Systrace 线程 CPU 运行状态分析技巧 - Runnable
Runnable 状态 在 Systrace 中的显示方式
Perfetto/Systrace: 不同 CPU 运行状态异常原因 101 - Running 长[1] 中讲解了导致 CPU 的 Running 状态耗时久的原因与优化方法,这一节介绍 Runnable 状态切换原理与对应的排查与优化思路。在 Systrace 中显示为蓝色,表示线程处于 Runnable,等待被 CPU 调度执行。
Systrace 中 Runnable 的可视化效果展示如下,点击就可以查看 wakeup 信息(不一定有)
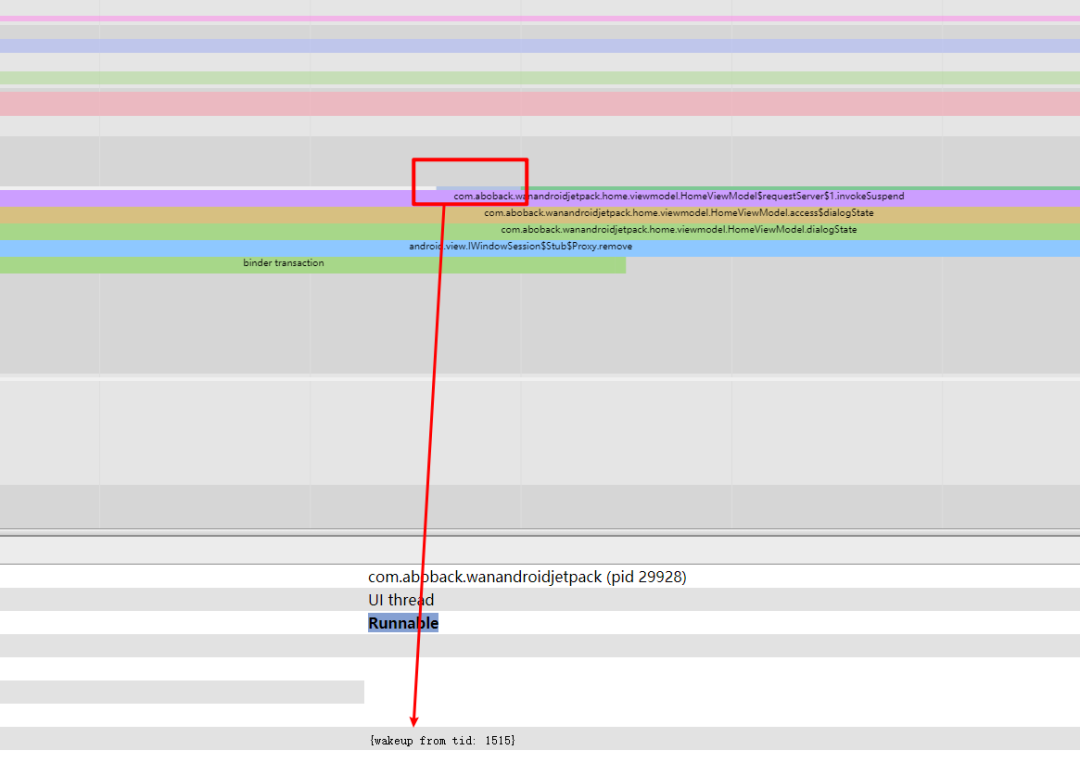
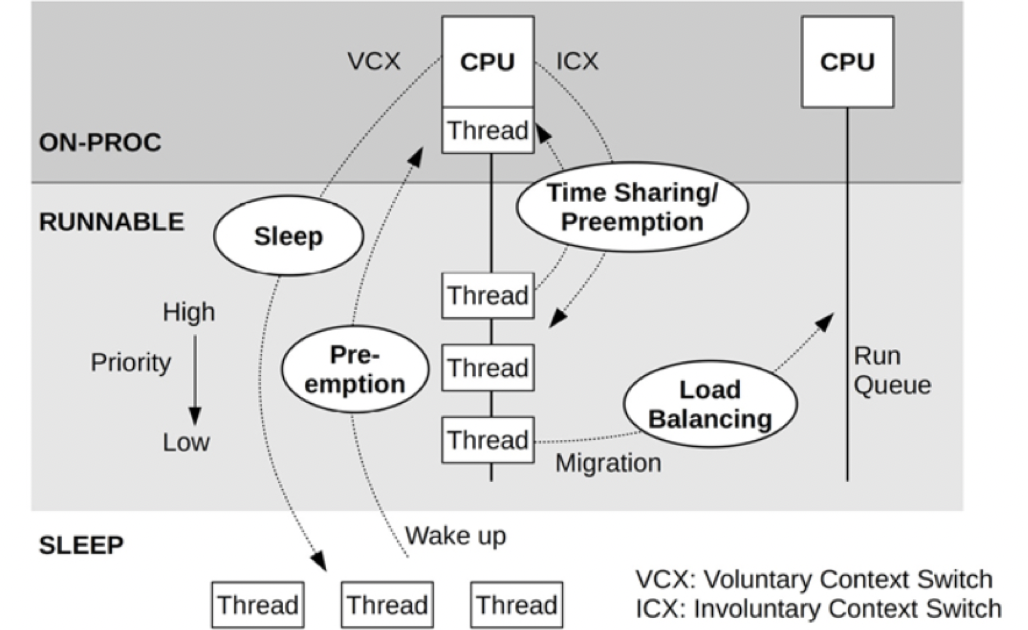
从图 2 可知,一个 CPU 核在某个时刻只能执行一个线程,因此所有待执行的任务都在一个「可执行队列」里排队,一个 CPU 核就有一个队列。能插入到这个队列里排队的,代表着这个线程除了 CPU 资源,其他资源均已获取,如 IO、锁、信号量等。处于「可执行队列」的时候,线程的状态就会被置为 RUNNABLE,也就是 Systrace 里看到的 Runnable 状态。
Linux 内核是通过赋予不同线程执行时间片并通过轮转的方式来达到同时执行多个线程的效果,因此当一个 Running 中的线程的时间片用完时(通常是 ms 级别)将此线程置为 Runnable,等待下一次被调度。也有比较特殊的情况,那就是抢占。有些高优先级的线程可以抢占当前执行的线程,而不必等到此线程的时间片到期。
当一个 CPU 有多个核的时候显然可以多个核同时工作,这时候不必都在一个 CPU 核上排队,根据负载情况(也就是排队情况),将线程迁移到其他核执行是必要的操作。掌管这些调度策略的,是通过 Linux 的调度器来实现的,它具体通过多个调度类(Schedule Class)来管理不同线程的优先级,常见的有:
- SCHED_RR、SCHED_FIFO: 实时调度类,整体优先级上高于 NORMAL。
- SCHED_NORMAL: 普通调度类,目前常用的是 CFS(Complete Fair Scheduler)调度器。实时类的优先级高于普通调度类,高优先级的能抢占低优先级,并且要等待高优先级的执行完才能执行低优先级的。一般情况下 Runnable 的时间都很短,但出异常的的时候它会影响关键线程的关键任务在指定时间内完成。

这个可能不止是一个线程,甚至是多个。特别是涉及到 UI 相关的任务,这种情况就更为复杂了。AOSP 体系下典型的一帧绘制是经过 UI Thread → Render Thread → SurfaceFlinger → HWC(参考 图 3),其中任何一个线程被 Runnable 阻塞导致没有在规定时间内完成渲染任务,都将会导致界面的卡顿(也就是掉帧)。我们从实践中总结出以下 5 大门类,系统层面出异常的原因较多,但也见过应用自身逻辑导致 Runnable 过长情况。
原因 1: 优先级设置错误
- 应用设置了过高的优先级:至于抢占了其他线程的任务,对后者来说显得自己优先级太低了。
- 应用设置了过低的优先级:当此线程处于「关键链路」时,以 Runnable 执行的概率就越高,导致卡顿概率也高。
- 系统出 Bug 时把线程优先级设为过高或者过低。
优化思路:
- 应用视情况调整线程优先级,可从 Trace 中可以看到是被哪个线程抢占了。
- 系统将关键线程调度策略设置成 FIFO。
我们在实践中见到过不少应用因为设置错了优先级反而导致更卡。原因比较复杂,可能开发者所使用的机器用当时的优先级策略没问题,但是在别的厂商的调度器(头部大厂基本都有自己改动调度器)下就会出现水土不兼容的情况。一般情况下,三方应用开发者不建议直接调用这类 API,弄巧成拙,屡见不鲜。
长远看来更靠谱的方式是合理安排自己的任务模型,不要把对实时性要求很高的任务放到 worker 线程上。
原因 2: 绑核不合理
有时候为了让线程运行得更快,会把线程绑定到大核,在前面解决 Running 时间长时也有建议绑大核,但是绑核一定要谨慎,因为一旦把线程绑定在某个核,表示线程只能运行在这个核上即使其它核很空闲。如果多个线程都绑定在某个核,当这个核很繁忙调度不过来时,这些线程就会出现 Runnable 时间很长的情况。所以绑核一定要谨慎!下面是绑核需要注意的一些事项:
- 线程绑核不要绑定在单个核上,这样容错率会特别低,因为一旦这个核被其它线程抢占绑定这个核的线程就要等着,所以尽量以 CPU 簇为单位进行绑核,比如线程要绑定大核,可以指定 4-7 大核而不是指定某个一大核。
- 2 个大核平台尽可能减少绑定大的核线程数目,不然会使得大核很容易繁忙,把绑核会变成「负优化」。
- 要正确区分大小核,比如 8 个核的平台,4-7 不一定就是大核,有的平台可能 0-3 才是大核。
- 只能在 CPUSET 允许范围内绑核,如果 CPUSET 只允许进程跑 0-3,如果进程试图绑定在 4-7 会绑核失败,甚至会有一些意料之外的致命错误。
原因 3: 软件架构设计不合理
重申下,Runnable 是指在 CPU 核上的排队耗时,按常识可可知道排队长、频繁排队时出问题概率也就越高。一个绘制任务所依赖的线程数量越多,出问题的概率也越高,因为排队次数变多了嘛。
软件架构不止要满足业务需求,也要在性能、扩展性方面上做思考,从上面推导可知,如果你程序编程模型需要大量线程协同运行来完成关键操作,如绘制,那出问题的概率就越高。
最常见的有,两个线程之间有频繁的有通讯与等待(线程 A 把任务转移到线程 B 执行,A 等待 B 任务执行完后被唤醒), CPU 繁忙时很容易打出 Runnable 等待状态,CPU 越忙概率越高。
优化思路:
- 应用调整线程优先级,见「原因 1」。
- 优化代码架构/逻辑,免频繁等待其他线程的唤醒,在 Trace 中可以看到线程的依赖关系。可借助 CPU Profiler 探查代码执行逻辑,提高分析唤醒关系的效率。
- 平台通过修改调度器来识别有关系链的线程组,优先调度这个组里的线程。
原因 4: 应用自己或系统整体负载高导致排队的任务非常多
从上述的调度原理可知,如果大量任务挤在一个核的「可执行队列」上,显然越是后面,优先级越低的任务排队时间就越长。
排查的时候你可以在 Perfetto/Systrace 的 CPU 核维度任务上,即使在放大后的界面看到排满了密密麻麻的任务,这基本上就意味着系统整体负载较高了。通过计算,可算出 CPU 每时刻的使用量,基本上都会在 90%以上。你可以通过选择一个区间,以时间来排序,看看都在执行什么任务,以此来逐个排查同时执行大量程序的原因是什么。
简单总结就是,同时执行的任务太多了,主要原因来自两方面:
1.应用自身高占用
应用自身就把 CPU 资源都给占满了,狂开十来个线程来做事情,即使是头部大厂也会做这种事。
优化建议:
- 找出应用所有占用高的线程,看看各线程此刻跑起来的行为是否异常,如果异常则要优化它。
- 优化线程负载本身,可使用 simpleperf 等工具进行函数级别的定位。
- 调整优先级,使用比 CFS 更高优先级的调度器,如设置为 RT。不过它带来的隐患也较多,需要慎重。
- 优化软件架构,区分关键与非关键线程,通过合理设置「绑核 & 优先级」来为关键线程让出资源。如,不重要线程绑到小核运行或设置低优先级、渲染相关线程设置高优先级等,让渲染线程相关的线程能占用到更多的 CPU 资源。设计架构的时候一定要考虑运行环境恶劣的情况,因为安卓从设计上就不敢保证所有资源都优先供给你,肯定有别人跟你抢资源。
2.系统服务高占用
有的厂商 ROM 自己本身就有很多任务,设计不合理的话自己家程序就吃满了大量资源,导致留给应用运行的资源较少。还有些是管控措施设计的一般,以至于留给了大量流氓应用可乘之机,各路神仙利用自己的「黑科技」在后台保活后进行各种拉活同步操作。
3.平台厂家的黑科技
厂家除了要优化自身服务,以做到「点到为止」外,可以实现如下功能来尽可能把资源分配合理化,让出更多资源给前台应用。
1 . 通过 CGROUP 的 CPUSET 子系统,让不同优先级的线程运行在不同的 CPU 核心。AOSP 自带了 CPUSET 分组功能,不过有些缺陷如:
a . 分组不够精细,很多后台都可以跑满所有核
b . 没有考虑进程的工作状态,如 音乐、导航、录音、视频、通话、下载
c . 对 Java 进程 fork 的子进程放任不管
2 . 通过 CGROUP 的 CPUCTL 子系统,进行资源配额,如限制异常进程、普通后台进程的不同量级的 CPU 最高使用量。
3 . 通过线程&进程级别的冻结技术,在应用退出后台之后冻结进程让其拿不到 CPU 资源,类似 iOS 的做法。难点在于:
a . 切断和恢复各跨进程通信
b . 进程关系的梳理
c . 兼容性问题,需要有大量的测试验证
4 . 按需启动系统进程与管控好后台进程自启动。
每一个优化说简单也简单,说难也难,依赖厂家的技术积累。
原因 5: CPU 算力限制、锁频、锁核、状态异常
排队做核酸检测一样,检测窗口多的队列排队时间少。CPU 算力差、关核、限频,导致 Runnable 的概率也更高。通常的原因有:
- 场景控制
- 不同场景模式下的不同频率、核心策略
- 高温下的锁频锁核
2 . CPU 省电模式,如高通的 Low Power Mode。
3 . CPU 状态切换,如 C2/C1 切换到 C0 耗时久。
4 . CPU 损坏,概率小但也有可能会出现。
5 . 低端机 :安卓上的低端机。
其中:
- 原因 1 场景控制, 考验厂家的能力与各自的标准,应用程序能做的还是那句名言 → 降低自己负载,少惹平台。厂家为了设计好「场景控制」,需要有精细化的场景识别与合理的控制能力,将功耗与性能的平衡做到全局最优化,不同场景下应突出不同的业务能力,而不是一杆子拍死。
- 高温下的优化建议请参考「Perfetto/Systrace: 不同 CPU 运行状态异常原因 101 - Running 长[2]」中的「原因 5: 温升导致 CPU 关核、限频」。
- 原因 3 CPU 状态切换 是芯片固有的特性,出现的概率小,但也不是不可能,每个芯片架构升级换代的时候就时不时遇到「妥协」版的 CPU 产品。厂家对芯片的评估是个比较隐性的能力,很少会被大众提及,但是非常重要的一个能力。电子消费品历史中,也总是重演关键器件选错了,导致厂家走入万劫不复境地的真实案例。
- 原因 5,安卓上的低端机,真的就指配备里低算力的 CPU,这与苹果的做法不一样,它的 CPU 至少跟当期旗舰是一样的。同样参考 「Perfetto/Systrace: 不同 CPU 运行状态异常原因 101 - Running 长[3]」中的「原因 6: 算力弱」。
原因 6: 调度器异常
几乎所有的厂家都做了调度器优化方面的工作,虽然概率小,但也有可能会出异常。场景锁频锁核机制有问题、内核各种 governor 的出问题的时候,会出现明明 CPU 的其他核都很闲,但任务都挤在某几个核上。
系统开发者能做的就是把基础「可观测性技术」建好,出问题时可以快速诊断,因为这类问题一是不好复现,二是现象出现时机较短,可能立马就恢复了。
原因 7: 处理器区分执行 32 位与 64 位进程
有些过渡期的芯片,如最近推出的骁龙 8Gen1 与 天玑 9000,会有非常奇葩的运行限制。32 位的程序只能运行某个特定微架构上,64 位的则畅通无阻。且先不说这种「脑残设计」是处于什么所谓「平衡」,他带来的问题是,当你用的应用大量还是 32 位的时候,很多任务(以进程为单位)都挤在某个核心上运行,结合前面的理论,都挤在一起,出现 Runnable 的概率就更高。
- 对应用开发者,建议尽快升级至 64 位程序。如果你用的是第三方方案,尽早通知改进或者改用其他方案。
- 对系统开发者,一是根据问题联系应用厂商做更新,二是特殊加强后台管理功能,进一步降低 32 位程序的运行负载。
参考资料
[1]Perfetto/Systrace: 不同 CPU 运行状态异常原因 101 - Running 长: https://articles.zsxq.com/id_bp46saqr6ish.html
[2]Perfetto/Systrace: 不同 CPU 运行状态异常原因 101 - Running 长: https://articles.zsxq.com/id_bp46saqr6ish.html
[3]Perfetto/Systrace: 不同 CPU 运行状态异常原因 101 - Running 长: https://articles.zsxq.com/id_bp46saqr6ish.html