Linux网络和eBPF
关于本文
Linux 现在已经支持了很多种和网络相关的 eBPF 程序了,这些程序可以附加到任何套接字上,可以提取流经数据包的相关信息,可以检测和控制系统的网络流量,可以对网络接口的数据包进行过滤,可以对数据包进行放行、禁止或重定向等,可以修改网络连接状态…这些能力在 service mesh,云原生[2][3]等场景下有极大的作用,本文会介绍一些 eBPF 程序在网络上的应用。
如何实现
从网络的角度来看,使用 BPF 程序主要有两个用途: 数据包捕获和过滤 [1]。
它这些能力的实现主要取决与以下两种类型的程序:
- 套接字相关程序
- 基于 BPF 分类器和流量控制程序
网络相关的 eBPF 程序通常会需要传一个参数 struct __sk_buff,我们先来看看他的结构[4][5]:
struct __sk_buff {
__u32 len; /* 整个数据区域的长度, 这个 len 只计算有效的协议长度,如果在 l3 时, 不会计算 l2 的协议头长度*/
__u32 pkt_type; /*标记帧的类型*/
__u32 mark;
__u32 queue_mapping;
__u32 protocol; /*协议类型*/
__u32 vlan_present;
__u32 vlan_tci;
__u32 vlan_proto;
__u32 priority;
__u32 ingress_ifindex;
__u32 ifindex;
__u32 tc_index; /* traffic control index */
__u32 cb[5]; /* 保存与协议相关的控制信息, 每个协议可以独立使用这些信息*/
__u32 hash;
__u32 tc_classid;
__u32 data; // 数据开始指针
__u32 data_end; // 数据结束指针
__u32 napi_id;
/* Accessed by BPF_PROG_TYPE_sk_skb types from here to ... */
__u32 family;
__u32 remote_ip4; /* Stored in network byte order */
__u32 local_ip4; /* Stored in network byte order */
__u32 remote_ip6[4]; /* Stored in network byte order */
__u32 local_ip6[4]; /* Stored in network byte order */
__u32 remote_port; /* Stored in network byte order */
__u32 local_port; /* stored in host byte order */
/* ... here. */
__u32 data_meta;
__bpf_md_ptr(struct bpf_flow_keys *, flow_keys);
__u64 tstamp;
__u32 wire_len;
__u32 gso_segs;
__bpf_md_ptr(struct bpf_sock *, sk);
__u32 gso_size;
__u32 :32; /* Padding, future use. */
__u64 hwtstamp;
};
它是对内核网络核心结构 struct sk_buff 的用户可访问字段的镜像。BPF 程序中对 struct __sk_buff 字段的访问,将会被 BPF 校验器转换成对相应的 struct sk_buff 字段的访问[7]。而 sk_buff 是 Linux 网络协议栈里最重要的结构体,它用来管理和控制接受或发送数据包,在内核中各个协议之间传输时,不需要拷贝 sk_buff 的数据,只需要改协议头和移动数据指针,当数据从 L4 到 L2 时,数据段只用移动 sk_buff 里的 data 指针即可 。
BPF 程序通过访问 __sk_buff 中暴露的这些数据 ,可以选择放行(PASS)或丢弃(DROP)数据包; 可以将当前流量信息保存到 BPF 映射 来统计流量数据。甚至在一部分 BPF 程序里,可以对这些数据包进行重定向或改变其基本结构[1]。
可以说 __sk_buff 是 eBPF 程序可以在网络上大方异彩的核心,那下面我来介绍一下这些 BPF 程序都实现了什么强大的功能。
套接字相关程序
套接字相关程序,主要需要和 BPF Map 结合起来使用,需要了解的 map 主要有两种,BPF_MAP_TYPE_SOCKMAP 和 BPF_MAP_TYPE_SOCKHASH 这两种类型都是存储 socket 信息,常用于在套接字相关 BPF 程序里触发对数据的重定向[15]。
这两类 Map 在功能上没有本质上的区别,只是使用的数据结构不同。
套接字选项程序
(一): BPF_PROG_TYPE_SOCK_OPS
介绍:
当数据包通过内核网络栈的多个阶段中转时,这种类型程序允许运行时修改套接宇连接选项。该程序类型可以在套接字连接的生命周期中被多次调用。通过这个程序,你可以知道程序被调用
是发生在连接生命周期内哪个阶段。有了这些信息,你可以访问网络 IP 地址和连接端口之类的数据,井且还可以修改连接选项,设置超时以及更改给定数据包的往返延迟时间[1]。
hook 点:
其他类型的 BPF 程序大多只会在一处执行,但 SOCK_OPS 程序不同,它在多个地方执行,op 字段表示触发执行的地方。op 字段是枚举类型,下面是所有的枚举类型[16]:
enum {
BPF_SOCK_OPS_VOID,
BPF_SOCK_OPS_TIMEOUT_INIT, // 初始化 TCP RTO 时调用 BPF 程序
// 程序应当返回希望使用的 SYN-RTO 值;-1 表示使用默认值
BPF_SOCK_OPS_RWND_INIT, // BPF 程序应当返回 initial advertized window (in packets);-1 表示使用默认值
BPF_SOCK_OPS_TCP_CONNECT_CB, // 主动建连 初始化之前 回调 BPF 程序
BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB, // 主动建连 成功之后 回调 BPF 程序
BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB,// 被动建连 成功之后 回调 BPF 程序
BPF_SOCK_OPS_NEEDS_ECN, // If connection's congestion control needs ECN */
BPF_SOCK_OPS_BASE_RTT, // 获取 base RTT。The correct value is based on the path,可能还与拥塞控制
// 算法相关。In general it indicates
// a congestion threshold. RTTs above this indicate congestion
BPF_SOCK_OPS_RTO_CB, // 触发 RTO(超时重传)时回调 BPF 程序,三个参数:
// Arg1: value of icsk_retransmits
// Arg2: value of icsk_rto
// Arg3: whether RTO has expired
BPF_SOCK_OPS_RETRANS_CB, // skb 发生重传之后,回调 BPF 程序,三个参数:
// Arg1: sequence number of 1st byte
// Arg2: # segments
// Arg3: return value of tcp_transmit_skb (0 => success)
BPF_SOCK_OPS_STATE_CB, // TCP 状态发生变化时,回调 BPF 程序。参数:
// Arg1: old_state
// Arg2: new_state
BPF_SOCK_OPS_TCP_LISTEN_CB, // 执行 listen(2) 系统调用,socket 进入 LISTEN 状态之后,回调 BPF 程序
};
如何使用:
套接字选项程序有着强大的功能,拓展性极强,最简单的用法,可以监听服务器的套接字状态的变化,做监控使用。
除此之外,结合 bpf_setsockopt() 和 bpf_getsockopt()动态修改 socket 配置, 能够实现 per-connection 的优化,提升性能,例如在监听到被动连接事件,发现对端和本机不在同一个网段,就动态修改这个 socket 的 MTU[6]。这样能避免包因为太大而被中间路由器分片。
又或者连接在同一网段内,可以调低数据超时重传的时间,以降低丢包带来的影响。
更进一步,结合一些 tcp-options 框架[17][18],可以实现自定义 TCP option ,发送端同接受端进行一些用户态自定义的交流[19]。
至于套接字选项程序的使用示例,在后面有一个结合 BPF_PROG_TYPE_SK_MSG 程序配合的本地 socket redirection 应用里我会做介绍。
套接字消息传递程序
(一): BPF_PROG_TYPE_SK_MSG
介绍:
这种类型的程序可以控制是否将消息发送到套接字。内核通过套接宇映射(BPF_MAP_TYPE_SOCKMAP 和 BPF_MAP_TYPE_SOCKHASH)可以快速访问特定的套接宇组。当套接字消息 BPF 程序附加到套接字映射上时,发送到这些套接字的所有消息在发送前都将被过滤。这种类型的程序有两种可能的返回值 SK_PASS 和 SK_DROP ,SK_PASS 意味着希望内核将消息发送到套接字,SK_DROP 意味着希望内核忽略该消息,不将消息传递给套接字[1]。
hook 点:
sendmsg() 系统调用触发执行,主要是对 socket 的 egress traffic 进行处理[20]。
如何使用:
这里的使用示例,实现了本地套接字重定向的能力,对于源和目的端都在同一台机器的应用来说,这个应用可以绕过整个 TCP/IP 协议栈,直接将数据发送到 socket 对端[21]。
此应用分为两部分:
第一部分需要 BPF_PROG_TYPE_SOCK_OPS BPF 程序来做,在建立套接字连接的时候,监听主动建连(BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB)和被动建连(BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB)事件,利用 bpf_sock_hash_update 函数将套接字存储到 sockmap(BPF_MAP_TYPE_SOCKHASH) 之中。
第二部分就需要 BPF_PROG_TYPE_SK_MSG 来做了,因为在建连的时候,套接字的主动建连方和被动建连方已经将 socket 信息存到 sockmap 里了,因此在发送端发送数据时,如果判断出 sockmap 中有 socket 信息,说明被动建连方是本机,直接使用 msg_redirect_hash 函数,将数据重定向过去,从而不经过内核栈,整个过程如下图[23]。
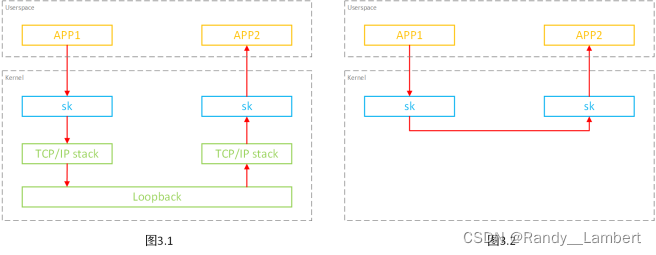
这部分的源码在这里[22],十分详细,大家有兴趣的话,可以看看。
套接字映射程序
(一): BPF_PROG_TYPE_SK_SKB
准确的说这应该是两个 BPF 程序,BPF_SK_SKB_STREAM_VERDICT 和 BPF_SK_SKB_STREAM_PARSER。
BPF_SK_SKB_STREAM_PARSER ,该类型的BPF程序不可单独使用,必须与 BPF_SK_SKB_STREAM_VERDICT 程序搭配使用,其用于确定一条完整消息的边界。通常数据流协议,在协议头中会指定 playload 有几个字节,然后通过底层 tcp 读取完协议头 header 和完整的 payload 后,才形成一条完整的消息记录。当 BPF_SK_SKB_STREAM_VERDICT 程序不能自行确定一条完整的消息长度时,就需要该BPF程序来确定是否读取到一条完整消息的尾部。
大多数情况下,BPF_SK_SKB_STREAM_VERDICT 程序要么是可以自行确定消息的边界要么只是从 skb 中获取一些元数据例如 IP 地址。这时,该类型的BPF程序一般就直接返回 SKB 长度即可。在内核 5.10 版本之后,这种情形的BPF_SK_SKB_STREAM_PARSER 程序可以省略,仅使用 BPF_SK_SKB_STREAM_VERDICT 即可[23][24][25]。因此我主要介绍一下 BPF_SK_SKB_STREAM_VERDICT 的使用。
介绍:
套接字映射程序可以访问套接字映射和进行套接字重定向 。套接字映射(BPF_MAP_TYPE_SOCKMAP 和 BPF_MAP_TYPE_SOCKHASH)可以保留对一些套接字的引用。我们可以使用这些引用和特定的帮助函数(bpf_sk_redirect_map)将套接字的数据包重定向到其他套接字 。这种程序类型可以实现内核级别负载平衡功能。通过跟踪多个套接字,我们可以在内核空间的多个套接字之间转发网络数据包[1][26]。
另外,套接字映射程序与上层应用配合,还可以在内核中实现动态解析消息流的能力[30]。
hook 点:
主要是对 socket 的 ingress traffic 进行处理[20]。
如何使用:
就像上面介绍的,结合套接字映射,我们可以利用 BPF_SK_SKB_STREAM_VERDICT 实现内核态的负载均衡和代理服务,功能十分强大,这里是一个套接字代理重定向的例子[27],用户态程序将需要代理重定向的 socket 写入套接字映射,内核态的BPF_PROG_TYPE_SK_SKB 利用 bpf_sk_redirect_map 函数将套接字数据进行重定向,有兴趣可以看看。
除此之外,我感觉 BPF_PROG_TYPE_SK_SKB 类型的程序也可以实现上面 BPF_PROG_TYPE_SK_MSG 实现的本地套接字重定向的功能,不过我没有进行实验。
注:
套接字相关程序不止只有上述我介绍的几个,还有几个其他的套接字相关程序(例如: BPF_PROC_TYPE_FLOW_DISSECTOR),我目前没有用过这几种套接字程序,在这里就不介绍了。
分类器和流量控制程序
套接字过滤器程序
(一): BPF_PROG_TYPE_SOCKET_FILTER
介绍:
在 BPF 技术刚出现的时候,BPF 程序等同于数据包过滤,作为添加到 Linux 内核的第一个 BPF 程序类型,它会附加到原始套接字上,用于访问所有套接字处理的数据包,可以决定是丢弃还是允许这些数据包。但是,它只能用于对套接字的观测,不允许修改数据包内容或更改其目的地[1]。
hook 点:
sock_queue_rcv_skb(): 处理 socket 入向流量,TCP/UDP/ICMP/raw-socket 等协议类型都会执行到这里。
如何使用:
作为最早加入内核的 BPF 程序类型,内核自带了几个使用示例(就看 sockex1 - sockex3 几个例子)[8],大家有兴趣可以去看看这三个例子,他们实现了 用 BPF 程序 过滤网络设备设备上的包,根据协议类型、IP、端口等信息统计流量等功能。
流量控制分类器(TC 子系统)
TC(Traffic Control) 是 Linux 的 QoS 子系统,主要有两类,分别是 tc 分类器(classifiers) 和 执行器(actions),他们的主要是做网络数据的流量控制和带宽分配,来优先处理某些包或者提前丢弃某些包,tc 支持 eBPF ,因此能直接将 BPF 程序作为 classifiers 和 actions 加载到 ingress/egress hook 点[9]。它比套接字过滤程序的功能更加强大,以钩子形式进入流量调度操作的不同级别,读取和更新套接宇缓存区及数据包元数据来执行流量整形、跟踪、预处理等操作[28][29]。
基础概念和术语
在了解流量控制类的 BPF 程序之前,需要先解释一下流量控制相关的概念。
排队规则
排队规则 (qdisc) 定义了调度对象,该对象通过更改数据包的发送方式使进入接口的数据包来排队。这些对象可以是 无分类 的也可以是 有分类 的 。
默认的排队规则是 pfifo_fast ,它是无分类的,将数据包进入三个 FIFO (先进先出)队列中,并基于优先级出队[1]。
fq_codel 也是一种无分类的排队规则,它使用随机模式对进入的数据包分类,能够以公平的方式对流量进行排队。
执行 ip -a 命令可以当前系统中配置的 网络接口列表 :
[shouxunsun@RandyLambert unified]$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp8s0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc fq_codel state DOWN group default qlen 1000
link/ether 8c:16:45:ed:3e:cb brd ff:ff:ff:ff:ff:ff
......
可以看到 lo 网络接口 支持的排队规则是 noqueue ,而 enp8s0 网络接口的排队规则是 fq_codel ,接下来,我们可以使用 tc 命令来列出接口的排队规则信息:
[shouxunsun@RandyLambert unified]$ tc qdisc ls
qdisc noqueue 0: dev lo root refcnt 2
qdisc fq_codel 0: dev enp8s0 root refcnt 2 limit 10240p flows 1024 quantum 1514 target 5ms interval 100ms memory_limit 32Mb ecn drop_batch 64
qdisc noqueue 0: dev wlp7s0 root refcnt 2
qdisc noqueue 0: dev br-11320591f748 root refcnt 2
qdisc noqueue 0: dev docker0 root refcnt 2
qdisc noqueue 0: dev br-bc116f86faf0 root refcnt 2
qdisc noqueue 0: dev vetha56d4a3 root refcnt 2
qdisc noqueue 0: dev veth6287cad root refcnt 2
qdisc noqueue 0: dev veth6ed5f57 root refcnt 2
qdisc noqueue 0: dev veth50a4683 root refcnt 2 针对 enp8s0 我们可以看到它最多处理 10240 个传入数据包,他使用的是 fq_codel 类型的分类器, 该输出还包含获得的数据包数量 , 当前是1024 。
有分类排队规则、过滤器和分类
有分类排队规则允许为不同种类的流量定义分类,以便可以对其应用不同的规则 。拥有一个分类排队规则意味着其可以包含更多的排队规则 。通过这种层次结构,我们可以使用过滤器 (分类器)确定数据包是否进入队列的下一个分类,从而对流量进行分类。
过滤器会根据数据包类型分配数据包到特定的分类 。过滤器用于有分类排队规则中确定数据包进入队列的分类,两个或多个过滤器可以映射到同一个分类。每个过滤器根据数据包信息使用已有的这些分类器对数据包进行分类[1]。
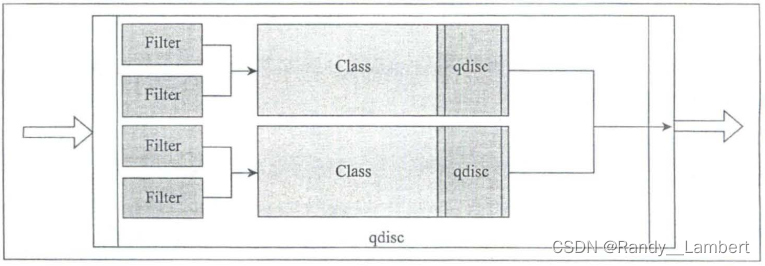
无分类排队规则
无分类排队规则不能包含任何子排队规则,因为其不允许与任何分类相关联。这意味着不能将过滤器附加到无分类排队规则上。由于无分类排队规则不能有子排队规则,因此我们无法向其添加过滤器和分类器。从 BPF 的角度来看,无分类排队规则没什么意义,但是它仍然能够满足简单的流量控制需求[1]。
tc 子系统相关 BPF 程序类型
实际上,在 tc 子系统相关 BPF 程序类型中,为了和 tc 子系统相对应,有两种类型的 BPF 程序,BPF_PROG_TYPE_SCHED_CLS 对应 tc classifier,做分类器,BPF_PROG_TYPE_SCHED_ACT 对应 tc action ,做 执行器,但是因为 BPF_PROG_TYPE_SCHED_ACT 有很多缺点[10],同时 BPF_PROG_TYPE_SCHED_CLS 类型的 BPF 程序逐渐发展,分类器自己就能够(无需 action 参与)修改包的内容(mangle packet contents)、更新校验和 (update checksums)等功能。出现了 direct-action 模式[11],classifier 类型的程序已经成为了 action 类型程序的超集,结合 action 类型的 BPF 程序已经没有什么额外能力了。直接使用 classifier BPF 程序的 direct-action 模式本身已经能以一种高效的方式做任何处理[9],本文也就不再介绍 BPF_PROG_TYPE_SCHED_ACT 类的 BPF 程序了。
(一): BPF_PROG_TYPE_SCHED_CLS
介绍:
BPF_PROG_TYPE_SCHED_CLS 类型程序,以 hook 的形式插入数据路径上的 ingress 和 egress 点。读取和更新套接字缓存区及其数据包元数据来执行流量整形,跟踪,预操作等操作。
hook 点:
ingress hook sch_handle_ingress():由 __netif_receive_skb_core() 触发
egress hook sch_handle_egress():由 __dev_queue_xmit() 触发
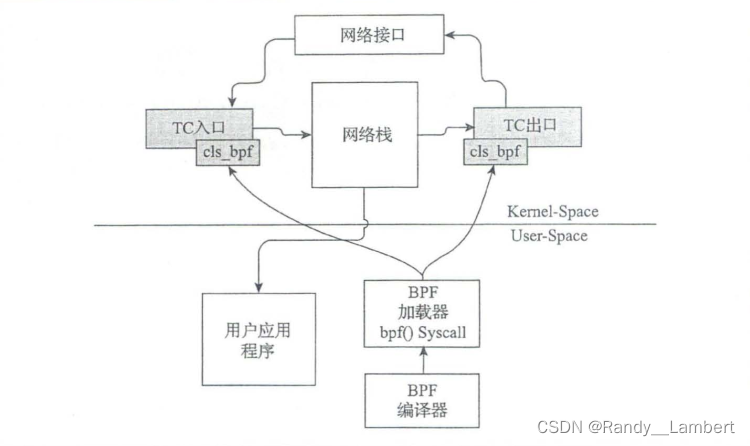
如何使用:
Linux 内核观测技术 这本书给了一个十分简单易懂的示例[13],这个示例会在 ingress 处对数据包的协议进行判断,如果是 HTTP 包,则打印 Yes! It is HTTP! ,同时,利用 tc 命令设置排队规则和加载 BPF 程序。
XDP(eXpress Data Path)类型相关程序
XDP 程序和 cls_bpf 程序使用起来十分相像,但实际上还是有很多不同点的, XDP 程序在进入主内核网络栈之前执行,比 tc 程序还早,因此 XDP 程序无法像 tc 一样访问套接字缓冲区结构体 sk_buff(使用的结构为 xdp_buff[12],结构十分轻量)。
struct xdp_md {
__u32 data;
__u32 data_end;
__u32 data_meta;
/* Below access go through struct xdp_rxq_info */
__u32 ingress_ifindex; /* rxq->dev->ifindex */
__u32 rx_queue_index; /* rxq->queue_index */
__u32 egress_ifindex; /* txq->dev->ifindex */
};该结构是数据包的早期表示,不带元数据。这样做导致 XDP 程序比起 tc 程序少了很多信息。但是,由于是在内核代码之前执行, XDP 程序可以更早丢弃数据包[1]。
(一): BPF_PROG_TYPE_XDP
介绍:
BPF_PROG_TYPE_XDP 是 Linux 网络数据路径上内核集成的数据包处理器,具有安全、可编程、高性能的特点。当网卡驱动程序收到数据包时,该处理器执行 BPF 程序。这使得 XDP 程序可以在最早的时间点,以极高的效率对接收到的数据包进行丢弃、修改或允许等操作。适用于 DDoS 防御、四层负载均衡等场景[6],除此之外,结合 BPF Map,XDP 程序还可以将数据包从指定的网卡,CPU 重定向出去[15]。
hook 点:
XDP 类型的程序比较特殊,他有三种类型:
- 原生 XDP (性能较好,默认模式,需要网络驱动支持)
- 卸载 XDP (性能最好,直接将 BPF 程序卸载到网卡上,而不是 CPU上,同样需要网卡驱动支持)
- 通用 XDP (性能最差,是一种测试模式,优点是不需要网卡驱动支持)
值得注意的是,与 tc 程序相比,XDP BPF 程序只能在 ingress 点触发。
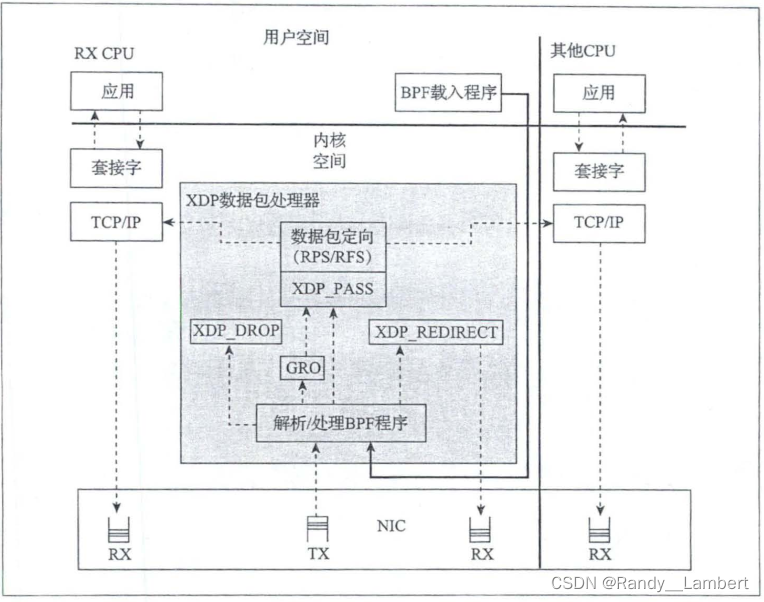
如何使用:
和 tc 程序一样,Linux 内核观测技术 这本书也给了使用示例[14],这是一个通用 XDP 类型的程序,主要功能是禁止一个服务器的所有 TCP 连接,丢弃每个 TCP 数据包,同时允许除了 TCP 协议外的其他任何内容,从而阻止外网访问此服务器的页面。
XDP 程序加载和卸载是利用 ip 工具实现的。
注:
流量控制分类器程序不止只有上述我介绍的几个,还有几个其他的相关程序我目前没有接触使用过,在这里就不介绍了。
结语
我只是一个学生,因为毕业设计选题是和 eBPF 网络相关,因此最近系统的学习了这方面的知识,我自己水平有限,这篇文章里有说的不对的地方,还请大家见谅,同时,也可以给我指出来。
引用
[1]: Linux 内核观测技术
[2]: https://cloudnative.to/tags/ebpf/
[3]:https://www.googleadservices.com/pagead/aclk?sa=L&ai=DChcSEwjnrNP_pNf2AhXXrZYKHcYgBwIYABAAGgJ0bA&ae=2&ohost=www.google.com&cid=CAESbeD2lD4Bh3oEfAFgYrtWJ11xH8FO4nvtO1kY7KqZXAFMKX7j-W69KfYNCOeybWyMLT9j6y35P0hX9VTG8v5jXHLjQNom1-6ithT6JMXR7tOWPLu_jXP-3_UC2VCJEd8BaUGH7uKEs2VH7OkZh_k&sig=AOD64_3HvGs657MPR4wcxVx0Pn8Z7n5C7g&q&adurl&ved=2ahUKEwi9rcv_pNf2AhXnxYsBHfAfDUgQ0Qx6BAgCEAE
[4]:https://elixir.bootlin.com/linux/v5.17/source/include/uapi/linux/bpf.h#L5401
[5]: https://www.jianshu.com/p/3738da62f5f6
[6]:https://arthurchiao.art/blog/bpf-advanced-notes-1-zh/#1-bpf_prog_type_socket_filter
[7]: https://lwn.net/Articles/636647/
[8]: https://github.com/torvalds/linux/blob/v5.10/samples/bpf/
[9]: https://houmin.cc/posts/28ca4f79/
[10]:Daniel Borkman.2016.NetdevConf: On getting tc classifier fully programmable with cls_bpf
[11]: http://arthurchiao.art/blog/understanding-tc-da-mode-zh/
[12]:https://elixir.bootlin.com/linux/latest/source/include/uapi/linux/bpf.h#L5594
[13]:https://github.com/bpftools/linux-observability-with-bpf/tree/master/code/chapter-6/tc-flow-bpf-cls
[14]:https://github.com/bpftools/linux-observability-with-bpf/tree/master/code/chapter-7/iproute2
[15]:http://arthurchiao.art/blog/bpf-advanced-notes-2-zh/#1-bpf_map_type_sockmap
[16]:https://elixir.bootlin.com/linux/latest/source/include/uapi/linux/bpf.h#L5966
[17]: https://inl.info.ucl.ac.be/system/files/tcp-ebpf.pdf
[18]: https://github.com/hoang-tranviet/tcp-options-bpf
[19]:https://inl.info.ucl.ac.be/system/files/Netdev+0x13±+Making+the+Linux+TCP+stack+more+extensible+with+eBPF+(1).pdf
[20]: https://blog.csdn.net/xzhao28/article/details/110247605
[21]: https://cyral.com/blog/how-to-ebpf-accelerating-cloud-native/
[22]: https://github.com/cyralinc/os-eBPF/
[23]: https://www.51cto.com/article/645284.html
[24]: https://lwn.net/Articles/731133/
[25]: https://lwn.net/Articles/768371/
[26]: https://github.com/facebookincubator/katran
[27]: https://mp.weixin.qq.com/s/VL6oKW1m0PXmuuE1v8h0iw
[28]: tc(8) manpage for a general introduction
[29]: tc-bpf(8) for BPF specifics
[30]:https://www.kernel.org/doc/Documentation/networking/strparser.txt