iOS 直播流程概述
iOS 直播流程概述
写在前面
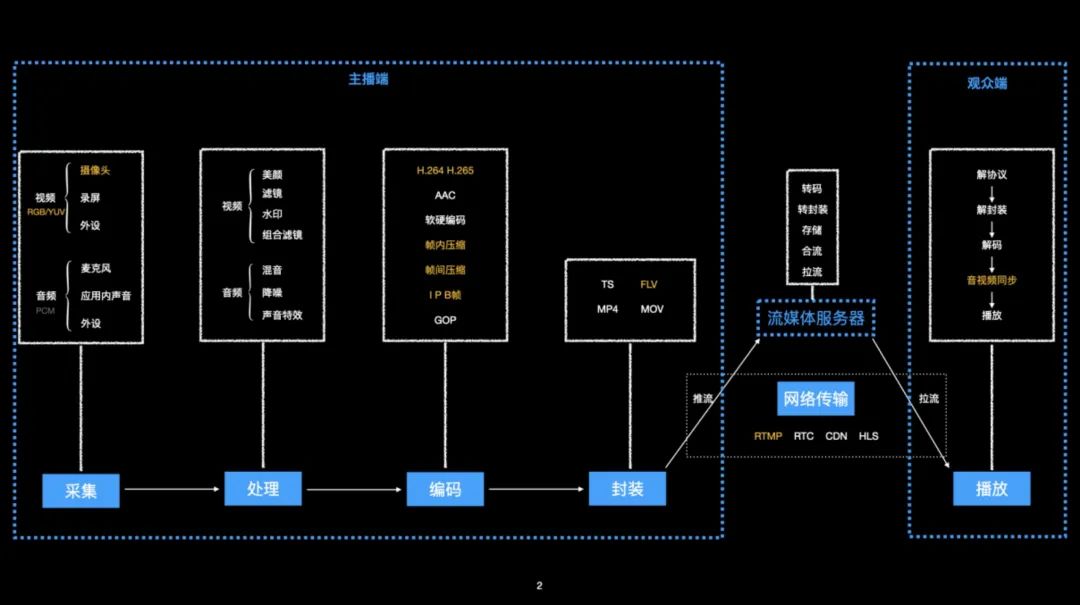
本文目的在于带大家了解一场直播背后,需要经历哪些阶段,以及每个阶段都做了哪些工作,才能够把主播的声音画面送到观众的面前。我们把直播的流程划分为以下六个阶段:
- 采集
- 处理
- 编码
- 封装
- 网络传输
- 播放
下面来一一介绍。
采集
采集又分为视频采集、音频采集。
一般来说,我们会借助系统 api 来实现这一部分的工作。以 iOS 为例,需要用到 AVFoundation 框架来获取手机摄像头拍到的视频数据,或者使用 ReplayKit 录制屏幕,以及麦克风收集到的音频数据。
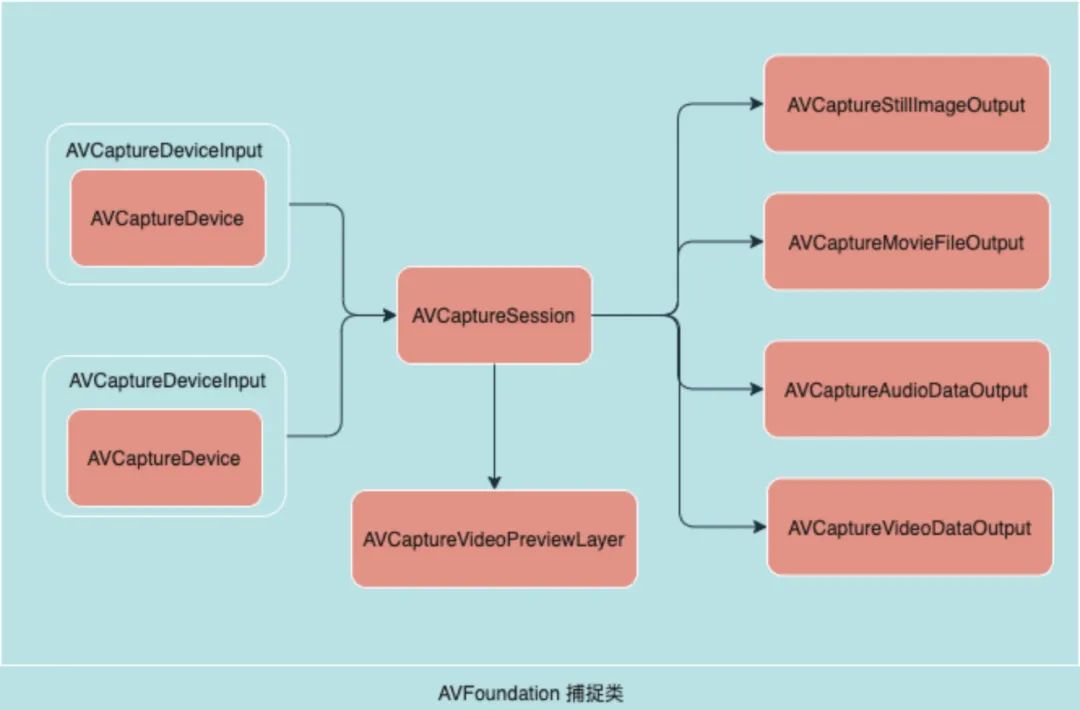
视频采集:摄像头
核心类 AVCaptureXXX
使用摄像头采集视频的几个核心类如下图所示:
// 1. 创建一个 session
var session = AVCaptureSession.init()
// 2. 获取硬件设备:摄像头
guard let device = AVCaptureDevice.default(for: .video) else {
print("获取后置摄像头失败")
return
}
// 3. 创建 input
let input = try AVCaptureDeviceInput.init(device: device)
if session.canAddInput(input) {
session.addInput(input)
}
// 4. 创建 output
let videoOutput = AVCaptureVideoDataOutput.init()
let pixelBufferFormat = kCVPixelBufferPixelFormatTypeKey as String
// 设置 yuv 视频格式
videoOutput.videoSettings = [pixelBufferFormat: kCVPixelFormatType_420YpCbCr8BiPlanarFullRange]
videoOutput.setSampleBufferDelegate(self, queue: outputQueue)
if session.canAddOutput(videoOutput) {
session.addOutput(videoOutput)
}
// 5. 设置预览 layer:AVCaptureVideoPreviewLayer
let previewViewLayer = videoConfig.previewView.layer
previewViewLayer.backgroundColor = UIColor.black.cgColor
let layerFrame = previewViewLayer.bounds
let videoPreviewLayer = AVCaptureVideoPreviewLayer.init(session: session)
videoPreviewLayer.frame = layerFrame
videoConfig.previewView.layer.insertSublayer(videoPreviewLayer, at: 0)
// 6. 在 output 回调里处理视频帧:AVCaptureVideoDataOutputSampleBufferDelegate
func captureOutput(_ output: AVCaptureOutput, didOutput sampleBuffer: CMSampleBuffer, from connection: AVCaptureConnection) {
// todo: sampleBuffer 视频帧
}色彩二次抽样:YUV
一般来说,我们看到的媒体内容,都经过了一定程度的压缩。包括直接从 iPhone 摄像头采集的图像数据,也会经过色彩二次抽样这一压缩过程。
在上一步中创建 output 的时候,我们设置了视频的输出格式是kCVPixelFormatType_420YpCbCr8BiPlanarFullRange 的。在这句代码中,我们需要注意到两个地方:420和YpCbCr。
YpCbCr:代表YUV(Y-Prime-C-B-C-R) 格式。- Y 指的是亮度信息
- UV 是色彩信息。
人眼对亮点信息更敏感,单靠 Y 数据,可以完美呈现黑白图像;也就是说可以压缩 UV 信息,而人眼难以发现。
❝下右图:单靠黑白亮度信息,已经足以描述整个照片的纹理。加上 uv 色彩信息后,就成了下左图的彩色图片的效果。

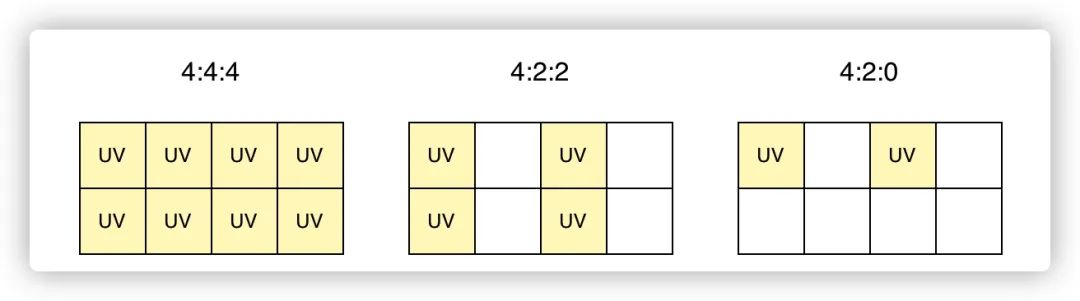
420:代表的是设备取样时色彩二次抽样的参数
4:2:0 中,第一个数,代表几个关联的色块(一般是4);第二个数,代表第一行中包含色彩 uv 信息的像素个数;第三个数,代表第二行中包含色彩 uv 信息的像素个数。(每个像素里都包含亮度信息 Y)
❝取样的时候,一些专业的相机会以 4:4:4 的参数捕捉图像,面向消费者的 iPhone 相机,通常用 4:2:0 的参数,也能拍出来高质量的视频或图片。!
视频采集:录屏
录屏又分为两种:
- 应用内采集:只能采集当前 app 的屏幕内容
- 应用外采集:可以采集这个手机屏幕的内容,包括退后台之后,整个手机界面的录制。一般用来做游戏直播、会议 app 分享屏幕功能。
1. 应用内采集
// iOS 录屏使用的框架是 ReplayKit
import ReplayKit
// 开始录屏
RPScreenRecorder.shared().startCapture { sampleBuffer, bufferType, err in
} completionHandler: { err in
}
// 结束录屏
RPScreenRecorder.shared().stopCapture { err in
}针对应用内录屏,有以下两个 Tip:
- 不想要被录制进去的 UI ,可以放到自定义 UIWindow 上
- 录屏同时开启前置摄像头,可以获取
RPScreenRecorder.shared().cameraPreviewView,并将其添加到当前视图上。
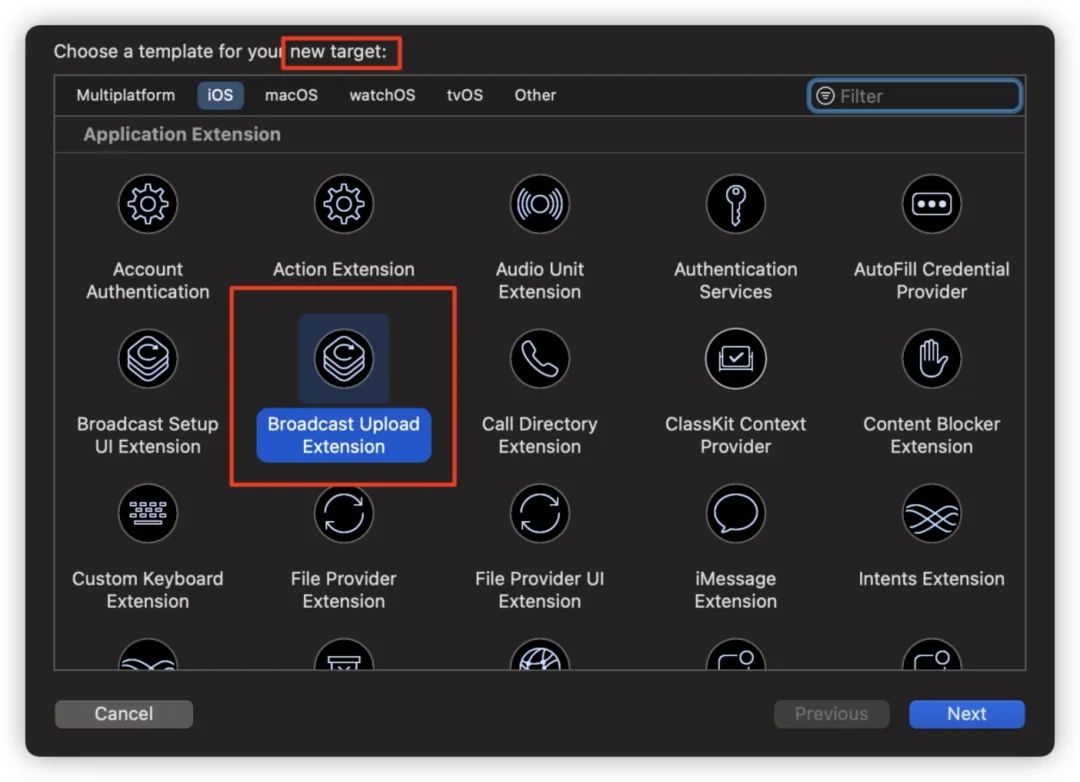
2. 应用外采集
应用外采集需要创建一个 broadcast upload extension,创建完成后会生成一个 SampleHander 类,在这个类里面可以获取到采集的视频数据。
class SampleHandler: RPBroadcastSampleHandler {
func sohuSportUserDefaults() -> UserDefaults? {
return UserDefaults.init(suiteName: "com.xxx.xx")
}
override func broadcastStarted(withSetupInfo setupInfo: [String : NSObject]?) {
// 开始录屏,setupInfo 是从 UI extension 传递过来的参数
}
override func broadcastPaused() {
// 暂停录屏
}
override func broadcastResumed() {
// 继续录屏
}
override func broadcastFinished() {
// 录屏结束
}
// 录屏回调
override func processSampleBuffer(_ sampleBuffer: CMSampleBuffer, with sampleBufferType: RPSampleBufferType) {
// sampleBuffer
switch sampleBufferType {
case .video:
// 视频
case .audioApp:
// 应用内声音
case .audioMic:
// 麦克风声音
}
}
}extension 进程和主 app 进程间通信,可以通过以下几种方式:
- App Group:User Default
- 使用
socket往 host app 传输数据 CFNotification
音频采集:Audio Unit
iOS 直播中的音频采集,我们一般会用到 Audio Unit 这一底层框架,这一框架允许我们在采集的时候对录制的音频进行一些参数设置,以便获取到最高质量与最低延迟的音频。核心代码如下:
// 创建 audio unit
self.component = AudioComponentFindNext(NULL, &acd);
OSStatus status = AudioComponentInstanceNew(self.component, &_audio_unit);
if (status != noErr) {
[self handleAudiounitCreateFail];
}
// asbd
AudioStreamBasicDescription desc = {0};
desc.mSampleRate = 44100; // 采样率
desc.mFormatID = kAudioFormatLinearPCM; // 格式
desc.mFormatFlags = kAudioFormatFlagIsSignedInteger | kAudioFormatFlagsNativeEndian | kAudioFormatFlagIsPacked;
desc.mChannelsPerFrame = 1; // 声道数量
desc.mFramesPerPacket = 1; // 每个包中有多少帧, 对于PCM数据而言,因为其未压缩,所以每个包中仅有1帧数据
desc.mBitsPerChannel = 16;
desc.mBytesPerFrame = desc.mBitsPerChannel / 8 * desc.mChannelsPerFrame;
desc.mBytesPerPacket = desc.mBytesPerFrame * desc.mFramesPerPacket;
// 回调函数
AURenderCallbackStruct callback;
callback.inputProcRefCon = (__bridge void *)(self);
callback.inputProc = handleVideoInputBuffer;
// 设置属性
AudioUnitSetProperty(self.audio_unit, kAudioUnitProperty_StreamFormat, kAudioUnitScope_Output, 1, &desc, sizeof((desc)));
AudioUnitSetProperty(self.audio_unit, kAudioOutputUnitProperty_SetInputCallback, kAudioUnitScope_Global, 1, &callback, sizeof((callback)));
UInt32 flagOne = 1;
AudioUnitSetProperty(self.audio_unit, kAudioOutputUnitProperty_EnableIO, kAudioUnitScope_Input, 1, &flagOne, sizeof(flagOne));
// 配置 AVAudioSession
AVAudioSession *session = [AVAudioSession sharedInstance];
[session setCategory:AVAudioSessionCategoryPlayAndRecord withOptions:AVAudioSessionCategoryOptionDefaultToSpeaker | AVAudioSessionCategoryOptionInterruptSpokenAudioAndMixWithOthers error:nil];
[session setActive:YES withOptions:kAudioSessionSetActiveFlag_NotifyOthersOnDeactivation error:nil];
[session setActive:YES error:nil];
#pragma mark - 音频回调函数
static OSStatus handleVideoInputBuffer(void *inRefCon,
AudioUnitRenderActionFlags *ioActionFlags,
const AudioTimeStamp *inTimeStamp,
UInt32 inBusNumber,
UInt32 inNumberFrames,
AudioBufferList *ioData) {
//
}处理
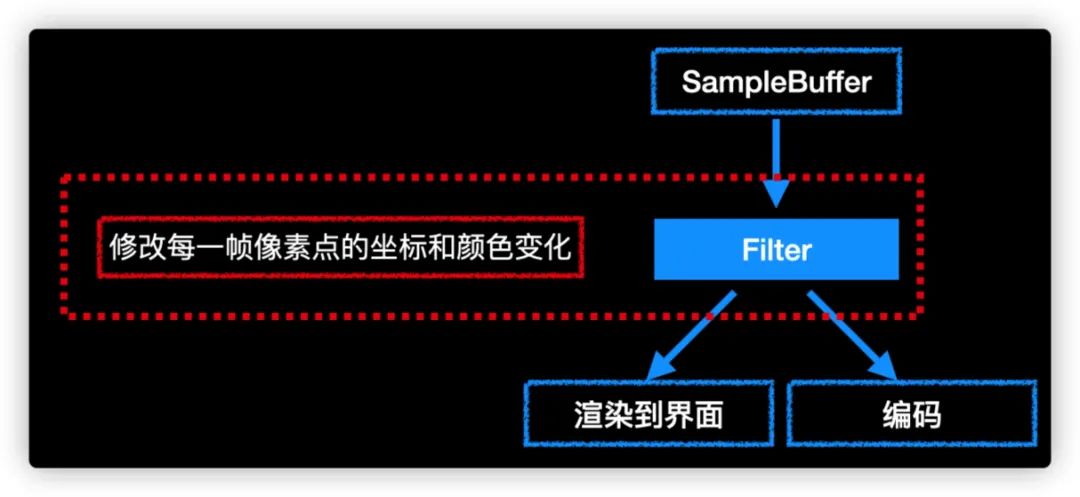
对视频来说,这一阶段的主要工作是拿到 SampleBuffer,做一下美白、磨皮、滤镜等效果。本质上来说,这些操作都是在修改每一帧像素点的坐标和颜色变化,流程如下:
❝这一阶段,常用到的一个三方库是 GPUImage,这个库提供了常见的 100+ 滤镜的算法。它有三个版本:
- GPUImage 1:OC + OpenGL
- GPUImage 2:Swift + OpenGL
- GPUImage 3:Swift + Metal
编码
在拿到采集处理后的音视频原数据之后,还要经过编码压缩才能往外传输数据。
压缩分为两种,有损和无损,区别如下:
- 有损压缩:解压缩后的数据和压缩前的不一致,压缩过程中会丢失一些人眼人耳不敏感的图像或音频信息,丢失的信息不可恢复。
- 无损压缩:压缩前和压缩后的数据一致,优化数据的排列等。
视频的编码,是为了压缩它的大小,以便于能够更快的在网络上传输。很明显,这是一个有损压缩过程。在这个过程中,会丢弃掉一些冗余信息,常见的冗余信息如下:
- 空间冗余:图像相邻像素之间有较强的相关性
- 时间冗余:视频序列的相邻图像之间内容相似
- 视觉冗余:人的视觉系统对某些细节不敏感
- 知识冗余:规律性的结构可由先验知识和背景知识得到
- 结构冗余:某些图片中固定存在的分布模式
总结来说:编码就是一个丢弃冗余信息的压缩过程。
视频编码过程
具体的编码过程如下:
- 找到冗余信息:每一帧原始采样分块
- 把图片分组:有差别的像素只有 10% 以内的点,亮度差值变化不超过 2%,而色度差值的变化只有 1% 以内一组称为 GOP (包括一个 I 帧,多个 P/B 帧)
- 逐帧进行编码
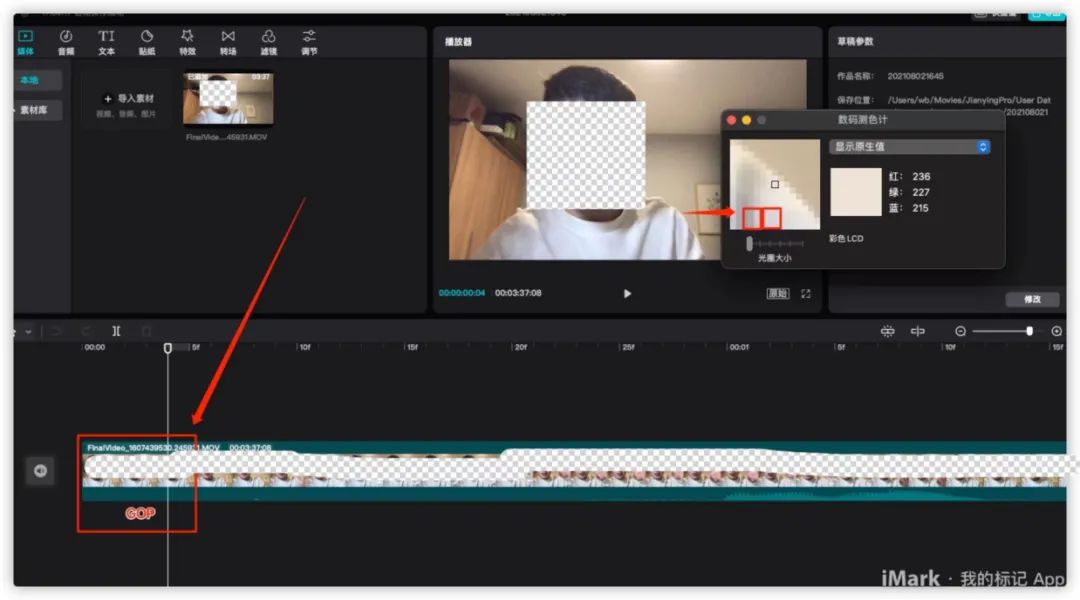
先看左下角红框里,我框了5帧图片出来,这几帧图片,内容差别很小,我们可以把他们分成一个组。来处理我们上面说过的时间冗余信息。每一组图片叫做 GOP 。
再看右边这个小箭头,我把箭头尾部,肩膀这部分放大了,可以看到一个个像素,每个小红框里假如说是有16*16个像素,就是一个分块。在这个分块,我们处理上面说过的空间冗余。
分组,分块之后。一帧帧的去处理图片。这就是编码的大概流程。
I P B 帧
帧的编码方式:
- 帧内压缩:压缩一帧图像时,仅考虑本帧的数据而不考虑相邻帧之间的冗余信息。
- 帧间压缩:相邻几帧的数据有很大相关性,连续的视频相邻帧之间有冗余信息,又称作时间压缩。
在对视频帧编码后,原始视频数据会被压缩成三种不同类型的视频帧:I帧、P帧、B帧
- 如下图所示,第一张图片是 I 帧,第二个是 P 帧。P 帧相对于 I 帧,三个豆豆往左移动了一点,那么在编码 P 帧的时候,可以只记录这个偏移量,其他的信息就参考 I 帧来就行。
- 第三个 B 帧,他的豆豆数量和第四个 I 帧一样。那我可以直接记录前三个豆豆相对于P帧的位移,以及最后一个豆豆相对于后面I帧的位移,就可以编解码这一帧数据了。
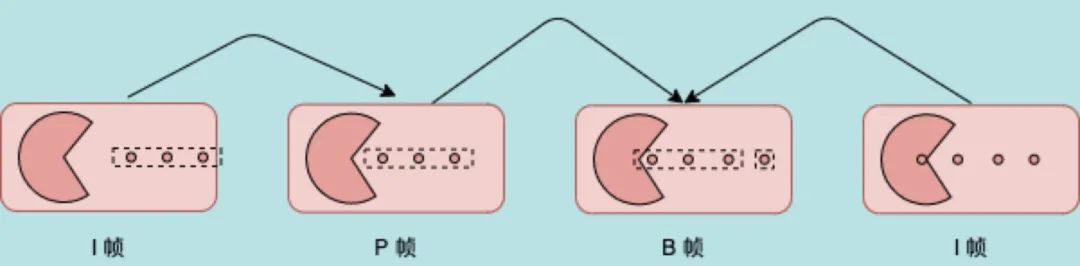
- I 帧:关键帧,完整编码的帧。可以理解成一张完整画面,不依赖其他帧。
- P帧:预测帧,参考前面的 I 帧或 P 帧进行编解码。
- B帧:双向帧,参考前面的 I 帧或 P 帧,和后面的 P 帧进行编解码。
H.264、H.265
H.264 的压缩方式,是在两方面对视频帧进行了压缩:
- 空间:压缩独立视频帧(帧内压缩)
- 时间:通过以组(GOP)为单位的视频帧压缩冗余数据(帧间压缩)
H.265 是基于 H.264 基础上,做了些改进,本质上是一样的。
核心方法如下:
// 创建编码器
OSStatus status = VTCompressionSessionCreate(NULL, _configuration.videoSize.width, _configuration.videoSize.height, kCMVideoCodecType_H264, NULL, NULL, NULL, VideoCompressonOutputCallback, (__bridge void *)self, &compressionSession);
// 配置编码器属性
VTSessionSetProperty(compressionSession, kVTCompressionPropertyKey_MaxKeyFrameInterval, (__bridge CFTypeRef)@(_videoMaxKeyframeInterval));
//...
// 编码前资源配置
VTCompressionSessionPrepareToEncodeFrames(compressionSession);
// 编码
OSStatus status = VTCompressionSessionEncodeFrame(compressionSession, pixelBuffer, presentationTimeStamp, duration, (__bridge CFDictionaryRef)properties, (__bridge_retained void *)timeNumber, &flags);音频编码
数字音频压缩编码是在保证信号在听觉方面不产生失真的前提下,对音频数据信号进行尽可能的压缩。 去除声音中冗余成分(不能被人耳察觉的信号,他们对声音的音色、音调等信息没有任何帮助)。
音频冗余信息如下:
- 人耳能听到的频率范围是 20Hz ~ 20kHz,超过这个范围的声音都可以丢弃。
- 当一个强音信号和弱音信号同时存在时,弱音信号将被强音信号所掩蔽而听不见,这样弱音信号就可以视为冗余信息不用传送
音频编码核心方法如下:
#import <AudioToolbox/AudioToolbox.h>
// 创建编码器
OSStatus result = AudioConverterNewSpecific(&inputFormat, &outputFormat, 2, requestedCodecs, &m_converter);;
// 编码
AudioConverterFillComplexBuffer(m_converter, inputDataProc, &buffers, &outputDataPacketSize, &outBufferList, NULL)封装
封装就是把编码后的音视频数据,打包放到一个容器格式里。例如 mp4、flv、mov 等
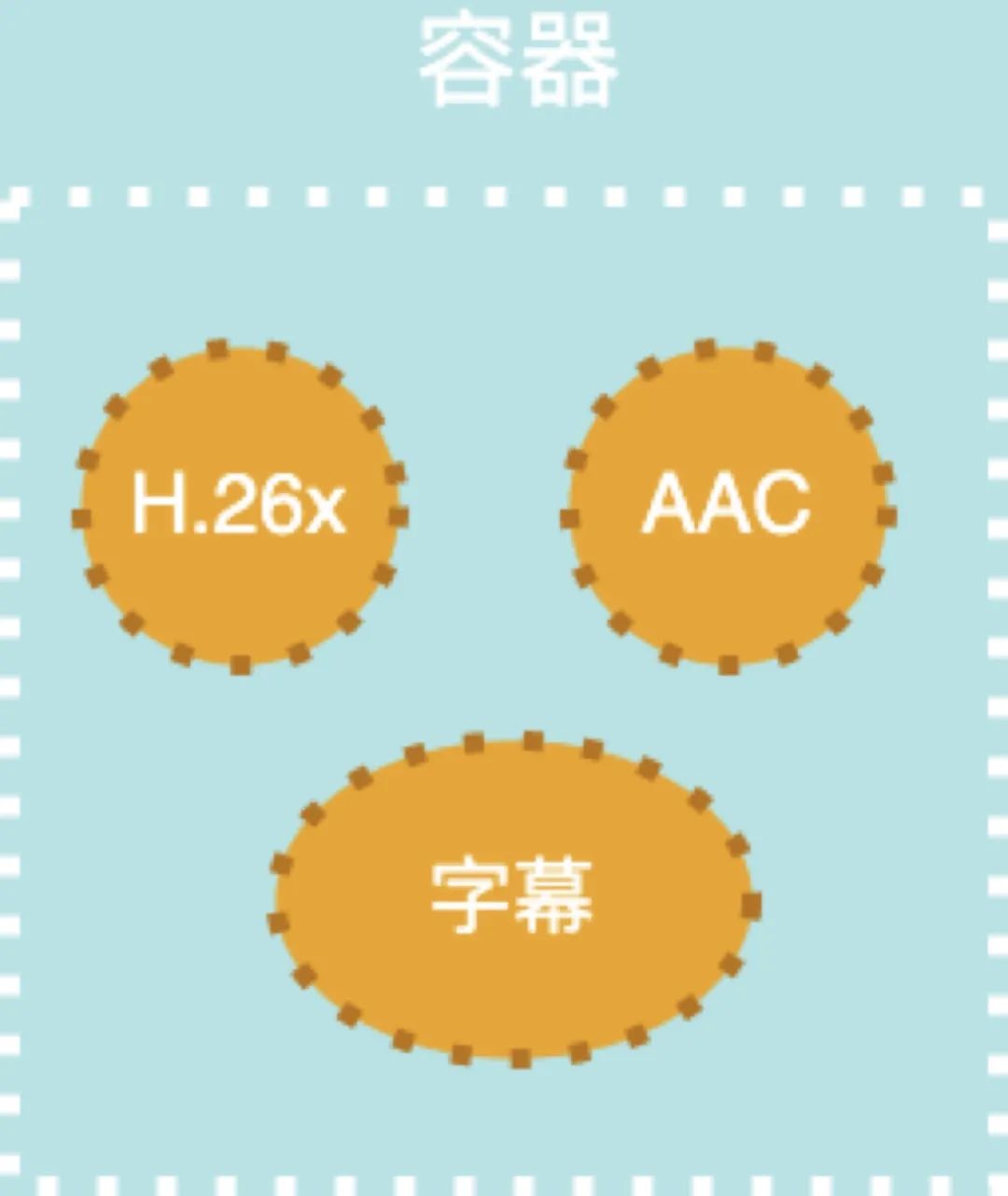
直播中比较常用的两种封装格式是 flv 和 ts,他们的区别在于编码器类型不一样。
FLV
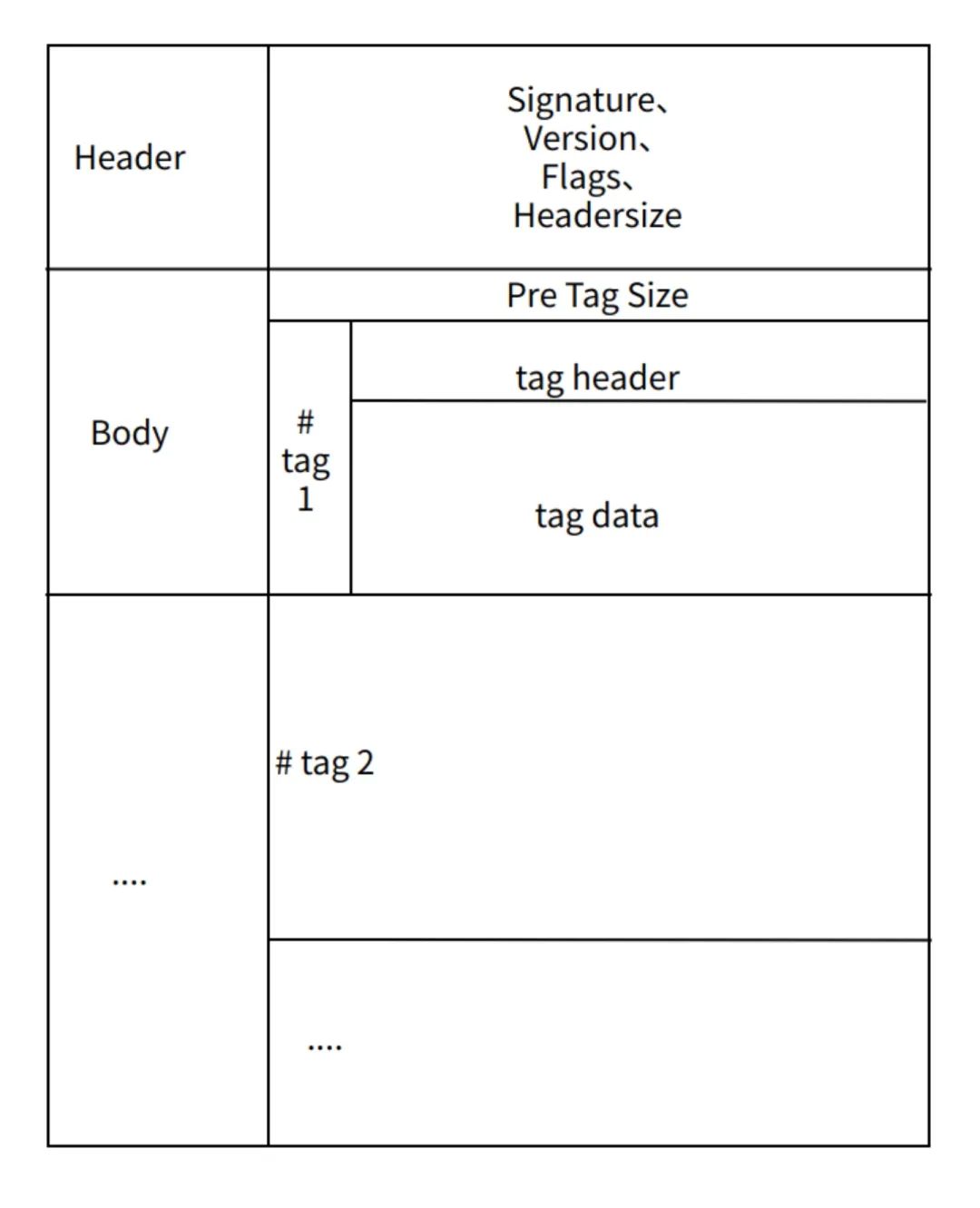
flv 支持 h.264 & AAC 编码器,我们这里就以他为例,看一下flv的文件结构是怎样的:
首先是有一个 flv header,里面包含 flv 的文件表示,以及flv版本信息等等。然后是flv body。body又分为一个个 tag,在 tag 里面才是具体的音频数据,或者视频数据信息。
网络传输
在编码、封装完之后,就可以进行传输数据了。这一阶段,通常使用 RTMP 协议传输数据。这是一个应用层协议,基于 TCP。
RTMP 协议
❝RTMP 协议:https://www.adobe.com/devnet/rtmp.html
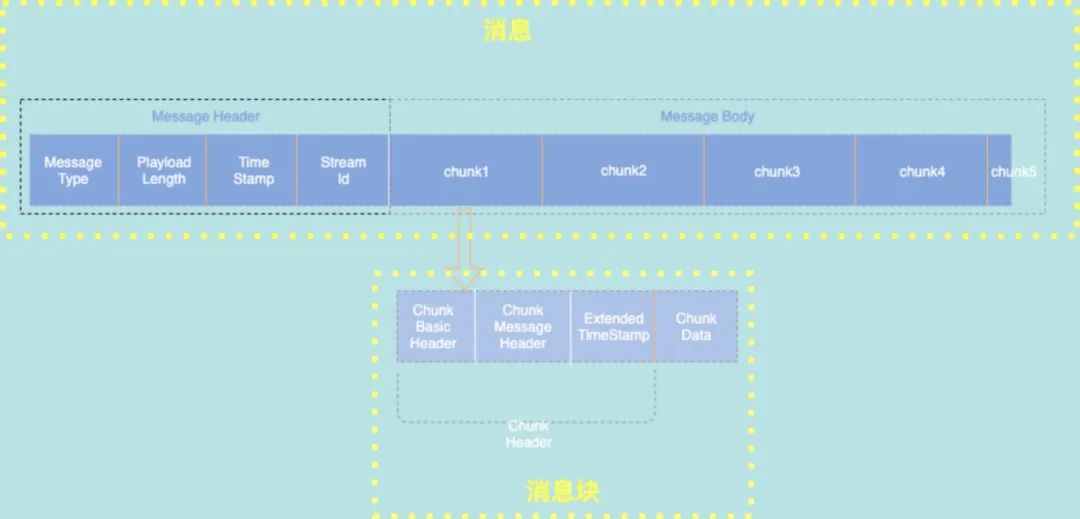
在传输过程中,rtmp 的报文格式叫做 message 消息。如下图,这是一个消息的图示。可以看到,消息又分为 message header 和 message body。
在消息首部,有表示消息类型的 type,有消息的长度信息,有时间戳等信息。
需要关注的是 type 这个字段,rtmp里有十多个消息类型,通过type区分,1到7 是用于协议控制的,8代表这是一个音频消息,9代表这是一个视频消息。15到20 负责客户端服务端之间的交互,比如播放暂停等操作。
右边是 message body,里面包含具体的数据信息。
在传递的过程中,会把消息体再拆分成更小的消息快 chunk。每一个chunk都是128 字节,只有最后一个chunk长度可以小于128。这个过程叫做消息分块。
- rtmp 传输媒体数据过程中,发送端首先把媒体数据封装成消息,然后把消息分割成消息块。最后将分割后的消息快通过 tcp 协议发送出去。
- 接收端在通过 tcp 协议收到数据后,首先把消息块重新组合成消息,然后通过对消息进行解封装处理就可以恢复出媒体数据。
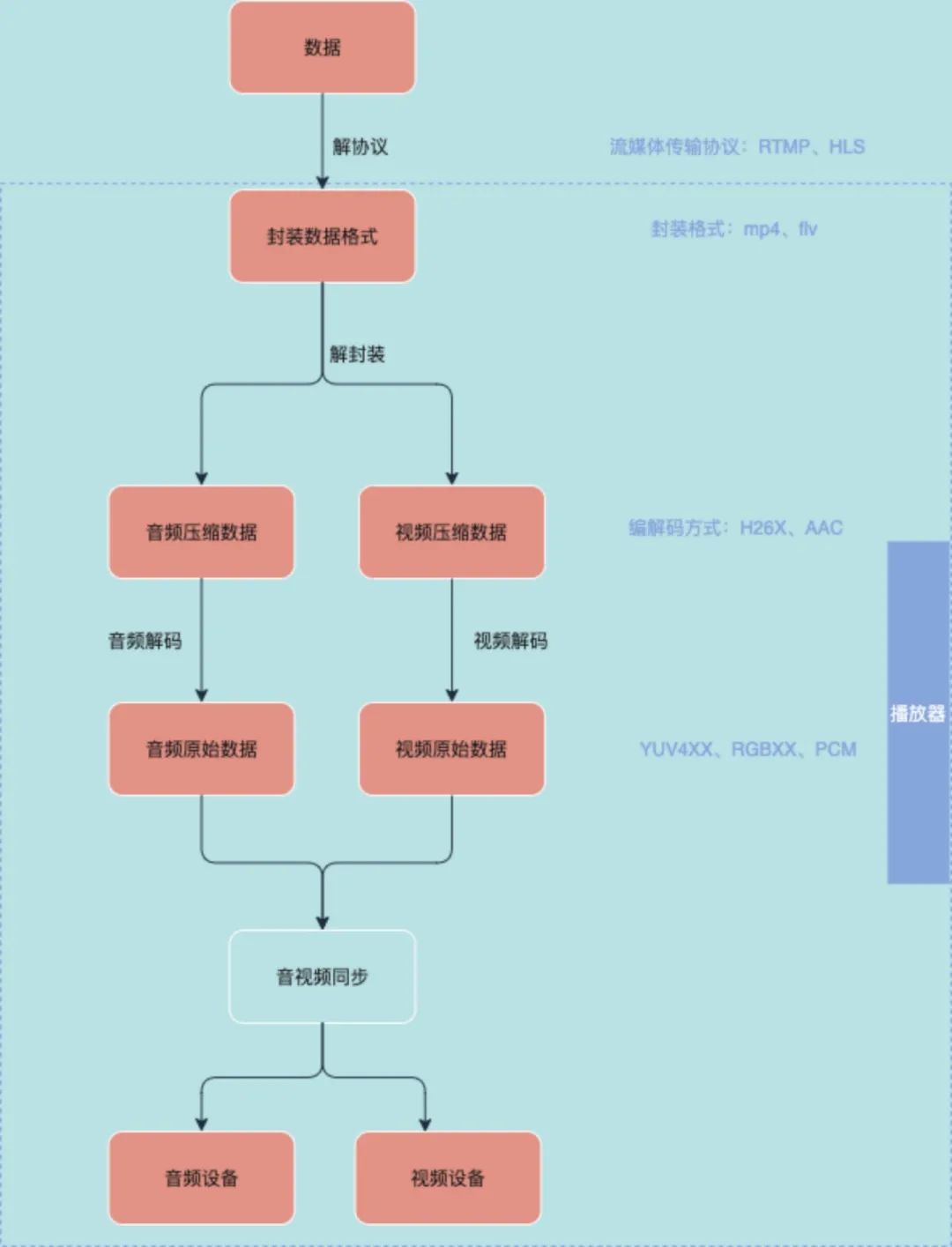
播放
最后一步是观众端拉流播放:
- 拉流完先解协议,比方说是用rtmp协议,那我就知道了,传递过来的是一个个的消息块 chunk,那我就把拉取到的 chunk 合成消息,就获取到封装好的视频数据了。
- 下一步就是解封装,判断这是个 flv 流,还是其他流。解封装后,就能拿到编码过的音视频数据。
- 再接着分别对音视频进行解码操作,拿到音频原始数据,和视频原始数据。
- 接着做一个音视频同步的操作,然后把视频渲染到屏幕上,同时使用麦克风播放音频 流程图如下: