转转反爬攻防战
-
一、背景
-
二、现状
-
三、前人研究
-
四、Cleaner爬虫清洁工
-
4.1 系统模型
-
4.2 效果
-
五、总结
一、背景
某日,数据组来报,前几日DAU增量惊人,望平台核实是否准确。G先生看了看数据,觉得这波增长应是受一周前新媒体投放带来的流量影响,正思索间,墙角处悠悠传来一个声音:“难道是它们又回来了?”
G先生瞬间挺直了后背,熟悉的人都知道,这是他在遇到特殊危险,比如獒这种猛兽时才会摆出的姿态。不知过了多久,他缓缓将虚弱不堪的身体摊到了椅子上道:“是的,是它们,那些可恶的虫子!”
二、现状
G先生四周坐满了人,仔细地听着他的分析。
“现在我们的局势是这样的。”G先生说:“其实我们每天都在承受着大量爬虫的侵扰,只不过有些时候它们被我们的防御机制阻挡在了系统之外,有些时候它们只是暂停了进攻。不幸的是,后者这种情况似乎更多一些。”
“总结起来”
“它们一般有两种特点”
- 规律性
- 高频次
“它们一般有两种攻击模式”
- 正面进攻:这种模式的特点是大量的请求,粗糙的伪装,聚焦在一个接口上,靠数量与多样性取胜。
- 间谍行动:较少但更有规律的请求,它们会尽量伪装成真实用户,模仿用户的行为,进而获取关键接口更核心的信息。
“它们的危害主要体现在四个方面”
- 数据安全性: 作为电商平台,最关键的商品信息,以及用户信息一旦被爬取,极有可能造成商品流失、用户信息泄露、甚至电信诈骗等一系列安全问题。
- 大数据异常: 数据统计如dau,pv,uv等都依赖于各接口每天的请求日志,这些日志一旦记录了非真实用户的爬虫数据,便会失去统计效力。
- 服务稳定性: 由于上面提到的第一种攻击模式,爬虫会进行大量的请求,有的甚至接近于洪泛攻击,这会极大地增加服务器的负荷,如果同时还有拉新等活动,则会造成流量暴增,进而导致系统瘫痪。
- 个性化失效: app会根据所有用户的搜索内容提供给一般用户搜索关键词,爬虫如果侵入搜索接口,并大量搜索恶意关键词,则会使推给正常用户的关键词变得不准确,从而影响用户体验。
“目前转转app中已有的反爬虫策略很基础,只包含一些必要的合法性校验,小时级别的延迟风控以及手动封禁策略。”G先生摇了摇头:“用现有的手段防范攻击,阻断危害是远远不够的。”
三、前人研究
“针对上面提到的爬虫的特点,我们要为转转建设的是一套根据爬虫特点,足以规避上述两种攻击模式,尽量不依赖前端,能够准确地分辨正常用户和爬虫请求,并且达到秒级别实时封禁的反爬虫系统。”
“我们需要借鉴前人的探索”
“几种常用的后端反爬虫方法”
- 登录限制: 要求用户请求接口时必须登录,这种方式可以很大程度上增加爬虫成本,但较为霸道,在关键节点很容易影响到用户体验。
- cookie校验: 用户请求cookie里可以携带一些用于鉴别身份的数据,这些数据有自己的一套生成规则,支持合法性校验,对这些数据进行验证,可以鉴别出是否是真实用户。但是当爬虫破解了生成规则,或是利用真实用户的cookie进行请求时,这种方法就无法做到有效的防御了。
- 频次校验: 利用对每次请求的常见特征(由于ip的成本最高,所以一般选择ip)的频次统计,决定是否对该特征进行封禁。由于爬虫规律性,高频次的特点,这种方法可以有效地阻止大量的爬虫请求,但这也带来另一个问题,同一ip有时不止一个用户在用,可能误伤用户。而不选择ip,选择其他维度,伪造成本又太低。
- 验证码校验: 同一ip或用户进行多次请求达到一定阈值,则要求用户输入验证码,验证码有很多种,如文字、图形、滑动等。其中滑动图形验证码的效果最好,因为图像识别的成本较高,但需要前端配合,而且也会影响到用户体验。
- 数据加密: 前端对请求数据进行加密计算,并把加密值作为参数传给服务端,在服务器端同样有一段加密逻辑,生成一串编码,与请求参数进行匹配,匹配通过则会返回数据。这种方法依旧需要客户端参与,并且加密算法明文写在JS里,爬虫还是可以分析出来。
“已有的这几种方法都有各自的优点,但他们的缺点也很显著。”G先生皱了皱眉头:“可以肯定的是,利用任意一种,或者简单地缝合这几种方法,并不能在保证用户体验的同时,达到我们需要的效果。”
四、Cleaner爬虫清洁工
“我们需要反爬虫系统具有什么样的特点?”G先生环顾四周,自顾自地说道:
“反爬虫系统的基本特点”
- 准确性:有能力抓出爬虫,又要避免误伤。
- 实时性:秒级别的响应,如果等爬虫都抓完数据,满载而归了,再去封禁就没有意义了。
“结合攻击模式,应对爬虫的方法”
- 正面进攻:合法性校验,频次控制。
- 间谍行动:用户行为分析。
“根据爬虫特点与反爬方法,实际上我们已经有了系统的雏形,只不过还没有投入开发。”G先生邪魅一笑:“这就是我们的Cleaner爬虫清洁工系统。”
4.1 系统模型
“我们的Cleaner系统主要有3个模块。”G先生举起了2根手指。
“数据处理中心”,说着他弯下一根手指。
“封禁中心”,他又弯下一根手指。
“以及,封禁库”,这时他发现手指不够用了,但并没有被这种小事打断思绪,回身掏出了一张图片,继续说道:
“这仨模块如图所示。Cleaner利用mq进行解耦,用户日志,redis,本地缓存进行功能上的实现。下面我会对每个模块进行详细地讲解”

4.1.1 数据处理中心
“基于准确性和实时性,要考虑到的是,单单靠一个请求的行为特征是不够的,必须联系一段时间内所有相同用户发出的请求,这就是说要去搜集识别一段时间内所有日志,并在海量数据中分析出每一个请求链的特征、规律和危险程度。”G先生看到大家和他一样睿智的表情,点了点头:“是的,这里的关键就在于海量数据,而海量数据的实时处理嘛,大家可以想到什么?”
“对!就是flink。”G先生的声音渐渐变大:“flink作为一款分布式、高性能、实时、准确的开源流处理框架,完美符合我们的需求。Cleaner的数据处理中心正是基于flink实时处理日志实现的,它在处理完日志后将有用信息聚合成mq发送给下游的封禁中心作进一步的处理。”
“flink的原理我们就不探讨了,我们只是利用它的特性做数据聚合。下面这张图片上展示的就是Cleaner系统中flink处理日志的过程。”
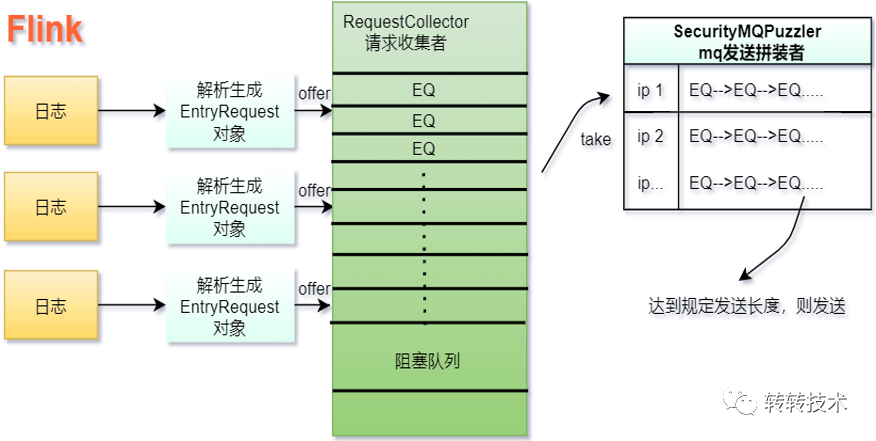
“数据处理中心拿到用户的每一条请求日志,会根据约定格式,生成一个对应的EntryRequest对象,这个对象里面包含封禁中心中需要识别、分析的用户特征,包括请求接口名,用户唯一标识,ip,版本,时间戳等等。”
“接下来,请求收集者RequestCollector会一个一个地把这些EntryRequest对象收集起来,放进它内部的一个有界阻塞队列中。之所以用到有界,是防止在接下来的处理过程中,由于某些时刻的处理不及时,导致的数据积压,从而影响系统功能”
“MQ发送拼装类SecurityMQPuzzler会坚持不懈地从这个有界队列中拿出EntryRequest对象,同样地为了防止数据积压,它的内部维护着一个最大容量为10w个key,写后一小时失效的本地缓存。”
“缓存中的key可以设置为想要鉴别的维度,既可以是用户的某种唯一标识,也可以是最常用,替换成本最高的ip。缓存中的value是同一key下EntryRequest的list,按照取来的顺序EntryRequest被放入这个list中,这个list承担了类似滑动窗口的作用,当list的长度达到事先设置的阈值,就会将这个list放入MQ实体中,发送出去。”
“总结一下”
“数据处理中心是保证Cleaner系统实时性的关键。由于其需要处理海量数据的特点,flink作为其核心承担了数据分析的工作,数据处理中心和下游封禁中心之间利用MQ进行削峰,解耦,以防止可能出现的模块之间的恶性连锁反应。”
4.1.2 封禁中心
“数据处理中心要解决的是实时性的问题,而封禁中心要解决的就主要是准确性的问题了。它的设计如下图。”
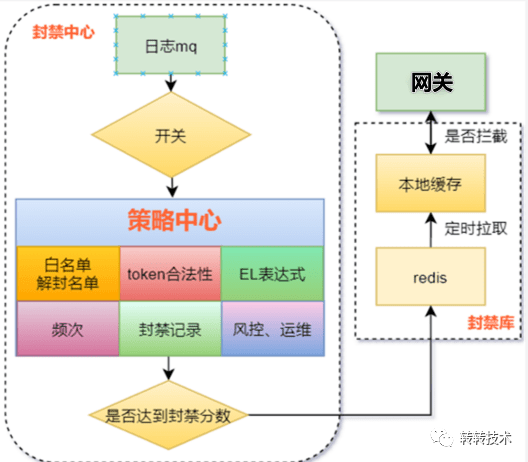
“封禁中心的核心在于设置策略与计分标准。”
“在接收到数据处理中心发出的MQ后,分析数据之前,我们首先要有个开关,毕竟如果有天这个系统抽风了,至少可以及时关闭它。”
“策略中心包含着诸多分析用户行为的策略,它会对这些MQ中用户的行为list针对这些策略进行判定,打分,每一个策略会有一个得分。如果最后这个用户的所得分数之和大于设置的惩罚阈值,则将之封禁。”
“几种主要的策略”
- 用户唯一标识合法性: 由于用户的唯一标识具有一定的生成规则,转转也不例外,我们自然可以利用这些规则判断请求是否为真实用户。大量的非法请求都不需要其他判断,仅用生成规则即可屏蔽,这种策略主要是用来阻挡正面进攻。
- 频次: 同样地,这种策略主要是用来阻挡正面进攻。只不过它是用来弥补标识合法性策略的不足,当爬虫利用真实用户的标识进行大量请求时,我们可以利用它们高频次的特点,对特定接口设置阈值频次,当请求次数超过限制,则对指定用户特征进行封禁。
- El表达式: 上面两种策略可以极大地削弱正面进攻的影响,但是对于间谍行动则几乎无能为力,因为当一些狡诈的爬虫在多次受挫,摸清了反爬策略,频次阈值后。它们就会选择模仿真实用户的行为进行请求,放弃短时间获取大量信息的幻想,转而寻求虽然时间长但可以获取完整数据的途径。这时EL表达式就派上了用场,由于封禁中心可以得到用户的一个请求串,Cleaner可以分析在这串请求中用户的行为,看看它们和正常用户的请求有何偏差,这时的爬虫虽然没有了高频次的特点,但周期性,规律性的特点,是爬虫的原罪,它们永远无法避免。根据一些接口请求顺序的不同,频次比例的不同等特点可以推断出该用户是否非法。
- 封禁记录: 辅助策略,把命中封禁的用户维度落入数据库中,作为日后判定是否封禁的一项指标。
- 黑白名单: 指定特征跳过或强制封禁,支持手动添加,以防系统失效或紊乱。
- 接入其他封禁库:辅助策略,结合其他业务的封禁信息,完善判断结果。
“计分标准”
“计分标准实际上是对每个策略得分的微调,这需要从多次抗击爬虫的实战中得来,并在最后动态平衡到一定的数值。”G先生凝神道:“没有完美确定的那个数值,我们能做的只有无限逼近。”
“总结一下”
“封禁中心是Cleaner系统的核心,是整个系统保证准确性的关键。由于爬虫会不断进化,进攻方式也多种多样,所以封禁中心的关键就在于不断迭代,动态地调整各种策略以及参数,在实际应用中不断完善,达到最好的效果。”
4.1.3 封禁库
“对于被封禁的用户,我们会把其封禁维度放入和网关连通的redis中”
“当用户请求进入网关,我们需要迅速判定这次请求是否非法,由于数据量庞大,耗时需要尽可能低,所以封禁库的设计必须轻量化,响应必须足够快。Cleaner的封禁库仅采用了本地缓存和redis,每过一定的时间间隔,本地缓存就会从redis中更新封禁的key,而本地缓存的耗时几乎可以忽略不计。”
“系统的模块就大概是这样了,有没有人有兴趣一起开发?”G先生环顾四周,找到了一双热烈的眼神:“小C,就你了。”
小C一下子站起身,和G先生一起走进小黑屋里密谋了起来。
4.2 效果
A thousand years later...
“实际应用后,经历了多次爬虫清理任务,这过程中也有多次参数和策略的调整。”G先生拍了拍小C的肩膀道:“果然最终的效果显著,你看这个图。横轴是每天每个ip请求某核心接口的次数,竖轴是每天请求该接口某一次数范围内的ip总数。”
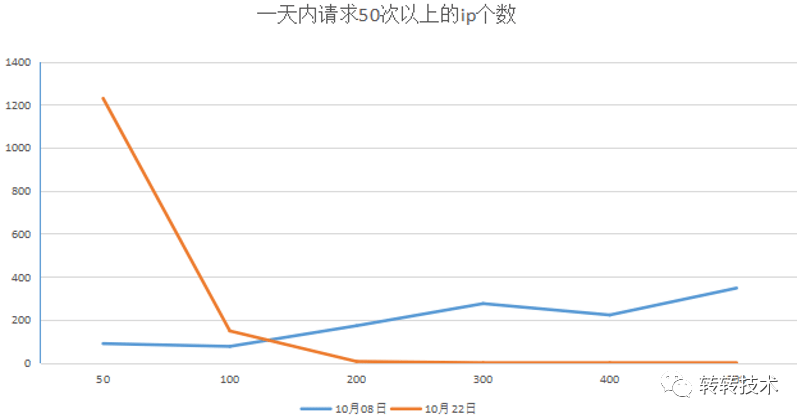
“说明我们成功了。”小C激动地说:“50次ip的升高说明了原来200次以上的ip都在请求了50次之后被及时封禁住了!”
“是呀,现在看来至少现阶段我们是成功的。爬虫的进攻已经被我们阻挡住了。没有辜负这段时间的辛苦呀!”G先生和小C灿烂地笑了,笑得像两只200斤的獒。
五、总结
我们在应对爬虫的过程中,考察了前人的研究成果,总结了爬虫具有的和反爬系统应具有的特点,最终规划出一个可实行的具体的反爬虫系统方案。
反爬虫系统
- 基本特性:实时性,准确性。
- 基本功能:合法性校验,频次控制,用户行为分析。
- 基本模块:大数据处理中心,封禁策略中心。
- 基本策略:合法性校验策略,频次策略,EL表达式策略,黑白名单策略。
- 两个动态:反爬策略的完善、插拔;计分标准的调整。
- 一种平衡:爬虫和反爬虫是一个漫长的博弈过程,二者最终会达到一种平衡状态,面对爬虫的不断反弹,我们能做的是持续地监控,迅速地压制。
目前,Cleaner反爬虫系统可以达到对可疑用户10s内的迅速封禁,以搜索接口为例每天阻拦着数百万次高危请求。
Cleaner正时时刻刻保卫着转转的数据安全。