Go错误集锦 | 处理error时有哪些常见的陷阱
大家好 ,今天跟大家聊聊在Go中处理error时有哪些常见的陷阱以及如何避免。
陷阱01:不理解使用panic处理错误的场景
在Go中,error通常是被当做函数或方法的最后一个返回值来处理的。但有时候也会遇到使用panic的场景。那么什么场景下该使用panic呢?
panic基础使用
在go中,panic是一个内建函数,该函数会中止所在协程的正常执行。例如:
package main
import (
"fmt"
)
func main() {
fmt.Println("a")
panic("foo")
fmt.Println("b")
}上述代码在打印输出a后,在打印b之前就中止了。
a
panic: foo
goroutine 1 [running]:
main.main()
main.go:9 +0x65一旦panic被触发,该panic就会中止所在函数的正常执行,还会按当前协程中的所有defer调用栈依次执行直到该协程返回或panic被recover捕获。
func main() {
defer func() {
if r := recover(); r != nil {
fmt.Println("recover", r)
}
}()
f()
}
func f() {
fmt.Println("a")
panic("foo")
fmt.Println("b")
}在f函数中,一旦panic被触发,就会中止f函数的执行,并返回到当前的调用栈:main函数。在main函数中,因为panic被recover捕获了,所以并没有中止该协程。
a
recover foo我们应该注意,只有在defer函数中调用recover才能捕获到panic。否则,recover将会返回nil。这就是为什么当一个函数panic时,defer会被执行的原因,
何时该使用panic
在Go中,panic被用来处理在正常操作期间不应该出现的错误,或者我们不准备处理的错误。
例如在net/http包中,有一个WriteHeader方法中,调用了checkWriteHeaderCode函数来检查状态码是否合法:
func checkWriteHeaderCode(code int) {
if code < 100 || code > 999 {
panic(fmt.Sprintf("invalid WriteHeader code %v", code))
}
}如果状态码code不合法,该函数就会引发一个panics,以表示这是一个本来就不该发生的错误。
另一个panic例子就是在database/sql包中,当注册一个数据库驱动的时候:
func Register(name string, driver driver.Driver) {
driversMu.Lock()
defer driversMu.Unlock()
if driver == nil {
panic("sql: Register driver is nil")
}
if _, dup := drivers[name]; dup {
panic("sql: Register called twice for driver " + name)
}
drivers[name] = driver
}在该函数中,如果driver是nil或在drivers中已经存在,则会触发panics。
在这两个案例中,都是当被认为是在编程中本不该发生的错误而使用panic来处理。
另外一种引起panic的例子是当我们的程序存在依赖时,但在初始化时所依赖的东西失败了。
假设我们有一个创建客户账号服务的API。该服务在处理过程中需要验证请求所提供的email地址。我们通过使用正则表达式来实现该功能。
在Go中,regexp包有两个创建正则表达式的函数:Compile和MustCompile。前一个函数Compile返回一个regexp.Regexp和一个错误类型,而后一个函数MustCompile只返回一个regexp.Regexp,但当遇到错误时会触发panic。在这个例子中,正则匹配是一个强依赖。就是说,如果匹配失败,我们就不会验证任何输入的email。因此,我们选择使用MustCompile函数并在遇到错误的时候触发panic。
还有一个经常用的例子,通常我们的服务会依赖redis等第三方缓存服务,那么在主服务启动的时候就需要先连接上redis,以便在后续的子协程中可以使用全局的redis客户端连接直接进行缓存读写服务。那么如果在启动main服务的时候,redis启动失败,这时就需要触发panic终止服务启动。因为如果连接redis服务失败,如果再继续执行后面的操作,即使有请求进来,那么读取缓存也是失败的。
所以,panic应该被慎重使用,一般是被用在认为那些本不该发生的错误时才会引发panic。另外一个就是在服务强依赖时,所依赖的服务发生了错误而必须要终止整个程序。
陷阱02:忽略了fmt.Errorf中%w指令的使用
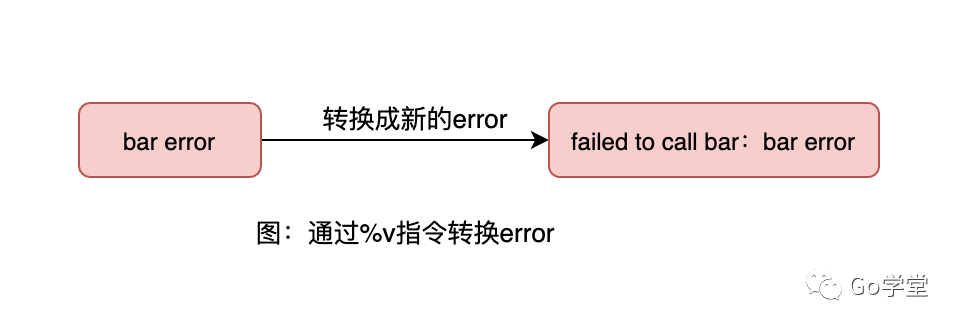
在Go中,我们可以使用fmt.Errorf函数根据占位符将一个值格式化成一个新的错误值,例如我们可以通过%v指令将一个error值转换成一个新的error值。例如:
barError := errors.New("bar error")
fmt.Errorf("foo failed:%v", barError) //foo failed:bar error这种方式的特点是在调用者处理错误的时候能够知道原始的错误信息是什么(这里指barError),但不能根据原始错误的类型或值来进行逻辑处理。如图所示:
自go1.13版本起,go支持了%w指令。该指令是将一个error嵌套到另一个error中。并且能够通过unwrap函数来解析出被嵌套的错误,这样调用者在处理错误的时候就能够根据原始的错误类型来进一步出来了。
在实际项目中,使用%w指令来嵌套一个错误的使用场景主要有以下两类:
- 给一个错误添加更多的上下文信息时,同时需要保留原始错误类型
- 将一个错误转换成一个标准的错误类型,同时也需要保留原始错误类型
场景一:如何给错误添加更多的上下文信息
假设我们收到一个特定用户访问数据库的请求,但是在查询期间得到了一个拒绝访问的错误。为了排查问题,我们将该错误记录到日志中,那么如果我们只记录“permission deny”这样的信息是不足以排查出问题来的。如下:
ErrPermissionDeny := errors.New("permission deny")
user := "dummy"
table := "admin"
err := query(user, table)
if err != nil {
log(err)
}
func query(user, table) error {
err := user.query(table)
if err != nil {
return ErrPermissionDeny
}
}
所以,我们需要将“具体哪个用户对哪个数据资源的访问没有权限”这样的信息添加到错误信息中,这样就能够使我们快速地定位到问题的所在了。如下图:
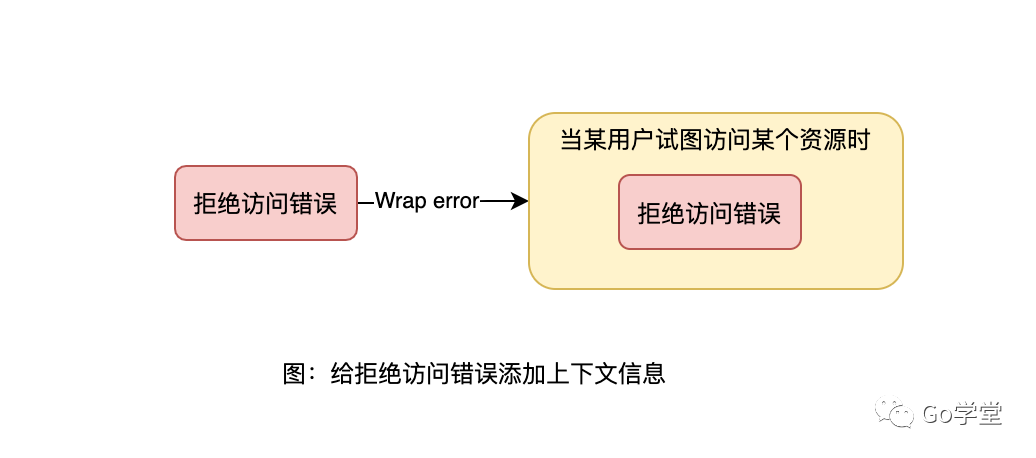
我们看下代码:
ErrPermissionDeny := errors.New("permission deny")
user := "dummy"
table := "admin"
err := query(user, table)
if err != nil {
log(err)
}
func query(user, table) error {
err := user.query(table)
if err != nil {
return fmt.Errorf("when %s access resource %s:%w", user, table, ErrPermissionDeny)
}
}场景二:将收到的错误信息转换成另外一个标准的错误类型
我们在返回错误时,需要保留原始的错误类型可用,以便调用者可以根据原始错误类型进行逻辑处理,我们就可以使用%w指令来进行嵌套error。例如如下:
if err != nil {
return fmt.Errorf("permission deny:%w", err)
}
在这两个场景中,调用者可以通过errors.Unwrap函数来将错误信息解封一层,并根据原始错误的类型来进一步处理错误。同时也可以使用errors.Is和errors.As函数直接来判断错误。
所以,如果我们在实际应用中,如果想保持原始的错误信息,就使用%w指令将原始错误嵌套到一个新的错误中,但同时这样调用方的错误处理逻辑也就强依赖于原始的错误类型了。否则,可以使用%v指令,只将原始错误信息加入到新的错误类型中即可,这样调用方在处理错误的时候就不会强依赖原始错误类型了。
陷阱03:错误类型比较时使用==而未用errors.As()
上文中我们提到了使用%w指令可以将错误进行嵌套。那么,我们来看看开始使用这种方式对错误进行嵌套后会给我们带来哪些容易忽略而造成错误的地方。
我们看下面的一个例子。我们实现了这样一个HTTP处理函数:根据ID返回账户的金额。首先处理函数会解析得到的ID,并根据ID从数据库返回账户金额。如果出现以下两种场景,该函数会返回错误:
- 如果ID是非法的(ID的长度不是5个字符)
- 如果查询数据库失败,则返回错误
在第一种场景中,函数返回StatusBadRequest(400)错误,在第二种场景中,函数返回ServiceUnavailable(503)错误。我们看下第一版的实现:
type transientError struct {
err error
}
func (t transientError) Error() string {
return fmt.Sprintf("transient error: %v", t.err)
}
func getTransactionAmount(transactionID string) (float32, error) {
if len(transactionID) != 5 {
return 0, fmt.Errorf("id is invalid: %s", transactionID)
}
amount, err := getTransactionAmountFromDB(transactionID)
if err != nil {
return 0, transientError{err: err}
}
return amount, nil
}在上面的代码中,我们看到,如果ID值非法,则返回一个标准的错误。如果查询数据库失败,则返回一个transientError类型的错误。
然后,我们再来看HTTP的处理函数,该函数根据返回的错误类型来返回对应的状态码:
func GetTransactionAmountHandler(w http.ResponseWriter, r *http.Request) {
transactionID := r.URL.Query().Get("transaction")
amount, err := getTransactionAmount(transactionID)
if err != nil {
switch err := err.(type) {
case transientError:
http.Error(w, err.Error(), http.StatusServiceUnavailable)
default:
http.Error(w, err.Error(), http.StatusBadRequest)
}
return
}
// Write response
}我们看到,在HTTP处理器函数中,通过switch来匹配错误类型。如果是transientError类型,则返回503,否则返回400。
目前看程序一切正常。那如果我们将程序重构一下,transientError错误不再由getTransactionAmount函数直接返回,而是由getTransactionAmountFromDB函数返回。而getTransactionAmount函数将会通过%w指令将该错误嵌套到一个标准错误中:
func getTransactionAmount(transactionID string) (float32, error) {
// Check transaction ID validity
amount, err := getTransactionAmountFromDB(transactionID)
if err != nil {
return 0, fmt.Errorf("failed to get transaction %s: %w", transactionID, err)
}
return amount, nil
}
func getTransactionAmountFromDB(transactionID string) (float32, error) {
// ...
if err != nil {
return 0, transientError{err: err}
}
// ...
}重构之后,会对HTTP handle的错误处理带来什么影响呢?当我们运行该代码时会发现会一直返回400错误。为什么呢?
在重构之前,transientError错误是通过getTransactionAmount返回的:

重构之后,transientError是通过getTransactionAmountFromDB返回的:
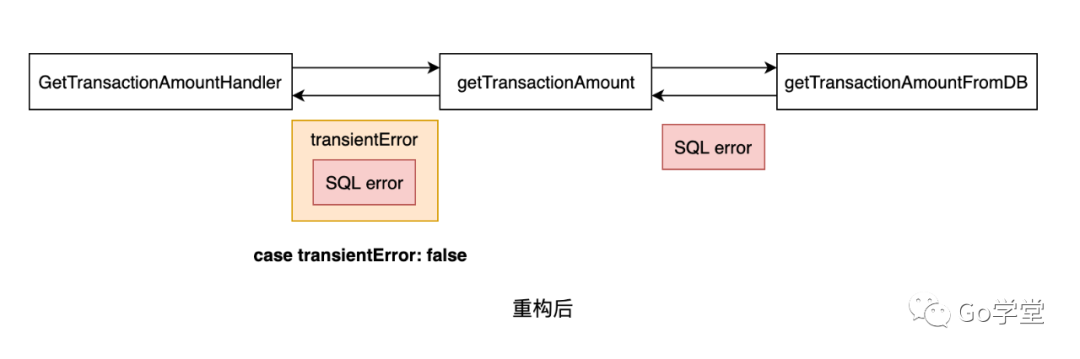
也就是说getTransactioAmount并没有直接返回transientError错误,而是嵌套在了一个标准的错误中。因此,在代码中的 case transientError不会覆盖到。
好在Go1.13不仅提供了%w指令,而且也提供了errors.As函数。该函数会递归的从嵌套的错误链中层层查找是否有对应类型的错误,如果有匹配到的,则返回true,如下:
func GetTransactionAmount(w http.ResponseWriter, r *http.Request) {
// Get transaction ID
amount, err := getTransactionAmount(transactionID)
if err != nil {
terr := transientError{}
if errors.As(err, &terr) {
http.Error(w, err.Error(), http.StatusServiceUnavailable)
} else {
http.Error(w, err.Error(), http.StatusBadRequest)
}
return
}
// Write response
}这就是我们要讲的在使用%w指令后需要在处理错误时要注意的类型判断方式的地方。下面我们再来看看使用了%w嵌套错误之后在错误值的判断上会有什么影响。
陷阱04:错误值比较时使用==而未用errors.Is()
在实际项目或开源项目中,大家都见过全局定义的错误值,我们称之为哨兵错误值,如下:
import "errors"
var ErrFoo = errors.New("foo")哨兵错误一般用于期望的错误值。那么什么是期望的错误值呢?比如我们在标准库中看到的:
- sql.ErrNoRows : 代表查询到的记录为空。
- io.EOF: 代表已经读取到文件末尾了。
这就是哨兵错误,传递给调用者期望的错误,客户端可以通过检查错误是否是期望的错误进行错误处理,比如判断是否读取到了文件末尾,是否从数据库读取到的记录为空等。所以,以下可以作为我们的一般指导原则:
- 期望的错误应该被定义成错误值(即一个全局变量错误)作为哨兵错误:var ErrFoo = errors.New("foo")
- 非期望的错误应该被定义成错误类型:type BarError struct{...},然后该类型实现error接口。
我们看下在项目中进行错误值比较时会遇到的坑是什么。一般我们会按如下使用==进行错误值判断:
err := query()
if err != nil {
if err == sql.ErrNoRows {
// ...
} else {
// ...
}
}由上节讲到的可知,如果哨兵错误通过%w被嵌套到一个新的错误中,那么这种比较的方式就会失效。所以,自go1.13起,我们可通过errors.Is函数来进行值的比较。该函数会对错误链进行层层比较。
陷阱05:对error进行了多次处理
将error处理了多次也是Go研发者经常犯的一个错误。下面我们讲解下为什么会出现这个问题以及如何避免。
假设我们有一个GetRoute函数,该函数的功能是计算两个地理位置之间的路径。该函数首先会调用一个validateCoordinates函数来校验起始地理位置的经纬度是否合法,然后通过校验后,再调用getRoute函数进行具体业务逻辑的处理。同时,我们期望将错误记录到日志中。
一种可能实现如下这样:
func GetRoute(srcLat, srcLng, dstLat, dstLng float32) (Route, error) {
err := validateCoordinates(srcLat, srcLng)
if err != nil {
log.Println("failed to validate source coordinates")
return Route{}, err
}
err = validateCoordinates(dstLat, dstLng)
if err != nil {
log.Println("failed to validate target coordinates")
return Route{}, err
}
return getRoute(srcLat, srcLng, dstLat, dstLng)
}
func validateCoordinates(lat, lng float32) error {
if lat > 90.0 || lat < -90.0 {
log.Printf("invalid latitude: %f", lat)
return fmt.Errorf("invalid latitude: %f", lat)
}
if lng > 180.0 || lng < -180.0 {
log.Printf("invalid longitude: %f", lng)
return fmt.Errorf("invalid longitude: %f", lng)
}
return nil
}
我们看到,在validateCoordinates函数中,我们记录了一次错误日志。同时在GetRoute中调用validateCoordinates返回错误时又记录了一次日志。这样我们实际上是将同一份错误记录了两次日志。
记录两份日志的问题在于一方面日志重复增加了磁盘量。另一方面会增加排查问题的难度。如果该函数被并发的调用多次,那么这两条日志在文件中记录的位置可能不是挨着的,以致于给调试排查问题增加复杂度。
错误处理的原则是一个错误仅被处理一次。将错误记录到日志中也是一种处理错误的方式,所以应该返回错误,由最上层的调用层来处理。因为我们应该是要么记录日志要么就返回,由上层记录日志。
好,我们看下经过改进的只将错误处理一次的代码:
func GetRoute(srcLat, srcLng, dstLat, dstLng float32) (Route, error) { err := validateCoordinates(srcLat, srcLng) if err != nil { return Route{}, err }
err = validateCoordinates(dstLat, dstLng)
if err != nil {
return Route{}, err
}
return getRoute(srcLat, srcLng, dstLat, dstLng)}
func validateCoordinates(lat, lng float32) error { if lat > 90.0 || lat < -90.0 { return fmt.Errorf("invalid latitude: %f", lat) } if lng > 180.0 || lng < -180.0 { return fmt.Errorf("invalid longitude: %f", lng) } return nil }
在这个版本中,我们通过将错误返回的方式达到了让错误只被处理一次的目的。
但这个版本中还有什么问题呢?我们看在GetRoute函数中,validateCoordinates函数被调用了两次。那么,如果validateCoordinates函数返回了一个错误,例如经度错误。那么,我们怎么区分是源地址的经度错了呢还是目的地址的经度错了呢。因此,我们需要增加一些上下文信息来区分错误。下面是我们通过%w指令来改写的最新版本:
func GetRoute(srcLat, srcLng, dstLat, dstLng float32) (Route, error) { err := validateCoordinates(srcLat, srcLng) if err != nil { return Route{}, fmt.Errorf("failed to validate source coordinates: %w", err) }
err = validateCoordinates(dstLat, dstLng)
if err != nil {
return Route{}, fmt.Errorf("failed to validate target coordinates: %w", err)
}
return getRoute(srcLat, srcLng, dstLat, dstLng)}
在这个版本中,我们既达到了让错误只被处理一次的目的,同时也达到通过增加上下文区分是源地址错误还是目的地地址错误的目的。
陷阱06:未正确的使用忽略error的方式
---------------------
在一些场景下,我们可能会想忽略了函数返回的错误。在Go中,只有一种可以忽略错误的方式,那就是将返回的错误赋值给下划线:"\_"。让我们看看为什么。
假设我们有一个函数notify,该函数返回一个error。如果我们在调用该函数时对该函数返回的错误不感兴趣,可能会这样写:
func f() { //... notify() }
func notify() error { // ... }
我们看到,在函数f中,调用了notify,但并没有对notify返回的error赋值给任何变量。这样的方式不影响代码的编译和运行。但是从可维护性上来讲,会降低代码的可读性。如果有人在阅读代码的时候看到这里,会很疑惑当时是因为忘记对错误进行处理了还是有意这么写的。所以,正确的写法应该如下:
_ = notify()
这样,就能明确得表达出忽略了错误,而非是忘记处理错误。
陷阱7# 未正确处理defer中的error
----------------------
defer中的error没有被处理也是研发者经常犯的一个错误。我们看下下面的示例,该示例根据客户ID从数据库中查询出账户的余额。我们使用database/sql包来实现。
const query = "..." func getBalance(db *sql.DB, clientID string) (float32, error) { rows, err := db.Query(query, clientID) if err != nil { return 0, err } defer rows.Close() // Use rows }
在代码中,我们使用了defer调用了rows.Close()。但是由源码可知,rows是一个\*sql.Rows类型,该类型实现了Closer接口:
type Closer interface { Close() error }
该接口的Close方法的返回值是一个error。也就是说在上面我们使用defer函数调用rows.Close()时,对返回的错误并没有处理,而是忽略了错误。
但根据上节我们提到的,忽略错误的方式只能是使用下划线的方式如下:
defer func() { _ = rows.Close() }()
这个版本的实现从可读性角度来讲有了提高。但是,我们在这里是不是真的要忽略该错误了。试想一下,当调用rows.Close()来释放数据库连接失败了,那么忽略该错误可能就不是我们期望的。所以,较好的方式就是将错误记录在日志里:
defer func() { err := rows.Close() if err != nil { log.Printf("failed to close rows: %v", err) } }()
这样当执行rows.Close()失败了,就会把错误记录到日志里。但是呢,根据上面提到的错误只被处理一次的原则,我们更希望将错误返回给调用者,让调用者来处理错误。可能实现的版本如下:
defer func() { err := rows.Close() if err != nil { return err } }()
请注意,这种实现方式是不能编译通过的。因为defer里的return语句是对匿名函数func()的返回,而非getBalance函数的返回。
那我们怎么样才能把defer中的错误作为getBalance函数的返回值呢?那就是使用具名返回值(带参数名的返回值)。我们看下代码:
func getBalance(db *sql.DB, clientID string) (balance float32, err error) { rows, err := db.Query(query, clientID) if err != nil { return 0, err }
defer func() {
err = rows.Close()
}()
if rows.Next() {
err := rows.Scan(&balance)
if err != nil {
return 0, err
}
return balance, nil
}
// ...}
这样是不是就可以了呢?当然也不行。我们看下为什么。如果`rows.Scan`函数执行错误时,就会执行`return 0, err`语句,但在执行return语句之前还会调用defer函数,那么如果rows.Close()执行成功,那么err就会把rows.Scan的err覆盖掉,这样也不符合预期。那怎么办呢?我们再来看下改进版本。
defer func() { closeErr := rows.Close() if err != nil { if closeErr != nil { log.Printf("failed to close rows: %v", err) } return } err = closeErr }()
在这个版本中,我们将defer中的错误赋值给了一个变量closeErr。在将closeErr赋值给err之前,先对err做了判断,如果err不为nil,则不将closeErr赋值给err,只记录日志。但如果err为nil,才将closeErr赋值给err。这样就解决了即记录了defer中的日志,又没有覆盖err本身的值。
总结
--
本文从各种角度讲解了在实际项目中处理error时的常见陷阱。主要如下:
- panic也是处理error的一种方式。但只有在产生非预期及依赖服务产生错误的场景下使用
- 自go1.13版本起,增加了%w指令,该指令可以将一个error嵌套到另一个error中,可以将源错误返回给调用者,以便调用者可以根据错误类型来做不同的逻辑处理。
- %w指令虽然带来了方便,但在进行错误类型以及错误值相等判断的时候也埋下了隐患,所以,需要使用errors.Is和errors.As函数来进行判断,而非==符号。
- 如果想忽略错误,最好是将错误值赋给 “\_”,这才是Go中忽略错误的唯一正确的方式
- 要遵循错误只被处理一次的原则。将错误记录到日志中也是一种处理错误的方式,最好的方式是将错误作为值返回给上层调用者,让上层调用者决定如何处理。
- 最后,通过代码演示了如何处理defer中的错误。