MySQL 简单查询语句执行过程分析(四)WHERE 条件
本文是 MySQL 简单查询语句执行过程分析 6 篇中的第 4 篇,第 1 ~ 3 篇请看这里:
[MySQL 简单查询语句执行过程分析(一)词法分析 & 语法分析]
[MySQL 简单查询语句执行过程分析(二)查询准备阶段]
[MySQL 简单查询语句执行过程分析(三)从 InnoDB 读数据]
今天我们分为 3 个部分来介绍,首先会看一下 where 条件在源码中的结构是什么样的,对 where 条件结构有了初步了解之后,再来看看判断记录是否匹配 where 条件的执行过程。最后,展开讲讲 3 种特殊类型的字段作为 where 条件时,是怎么进行比较的。
内容目录如下:
-
where 条件结构
-
where 条件比较
-
三种特殊类型字段怎么比较?
-
set 字段
-
enum 字段
-
bit 字段
-
示例表如下:
CREATE TABLE `t_recbuf` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`i1` int(10) unsigned DEFAULT '0',
`str1` varchar(32) DEFAULT '',
`str2` varchar(255) DEFAULT '',
`c1` char(11) DEFAULT '',
`e1` enum('北京','上海','广州','深圳','天津','杭州','成都','重庆','苏州','南京','洽尔滨','沈阳','长春','厦门','福州','南昌','泉州','德清','长沙','武汉') DEFAULT '北京',
`s1` set('吃','喝','玩','乐','衣','食','住','行','前后','左右','上下','里外','远近','长短','黑白','水星','金星','地球','火星','木星','土星','天王星','海王星','冥王星') DEFAULT '',
`bit1` bit(8) DEFAULT b'0',
`bit2` bit(17) DEFAULT b'0',
`blob1` blob,
`d1` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2001 DEFAULT CHARSET=utf8;1 . where 条件结构
我们平时在写 SQL 的时候,where 条件中会使用括号,也会出现多层 and、or 嵌套的情况,特别是使用各种 ORM 框架时,框架生成的 SQL 语句括号嵌套一层又一层,层峦叠嶂,非常壮观。
MySQL 中多层 where 条件会形成一棵树状结构,每多一个层级,都需要额外的逻辑处理,执行效率上会有一点影响,所以在语法分析阶段,就会对 where 条件的树状结构层级进行简化,可以合并的层级就合并。
上面说的树状结构,不是二叉树或多叉树实现的那种树结构,而是每一层的 Item_cond_and 或者 Item_cond_or 都包含一个子条件数组,而数组中的每个元素可能又是包含子条件数组的 Item_cond_and 或者 Item_cond_or,这样多层就会组成类似树状的结构。
文字描述太抽象,我们用一个例子来说明。
select * from t_recbuf
where (i1 > 1024 and e1 = '成都')
or (d1 > 1020.05 and d1 < 1048576.88)示例 SQL 中的 where 条件结构如下图:
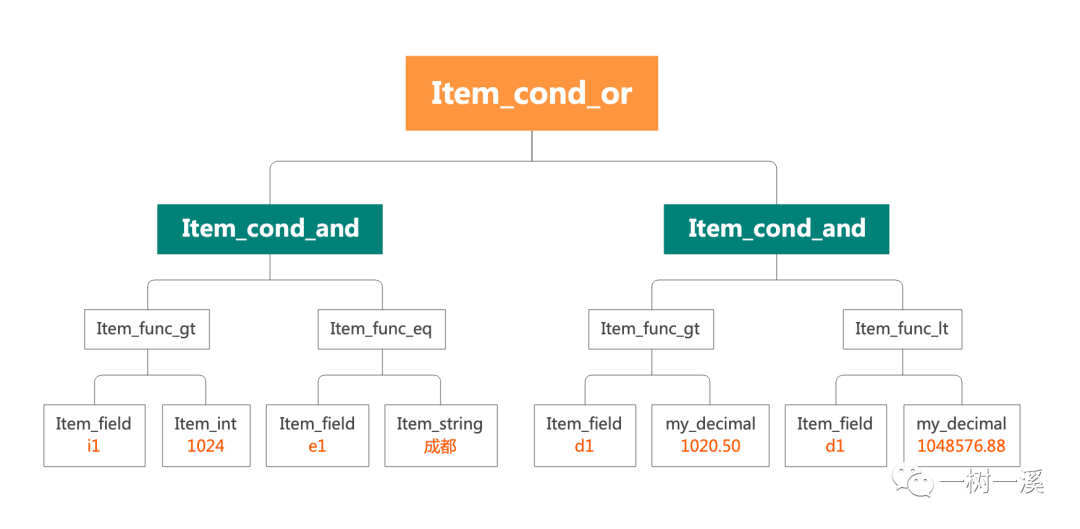
从上图可以看到,where 条件的结构有两层,第一层是 Item_cond_or 类实例,类实例有个 list 属性,是个数组,数组的两个元素都是 Item_cond_and 类实例。
第一个 Item_cond_and 类实例对应 where 条件中的 i1 > 1024 and e1 = '成都',这个类实例也有个 list 属性,是个数组,数组的两个元素分别是:
- Item_func_gt 类实例,表示
i1 > 1024 - Item_func_eq 类实例,表示
e1 = '成都'
第二个 Item_cond_and 类实例对应 where 条件中的 d1 > 1020.05 and d1 < 1048576.88,这个类实例也有个 list 属性,是个数组,数组的两个元素分别是:
- Item_func_gt 类实例,表示
d1 > 1020.05 - Item_func_lt 类实例,表示
d1 < 1048576.88
-
where 条件比较
还是以上一节 where 条件结构中的示例 SQL 为例来讲述本节的内容。
执行示例 SQL 从存储引擎读取到一条记录后,判断记录是否匹配 where 条件,其入口代码很简单,贴出来看一下:
// 以下代码中,各行代码之间也省略了其它无关的代码
Item *condition= qep_tab->condition();
bool found= TRUE;
if (condition)
{
found= MY_TEST(condition->val_int());
}对于示例 SQL 来说,代码中的 condition 就是 Item_cond_or 条件,执行 Item_cond_or::val_int() 时,会遍历 Item_cond_or 条件的 list 数组,判断其中两个 Item_cond_and 条件是否为 true,只要有一个为 true,condition->val_int() 返回 1,表示记录匹配 where 条件。
如果两个 Item_cond_and 条件都为 false,condition->val_int() 返回 0,表示记录不匹配 where 条件。
说完了怎么判断 Item_cond_or 条件是否为 true,再来深入一层,说说怎么判断它的下一层 Item_cond_and 条件是否为 true,我们以第一个 Item_cond_and 为例。
判断第一个 Item_cond_and 条件是否为 true 时,会遍历 list 数组,过程如下:
-
判断 Item_func_gt 条件(
i1 > 1024) -
如果为 false,结束循环,Item_cond_and 条件最终结果为 false。
-
如果为 true,还要判断接下来的 Item_func_eq 条件(e1 = '成都')。
-
判断 Item_func_eq 条件(
e1 = '成都') -
如果为 true,则 Item_cond_and 条件最终结果为 true。
-
如果为 false,则 Item_cond_and 条件最终结果为 false。
接下来,再往下深入一级,以 Item_func_eq 条件(e1 = '成都')为例说明最末级的 where 条件的判断过程。
Item_func_eq 条件(e1 = '成都' )中有一个属性 func,是用来比较存储引擎返回的 e1 字段的值是否等于成都的,func 属性在我们讲第二篇(查询准备阶段)时提到过,func 属性的值就是在查询准备阶段确定的,对于 e1 = '成都' 这个 where 条件,func 设置为字符串比较函数。
假设 server 层从存储引擎读取到一条记录,该记录 e1 字段的值为北京,和 where 条件中的成都,按字符串进行相等比较,结果为 false,那么 Item_func_eq 条件就为 false。
3 . 三种特殊类型字段怎么比较?
3.1 set 字段
set 类型的字段在 InnoDB 中以整数存储,字段返回给 server 层时也是整数,定义表结构时指定的每一个选项占用 1 bit。
示例表中,s1 字段定义时指定的选项为:吃, 喝, 玩, 乐, 衣, 食, 住, 行, 前后, 左右, 上下, 里外, 远近, 长短, 黑白, 水星, 金星, 地球, 火星, 木星, 土星, 天王星, 海王星, 冥王星。
共 24 个选项,每个选项占用 1 bit,正好占用 3 字节。
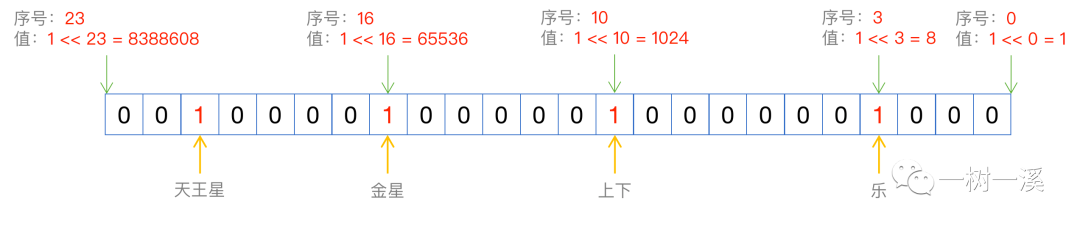
假设某条记录的 s1 字段包含 4 个选项:乐、上下、金星、天王星。
乐是第 4 个选项,序号为 3,值为 1 << 3 = 8。上下是第 11 个选项,序号为 10,值为 1 << 10 = 1024。金星是第 17 个选项,序号为 16,值为 1 << 16 = 65536。天王星是第 22 个选项,序号为 21,值为 1 << 21 = 2097152。
s1 字段的整数值由 4 个选项按位或计算得到:8 | 1024 | 65536 | 2097152 = 2163720,二进制示意图如下:
1,如果为 1,则把该选项文本(如上下)追加到 s1 字符串值的后面,用逗号分隔。
遍历完 24 个选项之后,s1 字段的整数值就转换为逗号分隔的字符串了(乐,上下,金星,天王星)。
示例 SQL 1:
select * from t_recbuf
where s1 = '水星,金星'前面读取出来的 s1 字段的字符串值(乐,上下,金星,天王星),和示例 SQL 1 的 where 条件 s1 ='水星,金星'进行比较,不相等,所以这条记录不匹配 where 条件。
从以上内容可知,用
where s1 = '水星,金星'这样的 where 条件只能找到 s1 字段的字符串值完全等于水星,金星的记录,是不能够找到 s1 字段中包含金星的记录的,如果想要查找 s1 字段中包含金星的记录怎么办?这就要用到 find_in_set() 函数了。
示例 SQL 2:
select * from t_recbuf
where find_in_set('金星', s1)还是以前面读取的记录为例,s1 字段包含 4 个选项:乐、上下、金星、天王星,执行示例 SQL 2 读取该记录的 s1 字段时,存储引擎返回的是整数值 2163720。
在语法分析阶段,find_in_set('金星', s1) 中的金星就被解析成选项对应的整数值 1 << 16 = 65536,然后和存储引擎返回的整数值进行按位与(2163720 & 65536 = 65536),计算结果为 65536,表示记录的 s1 字段中包含金星。
3.2 enum 字段
示例表中 e1 字段各选项及其对应的整数值如下图:

select * from t_recbuf
where e1 = '成都'执行示例 SQL 1,当读取到 e1 字段字符串值为长春的记录时,存储引擎返回的整数值为 13,server 层会把整数值 13 转换为对应的字符串值长春,然后和 where 条件中的成都进行等值比较,结果为不相等。
当读取到 e1 字段字符串值为成都的记录时,存储引擎返回的整数值为 7,server 层会把 7 转换为对应的字符串值成都,然后和 where 条件中的成都进行等值比较,结果为相等。
示例 SQL 2:
select * from t_recbuf
where e1 = 7执行示例 SQL 2,当读取到 e1 字段字符串值为长春的记录时,存储引擎返回的整数值为 13,不需要转换为字符串,直接和 where 条件中的 7 进行等值比较,结果为不相等。
当读取到 e1 字段字符串值为成都的记录时,存储引擎返回的整数值为 7,不需要转换为字符串,直接和 where 条件中的 7 进行等值比较,结果为相等。
3.3 bit 字段
bit 类型的字段,存储引擎以 C/C++ 中的 char 指针指向一块内存区域的形式,把字段内容返回给 server 层,server 层会把 char 指针指向的内存区域的内容转换为 where 条件中的值类型,然后进行比较。
所以,可以用整数、二进制作为 where 条件的值,和 bit 类型字段进行相等比较,或者进行按位与、按位或、按位异或这样的位操作,下面我们来举例说明。
示例 SQL 1:
select * from t_recbuf
where bit1 = 220示例 SQL 1 中,用整数 220 作为 where 条件的值进行查询,server 层会把 char 指针指向的内存区域中内容转换为整数,再和 where 条件中的 220 进行比较。
示例 SQL 2:
select * from t_recbuf
where bit1 = b'11011100'示例 SQL 2 中,我原来想象的是 server 层不会对存储引擎返回的 bit1 字段的内容进行类型转换,而是直接和二进制 b'11011100' 进行相等比较,但实际上,server 层会把存储引擎返回的 bit1 字段的内容转换为浮点数,并且也会把 where 条件中的二进制 b'11011100' 转换为浮点数,然后把两个浮点数进行比较,如果两个浮点数完全相等,或者它们的差值小于 0.5 时,都会被认为相等。
上面说的
差值小于 0.5中的 0.5 不是在代码中写死的,是计算得到的,可能根据字段的不同定义计算出来的值不一样,这个我们就不纠结了,知道有这么回事就行。
示例 SQL 3:
select * from t_recbuf
where bit1 = bit1 | b'100'当我们想要查询 bit1 字段中第 3 位是 1 的记录时,可以像示例 SQL 3 中一样,把 bit1 = bit1 | b'100' 作为 where 条件。
二进制显示时,高位在左边,低位在右边,第 3 位,是从右往左数的。
示例 SQL 3 的执行还是有点出乎意料,server 层会把存储引擎返回的内容转换为整数,然后把 where 条件中的 bit1 | b'100' 也计算出来得到一个整数,然后和 bit1 字段的整数值进行比较。
假设某条记录的 bit1 字段的二进制为 00000111,转换为整数 7,b'100' 转换为整数 4,然后用 7 和 4 进行按位或(7 | 4)得到 7,再和 bit1 字段的整数值 7 进行比较,判断记录是否和 where 条件匹配。
把示例 SQL 3 修改为以下 SQL 时,和示例 SQL 3 得到的结果是一样的,执行过程也基本上相同。
-- 把 b'100' 替换为 4,效果是一样的
select * from t_recbuf
where bit1 = bit1 | 4以上,就是本文的全部内容了,感谢大家花时间阅读,如果觉得有用,还请帮忙转发朋友圈,让更多的人看到,大家一起进步,谢谢 ^_^
预告一下,下一篇要写的内容是 MySQL 简单查询语句执行过程分析(五)发送数据,敬请关注!