sqlite3.36版本 btree实现(零)- 起步及概述
引言
理解算法的原理,以及能写出生产级别的实现,中间隔了很大的距离。本文是讲解sqlite btree实现系列文章的第零篇,讲解我探索“生产级 btree 实现”的过程,以及 sqlite btree 架构的简介。
起步
在去年(2020 年)大体把 btree 以及 b+tree 算法流程研究了之后,我写了两篇博客:
- B 树、B+树索引算法原理(上) - codedump 的网络日志[1]
- B 树、B+树索引算法原理(下) - codedump 的网络日志[2]
(鉴于 b+tree 只是 btree 的一个特例,下面描述将仅使用“btree”,不再严格区分两者。)
但是,这两篇文章仅仅只是让我懂得了最基本的原理。懂得原理,只是能做出 toy 级别的实现,拿 btree 类的存储引擎来说,要做到生产级产品,至少还有以下几个问题我当时不知道怎么做的:
- 如何处理不同大小的数据的存储?
- 删除一个数据之后,如何复用其留下的空间?
- 错误、崩溃恢复怎么做?
- 跟磁盘文件是如何交互的?
- 页面缓存模块如何实现?
等等等等,还有太多我还没有弄清楚的实现细节。
(我甚至还在微博上发问,得到了两个质量很高的回答,见本文最后的彩蛋部分[3]。)
对 LSM 类存储引擎有了解的人都知道,Leveldb 这个项目在 LSM 领域属于入门级别的生产级实现,即这个领域最精简、但是又能放心在某些要求不高的场景下用于生产的项目。在这之后,我一直在找那种 btree 领域的“leveldb”,很遗憾一直都没有找到,我分别看了目前 WiredTiger、innodb、sqlite 的对应实现,都太复杂了,看不下去。
直到有一天,无意间发现了这个项目:madushadhanushka/simple-sqlite: Code reading for sqlite backend[4],看介绍,作者把 sqlite2.5 里 b-tree 相关的部分代码抽取出来了,我编译运行了一下用例都能正常跑,代码量不过几千行,我只花了几天就看完了。
虽然按照 Release History Of SQLite[5] 上的记载,sqlite 2.5 版本是 2002 年的版本了,但是这个版本还是某种程度回答了我在上面的疑问。
趁热打铁,我又找来更新一些的 sqlite 3.6.10 代码继续看这部分的实现,这次花了更多的时间才看完,但是又增强了我的信心。由于这个版本的 sqlite,还未实现 btree 的 wal,还只是用了 journal 文件来做崩溃恢复(无论 wal 还是 journal,都会在后面文章展开详细讨论),所以在有足够的信心之后,我接下来又继续看当时(2021.10 月份)最新的 sqlite 3.36 版本的实现,这部分的实现对比 3.6.10 来说,在 btree 部分最大的变化就是多了 wal 的实现,在已经清楚 3.6.10 的前提下,再增加了解这部分的实现,也并不是什么难事了。
以上,简单描述了我探索一个生产级 btree 实现的初过程,btree 类存储引擎的实现博大精深,更复杂者还有很多(WiredTiger、innodb、tokudb...),但是无疑从低版本 sqlite 开始的探索流程,终于让我打开了走上这条路的一扇大门。
本系列文章就 sqlite 3.36 版本的 btree 实现展开描述,希望对那些和我一样对“生产级 btree 类存储引擎实现”有好奇心的人有一点帮助。
当然,如果你还是觉得吃力,可以先从 madushadhanushka/simple-sqlite: Code reading for sqlite backend[6] 这里看起。这里并不建议对 btree 原理没有了解的人直接上手 sqlite 的实现,如果需要了解原理请参考相关文章或者我上面给出的我写的两篇博客。这系列文章中,将不再对 btree 原理做过多描述,将假设读者已经了解这部分内容。
sqlite 的 btree 架构概述
下面简单描述一下 sqlite 的 btree 架构,从高往低大体分为以下几个部分:
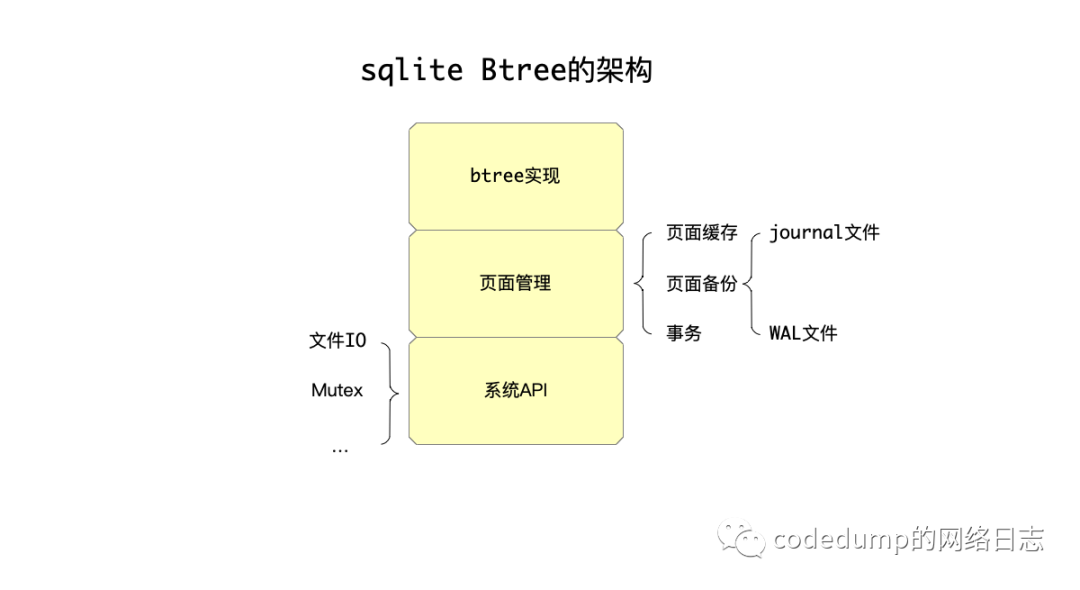
btree 架构
这三部分架构,由下往上依次是:
-
系统级 API 的实现:因为 sqlite 是一个可以在多个平台编译运行的数据库,所以系统级 API 这一层,需要解决平台相关的文件 IO、锁等问题。这部分实现,将不在这系列文章中介绍,因为并不属于数据库实现时的核心问题。
-
页面管理模块:btree 存储引擎,其操作文件的最基本单位就是页面。页面管理模块解决以下的问题:对上层的 btree 模块,暴露针对页面读、写的接口,内部会缓存页面的内容,何时将修改的页面(所谓脏页面,dirty page)落盘到磁盘,是否需要 sync 修改,崩溃或者重启时的数据恢复,这些都不需要上层的 btree 模块关心。为了达到这些效果,内部还有几个子模块:
-
页面缓存模块:用于缓存页面的内存有限,何时淘汰缓存中的页面、何时将缓存中的脏页面落盘,等等都由这个模块负责。
-
页面备份:从上面的描述可以看到,因为页面的修改并不一定马上落盘,而是可能只是修改了缓存中的页面,这样在系统发生崩溃的时候,需要做恢复操作,一些没有完成的事务需要回滚,等等。这部分页面管理模块由两种不同的实现:journal 文件:这是早期,但是效率并不高的实现;WAL 文件:这是从 3.7 之后引入的更高效的方式。
-
事务:事务处理也放在了页面管理中。
-
btree:基于页面管理模块之上,实现了可以存储可变数据的 btree 模块。
可以这样来简单区别理解“页面管理”模块和 btree 模块的功能:
- 页面管理:顾名思义,页面管理模块的最基本单位是”页面“,页面的读、写、缓存、落盘、恢复、回滚等,都由页面模块负责。上一层依赖页面管理模块的 btree 模块,不需要关心一个页面何时缓存、何时落盘等细节。即:页面模块负责页面的物理级别的操作。
- btree:
- 负责按照 btree 算法,来组织页面,即负责的是页面之间逻辑关系维护。
- 除此以外,一个页面内部的数据的物理、逻辑组织,也是 btree 模块来负责的。即:btree 负责维护页面间的逻辑关系,以及一个页面内数据的组织。
从上面的分析可以看出来,“页面管理模块”无疑是这里最大最复杂的部分,Andy Pavlo 在 CMU 15445 课程中提到过:任何用 mmap 来做页面管理的做法都是很糟糕的做法(如 boltdb、LMDB 等)。

mmap
这系列的文章,也将按照这个顺序,从下往上逐层分析 sqlite 的 3.36 版本的 btree 实现。
彩蛋
2021 年 9 月 5 日,我在微博上就处理崩溃恢复的实现,提了一个问题(见:那些很成熟的存储引擎... - @玩家老 C 的微博 - 微博[7]):
那些很成熟的存储引擎,都是怎么处理崩溃恢复问题的呢,比如写数据落盘到一半,进程崩了,该如何恢复呢?求资料和指点。
得到了两个很不错的指点回复:
ba0tiao 的回复
做 InnoDB 这块挺久了, 我试试说说 InnoDB 是怎么做的吧..
其实你这里应该细分成两个问题
1.16kb 的 page 写入的原子性该如何保证2.Btree 结构的完整性如何保证, 也就是你说的修改了 n 个页面以后如果修改了父子, 兄弟关系以后, 如果解决中间的 crash 的问题
问题 1 是通过 double write buffer 来解决的, 因为 InnoDB 的 page 大小是 16kb, 很多文件系统只能保证 4kb 大小写入的原子性, 因此需要写入前先将 page 的内容写入到 double write buffer 来保证, 如果写入失败也不会将原有 page 的内容覆盖.
问题 2 是通过 redo log + mtr(mini transaction) 进行保证.
InnoDB 里面的 redo log 是由 mtr 组成, mtr 是修改 btree 的最小单位. 每次写入 redo log 的时候必须是一个完整的 mtr 的内容, 具体实现方式是 mtr 会有 MULTI_REC_END 标记, 在 crash recovery 的时候, 如果读取到 mtr 的内容没有 MULTI_REC_END 标记, 那么则会认为这个 mtr 不完整, 就会把这段 mtr 抛弃.
那么是不是一次 insert 操作产生的 redo log 都包含在一个 mtr 里面呢?
不是的.
我们知道在 btree 里面对 page 的修改都需要对 page 加锁, 从 fsp 模块分配一个 new page 也需要对 root page 进行加锁等等. 所以 InnoDB 的 mtr 里面自然就包含对锁的操作, 因此要修改某一个 page 的时候, mtr begin 的时候会对该 page 加锁, 然后写入修改的内容, 然后 mtr commit 的时候, 对于修改的 page 的锁就可以释放了.
如果整个 insert 的过程都放在一个 mtr 里面做, 那也是可以的, 也就是对于所有 page 的 latch 都是一开始持有, 最后的时候在释放, 就算后续这个 page 已经不再修改了, 也依然要一直持有. 很容易理解这样并发自然就降低下来的, 因此在 InnoDB 设计里面, mtr 的粒度是尽可能小的. 修改完 page 就应该尽快的 commit, 然后将 page lock 释放. 但是又需要保证每一次的 mtr 操作前和操作后 btree 的完整性.
体现具体的例子就是, InnoDB 里面对于一个简单的 insert 操作, 其实是有非常多个 mtr 组成, 尽可能减少持有锁的时间.
但是在做 btree 分裂操作的时候, 分配新的 page, 将之前 page 一半的数据迁移到 new page 是在一个 mtr 里面完成, 但是后续具体的 insert 操作是在另外一个 mtr 里面完成的. 那么如果在做分裂操作过程中 crash, 那么这个分裂操作是不会完成的, 如果在分裂操作完成以后, insert 之前 crash, 那么 btree 是已经分裂过的, 只是数据没有插入了.
当然这里会有你说的更复杂的设计的父节点 and 父节点的父节点的分裂, 那么自然持有锁的时间就更长了, 但是在我们在这里是做的一些优化.
还有一些比如 InnoDB redo log 是"physical to a page, logical within a page" 就是解决我们上面说的如果分裂操作成功了, 但是这个事务要回滚, 这个时候该如何处理等等..
具体的内容其实这些文章里面都有:
1.C. Mohan, Don Handerle. ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging.
2.C. Mohan, Frank Levine. ARIES/lM: An Efficient and High Concurrency index Management Method Using Write-Ahead Logging.
3.Goetz Graefe. A Survey of B-Tree Logging and Recovery Techniques.4.Goetz Graefe. A Survey of B-Tree Locking Techniques.
对了 Goetz Graefe 号称 Btree 守护神
(见:做 InnoDB 这块... - @ba0tiao 的微博 - 微博[8])
注:
- ba0tiao应该是阿里云负责 PolarDB 开发的资深开发。
- 他的博客是:baotiao[9]
- 知乎专栏:MySQL 内核揭秘 - 知乎[10]
BohuTANG 的回复
可以深入一点:如果每次写的 log 都在,怎么做到基于这些 log 做回放的问题?其实就是 redo-log +checkpoint+ LSM 的机制。
redo 解决数据不丢,checkpoint 解决 recovery 的时候扫描的 redo 尽量少,LSM 解决每次写入后新的 page 不会覆盖老的数据,这类实现是比较简单可行,也是目前的主流做法
(见:可以深入一点:如果每... - @BohuTANG 的微博 - 微博[11])
以及:
目前大部分理论都参考于这篇 ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging – Mohan et al. 1992
(见:目前大部分理论都参考... - @BohuTANG 的微博 - 微博[12])
引用链接
[1] B树、B+树索引算法原理(上) - codedump的网络日志: https://www.codedump.info/post/20200609-btree-1/
[2] B树、B+树索引算法原理(下) - codedump的网络日志: https://www.codedump.info/post/20200615-btree-2/
[3] 彩蛋部分: https://www.codedump.info/post/20211217-sqlite-btree-0/#%E5%BD%A9%E8%9B%8B
[4] madushadhanushka/simple-sqlite: Code reading for sqlite backend: https://github.com/madushadhanushka/simple-sqlite
[5] Release History Of SQLite: https://www.sqlite.org/changes.html
[6] madushadhanushka/simple-sqlite: Code reading for sqlite backend: https://github.com/madushadhanushka/simple-sqlite
[7] 那些很成熟的存储引擎... - @玩家老C的微博 - 微博: https://weibo.com/1642628345/KwKqNgScT
[8] 做InnoDB 这块... - @ba0tiao的微博 - 微博: https://weibo.com/1832563813/KwRpIxunM
[9] baotiao: http://baotiao.github.io/
[10] MySQL内核揭秘 - 知乎: https://www.zhihu.com/column/360infra
[11] 可以深入一点:如果每... - @BohuTANG的微博 - 微博: https://weibo.com/1691468715/KwT2GdDfu
[12] 目前大部分理论都参考... - @BohuTANG的微博 - 微博: https://weibo.com/1691468715/Kx3yAhFKj
[13] datafuselabs/databend: https://github.com/datafuselabs/databend
[14] [ 虎哥的博客 ]: https://bohutang.me/