如何使用 AntV S2 打造大数据表格组件?
导读
在蚂蚁的大数据研发平台中,数据表格是一类重要的业务组件。我们需要流畅的展示 SQL 查询出来的上万条结果,并对结果做筛选、排序、搜索、复制、框选、聚合分析等操作。同时也存在数据手工录入的场景,需要表格有可编辑的能力。所以我们最终需要的是一种 JavaScript 版的电子表格,类似一个简单的 Excel 工作簿。
本文记录的是,在开源软件不足以满足需求,同时商业软件价格高、定制难的情况下,我们如何基于开源 Canvas 表格渲染库 AntV S2 来实现拥有诸多功能的 React 大数据表格组件,并且解决了之前商业软件版本实现的性能问题和拓展性问题。
业务场景介绍
Dataphin 是蚂蚁内部的大数据研发平台,同时也有云上版本对外售卖。Dataphin 一站式提供数据采、建、管、用全生命周期的大数据能力。在 Dataphin 中有很多场景都用到了大数据表格。最典型的就是研发模块中,用来展示计算任务的运行结果:
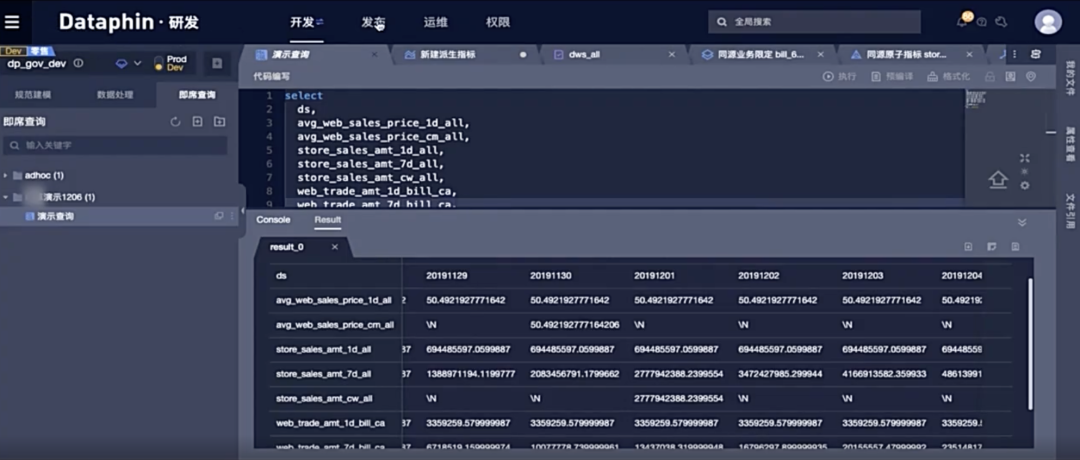
以下是数据表格常用功能的演示: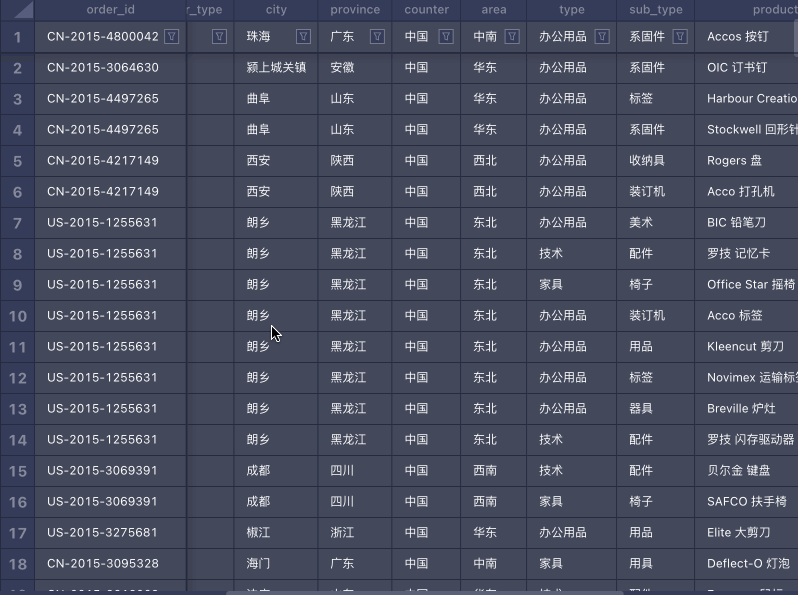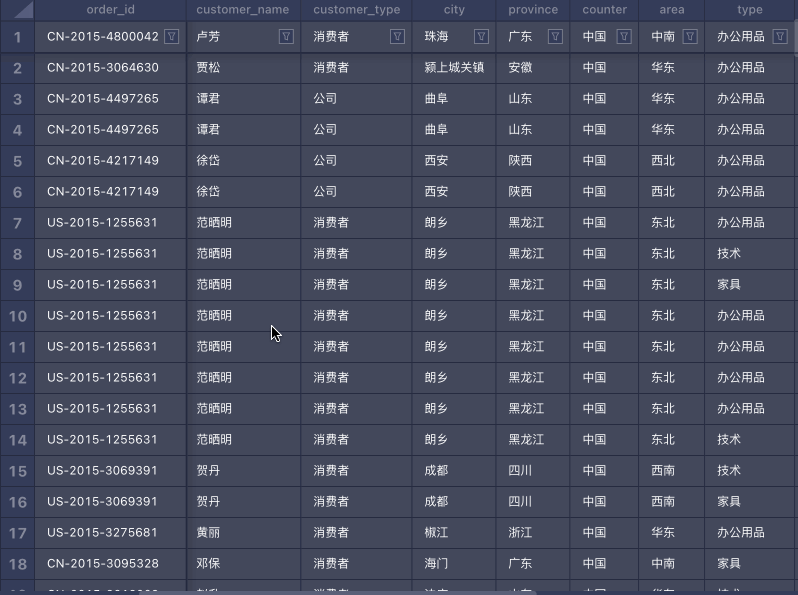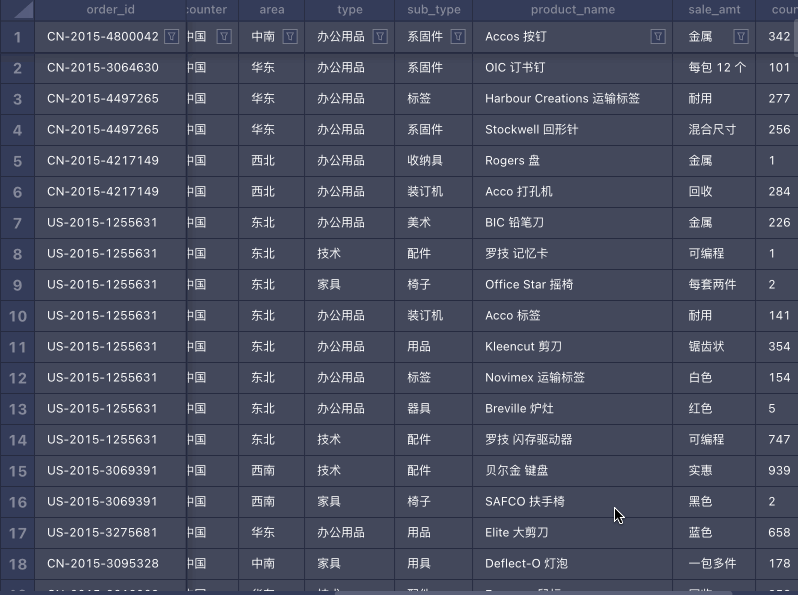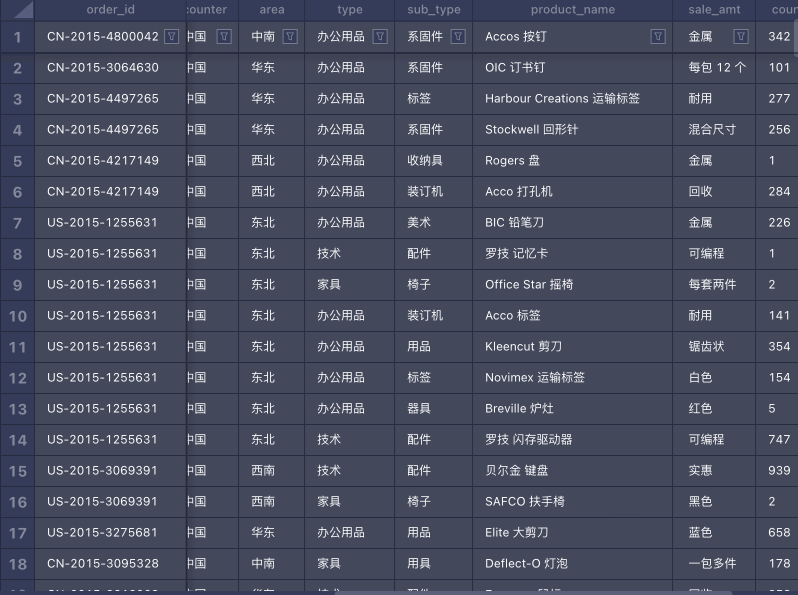
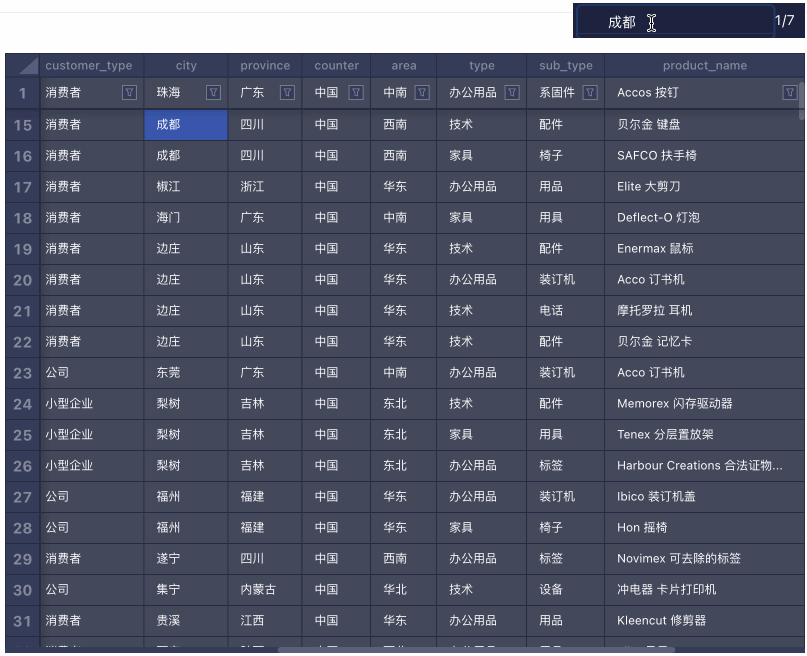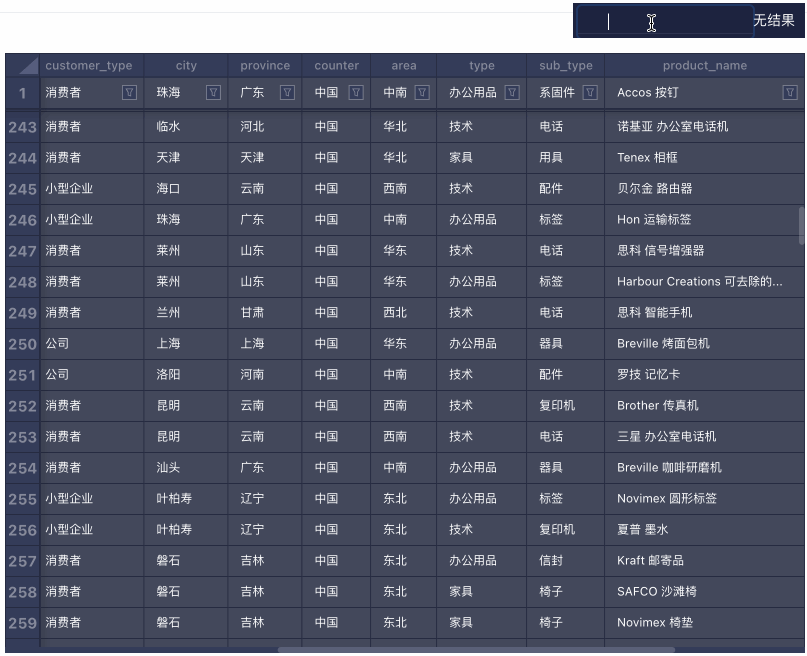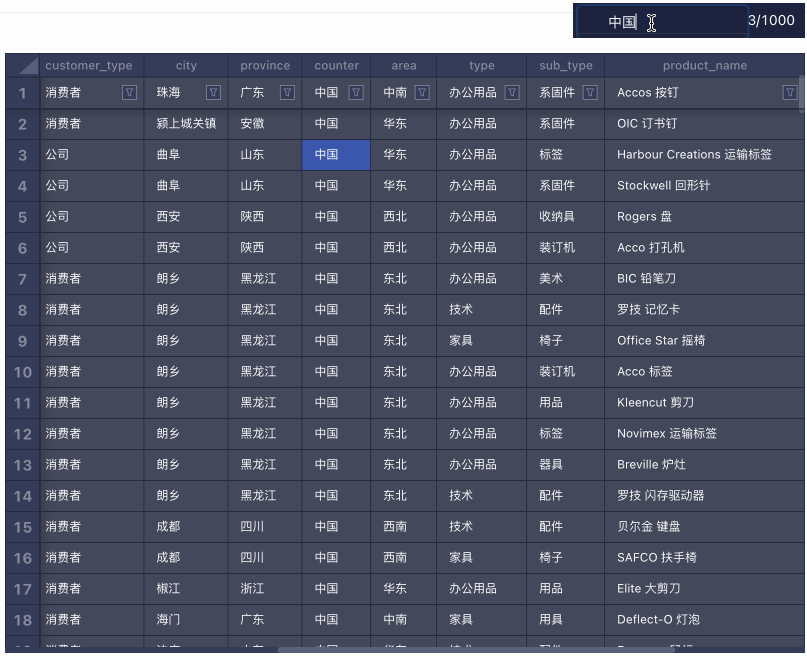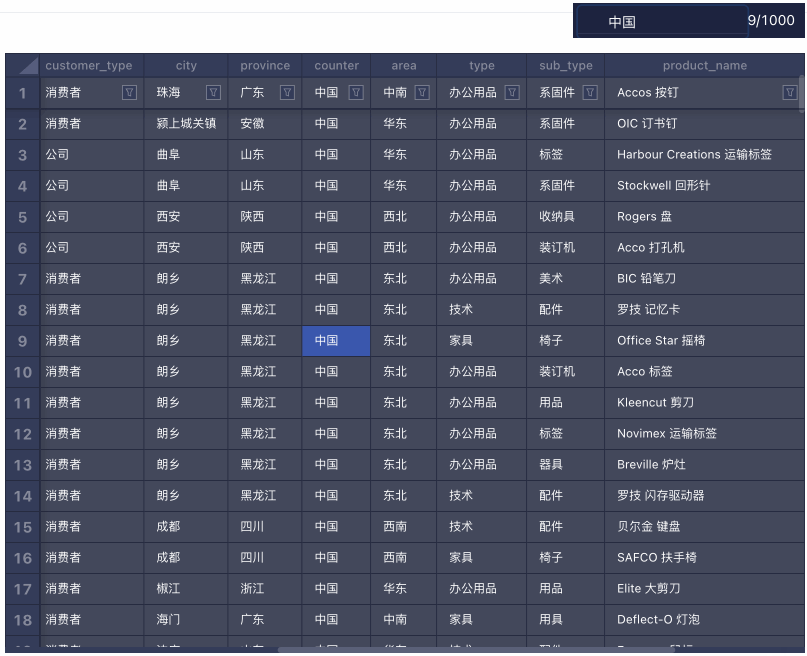 搜索
搜索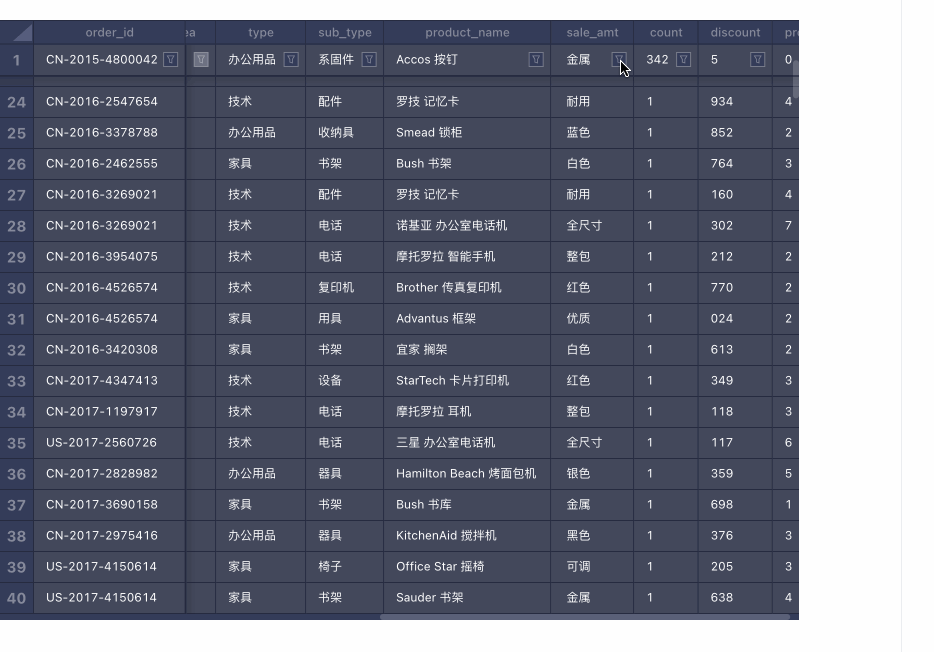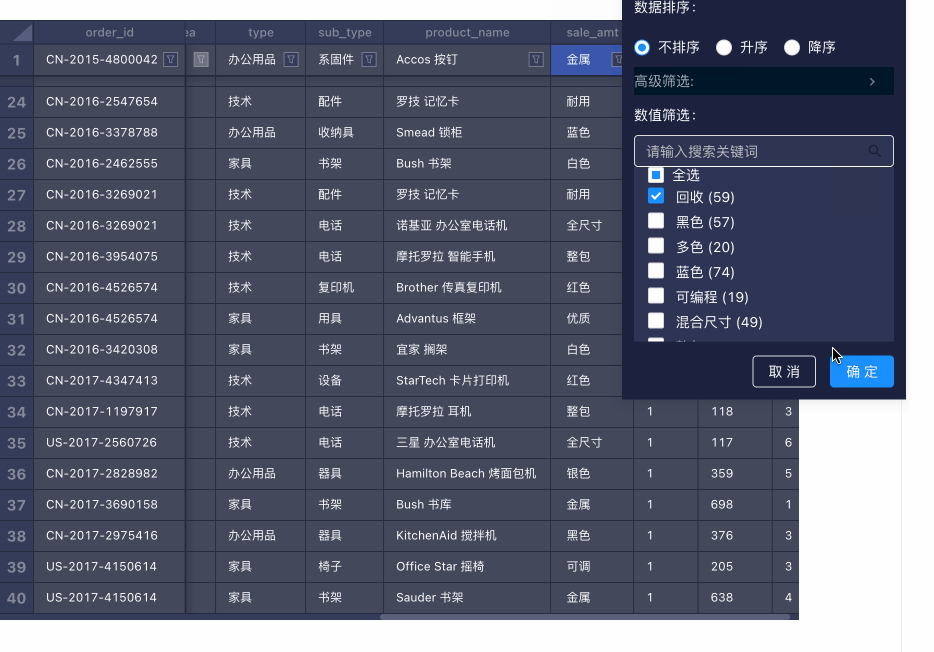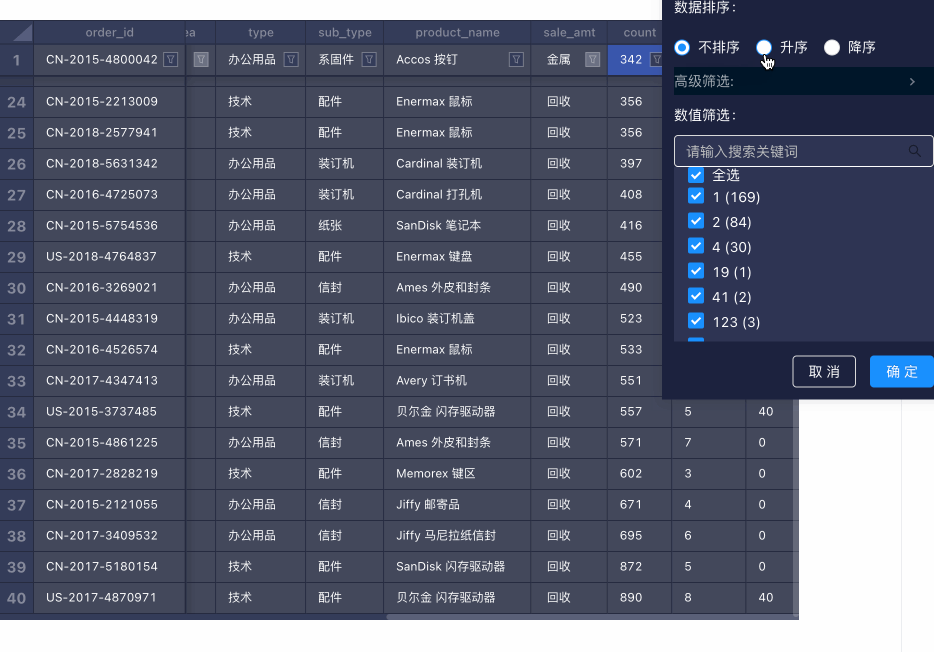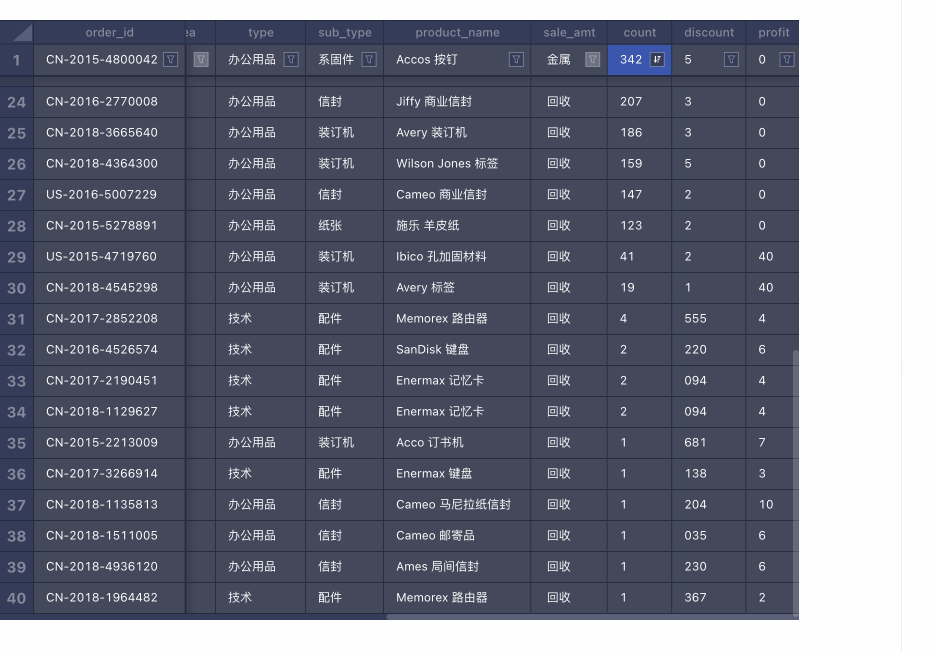 筛选 & 排序
筛选 & 排序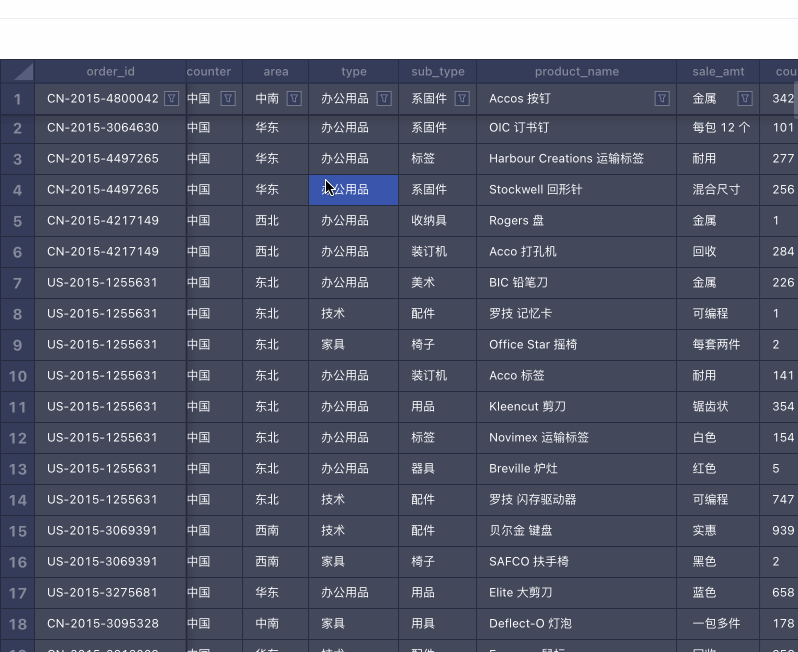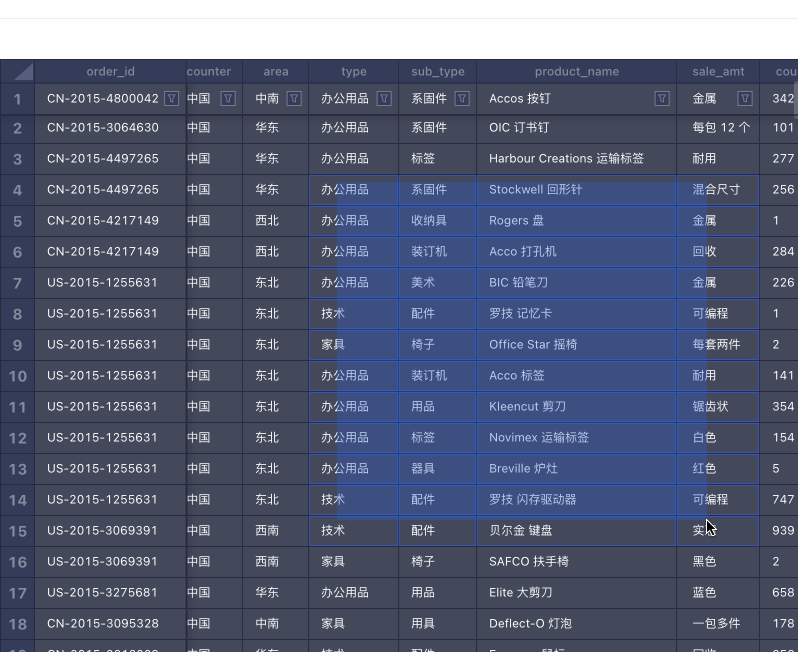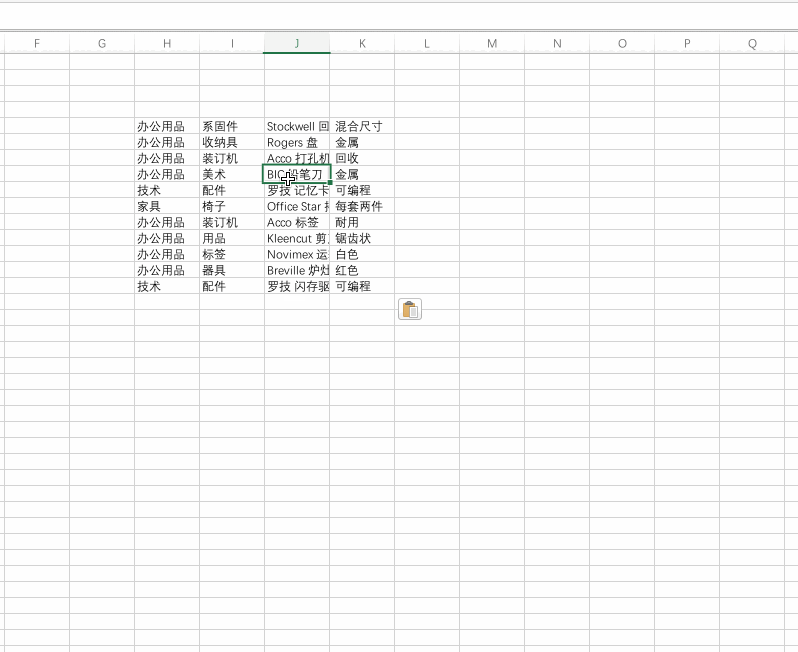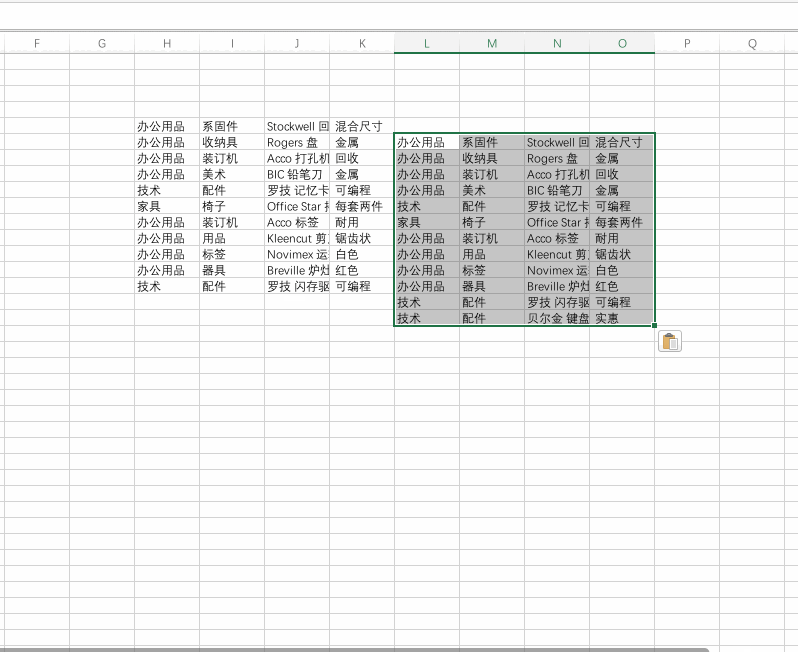 框选 & 复制
框选 & 复制

技术选型:为什么使用 AntV S2 ?
对于复交互的电子表格类组件来说,基于 Canvas 实现会比 DOM 实现有着更大的优势。从性能上说,DOM 渲染需要经过如下的渲染流程,所有的 UI 改动都会涉及内部数据结构的构建、样式的解析、布局的计算。最终才渲染出来: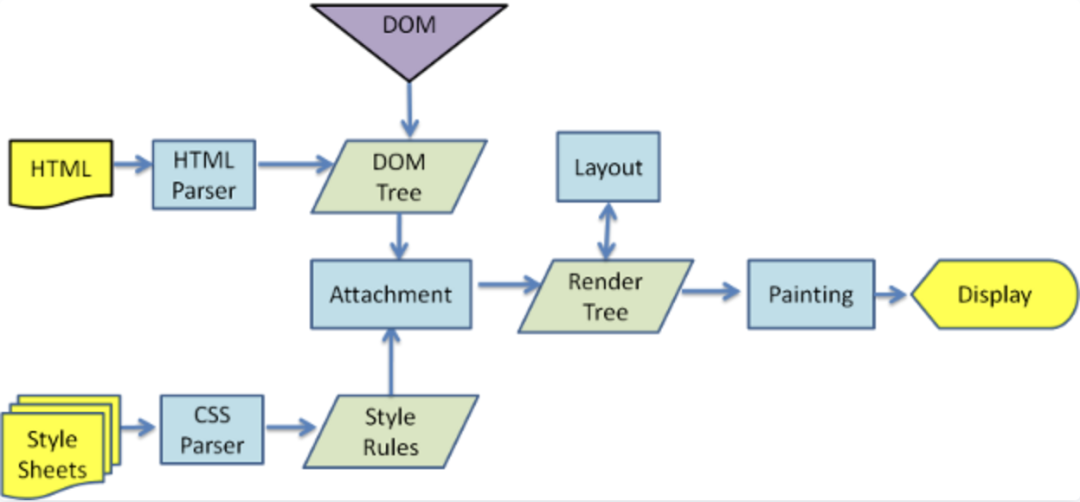
| 产品名称 | 技术栈 | 开发商 | 费用 | 结论 |
|---|---|---|---|---|
| SpreadJS[1] | Canvas | 公司 | 收费 | 市场上最强大的 Excel 组件,但需要比较高的授权费用,同时在多实例、大数据量的场景下,性能比较差,并且很难拓展和定制 UI |
| LuckySheet[2]、x-spreadsheet[3] | Canvas | 个人 | 开源 | 开源的类 Excel 组件。都是个人作品,由社区力量维护,投入的持续性、稳定性无法保障,在产品细节体验上也不如 SpreadJS |
| Handsontable[4] | DOM | 公司 | 收费 | DOM 实现。同时需要收费。 |
| 语雀、钉钉等表格服务 | Canvas | 公司 | / | 通过服务化的 SDK 提供前后端一体的服务,而不是单纯的前端组件形式。同时拓展性也不如开源产品。 |
在市场上无法找到合适的选择之后,我们蚂蚁数据智能前端团队选择将内部的交叉表组件孵化为开源的 AntV S2 表格渲染引擎。
S2 是 AntV 团队推出的数据表可视化引擎,旨在提供高性能、易扩展、美观、易用的多维表格。不仅有丰富的分析表格形态,还内置丰富的交互能力,帮助用户更好地看数和做决策。
S 取自于 SpredSheet 的两个 S,2 也代表了透视表中的行列两个维度。S2 不仅有交叉表模式,还支持明细表模式。
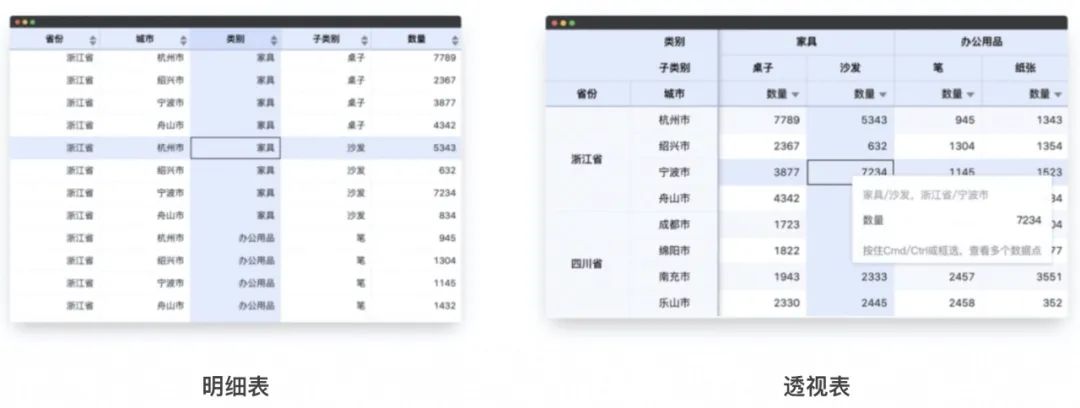
明细表就是普通的表格。类似 Antd Table 组件。适用于明细数据的展示。比如我们一开始说到的 SQL 查询结果的预览等等。明细表组件流畅在支持 10w+ 条大数据展示的基础上,还支持丰富的交互:单选、刷选、复制到 Excel、快捷键多选、列宽高拖拽调节等等。方便用户快速的对数据做选择和操作。
表格功能实现
S2 的明细表为我们提供了一个很好的基础底座,关于明细表的功能,大家可以参考文档[5]。接下来就聊聊如何在明细表的基础上,利用 S2 的高拓展性设计,实现一款功能丰富的 React 大数据表格组件。其中一些常用功能内置到了 S2 中,比如行列冻结、复制等。另外还揭秘了一些 S2 的内部实现,比如虚拟滚动的原理。
功能大图
首先看一下大数据表格组件的功能大图:
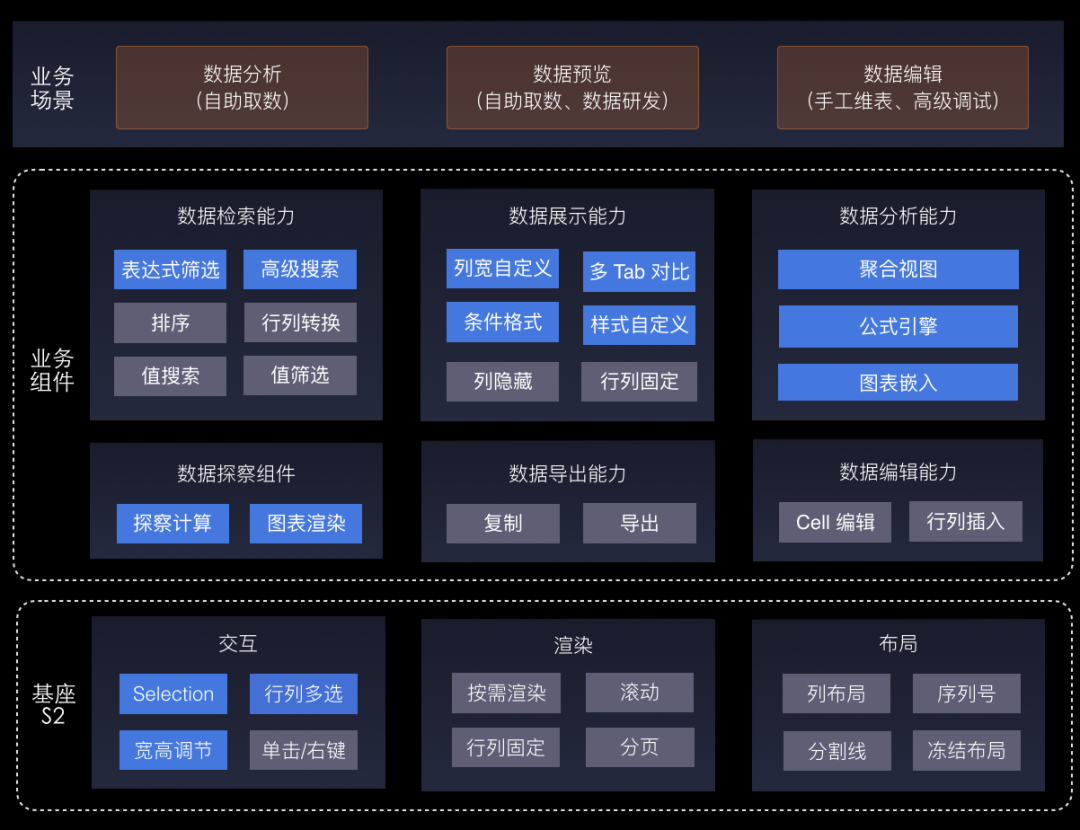
上图的能力中,包含了数据展示、检索、导出、编辑等核心能力。其中分析方面的公式、聚合等能力是未来规划的。接下去会讲讲目前实现的这些核心功能的设计与实现。
交互
单元格编辑
单元格编辑是大数据表格在交互上遇到的最核心诉求。用户可以直接的编辑数据,录入数据。在手工维度表、调试录入 Mock 数据等等场景有着广泛的使用。由于 S2 的定位是分析表、明细表核心库,所以单元格编辑的能力并没有内置。这个能力需要大数据表格组件来扩展实现。
首先需要考虑的问题便是技术实现上,编辑能力是使用 DOM 还是 Canvas 实现?在功能开发之前,我们调研了业界各类主体基于 Canvas 的电子表格库,结果大致如下:
| 库 | 单元格编辑实现 |
|---|---|
| SpreadJS | DOM |
| 语雀表格 | DOM |
| x-spreadsheet | DOM |
可以看到,主流的实现都选择了 DOM 作为单元格编辑的载体。考虑到光标绘制,文本选中,换行逻辑等等一系列在 DOM 中都将由浏览器实现,在 Canvas 中则需要重新实现,使用 Canvas 上覆盖 DOM 节点做文本编辑是性价比最高的方案。所以我们最终决定使用 DOM 来实现,效果如下:
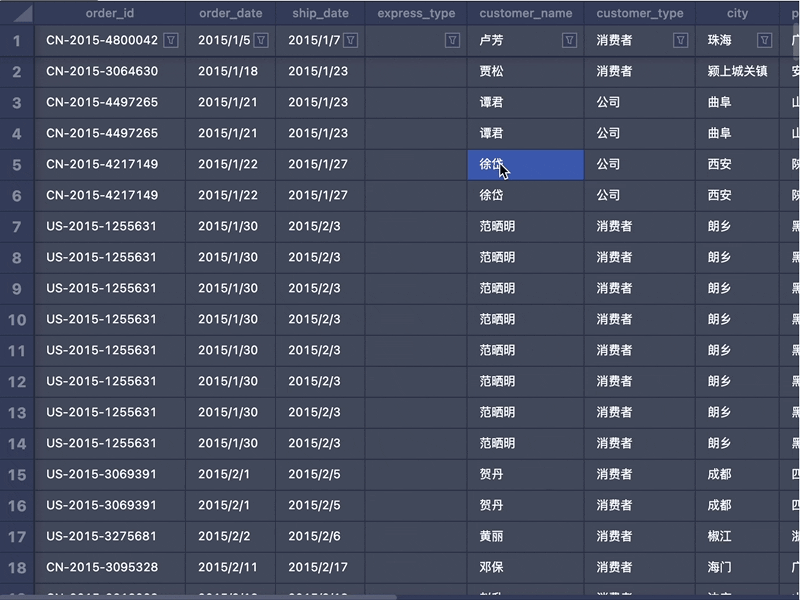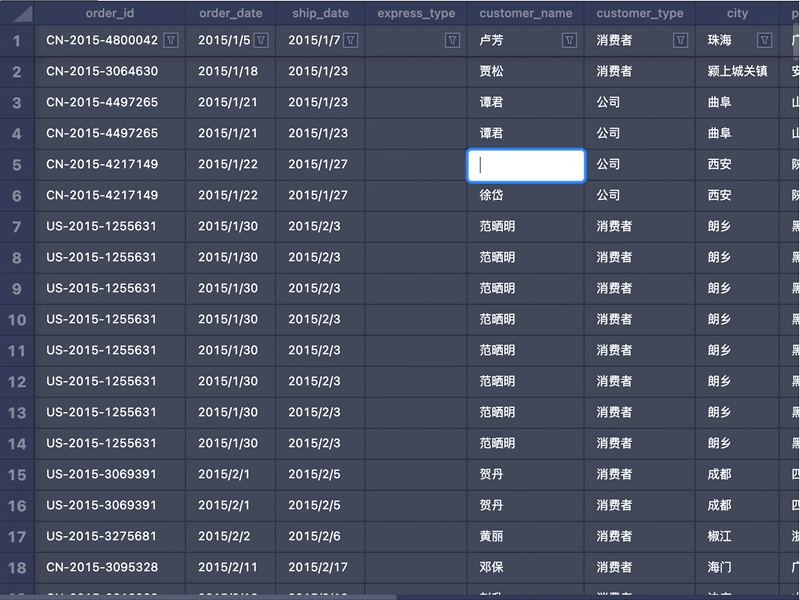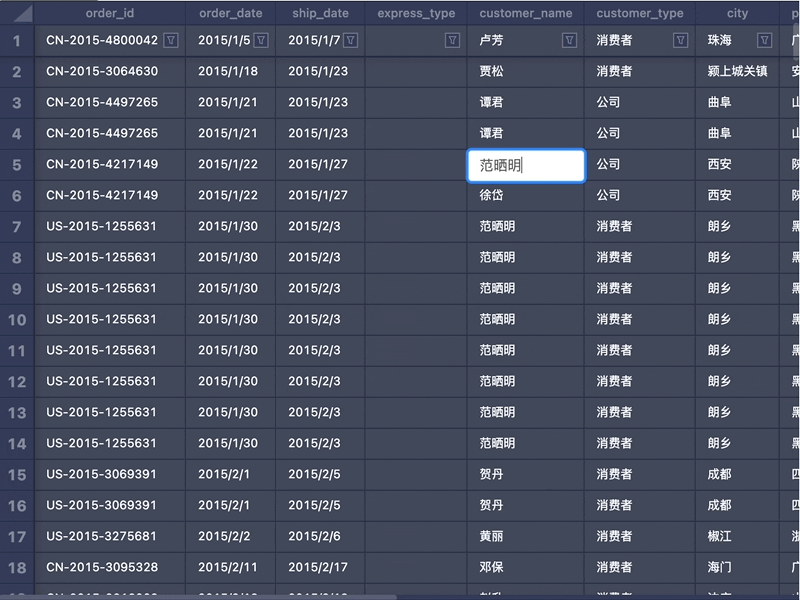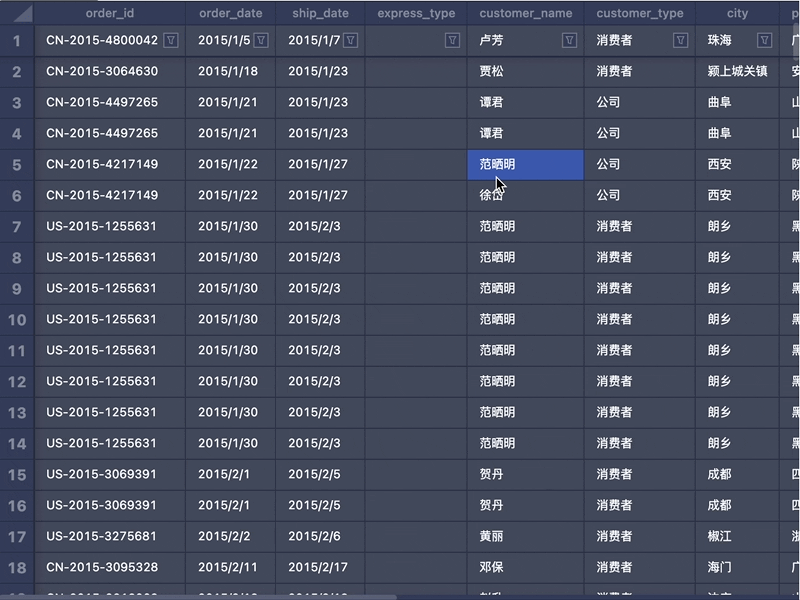
1. 计算DOM遮罩大小和坐标编辑态其实类似一种 Modality。需要用户的 Focus,在编辑时需要阻断和底部表格的交互。所以我们需要挂载一个 DOM 遮罩容器节点,大小和 Canvas 保持一致,用于放置 TextArea。元素的定位使用到了目前的窗口滚动的 Offset 和 Canvas 容器的坐标值。
const EditableMask = () => {
const { left, top, width, height } = useMemo(() => {
const rect = (spreadsheet?.container.cfg.container as HTMLElement).getBoundingClientRect();
const modified = {
left: window.scrollX + rect.left,
top: window.scrollY + rect.top,
width: rect.width,
height: rect.height,
};
return modified;
}, [spreadsheet?.container.cfg.container]);
return (
<div
className="editable-mask"
style={{
zIndex: 500,
position: 'absolute',
left,
top,
width,
height,
}}
/>
);
};
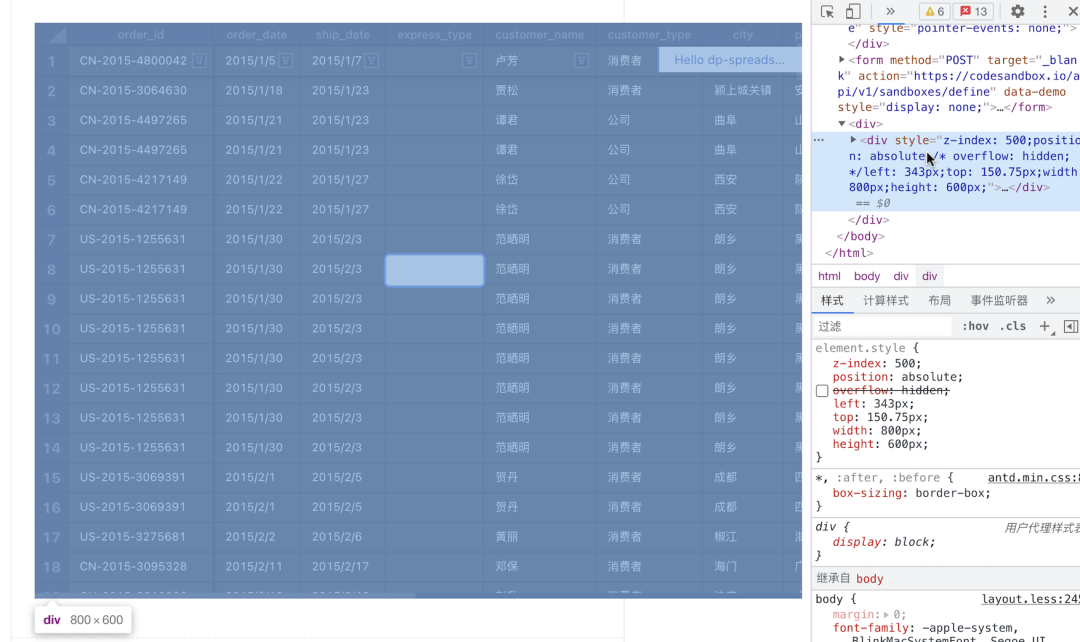
2. 注册事件并渲染 TextArea 元素
编辑操作一般会由双击来触发,而 S2 为我们提供了 DATA_CELL_DOUBLE_CLICK 事件。然后来看看 TextArea 的渲染逻辑,我们需要拿到单元格的定位和当前数据值。在触发事件时,从被双击的 DataCell 对象中可以拿到 x/y/width/height/value 这几个核心数据。需要注意,这里的 x 和 y 针对的是整个表格,而不是当前的 ViewPort,因此我们需要使用 spreadsheet.facet.getScrollOffset() 获取表格内部的滚动状态并对 x/y 做针对性的修改。
核心逻辑如下:
// 从事件回调拿到 Cell 对象
const cell: S2Cell = event.target.cfg.parent;
// 计算定位和宽高
const {
x: cellLeft,
y: cellTop,
width: cellWidth,
height: cellHeight,
} = useMemo(() => {
const scroll = spreadsheet.facet.getScrollOffset();
const cellMeta = _.pick(cell.getMeta(), ['x', 'y', 'width', 'height']);
// 减去滚动值,获取相对于 ViewPort 的定位
cellMeta.x -= scroll.scrollX || 0;
cellMeta.y -=
(scroll.scrollY || 0) -
(spreadsheet.getColumnNodes()[0] || { height: 0 }).height;
return cellMeta;
}, [cell, spreadsheet]);
// 获取当前单元格数值并存到 state 中
const [inputVal, setinputVal] = useState(cell.getMeta().fieldValue);接着我们使用 x/y/width/height 把 TextArea 渲染到 DOM 遮罩中,填充单元格当前的值,并手动 .focus(),方便用户直接开始编辑操作。
3. 编辑完成后清理逻辑
在用户触发了 onBlur 事件或者输入回车的时候,我们销毁 TextArea,并将修改后的值回填到spreadsheet.originData 中。并且抛出对应的事件,通知使用者。
刷选
在 Excel 中,刷选是一种重要的交互。用户可以自由的批量框选单元格,并且在鼠标移动到画布外时,画布会自动滚动,同时更新框选区域:
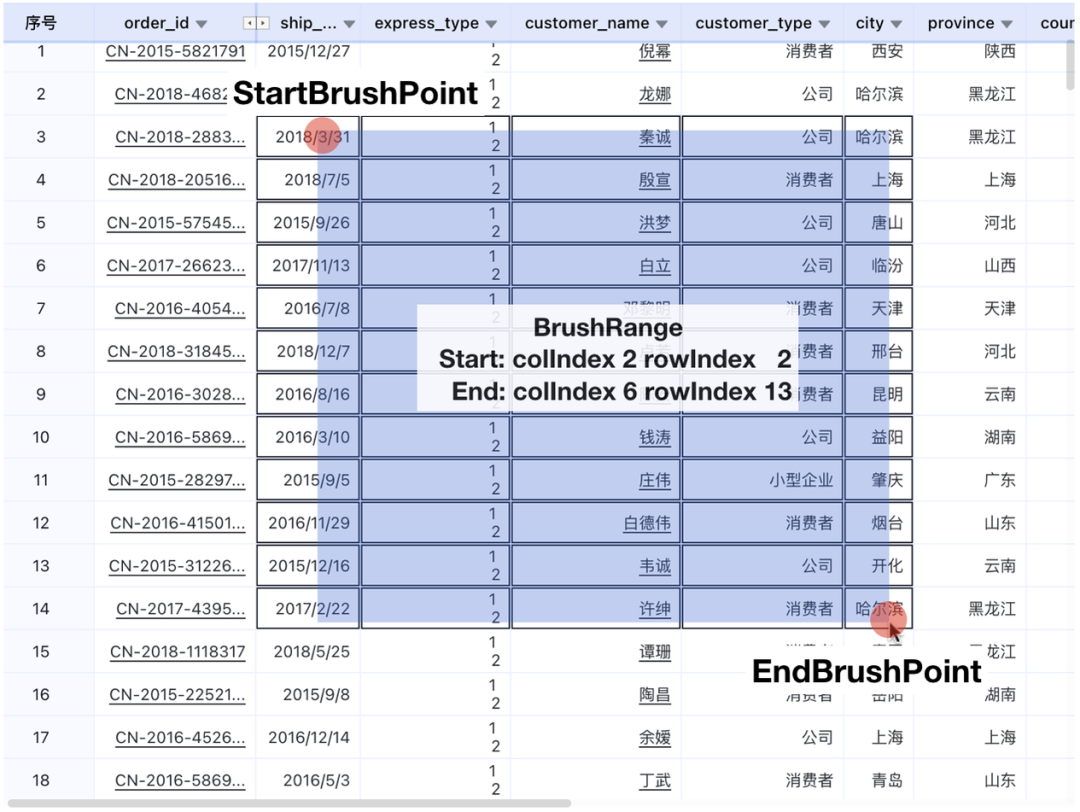
S2 中内置了刷选的交互。下面我们来看这个交互的实现方式。首先明确一些概念:
- StartBrushPoint 刷选开始点。MouseDown 事件时记录。
- EndBrushPoint 刷选结束点。MouseMove 事件时更新。
- BrushRange 刷选范围。包含了开始点的行列 Index 和结束点的行列 Index。

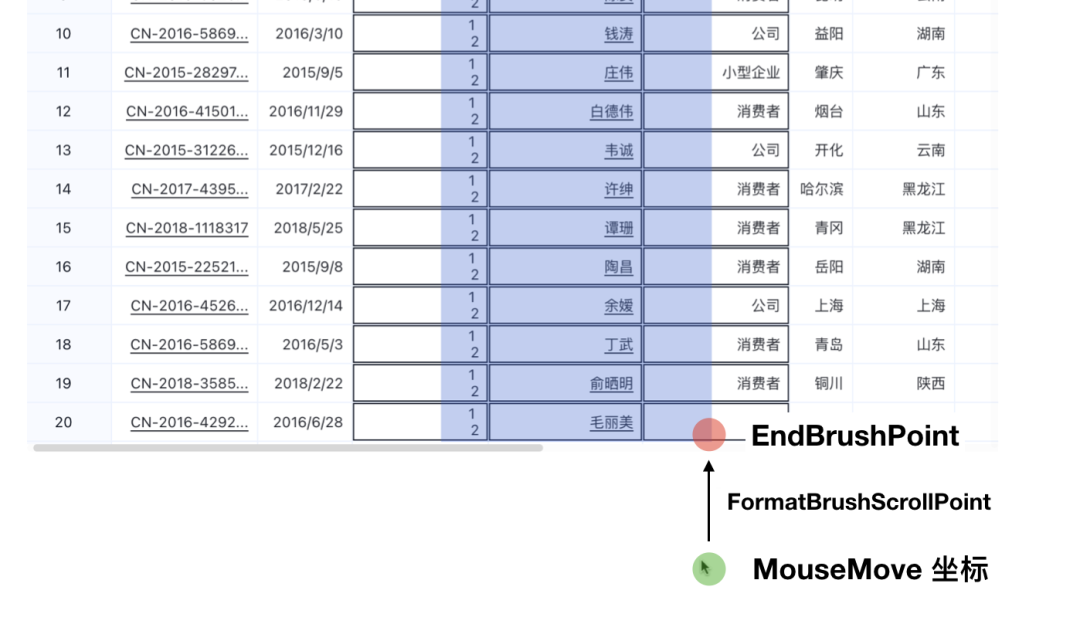
首先在滚动触发阶段,监听 MouseMove 事件时,需要增加判断,如果鼠标不在画布范围内,就进入自动滚动流程,并把 EndBrushPoint 限制在画布上。如图:
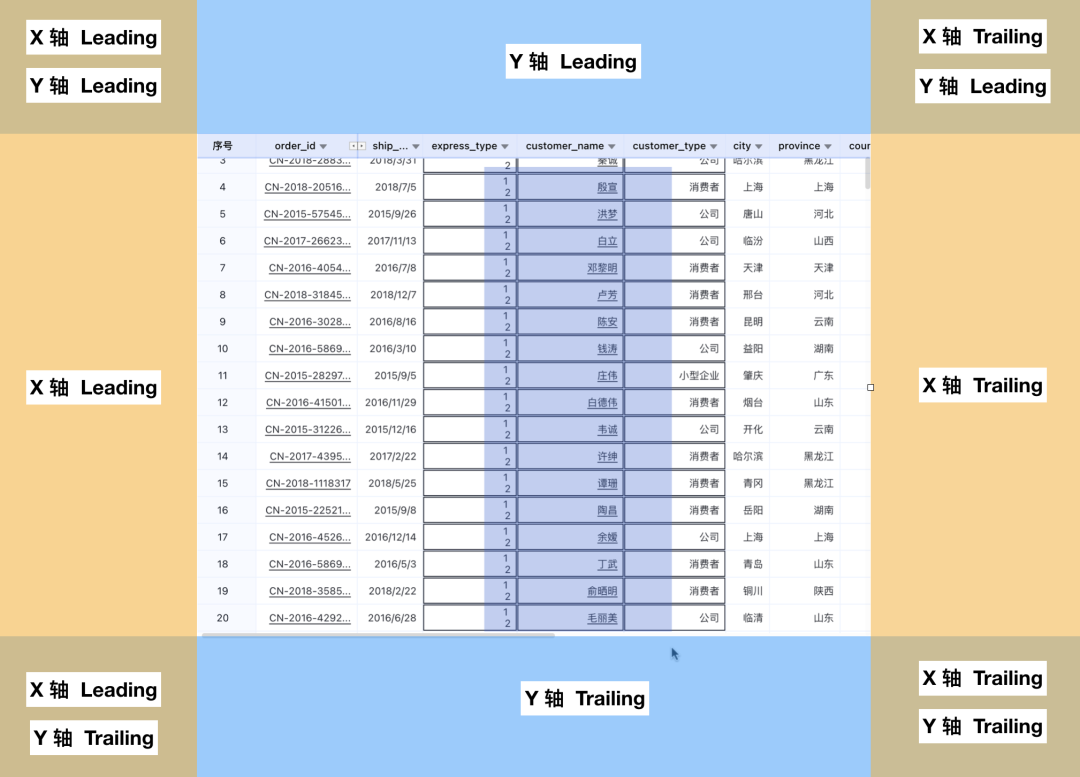
同时在这个过程中,我们还可以得到滚动的方向。我们把滚动方向分为 Leading 和 Trailing 两种(头部和尾部)。同时又分 X 轴和 Y 轴两个方向。这样就有了 8 种滚动的可能方向。根据 MouseMove 坐标所在的位置,就可以计算出需要滚动的方向。如下图所示:
在知道滚动方向之后,就可以触发自动滚动了。
还有一些细节问题需要考虑。比如在滚动中,每个格子的宽和高都有可能是不同的,如果滚动的距离是一个恒定的值,那在遇到很高或者很宽的格子时,就会出现龟速滚动几次才能滚完一个格子的情况。所以每次滚动的距离,必须是一个动态的值。实际落地的方案是这样的:拿向右滚动举例,滚动的 Offset 会定位到下一个格子的右侧边缘。比如这样:
在循环滚动时,滚动的频率也是一个需要注意的细节。不同的用户对于滚动频率有不同的诉求。所以滚动频率也不应该是恒定的。一种方案是将滚动速度和滚动离开画布的距离关联起来。往下面拉的越多,滚动就越快,直到一个最大值。比如 Excel 中的实现:
const MAX_SCROLL_DURATION = 300;
const MIN_SCROLL_DURATION = 16;
let ratio = 3;
// x 轴滚动速度慢
if (config.x.scroll) {
ratio = 1;
}
this.spreadsheet.facet.scrollWithAnimation(
offsetCfg,
Math.max(MIN_SCROLL_DURATION, MAX_SCROLL_DURATION - this.mouseMoveDistanceFromCanvas * ratio),
this.onScrollAnimationComplete,
);里面的一些参数,是根据实际的用户体感来确定的。需要经过不断的优化迭代,达到一个比较理想的状态。
渲染
虚拟滚动
在大数据表格场景中,如何高性能的渲染大量数据一直都是最重要的问题之一。我们可以把大数据表格看成一个长列表,对于长列表,最常见的优化策略就是只渲染可见区域的内容。在滚动事件触发后,根据滚动 Offset 调整相应渲染的内容即可。在用户看来,还是一个完整的长列表。
DOM 的虚拟列表实现[6]需要考虑的东西比较多,也有 React-Virtualized 这样的库可以直接使用。基于 Canvas 的长列表优化方式,我们叫虚拟滚动。因为基于 Canvas 的应用每次渲染都会重绘整个界面。我们使用 requestAnimationFrame 来定时 Schedule 一次渲染,让频繁的滚动事件落到浏览器的渲染周期中。然后在每个 animationFrame 的回调中,只需要计算出当前视口内的元素范围然后渲染这些格子就可以了。
下面讲讲具体的实现流程:
第一步:计算可视区坐标范围,得出可视区内的格子列表
首先根据行列信息和当前滚动 Offset 计算出可视区的范围,获得一个数组,包括 [xMin, xMax, yMin, yMax]。也就是行和列的 index 范围。如下图所示:

第二步:和上一次格子列表做对比,得到 Diff
这一步中,我们将上一次渲染的可视区 Index 和当前进行 Diff,拿到需要新增和删除的格子:
export const diffPanelIndexes = (
sourceIndexes: PanelIndexes,
targetIndexes: PanelIndexes,
): Diff => {
const allAdd = [];
const allRemove = [];
Object.keys(targetIndexes).forEach((key) => {
const { add, remove } = diffIndexes(
sourceIndexes?.[key] || [],
targetIndexes[key],
);
allAdd.push(...add);
allRemove.push(...remove);
});
return {
add: allAdd,
remove: allRemove,
};
};第三步:分别对 Diff 结果做 add 和 remove 操作
这一步中,我们通过 AntV/G 的 API 对 Canvas 对象树做操作,把格子实例化并添加/删除。实际的效果类似以下的动画演示(图中的 add 操作做了延迟处理,让效果更明显):
这个官网例子[7]展示了明细表在 100W 数据下流畅渲染的表现。
自定义列头
在我们的业务中,在数据的列头之外,还需要实现类似 Excel 的序号列头,就像这样: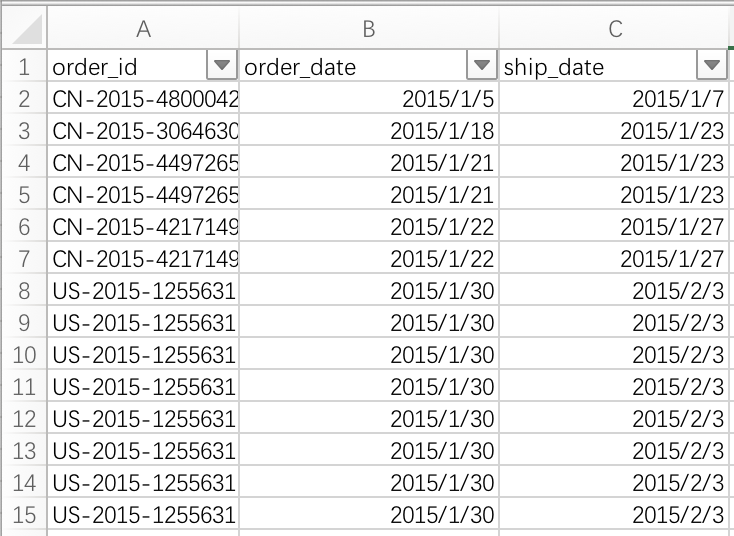

S2 的 Options 中提供了诸多 API 来自定义单元格的渲染: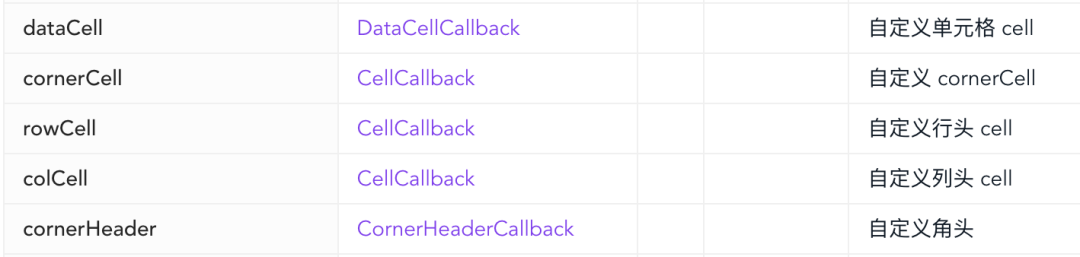
import { TableDataCell } from '@antv/s2';
class S2Cell extends TableDataCell {
private drawActionIcon() {
// 绘制逻辑,因为 TableDataCell 继承了 AntV/G 的 Group 对象
// 所以这里直接使用 addShape 这样的属性就可以做 Canvas 的绘制
}
}
export default S2Cell;在上述代码中,通过 S2 内置的 renderIcon 工具方法,来绘制 Icon,并且根据筛选和排序的状态来控制 Icon 的样式。同时还可以注册自定义的事件,来定义 Icon 点击时的行为。这些绘图 API 底层都是 AntV/G。所以在自定义 S2 的单元格时,我们只需要简单学习 G 的 API 就可以上手。
通过自定义角头,还可以实现类似 Excel 的三角形角头效果:
import { TableCornerCell } from '@antv/s2';
export default class CornerCell extends TableCornerCell {
protected drawTextShape() {
this.textShape = this.addShape('polygon', {
// 图形属性
});
}
}
布局
行列冻结
前端的表格一般都支持左侧或者右侧一定数量列的固定,比如 Antd。除了列的固定,基于 Canvas 的 SpreadJS[8],还支持行的固定。这也是 Excel 的常用功能之一:
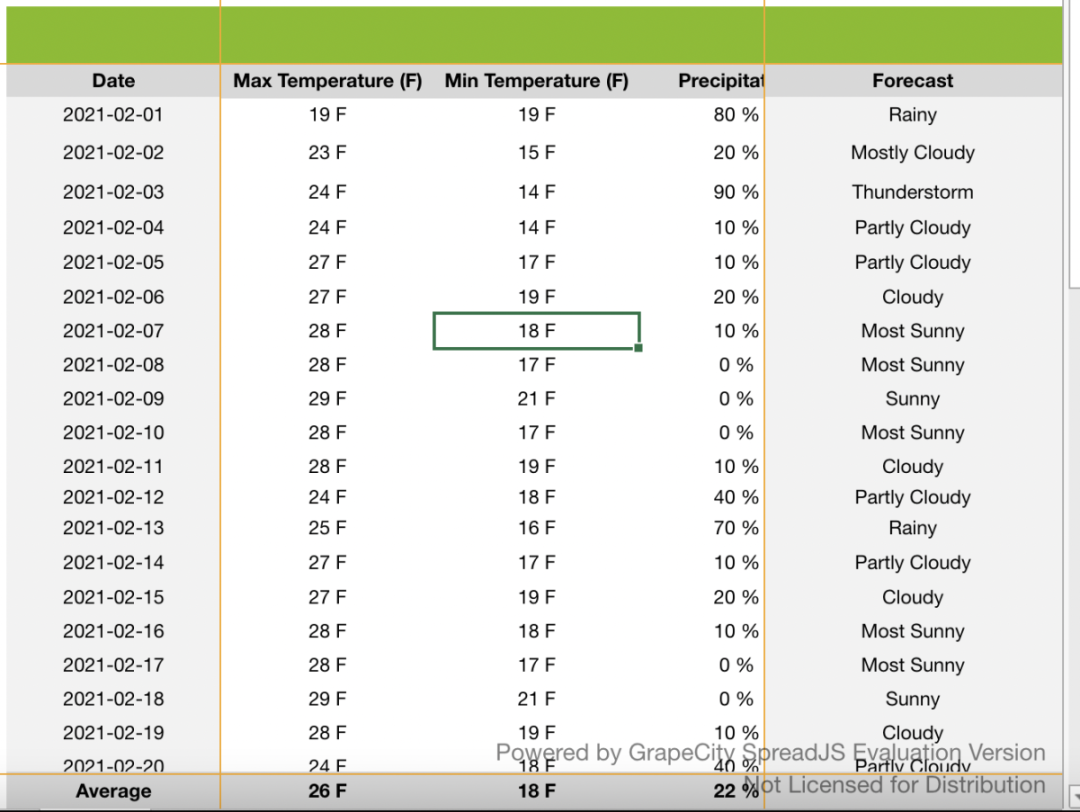
冻结的意思就是,不管表格的内容如何滚动,冻结的行始终显示在视图上方或者下方,冻结的列会始终显示在视图的左侧或者右侧,也就是说,冻结的行的 y 坐标在滚动时保持不变,冻结的列的 x 坐标在滚动时保持不变。
在 S2 中,我们可以通过设置这些 Options [9]实现行列冻结:
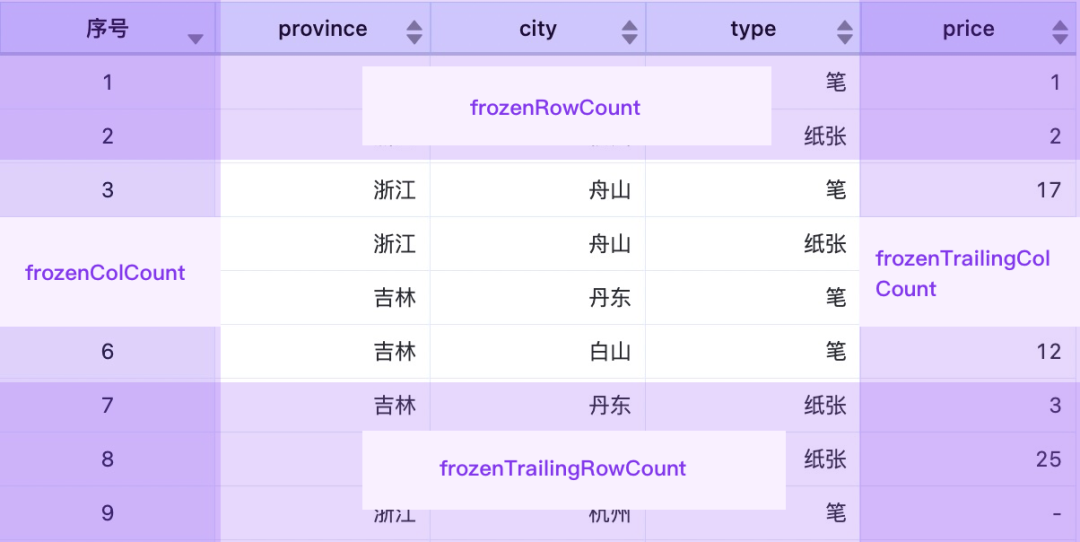
下面聊聊如何实现行列冻结,因为我们需要在滚动时对冻结的部分做特殊处理。所以首先需要对做明细表的内容区域做分组: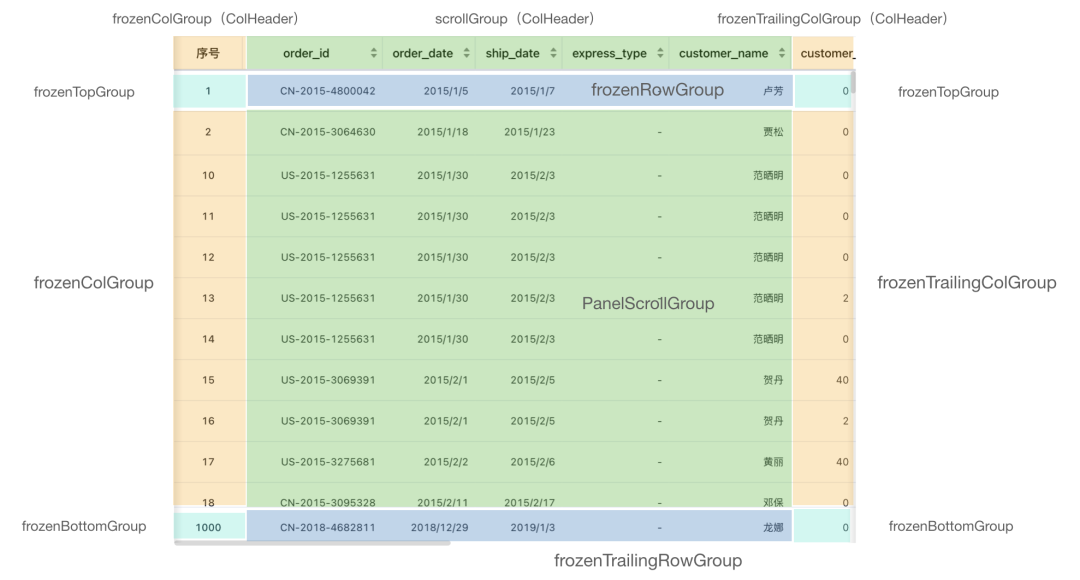
除了这几个常规的分组之外,我们还注意到,四个冻结分组在四个角上是有交叉的,这些交叉区域的格子,在 x、y 两个方向都不需要滚动,所以这些格子需要专门放到一个分组里,并做类似 postion: fixed 的特殊定位处理。对这些格子,我们放入 frozenTopGroup 和 frozenBottomGroup 两个分组。
同时,对于列的固定,不仅仅是数据格子需要固定,列头也要做固定。所以我们把列头区域也分为三个分组,分别是 frozenColGroup、scrollGroup 和 frozenTrailingColGroup。
所以接下去的思路是,首先在渲染时,确定格子属于哪个区域,然后加入对应的分组中。然后在 translate 时,对不同分组做不同的 translate 操作。比如固定列只需要在 y 方向上滚动,固定行只需要在 x 方向滚动。
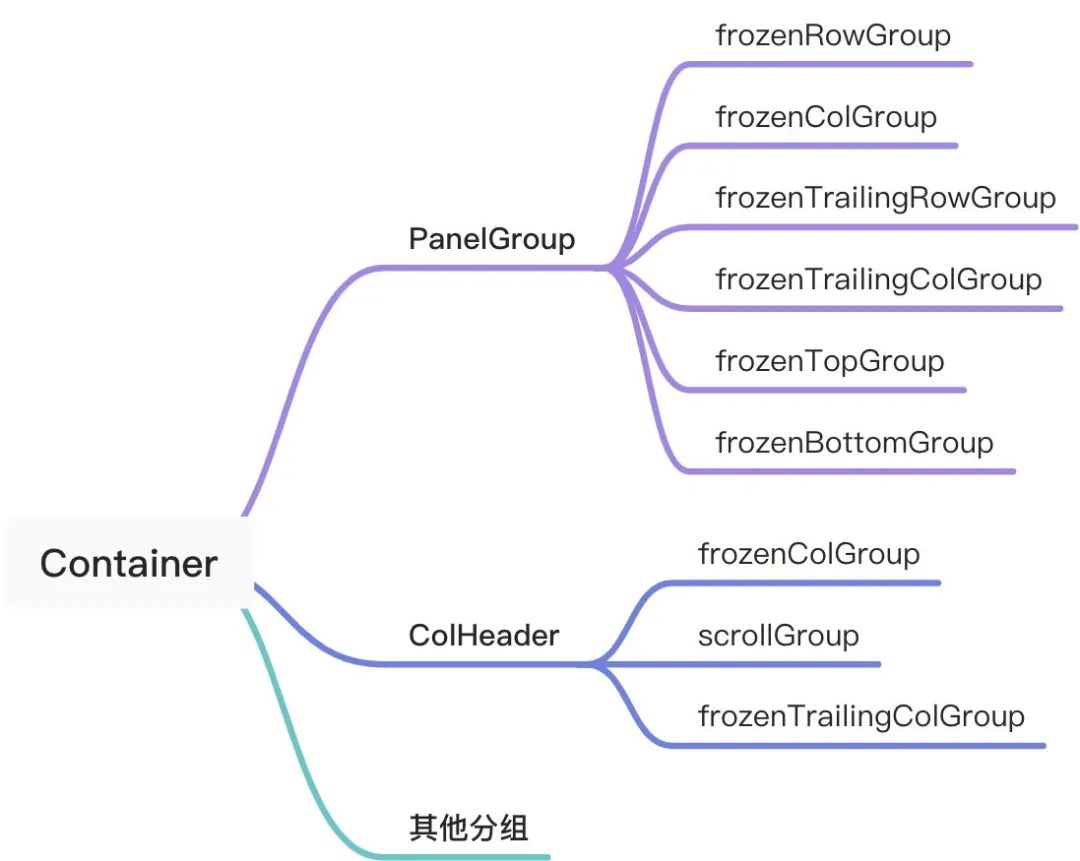
新分组概览接下来我们需要对渲染链路做改造:
第一步:渲染交叉冻结区域格子
对于交叉冻结区的格子,也就是四个角上的区域:frozenTopGroup/frozenBottomGroup 两个分组。这些格子在表的渲染周期中只需要添加一次,所以可以和 header 一样,在 S2 初始化的时候把节点插入即可。
第二步:计算可视区域格子坐标范围
S2 中用的是上文介绍的虚拟滚动,因此在渲染时会通过 scrollX 和 scrollY 计算出当前可视区域内的格子有哪些。之前内容区只有一个分组,计算出的格子坐标范围是这样的结构:-
export type Indexes = [number, number, number, number]; // x Min, x Max, y Min, y Max
坐标在这个矩形范围内的格子会被渲染。
在支持行列冻结之后,这段逻辑就需要做修改,不仅要计算出滚动区域的格子范围,还需要计算出 frozenRow、frozenCol、frozenTrailingRow、frozenTrailingCol 这四个冻结区域的格子范围。因为行列冻结区域是支持单向滚动的,所以也需要做虚拟滚动。可视区坐标计算结果需要改成如下结构:
export type PanelIndexes = {
center: Indexes;
frozenRow: Indexes;
frozenCol: Indexes;
frozenTrailingRow: Indexes;
frozenTrailingCol: Indexes;
};第三步:对格子分组渲染
这一步很简单,对于可视区的每个格子,判断格子属于那一个分组,然后把格子加入这个分组即可。
第四步:滚动时做 translate
在 translate 时,对于行列冻结的分组,需要做单向滚动。
- 其中 frozenRow、frozenTrailingRow 需要跟随 X 方向的滚动。
- 其中 frozenCol、frozenTrailingCol 需要跟随 Y 方向的滚动。
ColHeader 改造
和 Panel 区一致,ColHeader 也要做分组渲染改造。在 layout 时,把 ColHeader 分为 frozenColGroup(左侧固定列头),scrollGroup(非固定的普通列头),frozenTrailingColGroup(右侧固定列头)。然后在 ColHeader 做 offset 操作时,只对 scrollGroup 做偏移即可。
需要注意的是,列头是可以做 Resize 操作的。因此还绘制了 Resize 热区。对于冻结的列,我们也需要固定热区的绘制位置。所以对于冻结列的 Resizer,是需要专门画到一个分组里面的,类似列头格子的 scrollGroup。同时对于非冻结列的热区,要做一个 Clip 操作,防止热区溢出到冻结列的区域。
工具栏操作
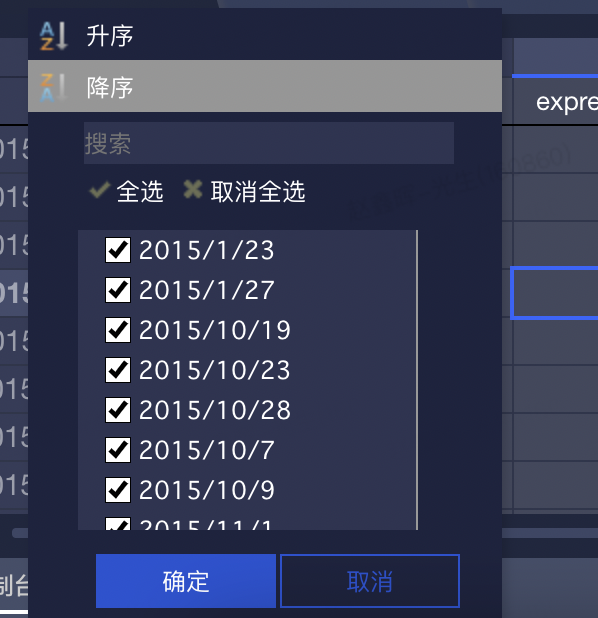
筛选 & 排序
筛选是用户使用的高频操作之一。目前我们已经实现的筛选模式有两种:数值筛选和表达式筛选。下面就分别聊聊两者的设计和实现:数值筛选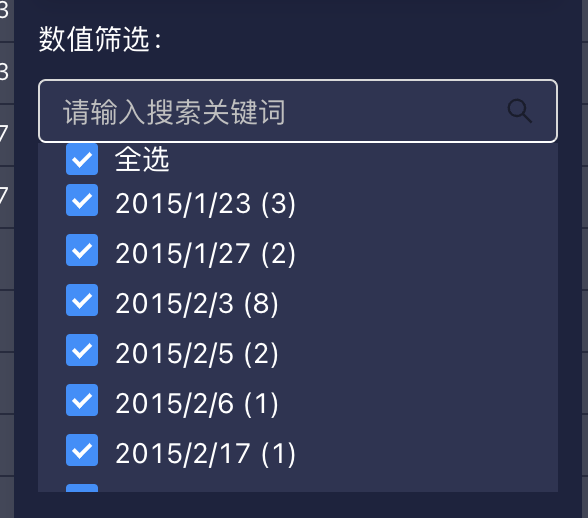
export interface FilterParam {
filterKey: string; // 要筛选的列的 key
filteredValues?: unknown[]; // 被筛选(去掉)的值
}在大数据表格中实现的主要是帮助用户可视化编辑要过滤的值。难点如下:
-
筛选细节逻辑对齐 Excel
-
搜索文本筛选:搜素框有筛选值时,点确定的时候以筛选框里的值为基数(不在筛选范围内的值会被全部过滤掉)。
-
筛选值联动:当其他列已经有筛选条件且当前项没有筛选条件的情况时,数值筛选的勾选框中会隐藏已经被其他行的筛选条件筛选掉的值。此时如果再做筛选,所有设置过筛选参数的列的筛选值会共同起作用。类似一个多级联动的筛选。
-
大数据量卡顿
-
因为 Checkbox 是采用 DOM 渲染的,而大数据表格组件会经常性的承载 1w+ 的数据量,导致用户在筛选时会卡顿,影响用户体验。解决方案是将数值筛选的 UI 组件整体做一层虚拟滚动,比如使用 react-virtualized。只渲染可视区域内的 DOM 元素。
表达式筛选
在表达式筛选中,支持用户通过配置表单的方式,使用由字段、操作符、数值构成的表达式做筛选。同时两个表达式可以通过 AND 和 OR 两种逻辑条件进行组合。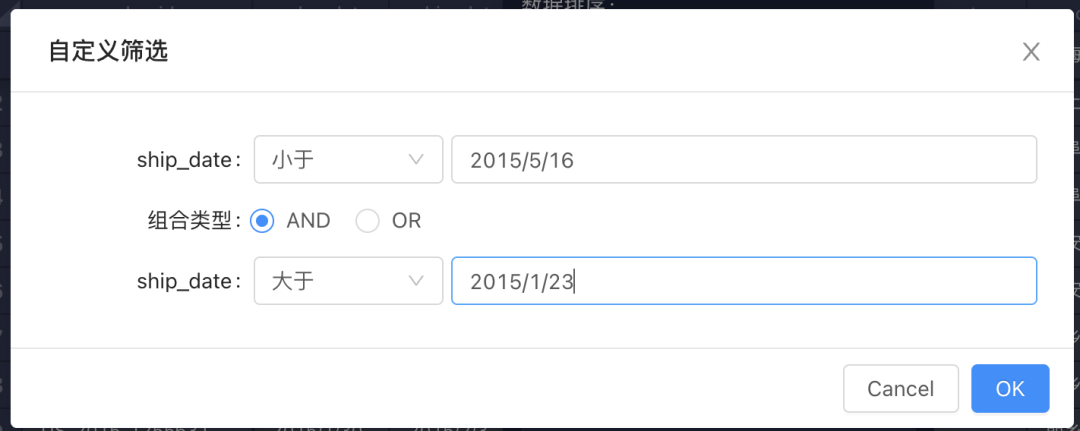
interface Serializable<T> {
// 序列化,支持从string重建方法
serialize(): ExpressionOf<T>;
}
// 组合类型
export enum JoinType {
OR = 'OR',
AND = 'AND',
}
// 一元运算符
type UnitExpressionOf<T> = {
key: FilterFunctionTypes;
operand: T;
};
// 二元运算符
type JoinExpressionOf<T> = {
type: JoinType;
funcA: ExpressionOf<T>;
funcB: ExpressionOf<T>;
};
export type ExpressionOf<T> = UnitExpressionOf<T> | JoinExpressionOf<T>;
export abstract class FilterFunction<T> implements Serializable<T>, Filterable {
filter(value: unknown): boolean {
throw new Error('Method not implemented.');
}
key: FilterFunctionTypes;
private _operand: T;
// 表达式另一侧的值:e.g., value > 2,则2是这个值
public get operand(): T {
return this._operand;
}
public set operand(value: T) {
if (isValidNumber(value)) this._operand = Number(value) as unknown as T;
else this._operand = value;
}
public serialize() {
return {
key: this.key,
operand: this.operand,
};
}
}
继承FilterFunction,实现.filter()方法,我们就获得了能在业务组件中使用的筛选表达式类型,并且支持任意原子能力的 AND 和 OR: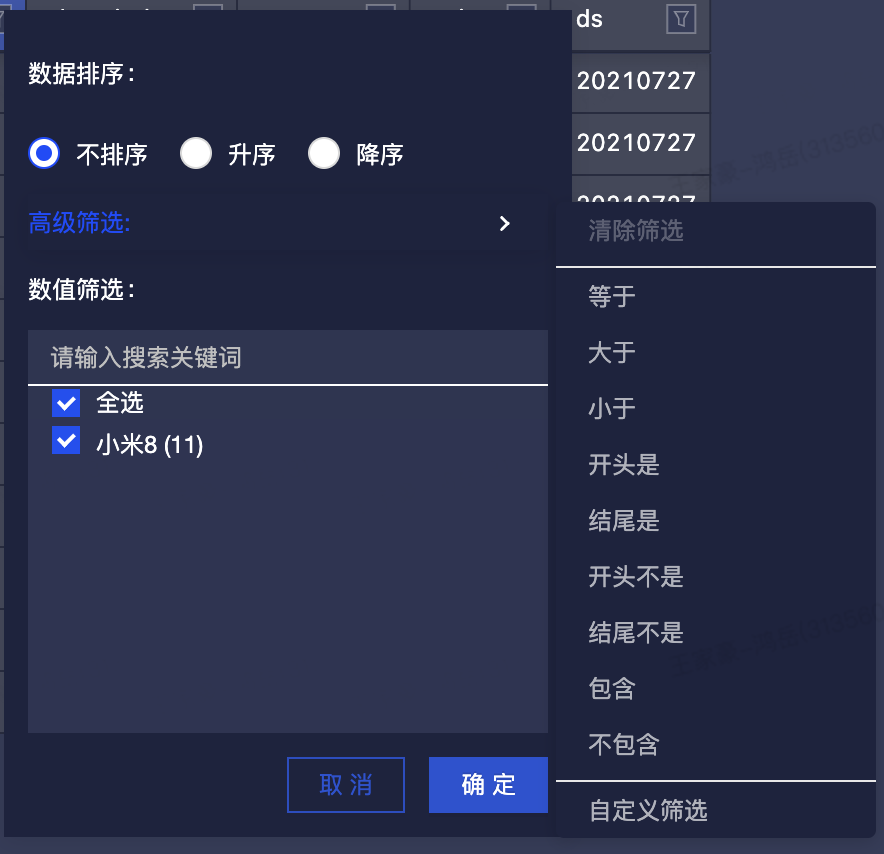
排序使用 S2 的 DataCfg 的 sortParams [10] 实现。
排序的实现和筛选基本类似,有一个需要注意的点:筛选可以在多个数据列中同时进行,而排序是排它的,因此在其他列已有排序的情况下设置当前列的排序,会导致其他列的排序条件被覆盖。
搜索
搜索的实现流程:
- 对数据集做遍历,找出所有匹配关键词的单元格
- 用户选择搜索结果,对下一个搜到的单元格做 Focus 操作
难点主要在 Focus 操作,需要把不在视口内的格子滚动进入视口内。比如这样: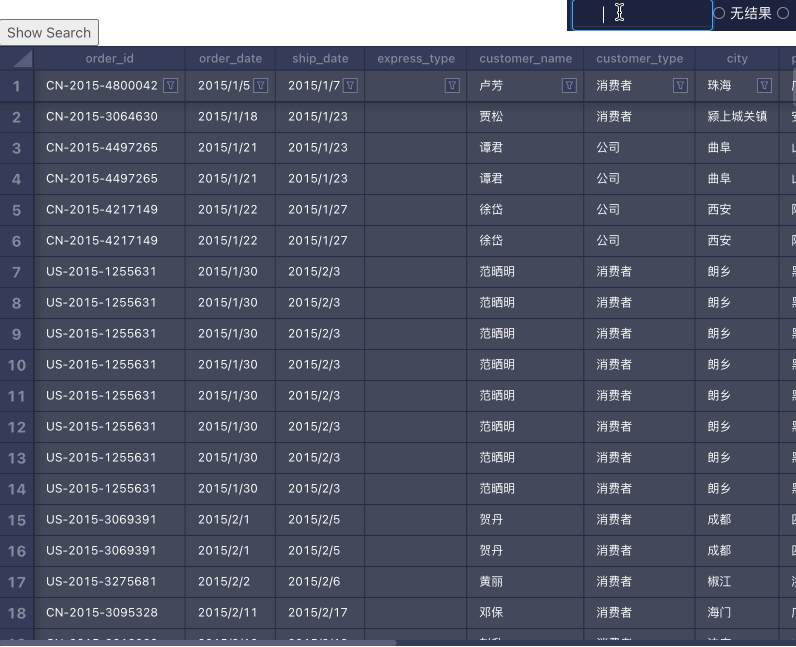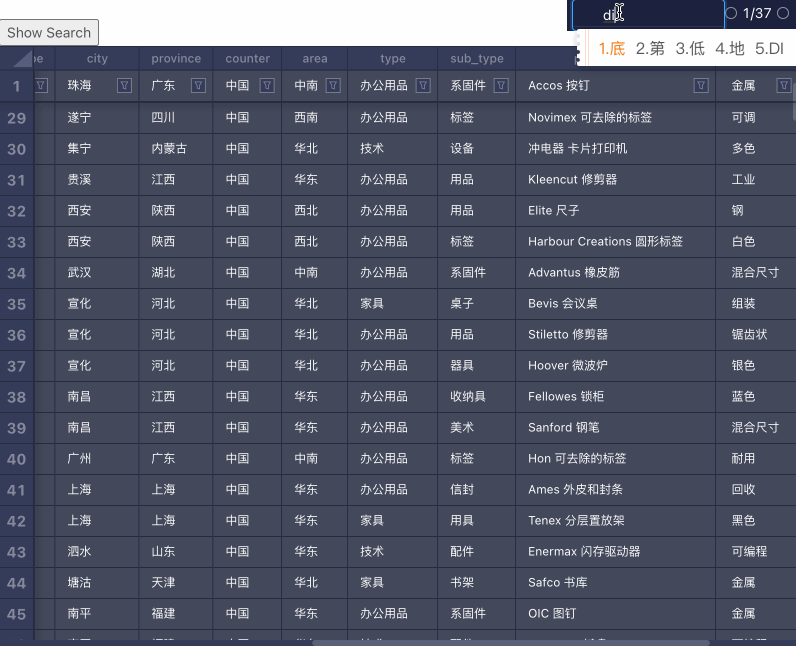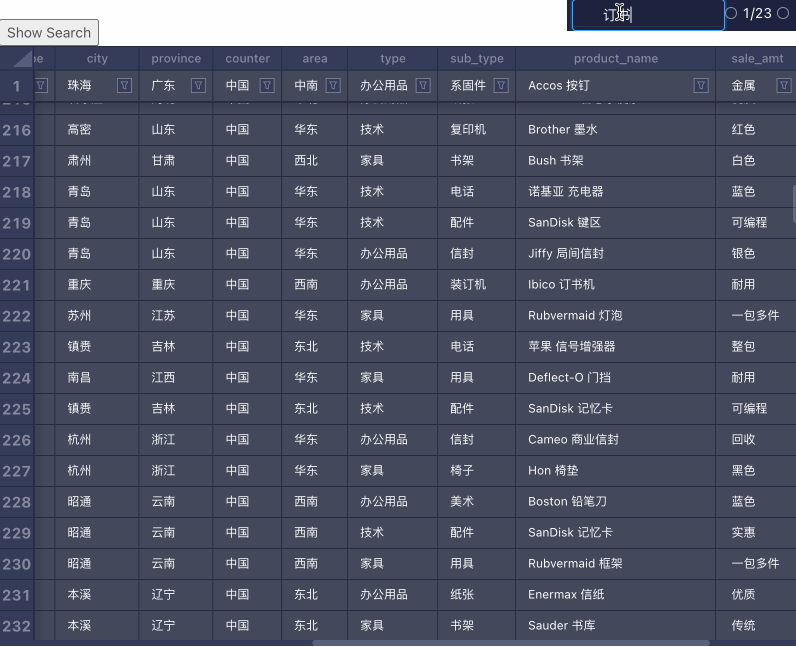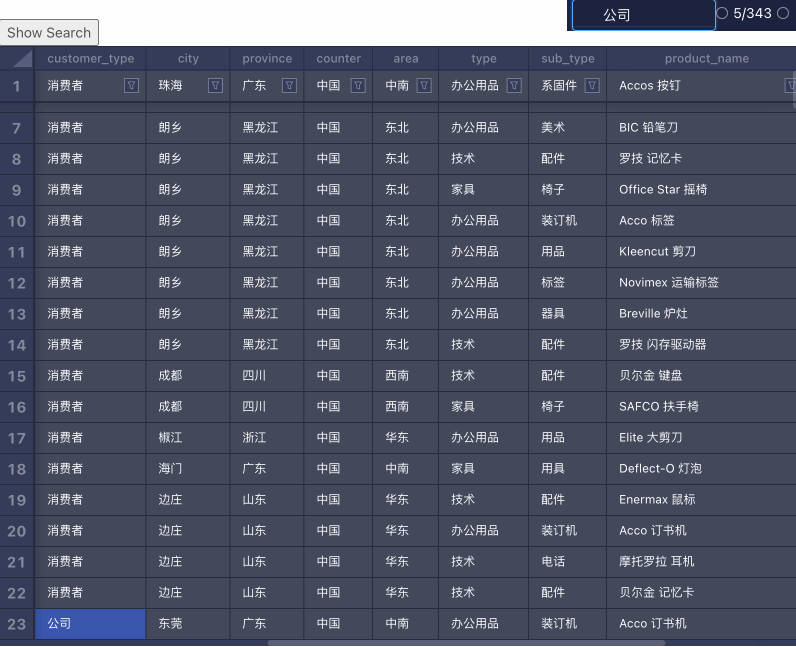
facet.scrollWithAnimation API。参数是滚动的 Offset。所以问题最终可以归结到如何计算滚动的 Offset,从而让格子进去视口内。
核心逻辑就是使用之前提到的 calculateInViewIndexes 拿到当前可视区域的范围。然后判断当前格子在 X 和 Y 两个方向上处于当前视口的哪个方向,并计算出相应的滚动 Offset。还有一点就是行列冻结区域的宽高需要从 Offset 中减去,这样才能让格子从行列冻结的区域之下“露”出来。
列展示控制
列展示控制可以让用户通过勾选的方式选择部分列做展示,有助于列数据较多时,让用户专注在当前关注的几列上: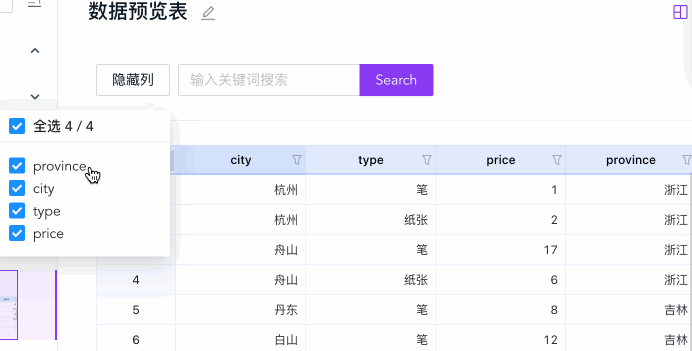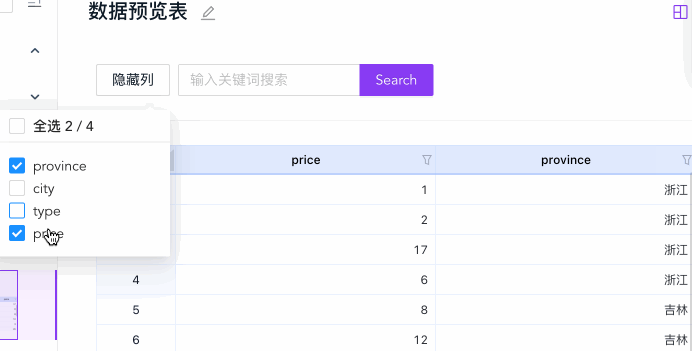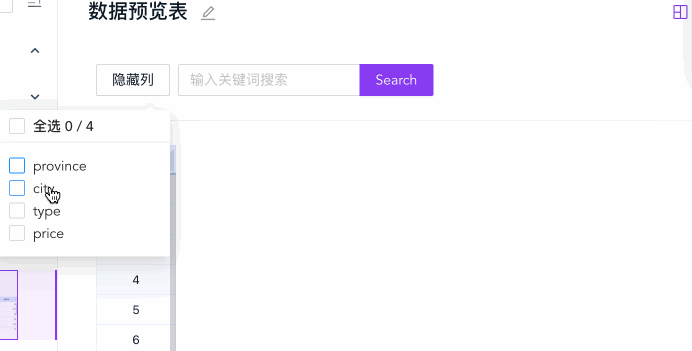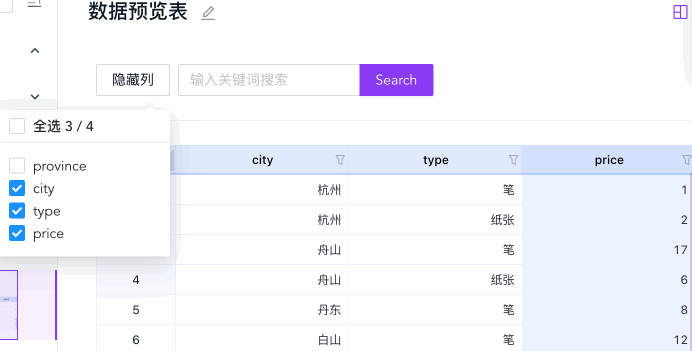
const hiddenCols = [] // 用户选择的要隐藏的列
const cols = [] // 所有的列
s2.setDataCfg({
fields: {
// 筛掉在 hiddenCols 数组中的列
columns: cols.map((col) => hiddenCols.indexOf(col) === -1)
}
})只要修改 hiddenCols 然后重新渲染,即可做到外部 UI 控制的隐藏列功能。
复制
S2 实现了页面表格到 Excel 的保留单元格的复制功能。下面聊聊实现这个功能要注意的一些点:
1 数据内容的获取
S2 使用虚拟滚动的模式,所以我们不能直接从 DataCell 实例上去获取数据。比如在整行整列选择的时候,不可见的区域内的 Cell 实际上都是未渲染的,也就不能从这里去获取数据。为了解决这个问题,我们对 S2 做了改造,在选中交互时,S2 提供的是 Cell Meta(Cell 的元数据,比如格子类型、行列 index)。在复制时,我们最终是通过 Cell Meta 从源数据中选出被选中格子的信息,再重新拼接成需要复制的内容。
2 数据内容的拼接
获取到数据内容后,我们需要把这些内容拼合在一起,使之符合表格复制的规范。我们知道剪切板中的数据最终是一个字符串,那 Excel 又是如何识别不同的单元格呢?
答案就是制表符'\t'和换行符 '\r\n' 。每一行的数据,通过换行符 '\r\n' 做区分。每行中每个格子的数据后,需要跟一个制表符'\t'。
有一个情况需要特别考虑,就是单元格内部的换行。行内和整体换行的标记都是 '\r\n' ,那么如何区别这两种情况呢?在实际操作时,只需要在单元格的内容外包一层双引号,告诉表格这是一个单元格里面的内容,那么就可以实现行内换行了。实际代码如下:
export const convertString = (v: string) => {
if (/\n/.test(v)) {
// 如果单元格内容里有换行符,在外面包一个引号
return '"' + v + '"';
}
return v;
};3 复制 API 的选择
之前主流的复制 API 是 document.execCommand('copy')。但这个 API 在数据量大的情况下(数万),会有卡顿的情况。所以在有条件的浏览器中,我们使用 navigator.clipboard API 做复制。工具函数 copyToClipboard 的大致逻辑如下:
export const copyToClipboard = (str: string, sync = false): Promise<void> => {
if (!navigator.clipboard || sync) {
return copyToClipboardByExecCommand(str);
}
return copyToClipboardByClipboard(str);
};
export const copyToClipboardByClipboard = (str: string): Promise<void> => {
return navigator.clipboard.writeText(str).catch(() => {
return copyToClipboardByExecCommand(str);
});
};
export const copyToClipboardByExecCommand = (str: string): Promise<void> => {
return new Promise((resolve, reject) => {
const textarea = document.createElement('textarea');
textarea.value = str;
document.body.appendChild(textarea);
textarea.focus();
textarea.select();
const success = document.execCommand('copy');
document.body.removeChild(textarea);
if (success) {
resolve();
} else {
reject();
}
});
};成果:成倍性能提升、完美自定义 UI ,顺利替换商业表格产品
上面我们介绍了如何基于 AntV/S2 实现全功能大数据表格。现在来看看这个新的表格解决了哪些问题。之前我们的线上的大数据表格使用 SpreadJS(v13),存在着以下的问题:
基于 SpreadJS 的老组件的问题
1. 内置组件样式定制难
SpreadJS 的内置筛选、排序等 UI 组件是原生 JS 编写的。无法使用 React 组件做拓展或者替换。也无法定制 DOM 结构。所以内置的图标、布局都很难修改。基本是一锤子买卖。同时 Modal 出现的位置也无法定制,限制在表格内部,经常会出现遮挡表格内容的情况。
2. 单元格渲染定制难
SpreadJS 的单元格理论上可以拓展,但是只能使用 Canvas 原生的 API 去绘制。并且缺少文档和源码支持。整体来说渲染定制非常困难。比如加一个脱敏的 icon,就需要耗费数天时间,并且实现比较勉强。
3. 使用复杂,经常有未知的 Bug
SpreadJS 和 React 一起使用时,是需要自行封装 React 组件的。这就是额外的成本。同时在使用过程中我们也发现了一些偶发的渲染异常,但没有完整源码,所以排查比较困难。
4. 体量大,数据模型复杂,导致性能较差
同时打开 10 个数据结果 Tab(10 个表格实例),每个展示 1000 条数据。此时切换有明显的卡顿。切换时间大致在 500ms 左右。用户感知明显。
在大数据量场景下,预览用户上传的 5万条数据文件,SpreadJS 需要加载 8 秒时间才能正常展示。
基于 S2 的大数据表格如何应对这些问题
拓展性 & 组件化:解决内置组件样式定制 & 单元格渲染定制和上手难问题
利用 S2 内置的筛选和排序等 API,还有自定义单元格渲染的能力,我们只需要封装 React 组件,就可以自由的定制组件的 UI。比如在业务中,我们使用了 Antd 作为 UI 基础库,来封装符合业务风格的筛选 & 排序 Modal。我们可以借助 Antd 的能力,而不用重复建设 Modal 能力。同时 Modal 的整体的布局和内容都是自定义的,有着很大的自由度: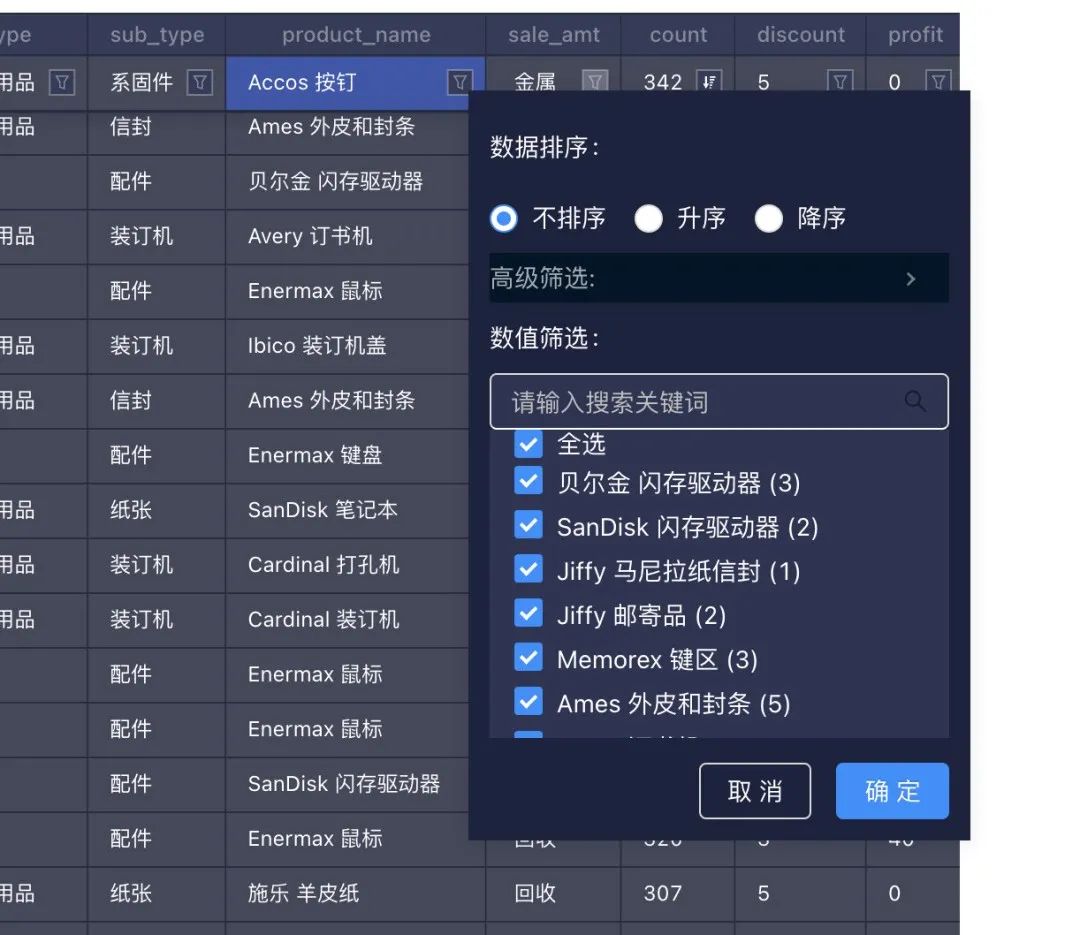
开源 & 自研:解决疑难杂症
在商业软件中,我们很难在购买到的编译混淆后的代码中做 Debug。而在开源软件中,有源码在手,一切疑难问题都不是问题,都可以看源码,排查问题得到解决。同时借助开源社区的力量,Bug 也会很快得到修复。经过一段时间的进化和磨练之后,S2 会变的更加强大和完善。
轻量级数据模型 & 虚拟滚动:解决大数据量下性能问题
S2 定位是一个轻量级的表格渲染核心,所以没有 Excel/SpreadJS 那样复杂的功能和数据模型。在大数据表格组件这个场景下,其实不需要那么重的数据模型,S2 的轻量级设计是更合适的。在性能表现上,10 个Tab 切换时,切换耗时为 80ms,是老方案的 6倍。在 5 万条数据的情况下,S2 渲染和初始化只需要 1秒。是老方案的 8 倍。
同时 S2 也可以根据实际情况做拓展,未来我们也会推出基于 S2 的类 Excel 电子表格场景组件,提供插件化、场景化的能力,用户可以按需使用,也可以通过插件化的方式引入公式等等高级功能。
结语
感谢你看到了这里,关于如何使用 AntV/S2 打造大数据表格组件的故事已经讲完了。但 AntV/S2 才刚刚起步。接下来我们会把大数据表格场景的单元格编辑、搜索、高级排序等等能力沉淀到 s2-react 中,让整个社区都可以使用到。同时也会继续加强 S2 明细表的底层能力。支持多层级列头、聚合计算等能力,对大分辨率下的渲染性能做优化。也欢迎社区的同学和我们一起共建 AntV/S2,打造最强的开源大数据表格引擎。
S2 的相关链接:
- Github:https://github.com/antvis/s2
- 官网:https://s2.antv.vision/
- 核心层: @antv/s2 V1.11.0:https://www.npmjs.com/package/@antv/s2
- 组件层: @antv/s2-react V1.11.0:https://www.npmjs.com/package/@antv/s2-react
[1] https://www.grapecity.com/spreadjs
[2] https://github.com/mengshukeji/Luckysheet
[3] https://github.com/myliang/x-spreadsheet
[4] https://handsontable.com/
[5] https://s2.antv.vision/zh/docs/manual/basic/sheet-type/table-mode
[6] https://github.com/dwqs/blog/issues/70
[7] https://s2.antv.vision/zh/examples/case/performance-compare#table
[8] https://www.grapecity.com/spreadjs/demos/features/worksheet/frozenline-viewport/purejs
[9] https://s2.antv.vision/zh/docs/manual/basic/sheet-type/table-mode#%E8%A1%8C%E5%88%97%E5%86%BB%E7%BB%93
[10] https://s2.antv.vision/zh/docs/api/general/S2DataConfig#sortparams
有点意思,那就点个关注呗 ♀️