降低前端业务复杂度新视角:状态机范式
无论做业务需求还是做平台需求的同学,随着需求的不断迭代,通常都会出现逻辑复杂、状态混乱的现象,维护和新增功能的成本也变的十分巨大,苦不堪言。下图用需求、业务代码、测试代码做对比:
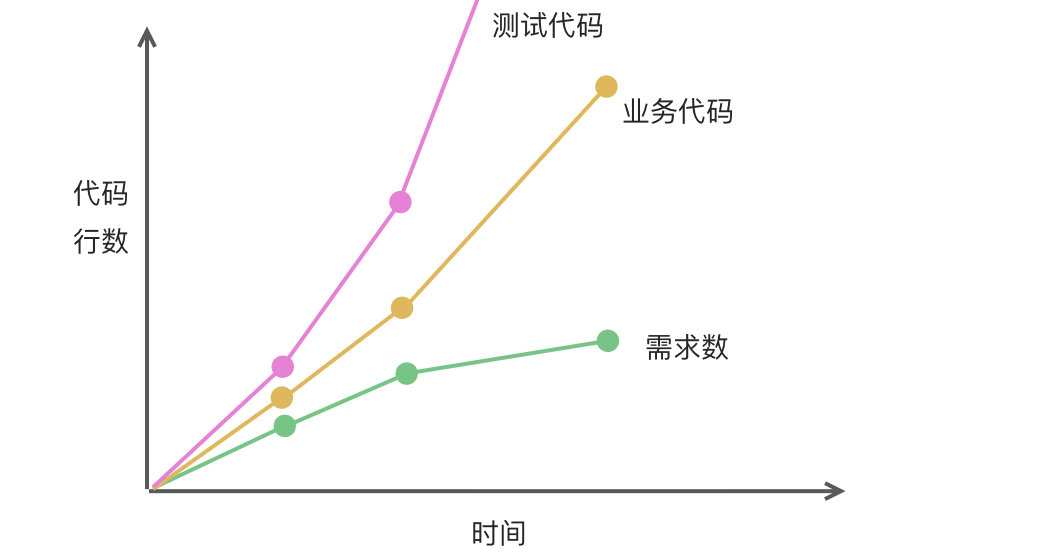
- 阶段 1:正常,都是线性增长。
- 阶段 2:需求数正常增长,业务代码行数开始增长,测试代码行数大幅度增长。
- 阶段 3:业务代码行数开始大幅增长,测试代码行数剧增(超出屏幕),而需求数开始下降。
这可以很好的表达出,从业务最开始,到长期迭代后,复杂度提升带来的问题。做一个相同的需求,最开始可能 1 天就可以搞定,但长期迭代后,可能要 3 天,甚至更多,这并不是开发人员主观上导致的,而是代码状态的维护成本太高,做到最后经常会出现牵一发而动全身。也侧面抑制了业务的迭代速度。
所以对于长期迭代的产品,切记不要简单做,否则都是给后面挖的坑。
当然,看问题还是要去看本质。根据复杂度守恒定律(泰斯勒定律),每个应用程序都具有其内在的、无法简化的复杂度。这一固有的复杂度都无法依照我们的意愿去除,只能设法调整、平衡。而现在前端的复杂度拆分主要包括:框架、通用组件、业务组件和业务逻辑,如下图所示:

我们就要去思考,到底哪里还能把复杂度给降下来。换个角度,是不是可以从业务共有的 “业务逻辑” 侧去进行突破?目前发现的,做业务侧提效的方案中,很少有从 “业务逻辑” 视角为出发点去做的,更多的是聚焦在场景化上的提效。
把视角聚焦到 “业务逻辑” 侧,这里就要看所有业务中都会面临的问题,是什么让业务复杂度提升上去了。这里主要存在两点,如下:
-
代码层面
-
各种各样的业务状态导致的
flag变量的剧增:即便是自己,写多了这种变量,也很难清楚的知道每个flag是干什么用的。 -
各种判断业务状态的
if/else:if/else嵌套地狱估计在很多大型的业务产品中都能看到吧。还有内部的各种逻辑判断,如isA && isB || !(isC || !isD && isE),完全看不懂,即便问 PD,时间久了她也不知道了。还有因此可能导致一些意识不到的 Bug。 -
协作层面
-
做业务的同学很难有全局业务视角,所以面对 PD 的需求很难有话语权。如果需求设计不合理,只能等到你做完了,在 UAT 的阶段才能发现,然后 PD 会给你提一个新需求,让你再去修正(虽然是 PD 的问题,但缺乏避免 PD 犯错的途径)。
-
测试同学,测试的内容范围,多数情况下,取决于前端同学给定的测试范围。而很多时候代码的改动,前端也不确定到底哪些页面会受影响。所以要么导致测试同学测试不完整,要么导致测试同学需要全量回归,这可是非常巨大的测试成本。
-
当其他前端开发人员,参与到项目中时,面临这种复杂的项目也是头大,需要花费很大的成本梳理清楚业务与代码的关联。导致合作或者交接项目时,困难。
我们需要通过发现的这些问题,来寻找合适的解决方案。
1 . 解决代码层面的问题
代码层面的问题,主要来源于 flag 变量过多,及 if/else 的嵌套及大量分支,导致难以修改和扩展,任何改动和变化都是致命的。其实这类问题,在设计模式中是有合适的方案——状态模式。
1.1. 状态模式
状态模式主要解决的是,当控制一个对象状态转换的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示不同状态的一系列类当中,减少相互间的依赖,可以把复杂的判断逻辑简化。
「状态模式是一种行为模式,在不同的状态下有不同的行为,它将状态和行为解耦。」
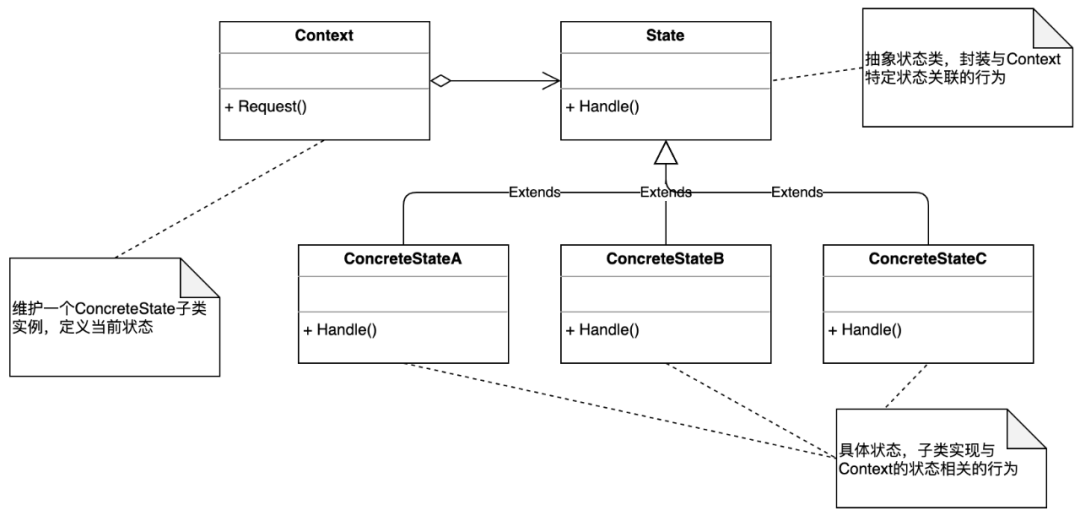
从类图中可以看到,状态模式是多态特性和面向接口的完美体现,State 是一个接口,表示状态的抽象,ConcreteStateA 和 ConcreteStateB 是具体的状态实现类,表示两种状态的行为,Context 的 request() 方法将会根据状态的变更从而调用不同 State 接口实现类的具体行为方法。
状态模式的好处是,「将与特定状态相关的行为局部化,并且将不同状态的行为分割开来」。这样这些对象就可以不依赖于其他对象而独立变化了,未来增加或修改状态流程,就不是困难的事了。
当一个对象的行为取决于它的状态,并且它必须在运行时刻根据状态改变它的行为时,就可以考虑使用状态模式了。
1.2. 状态机
状态机,全称有限状态机(finite-state machine,缩写:FSM),又称有限状态自动机(finite-state automaton,缩写:FSA),是现实事物运行规则抽象而成的一个数学模型,并不是指一台实际机器。状态机是图灵机的一个子集。它是一种认知论。从某种角度来说,我们的现实世界就是一个有限状态机。
有限状态自动机在很多不同领域中是重要的,包括电子工程、语言学、计算机科学、哲学、生物学、数学和逻辑学。有限状态机是在自动机理论和计算理论中研究的一类自动机。在计算机科学中,有限状态机被广泛用于建模应用行为、硬件电路系统设计、软件工程,编译器、网络协议、和计算与语言的研究。它是非常成熟的一套方法论。
有限状态机包含五个重要部分:
- 初始状态值 (initial state)
- 有限的一组状态 (states)
- 有限的一组事件 (events)
- 由事件驱动的一组状态转移关系 (transitions)
- 有限的一组最终状态 (final states)
更简洁的总结,就三个部分:
- 状态 State
- 事件 Event
- 转换 Transition
同一时刻,只可能存在一个状态。例如,人有 “睡着” 和 “醒着” 两个状态,同一时刻,要么 “睡着” 要么 “醒着”,不可能存在 “半睡半醒” 的状态。
逻辑学中说,现实生活中描述的事物都可以抽象为命题。命题本质上就是状态机的 State,Event 就是命题的条件,通过命题和条件推导过程。而 Transition 就是命题推导完成的结论。
所以当我们拿到需求的时候,首先要分离出哪些是已知的命题(State),哪些是条件(Event),哪些是结论(Transition)。而我们要通过这些已知命题和条件,推导出结论的过程。
1.2.1. 拿我们经常用到的 Fetch API 来举例子
fetch(url).then().catch()
有限的一组状态:


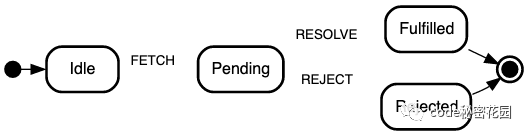
Idle状态只处理FETCH事件Pending状态只处理RESOLVE和REJECT事件
由事件驱动的一组状态转移关系:
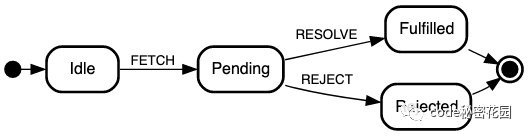
1.3. 状态机 VS 传统编码 示例
下面采用一个小需求来对比一下区别。
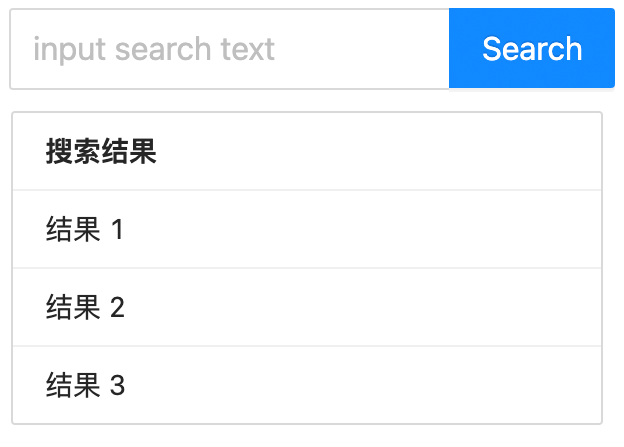
1.3.1. 需求描述
根据输入的关键字进行搜索,并将搜索结果显示出来。如下图所示:
1.3.2. 基于传统编码
根据关键字拿到请求结果,再将结果塞回去就行了,代码如下:
function onSearch(keyword) {
fetch(SEARCH_URL + "?keyword=" + keyword).then((data) => {
this.setState({ data });
});
}看似几行代码就把这个需求搞定了,但其实还有一些其他问题要处理。如果接口响应比较慢,则需要给一个用户预期的交互,如 Loading 效果:
function onSearch(keyword) {
this.setState({
isLoading: true,
});
fetch(SEARCH_URL + "?keyword=" + keyword).then((data) => {
this.setState({ data, isLoading: false });
});
}还会发生出请求出错的情况:
function onSearch(keyword) {
this.setState({
isLoading: true,
});
fetch(SEARCH_URL + "?keyword=" + keyword)
.then((data) => {
this.setState({ data, isLoading: false });
})
.catch((e) => {
this.setState({
isError: true,
});
});
}当然,不能忘记把 Loading 关掉:
function onSearch(keyword) {
this.setState({
isLoading: true,
});
fetch(SEARCH_URL + "?keyword=" + keyword)
.then((data) => {
this.setState({ data, isLoading: false });
})
.catch((e) => {
this.setState({
isError: true,
isLoading: false,
});
});
}我们每次搜索时,还需要把错误清除:
function onSearch(keyword) {
this.setState({
isLoading: true,
isError: false,
});
fetch(SEARCH_URL + "?keyword=" + keyword)
.then((data) => {
this.setState({ data, isLoading: false });
})
.catch((e) => {
this.setState({
isError: true,
isLoading: false,
});
});
}这就结束了么,是不是我们把所有的 Bug 都考虑进去了?并没有。当用户在等待搜素请求的时候,不应该再去搜索,所以搜索结果返回前,禁止再次发送请求:
function onSearch(keyword) {
if (this.state.isLoading) {
return;
}
this.setState({
isLoading: true,
isError: false,
});
fetch(SEARCH_URL + "?keyword=" + keyword)
.then((data) => {
this.setState({ data, isLoading: false });
})
.catch((e) => {
this.setState({
isError: true,
isLoading: false,
});
});
}可以看到,应用的复杂度在不断变大,可能你经历的场景比这个小示例还要复杂的多的多。如果因为搜索接口特别慢,用户希望有一个中断搜索的功能,那么新的需求又来了:
function onSearch(keyword) {
if (this.state.isLoading) {
return;
}
this.fetchAbort = new AbortController();
this.setState({
isLoading: true,
isError: false,
});
fetch(SEARCH_URL + "?keyword=" + keyword, {
signal: this.fetchAbort.signal,
})
.then((data) => {
this.setState({ data, isLoading: false });
})
.catch((e) => {
this.setState({
isError: true,
isLoading: false,
});
});
}
function onCancel() {
this.fetchAbort.abort();
}不能落下对 catch 的特殊处理,因为中断请求会触发 catch:
function onSearch(keyword) {
if (this.state.isLoading) {
return;
}
this.fetchAbort = new AbortController();
this.setState({
isLoading: true,
isError: false,
});
fetch(SEARCH_URL + "?keyword=" + keyword, {
signal: this.fetchAbort.signal,
})
.then((data) => {
this.setState({ data, isLoading: false });
})
.catch((e) => {
if (e.name == "AbortError") {
this.setState({
isLoading: false,
});
} else {
this.setState({
isError: true,
isLoading: false,
});
}
});
}
function onCancel() {
this.fetchAbort.abort();
}最后还要处理没有值的情况:
function onSearch(keyword) {
if (this.state.isLoading) {
return;
}
this.fetchAbort = new AbortController();
this.setState({
isLoading: true,
isError: false,
});
fetch(SEARCH_URL + "?keyword=" + keyword, {
signal: this.fetchAbort.signal,
})
.then((data) => {
this.setState({ data, isLoading: false });
})
.catch((e) => {
if (
e &&
e.name == "AbortError"
) {
this.setState({
isLoading: false,
});
} else {
this.setState({
isError: true,
isLoading: false,
});
}
});
}
function onCancel() {
if (
this.fetchAbort.abort &&
typeof this.fetchAbort.abort == "function"
) {
this.fetchAbort.abort();
}
}仅仅这么简单的一个小需求,从开始几行代码就可以完成,到最终判断各种边界完成的代码,对比一下,如下图所示:
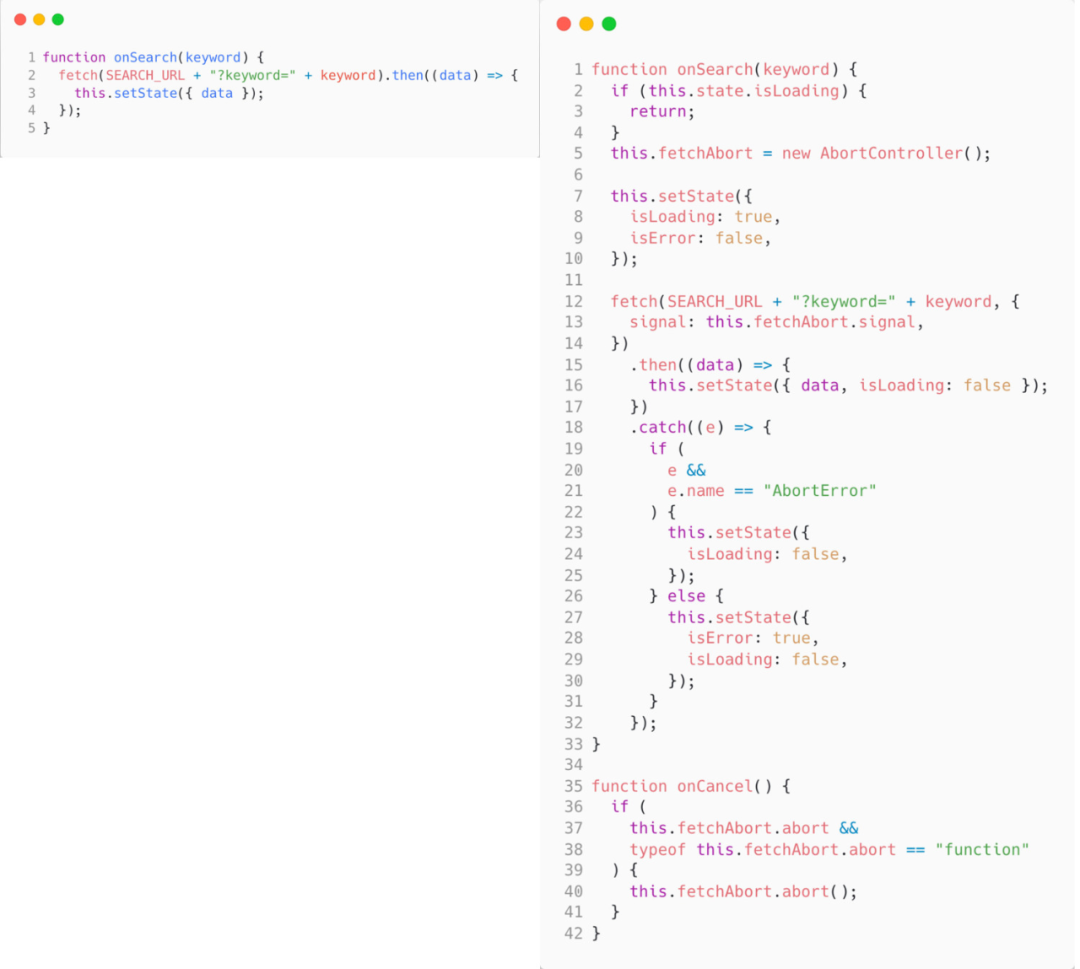
可以看到,这种包含各种 flag 变量和嵌套着各种 if/else 的代码,会越来越难维护,所有的逻辑只存在于你的脑子里。当你写测试的时候必须从头再梳理一遍代码逻辑,才能写出来。
由于业务的高频变化,很多业务开发人员是不写单元测试的,因为成本太高太高,这也导致了交接代码时,别人去理解你的代码是一件很困难的事。写久了,你自己都可能读不懂代码里面的逻辑了。
这样会导致:
- 难以测试
- 难以阅读
- 可能含有隐藏的 Bug
- 难以扩展
- 新功能增加时还会使逻辑进一步混乱
1.3.3. 基于状态机
看一下我们用状态机的做法。记住流程:梳理出有哪些状态,每个状态有哪些事件,经历了这些事件又会转换到什么状态。
下面是用 XState 状态机工具的 JSON 描述:
{
"initial": "空闲",
"states": {
"空闲": {
"on": {
"搜索": "搜索中"
}
},
"搜索中": {
"on": {
"搜索成功": "成功",
"搜索失败": "失败",
"取消": "空闲"
}
},
"成功": {
"on": {
"搜索": "搜索中"
}
},
"失败": {
"on": {
"搜索": "搜索中"
}
}
}
}没错,就这几行代码就描述清楚所有的关系了。并且,可以把它可视化出来,如下图所示:
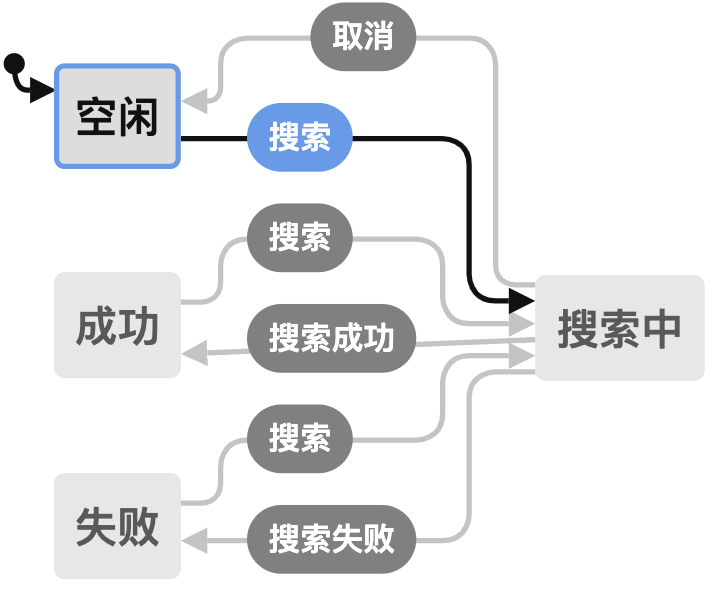
可以看到状态之间表达的非常清晰,结合到 View 中,也不需要再去编写复杂的 flag 及 if/else 了,View 中只需要知道当前是什么状态,已及将事件发送到状态机就可以了,其他什么都不需要做。在新增或者修改需求的情况下,只需要对状态进行新增或者编排就可以了。
而且可视化后,有以下变化:
- 清晰的看到有哪些状态
- 清晰的看到每个状态可以接受哪些事件
- 清晰的看到接受到事件后会转移到什么状态
- 清晰的看到到达某个状态的路径是怎么样的
2 . 解决协作的问题
另一个很大的问题是解决协作问题,主要包括:
- 与测试开人员的协作沟通
- 与 PD 人员的协作沟通
- 与其他前端开发人员的协作沟通
- 与用户的协作沟通
这里就需要引用一个可视化的概念了。「可视化,是利用人眼的感知能力对数据进行交互的可视表达以增强认知的技术」 。
所以很大程度上,可视化可以解决一大部分协作问题。当然,必须要确定把什么进行可视化才是有意义的。
要想可视化,状态工具就需要具备可序列化的能力。这也是 Redux 之类的状态管理工具缺乏的,主要有以下几方面问题:
- 不具备可视化的能力
- 状态和数据混在一起
- 所有的状态都是平级的,无法描述状态之间的关系
2.1. 状态图
回到状态机。你单纯用状态机去写代码,需求数量上去了,状态多了,会面临 “状态爆炸” 问题,依然很难维护,且阅读成本巨大。
当然,这个场景其实很早之前就有人考虑到了,1987 年,Harel 就发表论文,解决复杂状态机可视化的问题,在状态机的基础上进一步增强,提出状态图的概念。随后,由微软、IBM、惠普等多家公司,从 2005 到 2015 年花了 10 年时间制定了规范,并推出了 W3C 的 State Chart XML (SCXML) 规范,至此基本稳定,各家编程语言也基于此规范进行了状态图的封装。
看一下,状态机、状态图和手写代码复杂度的对比,如下图所示:

从图中可以看到:
- 传统编码方式,随着状态和逻辑的增加,复杂度是线性增长的。
- 使用状态机,前期复杂度很底,但随着状态的增多,“状态爆炸”现象的出现,复杂度也急剧增长。
- 使用状态图,虽然前期成本略高,但后期的状态和逻辑的增长,基本不太会影响它的复杂度。
前面给状态机画的图,就是状态图。
状态图大概长这样,如下图所示:
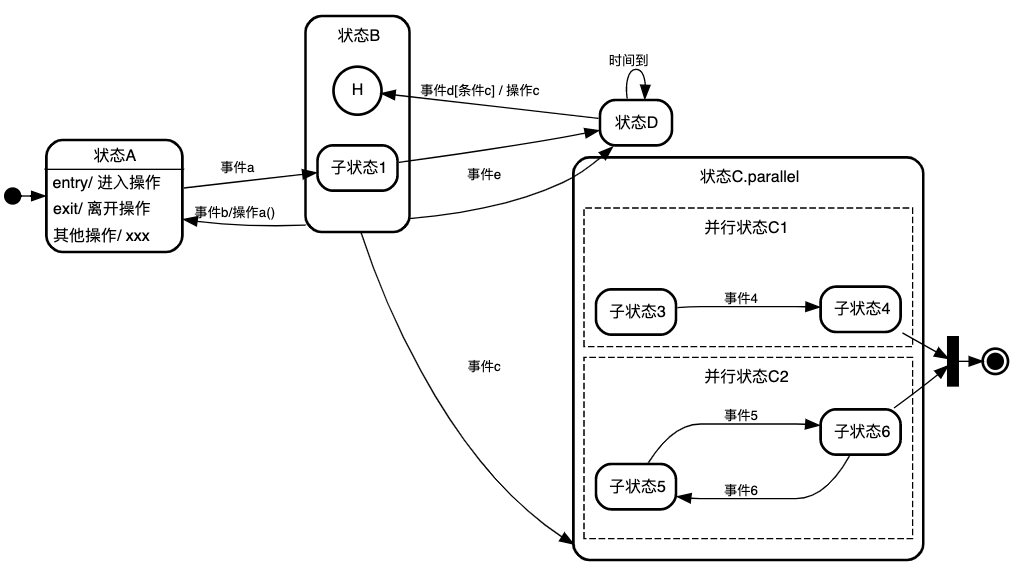
主要包括:
-
状态
-
原子状态
-
复合状态
-
条件状态
-
最终状态
-
历史状态
-
初始状态
-
并行状态
-
伪/瞬间状态
-
转换
-
自动转换
-
延迟转换
-
自身转换
-
内部转换
-
操作
-
自定义操作
-
进入操作
-
退出操作
-
数据操作
-
日志操作
-
事件
-
生成事件
-
延迟时间
-
条件
-
数据
-
调用
即使状态非常复杂,也可以通过状态图的模式进行聚合、分组、细化,还可以通过 Actor 模型进行划分,不会发生 “状态爆炸” 现象。
2.2. 文档化
目前对项目需求的描述主要有:
- 产品需求文档(PRD)
- 设计稿
而这两个,在描述页面行为上都不够细致,PRD 几乎不会去描述过于细节的交互行为,设计稿大概率也不会(因为业务交付周期上不允许在这上面花费太多的时间)。而对于这些不清楚的、模糊的点,就带来了后面的问题,针对于这些细节点,各个角色之间的沟通成本和拉通成本。
还有一个很严重的问题,就是同步问题。很多时候在开发过程中,进行需求变动,而大多数情况下,这些变动不会重新对 PRD 和设计稿进行修改,不同角色之间去对焦及未来回顾,都是问题。
而如果你使用状态机开发,那这两个问题就可以迎刃而解。状态机方式,要求你在开发之前必须把所有可能的状态都罗列出来,状态之间的关联关系必须描述清晰。基于生成的状态图,是可以完全表达清楚所有的状态交互及变化,且它是来源于代码的,所以它是实时同步的,你代码中怎么运行的,这个状态图就是怎么表达的。
2.3. 角色影响
回到前面说的,与不同角色协作的问题上。有了状态图的加持,会发生什么变化:
- 设计师可以根据状态图中的不同状态,来确定哪种状态合适用什么样的 UI。
- 对于 PD,可以查看状态图,以了解系统行为,并验证是否满足要求。
- 对于测试和用户,状态图完全充当说明书用,以前不知道如何才能到达某个状态,现在一目了然。
- 对于测试还有一个很大的区别,因为基于状态机去写的,所以可以使用 Model-Based Testing,而这部分测试,可以由某些状态机工具自动化掉。
- 对于交接的前端开发来说,有说明书在手,每个状态都十分清晰,能做的事也十分清晰,在具备状态机基础的情况下,是可以快速上手的。
2.4. 提升用户体验度:用户操作链路追踪和分析
除了解决复杂度的问题,基于状态机的特性,还可以带来一些新的思路,如用户操作链路追踪和分析。
2.4.1. 常见分析用户操作链路方法
目前,针对于分析用户操作链路的方法,主要是在页面中的可操作标签上进行埋点,如,Button、Tab Item 等。有手动埋点和自动埋点。
- 手动埋点,可以按照你的意愿来收集特定区域的操作数据,但成本偏高,需要一个一个的手动接入,还可能需要自行上报数据。
- 自动埋点,通常是自动在一些常用的标签上埋点,但会存在具体的标签变更的问题,且不能覆盖所有可操作的区域,数据精度不够。
无论使用哪种埋点,都存在 「回放噪音」 的问题。
如,上报信息里包含,“查看详情” 按钮的操作,那么对应的 “详情对话框” 一定会出来么?这个时候链路回放,只能去猜测,认为点击了这个按钮,就意味着这个对话框出来了。其实是不准确的。
如果,页面上新增加了一个功能,要判断这个新功能用户的使用量,及用户做了哪些操作才找到这个新功能。通过这个数据来判断新的交互设计是否存合理。在这种不精准数据及 “噪音” 的回放中也是不准确的。
同样,分析页面中的哪些部分是高频操作,也有类似的问题。
2.4.2. 基于状态机的链路分析方法
状态机做这种用户链路分析,是天然合适的。因为用户的所有操作,所有行为,本质上就是 “状态在接收了什么事件,要变换到什么状态” 上的过程。这是在 View 上埋点的方式缺乏的。
我们只需要在每次 “状态” 发生转换时,把状态图数据上报到分析平台就可以。完全可以基于状态的方式, 1:1 的回放用户操作链路。
3 . 总结
最后,总结一下状态机方式带来的好处和不足。
3.1. 优势
-
比传统的编码方式,更容易理解。
-
基于行为建模,与视图解耦。
-
更容易改变行为:组件中的行为被提取到了状态机中,与 把行为和业务逻辑一起嵌入的组件相比,行为的更改相对容易。
-
更容易的理解代码。
-
更容易测试
-
构建状态图的过程必须探索所有状态,也是让你具备业务全局视角的过程,它迫使你考虑所有可能发生的场景。
-
基于状态图的代码比传统代码具有更少的 Bug 数。相关数据表示,错误减少了 80% 到 90%,剩下的错误也很少出现在状态图本身。
-
有助于处理可能会被忽视的特殊情况。
-
随着复杂性的增加,状态图可以很好地扩展。
-
状态图是一个很好的交流工具。
3.2. 带来的一些问题
-
需要学习新的东西,状态机是一种范式的转化,且容易有抵触心里,不愿意走出舒适圈。
-
新的格式
-
新的重构技术
-
新的调试工具
-
部分人觉得可视化这种东西,没什么用。
-
陌生的编码方式,在团队内可能出现不同的阻力。
-
虽然大多数人听过状态机,但实际的编程中离它遥远,所以并不熟悉它。
-
编程方式的转换,很多人需要弄清楚原来的代码,现在该如何去写,如何映射。
-
部分人会质疑它的有效性。
-
必须有人基于这种模式实践过,对它非常了解才可以。
-
如果从来没用过它,使用这种模式会无从下手,令人生畏。
3.3. 为什么用的人不多
状态机已经发展几十年了,前面也说过,在非常的多场景有使用,像电子、嵌入式、游戏、通讯等领域。那为什么前端上使用较少呢(限定国内)?
除了上面列出的 “带来的一些问题” 中的一些点,我觉的还有以下问题导致的:
- 缺少指导图书:现在搜索一下关于状态图的前端图书或者教程,搜索结果告诉你 0 条。资料很少(嵌入式之类的状态机资料还是挺多的)。
- “用最简单的方式去实现” 的心态:很多人喜欢用
if/else/switch来解决问题。 - “你觉得你不需要” 的心态:复杂度在每一个
flag变量和布尔值中蔓延。就像温水煮青蛙,温水中的青蛙不会注意到温度的缓慢升高一样,开发人员也不会注意到复杂度的蔓延。在一些小的系统中运行的很好,但随着系统的迭代和变大,一个个凌乱的if/else/switch语句,它修改了各种变量的状态,以试图维持它们的一致性。就好像你不需要状态机,直到为时已晚。 - 就像 RxJS、函数式编程之类的一样,大家都知道它很好,但就是不用它。
3.3. 总结
任何解决方案都不能解决一切问题,一定要找到它适合的场景。不过,现阶段,状态机确实是我能看到的,解决复杂业务逻辑最好的工具。
如果文中说的问题也发生在你身边,且无法彻底解决,那推荐你可以尝试一下,或许会有惊喜。