好代码和坏代码
要写出好代码,首先需要提升品位。
很多软件工程师写不好代码,在评审他人的代码时也看不出问题,就是因为缺乏对好代码标准的认识。
现在还有太多的软件工程师认为,代码只要可以正确执行就可以了。这是一种非常低的评价标准,很多重要的方面都被忽视了。
好代码的特性
好代码具有以下特性。
1. 鲁棒(Solid and Robust)
代码不仅要被正确执行,我们还要考虑对各种错误情况的处理,比如各种系统调用和函数调用的异常情况,系统相关组件的异常和错误。
对很多产品级的程序来说,异常和错误处理的逻辑占了很大比例。
2. 高效(Fast)
程序的运行应使用尽量少的资源。资源不仅仅包括CPU,还可能包括存储、I/O等。
设计高效的程序,会运用到数据结构和算法方面的知识,同时要考虑到程序运行时的各种约束条件。
3. 简洁(Maintainable and Simple)
代码的逻辑要尽量简明易懂,代码要具有很好的可维护性。对于同样的目标,能够使用简单清楚的方法达成,就不要使用复杂晦涩的方法。
“大道至简”,能否把复杂的问题用简单的方式实现出来,这是一种编程水平的体现。
4. 简短(Small)
在某种意义上,代码的复杂度和维护成本是和代码的规模直接相关的。在实现同样功能的时候,要尽量将代码写得简短一些。
简洁高于简短。这里要注意,某些人为了能把代码写得简短,使用了一些晦涩难懂的描述方式,降低了代码的可读性。这种方式是不可取的。
5. 可测试(Testable)
代码的正确性要通过测试来保证,尤其是在敏捷的场景下,更需要依赖可自动回归执行的测试用例。
在代码的设计中,要考虑如何使代码可测、易测。一个比较好的实践是使用TDD(Test-Driven Development,测试驱动开发)的方法,这样在编写测试用例的时候会很快发现代码在可测试性方面的问题。
6. 共享(Re-Usable)
大量的程序实际上都使用了类似的框架或逻辑。由于目前开源代码的大量普及,很多功能并不需要重复开发,只进行引用和使用即可。
在一个组织内部,应鼓励共享和重用代码,这样可以有效降低代码研发的成本,并提升代码的质量。
实现代码的共享,不仅需要在意识方面提升,还需要具有相关的能力(如编写独立、高质量的代码库)及相关基础设施的支持(如代码搜索、代码引用机制)。
7. 可移植(Portable)
某些程序需要在多种操作系统下运行,在这种情况下,代码的可移植性成为一种必需的能力。
要让代码具有可移植性,需要对所运行的各种操作系统底层有充分的理解和统一抽象。一般会使用一个适配层来屏蔽操作系统底层的差异。
一些编程语言也提供了多操作系统的可移植性,如很多基于Python语言、Java语言、Go语言编写的程序,都可以跨平台运行。
8. 可观测(Observable) / 可监控(Monitorable)
面对目前大量存在的在线服务(Online Service)程序,需要具备对程序的运行状态进行细致而持续监控的能力。
这要求在程序设计时就提供相关的机制,包括程序状态的收集、保存和对外输出。
9. 可运维(Operational)
可运维已经成为软件研发活动的重要组成部分,可运维重点关注成本、效率和稳定性三个方面。
程序的可运维性和程序的设计、编写紧密相关,如果在程序设计阶段就没有考虑可运维性,那么程序运行的运维目标则难以达成。
10. 可扩展(Scalable and Extensible)
可扩展包含“容量可扩展”(Scalable)和“功能可扩展”(Extensible)两方面。
在互联网公司的系统设计中,“容量可扩展”是重要的设计目标之一。系统要尽量支持通过增加资源来实现容量的线性提高。
快速响应需求的变化,是互联网公司的另外一个重要挑战。可考虑使用插件式的程序设计方式,以容纳未来可能新增的功能,也可考虑使用类似Protocol Buffer 这样的工具,支持对协议新增字段。
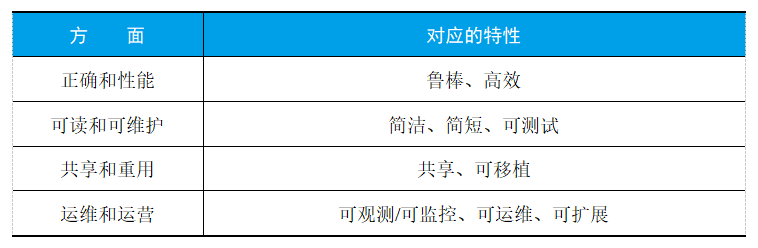
以上十条标准,如果要记住,可能有些困难。我们可以把它们归纳为四个方面,见表1。
表1 对一流代码特性的汇总分类
坏代码的例子
关于好代码,上面介绍了一些特性,本节也给出坏代码(Bad Code)的几个例子。关于坏代码,本书没有做系统性总结,只是希望通过以下这些例子的展示让读者对坏代码有直观的感觉。
1. 不好的函数名称(Bad Function Name)
如do(),这样的函数名称没有多少信息量;又如myFunc(),这样的函数名称,个人色彩过于强烈,也没有足够的信息量。
2. 不好的变量名称(Bad Variable Name)
如a、b、c、i、j、k、temp,这样的变量名称在很多教科书中经常出现,很多人在上学期间写代码时也会经常这样用。如果作为局部变量,这样的名称有时是可以接受的;但如果作为作用域稍微大的变量,这样的名称就非常不可取了。
3. 没有注释(No Comments)
有写注释习惯的软件工程师很少,很多软件工程师认为写注释是浪费时间,是“额外”的工作。但是没有注释的代码,阅读的成本会比较高。
4. 函数不是单一目的(The Function has No Single Purpose)
如LoadFromFileAndCalculate()。这个例子是我编造的,但现实中这样的函数其实不少。很多函数在首次写出来的时候,就很难表述清楚其用途;还有一些函数随着功能的扩展,变得越来越庞杂,也就慢慢地说不清它的目的了。
这方面的问题可能很多人都没有充分地认识到——非单一目的的函数难以维护,也难以复用。
5. 不好的排版(Bad Layout)
不少人认为,程序可以正常执行就行了,所以一些软件工程师不重视对代码的排版,认为这仅仅是一种“形式”。
没有排好版的程序,在阅读效率方面会带来严重问题。这里举一个极端的例子:对于C语言来说,“;”可作为语句的分割符,而“缩进”和“换行”对于编译器来说是无用的,所以完全可以把一段C语言程序都“压缩”在一行内。这样的程序是可以运行的,但是对人来说,可读性非常差。这样的程序肯定是我们非常不希望看到的。
6. 无法测试(None Testable)
程序的正确性要依赖测试来保证(虽然测试并不能保证程序完全无错)。无法或不好为之编写测试用例的程序,是很难有质量保证的。
好代码从哪里来
上一节说明了好代码的特性,本节来分析好代码是如何产出的。
▊ 好代码不止于编码
好代码从哪里来?
对于这个问题,很多读者肯定会说:“好代码肯定是写出来的呀。”
我曾做过多次调研,发现很多软件工程师日常所读的书确实是和“写代码”紧密相关的。
但是,这里要告诉读者的是,代码不只是“写”出来的。在很多年前,我所读的软件工程方面的教科书就告诉我,编码的时间一般只占一个项目所花时间的 10%。我曾说过一句比较有趣的话:
“如果一个从业者告诉你,他的大部分时间都在写代码,那么他大概率不是一个高级软件工程师。”
那么,软件工程师的时间都花到哪里去了呢?软件工程师的时间应该花在哪里呢?
好的代码是多个工作环节的综合结果。
(1)在编码前,需要做好需求分析和系统设计。而这两项工作是经常被大量软件工程师忽略或轻视的环节。
(2)在编码时,需要编写代码和编写单元测试。对于“编写代码”,读者都了解;而对于“编写单元测试”,有些软件工程师就不认同了,甚至还有人误以为单元测试是由测试工程师来编写的。
(3)在编码后,要做集成测试、上线,以及持续运营/迭代改进。这几件事情都是要花费不少精力的,比如上线,不仅仅要做程序部署,而且要考虑程序是如何被监控的。有时,为了一段程序的上线,设计和实施监控的方案要花费好几天才能完成。
因此,一个好的系统或产品是以上这些环节持续循环执行的结果。
▊ 需求分析和系统设计
1. 几种常见的错误现象
相对于编码工作,需求分析和系统设计是两个经常被忽视的环节。在现实工作中,我们经常会看到以下这些现象。
(1)很多人错误地认为,写代码才是最重要的事情。不少软件工程师如果一天没有写出几行代码,就会认为工作没有进展;很多管理者也会以代码的产出量作为衡量工作结果的主要标准,催促软件工程师尽早开始写代码。
(2)有太多的从业者,在没有搞清楚项目目标之前就已经开始编码了。在很多时候,项目目标都是通过并不准确的口头沟通来确定的。例如:
“需要做什么?”
“就按照×××网站的做一个吧。”
(3)有太多的从业者,在代码编写基本完成后,才发现设计思路是有问题的。他们在很多项目上花费很少(甚至没有花费)时间进行系统设计,对于在设计中所隐藏的问题并没有仔细思考和求证。基于这样的设计投入和设计质量,项目出现设计失误也是很难避免的。而面对一个已经完成了基本编码的项目,如果要“动大手术”来修改它,相信每个有过类似经历的人都一定深知那种感受——越改越乱,越改越着急。
以上这几种情况,很多读者是不是都有过类似经历?
2. 研发前期多投入,收益更大
关于软件研发,首先我们需要建立一个非常重要的观念。
在研发前期(需求分析和系统设计)多投入资源,相对于把资源都投入在研发后期(编码、测试等),其收益更大。
这是为什么呢?
要回答这个问题,需要从软件研发全生命周期的角度来考量软件研发的成本。除编码外,软件测试、上线、调试等都需要很高成本。如果我们把需求搞错了,那么与错误需求有关的设计、编码、测试、上线等成本就都浪费了;如果我们把设计搞错了,那么与错误设计相关的编码、测试、上线的成本也就浪费了。
如果仔细考量那些低效的项目,会发现有非常多的类似于上面提到的“浪费”的地方。软件工程师似乎都很忙,但是在错误方向上所做的所有努力并不会产生任何价值,而大部分的加班实际上是在做错误的事情,或者是为了补救错误而努力。在这种情况下,将更多的资源和注意力向研发前期倾斜会立刻收到良好的效果。
3. 修改代码和修改文档,哪个成本更高
很多软件工程师不愿意做需求分析和系统设计,是因为对“写文档”有着根深蒂固的偏见。这里问大家一个问题,如果大家对这个问题能给出正确的回答,那么在“写文档”的意识方面,一定会有很大的转变。
任何人都不是神仙,无法一次就把所有事情做对。对于一段程序来说,它一定要经过一定周期的修改和迭代。这时有两种选择:
选择一:修改文档。在设计文档时完成迭代调整,待没有大问题后再开始编码。
选择二:修改代码。只有粗略的设计文档,或者没有设计文档,直接开始编码,所有的迭代调整都在代码上完成。
请大家判断,修改代码和修改文档,哪个成本更高?
在之前的一些分享交流会上,对于这个问题,有人会说,修改文档的成本更高。因为在修改文档后还要修改代码,多了一道手续。而直接修改代码,只需要做一次,这样更直接。
这个回答说明了回答者没有充分理解“先写文档,后写代码”的设计方法。如果没有充分重视设计文档的工作,在输出的设计文档质量不高的情况下就开始编码,确实会出现以上提到的问题。但是,如果在设计文档阶段就已经做了充分考虑,会减少对代码的迭代和反复。
对于同样的设计修改,“修改代码”的成本远高于“修改文档”。这是因为,在设计文档中只会涉及主要的逻辑,那些细小的、显而易见的逻辑不会在设计文档中出现。在修改设计文档时,也只会影响到这些主要逻辑。而如果在代码中做修改,不仅会涉及这些主要逻辑,而且会涉及那些在文档中不会出现的细小逻辑。对于一段程序来说,任何一个逻辑出现问题,程序都是无法正常运行的。
4. 需求分析和系统设计之间的差别
很多读者无法清楚地区分“需求分析”和“系统设计”之间的差别,于是会发现,在写出的文档中,有些需求分析文档里出现了系统设计的内容,而有些系统设计文档里又混杂了需求分析的内容。
我们用几句话可以非常明确地给出二者的差异。
(1)需求分析:定义系统/软件的黑盒的行为,它是从外部(External)看到的,在说明“是什么”(What)。
(2)系统设计:设计系统/软件的白盒的机制,它是从内部(Internal)看到的,要说明“怎么做”(How)和“为什么”(Why)。
比如,对一辆汽车来说,首先使用者从外部可以看到车厢、车轮,坐在车里可以看到方向盘、刹车踏板、油门踏板等;操作方向盘可以改变汽车的行驶方向,脚踩刹车踏板、油门踏板可用于减速和加速。以上这些是对汽车的“需求分析”。
然后,我们想象汽车外壳和内部变成了透明的,可以看到汽车内部的发动机、变速箱、传动杆、与刹车相关的内部装置等。而这些对驾驶者来说是不可见的,它们是对汽车的“系统设计”。
本文节选自《代码的艺术:用工程思维驱动软件开发》一书,想要了解更多相关内容,欢迎阅读本书!