当eBPF遇上Linux内核网络
大家好, 今天给大家分享的主题是《当eBPF遇上Linux内核网络》
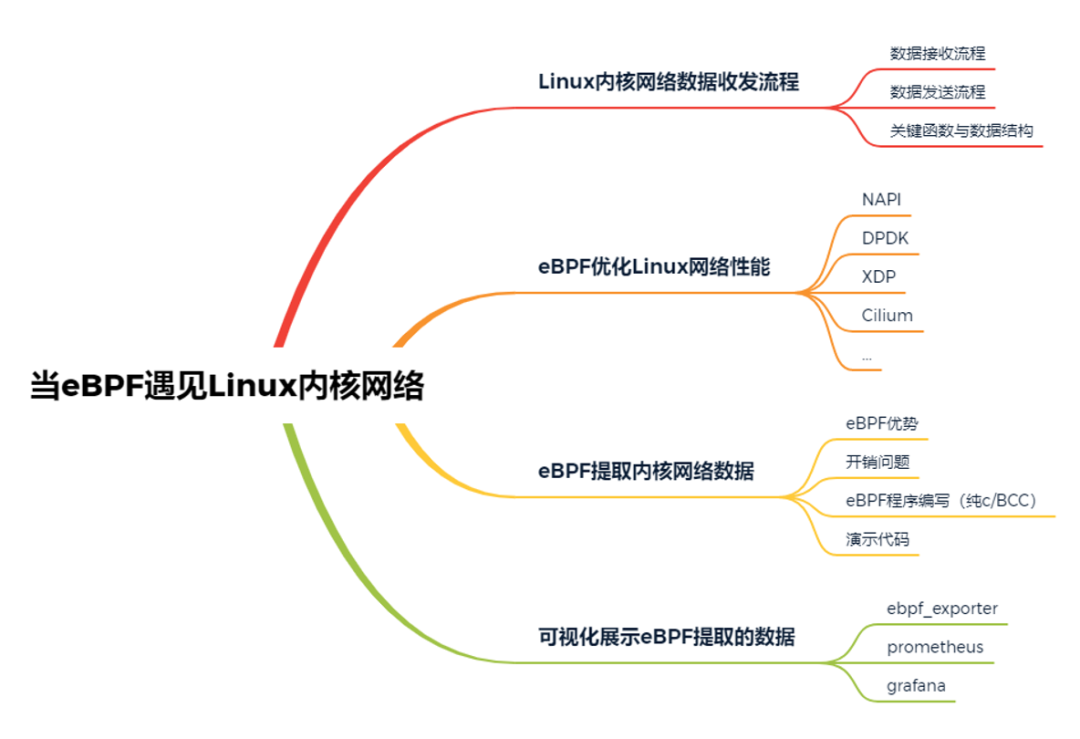
主要有四部分:
- Linux内核网络数据的收发流程
- eBPF优化Linux内核网络
- eBPF提取内核网络数据
- 可视化展示eBPF提取的数据
视频讲解链接:https://www.bilibili.com/video/BV1ch411U75f?spm_id_from=333.999.0.0
Linux内核网络数据收发流程
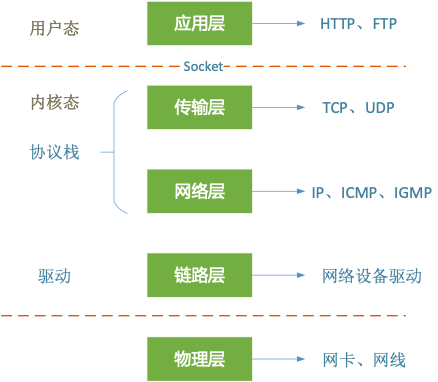
我们经常说的TCP/IP五层模型从上层到下层依次是应用层、传输层、网络层、链路层和物理层。其中应用层主要负责为应用进程提供服务,传输层主要负责实现端到端的数据传输,网络层主要负责数据报路由以及把分组报文发送到目标网络或者主机,链路层主要负责跨物理层在网段节点之间传输数据。
在Linux中主要对网络传输层、网络层和链路层进行了实现。传输层 网络层统称为协议层,链路层主要由网络设备驱动实现。
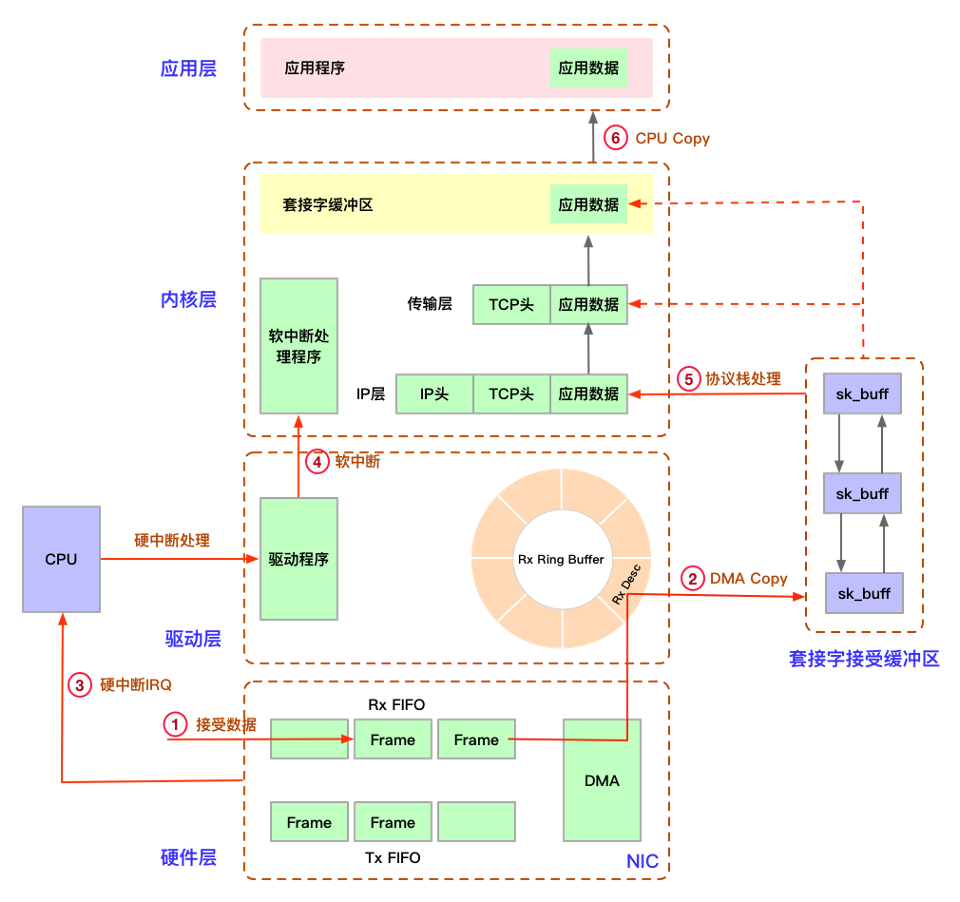
Linux网络接收数据包流程
在Linux内核中当数据包到达网卡的时候,通过DMA方式将数据映射到内存。然后硬中断通知CPU有数据到来,调用硬中断处理函数,之后交给软中断去处理。通过ksoftirq调用软中断处理函数,收包的软中断处理函数是net_rx_action函数,主要将Ring Buffer缓冲区数据做成sk_buff送给上层协议栈进行处理,之后数据包经过层层解包最终将数据放入套接字缓冲区中,CPU通过将数据拷贝给应用程序。
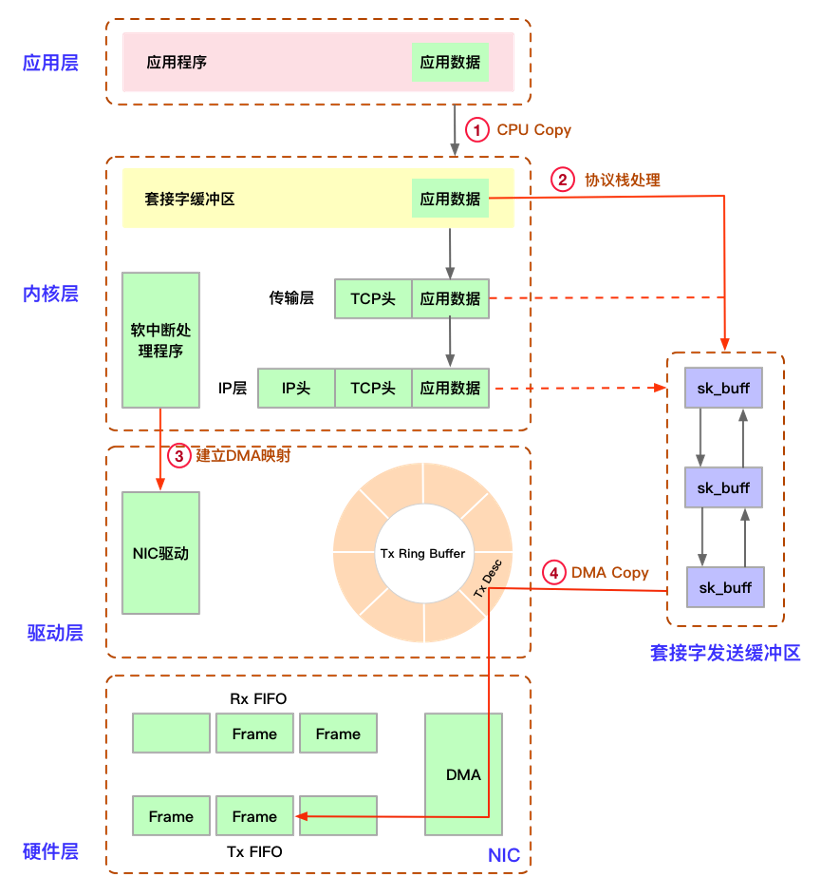
Linux网络接收数据包流程
首先,应用层应用程序通过CPU将数据拷贝到套接字缓冲区,然后数据包经过层层处理封装好数据包,经过软中断处理函数,通过建立dma映射,将数据放到发送缓冲区中,最后经过一个物理的网卡发送出去。
eBPF优化Linux网络性能
传统优化技术
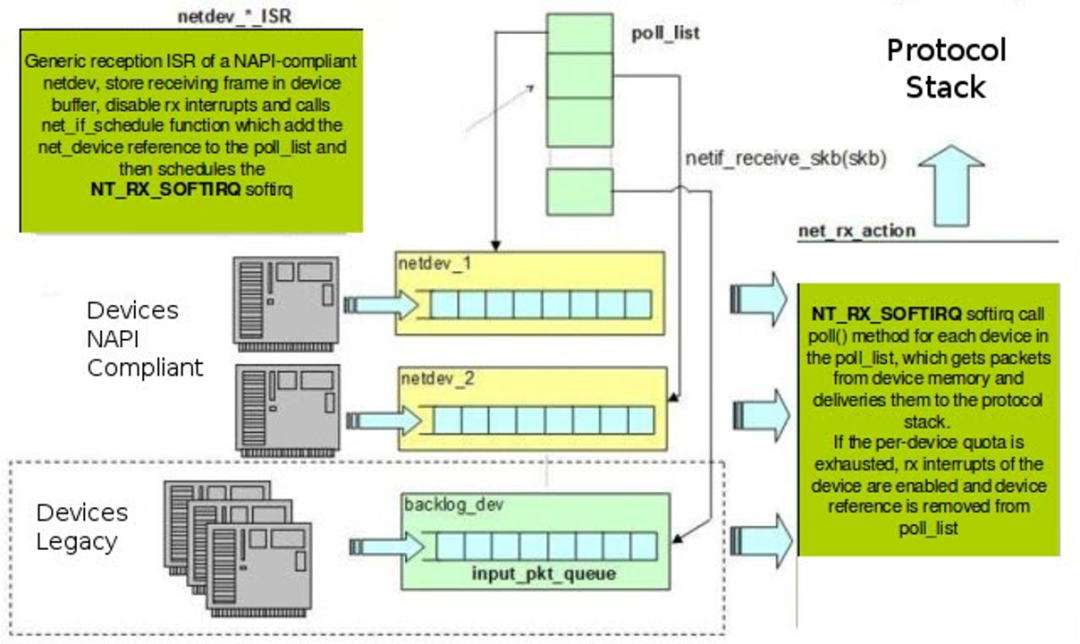
NAPI
当数据包到达网卡的时候产生中断,驱动程序通知网络子系统有新的数据包到来,这时不是立即去处理,而是以轮询方式进行处理。
在NAPI中有pool方法来一次性接收多个数据。驱动程序不再使用数据包接收队列,而是网卡本身维护用来保存接收数据的缓冲区,并且可以禁止中断。该方法减少了中断产生,在突发的情况下,减少丢包的可能性,避免了接收队列的饱和,进而提高了网络性能。
GRO、RSS、RPS、XPS、RFS
GRO是在接收数据包的时候通过合并足够类似的包来减少传送给网络栈的包数,即将接收到的一些很小的包合并为一个大包送到协议栈,进而来减少cpu的使用量提高性能。
RSS是一种高效的网卡驱动技术。他能够在多处理器的系统下使接收报文在多个cpu之间高效的分发,相当于cpu收包的负载均衡。
RPS是SS的软件实现,使用软件的方法实现接收的报文在CPU之间平均分配,利用报文的哈希值找到匹配的CPU将报文送到对应CPU对应的backlog队列进行下一步的处理。
XPS相较于RPS,它是软件支持的发送数据包的多对列。XPS软件主要支持发送数据。
RFS的目标是通过指派处理报文程序所在的CPU。来在内核中处理报文,那么用方式来增加CPU的缓存命中率。
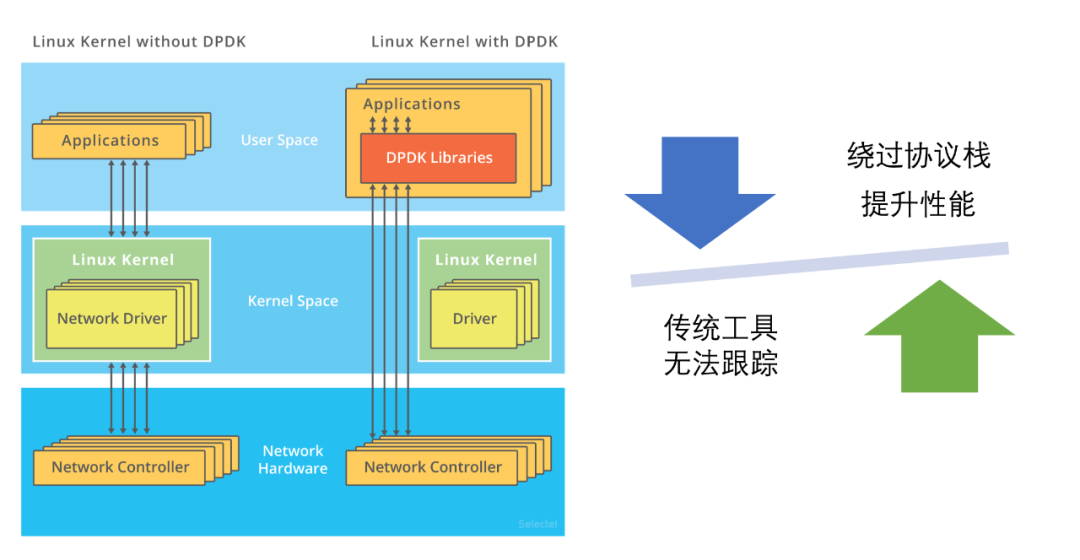
DPDK
如果在内核中没有DPDK,那么用户态收发数据就将数据放到内核协议栈经过一系列的处理,再到物理层网卡进行发送和接收数据。
DPDK用户态进行了实现,在用户态有DPDK的库。它实现了内核里面的协议站的功能,这时候就可以在用户态直接进行处理,将数据包处理好,直接放到物理层将数据发送出去。实际上就是将内核协议栈进行了短路,进而提高了网络性能。
优点:绕过了内核协议栈,提升了性能。
缺点:因为不走内核协议栈,传统的工具没法跟踪传统工具。
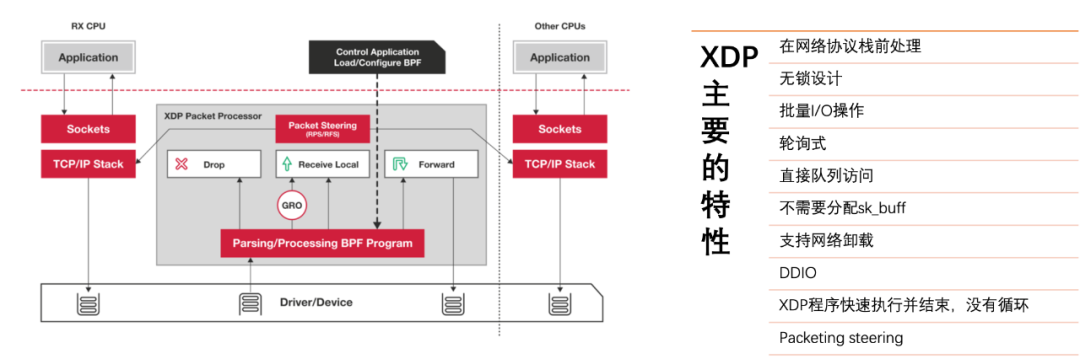
XDP
XDP为Linux内核提供了高性能可编程的网络数据路径。XDP需要网卡支持的,如果网卡支持那么网卡驱动程序里面有内置的bpf钩子,它可以访问原始的网络数据帧,直接告诉网卡对数据包的下一步操作。这么做避免了TCP/IP协议栈处理产生的额外消耗,通过驱动层做相关工作来提升性能。
XDP VS DPDK

XDP应用场景非常丰富,常见的有DDoS防御、负载均衡、SDR、网络统计、防火墙等。
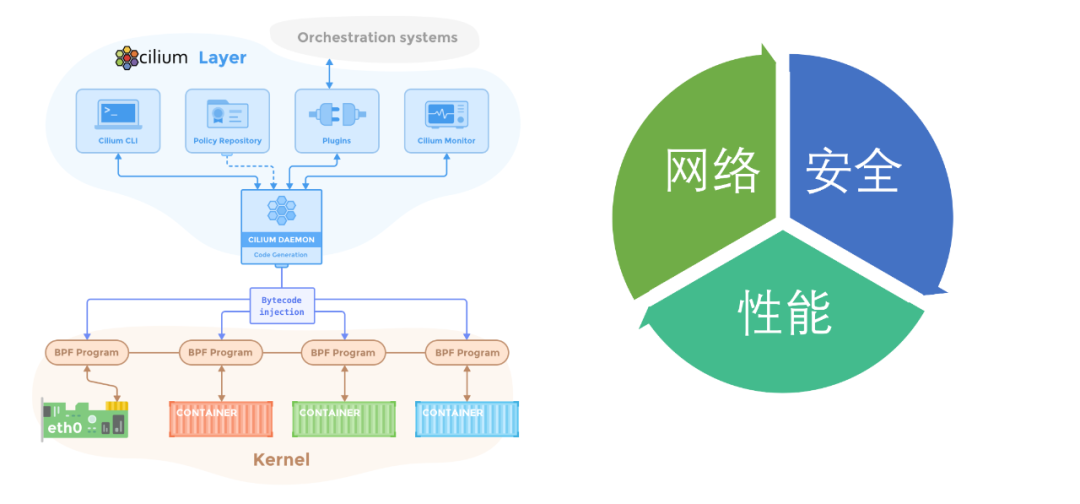
XDP应用Cilium
它是基于eBPF的开源项目。其目的是为了微服务环境提供网络负载均衡安全功能。他主要的场景是在微服务、容器中。
在网络方面,可以用Cilium来作为容器的网络方案。以k8s集群为例,南北向流量就指当外部网络如果要访问k8s集群的时候就通过Ingress来访问。如果说是在集群内部,有很多Node节点节点,每个节点里面有很多个Pod,每个Pod有很多个容器。那么他们整个集群里面进行互相访问和互联互通的网络流量,我们就成为东西向的流量。
k8s并没有去实现网络,而是定义了模型。各大厂商就自己去做了网络的CNI插件。比如说Cilium它可以作为网络的CNI插件,它可以实现在集群内部Node与Node之间,Pod与Pod之间,容器与容器之间,或者不同的pod不同的Node之间的网络访问。
对于安全方面,它是基于Identity做的安全,传统的安全基于ip+port,而Cilium给服务指定了Identity允许Service Lable来定义安全策略。
最后Cilium还可以做监控,在集群里部署Cilium的CNI插件就可以监控整个集群。
CIlium性能
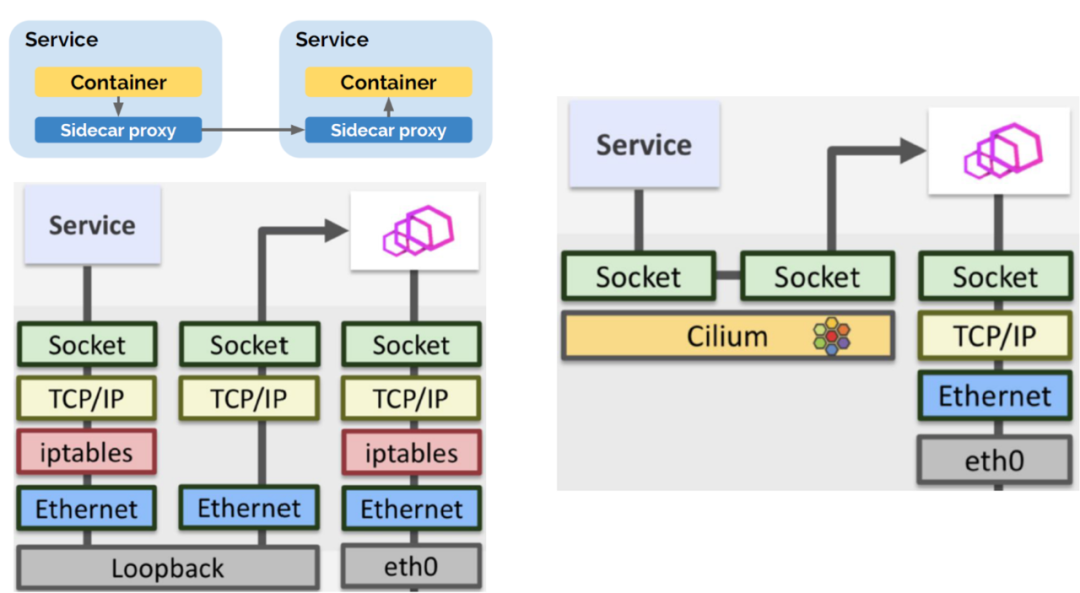
下图左边为传统网络,右边Cilium。
在传统的网络方案中,两个微服务之间要通信的话会经过Sidecar Poxy代理,他的数据走向看起来很短,实际上他走了完整的协议栈,而且在协议栈中还有iptables它里面维护了大量的规则,非常损耗性能。
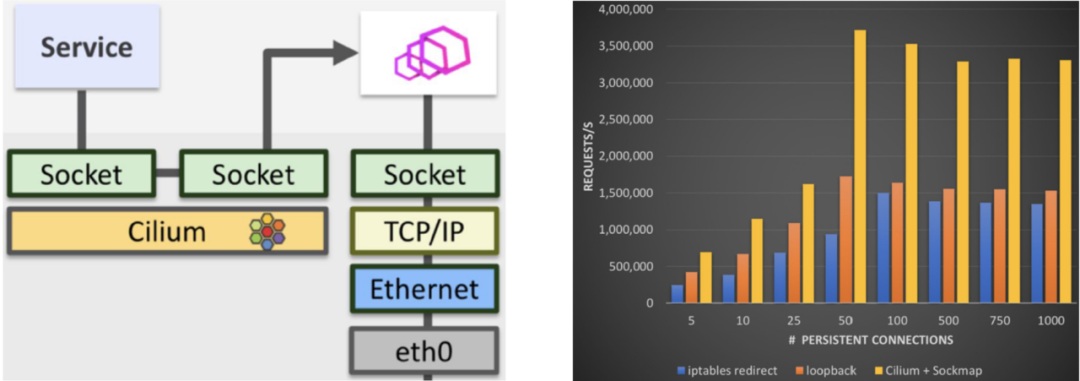
而Cilium将两个socket以短路的方式连接到了一起,绕过了协议栈直接在两个socket之间进行拷贝数据。从直观上来看,它的性能提升是非常大的。
下图是几种方法之间的性能比较,Cilium每秒处理请求数比传统方法效率成倍增加。
eBPF提取内核网络数据
eBPF能做什么
eBPF在跟踪,观测,安全,网络,技能调优方面都大有可为。
- 跟踪:比如要跟踪Linux内核里面的某个函数,我们想要知道这个函数调用了多少次,编写类似于Kprobe,Tracepoint这种类型的BPF程序用来跟踪内核的函数。
- 观测:编写eBPF程序来提取内核的一些数据。
- 安全:比如用eBPF程序抵御DDoS攻击。
- 网络:比如上面说的Cilium。
- 性能调优:用eBPF来提取细粒度的数据,然后通过数据做一些性能调优工作。
谁在使用eBPF
- FaceBook他们用eBPF重写了他们大部分的基础设施。比如使用eBPF重写了iptable和netfilter。他们的负载均衡也从Ipvs换成了BPF。
- 谷歌使用eBPF做Profiling,找出在分布式系统中应用消耗了多少cpu。他们也开始将BPF的应用范围扩展到了流量优化和网络安全。
- RedHat用BPF做了bpfilter。它会替换掉内核中的iptables。

eBPF跟踪内核原理
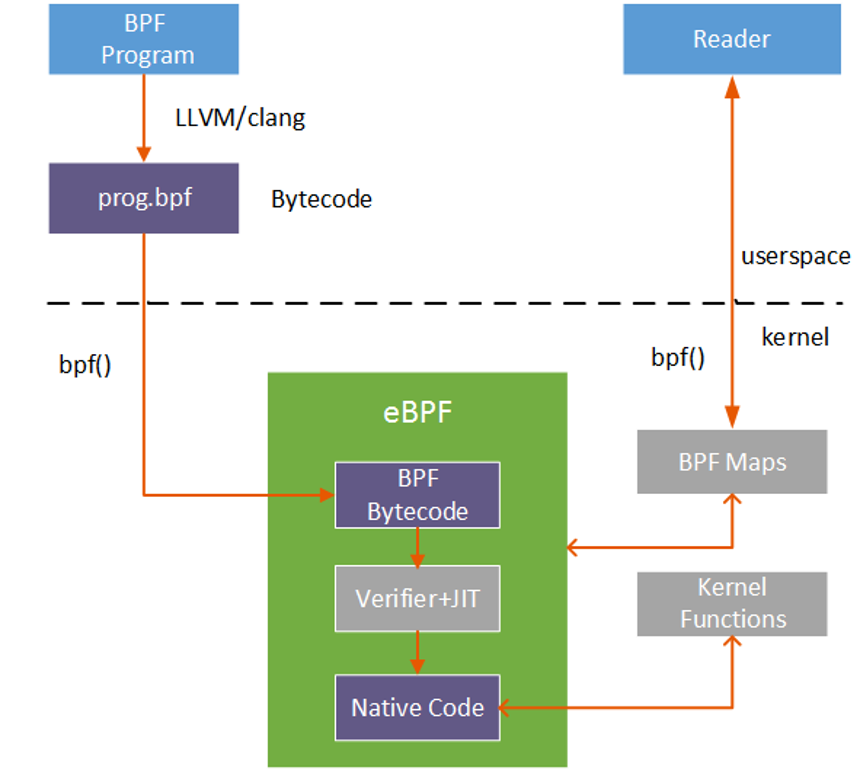
eBPF可以使用c、gobpf、BCC、bpftrace进行编写。常用的是BCC和bpftrace其中bpftrace就是在命令行就可以用一些很简短的一些命令来达到一个bpf观测的一个效果,BCC作为工具集,他是一个BPF的前端将bpf的一些api进行了更上一层的封装,就是你可以用python来做这些工作。
BCC程序通过LLVM和Clang将BPF程序编译成bpf字节码,通过bpf系统调用将bpf字节码注入内核中。其中bpf字节码首先经过安全验证检查防止写的bpf程序破坏内核,JIT将bpf字节码翻译成机器能识别的机器码注入内核。当我们监控的内核函数触发就去执行eBPF程序,其原理是当你监控函数执行的时候会在入口处做一个类似于中断替换,转去执行BPF程序,执行结束后回到刚才跳转处继续执行函数。
在eBPF机制中有BPF Map共享空间,可以被内核和用户同时访问,eBPF程序将提取出数据放入Map中用户从中拿到数据进行观测。
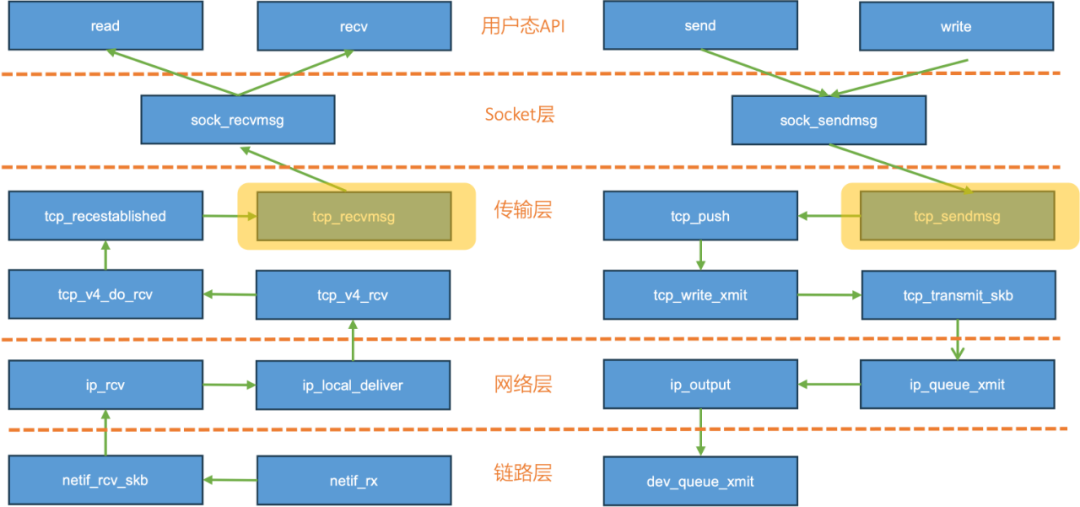
TCP协议收发数据关键函数执行流
下图是TCP协议收发数据流,左边是协议栈数据接收过程,右边是发送过程。下一节演示如何提取内核进程级TCP流量数据。
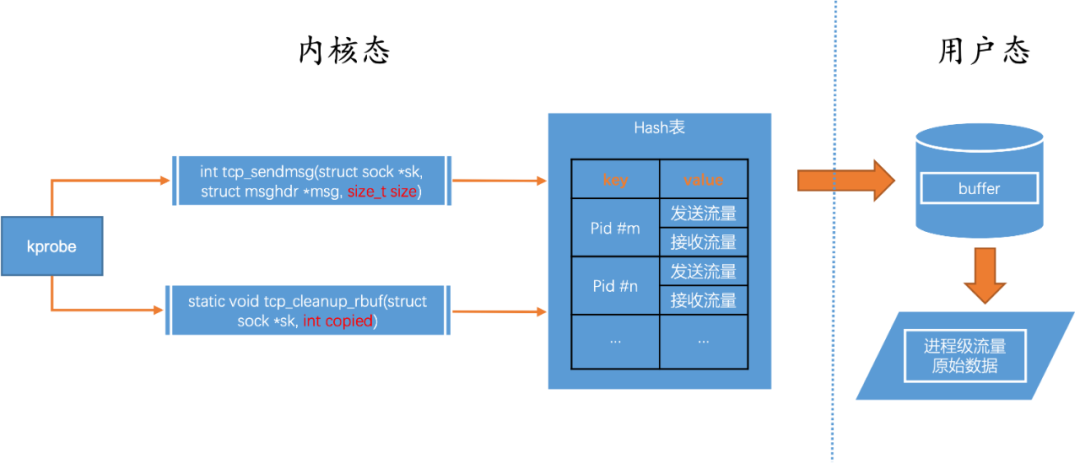
在TCP数据发送的时候,tcp_sendmsg是流量发送的一个必经之路,该函数的第三个参数中就有它的流量信息。
在TCP数据接收的时候,tcp_recvmsg是流量接收必经之路,该函数的第三个参数中就有它的流量信息。。
使用kprobe进行函数挂载,在数据报经过时函数触发BPF函数将数据放入Map中,用户态将数据从Map中进行提取展示。相较于tcp_recvmsg,tcp_cleanup_rbuf的执行次数会远远小于tcp_recvmsg减少了BPF程序触发次数所带来的开销,所以此处改为tcp_cleanup_rbuf为挂载点。
运行展示
通过下方视频链接可以更直观感受eBPF运行流程:
https://www.bilibili.com/video/BV1ch411U75f?p=4&spm_id_from=pageDriver
可视化展示eBPF提取的数据
- eBPF Exporter 是一个将自定义BPF跟踪数据导出到Prometheus的工具。可以将你的BPF程序嵌入在yml配置文件里面。然后执行Ebpf-exporter的时候加载这个配置就可以执行eBPF程序,然后将提取的数据通过一个端口暴露出来。
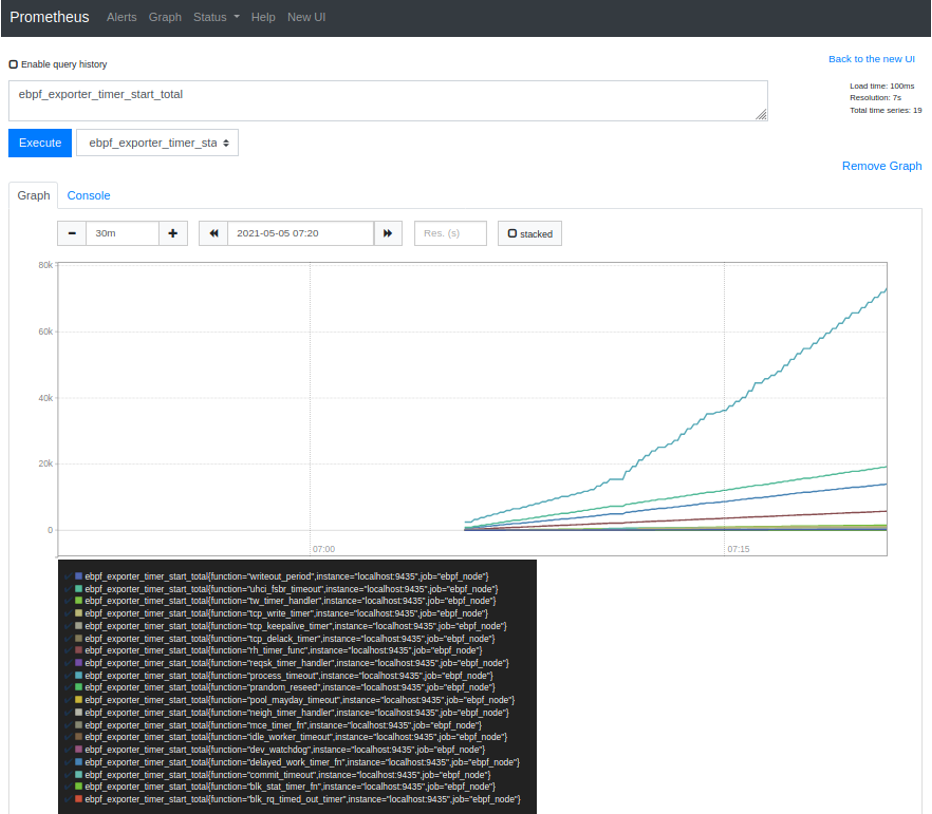
- Prometheus 是一个高扩展性的监控和报警系统,可以主动将暴露出来数据进行拉取存储展示。
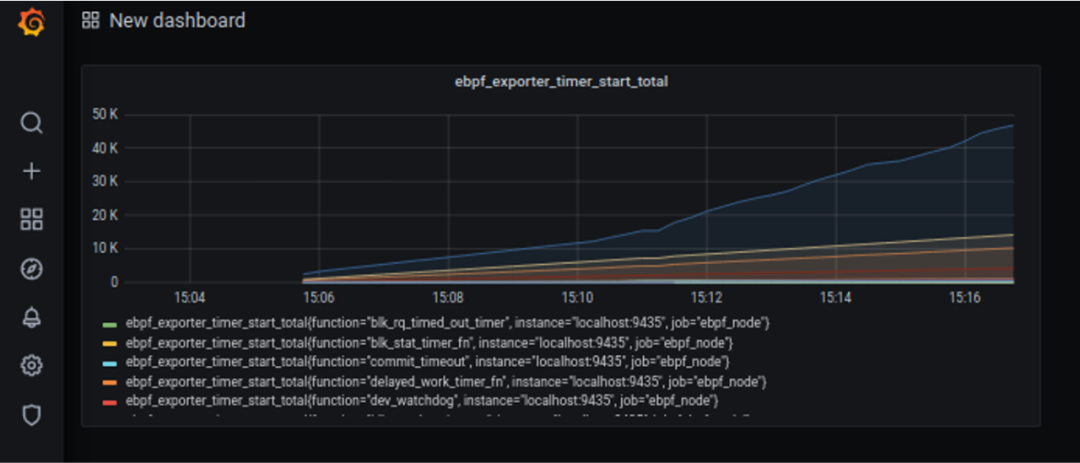
- Grafana 是一个用来展示各种各样数据的开源软件,它的图表非常丰富。
操作展示
通过下方视频链接可以更直观感受eBPF数据可视化展示:
https://www.bilibili.com/video/BV1ch411U75f?p=4&spm_id_from=pageDriver
学习资料
《Linux内核观测技术BPF》
《BPF之巅:洞悉Linux系统和应用性能》
《Systems Performance》
《BPF Performance Tools》
https://www.tcpdump.org/papers/bpf-usenix93.pdf
https://www.brendangregg.com/index.html
Cilium eBPF:https://ebpf.io
https://github.com/iovisor/bcc