ReolAudio - 基于分帧的 Web 音频工程解决方案
背景
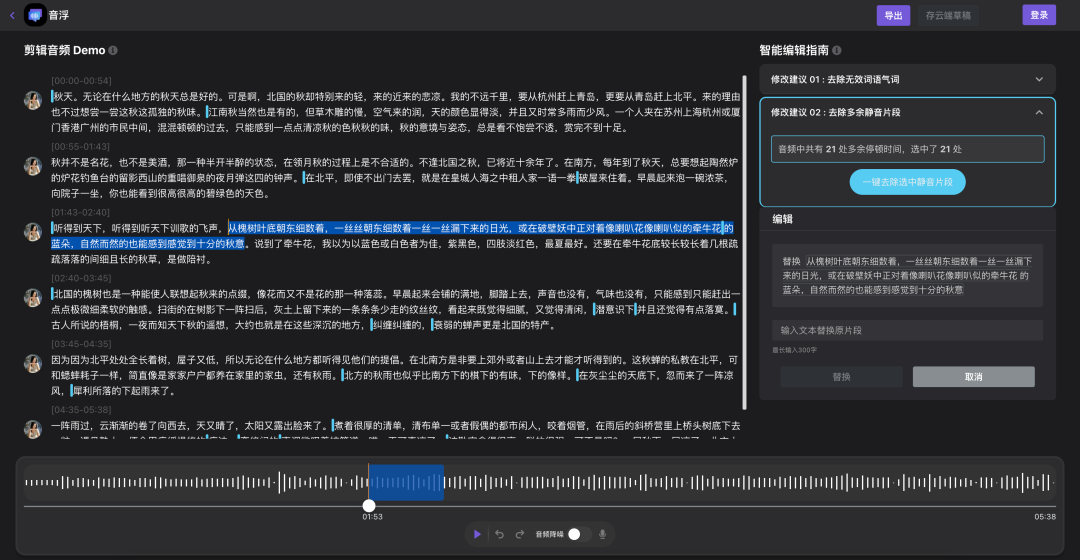
音浮
音浮是 Hackathon(字节跳动内部的创新项目比赛)的获奖项目。它是一个可视化的智能音频剪辑工具,会自动将用户输入的音频通过 ASR 引擎转成文字,变“听”为“看”,实现以编辑文本的方式剪辑音频。同时,依托于强大的音频 AI 技术,使用户可以一键去除无效语气词、重复词、静音片段,自动降噪,甚至可以通过语音合成和音色克隆来纠正说错的内容。
长音频问题
最初的技术方案
由于涉及到音频编辑,并且播放和波形都需要实时响应,所以最常规最直接的方法自然就是使用 AudioBuffer,以解码后的 PCM 数据来表示当前会话状态,既方便编辑又方便波形绘制。音浮起初也是基于这个方案,对于一些中长时长(30min 以内)的音频来说确实没有什么问题,但随着项目的成熟,对所支持音频时长要求越来越高,对各方面交互性能要求也越来越高,原本的技术方案面临着非常多的优化和功能实现上的挑战,进行技术改造甚至构建一套全新的前端音频处理架构势在必行。
技术挑战
总结下来,传统的基于 AudioBuffer 的音频编辑在面对大体量音频数据处理的场景中存在如下缺陷:
-
内存占用高
-
以常见的 44100hz 采样率,双声道音频为例,每小时解码后的数据需占用内存 44100 * 2 * 3600 * 4B ≈ 1.2GB。
-
由于 AudioBuffer 长度不可变,因而每次编辑需要创建新的 AudioBuffer 实例,这样新老实例并存就会产生相当于双倍体量的瞬时内存占用,很容易因内存申请失败而报错,甚至导致浏览器崩溃。
-
编辑性能差
-
直接编辑解码后的 AudioBuffer 由于需要操作大量内存,严重影响性能。
-
起播时间长
-
由于播放源为 AudioBuffer,需等待音频全量解码才能播放。在我的机器上每小时 mp3 音频全量解码约用时 8s。
-
首次波形绘制慢
-
首次绘制波形需等待音频全量解码,用时同起播时间。
-
不利于存储
-
AudioBuffer 数据量大,使用户会话难以存储,对于本地存储或许可以接收,但如果数百 MB 甚至过 GB 的数据要存在云端显然是不现实的。
切入点和难点
从以上总结不难看出,这些问题的根本原因在于长音频全量解码后的数据量巨大,因而我们很容易想到解决问题的核心切入点:流式解码和随机解码(解码音频中的某一特定时间范围的片段)。由于原始文件是一定要进行云端存储的,所以不如把用户会话中的一等公民由解码后的数据转换为解码前的数据,即原始音频文件。
但问题是,浏览器并没有提供可直接使用的 API(虽然 Chrome 从 94 开始实现了支持流式编解码的 Web Codecs API,但下文会说到为什么我们不使用它),所以这里的核心难点在于浏览器中的音频流式解码和随机解码实现。
初识 ReolAudio
最初,我们只是希望基于以上背景来探索一种 Web 音频流式解码方案,以解决音浮的长音频问题,后来发现它不仅能对音浮带来显著的优化效果,其中用以支撑这套方案的许多功能还具有较强的通用性,可以应用于除音浮以外的项目。例如我们在另一个项目里使用了基于分帧的音频剪辑,也取得了性能和稳定性的大幅度提高;再比如像 Web DAW 那样的重音频编辑场景,在基础架构层面面临着与音浮相似甚至更高的挑战,所以也天然适用。
因而在经过一段时间的迭代和优化后,我们把这套能力进行了重新梳理和封装,也就产生了本文所要介绍的 ReolAudio,其功能目前主要涵盖:
-
多种流行音频格式(mp3/mp4/m4a/aac/wav)资源的解析和分帧,即获取音频文件的元信息以及封装结构信息。
-
灵活的音频解码能力:全量解码、流式解码、随机定位解码。
-
一个高性能的采样播放器,用以支撑高定制化的前端音频播放器建设。
-
内置的帧序列化和反序列化工具,方便帧信息的本地或云端存储。
-
高性能、高可靠性的音视频格式(mp3/mp4/m4a/aac/wav/flac/ogg/flv/mid)检测。
-
一套完整的以帧序列为基础的在线音频剪辑、播放、波形、存储方案。
-
简单快速的音频文件剪辑。
定位和目标
音频相关应用的开发工作都可分为算法和工程两大方面,ReolAudio 则聚焦于前端场景下的音频工程。它致力于提供一套丰富、强大、通用的音频处理基础能力,并与原生 Web Audio API 相辅相成,使构建各种高级、高定制化的富音频交互应用或框架成为可能。同时,我们希望它保持轻量、高性能以及良好的兼容性。
基本原理
什么是分帧
虽然音频编码算法多种多样(如 mp3、aac、flac 等),但它们在最基本的层面上具有一定的共性,即都是先把原始 PCM 数据分为一帧一帧的最小单元(一帧时长通常在 20~60ms,这是因为基于声学原理,该时间段内的声音信号保持特征稳定的概率较大),再分别对每一帧进行编码,得到一个编码后的帧序列,最后将它们以一定的格式封装为完整的音频文件。基于此,可以对封装后的音频文件进行分帧,并解析出每一帧的参数,这两个过程在本文中分别称为 “分帧” 和 “解帧”。
为什么要分帧
- 分帧本质上是解封装,不涉及编解码,性能非常高,内存占用小。
- 不需要解码也可以编辑音频,通过帧序列的增删和排序就能实现音频的裁剪、拼接、插入等操作。
- 帧与帧是相对独立(不一定完全独立)的,一段连续的帧片段可以直接使用 Web Audio API 中的 decodeAudioData 进行解码,因此可实现流式解码、按需解码。
- 帧信息相当于音频文件的“地图”,理论上有了帧信息才能完全保证精确 seek,否则对于变比特率格式(如 abr/vbr 的 mp3),很难精确算出特定时间的数据在源文件中的位置。
- 初次绘制波形可采样解码,耗时大大降低;帧中可维护波形摘要,无需存储解码后数据也能快速生成后续波形。
- 如果以后需要用到 Web Codecs API,解封装相关操作仍需手动实现,可以直接复用。
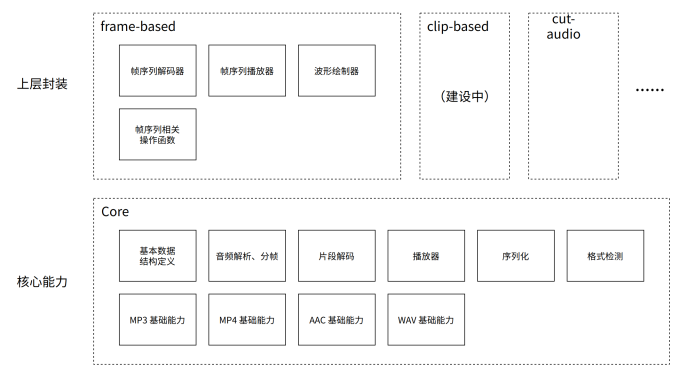
整体架构
-
核心能力:一些与具体业务、使用场景无关,仅与音频本身相关的通用底层能力。既包括针对各种已支持音频格式的特定能力(如 mp3 解帧、mp4 box 的解析等),又包含格式无关的通用能力。
-
上层封装:在核心能力的基础之上所封装的一些可能与具体业务场景相关的框架或功能。如专为音浮及相似应用场景打造的音频处理框架 frame-based、为 SoundOn 项目所编写的简单在线音频剪辑工具 cut-audio 等。
关于 FFmpeg+WebAssembly
谈到音视频,可能永远绕不开 FFmpeg 这个话题,因为它几乎是非浏览器环境音视频处理中所必然用到的工具。因此在最终确定技术方案之前,我们也投入了较多的精力尝试了基于 FFmpeg 的方案,探索了 FFmpeg 在前端落地的可行性与最佳实践,也从多个维度对分帧和 FFmpeg 两套方案进行了详细对比和总结,其中也说明了为什么最终选择了基于分帧的方案。对于也希望在浏览器中使用 FFmpeg 的同学,这些信息或可作为参考。
解码
浏览器的 deocodeAudioData 可能是世界上最好用的音频解码工具,文件解封装、解码、重采样、采样格式转换等全部流程都可以在一次简单的函数调用中完成,并且是在独立线程解码,不阻塞渲染,对编码格式的支持也较为完整,所以从必要性的角度看完全不需要 FFmpeg。
在性能方面,虽然浏览器解码也是基于 FFmpeg,但 WebAssembly 代码的执行性能终究达不到原生的水准。实测显示对于 mp3、aac、flac 等常见编码格式,WebAssembly 性能可以达到原生接口的 75% 左右,差别不是很明显,还是比较符合甚至超出预期的。
| 测试环境 | 输入格式 | 输出PCM格式 | 原生接口用时 | WebAssembly 用时 |
|---|---|---|---|---|
| Mac OS 12 Intel Core i9 Chrome 96 | 编码:mp3 声道:1 时长:3:55 | 采样率:44100 声道:同输入 样本格式:float32 | 290ms | 380ms |
| 编码:mp3 声道:2 时长:1:22:45 | 10.5~11s | 12.5~13s | ||
| 编码:aac 声道:2 时长:4:04 | 250ms | 330ms | ||
| 编码:flac 声道:2 时长:3:18 | 320ms | 400ms |
定位与时长
定位(Seek)与时长问题是决定我们选择分帧而非 FFmpeg 的关键性因素。
我们发现,在处理网络文件时,对于某些变比特率的音频(如 aac 文件、abr/vbr 的 mp3 文件、没有 SEEKTABLE 的 flac 文件等),FFmpeg 并不能准确获取音频时长以及进行精确定位。当然这并不是 FFmpeg 不够完美,只是这种音频由于比特率非恒定,其文件中数据位置与所对应时间点之间的对应关系通常是无规律的,这就导致它的时长计算与定位在理论上就无法做到极致精确,除非把资源完整加载到本地,但对于网络资源来说,它所带来的 IO 开销显然是不可接收的(尤其对于长文件)。因而要完美解决这个问题,对文件预处理并把必要的信息记录下来可能是唯一的方法。
对于播放器来说,定位与时长不精确可能只是体验上的问题,毕竟从整个音频的角度看,其内容并没有改变。而对于编辑器来说精确性是基本要求,在展示上都无法做到精确的话后续编辑也根本无法正常进行。
下面 3 个音频文件的内容完全相同,真实时长均为 3:55,其中 CBR 为原始音频,ABR、VBR 版本均由业界权威的 mp3 编码器 Lame 重新编码所得。当我们在浏览器中打开这些音频,可以明显发现 ABR 和 VBR 文件的时长展示和定位都是不准确的,其中 VBR 的时长误差更是接近一分钟。
轻量性
我自己尝试编译的精简版的 FFmpeg 中 wasm 文件大小为 1.4M,其中开启的解码器与 Chrome 的音频解码能力对齐,具体如下:
--enable-decoder=mp3 \
--enable-decoder=aac \
--enable-decoder=flac \
--enable-decoder=vorbis \
--enable-decoder=opus \
--enable-decoder=pcm_s8 \
--enable-decoder=pcm_s16le \
--enable-decoder=pcm_s24le \
--enable-decoder=pcm_s32le \
--enable-decoder=pcm_f32le \
--enable-decoder=pcm_alaw \
--enable-decoder=pcm_mulaw \
--enable-decoder=adpcm_ms \
--enable-decoder=gsm \而 ReolAudio 由于是纯 JavaScript,其代码量连同依赖一共也只有 80K(minified),仅相当于编译 FFmpeg 所产生的 WebAssembly 胶水代码的体量,所以从轻量性的角度说,ReolAudio 完胜。
成本和收益
FFmpeg:需要开发者熟悉 C 语言和 FFmpeg API,需要维护大量 C 语言代码,在实现 Seek 时还需要使用 SharedArrayBuffer 和 Atomics 处理多线程状态同步,复杂度较高,对前端开发者不太友好。
分帧:最大的成本是手写各种音频格式的分帧实现。但流行的音频格式也就固定的几种,且常年不变,所以只是一次性成本,后续几乎不存在额外的维护成本。虽然相较于 FFmpeg 方案来说也算是重复造轮子,但它在灵活性、可控性、高扩展性上所带来的收益还是比较高的。
所以综合来看,两者在实现上都有一定的成本和复杂性,但如果从成本所带来的收益上来看,还是分帧会具有一定的优势。
关于命名
ReolAudio,取自我非常喜欢的歌手 Reol,本名 れをる,是一位在演唱、作曲、作词方面都才华横溢且具有鲜明风格的日本艺术家。
核心能力
基本数据结构
在最基本的层面,ReolAudio 仅定义了“资源”和“帧”两种数据结构。
资源(AudioResource)
一个资源实例代表一个实际的音频文件,并包含了在解析它时所得到的一些关键元信息,其中有些信息是通用的,有些信息则仅存在于特定格式。
export interface AudioResource {
// 音频封装格式
type: AudioType;
// 文件总字节数
size: number;
// 音频总时长
duration: number;
// 音频采样率
sampleRate: number;
// 音频声道数
channelCount: number;
// 最小帧的字节数
minFrameSize?: number;
// 最大帧的字节数
maxFrameSize?: number;
// 每帧中包含采样点数(非恒定则为 0)
frameSampleSize?: number;
// 文件地址
url?: string;
// 文件数据
data?: ArrayBuffer;
// 音频帧序列
frames?: AudioFrame[];
// 文件名
name?: string;
// 与特定格式相关的信息或其他自定义信息
[other: string]: any;
}资源表(ResourceMap)
资源表其实就是一个资源 id 到资源实例的映射,方便其他对象通过资源 id 关联和查找相应实例。
export type ResourceMap = Record<number, AudioResource>
帧(AudioFrame)
一帧可看做源文件中一小段编码后的音频数据,也是编码和解码操作的最小单元。每个帧实例都至少包含它在源文件中的位置和大小,也可以包含一些额外信息如所属资源 id、采样点个数等。
export interface AudioFrame {
// 该帧所属的资源 id
uri?: number;
// 该帧在所属资源所有帧中的位置
index?: number;
// 该帧在源文件中的偏移位置
offset: number;
// 该帧在源文件中的字节数
size: number;
// 该帧所包含采样点个数
sampleSize?: number;
// 该帧第一个采样点在源音频所有采样点中的次序
sampleIndex?: number;
// 该帧波形摘要
wave?: Uint8Array;
}音频的解析与分帧
音频的解析与分帧旨在针对每一种需要支持的音频格式,分别实现对该类型文件的元信息读取和帧结构解析,并对外暴露统一接口。这部分是其他所有功能的基础,因为只有基于这些基本信息,才能支撑对音频的各种后续操作。
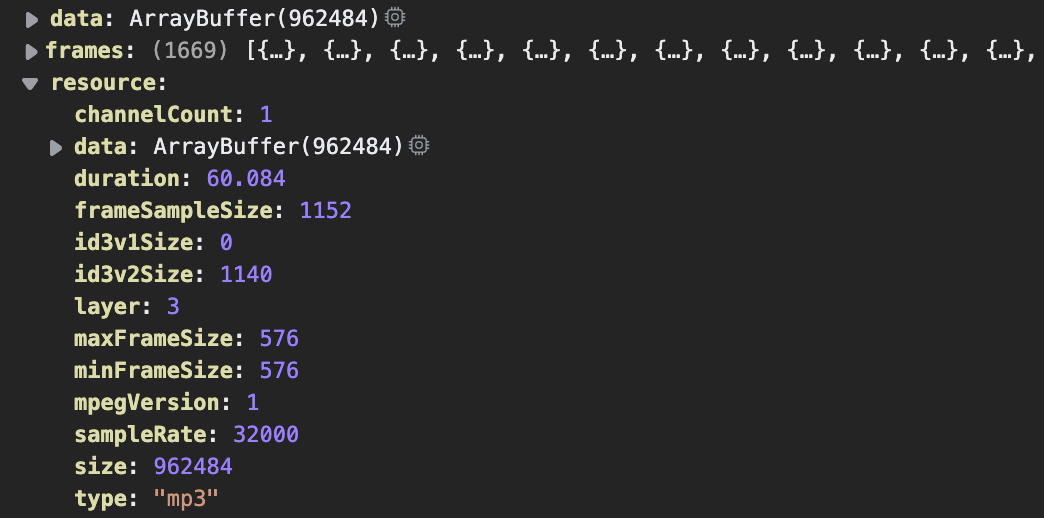
下面是一个 1min 时长 mp3 音频解析后得到的数据,可以看到整个音频包含 1669 个帧,resource 中不仅包含了所有基础音频信息,还有一些仅针对 mp3 的特殊字段,如 id3 tag 长度(id3v1Size、id3v2Size)、mpegVersion 等。
下面简要介绍下每种格式的基本处理方法。
MP3
结构相对比较简单,由可选的 id3v2 tag + mp3 frame 序列 + 可选的 id3v1 tag 组成,每个 mp3 frame 又分为 frame header 和 encoded data:
| id3v2? | mp3 frame | mp3 frame | ... | id3v1? (128 byte) | ||
|---|---|---|---|---|---|---|
| frame header | encoded data | frame header | encoded data | ... |
在处理它时首先需要“掐头去尾”,找出中间 mp3 frame 部分所在的位置。Id3v1 因为长度固定为 128 byte,所以比较好处理,只需检测文件末尾是否存在即可;对于 id3v2 来说,虽然根据规范可以在特定位置直接读取它的长度,但为了兼容长度记录错误的文件(现实中还是存在这种文件的...),仍需要手动解析出它的长度作为兜底,具体不展开叙述。
接下来进行 mp3 frame header 解析即可,所有关于当前帧的信息都可以从帧头读取,帧头详细结构可见:http://www.mp3-tech.org/programmer/frame_header.html。
在解析出必要的帧信息后,需要通过以下公式计算出该帧长度,以得到下一帧位置,并重复解帧操作,直到结束。
const size = Math.floor(sampleSize * bitrate * 125 / sampleRate + padding) * (layer === 1 ? 4 : 1)
MP4/M4A
不同于其他格式相对扁平的结构,mp4 由一堆层层嵌套的 box 组成,box 类型繁多且具有各自的解析方式,其官方规格说明文件更是超过 200 页。不过好在几乎所有 mp4 文件中音频流都为 aac 编码,也是浏览器唯一支持的 mp4 类型,因此我们会对用户上传的 mp4 文件进行预处理,提取其中的音频并转封装为 aac 文件,这样做的好处如下:
-
文件中的视频内容会被直接剔除。视频流的码率往往可以达到音频流的数倍乃至数十倍,所以只保留音频会大大减小文件体积,便于传输和存储。
-
转成 aac 后可以直接复用 aac 文件的处理逻辑,降低复杂度。
从 mp4 到 aac 的转换主要是先解析出整个文件的结构,得到一个层层嵌套的 box 树,然后单独查找并解析某些特定的 box(如 stsc、stsz、stco 等等)以计算出源文件中音频流每一帧的所在位置,再从源文件中切取出每一帧、添加 adts header 并组合成完整的 aac 文件。整个流程比较复杂,这里不展开叙述。
AAC
最简单的格式,由一连串的 adts frame 组成,每个 adts frame 又分为 adts header 和 encoded data:
| adts frame | adts frame | ... | ||
|---|---|---|---|---|
| adts header | encoded data | adts header | encoded data | ... |
其结构和处理方法均与 mp3 相似,这里不再赘述。
WAV
Wav 文件中存储的是未经编码的 PCM 数据(单个采样可能经过编码),最小存储单元是采样点,没有帧的概念。不过根据使用场景的需要,也可以人为进行分帧,如把每 30ms 的数据分为一帧。
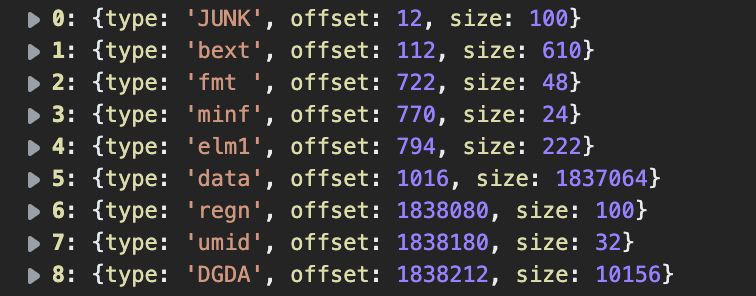
在最外层,wav 由一堆无序的 block 拼接而成,虽然 block 的类型多种多样,但我们实际需要的只有 fmt、fact、data 三种,其中 fmt 存储了音频元数据,fact 是某些编码格式特有且固定的,data 则存储了实际采样数据。在处理时我们首先解出文件中每个 block 的类型和位置(如下图),然后再分别处理我们所关注的 block 即可。
片段解码
提供音频片段解码能力,因为流式解码和随机解码都是以音频片段为最小解码单元,而非完整的音频文件,所以片段解码是实现前两者的基础。
解码方式
浏览器提供了两套 API 可用于音频解码,分别是 Web Audio API 中的 decodeAudioData 以及较新的 Web Codecs API。虽然前者的目标场景为完整文件的一次性全量解码,但通过调研我们发现还是有简单的办法用它来解码音频片段的,再加上兼容性、易用性上的巨大优势,我们毫无疑问选择它作为底层的解码引擎。两者详细对比如下:
| decodeAudioData | WebCodecs | |
|---|---|---|
| 目标场景 | 一次性全量解码 | 流式解码 ✅ |
| 兼容性 | chrome 14+, firefox 25+ ✅ | chrome 94+ |
| 编码格式支持 | 全部可播格式 ✅ | - wav 仅支持 a-law/u-law - 其他全部可播格式 |
| 格式检测 | 自动 ✅ | 无 |
| 重采样 | 自动 ✅ | 无 |
| 异步 | 是 ✅ | 是 ✅ |
片段处理
由于 decodeAudioData 的输入必须是完整的音频文件数据,所以在拿到音频片段后,需要根据其格式来确定是否要做后处理来将其包装为结构上的完整文件,再进行解码。
MP3
无论是 id3v2 tag 还是 id3v1 tag 都不是必须存在的,所以由若干个 mp3 frame 组成的片段从结构上仍然可以看做完整的 mp3 文件,因此 mp3 数据片段无需处理。
MP4/M4A
decodeAudioData 只能解码完整的 mp4 文件,但好在我们对 mp4 都会进行预处理转成 aac,所以无需单独处理 mp4。
AAC
本身就是一系列 aac 帧的组合,所以片段仍可看作完整文件,无需处理。
WAV
拿到 wav 数据片段后,需对其添加必要的 block,以拼装成完整的 wav 文件,才能进行解码。
由于 wav 中采样点的编码有多种(a-law, u-law, GSM 等),而每种文件中 block 结构也不尽相同,所以纯手工加 block 是比较繁琐的工作。因而我们采用的方式是在解析文件时直接从源文件提取必要的 block(fmt、fact),以 base64 格式保存在 resource 实例中,后续直接拼接并进行简单的数据修改即可。
播放器
SamplePlayer 是一个比较基础、底层的播放器,并不能直接播放音频资源或帧,而是需要向它输入原始的采样数据(float32 格式的 PCM 数据)。所以一般它是被用来继承而非直接使用,根据具体应用场景和需求来扩展它的能力。
技术选型
浏览器在音频方面提供了大量的 API,其丰富的功能几乎足以支撑任何复杂的音频应用,但同时也容易使我们在选择时犯难,因而在设计这个播放器之初,我们也详细对比并尝试了几种不同方案:
| 方案 | MSE | AudioBufferSourceNode | ScriptProcessor**Node** | AudioWorkletNode |
|---|---|---|---|---|
| 可行性 | 因支持的封装和编码格式非常有限,且不支持多种格式数据的混合,而无法实现需求 ❌ | AudioBuffer 拼接式播放 ✅ 为每次输入构建 AudioBufferSourceNode 并 schedule 到当前 AudioContext 时间线中 | 回调填充式播放 ✅ 在 ScriptProcessorNode 回调中从缓冲区读取数据 | 回调填充式播放 ✅ 在 AudioWorkletNode 回调中从缓冲区读取数据 |
| 优势 | - 兼容性好(chrome >= 14) - 便携:无需额外的脚手架配置 | - 用法简单,实现成本最低 - 便携:无需额外的脚手架配置 | - 是 ScriptProcessor 的官方替代品 - 回调执行在独立线程,可保证播放流畅性 | |
| 不足 | - 虽然理论上功能可以满足,但实现上不如回调填充式简单、清晰、直接,许多地方比较 hack - 暂停/继续有一定开销,缓存不易控制,暂停需清空已缓存的 SourceNode,继续播放不能直接复用已加载数据 | - 接口已被废弃 - 回调执行在主线程,当主线程 CPU 占用高时不能保证回调可及时执行(与 setTimeout 类似),导致播放卡顿或产生尖刺音 | - 仅支持 https 环境 - 便携性不是很好,因为使用了 AudioWorklet,所以需要脚手架额外引入一定的配置才能支持 | |
| 结论 | 不够底层,灵活性达不到要求 ❌ | 不是特别契合使用场景,综合评定不如 AudioWorkletNode ❌ | 受主线程 CPU 占用率影响过大 ❌ | 功能上完全满足需求,不足可以接受 ✅ |
经过综合评估,我们选择了基于 AudioWorkletNode 的回调填充式播放方案,同时,它也是官方推荐的用以实现高精度、高定制化播放器的接口:
If sample-accurate playback of network- or disk-backed assets is required, an implementer should use AudioWorkletNode to implement playback.
摘自: https://webaudio.github.io/web-audio-api/#AudioBufferSourceNode
设计方案
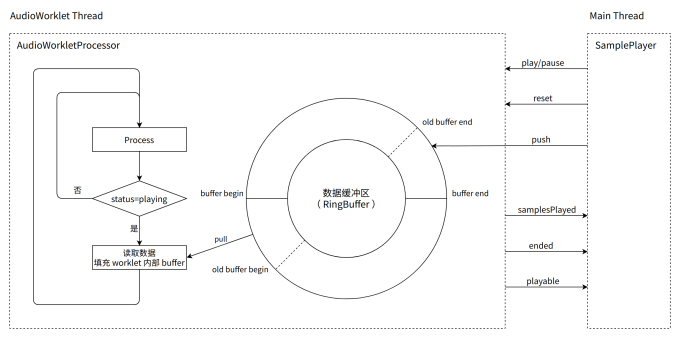
import { SamplePlayer } from 'xxx'
async function main() {
const ctx = new AudioContext({
sampleRate: 44100,
})
// 初始化:加载 AudioWorklet 处理脚本
await SamplePlayer.init(ctx)
const player = new SamplePlayer({
context: ctx,
channelCount: 2,
// 内部 buffer 最大容量为 60s 音频数据
bufferMaxDuration: 60,
})
player.connect(ctx.destination)
document.getElementById('play').onclick = () => {
player.play()
}
document.getElementById('pause').onclick = () => {
player.pause()
}
document.getElementById('push-data').onclick = async () => {
// 每声道一个 Float32Array 实例
const pcm: Float32Array[] = await getPcmDataSomeHow()
player.push(pcm)
}
}
main()序列化与反序列化
序列化主要是解决帧序列的压缩和存储问题。虽然帧序列仅仅是普通的数组,可以用 JSON 来表示,但 JSON 的信息密度低(例如存储一个 float32,二进制需要 4 个字节,而 JSON 可能需要十多个字节),即便可以进行再压缩,但相较于转换成紧密的二进制形式再压缩,数据量还是会大一些,而且转成二进制要比转成 JSON 性能更高。
因此,序列化主要是设计了一个专门把帧序列转成二进制形式的流程,转换后再对其进行 deflate 压缩,最终输出为二进制或字符串的形式。经实测,每小时帧信息的最终序列化结果不超过 1M,完全满足本地或网络存储的要求。
序列化
多个帧的序列化只需将每帧的序列化结果拼接即可,对于单个帧,序列化流程为:
1 . 定义帧字段枚举(FrameField)以及每个字段的值类型(FrameType),这样帧的每个字段名都只需要用一个 uint8 存储即可,字段值以特定的格式进行读写:
export enum FrameField {
uri = 1,
index = 2,
offset = 3,
size = 4,
sampleSize = 5,
sampleIndex = 6,
wave = 7,
}
const FrameType: Record<FrameField, string> = {
[FrameField.uri]: 'u16',
[FrameField.index]: 'u32',
[FrameField.offset]: 'u32',
[FrameField.size]: 'u16',
[FrameField.sampleSize]: 'u16',
[FrameField.sampleIndex]: 'f64',
[FrameField.wave]: 'wave',
}其中:wave 为波形摘要,它是一种自定义数据格式(专为 frame-based 框架而设计,下文有介绍),其结构为第一个字节存储振幅样本个数,后续每个字节存储各个振幅样本。
2 . 遍历帧中每个字段,以 uint8 的格式写入字段 id,再根据字段值类型写入具体值,之后以相同的方式处理下一个字段。
3 . 所有字段序列化完毕后,在序列化结果开头以 uint8 的格式写入总长度即可。
反序列化
按照序列化时的规则反向解析出每一帧的信息即可,这里不再赘述。
格式检测
格式检测作为音视频处理中的基础功能,有着广泛的应用场景,例如对用户的输入进行过滤、根据格式对文件做不同的处理等。由于文件名可任意修改,根据扩展名来判断文件格式通常是不可靠的,因而格式检测旨在通过文件内容来推断出文件真实格式。
基本目标
就我个人的总结,可靠的格式检测应当实现以下两个目标:
- 对于是某种格式的文件,一定能够检测出它是该种格式。
- 对于不是某种格式的文件,尽可能让它不被检测成该种格式。
目标 1 比较容易理解,假如输入的是一个标准的 mp3 文件,那么就一定要检测出它是 mp3,保证不会出现“冤枉好人”的场景,因此是必须要 100% 确保的。
对于目标 2,其实是功能与成本的一个权衡。为保证性能,通常我们仅仅是检测文件是否符合某种格式的特征(Magic Number,通常是某几个特定的字节),而这也就必然会产生不是某种格式的文件却能通过检测的可能性,为降低这种可能性,可以尽量检测较多的特征。
file-type
file-type 是 npm 上非常流行的文件格式检测工具,它支持多种输入形式(如 Buffer、TypedArray、Blob、Stream 等),以及几乎所有常见文件格式,包括各种音视频、图片、文档、压缩格式等。
ReolAudio 最初也直接依赖了它,但因为存在一些不符合要求的点而已不再使用:
-
不能满足目标 1。例如,如果一个 mp3 文件中记录的 id3v2 tag 长度与实际不符,将不能检测出它是 mp3 文件。
-
其针对浏览器的版本依然会引入 node 环境相关 polyfill(如 Buffer),这对于一个 library 来说是不可接受的。
-
检测的格式太多,不够轻量,且影响性能。
ReolAudio 的实现
ReolAudio 实现了一个音频格式检测函数:getType。它简单、可靠、轻量,使用时只需传入包含文件内容的 ArrayBuffer 即可:
import { getType, AudioType } from 'xxx'
const typ = getType(fileData)
if (typ === AudioType.MP3) {
console.log('File is mp3')
}getType 的不同之处在于它不仅检测 Magic Number,更充分利用了已有的解帧能力,这使得它的检测结果具有极高的准确性和可靠性,在非刻意伪造的情况下几乎不可能产生错误检测。
以下代码展示了我们如何判断一个文件是否为 mp3:
export function isMP3(buf: Uint8Array): boolean {
// 以 "ID3" 起始,说明是 id3v2 tag,该结构仅存在于 mp3,因而检测通过
if (buf[0] === 0x49 && buf[1] === 0x44 && buf[2] === 0x33) {
return true
}
// 没有 id3v2 tag 的情况下,进行 mp3 帧检测
try {
// 首先需通过 mp3 帧头检测
if (mp3.isFrameStart(buf, 0)) {
// 由于帧头不具备明显特征,通过检测也不能确保是 mp3,
// 因而此处尝试进行解帧,目的是得到下一帧位置
const { frame } = mp3.parseFrame(buf, 0)
// 若解出的下一帧位置仍通过帧头检测,则有足够的信心判定源文件是 mp3
if (mp3.isFrameStart(buf, frame.size)) {
return true
}
}
} catch (err) {
return false
}
return false
}目前支持的格式有:mp3、mp4/m4a、aac、wav、flac、ogg、flv、mid。
上层封装
frame-based
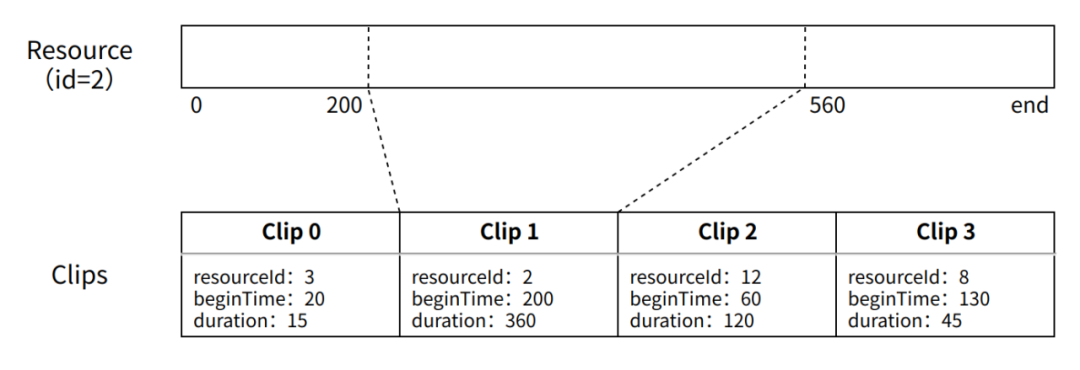
framed-based 是专为音浮及相似音频处理场景所打造的在线音频处理框架。它以“帧序列”来表示当前会话状态,支持不同格式不同文件中帧的组合,通过直接编辑帧序列来轻松实现音频的裁剪、拼接、插入、替换等操作,同时封装了强大的帧序列解码器、播放器、波形绘制器。
解码器
可独立解码片段:在完整的帧序列中,从属于同一个资源、且与在源文件中顺序一致且连续的子序列称为一个“可独立解码片段”。一个完整的帧序列也可看作由多个可独立解码片段组成,每个片段的帧所对应的音频数据可以进行一次性加载和解码。

-
输入
-
frames:帧序列
-
resourceMap:资源表
-
beginIndex:解码起始帧索引
-
targetDuration:目标解码时长(因为可能超出当前可独立解码片段范围,所以实际解码时长不一定能达到目标数值)
-
targetFrameCount:目标解码帧数(同上)
-
sampleRate:解码采样率
-
输出
-
endIndex:实际解码到的帧索引
-
duration:实际解码时长
-
data:解码后的 PCM 数据,每声道一个 float32Array
-
ended:是否已触达最后一帧
根据输入和可独立解码片段边界,我们可以得到本次解码的帧范围,再通过帧范围确定该片段在源文件中的偏移和长度,最后通过 HTTP Range 头加载下来并调用已有的片段解码能力去解码即可。
在确定解码帧范围时,有一个特殊处理,我们称之为“垫帧”:
In the case of Layer I or Layer II, frames are totally independent from each other, so you can cut any part of an MPEG audio file and play it correctly. The player will then play the music starting from the first full valid frame it will find. However, in the case of Layer III, frames are not always independant. Due to the possible use of the "byte reservoir", wich is a kind of internal buffer, frames are often dependent of each other. In the worst case, 9 input frames may be needed before beeing able to decode one single frame.
摘自: http://www.mp3-tech.org/programmer/frame_header.html
根据上述资料,帧间的数据并非完全独立,对于 mp3 文件,在最坏的情况下,需要有 9 帧的预输入才能得到 1 帧的准确解码数据,因此我们在确定帧范围时,都在目标范围的基础上往前追溯最多 9 帧,待解码完成后,再将这些帧对应的数据剔除。对于 aac 编码,我们目前没有找到相关资料,但实测显示,把“垫帧”数调到 2 就可以完全避免解码数据不完整的问题,因此我们目前将其设定为 2。
播放器
基于 SamplePlayer 和已有的帧序列解码能力,要实现帧序列的播放,其实仅额外需要一个数据加载调度机制即可。FramePlayer 继承自 SamplePlayer,在此基础之上实现了一个定时任务,用于根据当前播放进度自动调用解码器进行数据的预加载和解码,同时处理 Seek、解码数据裁剪等细节问题。
由于是继承关系,其使用方法与 SamplePlayer 基本一致,只需要额外指定要播放的帧序列和资源表、以及一些必要的参数来定制化它的数据加载策略即可:
import { FramePlayer } from 'xxx'
async function main() {
const ctx = new AudioContext()
await FramePlayer.init(ctx)
const player = new FramePlayer({
context: ctx,
})
player.connect(ctx.destination)
player.resourceMap = resourceMap
player.setFrames(frames)
// 每次最多加载的音频时长,单位 s
player.decodeDuration = 20
// 起播时最多加载的音频时长,单位 s,通常设定较小的值以降低起播时间
player.startupDecodeDuration = 10
// 加载音频提前时间,单位 s
player.loadBefore = 10
// 检测是否需要加载新数据的定时任务执行间隔,单位 s
player.tickInterval = 0.5
player.seek(20)
player.play()
}
main()波形绘制器
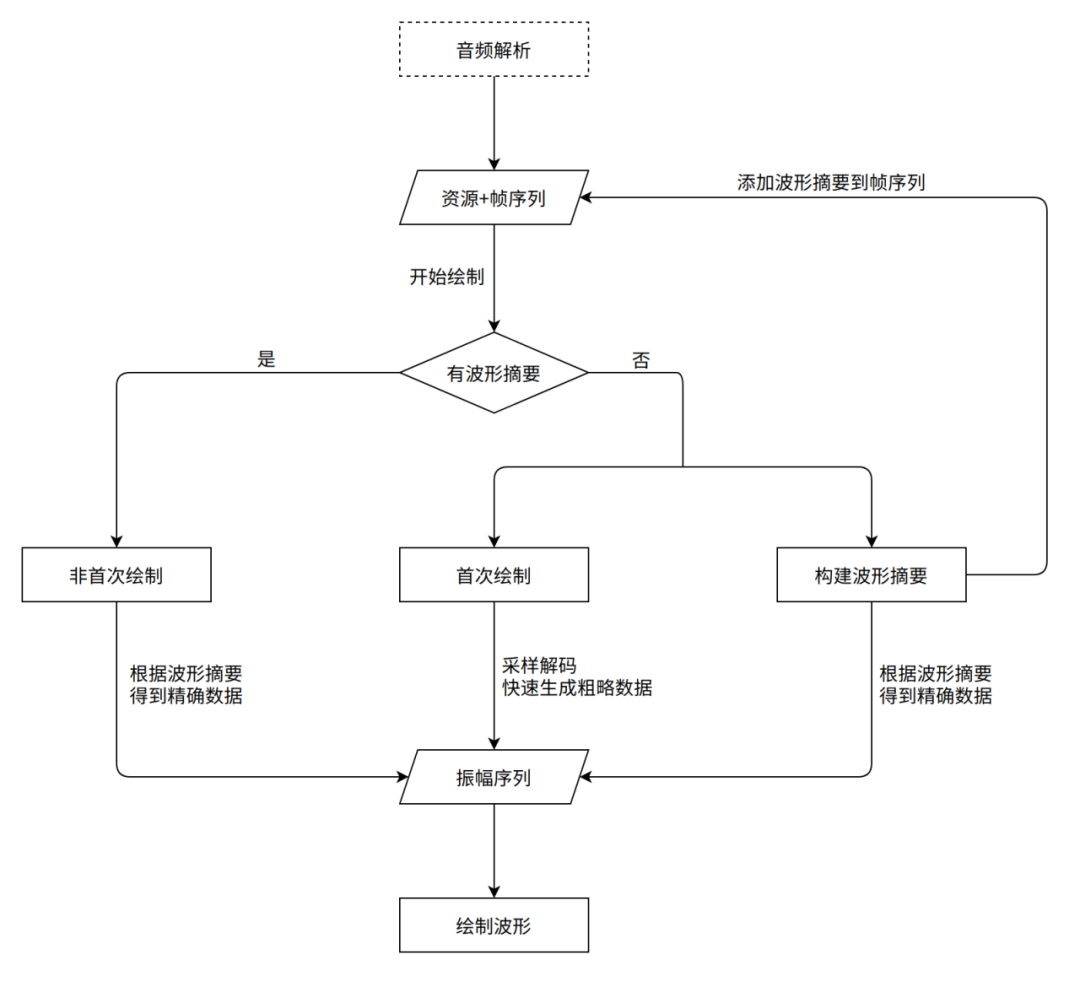
为了绘制出精确的波形,对音频进行全量解码仍然是不可避免的操作。因此当首次加载一个音频时,我们仍会对它全量解码,但并不需要保存解码后的数据,我们只是用这些数据来一次性生成“波形摘要”并保存起来。
波形摘要可以看作是降低时间精度(振幅精度基本不变)后的波形。与波形相同,它也是振幅序列,不同的是它仅存储一个声道的数据,每个振幅并不代表一个采样点,而是一小段时间内(默认 20ms,这样每帧大概 1~2 个幅值)的最大振幅,且用 uint8 来存储。根据这个规则,我们可以计算出对于 44100hz、双声道的音频文件,波形摘要的数据量仅为解码后 PCM 数据总量的 (1000 / 20) / (44100 * 2 * 4) = 1 / 7065,但即便降低到如此精度,对于音浮以及大部分对波形时间精度要求不高的应用来说都是足够的。我们将这些摘要存储在对应的帧中,之后无论怎样编辑帧序列,都只需要重新遍历一次即可绘制出波形,无需额外的解码操作。
此外,由于构建波形摘要本身需要一定时间,为了降低用户看到波形前的等待时间,我们充分利用了随机解码的能力,在构建波形摘要的同时,在音频内取若干等距时间点做采样解码,得到一个粗略的振幅序列,虽然它在振幅值上会有误差,但其构建速度非常快,可以快速呈现给用户,等摘要构建完成后再用精确的波形来覆盖它。
粗略波形(用时约 400ms):


clip-based
基于 Clip 的音视频编辑和处理是业界比较标准的方案。与 frame-based 不同,它将会话状态表示为 Clip 序列的形式,每个 Clip 相当于对某个音频资源中某一连续时间片段的引用,在播放时,根据 Clip 信息来实时加载和解码必要的音频资源片段。
cut-audio
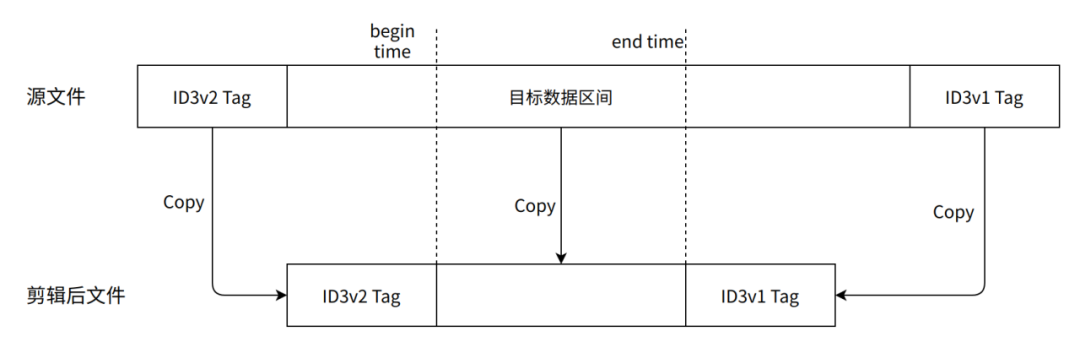
基于已有的分帧能力,可以轻易实现简单的音频剪辑。cut-audio 的工作原理类似我们在使用 FFmpeg 时指定了 -c copy 参数,当我们输入了剪辑片段的起止时间,它会根据元数据和分帧信息寻找到最近似的数据片段并从源文件中截取下来,再进行简单的封装操作即可得到剪辑后的文件。整个过程只有数据拷贝,不涉及任何编解码,因而具有极高的性能。
以 mp3 为例:
接入表现
音浮
该套技术方案最初专为解决音浮的长音频问题而设计,由于是全新的技术架构而非简单优化,接入后各方面性能指标均有显著提升。
以下性能指标对比数据均取自一个 1.5h、44100hz、双声道的 mp3 文件。
内存占用
-
接入前:常驻占用 1.9 G,编辑时瞬时占用高达 3.5 G
-
接入后:< 250M
起播时间
-
接入前:约等于全量解码时间,12s 左右
-
接入后:< 100ms
首次波形绘制时间
-
接入前:约等于全量解码时间,12s 左右
-
接入后:粗略波形绘制时间 < 1s
粗略波形:


本地/云草稿
-
接入前:解码后数据量太大,无法存储
-
接入后:会话状态通过帧序列/资源表保存,连同波形摘要数据量不超过 1.5M
SoundOn
SoundOn 是一个服务于海外音乐人的开放平台,帮助音乐人将他们的音乐分发到字节跳动旗下业务和其他平台上。
在线剪辑
尽管这些问题很可能是由不正确的使用方式或参数设定导致的,但基于 ReolAudio 来实现在线剪辑显然是更好的选择,而 cut-audio 正是在这种背景下诞生,接入后各项指标均有显著提升:
-
不存在兼容性问题,因为它完全不依赖任何浏览器 API。
-
由于直接复用源文件数据,不涉及编解码,其耗时、内存占用均可忽略。
-
经过一段时间的更新迭代后,剪辑成功率更是达到了 100%。
格式检测
平台最初直接使用 file-type 做格式检测,由于其不准确的问题,经常导致符合要求的文件无法被上传。在切换到 ReolAudio 后,便完全避免了这种 case 的产生。
未来计划
更多的音频格式支持
目前仅根据业务需要支持了几种最流行的音视频格式,未来会支持更多浏览器可播格式(如 flac、ogg),甚至某些浏览器原生不可播格式(如 flv)。
-
flac : 结构大体上与 mp3 相似。
-
flv : 音频多为 aac 编码,可以像处理 mp4 那样先转成 aac,且它的结构远比 mp4 简单。
-
webm : 有待调研。
API 文档建设
由于目前主要是团队内项目在使用,现有文档也多为介绍性的技术文档,缺乏完备的 API 文档和使用手册,因此后续会补充这部分内容。
实现 clip-based 框架
基于 Clip 的音视频处理是业界较为标准和成熟的方案。对于 ReolAudio 来说,得益于其强大的核心能力,完全可以在其之上以较低的成本实现 clip-based 架构。因此未来计划实现它并与 frame-based 作为两套并列的音频处理方案。
在 Web DAW 中的应用探索
相较于音浮,类似 Web DAW 的重音频编辑场景更加复杂,对内存占用、编辑性能、渲染性能等方面具有更高的要求,对音频处理基础架构有更高的挑战。另一方面,传统的基于 AudioBuffer 的音频编辑内存占用高,且单个会话需要保存大量 PCM 音频数据,导致项目文件体积庞大,非常不利于会话状态的本地/云端持久化、撤销重做、多人协作编辑等。而 clip-based 架构的特性天然与 Web DAW 应用场景高度吻合,可以完美解决上述问题。
参考
-
MPEG Audio Frame Header - CodeProject
-
MP3' Tech - Frame header
-
[Developer Information - ID3.org](<https://id3.org/Developer Information>)
-
ISO - ISO/IEC 14496-12:2020 - Information technology — Coding of audio-visual objects — Part 12: ISO base media file format
-
ADTS - MultimediaWiki
-
Wav file format - musicg-api
-
Audio Worklet Design Pattern | Web | Google Developers
-
MIME Sniffing Standard