童年神机小霸王原理(五)滚屏渲染2
Render&Scroll
本文继续来说滚屏渲染,讲述每条 Scanline 每个周期具体干些什么事情以及一些高级玩法,屏幕分割技术,看看前面所说的大片级效果是如何制作的。
还是先来看渲染部分,PPU (NTSC TV)每一帧渲染 262 条 scanlines,每条 scanline 又持续 341 个时钟周期,
对此,wiki 上有一张很详细的图,看懂了,就大致明白了:
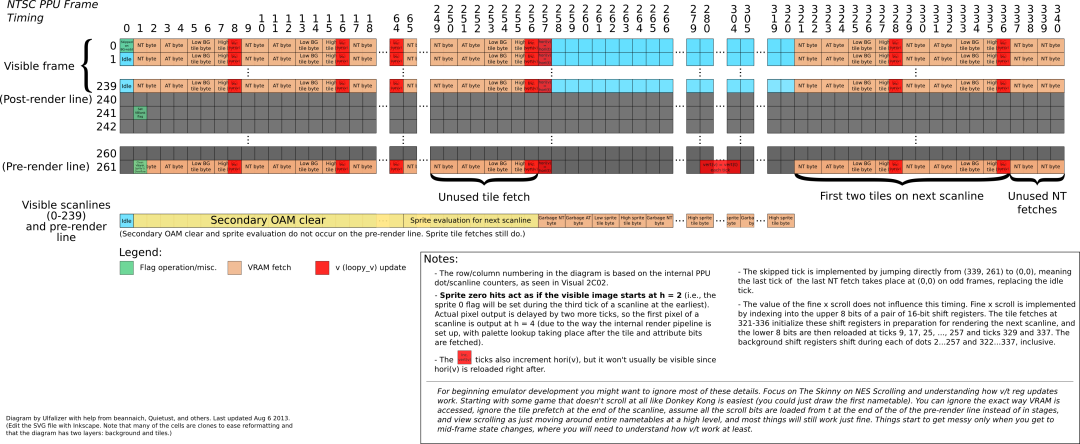
上面一排数字表示周期,左边一列数字表示第几条 Scanline,也可以当作坐标来看,(scanline,cycle),下面来详细地解读一下上图
scanline 0-239
这是可见的 240 条 scanlines,每个周期干的事情如下:
cycle 0
渲染的帧分奇偶,如果是奇数帧,这个周期直接跳过,如果是偶数帧,这个周期什么都不做 idle。奇数帧跳过一个周期是为了补偿物理信号输出方面的缺点,使其有更好的画面显示(emm具体的这方面不太懂,有知道的还请指教)
cycle 1 - 256
这 256 个周期循环往复取 4 个数据:
- NameTable 中的 tile 索引
- AttributeTable 中的颜色信息
- 根据 tile 索引取 tile 低位
- 根据 tile 索引取 tile 高位
每个数据花费 2 个周期,4 个数据 8 个周期取完,这刚好与 shift 寄存器每 8 个周期重新装载吻合。
cycle 8/16/24...
每 8 个周期,增加寄存器 v 中 X 坐标值:
if ((v & 0x001f) == 31){
v &= ~0x001f;
v ^= 0x400; //切换NameTable
}else
v += 1;如果 v 的 X 坐标值小于 31,那么 X 直接加 1,如果等于 31,X 值归零,切换横向 NameTable,举个例子:
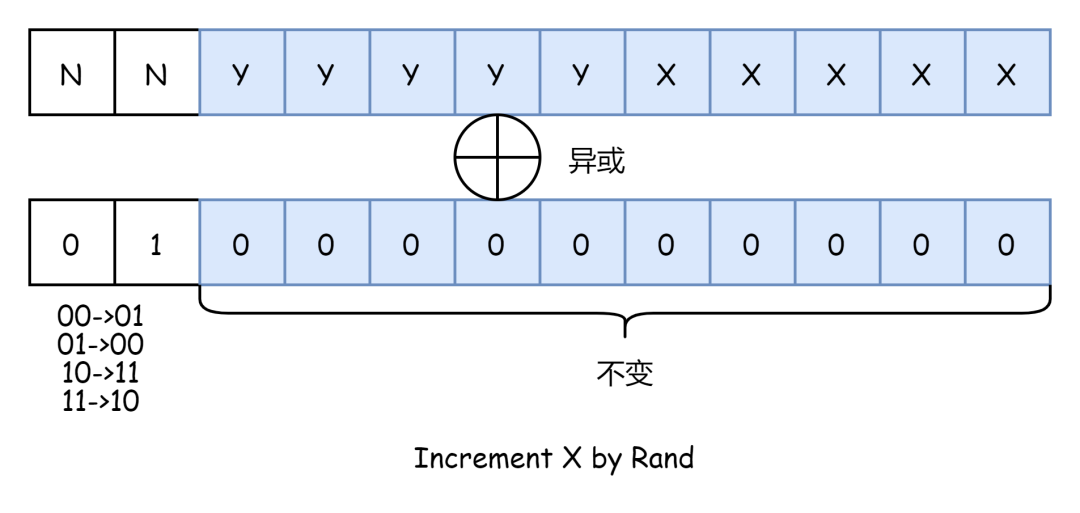
v 跟 0x400 进行异或运算,使得 NN 部分从 00->01 或者 01->00,10->11,11->10,四个 NameTable 的逻辑布局图前文说过,这里再来看一下:

0x2000 表示 NameTable 00,0x2400 表示 NameTable 01,0x2C00 表示 NameTable 10,0x2800 表示 NameTable 11,所以横向切换 NameTable 就是在水平方向相邻的两个 NameTable 之间切换。
cycle 256
在第 256 个时钟周期,增加 v 的 Y 坐标值,表示这一行像素数据已经取完,该准备下一行的数据了,所以增加 Y 的值,Y 值增加稍显复杂,来看伪代码:
if ((v & 0x7000) != 0x7000){ // if fine Y < 7
v += 0x1000 // increment fine Y
}else{
v &= ~0x7000 // fine Y = 0
int y = (v & 0x03E0) >> 5 // let y = coarse Y
if (y == 29){
y = 0 // coarse Y = 0
v ^= 0x0800 // switch vertical nametable
}else if (y == 31){
y = 0 // coarse Y = 0, nametable not switched
}else{
y += 1 // increment coarse Y
}
v = (v & ~0x03E0) | (y << 5) // put coarse Y back into v
}如果 fine_y < 7,那么之间 fine_y ++
如果 fine_y = 7,那么说明该切换纵向的下一个 tile 了,且 fine_y 回到 0,表示从新 tile 的第一行开始,此时还要检查 coarse_y,看看是否需要切换纵向 NameTable,纵向有 240 条可见 scanlines,即 个 tile,即 30 行之前是 NameTable,剩下的两行是 AttributeTable:
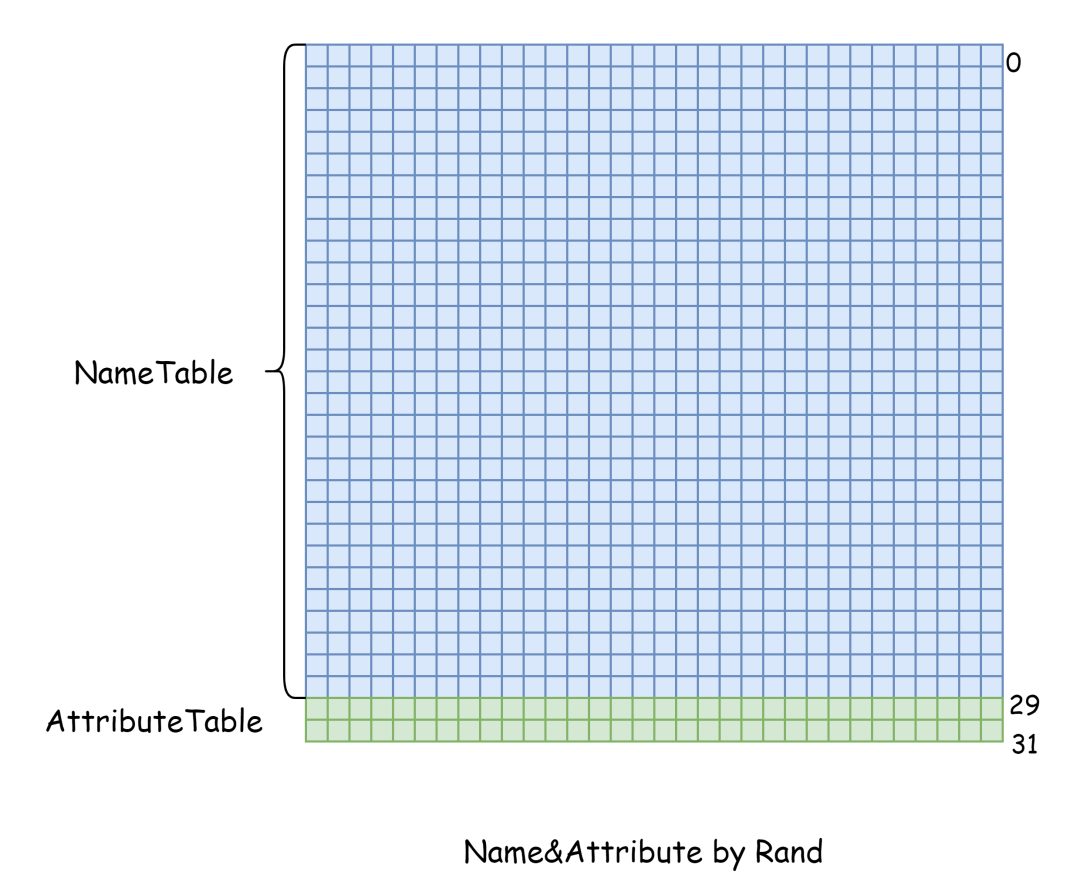
- 如果 coarse_y < 29,那么 coarse_y ++ 即可
- 如果 coarse_y = 29,那么 coarse_y 归 0,切换纵向 NameTable,道理同切换横向 NameTable 不再多说
- coarse_y 是可以设置成 [30, 31],这样会把 AttributeTable 中的内容当作 NameTable,理论上是错误无效的,不过也有这么干的。这种情况 coarse_y 直接归 0,不切换 NameTable
cycle 257
这个周期将 t 的 X 坐标值复制到 v 中,为什么呢?可以这样理解,现在这一行我们已经处理完了,该准备处理下一行了。cycle 256 已经使得 Y 指向下一行了,这里还需要使得 X 指向”行首“,这里的行首就是向 0x2005 写入的 X 坐标值,表示水平方向从哪开始渲染。
cycle 257-320
精灵相关,见后
cycle 321-336
取下一行背景需要的 2 个 tile,并且加载到 shift 寄存器。同样的是那 4 个数据:
- NameTable byte
- NameTable byte
- PatternTable tile low
- PatternTable tile high
同样每个取每个数据 2 周期,4 个数据 8 周期,总共 16 个周期,取两轮与 2 个 tile 吻合。
cycle 337-340
这 4 个周期取两个数据:
- NameTable byte
- NameTable byte
用处不明,mapper MMC5 会用到,但基本上这个没什么用。
Post-render(240)
scanline 240 为 post-scanline,不干什么事,空闲
V_Blank(241-260)
scanline 241-260 这 20 条 scanline 为 V_Blank 时间,这段时间的第一个(从0计数)周期设置产生 NMI 中断。这段时间内 PPU 不会访存,所以程序可以安全地访问 VRAM,这段时间也就是 CPU 来处理 NMI 中断的。前文曾提过,NMI 期间就可以重新填充 NameTable 来加载新的场景,设置 0x2005 scroll 寄存器来控制滚屏等等。
pre-render(-1or261)
scanline -1 或者 261 用作预渲染,一般模拟的时候当作 -1 来模拟较为方便。它的主要作用是为下一行做准备,这一行是不会渲染输出的,只是访存取数据。从图上可以看出与其他可见行没多少不同,直接来看不同的周期:
cycle 1
这个周期清除一些标志位:V_Blank,sprite 0 还有 sprite overflow,
cycle 280-304
每个周期将 t 的 Y 坐标值复制到 v
visible and pre scanline
这里对应着那张图的最后一行,描述可见的 240 条 scanline 和 预渲染的 1 条 scanline
cycle 1
同样的空闲
cycle 1-64
清空 Secondary OAM,指的是将 Secondary OAM 初始化为 0xFF
cycle 65-256
为下一行的精灵做评估,就是说计算下一行将会有哪些精灵需要渲染。
奇数 cycle 从 Primary OAM 读取数据,偶数 cycle 向 Secondary OAM 写数据
下面来看具体怎么评估,伪代码如下:
struct SPRITE_ENTRY{
unsigned char y; //y坐标
unsigned char id; //使用的tile索引
unsigned char attribute; //该精灵的属性
unsigned char x; //x坐标
}
struct SPRITE_ENRY POAM[64]; //Primary OAM 64个精灵,每个精灵4个属性byte
struct SPRITE_ENTRY SOAM[8]; //Second OAM
int sprite_cnt = 0; //目前已经评估了下一行有多少个精灵
int OAM_entry = 0; //评估第几个精灵
// int scanline; //当前正渲染第几条 scanline
// unsigned char control; //control 寄存器里面的值
while(OAM_entry < 64){
int diff = scanline - POAM[OAM_entry].y;
int sprite_high = control.sprite_size ? 16 : 8; //获取精灵的高度,是8*8的还是8*16的
if(diff >= 0 && diff < sprite_high){ //如果该精灵在下一行上
if(sprite_cnt < 8){ //如果精灵计数小于8,加进SOAM
memcpy(&SOAM[sprite_cnt],
&POAM[OAM_entry],
sizeof(struct SPRITE_ENTRY));
}
sprite_cnt++;
}
OAM_entry++;
}私以为伪码还是挺清晰的,不太明白的话再来看看示意图:

cycle 257-320
取下一行精灵需要的数据,同样的是那 4 个数据:
- Garbage NameTable byte
- Garbage NameTable byte
- PatternTable tile low
- PatternTable tile high
同样的每个数据需要花费 2 个周期,这里有朋友可能会发现,Garbage NameTable byte?NameTable 里面存放的是背景 tile 索引,而不是精灵的,精灵使用的 tile 索引存放在 OAM,之所以这里取精灵需要的 tile 也是这么个形式,是为了精灵可以重用背景的电路。
这里总共花费 64 个周期,,与每一行支持的精灵数 8 吻合。
屏幕分割
到此每条 scanline 每个周期干啥说完了,下面来说一些高级玩法,就是屏幕分割技术。
split X scroll
split X scroll 需要用到 sprite 0 hit,主要的作用可以用来制作静止的分数,血条等等,举个马里奥的例子:
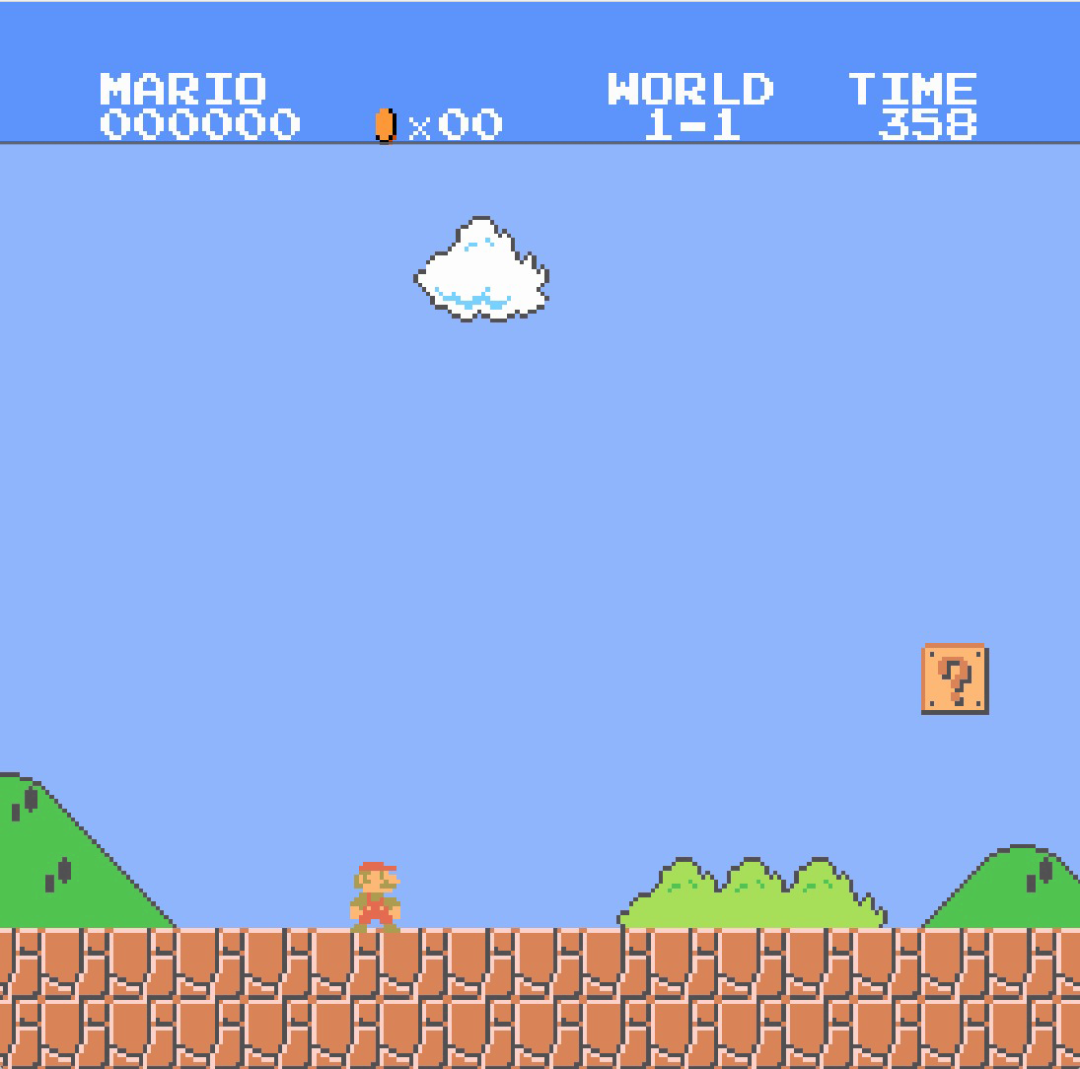
深色部分是不会像下面浅色部分滚屏的,感觉上面和下面分割开来,且只有水平方向的分割,所以叫做 split X scroll,下面来看看是如何实现的。
I sprite 0 hit
先来了解什么叫做 sprite 0 hit,sprite 0 hit 就是说如果第 0 个精灵的不透明像素与背景不透明像素重合的话,就将 0x2002 PPUSTATUS 状态寄存器的 bit6 置 1,表示触发了 sprite 0 hit。
这有什么作用?它是 PPU 与 CPU 同步的一种手段,当 V_Blank 触发 NMI 时,CPU 只是知道当前帧渲染完了,准备下一帧,这个时间同步不精细。于是创造一个 sprite 0 hit,编程人员将 sprite 0 放在一个特定位置,当触发 sprite 0 hit 时,CPU 就知道,哦,原来渲染到这条 scanline 了。
我们就可以利用这个特性来实现 split X scroll,我们就以超级马里奥为例子,来看 split X scroll 如何实现的。
II Implement
首先看超级马里奥的 sprite 0 在哪儿:
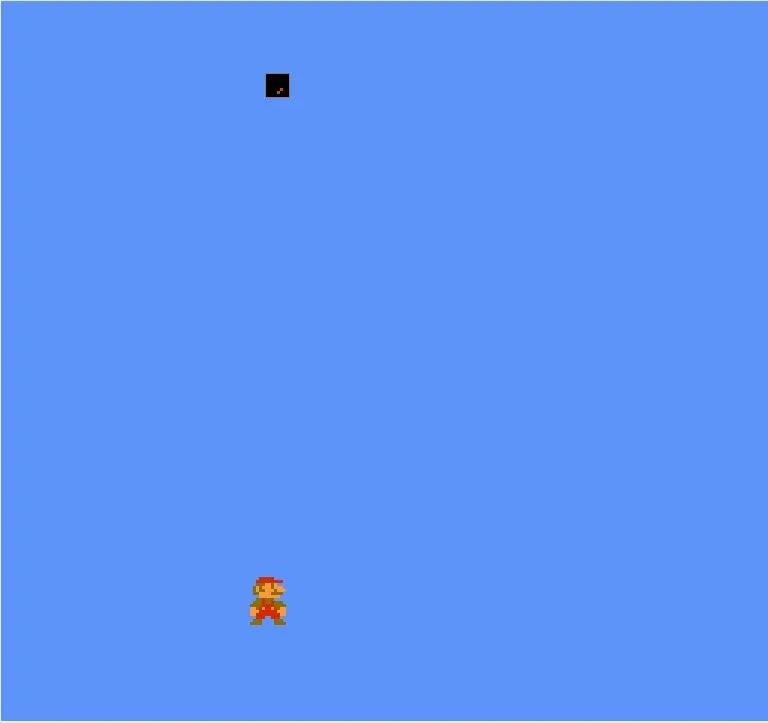
这是游戏刚开始的“两个”精灵,其中上面那个就是 sprite 0,具体在哪儿?

具体的,就是在金币的下方,金币是背景,且不是使用的通用背景色,sprite 0 也不是透明色,所以每一帧渲染到这一行的 sprite 0 所在的位置时就会触发 sprite 0 hit。
之后就在 NMI 的中断处理程序中做文章:
NMI:
LDA #$00
STA $2006 ; 清理VRAM addr,也就是 t v 清0
STA $2006
LDA #$00 ; 设置滚屏地址为0,也就是先让分数条等不滚动
STA $2005
STA $2005
LDA #%10010000 ; 使能NMI和选取NameTable
STA $2000这部分主要就是先清空寄存器 v 中存放的 VRAM 地址,然后设置滚屏地址为 0,即不滚屏。
WaitNotSprite0:
lda $2002
and #%01000000
bne WaitNotSprite0 ; 等待sprite0 标志位清0上述我们已经知道预渲染期间是会清零标志位的,其中就包括 sprite0。
WaitSprite0:
lda $2002
and #%01000000
beq WaitSprite0 ; wait until sprite 0 is hit然后这里就等待 sprite 0 hit
ldx #$10
WaitScanline:
dex ; 递减
bne WaitScanline ; 等待sprite0这一行渲染完成
LDA scroll ; 设置水平滚屏地址
STA $2005
LDA #$00 ; 纵向不滚屏
STA $2005触发 sprite 0 hit 之后,我们要先等待 sprite 0 所在的这一行渲染完成,经验值大概 16 次运算(上述递减)就差不多了。
之后将新的滚屏地址写进 0x2005 即寄存器 t 里面去,这就完成了 split X scroll。
可能有朋友疑惑为什么能行,这里就联系上面讲述的内容,每条 scanline 的 257 cycle,会重新将 t 中的 X 坐标复制到 v 中,所以实现了在渲染中途改变滚屏地址,实现 split X scroll。
这里再总结一下如何实现 split X scroll:
- 设置滚屏地址为 0,主要是为了状态条不滚动
- 等待清除 sprite 0 标志位
- 等待触发 sprite 0 hit
- 延迟一会儿,等待 sprite 0 所在行渲染完成
- 重新设置滚屏地址
这里可能有朋友疑惑,为什么要先等待 sprite 0 not hit 然后再等待 sprite 0 it,这里我们假设没有等待 sprite 0 not hit,那么 V_Blank 期间会一直检测到 sprite 0 hit,但实际上这只是当前帧的 sprite 0 hit,下一帧的 sprite 0 hit 还没到,所以需要等待 sprite 0 not hit。
split X/Y scroll
sprite X scroll 总的来说还是简单,设置滚屏地址只需要写 0x2005 就行了,但是如果想要在纵向也滚屏,那么只写 0x2005 就行不通了。因为每一行的 257 只会将 t 的 X 坐标值复制到 v,不会复制 Y 坐标值,预渲染会复制 Y 坐标值,但是每一帧只有一条预渲染 scanline,这时复制 Y 坐标值并不能实现渲染中途更改 Y 坐标值。
所以得另想它法,在前文滚屏渲染基础部分我们说过连续两次向 0x2006 写入数据后,t 中全部数据都会复制一份到 v。因此我们利用 0x2005 和 0x2006 来实现 split X/Y scroll
这里又因为 0x2005 和 0x2006 共享 w 和 t,且两者写入数据方式不太一样,具体的话我再放一遍图片,详细情况可以看前文:




正因为两者写入数据的差异,所以有如下所示的写入顺序和方式:
- NameTable number << 2 to 0x2006
- scroll Y to 0x2005
- scroll X to 0x2005
- ((Y & 0xF8) << 2) | X >> 3
当然也可以不这样,wiki 上还列出的有另外的方式,但是这种比较简单,有兴趣的话可以模拟走一遍,如此的确是能将 X/Y 写进 t 然后复制到 v 的,这里直接看 wiki 上给出的一个例子理解一下这个过程:
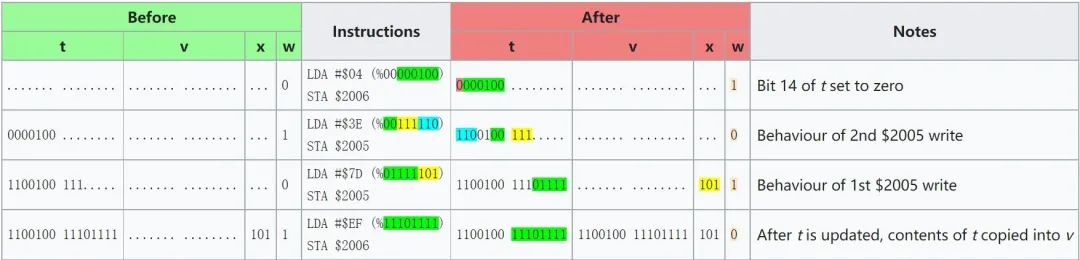
这种方式会立即设置 v,加之前面我们知道每一行有的周期会增加 X 有的周期会增加 Y,所以写入时间很重要。通常最后一个写入要在 H_Blank,前面我们多次提到垂直消隐 V_Blank,其实也还有个水平消隐 H_Blank,它发生在一条 scanline 末尾,通常将 cycle 257-320 视作 H_Blank。
cycle 256 会增加 Y 的值,所以如果在 256 之前写入,那么实际写入 0x2006 的值应为 Y-1,具体有没有一个什么参照使得写入时间确定呢?应该是没得的,我目前没发现相关资料,看到的代码都是经验值,可以使用 sprite 0 hit 来大致确认,但精确参照应该是没得的,这里有份大佬的代码,有兴趣的可以看一眼:
;Write nametable bits to t.
lda splitNT
asl
asl
sta PPUADDR
;Write y bits to t.
lda splitY
sta PPUSCROLL
;The last write needs to occur during horizontal blanking
;to avoid visual glitches.
;HBlank is very short, so calculate the value to write now, before HBlank.
and #$F8
asl
asl
sta tmp
lda splitX
;Write the X bits to t and x.
sta PPUSCROLL
;Finish calculating the fourth write.
lsr
lsr
lsr
ora tmp
;Wait for HBlank.
ldx #06 ;How long to wait. Play around with this value
;until you don't have a visual glitch.
loop:
dex
bne loop
;Write to t and copy t to v.
sta PPUADDR这份代码的意思就是上述所说的 4 次写入,只是增加了个等待 H_Blank,就不具体解释了。
好了本文就讲述这些,主要继续滚屏渲染的话题,有什么还请批评指正。