ESModule 加载与运行机制
ESModule 作为 JS 的标准模块机制,在日常开发中被广泛使用,但在大部分情况下,我们可能只是将其作为 JS 代码文件的组织形式来对待。作为 JS 的模块规范,ESModule 底层其实有一套非常完善的机制,来确保 ESModule 在不同场景下的性能以及行为的确定性。本文的主要内容是关于 ESModule 加载运行的相关原理和机制的分享,在理解了相关的原理和机制之后,你将会对平常在使用 ESModule 过程中遇到的一些问题(比如:循环引用在什么情况下会报错、TreeShaking 的原理等)有更加深入的理解。
从一个循环依赖例子说起
下面用一个包含循环引用的例子来分享 ESModule 的加载和执行过程-
// main.mjs
import { mod1Fn } from './mod1.mjs'
import { mod2Fn } from './mod2.mjs'
mod1Fn('main')
mod2Fn('main')
// mod1.mjs
import './mod2.mjs'
export let mod1Value = 'mod1Value'
export function mod1Fn(from) {
console.log(`${from} call mod1Fn\n`)
}
// mod2.mjs
import { mod1Fn, mod1Value } from './mod1.mjs'
export function mod2Fn(from) {
console.log(`${from} call mod1Fn\n`)
console.log('log mod1Value in mod2Fn')
console.log(mod1Value)
}
mod1Fn('mod2')
mod2Fn('mod2')
以上的代码内容分别描述了 main.mjs、mod1.mjs、mod2.mjs 3 个文件的内容,下面我们通过 node 来运行以上的代码,执行 node index.mjs ,输出结果如下
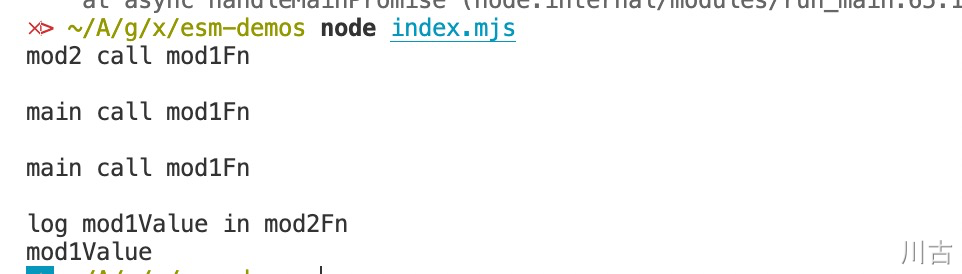
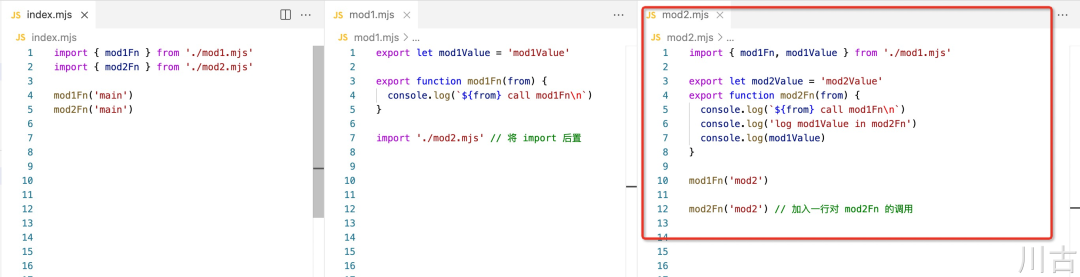
可以看出循环引用在 ESModule 中是可用的,但如果我们在 mod2.mjs 中增加一行调用 mod2Fn 的代码,如下所示:
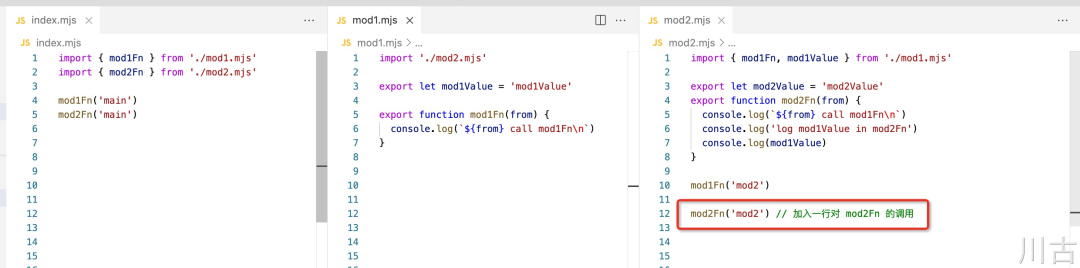
然后再执行代码,会发现实际执行会报错:
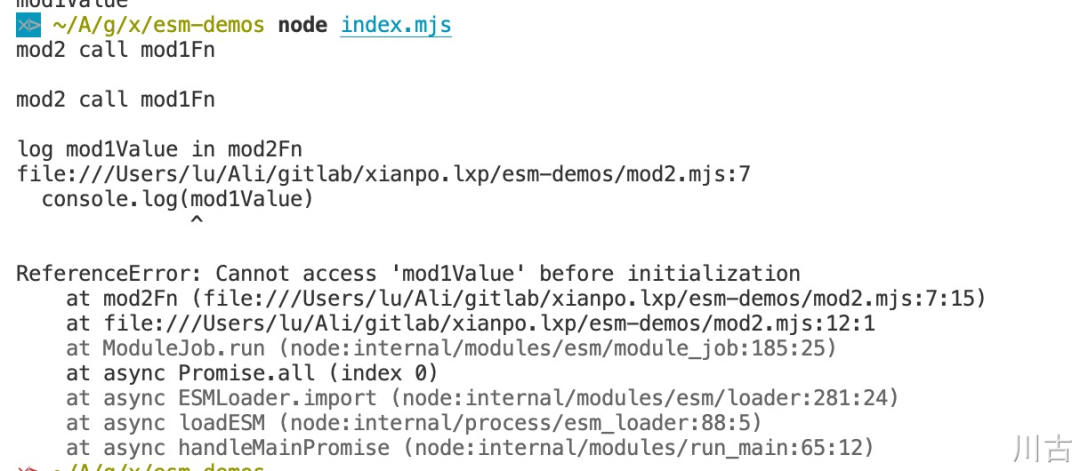
以上的报错是否似曾相识,从报错的信息我们大致可以推断出这个是一个和变量提升有关的报错,实际上报错的根因是在执行 mod2Fn('mod2') 时,mod1Value 还没有完成初始化,类似是下面这样的情况:
console.log(mod1Value)
let mod1Value = 'mod1Value'但是从直观上看,mod2.mjs 是在 mod1.mjs 之后加载的,为什么 mod1Value 会没有初始化呢,会不会是因为 import 的位置在 mod1Value 之前的原因,导致没有完成初始化呢,但实际上,即使将 mod2 的 import 后置,比如以下的代码
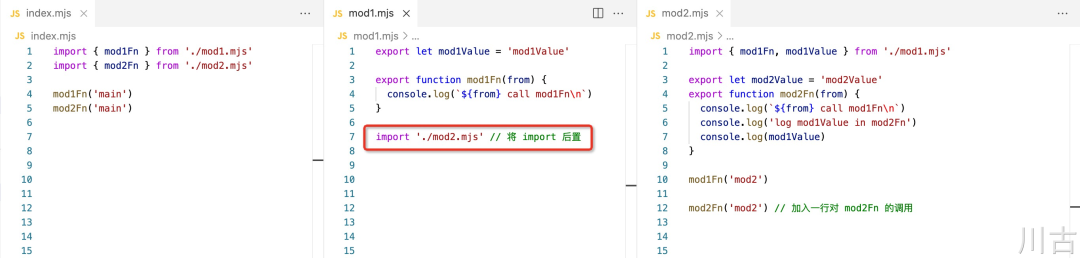
仍然还是会报错,因此我们可以得出报错的原因和 import 的位置是无关的。实际上 ESModule 的加载和执行过程并不是简单的一个按顺序执行的流程,下面我们从底层原理的角度,分享一下 ESModule 实际是如何被加载和执行的,以及会出现以上报错的原因。
ESModule 加载和执行过程解析
ESModule 的加载和解析过程整体上可以拆分为三个步骤:
- 获取代码和解析:建立模块之间连接
- 实例化模块:完成变量声明和环境对象(enviroment object)的绑定
- 执行代码:按照深度优先的顺序,逐行执行代码
下面我们还是以上面的代码为例,分享实际的过程
▐ 获取代码和解析:建立模块之间连接
首先浏览器或者 Node 等应用程序会通过网络请求或文件读写等形式获取到对应的 ESModule 的代码,比如上文中的代码 node main.mjs Node 会逐步执行以下操作:
- 通过文件读写的方式,读取 main.mjs 的文件内容,记录到 ESModule 中
- 逐行解析 JS 代码,获取依赖的 ESModule 的地址
- 然后继续加载对应依赖的模块,重复第一步的操作,直到所有的 ESModule 都完成了加载
在完成这一步之后,我们会得到下面这样一张图
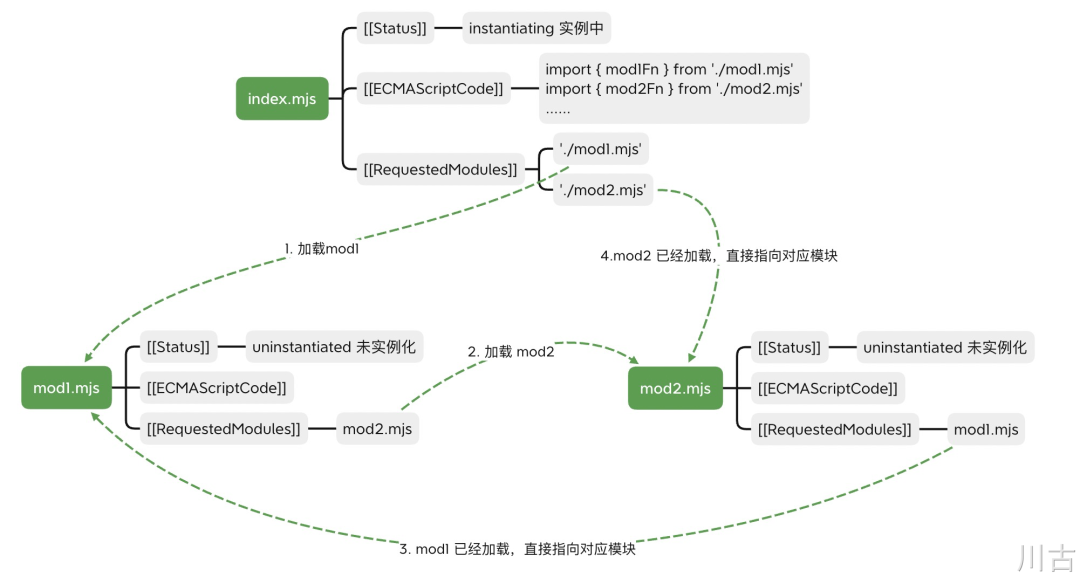
值得关注的是,以上的这些过程 JS 代码还没有被执行,是通过解析代码文本的方式,完成了模块的依赖解析和加载,以及建立模块之间的依赖关系。
▐ 实例化模块:完成声明和环境对象(enviroment object)的绑定
上面一步完成了模块之间的依赖关系生成,接下来实例化本质上是更进一步,完成每个模块内部的变量的声明以及构建模块间的引用关系。在这个过程中有几个要注意的点:
- 每个模块都会有各自环境对象且相互隔离,这也是不同模块可以有相同的名字的函数、变量而不会冲突的原因
- function、var 的变量提升的特性在这个场景下也适用,function 会直接完成初始化,var 则会初始化为 undefined
还是以上面的例子为例,完成实例化之后我们会得到以下的依赖关系,具体的结果可见下图:
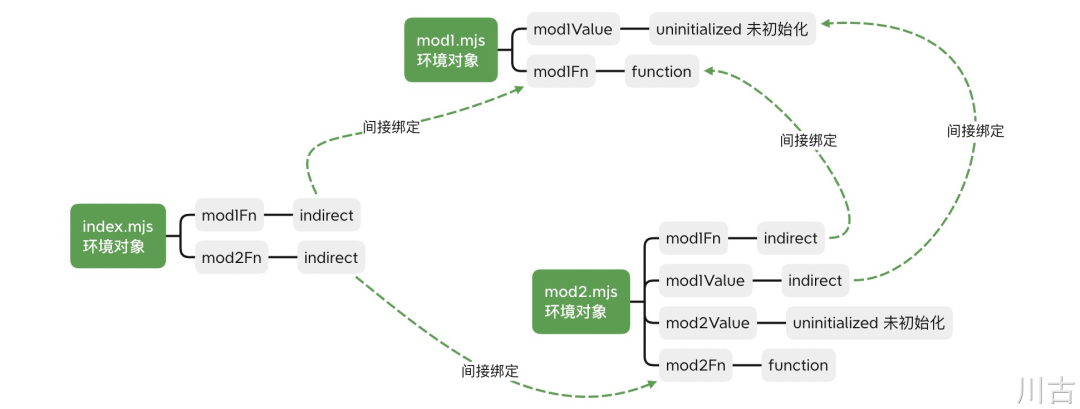
绑定的过程会有两种形式:
- 使用 import 的方式引入的,则会在当前模块生成一个间接绑定,指向对应的来源对象,比如 index.mjs 中的 mod1Fn
- 如果是在当前模块声明的,则直接绑定到当前的对象,比如 mod1.mjs 中的 mod1Fn
同样在这一个步骤,JS 代码仍然没有进入执行阶段
▐ 执行代码:按照深度优先的顺序,逐行执行代码
接下来进入实际的执行代码阶段,也是 JS 引擎开始执行代码的时机。整体的执行策略会遵循两个大的规则:
- 按照深度优先的顺序,首先执行最深的依赖的模块代码
- 每个模块的代码只会被执行一次
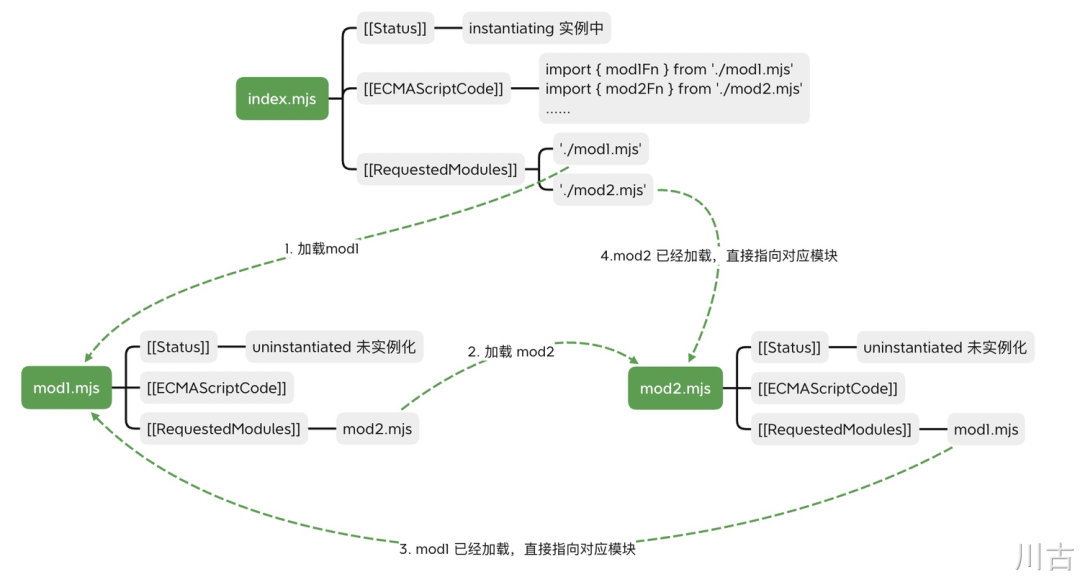
由第1阶段的依赖关系图,我们可以看出,依赖最深的是 mod2.mjs,所有 JS 引擎会先执行 mod2.mjs 中的代码,即:
然后根据第 2 阶段实例化代码得的到绑定关系图,会先执行以下红框中的部分
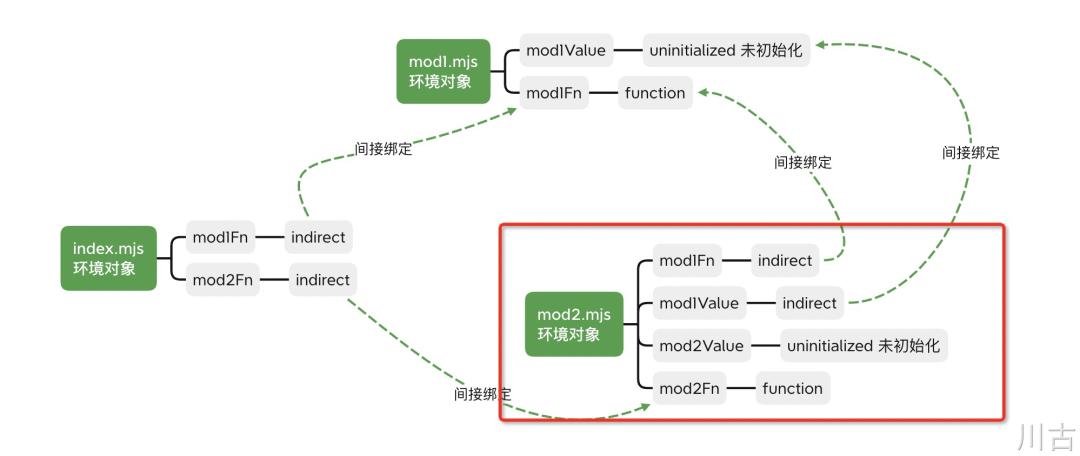
从上往下依次执行 mod2 中的代码,在执行到 12 行 mod2Fn('mod2') 时,mod2Fn 在第 7 行依赖了 mod1Value,而由上图我们可以看到,mod1Value 的状态是还未初始化,因此在执行 console.log(mod1Value) 时,代码会抛出没有初始化的错误。如果将 mod1.mjs 中的 let mod1Value 改为 var mod1Value,由于 var 天然有变量提升的特性,会先初始化为 undefined,实际运行时不会报错,会输出 undefined。
我们可以看出 ESModule import 不是简单的类似 require 的同步加载机制,下面我们来分析一下相比于同步的加载方式,ESModule 的加载策略上有哪些优势。
ESModule 加载运行策略相比于同步的方式又哪些优势
▐ 能够用更快的速度并发加载代码资源
在 Web 领域,网络的加载耗时一直是用户体验非常重要的影响因子,在 ESModule 的策略下,实际模块的依赖的解析不需要依赖代码的执行,而是直接通过静态分析的方式进行,这使得浏览器、Node 等应用可以用尽可能快的速度完成依赖的收集和资源的请求,而不会受具体模块代码执行耗时以及前后顺序的影响,可以使用尽可能多的并发请求来快速完成加载。
同时从最开始的例子中可以看出,在 ESModule 中 import 在文件的中的位置不会影响具体的行为表现,这使得浏览器可以进行类似 HTML 流式渲染一样,对 ESModule 进行 “流式加载”,比如一个 JS 文件有 1000 行,如果第一行写了一个 import,浏览器就可以直接进行对应模块的加载,而无需等待文件加载完成在进行下一个模块的加载。
▐ 支持 TreeShaking 的自动优化
ESModule 在实例化的阶段会完成相关变量的声明和绑定,在这个阶段我们可以得到对应的绑定关系图,比如之前例子中的以下这张图
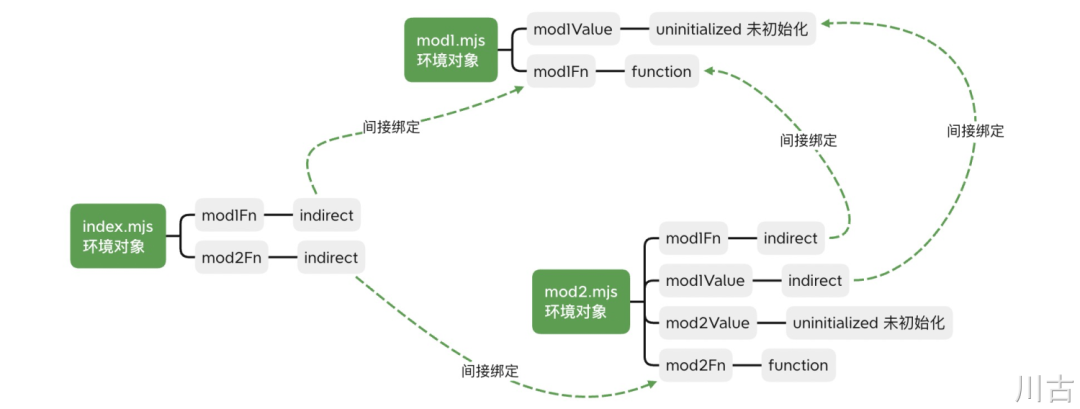
通过这张图我们可以明确的看出 mod2Value 没有被其他模块所引用,从而我们只需要判断在 mod2 内也没有使用 mod2Value ,则 mod2Value 相关的代码是无用的,这也是 TreeShaking 的原理。而在这一阶段,实际的代码还没有被执行,以上的依赖关系完全是按照代码文本的静态分析得出,所以这也保证了,我们在构建时也可以模拟浏览器或Node 进行类似的操作,生成对应的依赖关系图,然后针对单个模块分析哪些方法或变量时没有用,对代码进行自动的删减。
结语
本文简要的介绍了 ESModule 加载和执行的整体过程,在研究的过程也深刻感受到了 ESModule 整体规范的严谨性和完善性,考虑了诸多不同的方面,并不是简单的 CommonJS 的升级版本。对于底层原理更加深入的理解,也能够指导我们在使用一些新的技术能够更有方向性,比如 TreeShaking ,实际上就是充分利用了 ESModule 的规范,实现了非常优雅的代码自动剔除,能够保证几乎 0 成本的代码体积最优。实际上 ESModule 还有很多其他内容,比如 dynamic import、top level await 等,可以值得更多的研究和探索。