前端工程师如何快速使用一个NLP模型
本文预计需要20min,通过本文主要获得几个知识点:
-
了解 NLP 发展历程 和 NLP任务边界
-
学会 如何快速使用一个NLP模型
一、引言
万词王
前段时间,有个开源项目 万词王(github[1])开源了,短短时间收获了4k start
它是一种反向词典,其最大的用处在于解决舌尖现象(Tip of the tongue),即话到嘴边说不出来的问题。
例如输入描述:开飞机的人
输出描述:机师、飞行员、机长 等等...
站点地址 https://wantwords.thunlp.org/
刚看到这个库,感觉很好奇,于是便简单看了个大概思路
是怎么能根据一段描述 能反推 对应的概述词的呢?
大体思路
可参考学习 https://zhuanlan.zhihu.com/p/100382190?from_voters_page=true
根据这个库的 Readme 描述[2],来看看它的大体思路
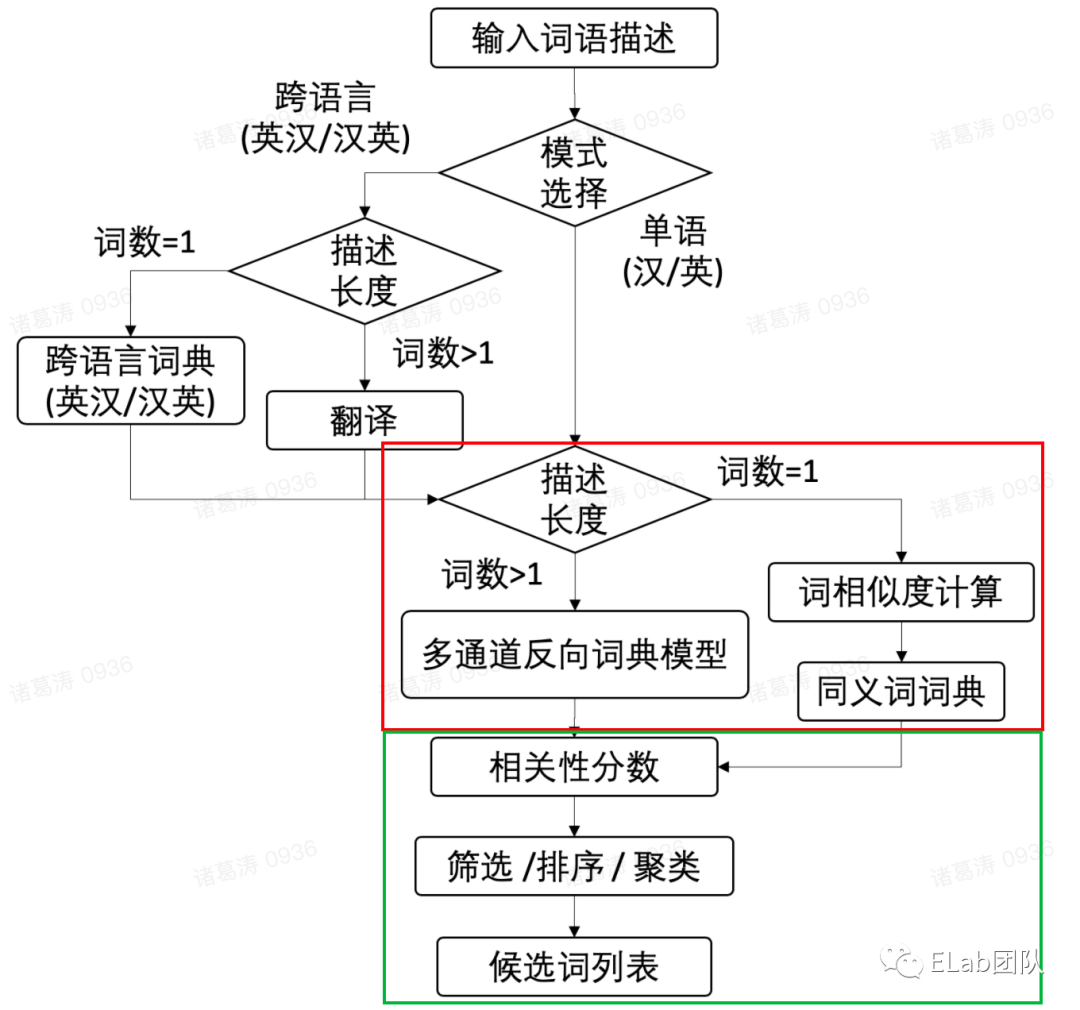
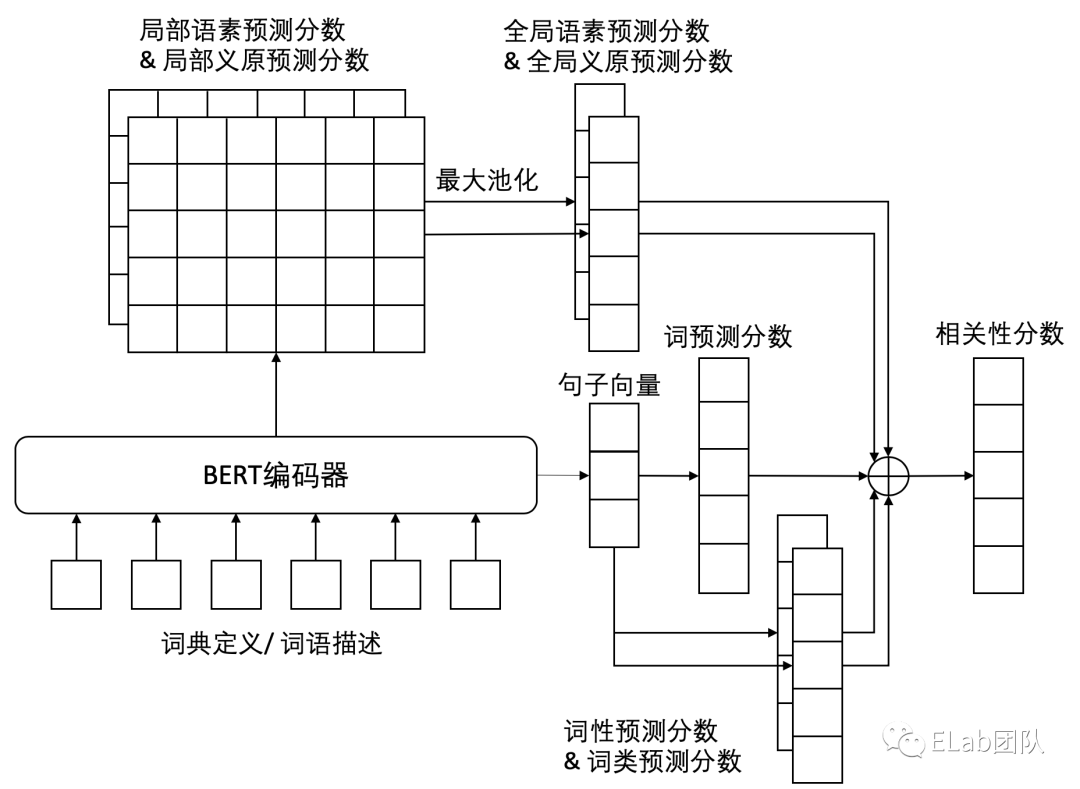
先对一段描述 采用分词工具 进行分词
-
如果分词后,只有一个词语,则从预训练的权重表中 匹配 同义词林中多个同义词的
-
如果分词后,有多个词语,则对每个词语进行一个bert编码分解成一个个token,采用 多通道反向词典语言模型 进行相关性分数计算,返将得分 前n个 的token,最后根据词典,将token反查得到对应中文
大体实现
不是本文关键,看不懂没关系,有些我也没太懂... 边学边看即可
初始化工作
# 初始化 文本分词工具
lac = thulac.thulac()
# 导入token分词工具
tokenizer_Ch = BertTokenizer.from_pretrained('bert-base-chinese')
# 加载同义词表、释义表
word2index, index2word, (wd_C, wd_sems, wd_POSs, wd_charas), mask_ = load_data()
# 添加同义词词林用于描述为一个词时的同义词推荐
index2synset = [[] for i in range(len(word2index))]
for line in open(BASE_DIR + 'word2synset_synset.txt').readlines():
wd = line.split()[0]
synset = line.split()[1:]
for syn in synset:
index2synset[word2index[wd]].append(word2index[syn])
# 加载 双向通道语言模型
MODEL_FILE = BASE_DIR + 'Zh.model'
model = torch.load(MODEL_FILE, map_location=lambda storage, loc: storage)
model.eval()分词
# 分词
import thulac
lac = thulac.thulac()
fenci = lac.cut(description)
# 得到分词列表
def_words = [w for w, p in fenci]词数为1:单通道
# 词向量找相关词,排序后,如果在词林里,则对应的同义词的分数乘以2
# tensor 矩阵相乘 预训练词嵌入权重表tonsor(137422,200) * tonsor(200,1) 得到 tonsor(137422,1) 即该词在 词林表中 权重表
score = (model.embedding.weight.data).mm(model.embedding.weight.data[def_word_idx[0]])
if RD_mode == 'CC':
# 当CC的时候,排除自身,EC的时候自身是最准确的,不排除。
score[def_word_idx[0]] = -10.
score[np.array(index2synset[def_word_idx[0]])] *= 2
sc, indices = torch.sort(score, descending=True)
# 获得排名前500的预测值
predicted = indices[:NUM_RESPONSE].detach().cpu().numpy()
score = sc[:NUM_RESPONSE].detach().numpy()词数>1:多通道
模型入参 https://github.com/thunlp/MultiRD/blob/fe72148c00/ChineseReverseDictionary/code/model.py
defi = '[CLS] ' + description
# 对文本输入进行编码
def_word_idx = tokenizer_Ch.encode(defi)[:80]
def_word_idx.extend(tokenizer_Ch.encode('[SEP]'))
# 在PyTorch张量中 转换indexed_tokens
definition_words_t = torch.tensor(np.array(def_word_idx), dtype=torch.int64, device=device)
# 模型调用
score = model('test', x=definition_words_t, w=words_t, ws=wd_sems, wP=wd_POSs, wc=wd_charas, wC=wd_C, msk_s=mask_s, msk_c=mask_c, mode=MODE)
sc, indices = torch.sort(score, descending=True)
# 获得排名前500的预测值
predicted = indices[0, :NUM_RESPONSE].detach().cpu().numpy()结果转换
# index2word 跟进词典释义表,将index转化为word
res = index2word[predicted]上面简单对一个 开源的NLP项目做了介绍,重点知道一个大概的处理轮廓即可:
step1、输入加工
- 将文本内容分词处理成token,可以让模型识别的数学描述
step2、模型处理
- 特征提取:做一系列变化,预测其最大的可能性,得到一个权重张量
step3、输出加工
- 将权重张量 数学描述 根据词典 转化为文本内容
单看完一个模型,对于NLP整个的发展有哪些故事,以及现状大家都在研究什么方向,还是没有清晰认识。下面说下 NLP 的发展历程 和现状,方便我们对 NLP有个简单的全局认识
二、NLP 简介
发展历史
参考 https://zhuanlan.zhihu.com/p/148007742

-
1950-1970 - 采用基于规则的方法
-
研究人员们认为自然语言处理的过程和人类学习认知一门语言的过程是类似的,基于这个理论,定义了大量规则,但因规则的局限性,只能解决一些简单问题
-
1970-20世纪初 - 采用基于统计的方法
-
随着技术发展 和 语料库丰富,基于统计的方案逐渐代替了基于规则的方法,nlp由经验主义向理性主义过渡,开始从实验室走向实际应用
-
2008-2018 - 引入深度学习的RNN、LSTM、GRU
-
在图像识别和语音识别领域的成果激励下,人们也逐渐开始引入深度学习来做自然语言处理研究,由最初的词向量到2013年的word2vec,将深度学习与自然语言处理的结合推向了高潮,并在机器翻译、问答系统、阅读理解等领域取得了一定成功
-
现今
-
2017年谷歌提出了Transformer架构模型,2018年底,基于Transformer架构,谷歌推出了bert模型,bert模型一诞生,便在各大11项NLP基础任务中展现出了卓越的性能(一个排名榜单[3]),现在很多模型都是基于或参考Bert模型进行改造
-
如果想了解 Transformer 和 bert,可以看这个视频
https://www.bilibili.com/video/BV1P4411F77q?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1Mt411J734?spm_id_from=333.999.0.0
-
bert 大家族
-

目前研究方向
方向分为两个方向
https://zhuanlan.zhihu.com/p/56802149
-
自然语言理解 NLU
-
自然语言生成 NLG
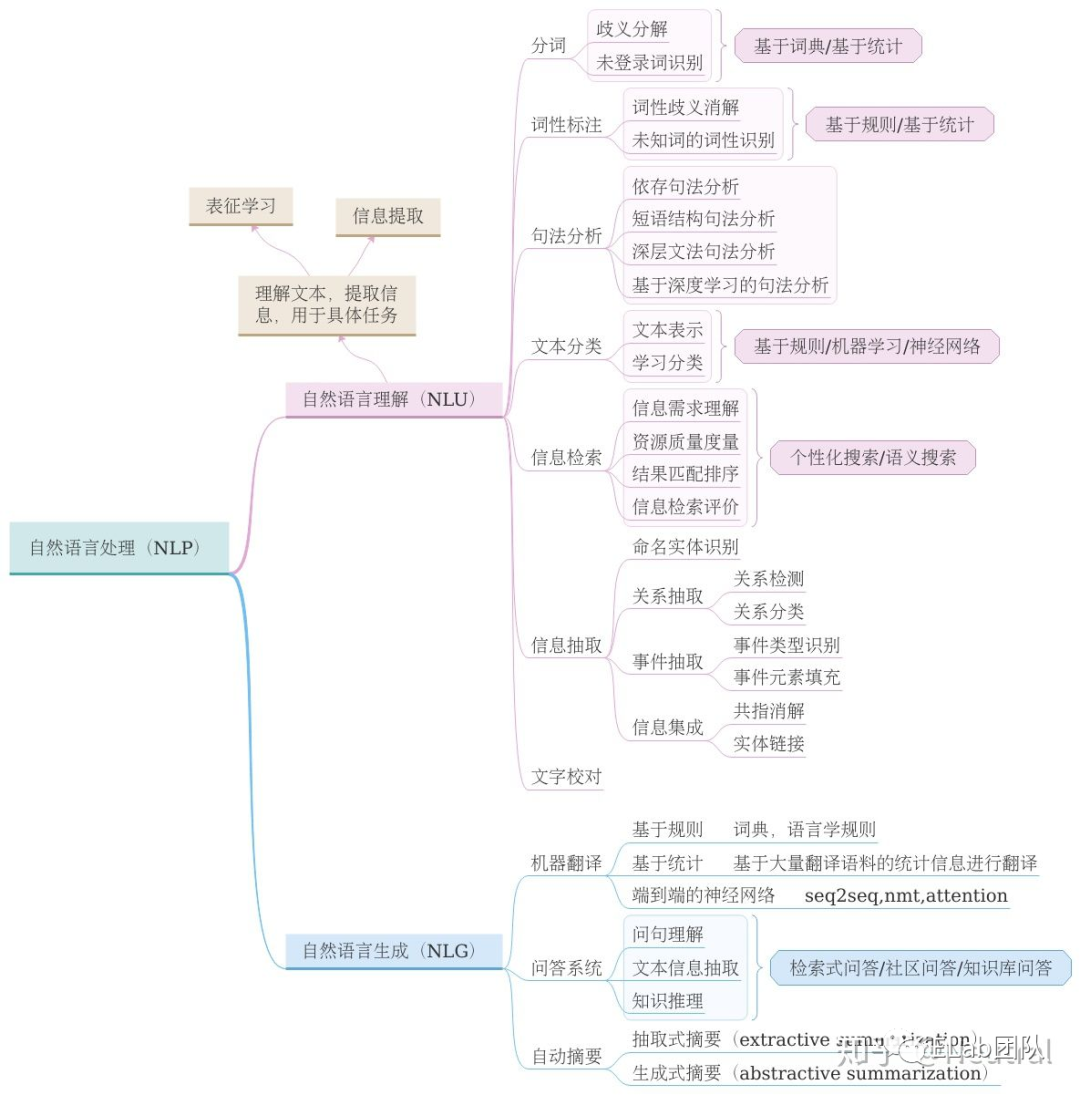
- 序列标注:分词/POS Tag(词性标注)/NER(命名实体识别)/语义标注
- 分类任务:文本分类/情感计算
- 句子关系判断:Entailment 文本蕴含/QA/自然语言推理
- 生成式任务:机器翻译/文本摘要
了解完NLP的发展历程 和 边界(常见的探索方向)
下面以 bert模型为例,实战下如何调用 一个模型
三、实战模型调用
实战前,应该会有两个问题比较懵逼
Q1:模型可以去哪里找?
A1:现在已经有一个很成熟的社区整合了大量的模型,我们可以拿来即用,它就是 HuggingFace(当然github自己搜也行,但比较零散)
Q2:有了模型怎么用?
A2:不用慌,HuggingFace提供了非常详细的上手教程,可以快速上手!
↓↓↓↓
先简单说下Hugging Face
Hugging Face
https://huggingface.co/

- 其对外提供了一个库 Transformers,Transformers 提供了数以千计的预训练模型,支持 100 多种语言的文本分类、信息抽取、问答、摘要、翻译、文本生成,并且Transformers 与 PyTorch、 TensorFlow 无缝整合
一点小插曲:这个库名字一直在变,网上一些不同时间发表的文章对其称呼不一致,不要懵逼,其实是一个库...
一开始名称是 pytorch-pretrained-bert ,后来更名为 pytorch-transformers,2.0后更名为 Transformers
访问站点,我们可以切换到model列表
可在左侧边栏 根据你想做的事情,做一个筛选
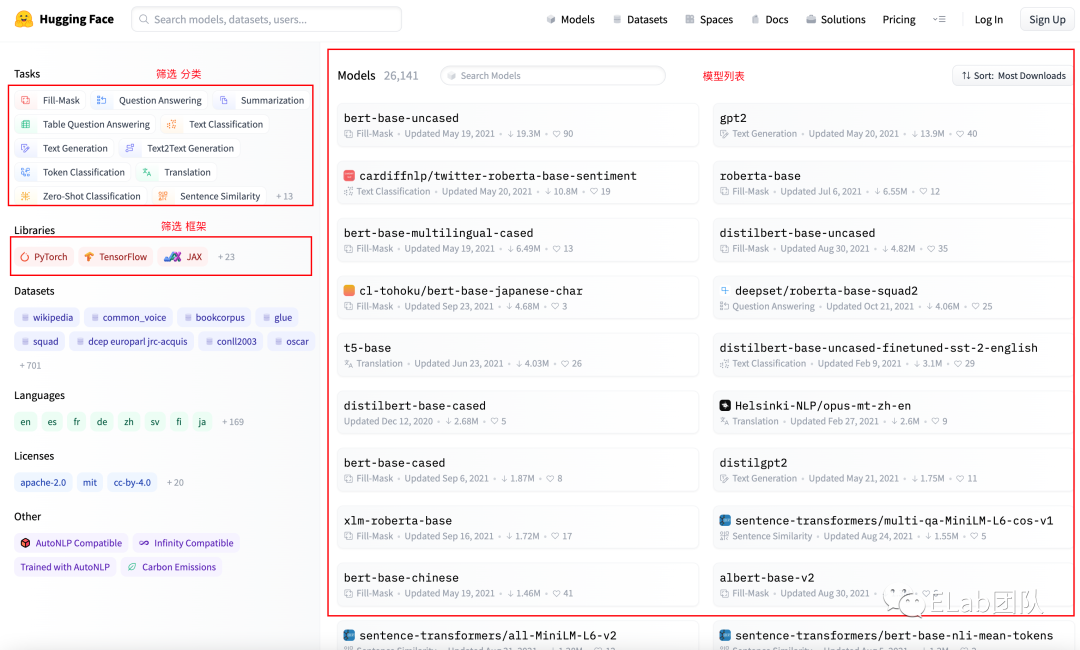
model加载支持两种方式,离线 和 远程,如果需要离线,可以切换到 Files and versions 窗口下载资源
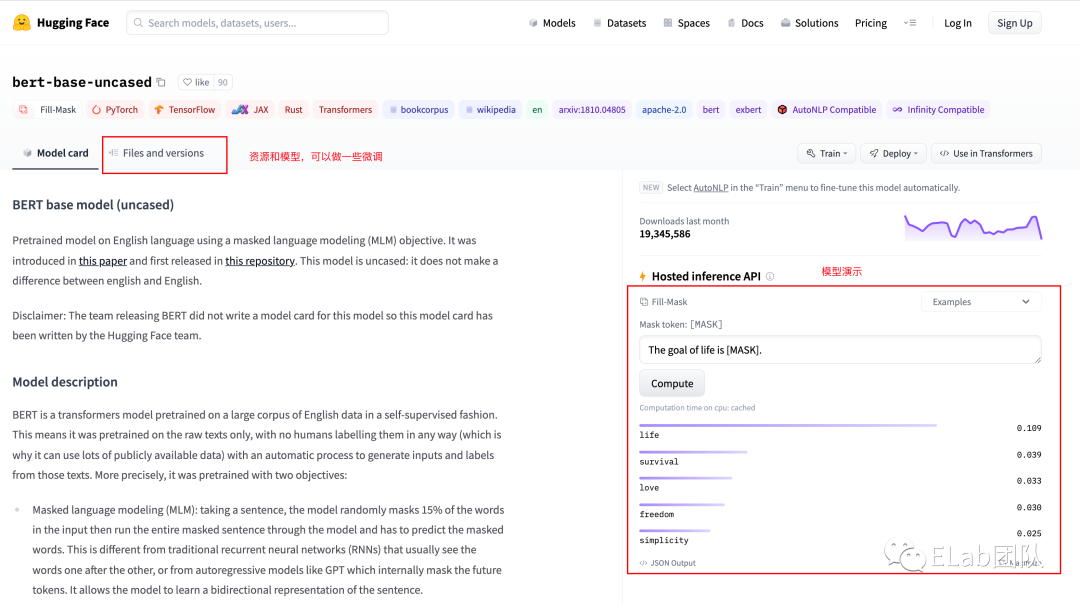
调用一个模型:实战 bert-base-chinese
方式一 使用 pytorch 调用
pytorch 是facebook推出的 机器学习库(与tensorflow类型),其支持 友好的调试 和 稳定的api,一经推出就大受欢迎,目前使用 pytorch 比 tensorflow的人多
import numpy as np
import torch
from transformers import BertTokenizer, BertForMaskedLM
# BERT [CLS] 和 [SEP] 标记句子的开头和结尾
samples = ['[CLS] 诸葛[MASK]是三国时期人物[SEP]'] # 准备输入模型的语句
mask_index = 3
# ---- step1、token处理 ----
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
# 将句子分割成一个个token,即一个个汉字和分隔符
tokenized_text = [tokenizer.tokenize(i) for i in samples]
# 把每个token转换成对应的索引
input_ids = [tokenizer.convert_tokens_to_ids(i) for i in tokenized_text]
input_ids = torch.tensor(input_ids)
# ---- step2、模型调用 ----
# 读取预训练模型
model = BertForMaskedLM.from_pretrained('bert-base-chinese')
model.eval()
# model输出查看列表 https://huggingface.co/docs/transformers/main_classes/output
# 我们可以在该文档中,找到对应模型的出参,方便 做结果转换 操作
outputs = model(input_ids)
# ---- step3、结果转换 ----
# torch 张量转化为 numpy,方便处理
sample = outputs.logits[0].detach().numpy()
pred = np.argsort(-sample[mask_index],axis=0)[:20]
print(tokenizer.convert_ids_to_tokens(pred))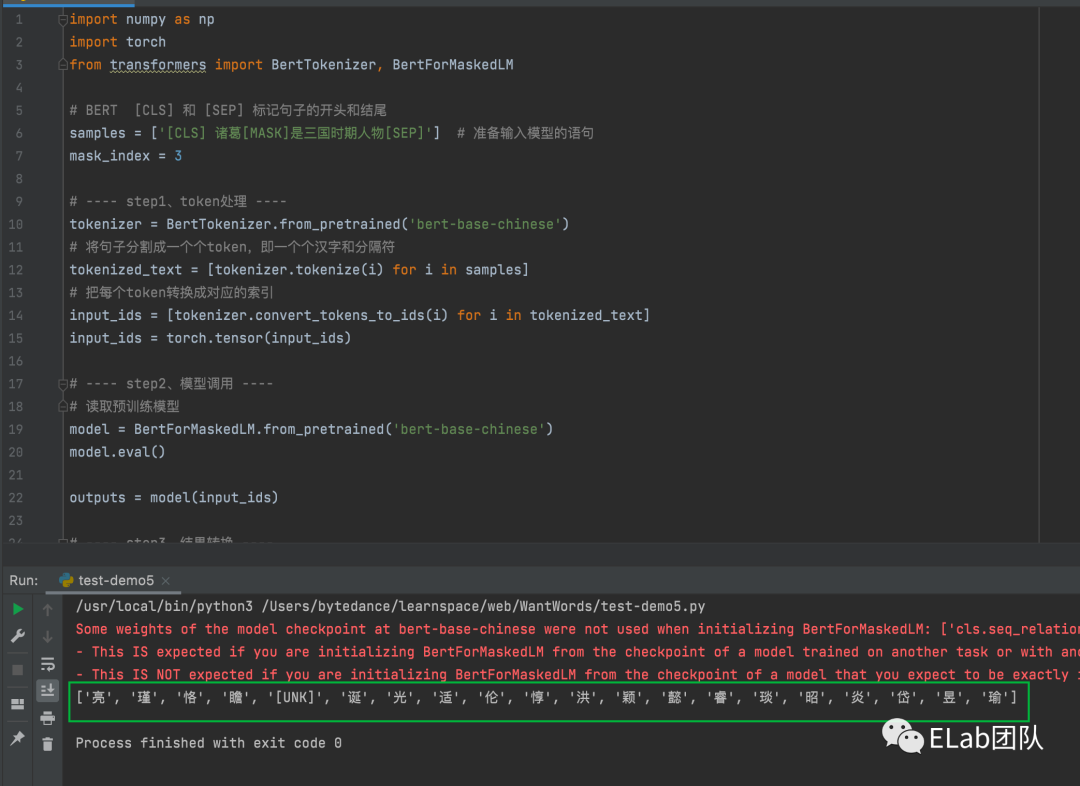
方式二 使用 pipeline 调用
使用pytorch还是比较比较麻烦的,我们还可以 HuggingFace 提供的pipeline快速调用model
pipeline 对模型输入 和 输出做了统一封装,所以更便捷
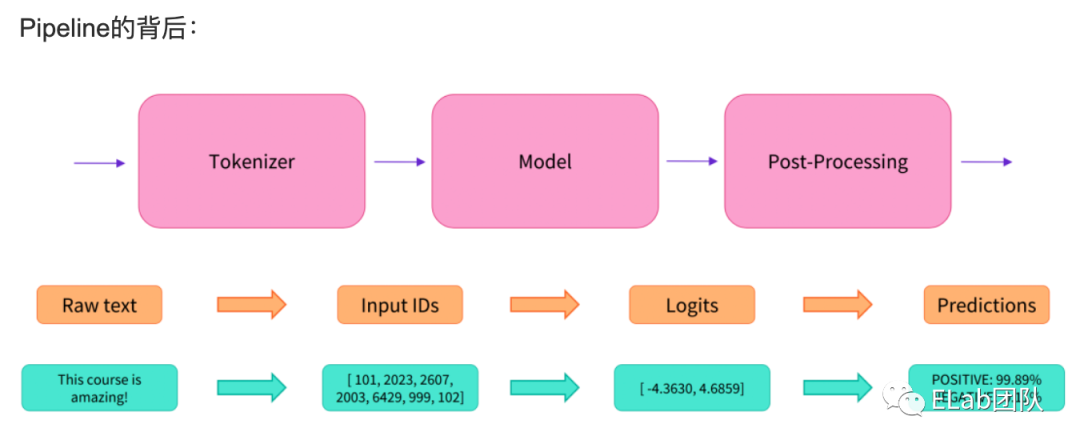
https://huggingface.co/docs/transformers/main_classes/pipelines
调用例子:
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-chinese')
print(unmasker( 巴黎是[MASK]国的首都。 ))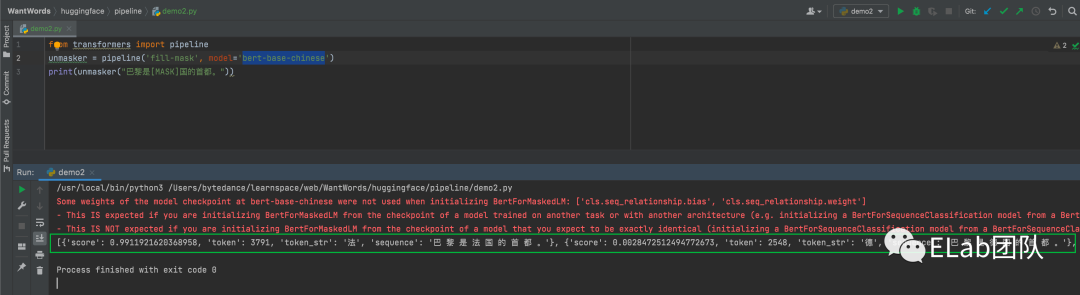
开发API接口
功能实现了,开发接口,python中可以使用 Flask、Django (类似 前端的koa和eggjs)框架开发即可,不再赘述
...
前端有了接口,距离一个产品的成型还远么

四、总结
看到这里,两个FLAG是否完成了呢?
-
了解 NLP的边界 和 目前最新的主流NLP模型有哪些
-
如果快速调用 一个NLP 模型
一点感悟:
放下心理负担: 作为没有接触过人工智能的前端开发,一开始面对 人工智能 容易产生畏惧心理。其实随着技术发展,很多技术都会产生分工现象(一部分工作越来越下沉,一部分工作越来越放低门槛),作为前端我们了解新技术的宏观面,对于新技术的边界范围有个认知即可
大白话:有很多现成的预训练model 可供直接使用,我们不用成为炼丹师,知道一个模型大体逻辑,成为调包侠即可
发挥 前端 优势: 前端是对于用户交互很敏感的一个群体,可以较快的找到产品痛点。我们是可以将一个nlp模型做一层包裹,创造一个个更具竞争力,更有趣的小产品
大白话:学会如何调用hugging face,你就可以将nlp等技术融入产品中,开发自己的智能产品 ~ 全栈gogogo
参考资料
[1]github: https://github.com/thunlp/WantWords
[2]Readme 描述: https://github.com/thunlp/WantWords/blob/main/README_ZH.md
[3]一个排名榜单: https://rajpurkar.github.io/SQuAD-explorer/