一文破解正则密码
前言
正则,熟悉的陌生人,我们在表单校验中见到它,也在框架源码 html 转 ast 树的 parser 原理中见到它;常常见到,需要时百度一搜,确实能用,却又一碰到就发憷,原因很简单,这火星文,谁看得懂呀!
本文目标,带你走进正则世界,作为一篇认真负责的科普文,一定要做到让你们一遍学懂却不会,于是反复来查看。

正则历史
正则其实就是规则的设定,用于验证或者获取信息。
真正起源于神经网络
20 世纪 40 年代,两位神经生理学家研究出了一种用数学方式描述神经网络的方法,并以此在 1956 年发表了一篇论文《正则表达式搜索算法》,主要描述了一种叫做正则集合(Regular Sets)的符合。
在计算机世界大放异彩
UNIX 之父在十年后的 1968 年,发表文章《正则表达式搜索算法》,并将正则移植到了大名鼎鼎的文本搜索工具grep中。

正则为什么存在
理解一个东西,不要一上来就背应用层的 API,要去理解,人的大脑本来就是被设计成对理解的东西很容易记忆,不要浪费自己的天赋。
我们说过,正则其实就是规则的设定,用于验证或者获取信息。匹配动作最粗暴的无疑是一一对应,a 对 a,b 对 b,这个规则就是完全一样才匹配,但这无疑太低效;一个事物很容易有共性,共性构成集合,比如手机号 13 位,邮箱带@等等,正则就是让我们更高效的匹配或获取这些特定规则集合的存在。

正则如何做到
正则中的处理方式就是设定子规则,让某些符号不再代表本身,而是代表一些子规则,就像搭建大楼,我们希望找到自己想要的规则,就得用合适的最小砖块,再设定使用量,就搭建完成了。
这个子规则,就是元字符,如我们常见的\d,代表单个 0-1 数字,\s就是换行指标等空白字符;需要注意的是,我们刚刚一直在强调单个,这其实也很好理解,对于文本而言,最小单元自然是单个字符,有了最小单元,我们再加上重复规模,就可以搭建我们自己的大楼了。
至此,我们对正则世界基本的了解算是到位了,开始更接地气的分享叭!

砖块:元字符
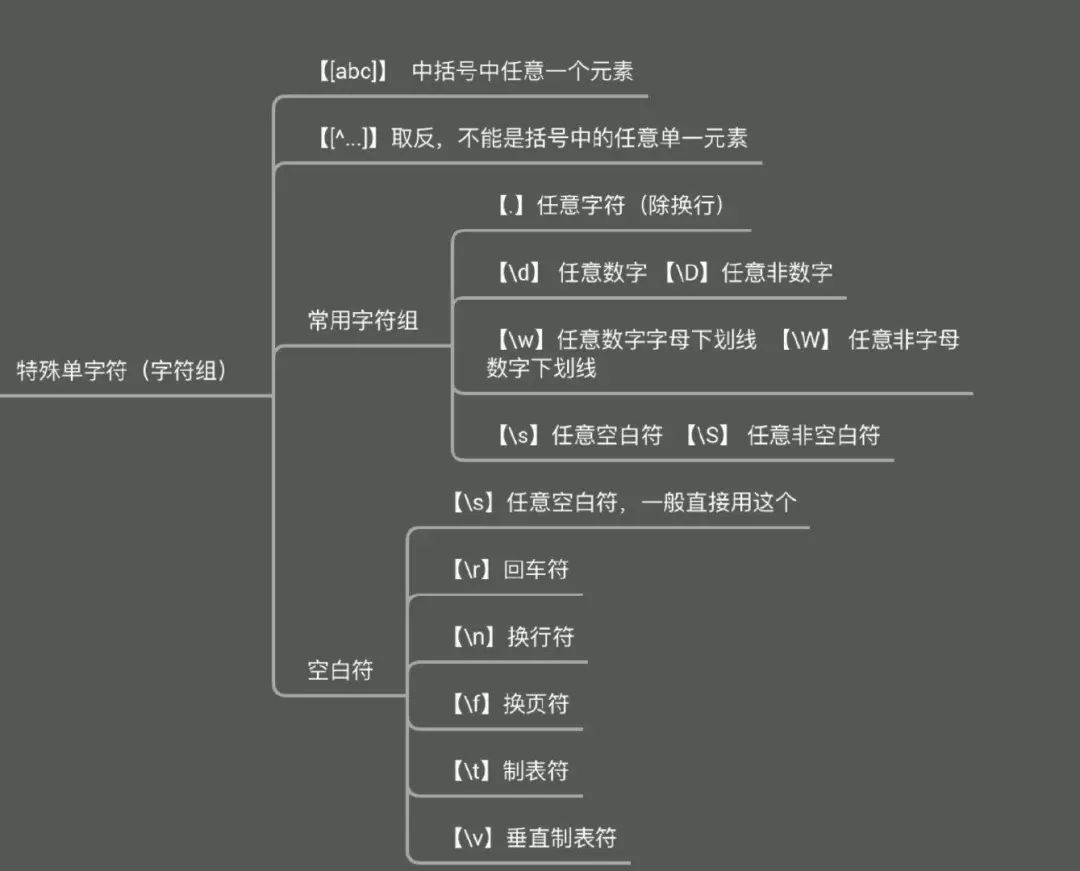
那我们先来了解元字符,有四个维度,分别是【字符组】、【取反字符组】、【常用字符组】、【空白字符】,可以记忆为 【3 + 1】,依次理解
字符组
基础使用
对于单字符选择而言,在正则中的术语被称为字符组,接下来我们都会用这个术语,但不要被迷惑,它并不是匹配一组数据,而只是匹配一组数据中的一个字符,这点很关键。
语法:[xxx]
匹配规则: 目标文本需包含【任意一个包含在括号中的元素】
获取信息规则:将获取第一个【任意一个包含在括号中的元素】
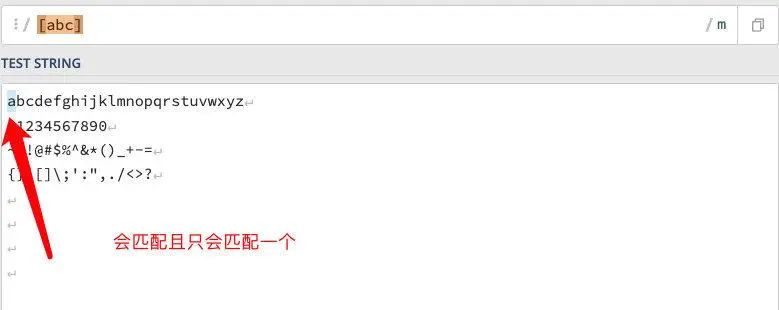
举例:/[abc]/这个正则将匹配 a、b、c 中的任何一位且只有一位,默认匹配第一位,使用测试平台会得到如下结果
取反字符组
取反逻辑
正常使用是范围内选取,不过也会出现【除了这些之外】的范围选取,这时就需要用到取反了
语法:[^xxx]
匹配规则: 目标文本需包含【任意一个不包含在括号中的元素】
获取信息规则:将获取第一个【任意一个不包含在括号中的元素】
举例:/[^abc]/这个正则将匹配非 a、b、c 中的任何一位且只有一位,默认匹配第一位,使用测试平台会得到如下结果

常用字符组
八二原则同样适用在字符组中,有很多常见的匹配规则,没必要重复写,于是正则就把这些特殊字符组分别取了个别名

| 使用符号 | 规则 | 对应字符组 |
|---|---|---|
| \d | 单个数字 | [0-9] (digit 数字) |
| \D | 单个任意非数字 | [^0-9] |
| \w | 单个任意数字字母下划线 | [0-9a-zA-Z_] 数字字符下划线 |
| \W | 单个任意非数字字母下划线 | [^0-9a-zA-Z_] 非单词字符 |
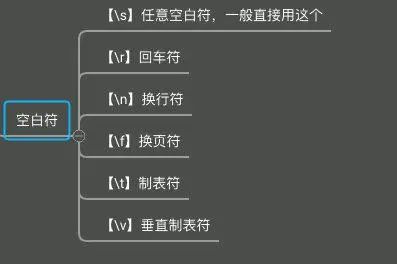
| \s | 单个任意空白符 | [ \t\v\n\r\f] 表示空白符 (空格、水平制表符、垂直制表符、换行符、回车符、换页符) |
| \S | 单个任意非空白符 | [^ \t\v\n\r\f] |
| . | 单个除换行符外任意字符 | [^\n\r\u2020\u2029] 通配符 除换行符、回车符、行分隔符、段分隔符外任意字符 |
其他常用字符组
| 对应字符组 | 对应字符组 |
|---|---|
| [\d\D] [\s\S] [\w\W] [^] | 任意字符 |
空白字符
这类字符比较特殊,单独拎出来,方便后期直接使用
要多少块砖:量词
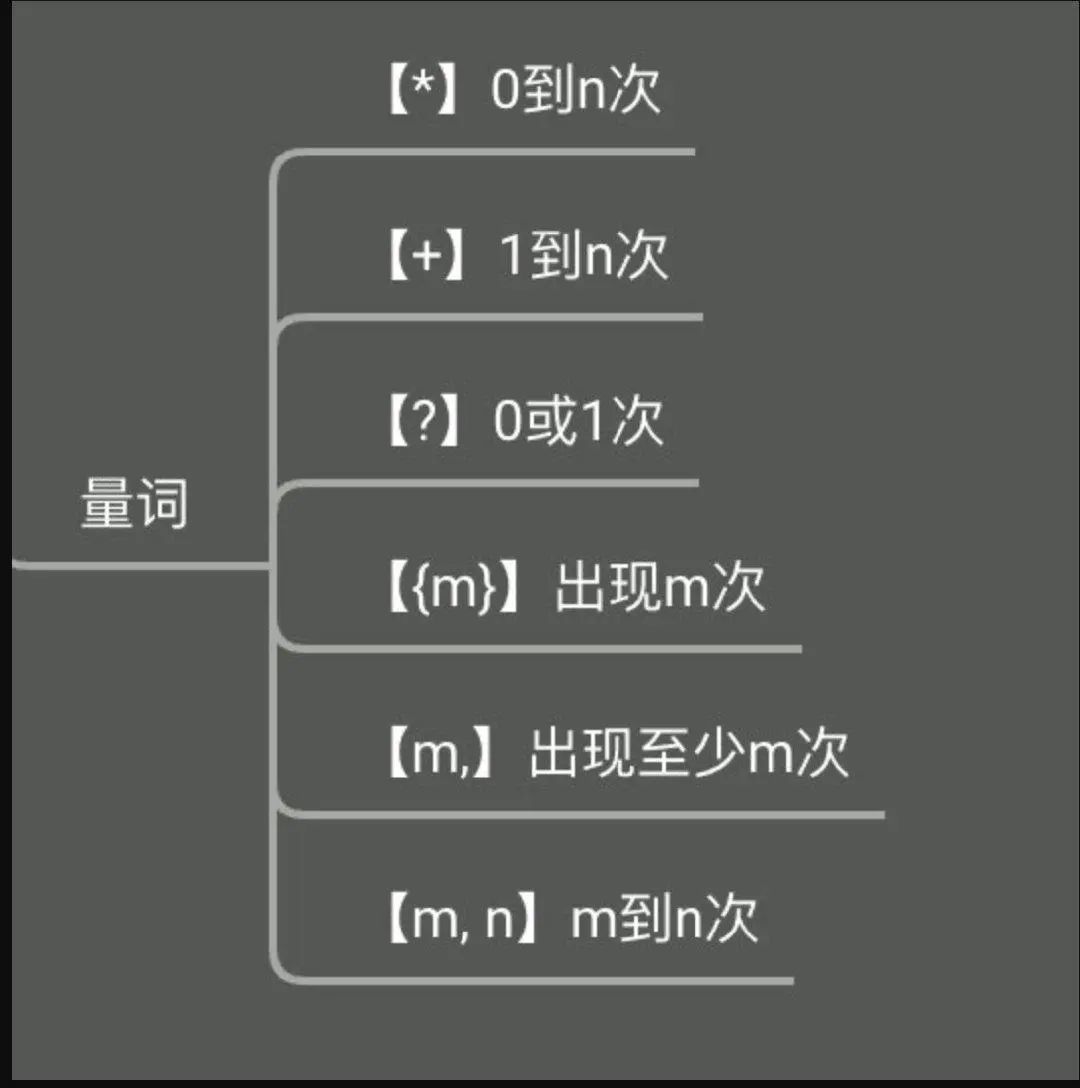
理解了字符组,我们就要了解规模了,这在正则中有个术语 --- 量词,还是【3+1】,依次理解
g,后面再补充;
看案例就行,我们还是以[abc]作为字符组最小单元来演示。
*号:0-n 次
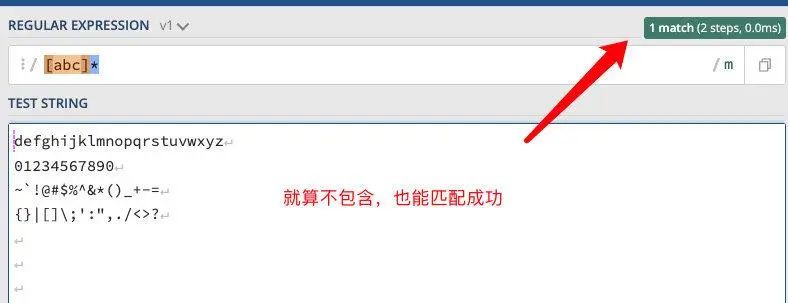
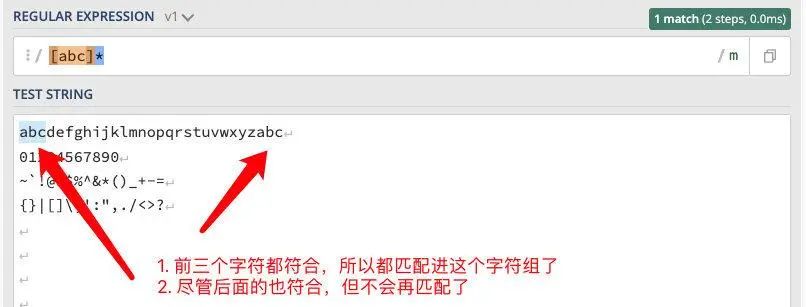
正则:/[abc]*/
匹配规则: 目标文本无需包含【任意一个包含在括号中的元素】,此匹配规则一定成立
+号:1+n 次
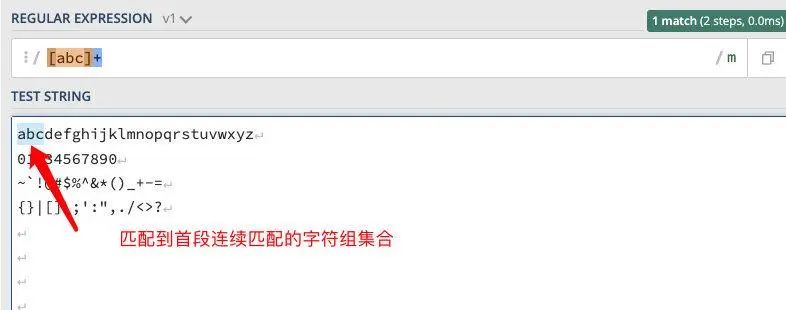
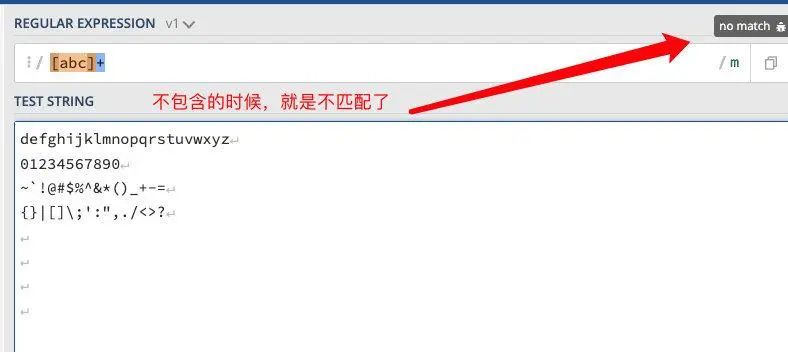
正则:/[abc]+/
获取信息规则:将获取第一段【包含在括号中且连续的元素组】
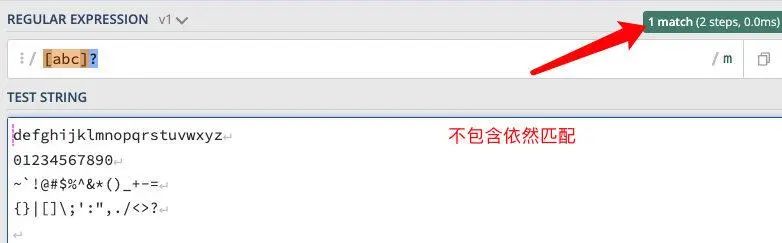
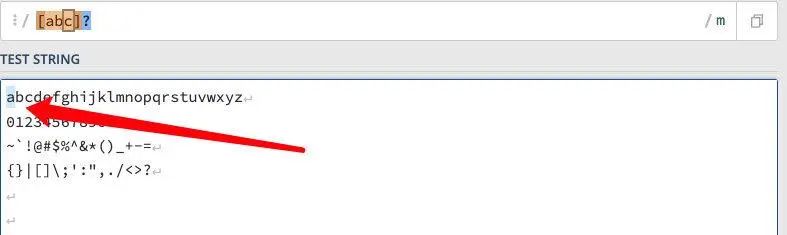
?号:0 次或 1 次
正则:/[abc]?/
匹配规则:此匹配规则一定成立
{}符号:精确控制次数
上面其实都属于特殊案例,我们可以通过{}精确控制匹配次数,主要有三个用法
- {m}:必须出现 m 次
- {m, n}:可以出现 m-n 次
- {m,}:至少出现 m 次
我们对这三种情况进行演示,动图如下
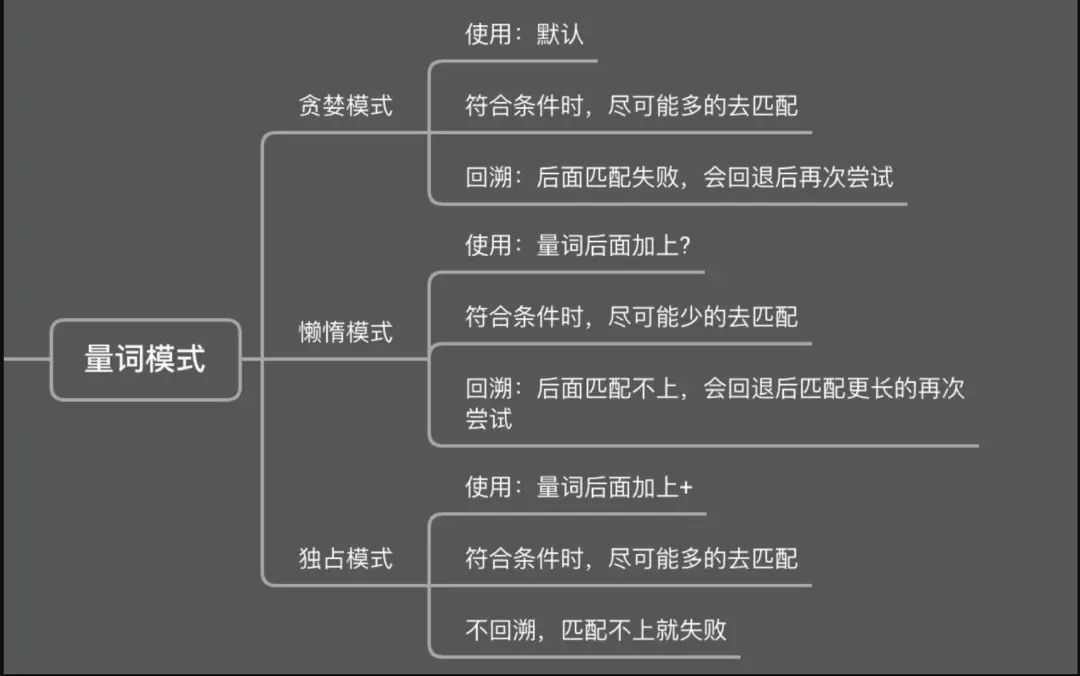
量词模式
量词还涉及到模式问题,因为量词有范围,这就意味着可取多可取少,但计算机是不允许有歧义的,所以量词存在三种模式
- 贪婪模式:默认,会尽可能匹配多的内容
- 懒惰模式:量词后面加个
?,会尽可能少匹配内容 - 独占模式:量词后面加个
+,不触发回溯动作
举例见模式区别
测试用例:aaabb
测试正则:
- 贪婪模式:
/a*/ - 懒惰模式:
/a*?/
贪婪模式:/a*/
匹配过程:
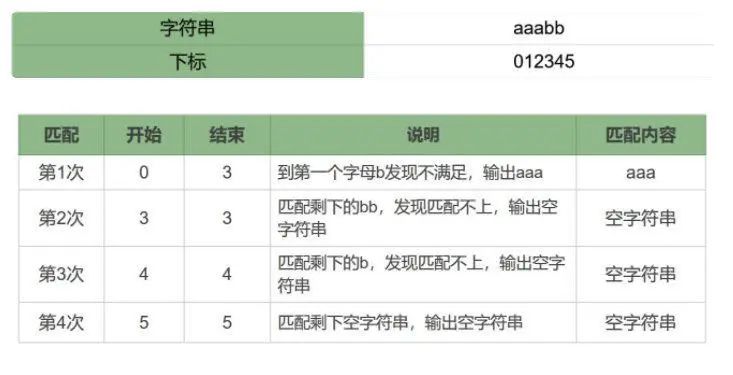
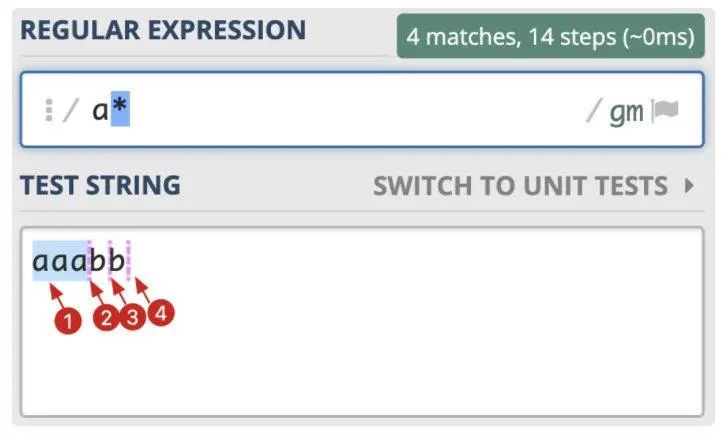
['aaa','','','']
懒惰模式:/a*?/
匹配过程:
匹配结果:
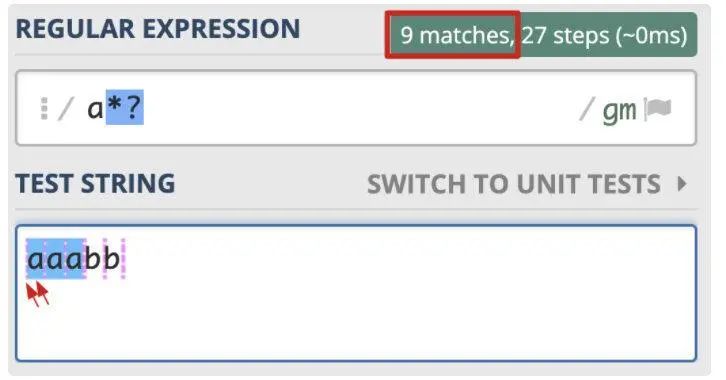
['','a','','a','','a','','','']
补充案例
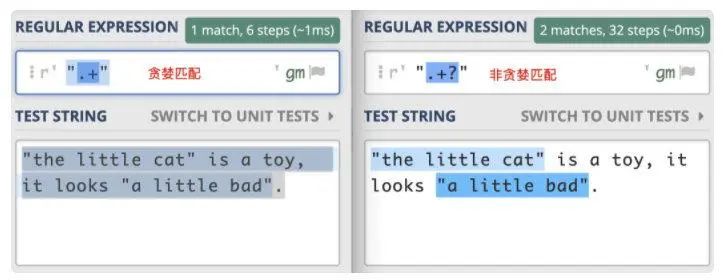
正则模式
既然量词有模式,正则本身自然也有模式,针对【大小写、多行、点通配、备注】情况,存在【3+1】种模式
- 不区分大小写模式
- 点通配模式
- 多行匹配模式
- 注释模式
我们来逐一了解
不区分大小写模式(Case-Insensitive)
语法:/(?i)reg/ 对应 js 为 /reg/i
注意点:
- 不区分大小写模式的指定方式,使用模式修饰符 (?i);
- 修饰符如果在括号内,作用范围是这个括号内的正则,而不是整个正则;
作用: 忽略大小写进行匹配
正则:/(?i)(cat) \1/ 对应 js 为 /(cat) \1/i
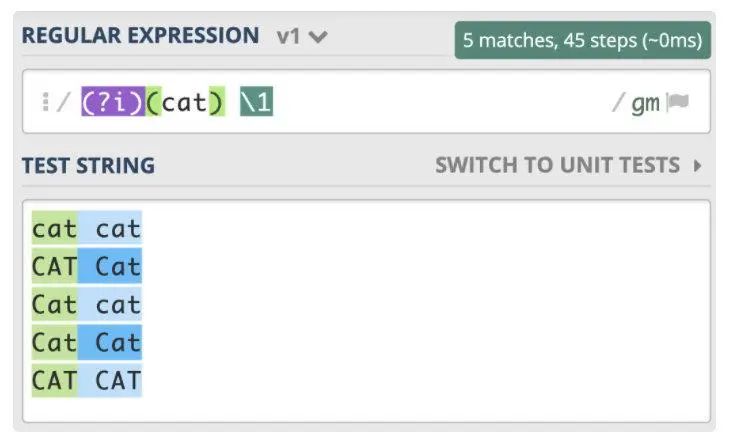
正则:/((?i)cat) \1/ 对应 js 为 暂无

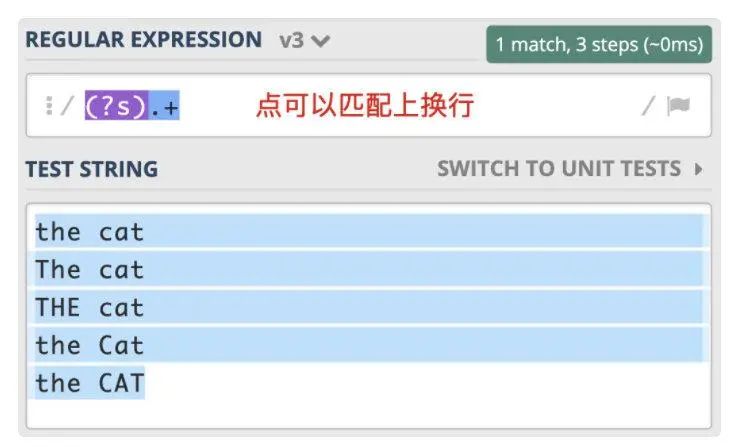
点通配模式(单行匹配模式 -- Single Line)
语法:/(?s)reg/ 对应 js 为暂无
注意点:
作用: 使得.元字符可以匹配包括换行在内的所有字符
多行匹配模式
语法:/(?m)reg/ 对应 js 为/reg/m
注意点:
作用: 使得^和$可以匹配上每行的开头或结尾
使用前正则:/^the|cat$/

/(?m)^the|cat$/ 对应 js 为/^the|cat$/m

注释模式
语法:/(?#)reg/ 对应 js 为 暂无
注意点:
作用: 使得正则支持添加备注信息
使用正则案例:/(\w+)(?#word) \1(?#word repeat again)/
正则位置信息
对于匹配而言,就像我们看一个人是不是自己要找的人,不只有对着画像、照片一直看这一个方法,也可以描述 TA 在什么东西的旁边、TA 面前是什么、背后是什么等等,这些位置信息在正则中同样有需求,并且有个专门的术语 -- 断言。
断言,即断定匹配文本的位置关系;前后的内容是什么、中止的位置在哪之类,落实下来分为三类:单词边界、行的开始/结束、环视。
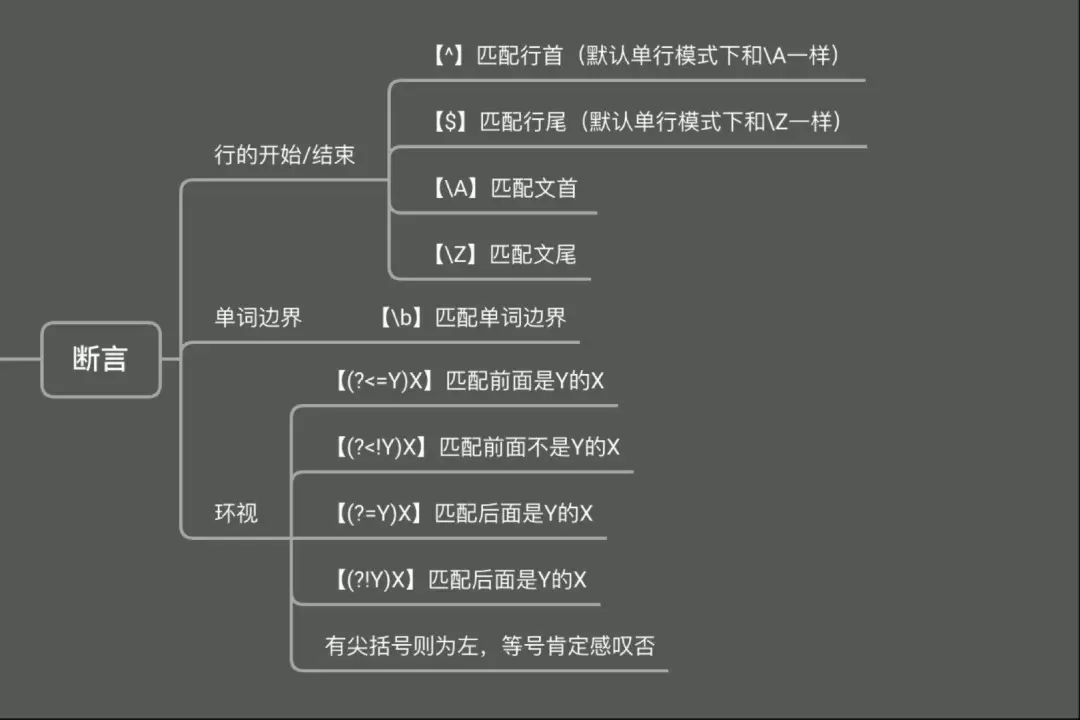
行的开始/结束
这个我们或多或少都接触过,如果我们要求匹配的内容出现在一行文本的开头或结尾,就可以使用^和$进行位置界定。
结合之前说的【模式】中多行模式的概念,默认处理文本会被正则当成一行进行处理,无论其是否换行,这是的开始结束就等同于文首和文末;而如果想处理多行情况,只需要改变模式为多行匹配即可,js 中语法为/reg/m。
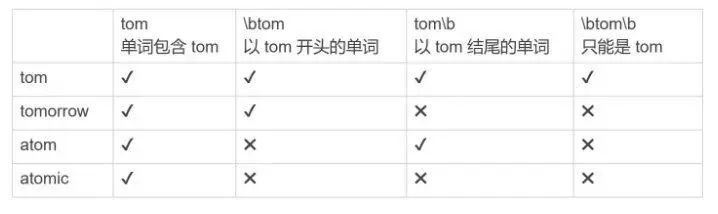
单词边界(Word Boundary)
多行模式+^$可以在行的维度处理边界问题,但如果是单词,就无能为力了,如我们希望在下面文本中替换tom这个人名为jerry
tom asked me if I would go fishing with him tomorrow.
这时如果替换的正则是/tom/ ,就会出现这种错误的替换现象

tom,而并不是只要包含 tom 就可以的部分,这时我们就可以使用到单词边界的概念,设定开始截止,避免出现匹配歧义。
基础概念
语法:\b
作用: 匹配到\w即【[A-Za-z0-9_]】表示范围之外的字符就中止匹配,可以理解为边界(Boundary)
实例
环视
我们刚刚说了边界,包括单词和行的边界,其实边界也就是要求匹配文本的前后一定是特定的内容,只是这个特定内容对行来说是^$,对单词边界来说是$;
那我们把这个特定范围再灵活点,对于一段内容而言,有前后两个方向、满足或者不满足两个情况,意味着有四种情况,如下表。
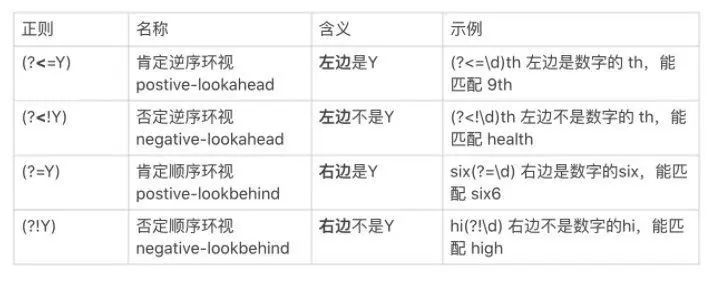
正则逻辑信息
根据前文,我们已经学习了【字符组】和【量词】的概念,就像一门编程语言,有组成物料还不够,自然还需要一些逻辑判断,在正则中也存在【逻辑元字符】这一概念。
逻辑元字符
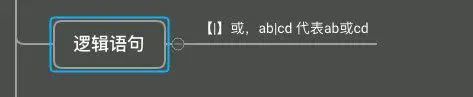
|号:或逻辑
某个资源可能以 http:// 开头,或者 https:// 开头,也可能以 ftp:// 开头,那么资源的 协议部分,我们可以使用 (https?|ftp):// 来表示。

正则优先级提升之分组
在正则中存在分组的概念,主要有两点作用:整体和复用。

整体
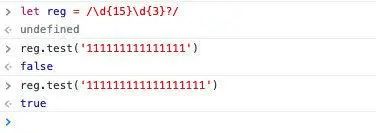
代表避免语义分析有歧义,如【匹配 15 位数字或 18 位数字】,这时如果写出这样的正则/\d{15}\d{3}?/;后面的\d{3}?将代表懒惰模式匹配,这个正则会只匹配 18 位数字而非 15 位
测试正则:/\d{15}\d{3}?/
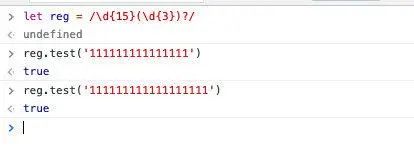
\d{3}是一个整体的需求,这可以使用分组实现
测试正则:/\d{15}(\d{3})?/
复用
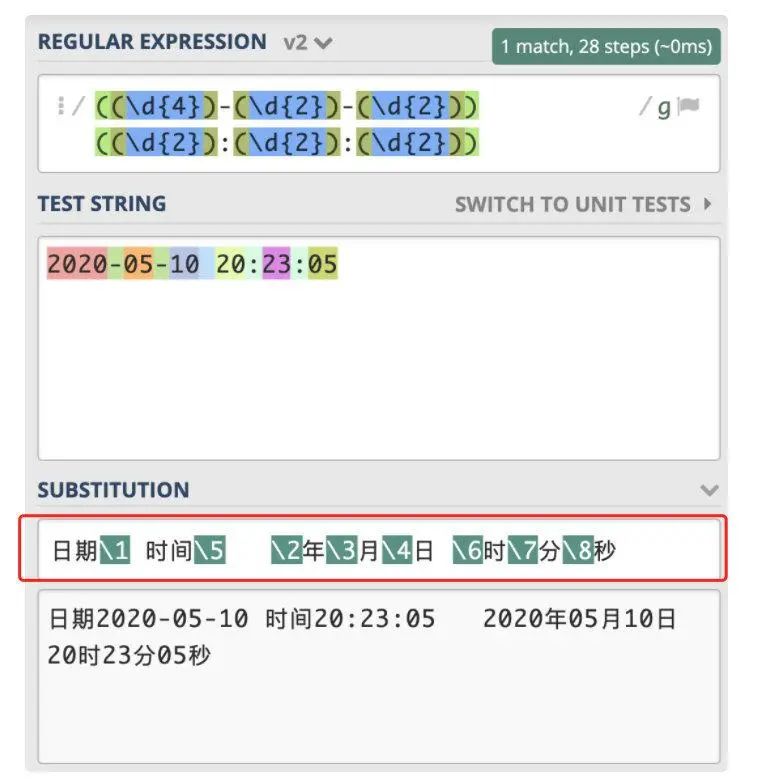
有些时候,我们也会需要用到之前匹配到的结果,如【查看文本中的连续重复单词】,解决思路就变成了
- 写出匹配单个单词的正则
- 使用之前的结果进行再次匹配
第二点,就是通过分组实现的;先了解下基础概念
基础概念
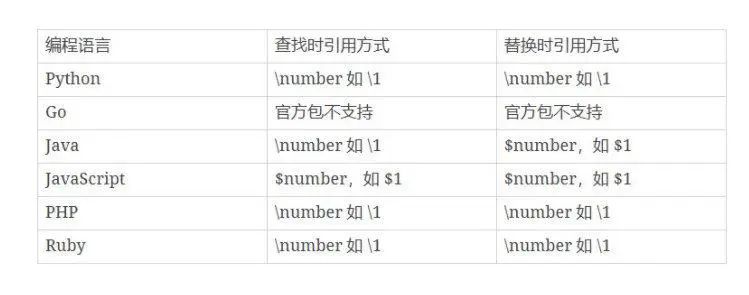
语法: 定义使用() ,正则中访问使用\编号,方法中访问使用$编号
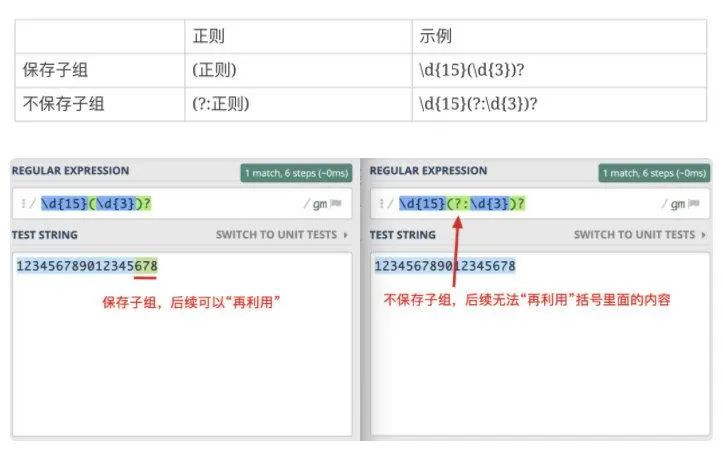
作用: 用于分组,被括号括起来的部分默认将被保存为子组,正则中可以通过子组编号访问,子组编号从一递增,也可以用语法(?:)从而不保存子组,避免占用编号。
分组引用语法详解
分组引用
假定分组编号为number,则可以使用\number进行引用
多编号情况
左括号是第几个,那就是第几个分组

不保存子组
使用此语法后不会为这个子组分配编号
替换功能
命名分组
V8 目前已经完全实现了命名捕获分组的提案 https://tc39.github.io/proposal-regexp-named-groups/,一起来了解下吧!
基础概念
语法: 定义使用(?<name>) ,正则中访问使用\k<name>,方法中访问使用$<name>
作用: 用于命名分组,不再使用编号访问而是直接通过分组变量名访问,更加准确

API 结合解构赋值
在 js 关于正则的方法中,如果存在命名分组,会存在groups属性,里面存放着每个命名分组的名称以及它们匹配到的值;结合解构赋值,会有很神奇的功效;
在 exec() 和 match() 中的使用:
exec() 和 match() 方法返回的匹配结果数组上多了一个 groups 属性,里面存放着每个命名分组的名称以及它们匹配到的值
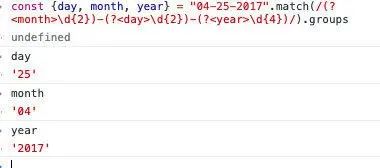
const {day, month, year} = "04-25-2017".match(/(?<month>\d{2})-(?<day>\d{2})-(?<year>\d{4})/).groups
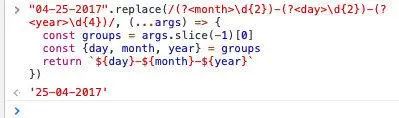
当replacement为函数时,在实参列表的最末尾,多传了一个 groups 对象
"04-25-2017".replace(/(?<month>\d{2})-(?<day>\d{2})-(?<year>\d{4})/, (...args) => {
const groups = args.slice(-1)[0]
const {day, month, year} = groups
return `${day}-${month}-${year}`
}) 
正则编程
这是最最关键的部分,学来就得用上呀,我们来分享在正则在前端编程中的应用。
正则最终还是要落实到编程语言中来,让我们来看下正则编程吧!
正则的处理可以区分为如下四类:
- 校验文本内容
- 提取文本内容
- 替换文本内容
- 切割文本内容
让我们逐一了解
校验文本内容
需注意:关于 lastIndex,即正则会将下一次匹配开始的位置 ;字符串的四个方法,每次匹配都是从 0 开始的,即 lastIndex 不变;而正则的两个方法 exec 和 test ,如果是全局匹配,则每次匹配完都会改变 lastIndex 的值,这就会导致可能出现【处理两次,第一次成功,第二次失败】的情况。
var regex = new RegExp(/^\d{4}-\d{2}-\d{2}/, 'g')
regex.test('2021-12-21') // true
console.log(regex.lastIndex ) // 10
regex.test('2021-12-21') // false
console.log(regex.lastIndex ) // 0由于我们这里是文本校验,并不需要找出所有的。所以建议 JavaScript 中文本校验在使用 RegExp 时不要设置 g 模式。
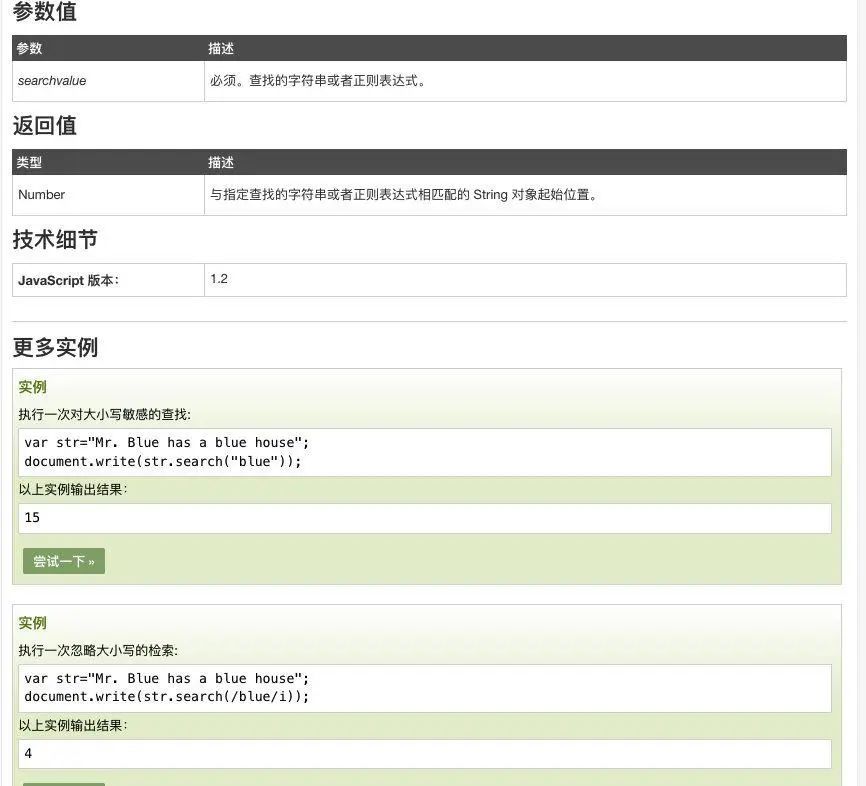
字符串方法:search
search 会将字符串转为正则
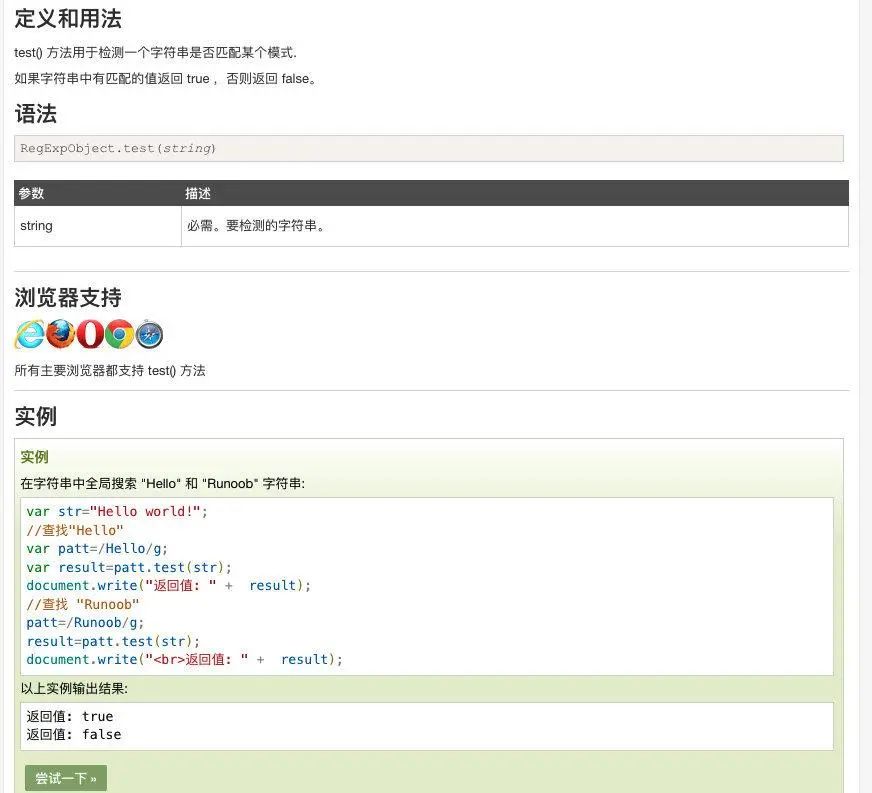
正则方法:test
提取文本内容
字符串方法:match
match 会将字符串转为正则
注意:match 方法的返回值与修饰符 g 有关(没有匹配上时返回 null)
- 没有 g :返回标准匹配格式,即:数组的第一个元素是整体匹配的内容,接下来是分组捕获的内容,然后是整体匹配的第一个下标,最后是目标字符串
- 有 g :返回的是一个包含所有匹配内容的数组

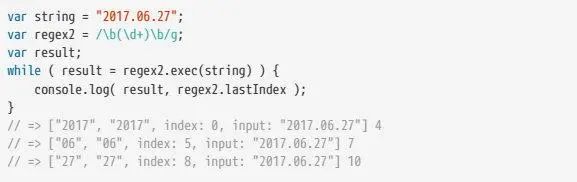
正则方法:exec
exec 比 match 更强大,可以解决 有修饰符 g 时 match 没有索引信息的问题,在使用 exec 时,正则会将下一次匹配开始的位置存放在正则的属性 lastIndex 上

替换文本内容
字符串方法:replace

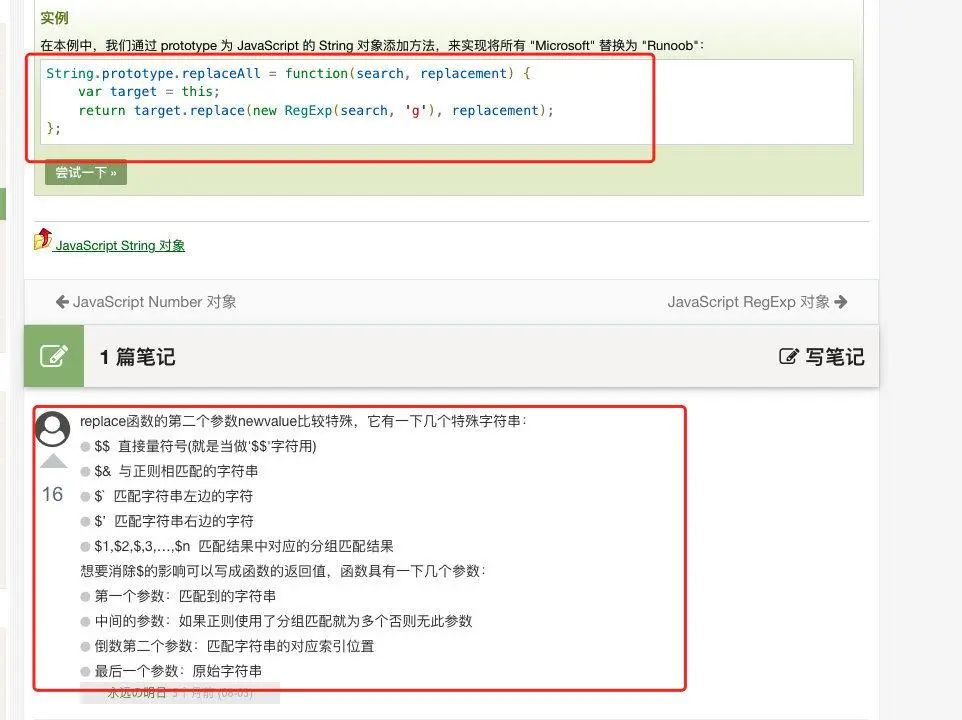
切割文本内容
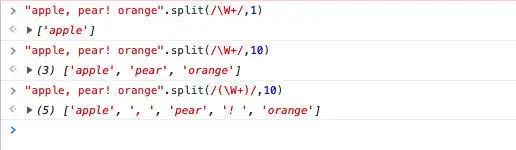
字符串方法:split
- 可以有第二个参数,表示结果数组的最大长度
- 如果正则使用分组时,结果数组中是包含分隔符的
前端相关 API 总结
-
string
-
match
-
split
-
search
-
replace
-
RegExp
-
test
-
exec
总结
做下总结吧,绘制知识图谱,方便自己记忆,也方便和人分享
3 + 1 元字符;3 + 1 常用元字符;3 + 1 正则量词;3 量词匹配模式;3 + 1 正则匹配模式;3 + 1 正则逻辑
首先物料元字符,有四个维度,分别是【字符组】、【取反字符组】、【常用字符组】、【空白字符】,可以记忆为 【3 + 1】;
理解了字符组,我们就要了解规模了,这在正则中有个术语 --- 量词还是【3+1】;
量词还涉及到模式问题,因为量词有范围,这就意味着可取多可取少,但计算机是不允许有歧义的,所以量词存在三种模式;
既然量词有模式,正则本身自然也有模式,针对【大小写、多行、点通配、备注】情况,存在【3+1】种模式;
就像定位,不止需要本身的绝对信息,还需要看他的相对位置信息,这个信息在正则中叫断言,存在三种情况,【行首尾、单词边界和环视】,其中环视又存在前后是不是四种情况
就像编程语言,我们有了零碎的物料是不够的,还需要逻辑,在正则中存在分支语句|和优先级分组,分组又有三类,默认分组、非捕获分组和命名分组
至此,我们也就用非常精炼的总结性语句概括了正则的整体脉络啦!

尾声
少年们,心法已定,拿走不谢,希望我能做到让你们一遍看懂而记不住,要首尾呼应,尝试动手自己实现下吧,有些需求会发现如果用正则的角度,会有很多很神奇的实现方式呀,而且如果能帮助到别人,也超有成就感的。