eBPF小工具演示直播回放
大家好, 在这里分享一些自己使用eBPF技术编写的小工具,希望可以让初学者更加了解eBPF技术,从而做出自己的一些有意思的工具。
传统工具介绍
首先,要介绍的关于CPU Time相关的一些工具。在使用eBPF技术之前,先来了解一下传统的常用于统计CPU Time的工具TOP。
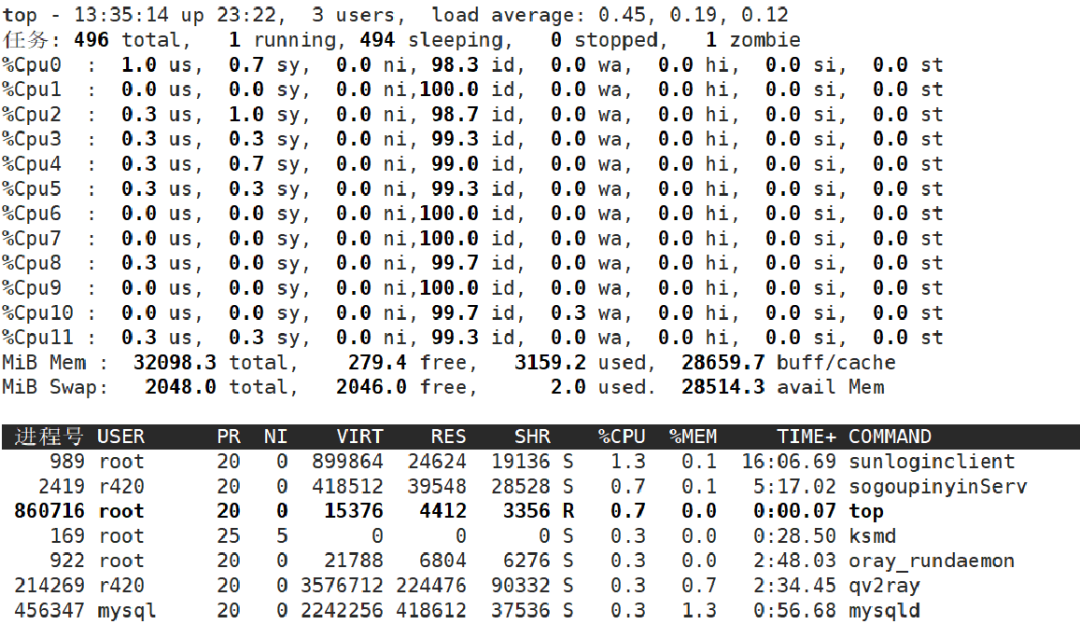
上图是TOP工具的使用界面,可以看到TOP工具将CPU Time分为user、system、nice、idle、iowait、hardirq、softirq以及steal几个部分。那么TOP工具展示的数据是从哪里来的呢?
其实是proc文件系统,我们输出/proc/stat,会看到这样格式的数据:
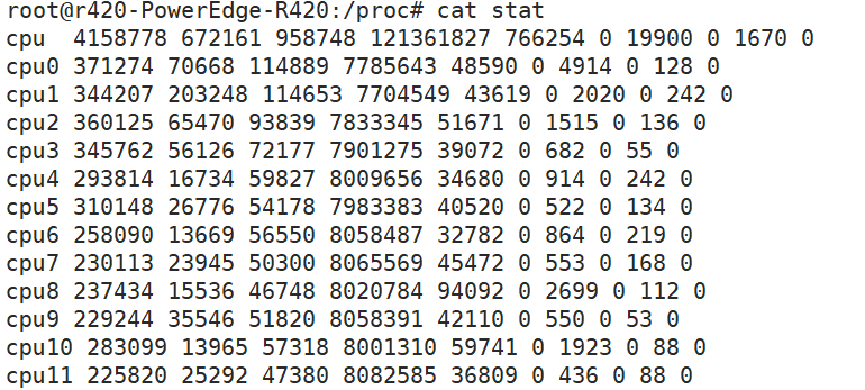
而通过分析proc文件系统的代码show_stat,可以看到除了idle和iowait有些特殊外,其余的时间信息数据皆是来自于cpustat数组。
for_each_online_cpu(i) {
struct kernel_cpustat kcpustat;
u64 *cpustat = kcpustat.cpustat;
kcpustat_cpu_fetch(&kcpustat, i);
/* Copy values here to work around gcc-2.95.3, gcc-2.96 */
user = cpustat[CPUTIME_USER];
nice = cpustat[CPUTIME_NICE];
system = cpustat[CPUTIME_SYSTEM];
idle = get_idle_time(&kcpustat, i);
iowait = get_iowait_time(&kcpustat, i);
irq = cpustat[CPUTIME_IRQ];
softirq = cpustat[CPUTIME_SOFTIRQ];
steal = cpustat[CPUTIME_STEAL];
guest = cpustat[CPUTIME_GUEST];
guest_nice = cpustat[CPUTIME_GUEST_NICE];
seq_printf(p, "cpu%d", i);
seq_put_decimal_ull(p, " ", nsec_to_clock_t(user));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(nice));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(system));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(idle));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(iowait));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(irq));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(softirq));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(steal));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(guest));
seq_put_decimal_ull(p, " ", nsec_to_clock_t(guest_nice));
seq_putc(p, '\n');
}那么,cpu_stat的数据是什么时候更新的呢?
一般来说,是在每次Tick的时候,在其对应的时钟中断处理函数中会调用一个函数update_process_times,该函数顺序执行到account_process_tick。
以下是account_process_tick的部分代码:
cputime = TICK_NSEC;
if (user_tick)
account_user_time(p, cputime);
else if ((p != this_rq()->idle) || (irq_count() != HARDIRQ_OFFSET))
account_system_time(p, HARDIRQ_OFFSET, cputime);
else
account_idle_time(cputime);根据Tick产生时是在用户态还是内核态以及idle进程的上下文等信息,选择不同的函数进行处理,这里是把这个TICK_NSEC,也就是每Tick对应的ns加到对应的cpustat数组中。
也就是说cpustat数组中的数据虽然是ns级的,但其实精度是要按照Tick的频率而定的,这就emmmm,不算很准确吧。
这里简单说一下选择cpustat的下标的问题,首先根据用户态和内核态是很容易区分的,最简单来说,当前程序使用的堆栈一个是内核堆栈,一个是用户态堆栈。而普通的内核态可以视为是系统调用进入,而是否在hardirq环境以及softirq环境可以通过preempt_count(thread_info的一个成员)进行判断。而idle状态,只需要判断当前进程是否是idle进程就可以了。
而至于前面说到的idle和iowait比较特殊,先清楚,iowait是在idle进程上下文中,但是rq->nr_iowait仍然大于0的情况。
这里直接分析get_idle_time的实现:
static u64 get_idle_time(struct kernel_cpustat *kcs, int cpu)
{
u64 idle, idle_usecs = -1ULL;
if (cpu_online(cpu))
idle_usecs = get_cpu_idle_time_us(cpu, NULL);
if (idle_usecs == -1ULL)
/* !NO_HZ or cpu offline so we can rely on cpustat.idle */
idle = kcs->cpustat[CPUTIME_IDLE];
else
idle = idle_usecs * NSEC_PER_USEC;
return idle;
}可以看到,这里主要是受NOHZ的影响,导致这里的计算有两条路径。
一般系统在高精度定时器开启时是会开启NOHZ的,所谓的NOHZ,俗称动态时钟,就是在idle进程执行idle任务(HLT指令或WFI指令等的时候)会关闭Tick,因为该CPU可能会空闲超出一个Tick,这时候关闭Tick,也就避免了每Tick的电能损耗。
而在进入实际的idle状态之前,每CPU的tick_sched会记录下进入idle的时间(该时间为高精度),而在proc文件系统计算的时候,会使用当前时间减去进入idle的时间,获得准确的时间,但遗憾的是,由get_cpu_idle_time_us可以看出,这里的最大精度是us。
通过对TOP工具数据来源代码的分析,可以看出传统工具的问题是依赖于内核数据结构的更新,而许多数据的粒度是与Tick的频率相关的,即便是最精度最高的idle时间,也只是us级。
而且以Tick为单位进行更新,也会将一些上下文的时间判断错误。如在两次Tick之间,从用户态进入系统态,在系统态触发Tick,根据上下文环境,就会将这段时间都视为是系统态时间。
那么,使用eBPF编写CPU Time相关的工具最直观的感受是什么呢?没错,就是直接可以获得ns级的时间信息,并且可以不出现这种以采样方式进行统计带来的误差。
进程CPU时间统计
来看第一个工具,直接选择一种最暴力的思想,统计出每一个进程的CPU Time,将idle进程和其它进程区分开来,这样得到总时间和idle时间,并以此算出CPU利用率。
我们知道一个进程在CPU上执行的开始和结束都是以调度为标志的。统计每一个进程的CPU Time,可以关注调度的关键挂载点。这里可以选择使用kprobe挂载到finish_task_switch函数上,也可以使用tracepoint挂载到sched/sched_switch上。
调度主要涉及到地址空间的切换和内核栈的切换,在以上两者切换完成之后,就会执行到finish_task_switch函数,做一些后续的清理工作,此时current宏已经发生了变化。
kprobe技术是需要依靠内核符号表查找地址,一般来说符号表中的函数基本都是可以挂载的,当然kprobe自身实现的一些和一些显示标注notrace的函数除外。我们可以通过/proc/kallsyms来查找符号表中是否有对应的内核函数。
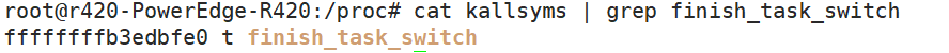
Tracepoint可以使用的点可以进入/sys/kernel/tracing/events进行查看:

在这里,我们选择使用kprobe到finish_task_switch函数上。
b = BPF(text=bpf_text)
b.attach_kprobe(event="finish_task_switch", fn_name="pick_start")当执行到finish_task_switch函数的时候,会转去执行我们自己定义的pick_start函数。
BPF_HASH(start, struct key_t);
BPF_HASH(dist, u32, struct time_t);
int pick_start(struct pt_regs *ctx, struct task_struct *prev)
{
u64 ts = bpf_ktime_get_ns();
u64 pid_tgid = bpf_get_current_pid_tgid();
struct key_t key;
struct time_t cpu_time, *time_prev;
u32 cpu, pid;
u64 *value, delta;
cpu = key.cpu = bpf_get_smp_processor_id();
key.pid = pid_tgid;
key.tgid = pid_tgid >> 32;
start.update(&key, &ts);
pid = key.pid = prev->pid;
key.tgid = prev->tgid;
value = start.lookup(&key);
if (value == 0) {
return 0;
}
delta = ts - *value;
start.delete(&key);
time_prev = dist.lookup(&cpu);
if (time_prev == 0) {
cpu_time.total = 0;
cpu_time.idle = 0;
}else {
cpu_time = *time_prev;
}
cpu_time.total += delta;
if (pid == 0) {
cpu_time.idle += delta;
}
dist.update(&cpu, &cpu_time);
return 0;
}这个函数的逻辑就是,在每次调度完成之后,记录下将要执行的进程的上处理器时间,并且查找出刚被换下的进程的上处理器时间,用现在的时间减去上处理器时间就可以得到本次进程执行的时间,将时间加到CPU总时间里面,如果刚被换下的进程是idle进程,也就是pid为0,那么把这部分时间算作idle时间。
可以看到,上述代码中用到了两个Map,Map在eBPF中可以作为内核态代码和用户态代码进行数据交流的一个桥梁。后面在用户态可以通过查找Map来获得CPU时间的一个统计信息。
dist = b.get_table("dist")
print("%-5s%-12s%-12s"%("CPU","IDLE(%)","CPU_USAGE(%)"))
while (1):
sleep(1)
for k, v in dist.items():
idle = (v.idle / v.total) * 100
print("%-5d%-12.2f%-12.2f"%(k.value,idle,100-idle))
dist.clear()以下是该工具的演示结果:
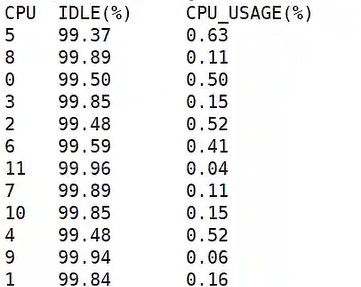
这里只是简单的按照是否为idle进程为判断标准,计算了一下CPU的利用率。当然也可以对这个工具做进一步的升级,比如要像TOP那样对每个进程的CPU利用率进行排序,我们可以以pid为key统计出所有进程的CPU时间。还比如,我们要对system时间进行进程的排序,可以只关注系统调用的入口和出口函数,同样以pid为key统计出所有进程的system时间(当然,这里要考虑中断抢占系统调用的情况)。
idleState情况统计
其实,如果说我们单纯想要获得idle时间,可以有开销更小的一些方法,比如说只关注idle进程。
每个CPU都有一个单独idle进程,当该CPU的runqueue没有任务可以运行的时候,就转去执行idle进程。idle进程执行do_idle函数,当要被调度的之前,会调用schedule_idle函数去执行调度主函数__schedule。
也就是说,我们可以只挂载do_idle和schedule_idle,就可以实现idle时间的追踪,与finish_task_switch的频繁调用相比,这样明显触发次数更少,带来的开销也更小。
但我要演示的第二个工具不是简单的获取idle时间以及CPU利用率,而是要深入去分析idle进程具体做了什么。
我们先来看下do_idle的部分代码:
while (!need_resched()) {
rmb();
local_irq_disable();
if (cpu_is_offline(cpu)) {
tick_nohz_idle_stop_tick();
cpuhp_report_idle_dead();
arch_cpu_idle_dead();
}
arch_cpu_idle_enter();
if (cpu_idle_force_poll || tick_check_broadcast_expired()) {
tick_nohz_idle_restart_tick();
cpu_idle_poll();
} else {
cpuidle_idle_call();
}
arch_cpu_idle_exit();
}只要在CPU没有被热插拔(hotplug)以及支持cpuidle模块的情况下,cpuidle是会去执行cpuidle_idle_call函数的,在这个函数中会选择一个cpuidle_state,然后让CPU进入该状态。
此时CPU其实一直在执行所谓的省电指令(X86:HLT;ARM:WFI),根据选择的cpuidle_state,会关闭CPU的一些子部件。进入的cpuidle_state越深,关闭的子部件越多,在该状态下越省电,同时,也意味着从该状态退出带来的延迟和电能损耗越高。
我们可以看下cpuidle_state的结构定义:
struct cpuidle_state {
char name[CPUIDLE_NAME_LEN];
char desc[CPUIDLE_DESC_LEN];
u64 exit_latency_ns;
u64 target_residency_ns;
unsigned int flags;
unsigned int exit_latency; /* in US */
int power_usage; /* in mW */
unsigned int target_residency; /* in US */
int (*enter) (struct cpuidle_device *dev,
struct cpuidle_driver *drv,
int index);
int (*enter_dead) (struct cpuidle_device *dev, int index);
int (*enter_s2idle)(struct cpuidle_device *dev,
struct cpuidle_driver *drv,
int index);
};我们重点关注其中的exit_latency_ns、target_residency_ns和power_usage这几个成员,exit_latency_ns是退出该状态需要花费的时间,target_residency_ns是期望在该状态停留的最低时间,如果实际在该状态的时间小于targe_residency_ns,则说明本次选择该idle_state的决定是错误的,不但没有节约,反倒增加了功耗。
我们来看一下我们选择挂载的函数:
sched_idle_set_state(target_state);
trace_cpu_idle(index, dev->cpu);
time_start = ns_to_ktime(local_clock());
stop_critical_timings();
if (!(target_state->flags & CPUIDLE_FLAG_RCU_IDLE))
rcu_idle_enter();
entered_state = target_state->enter(dev, drv, index);
if (!(target_state->flags & CPUIDLE_FLAG_RCU_IDLE))
rcu_idle_exit();
start_critical_timings();
sched_clock_idle_wakeup_event();
time_end = ns_to_ktime(local_clock());
trace_cpu_idle(PWR_EVENT_EXIT, dev->cpu);
/* The cpu is no longer idle or about to enter idle. */
sched_idle_set_state(NULL);在调用具体的进入该state的enter回调函数之前,会先调用sched_idle_set_state函数修改该CPU的运行队列的成员idle_state,而在离开该idle_state之后,也会调用sched_idle_set_state函数将该CPU的运行队列的成员idle_state置为NULL。
也就是说,通过挂载sched_idle_set_state函数,对其参数进行判断就可以知道当前是进入一个idle状态还是退出一个idle状态,并对进入和退出的时间进行记录,就可以知道本次是否满足最小停留时间。
该部分代码如下:
BPF_HASH(idle_start, u32, cpuidle_key_t);
BPF_HASH(idle_account, cpuidle_key_t, cpuidle_info_t);
// kernel_function : sched_idle_set_state
int do_idle_start(struct pt_regs *ctx, struct cpuidle_state *target_state) {
cpuidle_key_t key = {}, *key_p;
cpuidle_info_t info = {}, *info_p;
u32 cpu = bpf_get_smp_processor_id();
u64 delta, ts = bpf_ktime_get_ns();
if (target_state == NULL) {
key_p = idle_start.lookup(&cpu);
if (key_p == 0) {
return 0;
}
key.cpu = key_p->cpu;
key.exit_latency_ns = key_p->exit_latency_ns;
info_p = idle_account.lookup(&key);
if (info_p) {
delta = ts - info_p->start;
info_p->total += delta;
if (delta > (info_p->exit_latency_ns + info_p->target_residency_ns))
info_p->more++;
else
info_p->less++;
}
return 0;
};
key.cpu = cpu;
key.exit_latency_ns = target_state->exit_latency_ns;
idle_start.update(&cpu, &key);
info_p = idle_account.lookup(&key);
if (info_p) {
info_p->start = ts;
} else {
info.cpu = cpu;
bpf_probe_read_kernel(&(info.name), sizeof(info.name), target_state->name);
info.exit_latency_ns = target_state->exit_latency_ns;
info.target_residency_ns = target_state->target_residency_ns;
info.start = ts;
info.total = 0;
info.less = info.more = 0;
idle_account.update(&key, &info);
}
return 0;
}该工具演示结果如下:
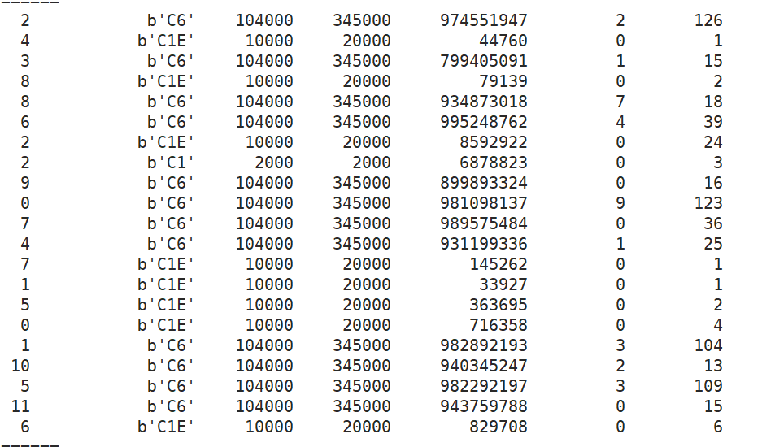
从左到右依次输出为:CPU、idle_state的名字、退出延迟、期望停留时间、在该状态停留的总时间、没有满足节约功耗的次数、满足的次数。
通过提取cpuidle模块的这部分数据,对后续优化该部分选择cpuidle状态的算法应该是比较有意义的。
使用CPU_CYCLES计算CPU利用率
第三个工具是计算CPU利用率的,不过该工具有点特殊,它借助于硬件信息进行CPU利用率的计算。
在谈第三个工具之前,我们先来了解一下perf,perf是Linux中一个特别常用的性能工具,其本质的实现基于一个函数perf_event_open,以下是man手册中perf_event_open的描述。

通过perf_event_open可以对定义的perf事件进行计数,通过read返回的文件描述符可以读取这些perf事件的计数信息。
perf支持的事件包括硬件、软件、cache以及tracepoint等等。
这里我们关注硬件中的一个事件PERF_COUNT_HW_CPU_CYCLES。
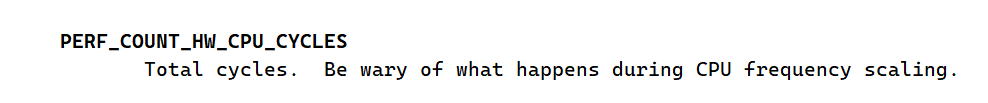
以上是man手册中对PERF_COUNT_HW_CPU_CYCLES的描述,可以看到该计数值是会受到CPU频率变换的影响,那么我们先把频率固定,然后看一下CPU_CYCLS和CPU频率有什么样的关系呢?

我们先将CPU频率定为2200000KHZ。
接下来依靠perf_event_open注册CPU_CYLES和CPU_CLOCK事件:
struct perf_event_attr attr_cpu_clk;
struct perf_event_attr attr_cpu_cyr;
memset(&attr_cpu_clk, 0, sizeof(struct perf_event_attr));
memset(&attr_cpu_cyr, 0, sizeof(struct perf_event_attr));
attr_cpu_clk.type = PERF_TYPE_SOFTWARE;
attr_cpu_clk.size = sizeof(struct perf_event_attr);
attr_cpu_clk.config = PERF_COUNT_SW_CPU_CLOCK;
attr_cpu_clk.sample_period = SAMPLE_PERIOD;
attr_cpu_clk.disabled = 1;
attr_cpu_cyr.type = PERF_TYPE_HARDWARE;
attr_cpu_cyr.size = sizeof(struct perf_event_attr);
attr_cpu_cyr.config = PERF_COUNT_HW_CPU_CYCLES;
attr_cpu_cyr.sample_period = SAMPLE_PERIOD;
attr_cpu_cyr.disabled = 1;
for (i = 0; i < nr_cpus; i++) {
// cpu cycle
fd_cpu_clk[i] = perf_event_open(&attr_cpu_clk, -1,
i, -1, 0);
if (fd_cpu_clk[i] == -1)
err_exit("PERF_COUNT_HW_CPU_CYCLES");
ioctl(fd_cpu_clk[i], PERF_EVENT_IOC_RESET, 0);
ioctl(fd_cpu_clk[i], PERF_EVENT_IOC_ENABLE, 0);
// cpu ref cycle
fd_cpu_cyr[i] = perf_event_open(&attr_cpu_cyr, -1,
i, -1, 0);
if (fd_cpu_cyr[i] == -1)
err_exit("PERF_COUNT_SW_CPU_CLOCK");
ioctl(fd_cpu_cyr[i], PERF_EVENT_IOC_RESET, 0);
ioctl(fd_cpu_cyr[i], PERF_EVENT_IOC_ENABLE, 0);
}在读取到CPU_CYCLES和CPU_CLOCK的计数值之后,将其与频率值进行如下运算,并与根据/proc/stat计算得到的CPU利用率进行对比。
read(fd_cpu_clk[i], &data_cpu_clk[i], sizeof(data_cpu_clk[i]));
read(fd_cpu_cyr[i], &data_cpu_cyr[i], sizeof(data_cpu_cyr[i]));
cpu_clk = data_cpu_clk[i] - prev_cpu_clk[i];
cpu_cyr = data_cpu_cyr[i] - prev_cpu_cyr[i];
double new_rate = cpu_cyr * 1000.0 / (22 * cpu_clk);
printf("CPU:%d CPU_CLOCK:%lld CPU_CYCLES:%lld RATE: %16.5f %16.5f\n",
i,
cpu_clk,
cpu_cyr,
new_rate,
cpu_rate);将CPU_CYCLES的计数值与CPU_CLOCKS的计数值与频率的乘积做一个除法,可以得到这样的结果:
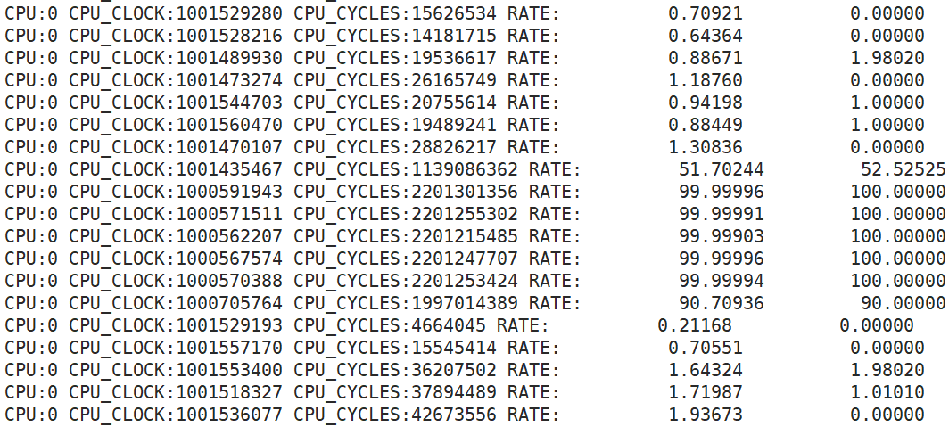
可以看到该公式计算的结果与根据/proc/stat中数据计算的结果基本上保持趋势的一致。为什么会这样呢?
之前说到cpuidle会去执行一些省电指令,其实在执行这些省电指令的时候,CPU_CYCLES会停止计数;而在执行其余指令时,CPU_CYCLES的计数值的增长速度是与当前CPU的频率保持一致的。
这就是说,只要我们在每次频率变化的时候读取一下CPU_CYCLES的计数值,然后做一个简单的运算,就可以知道CPU在上一个频率下的CPU利用率。这时候,就有两个问题要解决,如何获得频率的变化信息以及如何在ebpf的内核代码中读取perf事件的计数值。
首先,先来看下挂载的函数cpufreq_freq_transition_end的使用场景:
cpufreq_freq_transition_begin(policy, freqs);
ret = cpufreq_driver->target_intermediate(policy, index);
cpufreq_freq_transition_end(policy, freqs, ret);在执行具体的频率变化钩子函数之前,会先调用cpu_freq_transition_begin,而在具体的频率变化钩子函数之后,会调用cpufreq_freq_transition_end,我们可以根据其参数ret和freqs->new和freqs->old两个成员是否一致来判断是否进行了频率切换以及具体切换函数是否执行成功。
以下是获得频率变化的部分程序:
int do_cpufreq_ts(struct pt_regs *ctx, struct cpufreq_policy *policy, struct cpufreq_freqs *freqs, int transition_failed)
{
if (transition_failed) {
return 0;
}
u32 cpu = bpf_get_smp_processor_id();
u32 freq_new = freqs->new;
u32 freq_old = freqs->old;
if (freq_new == freq_old)
return 0;
bpf_trace_printk("CPU: %d OLD: %d ---> NEW: %d\\n", cpu, freq_old, freq_new);
// freq_cpu.update(&cpu, &freq_new);
return 0;
}该脚本的演示结果如下:
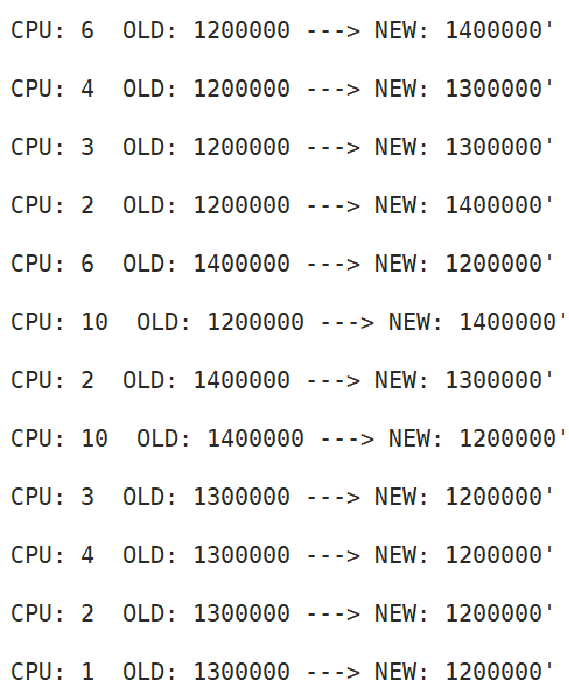
现在可以获得CPU的频率变化信息,那么怎么在ebpf内核态代码读取到perf事件的计数值呢?
这里需要借助一个特殊的Map,eBPF提供了许多种Map,有单纯的哈希表,队列,栈这些,还有一些Map是用于存取特殊的数据结构的,例如现在要使用的BPF_MAP_TYPE_PERF_EVENT_ARRAY。
我们需要创建该类型的Map,然后在用户态注册perf事件,然后将该perf事件的文件描述符更新到该Map中,在内核态程序中可以依靠读取该Map来获得perf事件的计数值。
部分实现代码如下:
// kern.c
struct {
__uint(type, BPF_MAP_TYPE_PERF_EVENT_ARRAY);
__uint(key_size, sizeof(int));
__uint(value_size, sizeof(u32));
__uint(max_entries, 64);
} pmu_cyl SEC(".maps");
u64 cpu = bpf_get_smp_processor_id();
u64 cyl = bpf_perf_event_read(&pmu_cyl, cpu);
char fmt[] = "CPU: %u CYL: %u \n";
bpf_trace_printk(fmt, sizeof(fmt), cpu, cyl);// user.c
struct perf_event_attr attr_cycles = {
.freq = 0,
.sample_period = SAMPLE_PERIOD,
.inherit = 0,
.type = PERF_TYPE_HARDWARE,
.read_format = 0,
.sample_type = 0,
.config = PERF_COUNT_HW_CPU_CYCLES,
};
static void register_perf(int cpu, struct perf_event_attr *attr) {
pmufd_cyl[cpu] = sys_perf_event_open(attr, -1, cpu, -1, 0);
ioctl(pmufd_cyl[cpu], PERF_EVENT_IOC_RESET, 0);
ioctl(pmufd_cyl[cpu], PERF_EVENT_IOC_ENABLE, 0);
bpf_map_update_elem(map_fd[0], &cpu, &(pmufd_cyl[cpu]), BPF_ANY);
}该脚本演示结果如下:
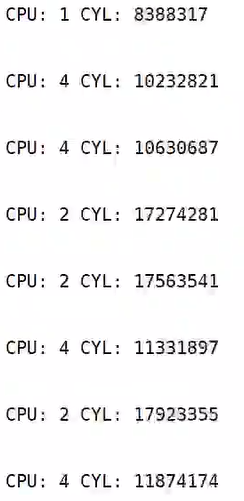
可以看到,在ebpf的内核态代码也是可以读取到perf事件的计数值。
如果说之前使用eBPF计数都只是单纯的对以往技术的封装升级,如kprobe挂载函数之类的,到这里就可以看到eBPF的优势,那就是可以很轻松地实现多种技术的联动,在这里就将kprobe和perf联动起来了。
打印内核函数调用关系
最后,我们再来看一个小工具,这个工具通过eBPF技术可以打印出来内核函数的调用关系。一般来说,如果要显示函数调用关系,最常使用的是dump_stack函数。
但是dump_stack函数的使用是有一定的局限的,一般都是在驱动代码中使用,而如果我们想要去打印某个内核函数的函数调用关系,去该函数内部中添加dump_stack函数,再重新编译一遍内核,这样明显不太现实。
而eBPF提供了一种比较特殊的Map,可以用于打印内核栈的函数调用关系,这就是BPF_MAP_TYPE_STACK_TRACE。
内核态函数可以通过bpf_get_stackid()获得触发eBPF程序时的内核态堆栈或者用户态堆栈的id号,而在用户态程序中可以通过该id号打印出触发时的堆栈信息,也就是函数调用关系。
下面我们看下这部分代码:
// kern.c
struct {
__uint(type, BPF_MAP_TYPE_STACK_TRACE);
__uint(key_size, sizeof(u32));
__uint(value_size, PERF_MAX_STACK_DEPTH * sizeof(u64));
__uint(max_entries, 10000);
} stackmap SEC(".maps");
#define STACKID_FLAGS (0 | BPF_F_FAST_STACK_CMP)
SEC("kprobe/finish_task_switch")
int bpf_prog1(struct pt_regs *ctx, struct task_struct *prev)
{
struct key_t key = {};
struct val_t val = {};
val.stack_id = bpf_get_stackid(ctx, &stackmap, STACKID_FLAGS);
bpf_get_current_comm(&val.comm, sizeof(val.comm));
key.pid = bpf_get_current_pid_tgid();
key.cpu = bpf_get_smp_processor_id();
bpf_map_update_elem(&task_info, &key, &val, BPF_ANY);
return 0;
}这时候需要两个Map,一个Map存储stackid,另外一个Map就是BPF_MAP_TYPE_STACK_TRACE。我们在用户态总是在第一个Map中获得stackid,然后再获得堆栈信息。
while (bpf_map_get_next_key(map_fd[0], &key, &next_key) == 0) {
bpf_map_lookup_elem(map_fd[0], &next_key, &val);
print_stack_info(&next_key, &val);
key = next_key;
}
static void print_stack_info(struct key_t *key, struct val_t *val) {
__u64 ip[PERF_MAX_STACK_DEPTH] = {};
int i;
printf("CPU: %d PID: %d COMM: %s\n", key->cpu, key->pid, val->comm);
printf("function call:\n");
if (bpf_map_lookup_elem(map_fd[1], &(val->stack_id), ip) != 0) {
printf("---NONE---\n");
} else {
for (i = PERF_MAX_STACK_DEPTH - 1; i >= 0; i--)
print_ksym(ip[i]);
printf("=========\n");
}
}
至于根据堆栈中的地址打印出函数名称的部分,需要借助于内核符号表的帮助,这部分的实现在C和python中都有对应的接口API。
下面是该工具的演示结果,本例中挂载函数为finish_task_switch:
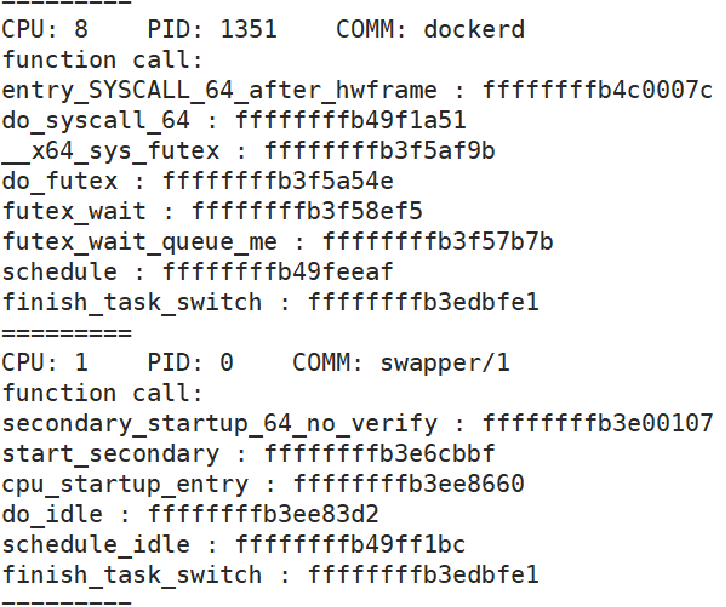
这里可以看到,同样是finish_task_switch,对于普通进程可能是schedule函数执行到这里的,而对于idle进程来说,则是从schedule_idle一步一步执行下来的。
目前这里还是使用C语言书写的,其实完全可以使用python去实现一下,这样会避免掉一个编译的过程,可以实现在命令行输入然后动态显示内核调用关系的功能。