基于pnpm + lerna + typescript的最佳项目实践 - 理论篇
本系列文章分为两篇:
理论篇和实践篇理论篇:介绍pnpm(pnpm的特点、解决的问题等)、lerna(lerna的常用命令)、typescript 实践篇:业务线中如何配置使用pnpm、lerna以及需要注意的坑有哪些 感兴趣的小伙伴赶紧收藏学习吧 ^_^
Part1pnpm
pnpm是一款当代受欢迎 新兴(问题较多) 的包管理工具。
为什么会出现pnpm?因为yarn的出现并没有满足作者的一些期待,反而有些失望。
After a few days, I realized that Yarn is just a small improvement over npm. Although it makes installations faster and it has some nice new features, it uses the same flat node_modules structure that npm does (since version 3). And flattened dependency trees come with a bunch of issues 几天后,我意识到 Yarn 只是对 npm 的一个小小的改进。尽管它使安装速度更快,并且具有一些不错的新功能,但它使用与npm相同的平面node_modules结构(自版本 3 起)。
扁平化的依赖树带来了一系列问题(具体后面会讲)
为什么叫pnpm?是因为pnpm作者对现有的包管理工具,尤其是npm和yarn的性能比较特别失望,所以起名叫做perfomance npm,即pnpm(高性能npm)
如何突显pnpm的性能优势?在pnpm官网上,提供了一个benchmarks图表,它比对了项目[1]在npm、pnpm、yarn(正常版本和PnP版)中,install、update场景下的耗时:
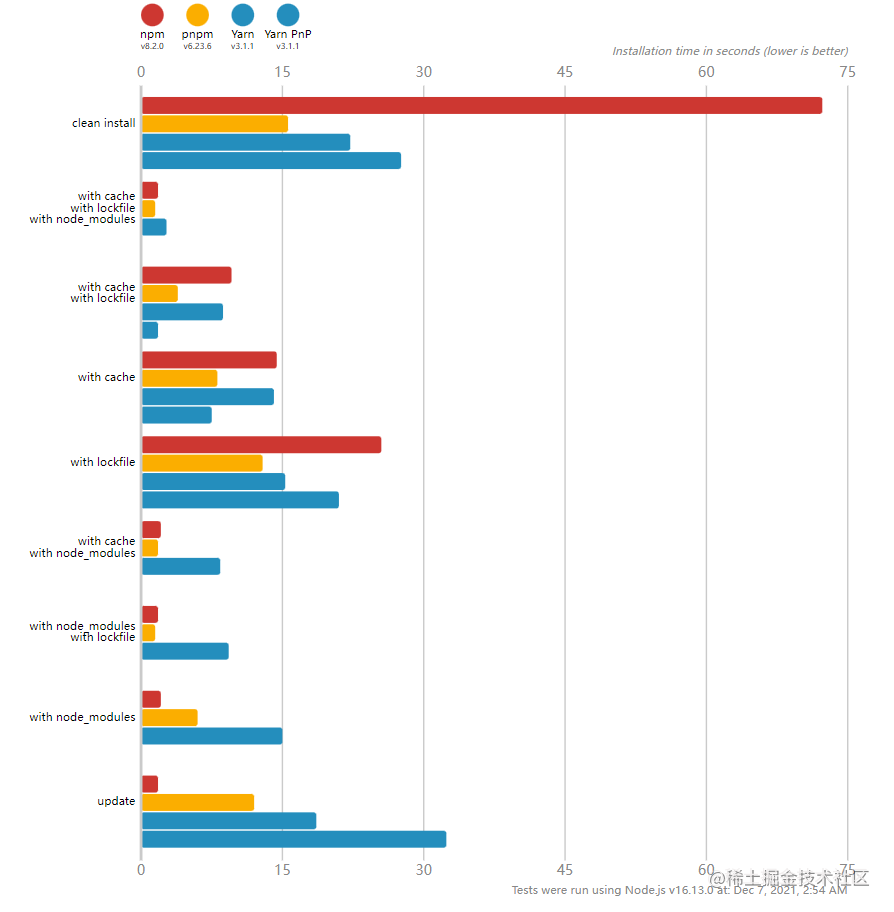
下面表格是上图中的具体数据:
| action | cache | lockfile | node_modules | npm | pnpm | Yarn | Yarn PnP |
|---|---|---|---|---|---|---|---|
| install | 1m 12.2s | 15.7s | 22.1s | 27.5s | |||
| install | ✔ | ✔ | ✔ | 1.6s | 1.3s | 2.6s | n/a |
| install | ✔ | ✔ | 9.5s | 4s | 8.6s | 1.9s | |
| install | ✔ | 14.2s | 14.2s | 14.2s | 7.4s | ||
| install | ✔ | 25.4s | 13s | 15.3s | 21.1s | ||
| install | ✔ | ✔ | 2.1s | 1.8s | 8.3s | n/a | |
| install | ✔ | ✔ | 1.6s | 1.4s | 9.4s | n/a | |
| install | ✔ | 2.1s | 5.9s | 15s | n/a | ||
| update | n/a | n/a | n/a | 1.6s | 12.1s | 18.7s | 32.4s |
可以看到pnpm(橘色)有很明显性能提升,在我们项目实践中(基于gitlib)提升更明显(跟store dir搭配使用)
在讨论性能提升原因之前,我们先了解下现有包管理工具中node_modules存在的问题
1node_modules 结构
Nested installation 嵌套安装
在 npm@3 之前,node_modules结构是干净、可预测的,因为node_modules 中的每个依赖项都有自己的node_modules文件夹,在package.json中指定了所有依赖项。例如下面所示,项目依赖了foo,foo又依赖了bar,依赖关系如下图所示:
node_modules
└─ foo
├─ index.js
├─ package.json
└─ node_modules
└─ bar
├─ index.js
└─ package.json上面结构有两个严重的问题:
- package中经常创建太深的依赖树,这会导致 Windows 上的目录路径过长问题
- 当一个package在不同的依赖项中需要时,它会被多次复制粘贴并生成多份文件
Flat installation 扁平安装
为了解决上述问题,npm 重新考虑了node_modules结构并提出了扁平化结构。在npm@3+ 和 yarn中,node_modules 结构变成如下所示:
node_modules
├─ foo
| ├─ index.js
| └─ package.json
└─ bar
├─ index.js
└─ package.json可以看到,hoist机制下,bar被提升到了顶层。如果同一个包的多个版本在项目中被依赖时,node_modules结构又是怎么样的?
例如:一个项目App直接依赖了A(version: 1.0)和C(version: 1.0),A和C都依赖了不同版本的B,其中A依赖B 1.0,C依赖B 2.0,可以通过下图清晰的看到npm2和npm3+结构差异:
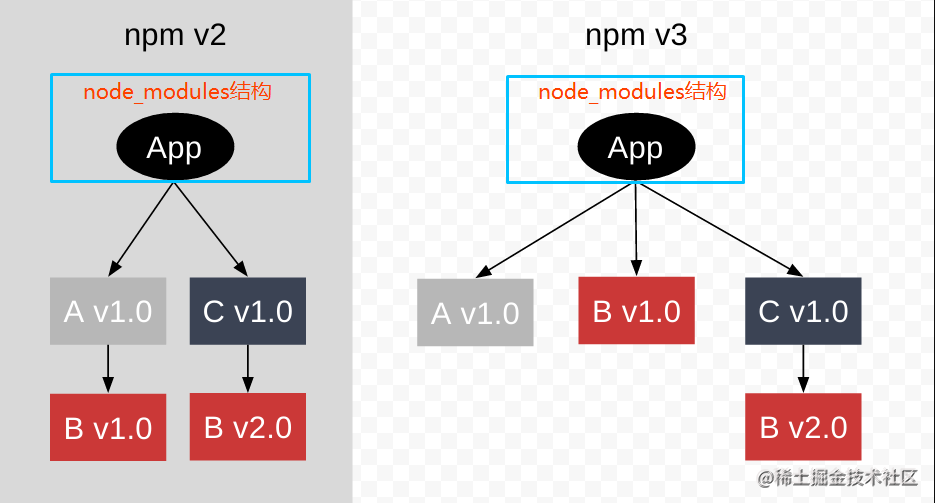
包B 1.0被提升到了顶层,这里需要注意的是,多个版本的包只能有一个被提升上来,其余版本的包会嵌套安装到各自的依赖当中(类似npm2的结构)。

至于哪个版本的包被提升,依赖于包的安装顺序!
依赖变更会影响提升的版本号,比如变更后,有可能是B 1.0 ,也有可能是 B 2.0被提升上来(但只能有一个版本提升)
细心的小伙伴可能发现,这其实并没有解决之前的问题,反而又引入了新的问题

npm3+和yarn存在的问题
Phantom dependencies 幽灵依赖
Phantom dependencies 被称之为幽灵依赖或幻影依赖,解释起来很简单,即某个包没有在package.json 被依赖,但是用户却能够引用到这个包。
引发这个现象的原因一般是因为 node_modules 结构所导致的。例如使用 npm或yarn 对项目安装依赖,依赖里面有个依赖叫做 foo,foo 这个依赖同时依赖了 bar,yarn 会对安装的 node_modules 做一个扁平化结构的处理,会把依赖在 node_modules 下打平,这样相当于 foo 和 bar 出现在同一层级下面。那么根据 nodejs 的寻径原理,用户能 require 到 foo,同样也能 require 到 bar。
nodejs的寻址方式:(查看更多[2])
- 对于核心模块(core module) => 绝对路径 寻址
- node标准库 => 相对路径寻址
- 第三方库(通过npm安装)到node_modules下的库: 3.1. 先在当前路径下,寻找 node_modules/xxx 3.2 递归从下往上到上级路径,寻找 ../node_modules/xxx 3.3 循环第二步 3.4 在全局环境路径下寻找 .node_modules/xxx
NPM doppelgangers NPM分身
这个问题其实也可以说是 hoist 导致的,这个问题可能会导致有大量的依赖的被重复安装.
举个例子:项目中有packageA、packageB、packageC、packageD。packageA依赖packageX 1.0和packageY 1.0,packageB依赖packageX 2.0和packageY 2.0,packageC依赖packageX 1.0和packageY 2.0,packageD依赖packageX 2.0和packageY 1.0。
在npm2时,结构如下
- package A
- packageX 1.0
- packageY 1.0
- package B
- packageX 2.0
- packageY 2.0
- package C
- packageX 1.0
- packageY 2.0
- package D
- packageX 2.0
- packageY 1.0在npm3+和yarn中,由于存在hoist机制,所以X和Y各有一个版本被提升了上来,目录结构如下
- package X => 1.0版本
- package Y => 1.0版本
- package A
- package B
- packageX 2.0
- packageY 2.0
- package C
- packageY 2.0
- package D
- packageX 2.0如上图所示的packageX 2.0和packageY 2.0被重复安装多次,从而造成 npm 和 yarn 的性能一些性能损失。
这种场景在monorepo 多包场景下尤其明显,这也是yarn workspace经常被吐槽的点,另外扁平化的算法实现也相当复杂,改动成本很高。那么pnpm是如何解决这种问题的呢?

2pnpm的破解之道:网状 + 平铺的node_modules结构
一些背景知识:inode、hardl link和symbolic link的基础概念[3]
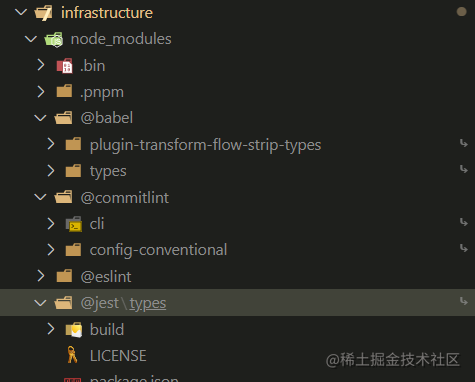
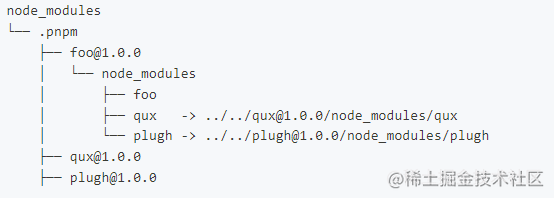
pnpm的用户可能会发现它node_modules并不是扁平化结构,而是目录树的结构,类似npm version 2.x版本中的结构,如下图所示
同时还有个.pnpm目录,如下图所示
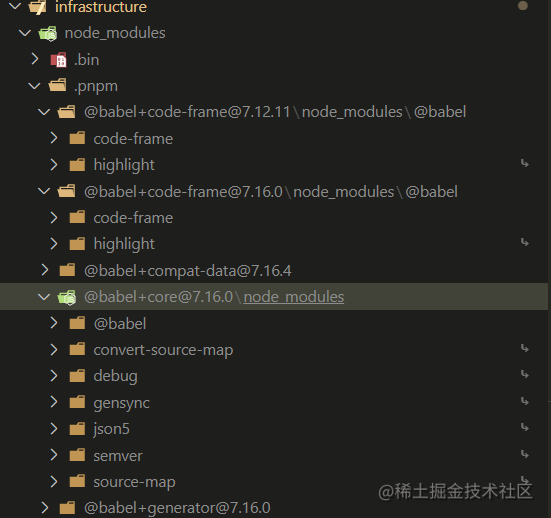
.pnpm 以平铺的形式储存着所有的包,正常的包都可以在这种命名模式的文件夹中被找到(peerDep例外):
.pnpm/<organization-name>+<package-name>@<version>/node_modules/<name>
// 组织名(若无会省略)+包名@版本号/node_modules/名称(项目名称)我们称.pnmp为虚拟存储目录,该目录通过<package-name>@<version>来实现相同模块不同版本之间隔离和复用,由于它只会根据项目中的依赖生成,并不存在提升,所以它不会存在之前提到的Phantom dependencies问题!
那么它如何跟文件资源进行关联的呢?又如何被项目中使用呢?
答案是Store + Links!
Store
pnpm资源在磁盘上的存储位置。
pnpm 使用名为 .pnpm-store的 store dir[4],Mac/linux中默认会设置到{home dir}>/.pnpm-store/v3;windows下会设置到当前盘的根目录下,比如C(C/.pnpm-store/v3)、D盘(D/.pnpm-store/v3)。
具体可以参考 @pnpm/store-path 这个 pnpm 子包中的代码:
const homedir = os.homedir()
if (await canLinkToSubdir(tempFile, homedir)) {
await fs.unlink(tempFile)
// If the project is on the drive on which the OS home directory
// then the store is placed in the home directory
return path.join(homedir, relStore, STORE_VERSION)
}由于每个磁盘有自己的存储方式,所以Store会根据磁盘来划分。如果磁盘上存在主目录,存储则会被创建在
<home dir>/.pnpm-store;如果磁盘上没有主目录,那么将在文件系统的根目录中创建该存储。例如,如果安装发生在挂载在/mnt的文件系统上,那么存储将在/mnt/.pnpm-store处创建。Windows系统上也是如此。
可以在不同的磁盘上设置同一个存储,但在这种情况下,pnpm 将复制包而不是硬链接它们,因为硬链接只能发生在同一文件系统同一分区上。
windows store如下图所示
pnpm install的安装过程中,我们会看到如下的信息,这个里面的Content-addressable store就是我们目前说的Store

CAS 内容寻址存储,是一种存储信息的方式,根据内容而不是位置进行检索信息的存储方式。
Virtual store 虚拟存储,指向存储的链接的目录,所有直接和间接依赖项都链接到此目录中,项目当中的.pnpm目录

如果是 npm 或 yarn,那么这个依赖在多个项目中使用,在每次安装的时候都会被重新下载一次
如图可以看到在使用 pnpm 对项目安装依赖的时候,如果某个依赖在 sotre 目录中存在了话,那么就会直接从 store 目录里面去 hard-link,避免了二次安装带来的时间消耗,如果依赖在 store 目录里面不存在的话,就会去下载一次。
当然这里你可能也会有问题:如果安装了很多很多不同的依赖,那么 store 目录会不会越来越大?
答案是当然会存在,针对这个问题,pnpm 提供了一个命令来解决这个问题: pnpm store | pnpm[5]。
同时该命令提供了一个选项,使用方法为 pnpm store prune ,它提供了一种用于删除一些不被全局项目所引用到的 packages 的功能,例如有个包 axios@1.0.0 被一个项目所引用了,但是某次修改使得项目里这个包被更新到了 1.0.1 ,那么 store 里面的 1.0.0 的 axios 就就成了个不被引用的包,执行 pnpm store prune 就可以在 store 里面删掉它了。
该命令推荐偶尔进行使用,但不要频繁使用,因为可能某天这个不被引用的包又突然被哪个项目引用了,这样就可以不用再去重新下载这个包了。
看到这里,你应该对Store有了一些简单的了解,接着我们来看下项目中的文件如何跟Store关联。
Links(hard link & symbolic link)
还记得文章刚开始,放了两张beachmark的图表,图表上可以看到很明显的性能提升(如果你使用过,感触会更明显)!
pnpm 是怎么做到如此大的提升的呢?一部分原因是使用了计算机当中的 Hard link[6] ,它减少了文件下载的数量,从而提升了下载和响应速度。
hard link 机制
通过hard link, 用户可以通过不同的路径引用方式去找到某个文件,需要注意的是一般用户权限下只能硬链接到文件,不能用于目录。
pnpm 会在Store(上面的Store) 目录里存储项目 node_modules 文件的 hard links ,通过访问这些link直接访问文件资源。
举个例子,例如项目里面有个 2MB 的依赖 react,在 pnpm 中,看上去这个 react依赖同时占用了 2MB 的 node_modules 目录以及全局 store 目录 2MB 的空间(加起来是 4MB),但因为 hard link 的机制使得两个目录下相同的 2MB 空间能从两个不同位置进行CAS寻址直接引用到文件,因此实际上这个react依赖只用占用2MB 的空间,而不是4MB。
因为这样一个机制,导致每次安装依赖的时候,如果是个相同的依赖,有好多项目都用到这个依赖,那么这个依赖实际上最优情况(即版本相同)只用安装一次。
而在npm和yarn中,如何一个依赖被多个项目使用,会发生多次下载和安装!
如果是 npm 或 yarn,那么这个依赖在多个项目中使用,在每次安装的时候都会被重新下载一次。
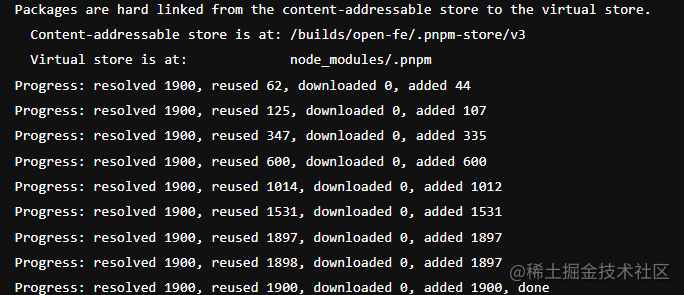
如图可以看到在使用 pnpm 对项目安装依赖的时候,如果某个依赖在 sotre 目录中存在了话,那么就会直接从 store 目录里面去 hard-link,避免了二次安装带来的时间消耗,如果依赖在 store 目录里面不存在的话,就会去下载一次。
通过Store + hard link的方式,不仅解决了项目中的NPM doppelgangers问题,项目之间也不存在该问题,从而完美解决了npm3+和yarn中的包重复问题!
如果随着项目越来越大,版本变更变多,历史版本的资源会堆积,导致Store目录越来越大,那如何解决这个问题呢?
针对这个现象,pnpm 提供了一个命令来解决这个问题: pnpm store | pnpm[7]。
同时该命令提供了一个选项,使用方法为 pnpm store prune ,它提供了一种用于删除一些不被全局项目所引用到的 packages 的功能,例如有个包 axios@1.0.0 被一个项目所引用了,但是某次修改使得项目里这个包被更新到了 1.0.1 ,那么 store 里面的 1.0.0 的 axios 就就成了个不被引用的包,执行 pnpm store prune 就可以在 store 里面删掉它了。
该命令推荐偶尔进行使用,但不要频繁使用,因为可能某天这个不被引用的包又突然被哪个项目引用了,这样就可以不用再去重新下载这个包了。
symbolic link
由于hark link只能用于文件不能用于目录,但是pnpm的node_modules是树形目录结构,那么如何链接到文件?通过symbolic link(也可称之为软链或者符号链接)来实现!
通过前面的讲解,我们知道了pnpm在全局通过Store来存储所有的node_modules依赖,并且在.pnpm/node_modules中存储项目的hard links,通过hard link来链接真实的文件资源,项目中则通过symbolic link链接到.pnpm/node_modules目录中,依赖放置在同一级别避免了循环的软链。
pnpm 的 node_modules 结构一开始看起来很奇怪:
- 它完全适配了 Node.js。
- 包与其依赖被完美地组织在一起。
有 peer 依赖的包的结构更加复杂[8]一些,但思路是一样的:使用软链与平铺目录来构建一个嵌套结构。
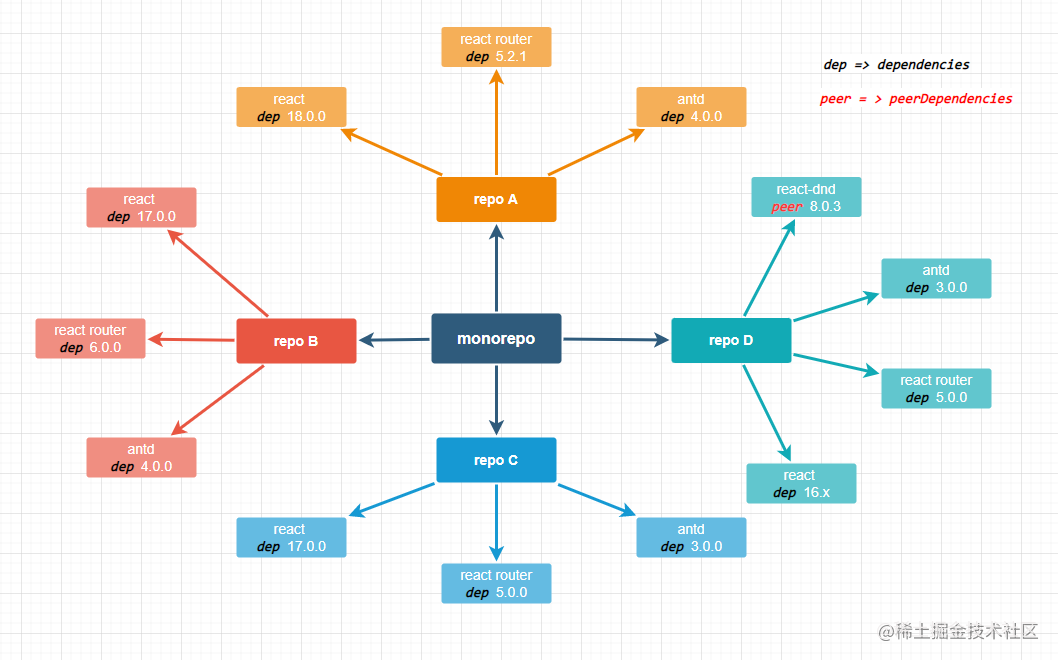
假设我们有个mono repo,它有repo A、repo B、repo C和repo D4个repo。每个repo有各自的一些依赖项(包括dependencies和peerDependencies),假定结构如下图所示:(需要注意有个peer dep)
下面是pnpm workspace中,比较清晰(不清晰的话留言,我可以改改!)说明了Store和Links间的相互关系:
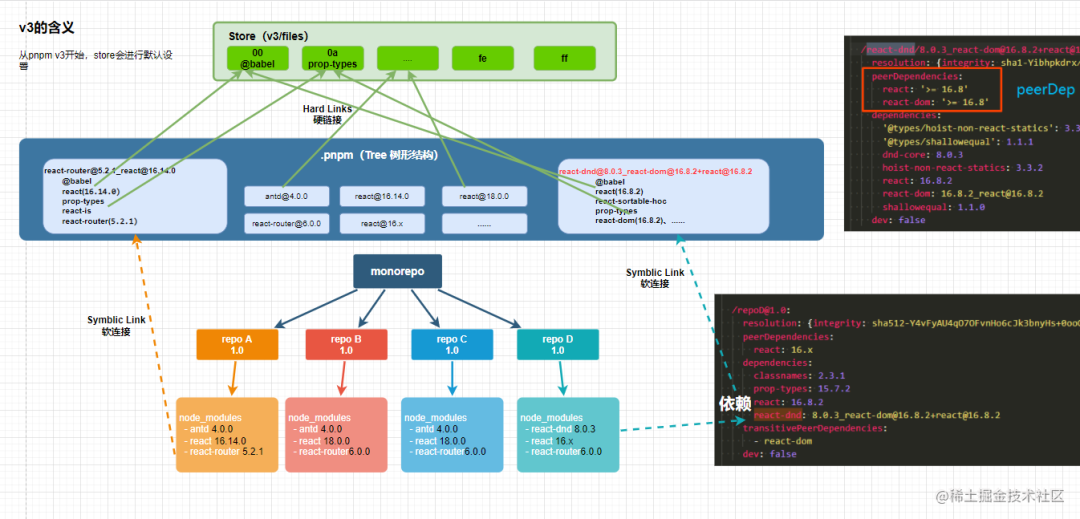
官网也更新了类似的调用关 图,大家也可以看看!
PeerDependencies
pnpm 的最佳特征之一是,在一个项目中,package的一个特定版本将始终只有一组依赖项。这个规则有一个例外 -那就是具有 peer dependencies [9]的package。
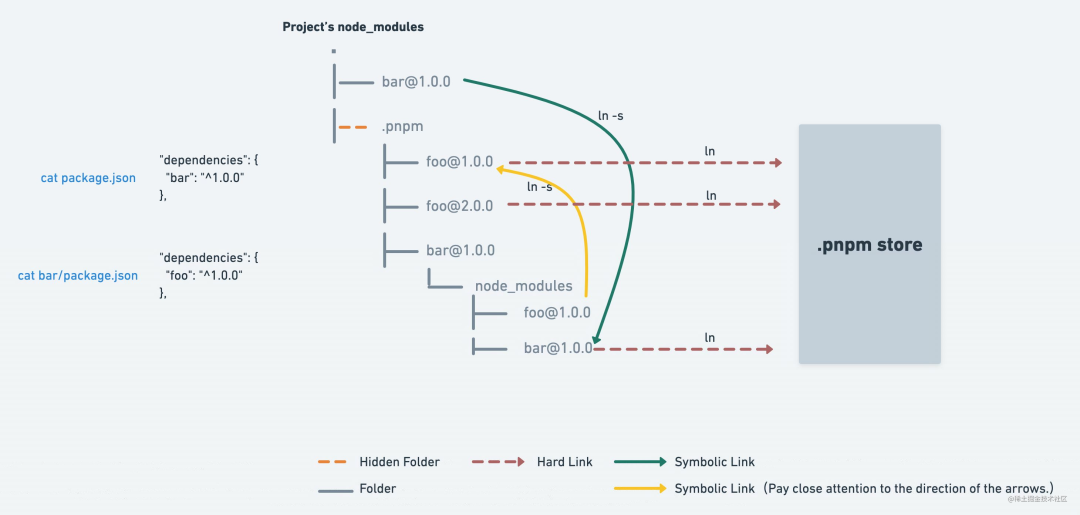
通常,如果一个package没有 peer 依赖项(peer dependencies),它会被硬链接到其依赖项的软连接(symlinks)旁的 node_modules,就像这样:
如果 foo 有 peer 依赖(peer dependencies),那么它可能就会有多组依赖项,所以我们为不同的 peer 依赖项创建不同的解析:

pnpm创建foo@1.0.0_bar@1.0.0+baz@1.0.0 或foo@1.0.0_bar@1.0.0+baz@1.1.0内到foo的软链接。因此,Node.js 模块解析器将找到正确的 peers。
peerDep的包命名规则如下(看起来就很麻烦)
.pnpm/<organization-name>+<package-name>@<version>_<organization-name>+<package-name>@<version>/node_modules/<name>
// peerDep组织名(若无会省略)+包名@版本号_组织名(若无会省略)+包名@版本号/node_modules/名称(项目名称)如果一个
package没有 peer 依赖(peer dependencies),不过它的依赖项有 peer 依赖,这些依赖会在更高的依赖图中解析, 则这个传递package便可在项目中有几组不同的依赖项。例如,a@1.0.0具有单个依赖项b@1.0.0。b@1.0.0有一个 peer 依赖为c@^1。a@1.0.0永远不会解析b@1.0.0的 peer, 所以它也会依赖于b@1.0.0的 peer 。
如果需要解决peerDep引入的多实例问题,可以通过 .pnpmfile.cjs[10]文件更改依赖项的依赖关系。
Part2lerna
Lerna 是一个管理工具,用于管理包含多个软件包(package)的 JavaScript 项目。它自身功能非常强大,特别是版本变更、项目发布等功能,可以满足各种复杂场景的诉求,除了workspace经常被人吐槽(可以使用yarn workspace),是业界当中使用规模最多的repo管理工具。
因为项目中要使用import带入、version版本变更、publish项目发布功能,所以着重介绍这三个命令,想要了解更多的同学可以去官网查看
3lerna import
将一个包内容(包括提交历史记录)导入到monorepo中。
命令如下:
lerna import <path-to-external-repository> --preserve-commit
<path-to-external-repository>是本地代码的存储目录,执行后导入到packages/<directory-name>中,包括原始提交作者、日期和消息。执行前需要确保分支的正确性(一般是master分支),之后导入就会自动执行。
需要注意目前仅支持本地导入,远程导入的话需要使用一些其他技巧。
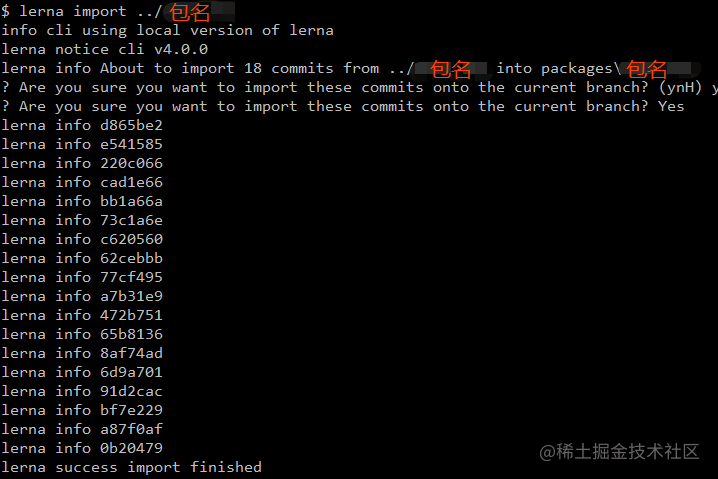
--preserve-commit选项,使用该配置项可以保留原始提交者和提交日期,从而避免下面的问题。
每次git提交都有一位作者和一位提交者(每人都有一个单独的日期)。通常他们是同一个人(和日期),但是因为lerna import从外部存储库重新创建每个提交,提交者就变成了当前的git用户(和日期)。这在技术上是正确的,但逻辑上不对,例如,在 Github 上,如果作者和提交者是不同的人,它就会同时显示他们,这可能会导致导入提交时的历史/职责出现混乱。
import命令对历史代码迁移到mono repo仓库特比有用。同时对每次历史变更为相对包目录进行修改。例如,添加package.json的提交将改为添加packages/<directory-name>/package.json。
4lerna version
修改自上次发布以来的包版本号。
为方便同学们学习,先简单介绍下语义化版本。
语义化版本
前端中的包应该遵循
语义化版本(也称为“semver”,来源于荷兰语)规范。当你从registry安装package时,它将会使用语义化的版本添加到项目的package.json中。
这些版本被分解major.minor.patch为以下其中之一:3.14.1, 0.42.0, 2.7.18。版本的每个部分随时间或者功能进行变更:
major主版本号:当你做了不兼容的 API 修改。minor次版本号:当你做了向下兼容的功能性新增。patch修订版本号:当你做了向下兼容的问题修正。 注意: 有时还有 semver 格式的“标签”或“扩展”,用于标记预发布或测试版(例如2.0.0-beta.3)
当开发人员谈论两个 semver 版本彼此“兼容”时,他们指的是向后兼容的更改(minor和 patch)
工作模式
Lerna有两种工作模式:Fixed mode和Independent mode
Fixed/Locked mode (default) 固定/锁定模式
固定模式下 Lerna 项目全局仅有一个版本号。该版本号在项目根目录下的lerna.json文件中version属性中维护。运行lerna publish时,如果模块从上次发布以来有能触发发版行为的更新,则version会修改为要发布的新版本。这意味着可以仅在需要时发布包的新版本。
注意:如果主版本为零,则所有更新都被视为
破坏性修改(Breaking change). 因此,lerna publish以零为主要版本运行并选择任何非预发布版本号将导致为所有包发布新版本,即使自上次发布以来并非所有包都已更改。
这是Babel[11]目前使用的模式。如果您想自动将所有软件包版本绑定在一起,请使用此选项。
这种方法的存在两个问题:
- 任何包的重大更改都会导致所有包都具有新的主要版本。
- 项目中包的版本变更会非常快
这些都是一致性带来的衍生效应,具体大家可以自行评估
Independent mode 独立模式
将lerna.json文件中的version设置为independent,即可以独立模式运行。项目初始化时,可以通过一下命令设置独立模式:
lerna init --independent
独立模式的 Lerna 项目允许各个包维护自己的版本。每次发布时,都会收到有关已更改的包的提示,以指定它是补丁、次要、主要还是自定义更改。
独立模式允许您更具体地更新每个包的版本并使每次更新有各自的意义。将这种模式与semantic-release[12]之类的东西结合起来会减少痛苦。(在atlassian/lerna-semantic-release[13]已经有这方面的工作)。
预发布
如果你有一个预发布版本号的软件包(例如2.0.0-beta.3),并且你运行了lerna version和一个非预先发布的版本(major、minor或patch),它将会发布那些之前发布的软件包以及自上次发布以来已经改变的软件包。
对于使用常规提交的项目,使用以下标志进行预发行管理:
- --conventional-prerelease[14]: 将当前更改作为预发行版本发布。
- --conventional-graduate[15]: 将预发布版本的包升级为稳定版本。
如果不使用上面的参数运行lerna version --conventional-commits,则只有在版本已经在prerelease中时,才会将当前更改作为prerelease释放。
生命周期
// preversion: 在设置版本号之前运行.
// version: 在设置版本号之后,提交之前运行.
// postversion: 在设置版本号之后,提交之后运行.lerna 将在lerna version期间运行npm 生命周期脚本[16]:
- 侦测更改的包,选择版本号进行覆盖。
- 在根目录运行
preversion。- 对于每个更改的包,按照拓扑顺序(所有依赖项在依赖关系之前): i. 运行
preversion生命周期。ii. 更新 package.json 中的版本。iii. 运行version生命周期。- 在根目录运行
version生命周期。- 如果可用[17],将更改文件添加到索引。
- 如果可用[18]创建提交和标记。
- 对于每个改变包,按照词法顺序(根据目录结构的字母顺序): i. 运行
postversion生命周期。- 在根目录运行
postversion。- 如果可用[19]推动提交和标记到远程服务器。(该流程会触发
git push操作)- 如果可用[20]创建发布。
5lerna publish
在当前项目中发布所有包
lerna publish # 发布自上一个版本以来发生了变化的包
lerna publish from-git # 发布当前提交中标记的包
lerna publish from-package # 发布注册表中没有最新版本的包在运行时,该命令做了下面几件事中的一个:
发布自上一个版本以来更新的包(背后调用了lerna version[21])。
这是 lerna 2.x 版本遗留下来的。
发布在当前提交中标记的包(
from-git)。发布在最新提交时注册表中没有版本的包(
from-package)。发布在前一次提交中更新的包(及其依赖项)的“金丝雀(canary)”版。
注意: Lerna 永远不会发布标记为private的包(package.json中的”private“: true)
在所有的发布过程中,都有生命周期[22]在根目录和每个包中运行(除非使用了--ignore-scripts)。
发布方式
from-git
除了 lerna version[23] 支持的语义化版本关键字外,lerna publish也支持from-git关键字。这将会识别lerna version标记的包,并将它们发布到 npm。这在您希望手动增加版本的 CI 场景中非常有用,但要通过自动化过程一直地发布包内容本身。
from-package
与from-git关键字类似,只是要发布的包列表是通过检查每个package.json确定的,并且要确定注册表中是否存在任意版本的包。注册表中没有的任何版本都将被发布。当前一个lerna publish未能将所有包发布到注册表时,就是他发挥的时候了。
生命周期
// prepublish: 在打包和发布包之前运行。
// prepare: 在打包和发布包之前运行,在 prepublish 之后,prepublishOnly 之前。
// prepublishOnly: 在打包和发布包之前运行,只在 npm publish 时运行。
// prepack: 只在源码压缩打包之前运行。
// postpack: 在源码压缩打包生成并移动到最终目的地后运行。
// publish: 在包发布后运行。
// postpublish: 在包发布后运行。Lerna 将在
lerna publish期间运行npm生命周期脚本[24],顺序如下:
- 如果采用没有指定版本,则运行所有版本生命周期脚本[25]
- 如果可用[26],在根目录运行
prepublish生命周期。- 在根目录中运行
prepare生命周期。- 在根目录中运行
prepublishOnly生命周期。- 在根目录运行
prepack生命周期。- 对于每个更改的包,按照拓扑顺序(所有依赖项在依赖关系之前): i. 如果可用[27],运行
prepublish生命周期。 ii. 运行prepare生命周期。 iii. 运行prepublishOnly生命周期。 iv. 运行prepack生命周期。 v. 通过JS API[28]在临时目录中创建源码压缩包。vi. 运行postpack生命周期。- 在根目录运行
postpack生命周期。- 对于每个更改的包,按照拓扑顺序(所有依赖项在依赖关系之前): i. 通过JS API[29]发布包到配置的注册表[30]。 ii. 运行
publish生命周期。 iii. 运行postpublish生命周期。- 在根目录中运行
publish生命周期。
- 为了避免递归调用,不要使用这个根生命周期来运行
lerna publish。10 . 在根目录中运行
postpublish生命周期。 11 . 如果可用[31],将临时的 dist-tag 更新到最新
6指令总览 (Commands)
指令参考地址(汉化)[32]
| 指令 | 解释 | 链接(英文) |
|---|---|---|
| lerna publish | 在当前项目中发布包 | 前往[33] |
| lerna version | 更改自上次发布以来的包版本号 | 前往[34] |
| lerna bootstrap | 将本地包链接在一起并安装剩余的包依赖项 | 前往[35] |
| lerna list | 列出本地包 | 前往[36] |
| lerna changed | 列出自上次标记发布以来发生变化的本地包 | 前往[37] |
| lerna diff | 自上次发布以来的所有包或单个包的区别 | 前往[38] |
| lerna exec | 在每个包中执行任意命令 | 前往[39] |
| lerna run | 在包含该脚本中的每个包中运行npm脚本 | 前往[40] |
| lerna init | 创建一个新的Lerna仓库或将现有的仓库升级到Lerna的当前版本 | 前往[41] |
| lerna add | 向匹配的包添加依赖关系 | [42] |
| lerna clean | 从所有包中删除node_modules目录 | [43] |
| lerna import | 将一个包导入到带有提交历史记录的monorepo中 | [44] |
| lerna link | 将所有相互依赖的包符号链接在一起 | [45 |
| lerna create | 创建一个新的由lerna管理的包 | [46] |
| lerna info | 打印本地环境信息 | [47] |
Part3typescript
TypeScript是JavaScript类型的超集,他可以编译成纯JavaScript。
TypeScript可以在任何浏览器、任何计算机和任何操作系统上运行,并且是开源的。
TS介绍的人已经相当多了,这里就不再介绍了!强力安利一波,用过的人都说香!
Part4总结
pnpm将来会成为主流的registry管理工具,这个毋庸置疑。现在pnpm的下载量已经击败了Bower,并且2021年的下载量是2020年的3倍,目前已经拥有了14.6k的Star。yarn和npm已经开始参考pnpm的设计并进行改进,vue、vite等框架也开始为pnpm背书,还没有用过pnpm的同学可以尝试下,相信你一定会喜欢它!
Yarn 在 v3.1[48] 添加了 pnpm 链接器。因此 Yarn 可以创建一个类似于 pnpm 创建的 node_modules 目录结构。此外,Yarn 团队计划实现内容可寻址存储,以提高磁盘空间效率。
Npm 团队决定也采用 pnpm 使用的符号链接的 node_modules 目录结构(相关 RFC[49])。
lerna强大的版本管理能力,完全可以弥补pnpm在包管理上的弱势,两者协同支持的的呼喊声也越来越强烈,相信将来lerna + pnpm一定会成为最佳monorepo管理方案之一。