Linux脏页回写机制浅析
从Linux 2.6.32开始,Linux内核脏页回写通过bdi_writeback机制实现,bdi的全拼是backing device info(持久化存储设备信息,如ssd、hdd)。用户态调用write系统调用写入数据后,文件系统只在页缓存中写入数据便返回了write系统调用,并没有分配实际的物理磁盘块,ext4称为延迟分配技术(delay allocation)。本文将介绍内核(kernel version 4.14)是在何时如何将写入的数据回写到磁盘。
核心数据结构初始化
回写机制借助了Linux中工作队列来完成,在内核启动的时候,系统会使用alloc_workqueue函数申请一个用于回写的工作队列。具体实现在函数default_bdi_init中。
// /mm/backing-dev.c
static int __init default_bdi_init(void)
{
int err;
bdi_wq = alloc_workqueue("writeback", WQ_MEM_RECLAIM | WQ_FREEZABLE |
WQ_UNBOUND | WQ_SYSFS, 0);
if (!bdi_wq)
return -ENOMEM;
err = bdi_init(&noop_backing_dev_info);
return err;
}
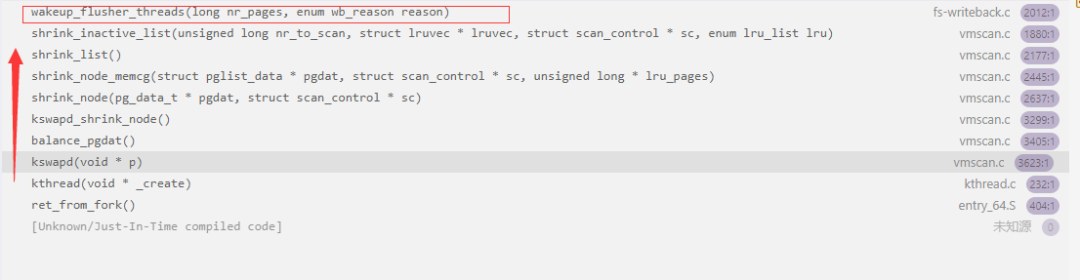
函数调用栈如下图。
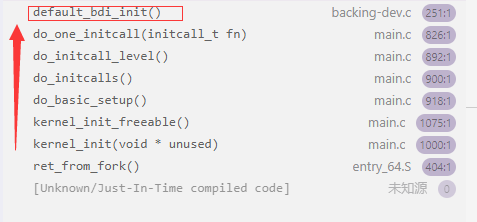
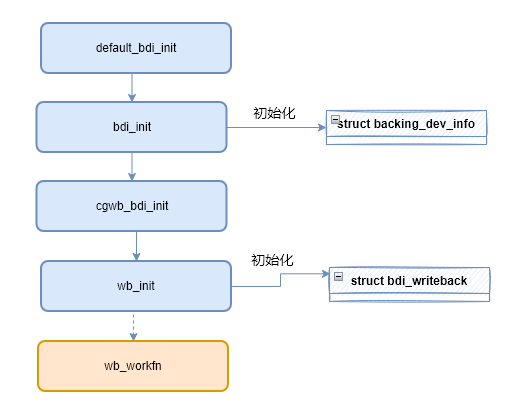
bdi_init()函数初始化bdi (struct backing_dev_info),该结构体包含了块设备信息,代表一个设备。
- struct backing_dev_info:描述一个块设备。
- struct bdi_writeback:管理一个块设备所有的回写任务。
- struct wb_writeback_work :描述需要回写的任务。
还有管理回写任务的结构体bdi_writeback,描述任务的结构体wb_writeback_work,其三者的关系如下图所示。

在bdi_init中对bdi进行初始化后,会继续调用倒wb_init(),该函数对bdi中的wb(struct bdi_writeback)进行初始化。
// /fs/fs-writeback.c
struct bdi_writeback {
struct backing_dev_info *bdi; /* our parent bdi */
unsigned long state; /* Always use atomic bitops on this */
unsigned long last_old_flush; /* 上次刷写数据的时间,用于周期性回写数据 */
struct list_head b_dirty; /* 暂存dirty inode,mark_dirty_inode会加入到这个list */
struct list_head b_io; /* 用于暂存即将要被writeback处理的inode */
struct list_head b_more_io; /* parked for more writeback */
struct list_head b_dirty_time; /* 暂存在cache过期的inode */
spinlock_t list_lock; /* protects the b_* lists */
struct percpu_counter stat[NR_WB_STAT_ITEMS];
struct bdi_writeback_congested *congested;
unsigned long bw_time_stamp; /* last time write bw is updated */
unsigned long dirtied_stamp;
unsigned long written_stamp; /* pages written at bw_time_stamp */
unsigned long write_bandwidth; /* 单次wb任务的带宽 */
unsigned long avg_write_bandwidth; /* further smoothed write bw, > 0 */
unsigned long dirty_ratelimit;
unsigned long balanced_dirty_ratelimit;
struct fprop_local_percpu completions;
int dirty_exceeded;
enum wb_reason start_all_reason; /* 回写任务的触发原因 ,常见的原因有周期回写、脏页超出阈值回写,和用户主动回写*/
spinlock_t work_lock; /* protects work_list & dwork scheduling */
struct list_head work_list; /* 保存wb_writeback_work结构的list,用于处理这次回写任务下面所有的任务 */
struct delayed_work dwork; /* work item used for writeback */
unsigned long dirty_sleep; /* last wait */
struct list_head bdi_node; /* anchored at bdi->wb_list */
};
//描述一个回写任务
struct wb_writeback_work {
long nr_pages;//待回写页面数量;
struct super_block *sb;// writeback 任务所属的 super_block;
enum writeback_sync_modes sync_mode;/*指定同步模式,WB_SYNC_ALL 表示当遇到锁住的 inode 时,它必须
等待该 inode 解锁,而不能跳过。WB_SYNC_NONE 表示跳过被锁住的 inode;*/
unsigned int tagged_writepages:1;
unsigned int for_kupdate:1;//若值为 1,则表示回写原因是周期性的回写;否则值为 0;
unsigned int range_cyclic:1;
unsigned int for_background:1;//若值为 1,表示后台回写;否则值为 0;
unsigned int for_sync:1; /* sync(2) WB_SYNC_ALL writeback */
unsigned int auto_free:1; /* free on completion */
enum wb_reason reason; /* why was writeback initiated? */
struct list_head list; /* pending work list */
struct wb_completion *done; /* set if the caller waits */
};wb_init在初始化过程中,给wb->dwork字段赋值了函数wb_workfn,后面触发回写任务时,就会通过该函数进行执行回写。
static int wb_init(struct bdi_writeback *wb, struct backing_dev_info *bdi,
int blkcg_id, gfp_t gfp)
{
INIT_LIST_HEAD(&wb->b_dirty);
...
wb->bw_time_stamp = jiffies;
...
INIT_DELAYED_WORK(&wb->dwork, wb_workfn);
wb->dirty_sleep = jiffies;
...
return 0;
}
至此bdi_writeback机制初始化完成。
触发回写任务的时机
由于写入的数据都缓存在内存中,猜想当空闲内存紧张的时候,内核会执行回写任务。于是我们需要减少系统可用内存,使用如下命令在内存中创建文件系统然后往里面写入文件。
mkdir tmp
mount -t ramfs ramfs tmp/使用 dd 命令在该目录下创建文件。我们创建了一个79M的文件。
dd if=/dev/zero of=tmp/file bs=1M count=79
完成上述操作以后系统还剩余2M内存,内核并没有立即触发回写,于是使用write系统调用继续向磁盘写入数据。

/* fs/fs-writeback.c
* Start writeback of `nr_pages' pages. If `nr_pages' is zero, write back
* the whole world.
*/
void wakeup_flusher_threads(long nr_pages, enum wb_reason reason)
{
struct backing_dev_info *bdi;
/*
* If we are expecting writeback progress we must submit plugged IO.
*/
if (blk_needs_flush_plug(current))
blk_schedule_flush_plug(current);
if (!nr_pages)
nr_pages = get_nr_dirty_pages();
rcu_read_lock();
//遍历当前的bdi_list所有的bdi设备
list_for_each_entry_rcu(bdi, &bdi_list, bdi_list) {
struct bdi_writeback *wb;
if (!bdi_has_dirty_io(bdi))
continue;
//遍历当前bdi设备中wb_list存储的所有wb
list_for_each_entry_rcu(wb, &bdi->wb_list, bdi_node)
wb_start_writeback(wb, wb_split_bdi_pages(wb, nr_pages),
false, reason);
}
rcu_read_unlock();
}GDB查看传入wakeup_flusher_threads的参数值分别是nr_pages = 0和reason = WB_REASON_VMSCAN。
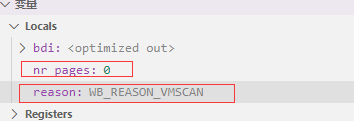
/*
* why some writeback work was initiated
*/
enum wb_reason {
WB_REASON_BACKGROUND,//脏页达到阈值,后台回写
WB_REASON_VMSCAN,//内存压力
WB_REASON_SYNC,//sync系统调用回写
WB_REASON_PERIODIC,//周期回写
WB_REASON_LAPTOP_TIMER,//Laptop模式回写
WB_REASON_FREE_MORE_MEM,
WB_REASON_FS_FREE_SPACE,
/*
* There is no bdi forker thread any more and works are done
* by emergency worker, however, this is TPs userland visible
* and we'll be exposing exactly the same information,
* so it has a mismatch name.
*/
WB_REASON_FORKER_THREAD,
WB_REASON_MAX,
};我们继续分析wb_start_writeback回写函数。该函数创建并初始化了一个wb_writeback_work来描述本次回写任务,最后调用wb_queue_work。
void wb_start_writeback(struct bdi_writeback *wb, long nr_pages,
bool range_cyclic, enum wb_reason reason)
{
struct wb_writeback_work *work;
if (!wb_has_dirty_io(wb))
return;
work = kzalloc(sizeof(*work),
work->sync_mode = WB_SYNC_NONE;
work->nr_pages = nr_pages;
work->range_cyclic = range_cyclic;
work->reason = reason;
work->auto_free = 1;
wb_queue_work(wb, work);
}wb_queue_work调用mod_delayed_work将该任务挂入工作队列(workqueue),在等待delay时间后由工作队列的工作线程(worker)执行初始化时注册的任务管理函数wb->dwork。Linux workqueue如何处理work的过程可以参考文章,本文跳过该过程,直接到回写任务的处理函数wb_workfn继续分析: http://www.wowotech.net/irq_subsystem/queue_and_handle_work.html
static void wb_queue_work(struct bdi_writeback *wb,
struct wb_writeback_work *work)
{
trace_writeback_queue(wb, work);
if (work->done)
atomic_inc(&work->done->cnt);
spin_lock_bh(&wb->work_lock);
if (test_bit(WB_registered, &wb->state)) {
list_add_tail(&work->list, &wb->work_list);
mod_delayed_work(bdi_wq, &wb->dwork, 0);
} else
finish_writeback_work(wb, work);
spin_unlock_bh(&wb->work_lock);
}
bool mod_delayed_work_on(int cpu, struct workqueue_struct *wq,
struct delayed_work *dwork, unsigned long delay)
{
unsigned long flags;
int ret;
do {//判断当前work的状态,找到一个pending的work
ret = try_to_grab_pending(&dwork->work, true, &flags);
} while (unlikely(ret == -EAGAIN));
if (likely(ret >= 0)) {
//将work加入到工作队列中,在delay时间周期后去执行
__queue_delayed_work(cpu, wq, dwork, delay);
local_irq_restore(flags);
}
/* -ENOENT from try_to_grab_pending() becomes %true */
return ret;
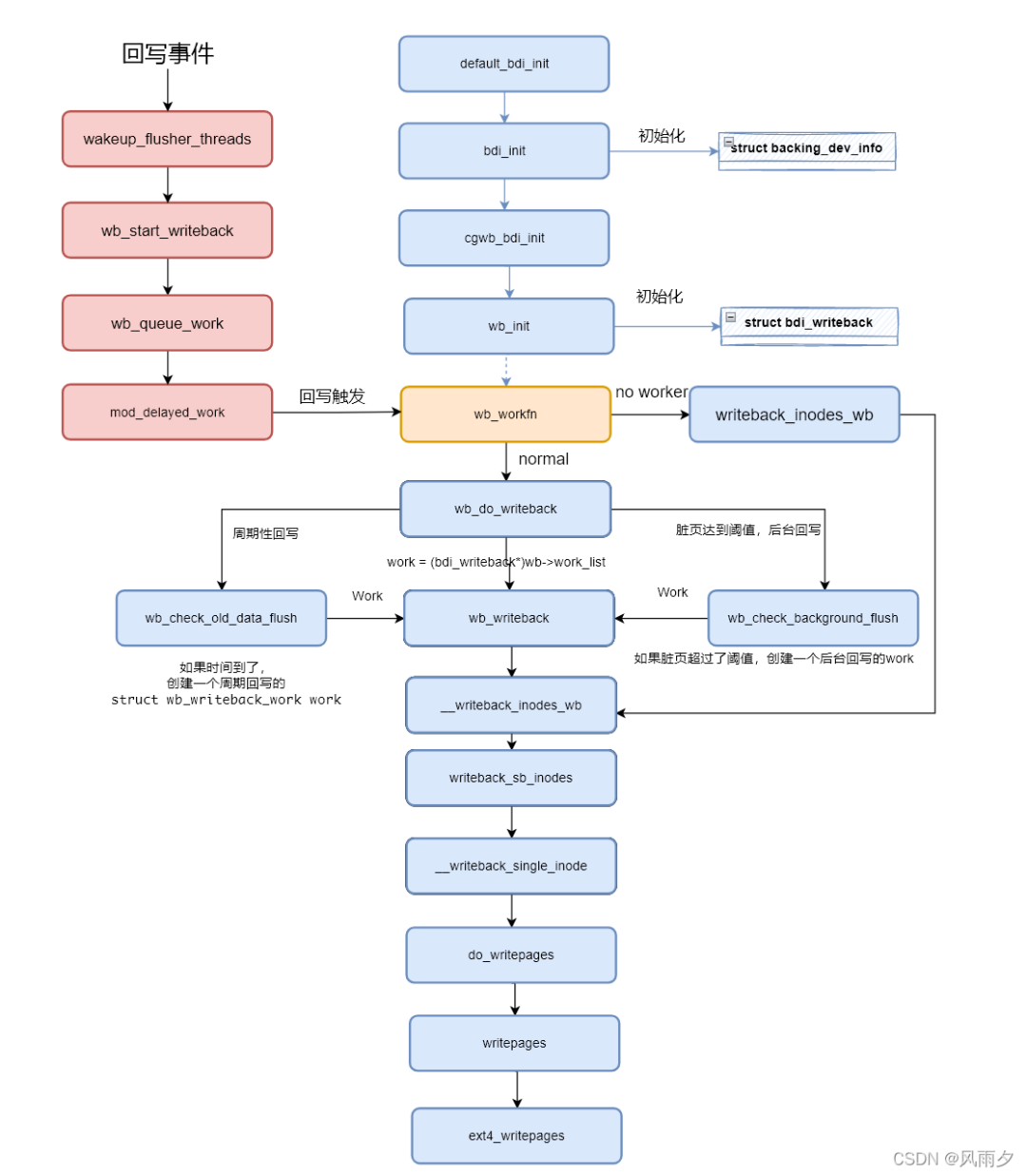
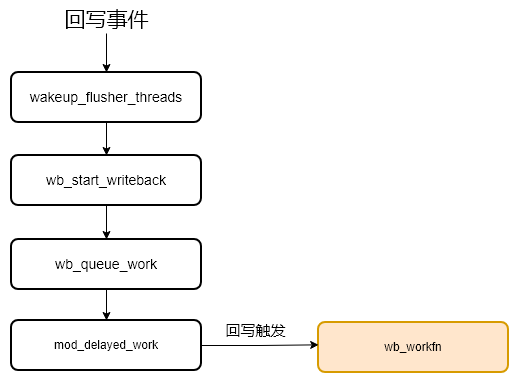
}关于触发内核回写的函数调用总结如下图:
回写任务的执行
回写的执行在文件系统层的函数调用如下所示。
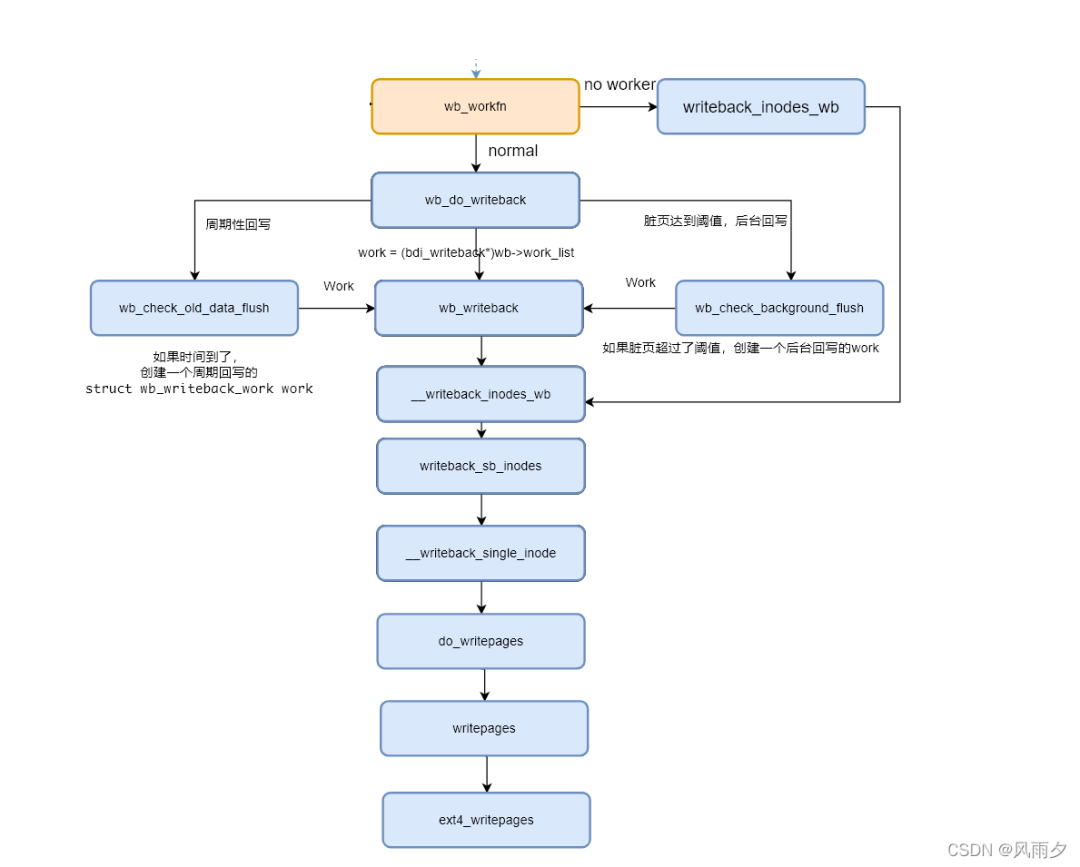
函数wb_workfn正常路径为遍历work_list,执行wb_do_writeback函数。如果没有足够的worker则执行writeback_inodes_wb函数回写1024个脏页。
void wb_workfn(struct work_struct *work)
{
struct bdi_writeback *wb = container_of(to_delayed_work(work),
struct bdi_writeback, dwork);
long pages_written;
set_worker_desc("flush-%s", dev_name(wb->bdi->dev));
current->flags |= PF_SWAPWRITE;
if (likely(!current_is_workqueue_rescuer() ||
!test_bit(WB_registered, &wb->state))) {
do {
pages_written = wb_do_writeback(wb);
trace_writeback_pages_written(pages_written);
} while (!list_empty(&wb->work_list)); // 正常情况下遍历work_list,执行wb_do_writeback
} else {
pages_written = writeback_inodes_wb(wb, 1024,
WB_REASON_FORKER_THREAD); // 没有足够的worker去处理writeback,紧急情况下回写。
trace_writeback_pages_written(pages_written);
}
if (!list_empty(&wb->work_list))
wb_wakeup(wb); // 如果没有处理完,再唤醒处理一次
else if (wb_has_dirty_io(wb) && dirty_writeback_interval)
wb_wakeup_delayed(wb); // 如果还有dirty inode在其他list,延迟500再执行一次
current->flags &= ~PF_SWAPWRITE;
}wb_do_writeback函数在遍历wb并调用wb_writeback回写结束后会进行定时回写和脏页是否超过阈值的回写检查。
/*
* Retrieve work items and do the writeback they describe
*/
static long wb_do_writeback(struct bdi_writeback *wb)
{
struct wb_writeback_work *work;
long wrote = 0;
//检查running标识,可以直接执行
set_bit(WB_writeback_running, &wb->state);
while ((work = get_next_work_item(wb)) != NULL) {
trace_writeback_exec(wb, work);
wrote += wb_writeback(wb, work);
finish_writeback_work(wb, work);
}
/*
* Check for periodic writeback, kupdated() style
*/
//定期回写检查
wrote += wb_check_old_data_flush(wb);
wrote += wb_check_background_flush(wb);//脏页超过阈值回写检查
clear_bit(WB_writeback_running, &wb->state);
return wrote;
}
wb_writeback根据是否包含superblock,分别调用writeback_sb_inodes和__writeback_inodes_wb。
static long wb_writeback(struct bdi_writeback *wb,
struct wb_writeback_work *work)
{
...
blk_start_plug(&plug);
for (;;) {
...
if (work->sb)
progress = writeback_sb_inodes(work->sb, wb, work);
else
progress = __writeback_inodes_wb(wb, work);
...
}
spin_unlock(&wb->list_lock);
blk_finish_plug(&plug);
return nr_pages - work->nr_pages;
}writeback_sb_inodes调用__writeback_single_inode。
static long writeback_sb_inodes(struct super_block *sb,
struct bdi_writeback *wb,
struct wb_writeback_work *work)
{
...
while (!list_empty(&wb->b_io)) { // 遍历wb->b_io里面的所有inode
struct inode *inode = wb_inode(wb->b_io.prev); // 从list中取出一个inode
...
if ((inode->i_state & I_SYNC) && wbc.sync_mode != WB_SYNC_ALL) {
spin_unlock(&inode->i_lock);
requeue_io(inode, wb); // 将这个inode迁移到wb->b_more_io
trace_writeback_sb_inodes_requeue(inode);
continue;
}
spin_unlock(&wb->list_lock);
if (inode->i_state & I_SYNC) { /* 对于SYNC模式的inode和SYNC的wb类型 */
/* Wait for I_SYNC. This function drops i_lock... */
inode_sleep_on_writeback(inode);
/* Inode may be gone, start again */
spin_lock(&wb->list_lock);
continue;
}
inode->i_state |= I_SYNC;
wbc_attach_and_unlock_inode(&wbc, inode); // 对于inode进行解锁
write_chunk = writeback_chunk_size(wb, work); // 计算需要写多少数据
wbc.nr_to_write = write_chunk; // 一般是4096
wbc.pages_skipped = 0;
__writeback_single_inode(inode, &wbc); // 将inode的数据写入磁盘
wbc_detach_inode(&wbc);
work->nr_pages -= write_chunk - wbc.nr_to_write; // 记录写了多少页
wrote += write_chunk - wbc.nr_to_write;
if (need_resched()) {
blk_flush_plug(current);
cond_resched();
}
tmp_wb = inode_to_wb_and_lock_list(inode); // 给wb加锁
...
return wrote;
}
__writeback_single_inode调用do_writepages。
static int
__writeback_single_inode(struct inode *inode, struct writeback_control *wbc)
{
struct address_space *mapping = inode->i_mapping;
long nr_to_write = wbc->nr_to_write;
unsigned dirty;
int ret;
WARN_ON(!(inode->i_state & I_SYNC));
trace_writeback_single_inode_start(inode, wbc, nr_to_write);
ret = do_writepages(mapping, wbc);
}
do_writepages就出现了我们熟悉的页缓存函数操作集struct address_space_operations *a_ops。其中writepages函数在ext4中的实现为ext4_writepages。
int do_writepages(struct address_space *mapping, struct writeback_control *wbc)
{
int ret;
if (wbc->nr_to_write <= 0)
return 0;
while (1) {
if (mapping->a_ops->writepages)
ret = mapping->a_ops->writepages(mapping, wbc);
else
ret = generic_writepages(mapping, wbc);
if ((ret != -ENOMEM) || (wbc->sync_mode != WB_SYNC_ALL))
break;
cond_resched();
congestion_wait(BLK_RW_ASYNC, HZ/50);
}
return ret;
}
//ext4延时分配
static const struct address_space_operations ext4_da_aops = {
.readpage = ext4_readpage,
.readahead = ext4_readahead,
.writepage = ext4_writepage,
.writepages = ext4_writepages,
.write_begin = ext4_da_write_begin,
.write_end = ext4_da_write_end,
...
};
接下来会在ext4_writepages中打包bio结构体,发送到通用块层,继续更底层的IO操作。
最后,bdi_writeback机制整体流程如下。