InnoDB原理篇:如何用好索引
前言
上一篇文章【[InnoDB原理篇:为什么使用索引会变快?] 】聊了下索引为什么快。
现在聊聊,我们如何用好索引
InnoDB中索引分类
我们都知道InnoDB索引结构是B+树组织的,但是根据数据存储形式不同可以分为两类,分别是聚簇索引与二级索引。
ps:有些同学还听过非聚簇索引和辅助索引,其他它们都是一个意思,本文统一称为二级索引。
聚簇索引
聚簇索引默认是由主键构成,如果没有定义主键,InnoDB会选择非空的唯一索引代替,还是没有的话,InnoDB会隐式的定义一个主键来作为聚簇索引。
其实聚簇索引的本质就是主键索引。
因为每张表只能拥有一个主键字段,所以每张表只有一个聚簇索引。
另外聚簇索引还有一个特点,表的数据和主键是一起存储的,它的叶子节点存放的是整张表的行数据(树的最后一层),叶子节点又称为数据页。
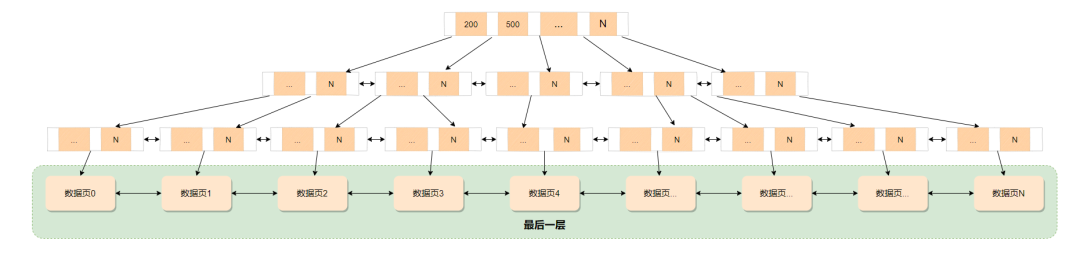
如果这里无法理解的话,可以去补下阿星的前两篇文章
- [InnoDB原理篇:聊聊数据页变成索引这件事]
- [InnoDB原理篇:为什么使用索引会变快?]
二级索引
知道了聚簇索引,再来看看二级索引是什么,简单概括,除主键索引以外的索引,都是二级索引,像我们平时建立的联合索引、前缀索引、唯一索引等。
二级索引的叶子节点存储的是索引值+主键id。
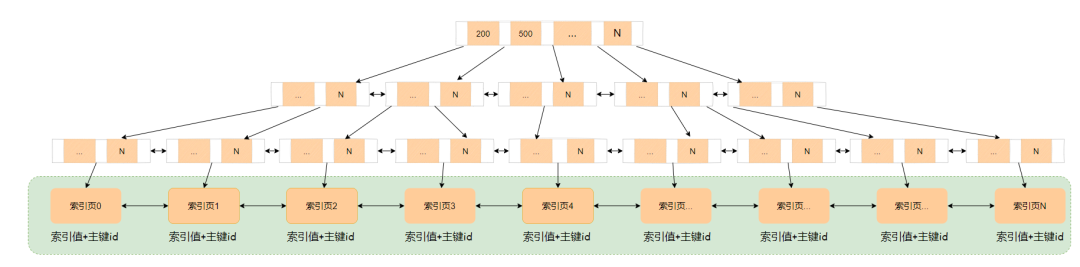
也就意味着,仅仅靠二级索引无法拿到完整行数据,只能拿到id信息。
那二级索引应该如何拿到完整行数据呢?
索引的查询
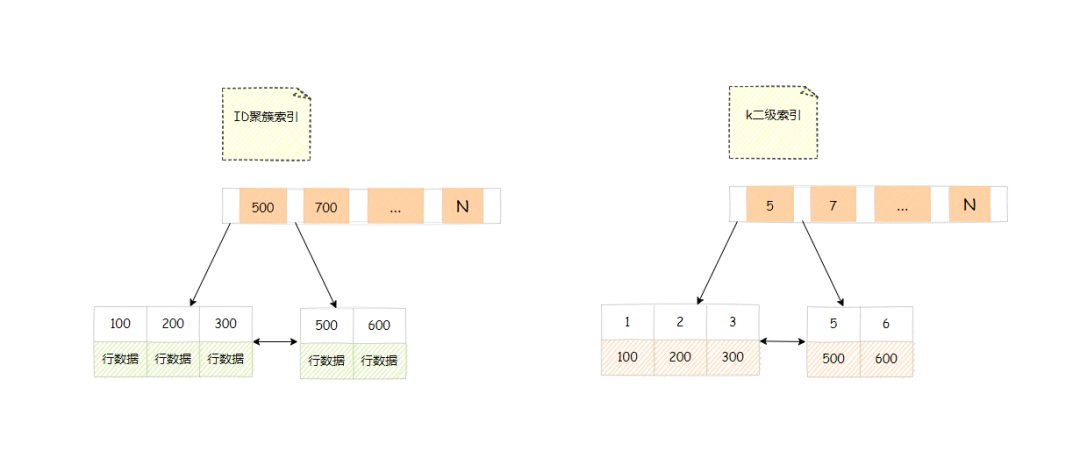
假设,我们有一个主键列为id的表,表中有字段k,k上有索引。这个表的建表语句是:
create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;表中有5条记录(id,k),值分别为(100,1)、(200,2)、(300,3)、(500,5)、(600,6),此时会有两棵树,分别是主键id的聚簇索引和字段k的二级索引,简化的树结构图如下
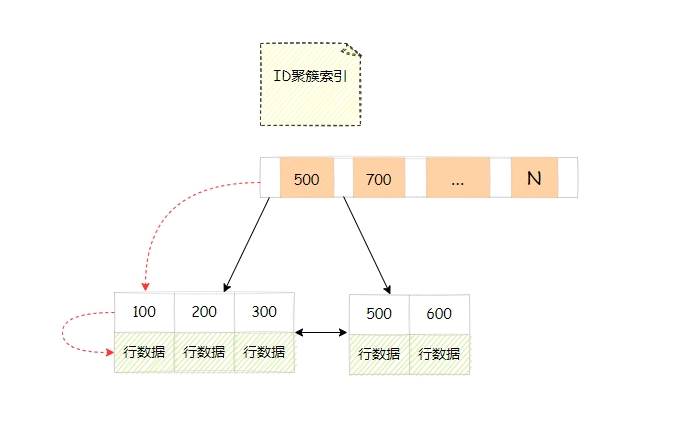
回表
我们执行一条主键查询语句select * from T where id = 100,只需要搜索id聚簇索引树就能查询整行数据。
select * from T where k = 1,此时要搜索k的二级索引树,具体过程如下
- 在 k 索引树上找 k = 1的记录,取得 id = 100
- 再到聚簇索引树查 id = 100 对应的行数据
- 回到 k 索引树取下一个值 k = 2,不满足条件,循环结束
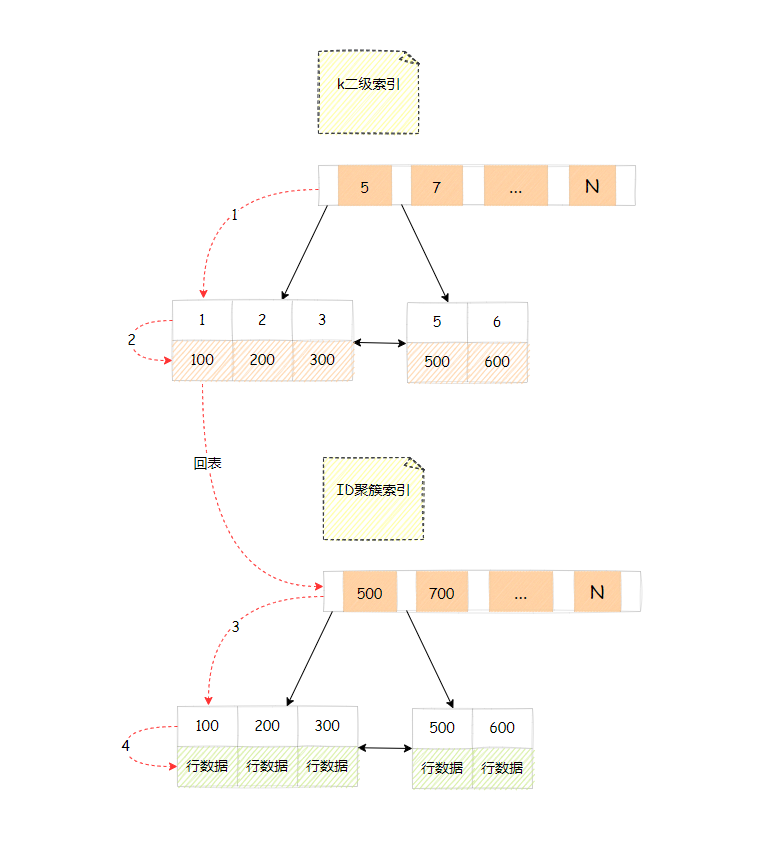
也就是说,基于二级索引的查询需要多扫描一棵聚簇索引树,因此在开发中尽量使用主键查询。
索引覆盖
可是有时候我们确实需要使用二级索引查询,有没有办法避免回表呢?
办法是有的,但需要结合业务场景来使用,比如本次查询只返回id值,查询语句可以这样写select id from T where k = 1,过程如下
- 在 k 索引树上找 k = 1的记录,取得 id = 100
- 返回 id 值
- 回到 k 索引树取下一个值 k = 2,不满足条件,循环结束
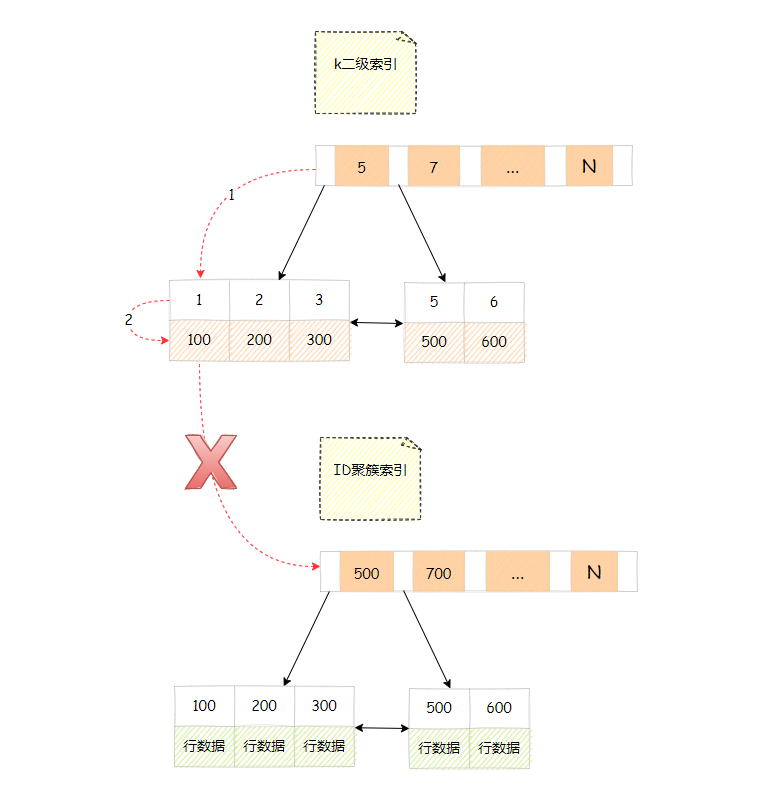
在这个查询中,索引k已经覆盖了我们的查询需求,不需要回表,这个操作称为覆盖索引。
由于覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
假设现在有一个高频的业务场景,根据k查询,返回name,我们可以把k索引变更成k与name的联合索引。
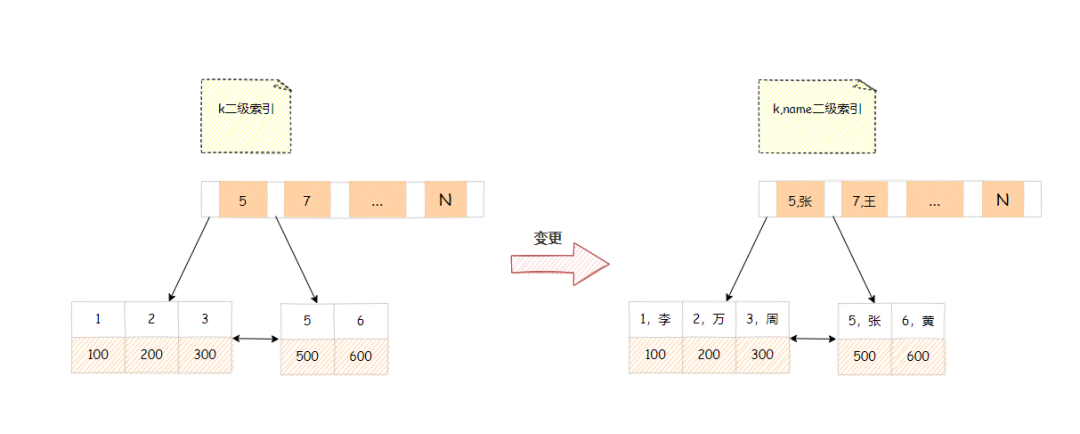
ps:设计索引时,请遵守最左原则匹配
索引下推
此时我们再建立一个name与k的联合索引。
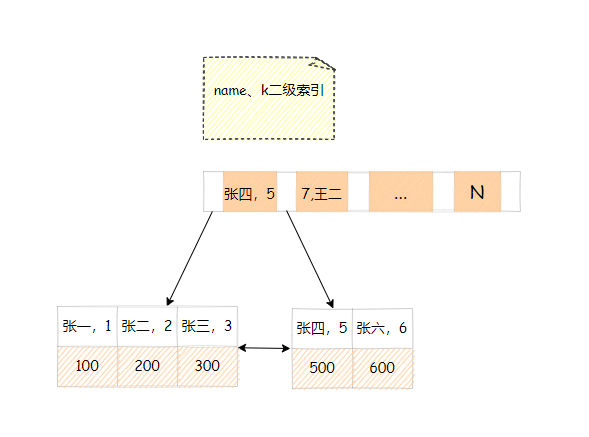
select k from T where name like '张%' and k = 2语句。
首先会在name与k树中用张找到第一条件满足条件的记录id = 100,然后从id = 100开始遍历一个个回表,到主键索引上找出行记录,再对比k字段值,是不是十分操蛋。
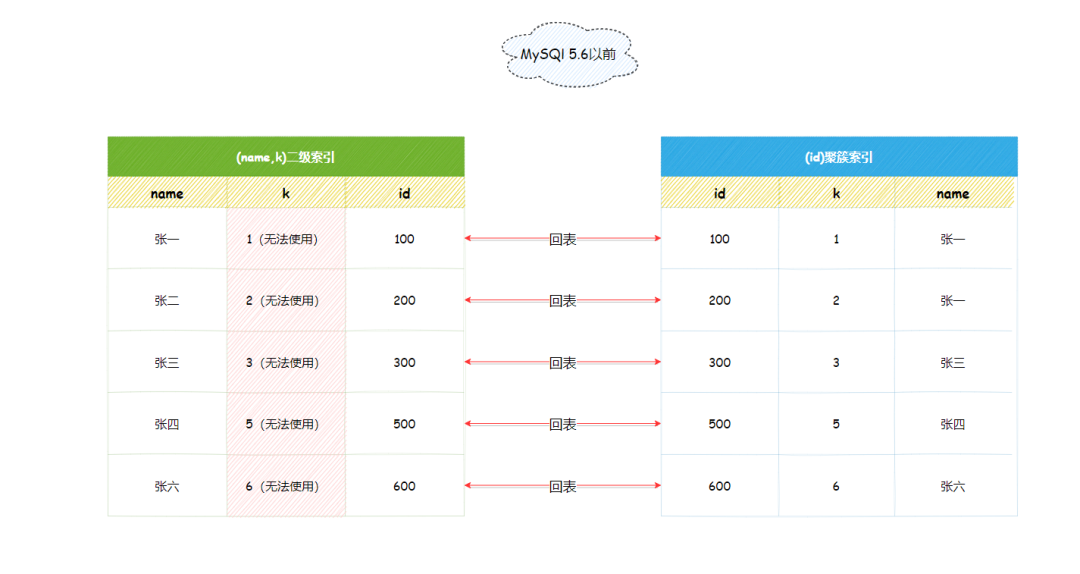
可以看到总共回表了6次
不过在MySQL 5.6版本引入的索引下推,可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
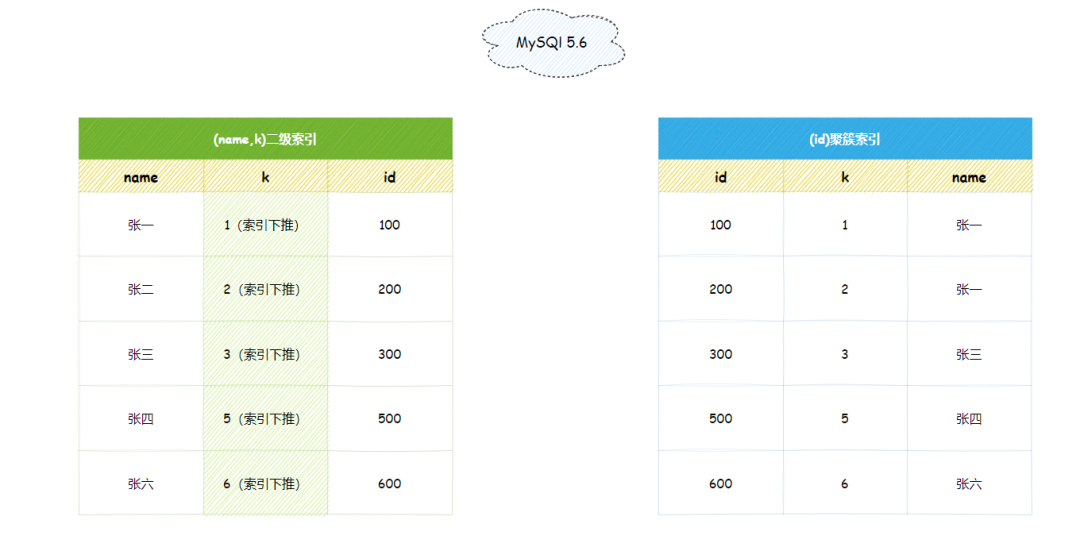
0次。
小结
本篇文章到这里就结束了,今天和大家聊了聚簇索引、二级索引、回表、覆盖索引、索引下推等知识,可以看到,在满足语句需求的情况下,尽量少地访问资源是数据库设计的重要原则之一,由于篇幅有限,很多内容还没展开,后续阿星会和大家聊聊如何设计索引。