前端数据流选型
1 . 什么是数据流
什么是流?
在数学中,一个流用数学方式形式化了“取决于时间的变化”的一般想法。暂且定义流是响应时间变化的一个集合体。
什么是数据流
依据之前的定义,数据流即随时间变化的一个数据集合。
前端针对于现状mvvm模式下,数据即页面,在多数情况下,数据不变页面不变。那么我们转换一下,数据==>页面,数据流是否可以等价为一个页面的变化集合。这个是什么,就是我们的业务逻辑。
当然,前面的假设,是经过很多转化,其实有很多漏洞和错误。但是可以作为一个简单的参考。
这个不是数据流的定义,只是作为一个引子思考。

2 . 现行前端数据管理模式
现行三大数据管理方式
-
函数式、不可变、模式化。典型实现:Redux。
-
响应式、依赖追踪。典型实现:Mobx。
-
响应式,以流的形式实现。Rxjs、xstream。
Redux模式(reduck)
redux模式常规用法是作为整个应用全局状态管理使用。这只是作为一个提高跨组件通信的能力的工具。redux的思想是作为独立于组件的一个数据仓库,对数据进行保护,保障数据稳定可靠。
可以简单理解redux是一个带保护的全局使用的Context(useContext)。
针对于原生的提供了数据保护(dispatch+reducer),对于更改只允许使用dispatch进行更改。能够保障可回溯性,数据来源清晰,能够十分良好的隔绝副作用。
使用方面:
- 优点:数据隔离,数据变化可溯源。
- 缺点:多redux直接完全隔离,小型化困难,action方法容易膨胀。
- 业务方面使用:对于大型项目拆分设计概念不足,store数据个人管控不友好,容易造成理解困难逻辑修改困难。
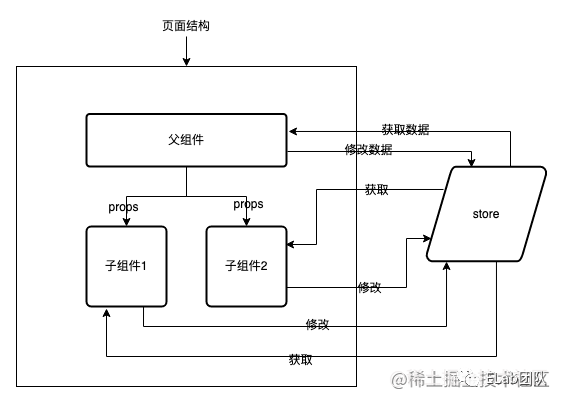
Mobx模式
mobx引入了全新的思想,将数据作为一个源头,拥有当数据变化时,通过计算状态,页面进行变化,并且根据observable,自动根据依赖执行更新。虽然有了action,但还是没有强制分离副作用。
mobx就好像将数据和组件进行绑定,形成依赖关系,自动订阅和自动发布,状态变更组件就变更。将逻辑和视图直接绑定在一起,这本应该是十分高效的情况,但是因为深入了组件,副作用的处理还是不够清晰,对于个人把控还是不够友好。
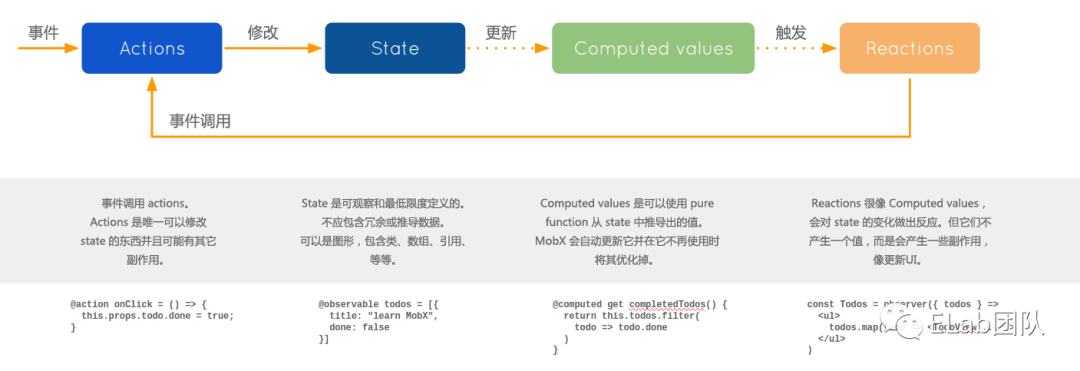
流模式(rxjs)
rxjs和mobx有些相似。rxjs将所有的数据都可以随意的拆散和组合成一个新的节点,可以简单理解为将redux的state进行了打散成多个数据节点,每一个任意节点都可以进行类似computed的计算生成新的节点。
流模式相较于redux模式没有action的规范,却定义了更改的节点范围,只能更改定义的入口节点(一条流的起始节点)。rxjs没有mobx从数据变化到页面变化这个功能,可以使用useState和useEffect实现或者现成的三方库rxjs-hooks。
rxjs的优势是,抽离所有数据源之后,剩余全部都是逻辑问题,副作用在抽离数据源的时候就已经剥离干净了(因为外部副作用数据也可以抽离成rxjs的节点),剩下就通过api和纯函数来编写具体的逻辑了。
又因为大量的api,拆解observable节点的成本极低,所以逻辑拆分十分容易,可读性十分高。
rxjs有推和拉的概念,在正常逻辑十分流畅的情况下,程序的代码应该是每个节点转变都会推动下一个节点的执行。在rxjs中将数据流进行串流好后,组件只要对于头部节点进行读写数据,对于尾部节点直接读取数据就可以,大部分逻辑全部被抽离出了组件。
使用方面:
- 优点:逻辑拆分简便,纯函数式编程。
- 缺点:数据拆分复杂,重设计,api学习和理解成本高。
理想情况下,页面就是一个个无状态组件,行为改变数据。数据变化又触发逻辑变更,逻辑变更数据。数据又回流到页面,这是一个整体的闭环,以数据为核心,完美的做到数据驱动页面。

新星 Recoil
recoil是facebook官方推荐的一个状态管理库,作为一个“新成员”,recoil相比于之前的三种状态管理方式,做了很多取舍。它有节点的概念,有atom(原子数据)和selector(派生数据)但是不和mobx一样,recoil是基于Immutable(不变)模式。
recoil的基础思想是atom数据之间没有关联,产生的关联数据全部由selector来产生,atom的变动,相关的selector随之变动,这个和响应式流的思想一致的。
recoil的优势,贴合react,可以将recoil的实现当作通过useMemo包装的context,api使用可以满足只读,只写进行拆分,可以十分贴合最优渲染,降低无用的渲染。
上述前三种数据流没有什么优劣好坏之分,只是在不同场景中使用各有各的优势而已。
3 . 理想中的源数据编程
数据与数据之间的关系
数据不是凭空产生的数据,数据可能又会产生新的数据。
数据之间推行的是最小可用原则,分而治之,这才更利于我们开发和维护。
个人把产生数据的起始数据定义为源数据。有些数据可以互相转换,那如何定义源数据???
定义源数据
从组件(页面)视角看一下数据。
- 面向接口编程
大部分情况下前端和后端之间的数据交互就只有接口这一种。又因为真实的所有数据都是从服务端获取的数据,所以下意识的以服务端接口为数据起始。数据处理的链路较长,范围变大对于个人的理解要求是十分高的,个人认为这对于一个大型应用是不健康的。
- 面向数据编程
分离接口请求,只关心组件状态,对于组件方面,任何数据不将其做区分,数据来就渲染。
个人将用户可交互的数据可以定义为源数据。因为前端接口请求也是由用户的信息请求来的。对于应用来说,只有用户的操作不可预知,其余操作都是可控的。
如果将可控的逻辑封装后抽离,管理的时候不需要再直接感知到这些,我们直面的就是用户的操作和页面的响应。
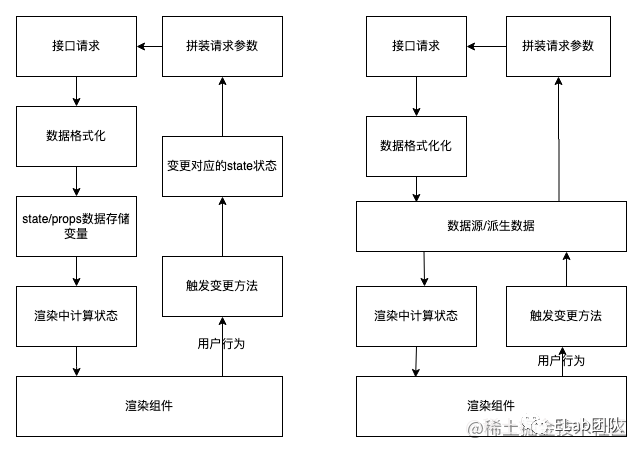
例如: 以单个列表页来说,用户选择的筛选项就是源数据,而接口请求回来的列表数据就是派生数据,由接口请求产生的页面loading态也可以是派生数据也可以是源数据。
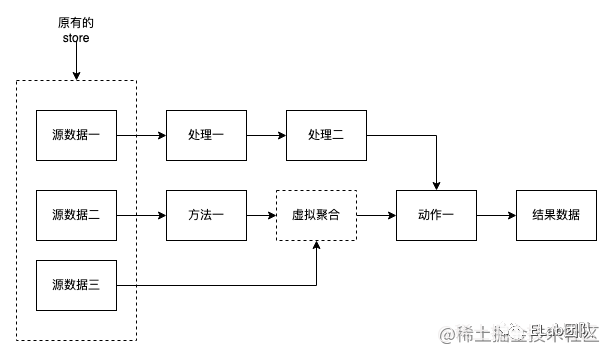
redux数据模型
在使用redux的时候没有很好的办法处理数据的层级关系,导致store中数据的池子越来越大,没有很强分层的概念,这也是redux小型化困难带来的,使用的时候会下意识将跨层级的数据存入store。
其次redux没法很好的描述数据与数据之间的关系,有人说computed可以描述数据与数据之间的关联,简单意义上是没问题的,但是computed的局限性,跨redux无法支撑,如果要使用,必须将所有源数据汇集到同一个redux之间,这与最小可用原则是相违背的。
就是因为redux的设计模式不够灵活,导致会将大量数据与数据之间的转化逻辑积压在页面或者组件内部,这对于视图层是一种负担。
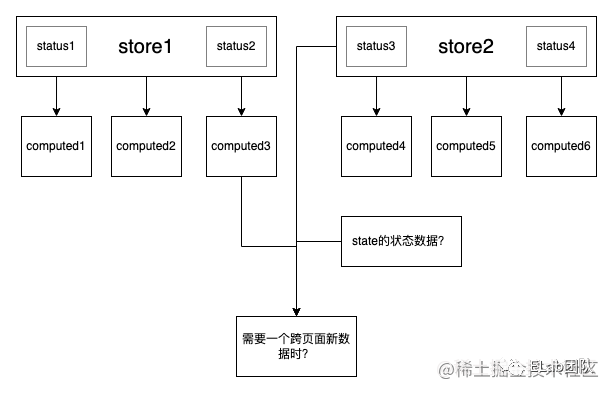
响应式流数据模型
为了方便理解,可以和之前一样将数据处理理解为computed,每一个节点都可以随意衍生出一个新的节点,但是触发整条流的变化又只会在初始节点(源数据)节点,使用整条流的结果。
在流模式中对于组件或页面外层的数据没有任何层次之分,每个节点都是平级的,如果分层,可以在业务上分层,通过不断的拼接,将业务逻辑进行串联,得出你想要的结果,相较于原先散乱在各地的逻辑,串联的流式逻辑在可读性上也更优。
流式数据的优点是拆分成本极低,这样也更符合我们的思想,代码块拆分,这样每一小块逻辑拆分出一个节点,逻辑复杂度就通过不断的拆解,变得十分低了,但是又不会因为拆解的过多,逻辑散乱。
- 没有固化数据的层级,离散的数据,可以自由定义和拼接。
- 以离散的数据,将逻辑串流,数据灵活之后,逻辑却是收敛,不会分散,做到了数据精准的使用。

reducx和rxjs的数据管理范围
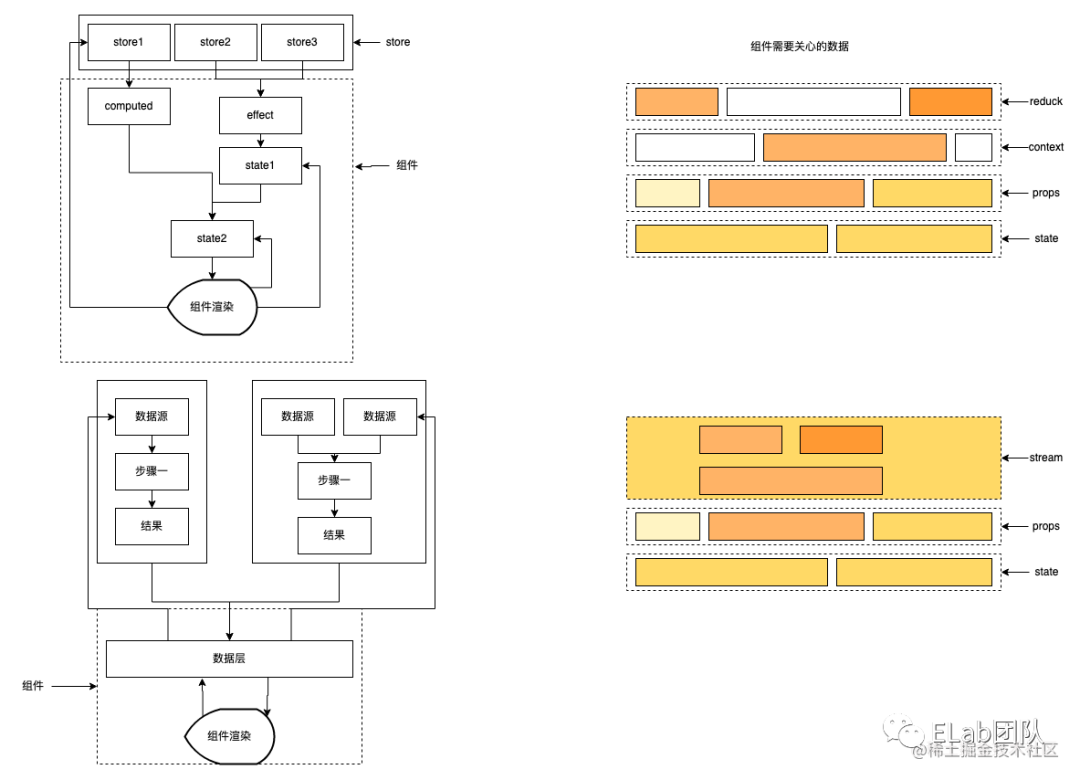
总结
综上所述,其实不同的模式带来的是针对不同场景的应用,redux的快捷应用,快捷开发,数据变化的稳定,mobx对于响应式的变化,都是各有各的特色。
在写代码的时候,我的感觉像是在构建一个动画的每一帧(视图),又要给出每一帧为什么变化(写逻辑,事件)的感觉,逻辑和视图混合在一起,对于整体的把控十分难处理,就像你需要对于整个动画的变化都掌握,抽离了视图和逻辑,逻辑只需要变化数据,视图只需要针对对应的数据变化而已。
参考文章
流动的数据——使用 RxJS 构造复杂单页应用的数据逻辑
精读《前端数据流哲学》