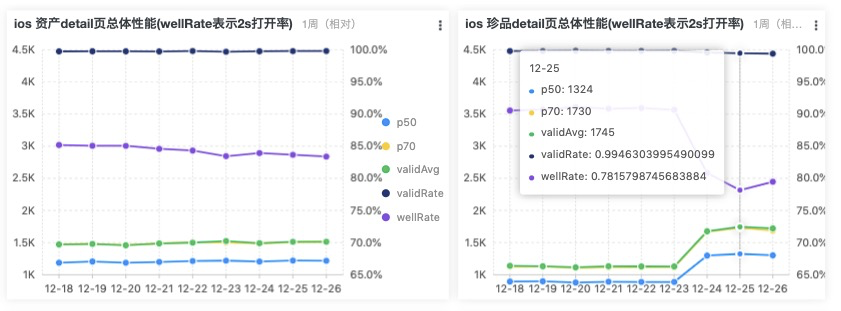
- 页面完全加载时间:
- p50,表示所有样本,按从小到大排名第50%位的数据,例如下图p50=1324说明50%的页面打开小于1324毫秒,
- p70,表示所有样本,按从小到大排名第70%位的数据,例如下图说明70%的页面打开小于1730毫秒,
- validAvg,表示去掉尖刺(>15秒异常数据)后的平均值
- wellRate,表示<2s的比例,下图说明约78.16%用户访问在2s内,
(从下图趋势看,detail页12.24的发布导致前端性能变差,需要查下原因)
- 页面白屏率:认为完全加载时间在5s以上(从用户体感来说5s以上已跳失,宽松点可以按照15s以上)的都是异常白屏的情况,
- 接口耗时:接口返回耗时也会影响前端性能,主要看平均耗时(去掉了>10s杂音)参考看成功耗时和失败耗时,耗时在>500ms的重点列出,warn级别
性能监控以及分析有个更详细文档,后面会出
▐ 剔除杂音,提高洞察风险有效性
-
存在的大概率报异常场景
(不过一般来说发布都会人为避免以下情景)
| 问题 | 举例描述 | 措施 |
|---|---|---|
| 业务在不同时段波动不一致 | 在凌晨量级小时剧烈波动、在白天量级大时较稳定的现象 | 自动动态调整阈值,避免误报 |
| 业务的冲高回落现象 | 拍卖接近固定时间点结拍时的大量出价,整点客户端push、商家活动带来的1h内冲高回落 | 若是回落到基线附近,则不报 |
| 业务的定时下跌现象 | 业务在固定时间点附近会出现骤跌,如01:00~07:00 | 设置不报时间点 |
| 大促现象 | 业务在每年双十一、双十二、红包期间数据和日常不一致 | 特定日子的数据波动实时监测,自动路由到大促模型 |
| 错误码监控中自动过滤短暂抖动 | 在错误码监控中,错误码经常会出现短暂的抖动后恢复到正常水位 | 需支持过滤历史相似的冲高抖动立即恢复现象,专注于对过高冲高、错误持续未恢复的情况进行告警 |
-
需要剔除的无效数据
api错误
长连接,统计到的taobao站外的接口数据,通常我们通过like('m.taobao.com/%')直接筛选出域内数据
js错误
a.与客户端交互的日志数据,webview框架数据等
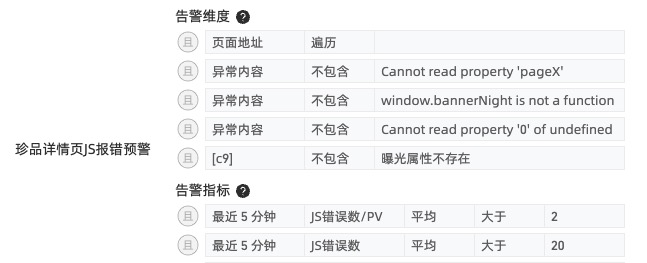
b.业务含义的报错,如下图举例Uncaught TypeError: Cannot read property '0' of undefined。存量的报错是因为用户手势滑动操作头图区域导致的报错
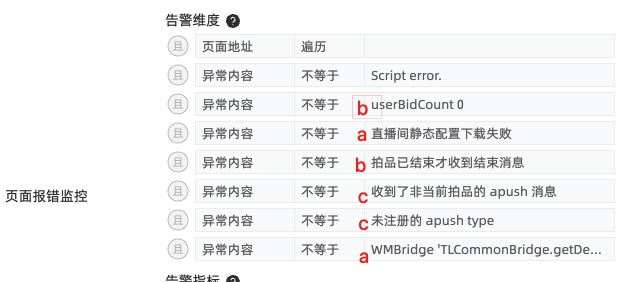
c.长连接、websocket、后端接口等引发的错误
abc三类,见下图举例
d.黄牛、机器人问题
一般加上影响用户数就可规避大部分,如下图中实例:js错误率很高的时候,影响人数其实只有1个

剔除无效数据,是个需要一定时间打磨的过程
-
建议主动自定义埋点+通用兜底
这是最好的排除无效数据的方法,但也需要进行梳理、以及手工埋点
总结
前端质量中,灰度监控,在保稳定和提效 多方位,都有明显效果,非常推荐!
同时也是需要业务前端开发和测试,甚至也会涉及到后端开发,共同齐心积极配合。
除了灰度监控,我们还有监控报警、线上巡检、性能分析,多个前端质量方案,全方位保障。