众所周知在浏览器的渲染进程里,V8作为JS的解析引擎存在,但是V8里是如何运行的,它又遇到哪些挑战,本文做简单介绍。视频和PPT内容可以看最后
脚本解析
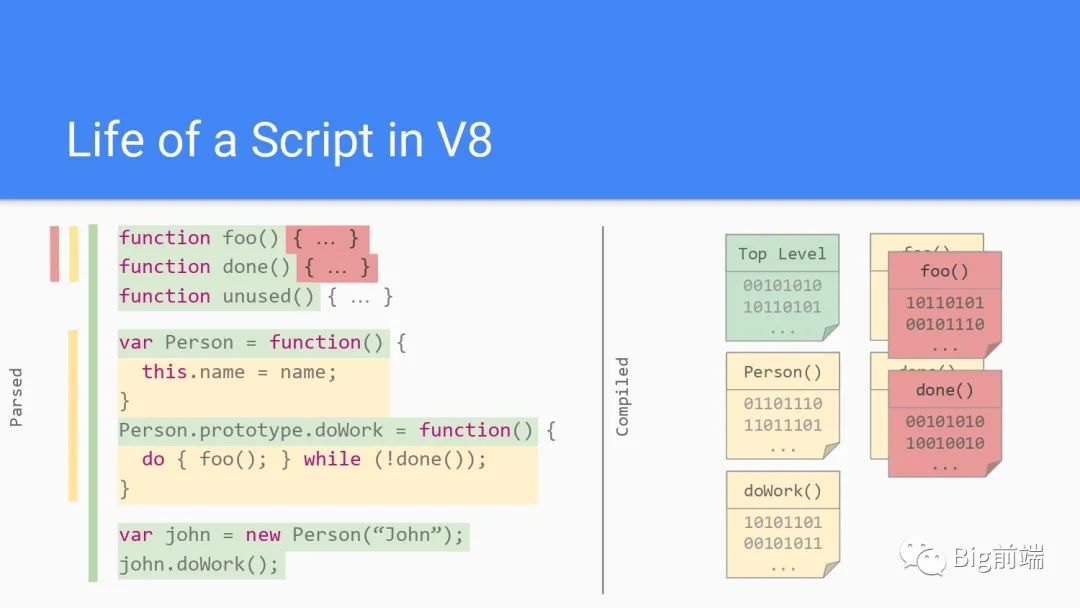
 在浏览器的网络进程获取到脚本内容后进入解析流程,依次解析如上图有各个函数,并会为函数的执行创建执行上下文,创建顺序依次为Top Level, Person, doWork, foo, done,与执行顺序一样,一次创建执行上下文后被压栈到调用栈里。在函数完毕通过指针上下移动,最后GC垃圾回收完成上下文销毁。
在浏览器的网络进程获取到脚本内容后进入解析流程,依次解析如上图有各个函数,并会为函数的执行创建执行上下文,创建顺序依次为Top Level, Person, doWork, foo, done,与执行顺序一样,一次创建执行上下文后被压栈到调用栈里。在函数完毕通过指针上下移动,最后GC垃圾回收完成上下文销毁。
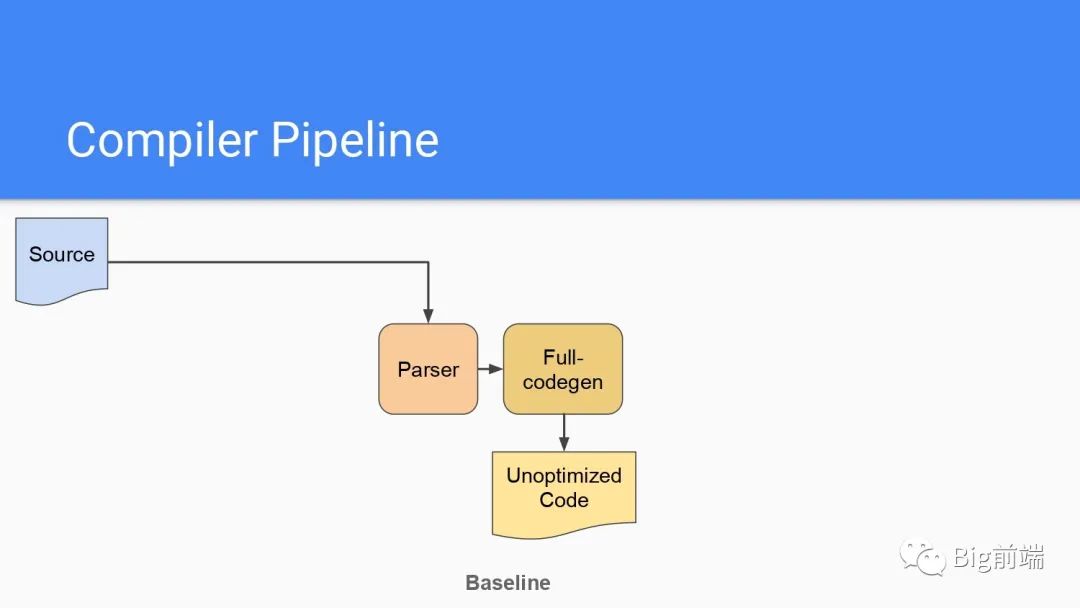
 整体流程如下,脚本被解析后全量编译生成没有优化的Bytecode字节码
整体流程如下,脚本被解析后全量编译生成没有优化的Bytecode字节码
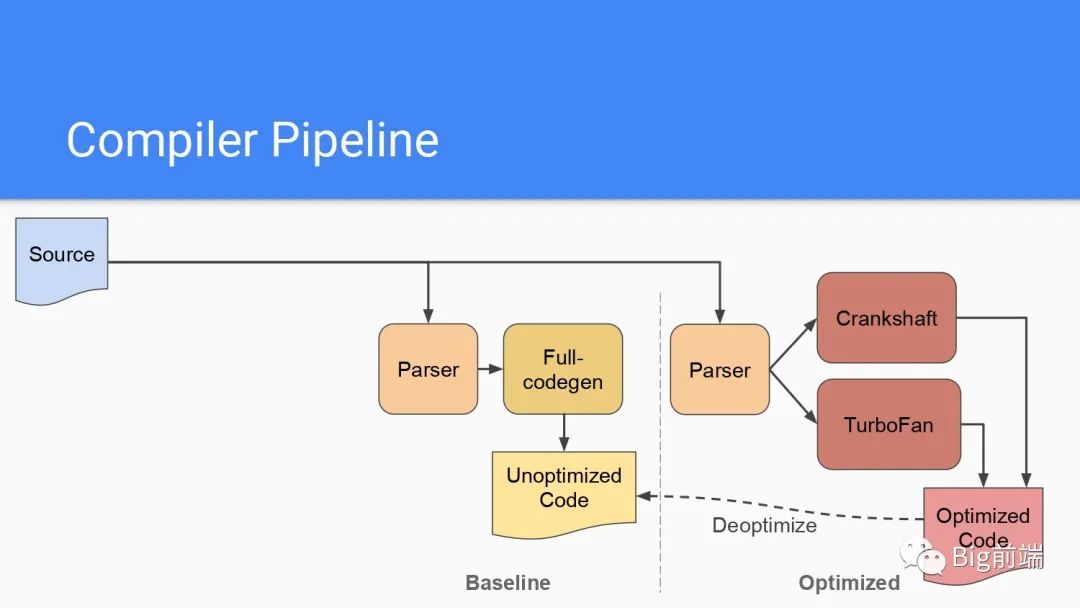
运行多次的脚本被优化
 运行多次的代码会被再次编译,通过Crankshaft(旧)或者TurboFan然后生成优化后的代码加速下次执行的效率
运行多次的代码会被再次编译,通过Crankshaft(旧)或者TurboFan然后生成优化后的代码加速下次执行的效率
问题是什么?
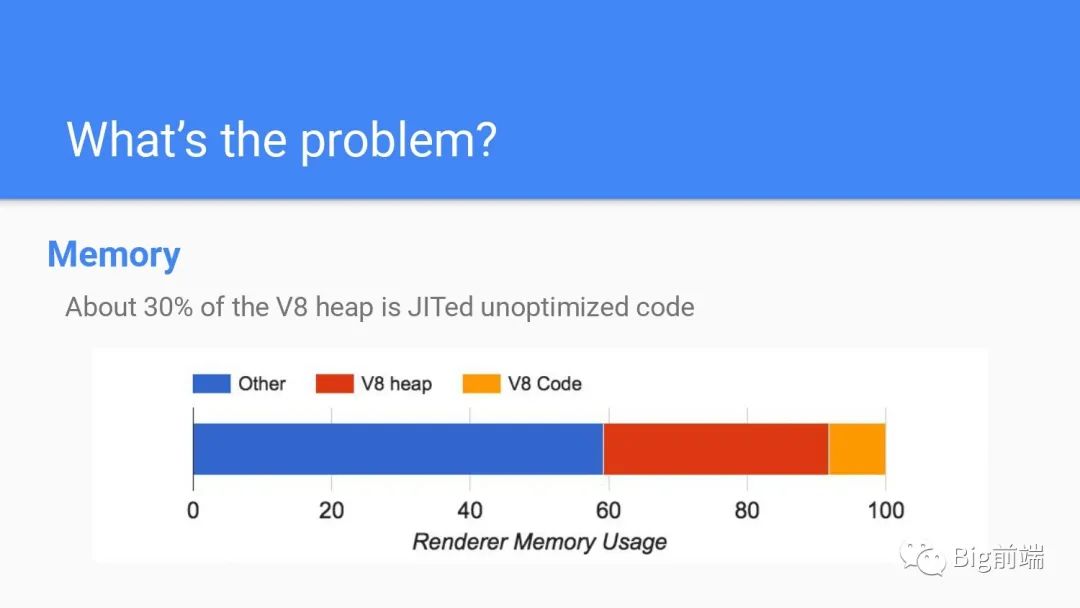
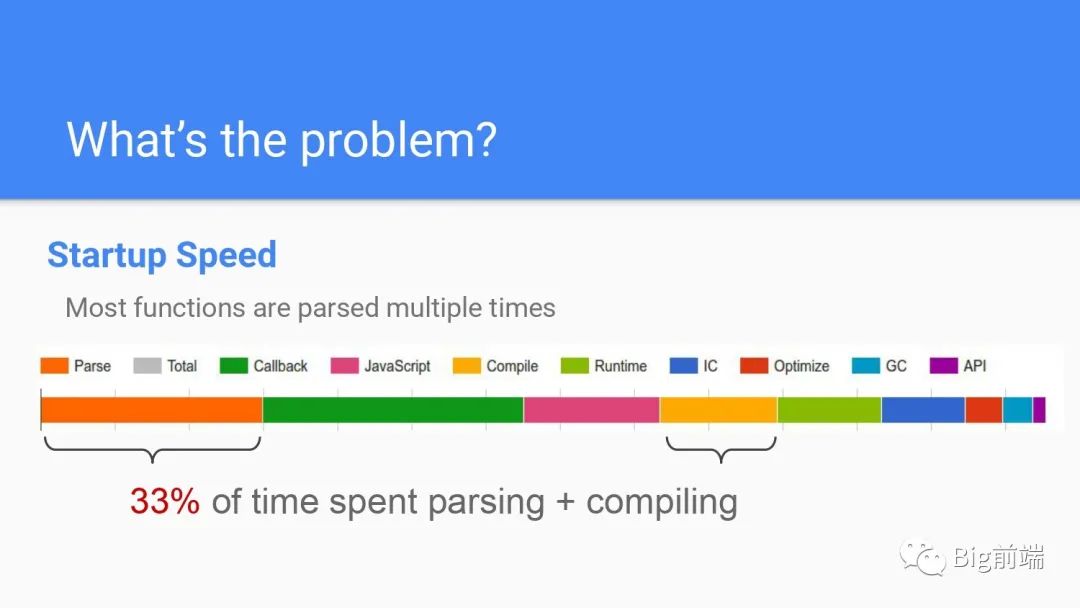 浏览器渲染进程的30%~50%的内存被V8堆占据,而从启动时间来看33%的时间会花费在Parse解析和Compile编译代码上
浏览器渲染进程的30%~50%的内存被V8堆占据,而从启动时间来看33%的时间会花费在Parse解析和Compile编译代码上
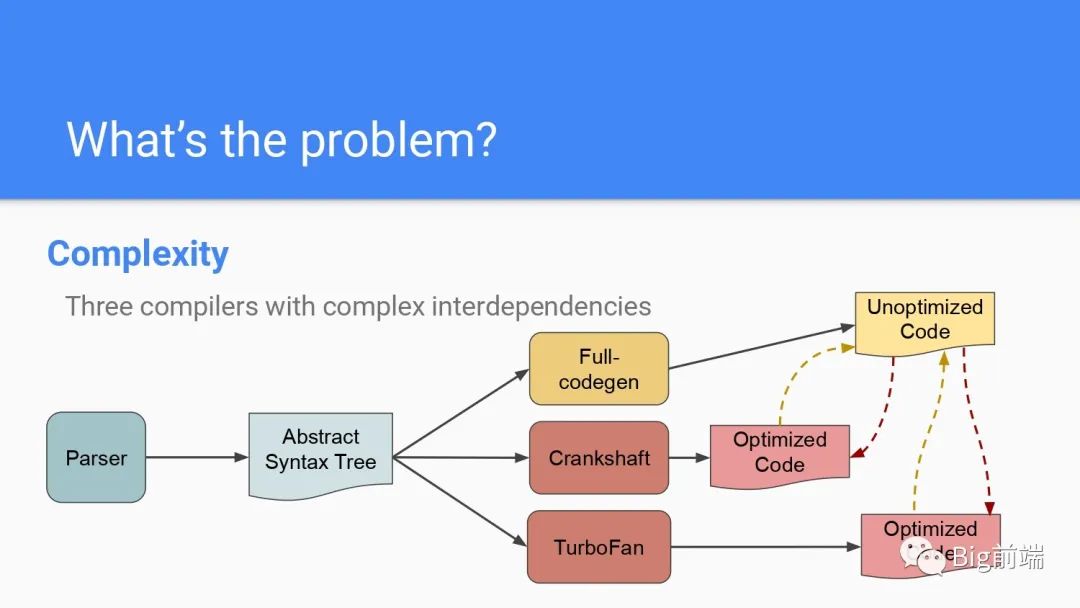 程序设计上的复杂性来说,AST抽象语法树后有多个编译器处理代码,优化部分也有不同的编译器处理,处理后需要跟没优化的代码做合并同步
程序设计上的复杂性来说,AST抽象语法树后有多个编译器处理代码,优化部分也有不同的编译器处理,处理后需要跟没优化的代码做合并同步
Ignition V8的字节码解析器
何谓解析器,我们知道比如C/C++,go这种语言的代码是需要经过编译为二进制文件的,运行的时候拿二进制文件就可以直接运行而不需要重新编译。而解释型的语言每次运行都需要通过解析器对程序进行动态解析和执行,比如JavaScript,Python等
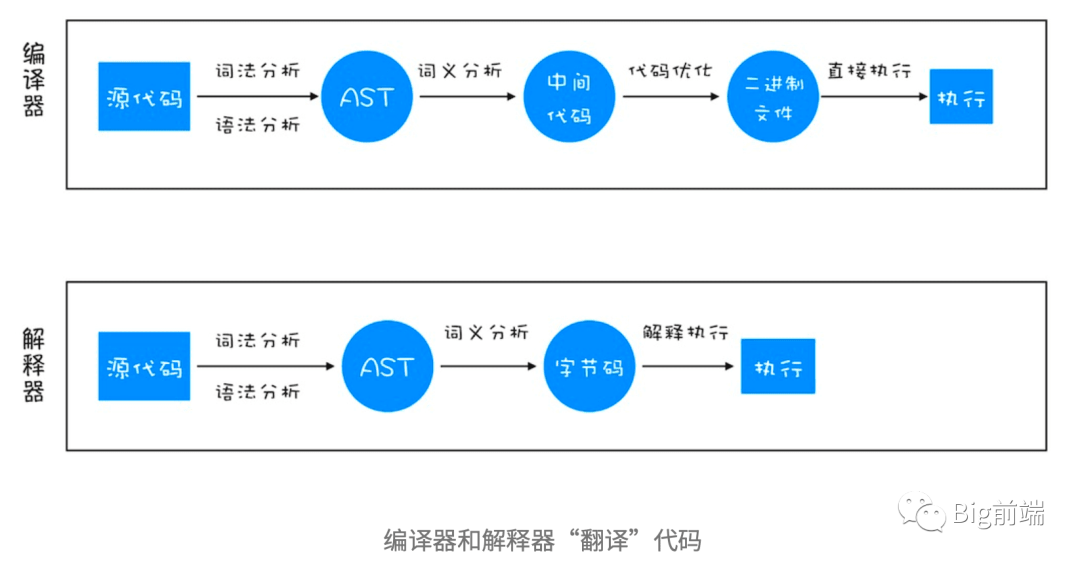 脚本代码被tokenize分词即「词法分析」和parse解析即「语法分析」后生成AST,编译为Bytecode字节码。Bytecode字节码比起机器码来说占用内存小,是处于机器码和AST的中间状态,平衡了内存和效率,如下从左到右可以看到原代码其实占用的磁盘空间最少也最易于阅读,机器码占用空间最多且最不易于阅读。
脚本代码被tokenize分词即「词法分析」和parse解析即「语法分析」后生成AST,编译为Bytecode字节码。Bytecode字节码比起机器码来说占用内存小,是处于机器码和AST的中间状态,平衡了内存和效率,如下从左到右可以看到原代码其实占用的磁盘空间最少也最易于阅读,机器码占用空间最多且最不易于阅读。
 有了如上的背景认识后应该可以理解为什么要这样做。
有了如上的背景认识后应该可以理解为什么要这样做。

- 比起编译为机器码,字节码可以减少内存消耗
- 减少解析的开销,字节码简洁方便JS立即编译的现状
- 降低compiler pipeline的复杂性,以字节码做中间产物,作为optimizing优化/deoptimizing取消优化的输入输出来源
所以此时的流程就变成下面这样,原始代码经过词法分析,语法分析后经过Ignition解析器解析为字节码,字节码又会被TurboFan优化。Ignition是点火的意思,TurboFan是涡轮增压的意思。汽车引擎运行时候一段时间点火燃烧,后面涡轮增压介入同一时间更多风进入燃烧室,汽油的燃烧更充分,如此循环反复代码执行越来越快。
 所以现在会存在三种编译模式,直接解释的,全量编译和优化后的三种流程。剧透一下2017年后Full-Codegen 和 Crankshaft 两个编译器已经被移除。也就是说现在其实只有Ignition和TurboFan两种,留下下图是为了纪念一下V8团队的同学几年架构优化工作。
所以现在会存在三种编译模式,直接解释的,全量编译和优化后的三种流程。剧透一下2017年后Full-Codegen 和 Crankshaft 两个编译器已经被移除。也就是说现在其实只有Ignition和TurboFan两种,留下下图是为了纪念一下V8团队的同学几年架构优化工作。
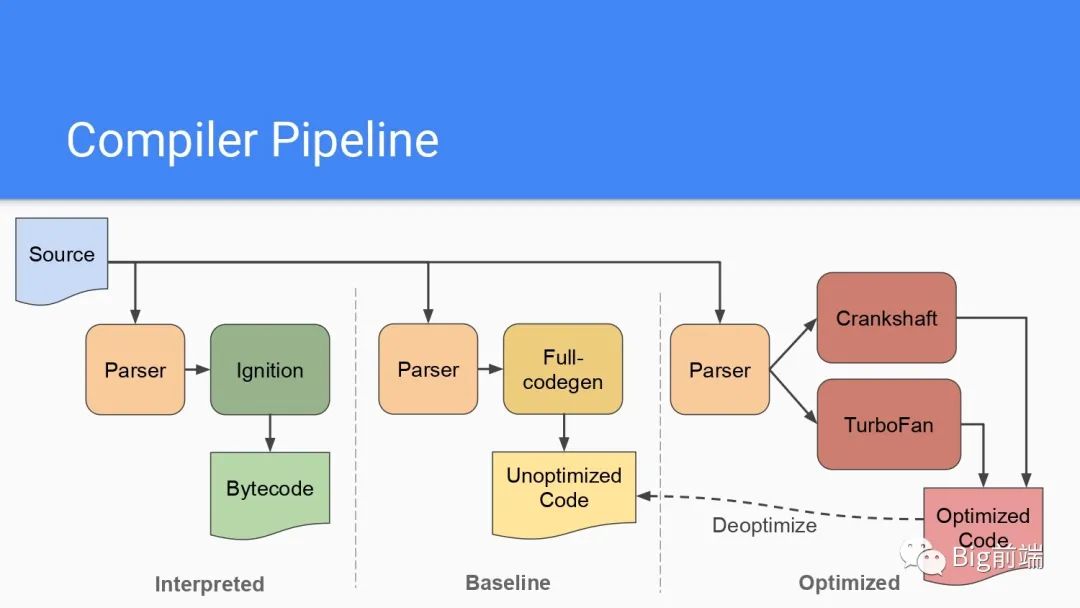 最终现在的V8的流程应该是下面这样的。「重点来了!重点来了!重点来了!」
最终现在的V8的流程应该是下面这样的。「重点来了!重点来了!重点来了!」
「JS源代码首次执行时候被解析为AST抽象语树,Ignition解释器逐条代解释为Bytecode字节码,如果途中发现有代码被重复执行多次,这种称为热点代码HotSpot,那么后台的编译器TurboFan会介入帮助将此处的热点代码编译为高效的机器码,当这段代码再次执行,则直接执行TurboFan编译后的机器码,这里就加速了部分热点代码的二次执行效率」
Deep Dive
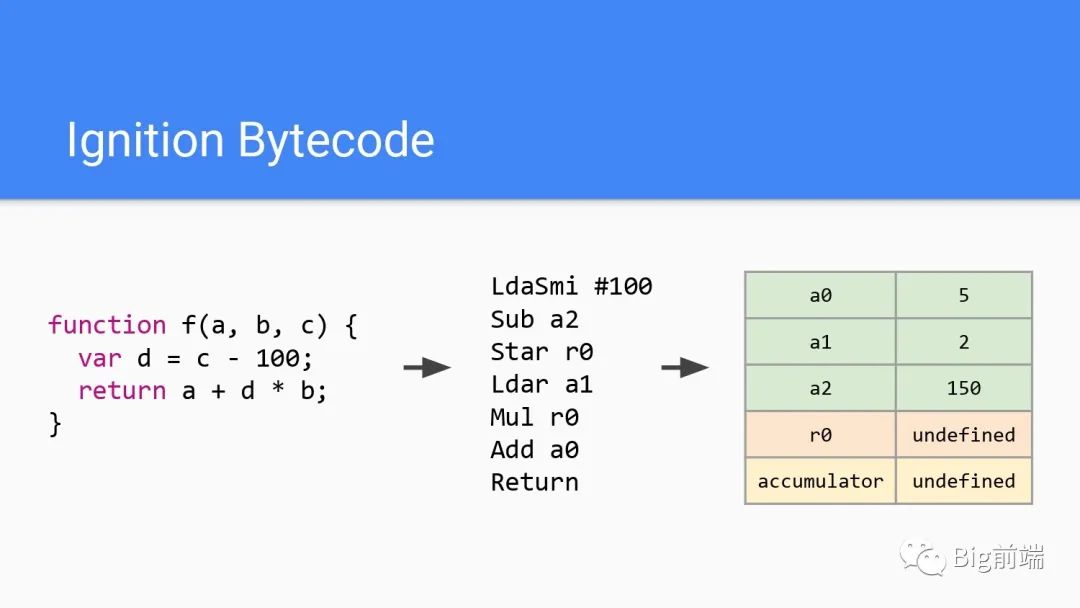 如上代码经过Ignition解析为字节码后,执行时候会创建上图右边的存储在堆栈中的局部变量或者临时表达式。想象有无限的寄存器空间可以分配使用,此处寄存器不是机器的寄存器而是内存堆栈上的一块空间。每次字节码进入时,r0都会作为操作数,以undefined初始化r0。
如上代码经过Ignition解析为字节码后,执行时候会创建上图右边的存储在堆栈中的局部变量或者临时表达式。想象有无限的寄存器空间可以分配使用,此处寄存器不是机器的寄存器而是内存堆栈上的一块空间。每次字节码进入时,r0都会作为操作数,以undefined初始化r0。
除此之外还有a2,a1,a0等等,sub是一个二进制操作。accumulator累加器作为每行字节码最后的隐式输出,可以避免执行栈的push/pop操作从而存储临时结果提高执行效率。一个执行从左到右是这样的
开始取r0数据 => 操作 => 输出结果到累加器里结束
继续操作 => 输出结果到累加器里结束
继续操作 => 输出结果到累加器里结束
……
累加器accumulator默认也是undefined,开始执行。
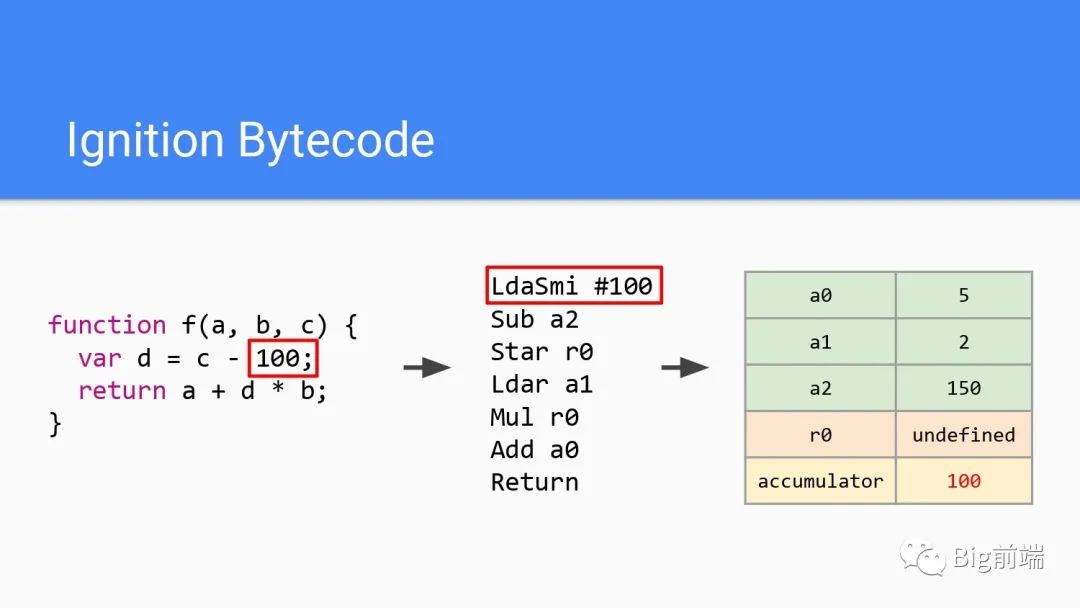 Lda是赋值,Smi是V8里小整数的名称,所以这里第一行字节码将100加载到累加器里,对应最右侧的红色100
Lda是赋值,Smi是V8里小整数的名称,所以这里第一行字节码将100加载到累加器里,对应最右侧的红色100
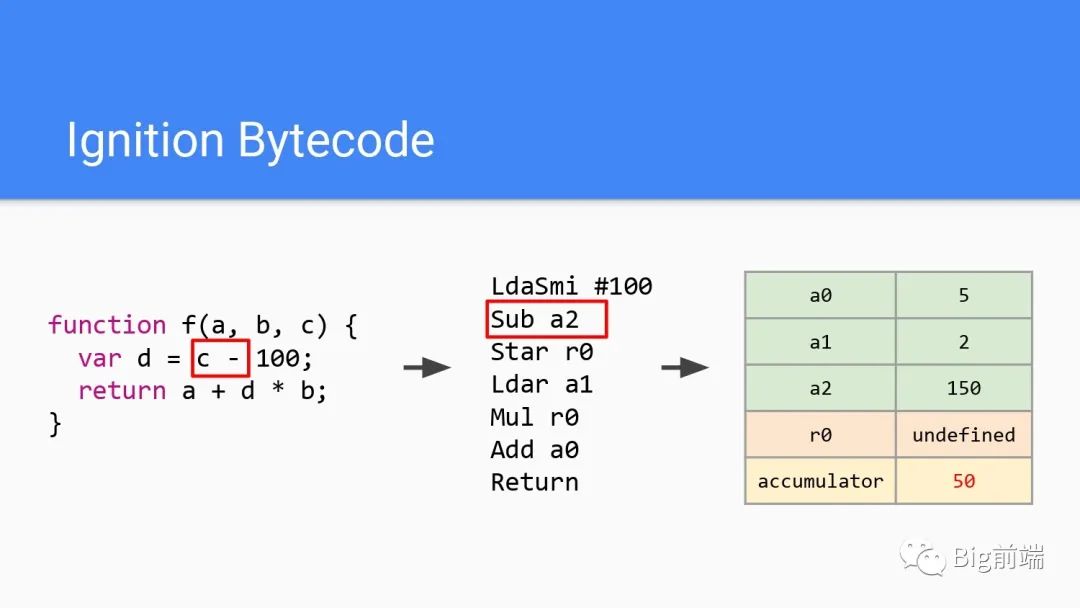 a2原有150减去累加器的100,最后得到50。所以累加器在第二行字节码结束后被存入50结束。进入第三行字节码,对应结果赋值给变量d
a2原有150减去累加器的100,最后得到50。所以累加器在第二行字节码结束后被存入50结束。进入第三行字节码,对应结果赋值给变量d
 所以这里Star是将累加器结果赋值给r0,r0为50,即源代码里d为50。继续第四行字节码
所以这里Star是将累加器结果赋值给r0,r0为50,即源代码里d为50。继续第四行字节码
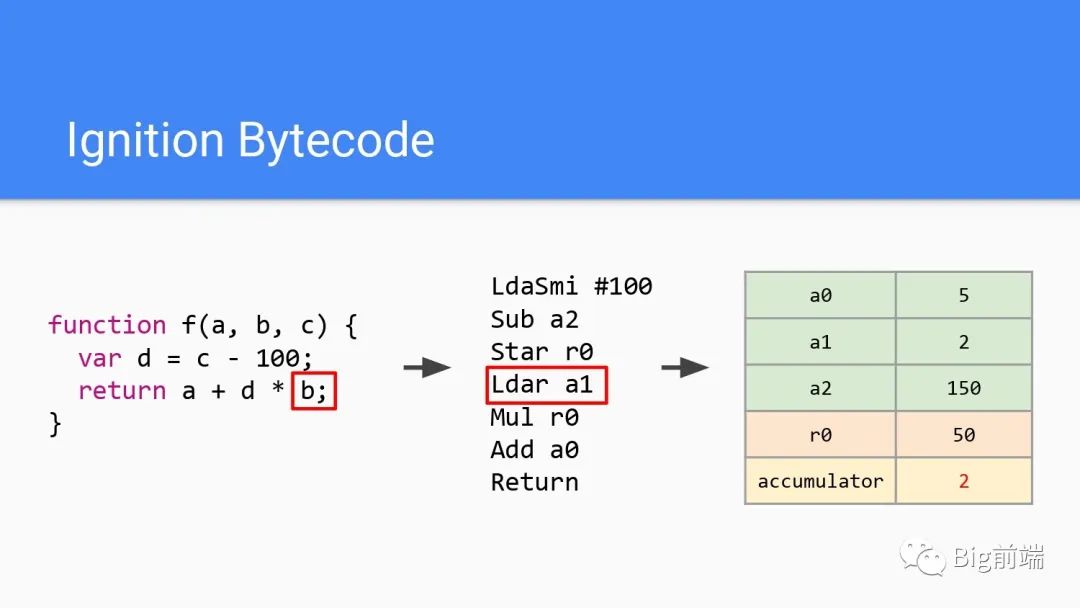 第四行Ldar加载参数b,赋值a1,就是2,此时累加器为2,r0为50
第四行Ldar加载参数b,赋值a1,就是2,此时累加器为2,r0为50
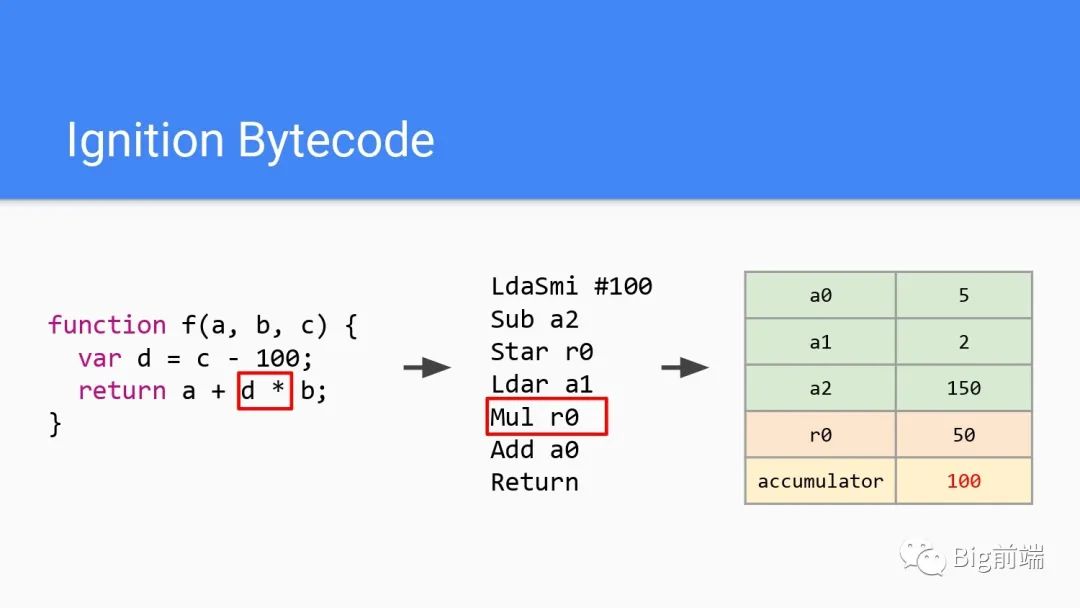 字节码第五行Mul为乘法,即执行2*50得到100存入累加器
字节码第五行Mul为乘法,即执行2*50得到100存入累加器
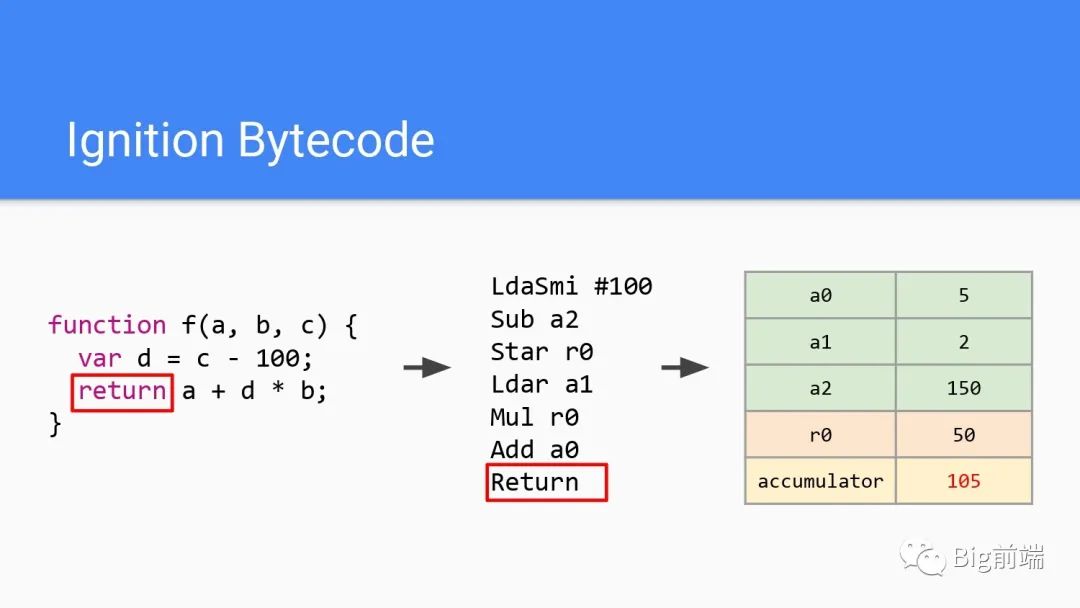
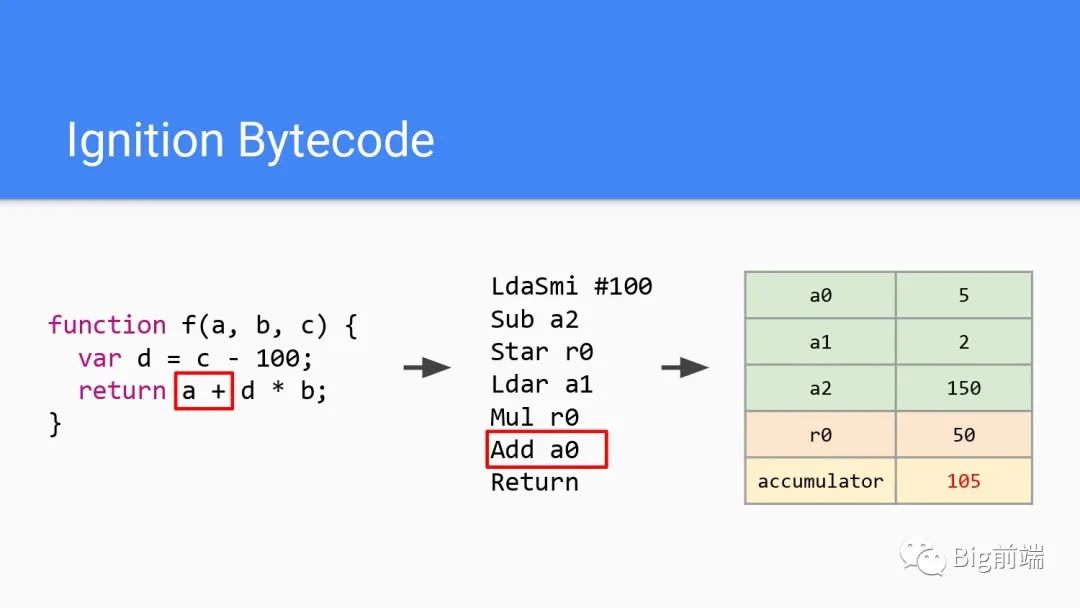 第6行字节码,加上a0的值,可以看到a0为5,所以此处最后累加器为105。最后一行字节码返回,即返回此时的累加器的值,最后返回了105。
第6行字节码,加上a0的值,可以看到a0为5,所以此处最后累加器为105。最后一行字节码返回,即返回此时的累加器的值,最后返回了105。
Ignition Bytecode Pipeline
 源代码被解析后生成AST,遍历AST节点后经过字节码生成器。代码如上图右边所示,首先访问左边表达式并存入寄存器,然后计算表达式的右侧(命名可以看出这里有累加器的参与),执行add操作后,将执行结果设置到累加器里。
源代码被解析后生成AST,遍历AST节点后经过字节码生成器。代码如上图右边所示,首先访问左边表达式并存入寄存器,然后计算表达式的右侧(命名可以看出这里有累加器的参与),执行add操作后,将执行结果设置到累加器里。
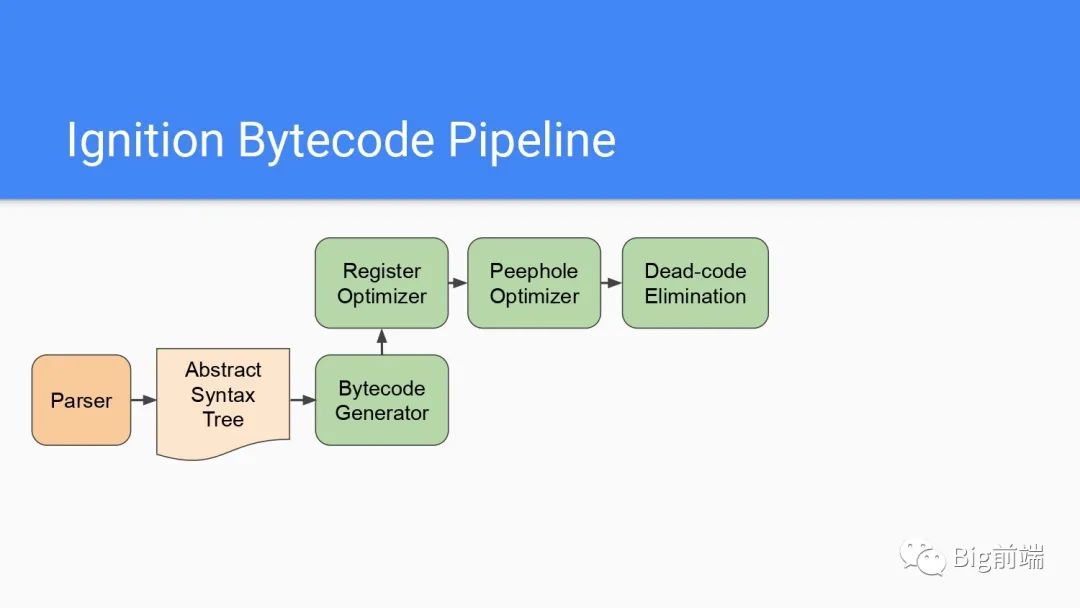 每个字节码编译流水线处理都包括了好几步,寄存器优化的部分即减少非必要的寄存器加载和存储,合并公共的字节码转化为单个字节码然后一次性执行所有操作,还有如果在开始执行前就知道返回的字节码结果,那么就可以进行简单的Dead-code去除以减少字节码体积。Dead-code即不会运行到的代码。
每个字节码编译流水线处理都包括了好几步,寄存器优化的部分即减少非必要的寄存器加载和存储,合并公共的字节码转化为单个字节码然后一次性执行所有操作,还有如果在开始执行前就知道返回的字节码结果,那么就可以进行简单的Dead-code去除以减少字节码体积。Dead-code即不会运行到的代码。
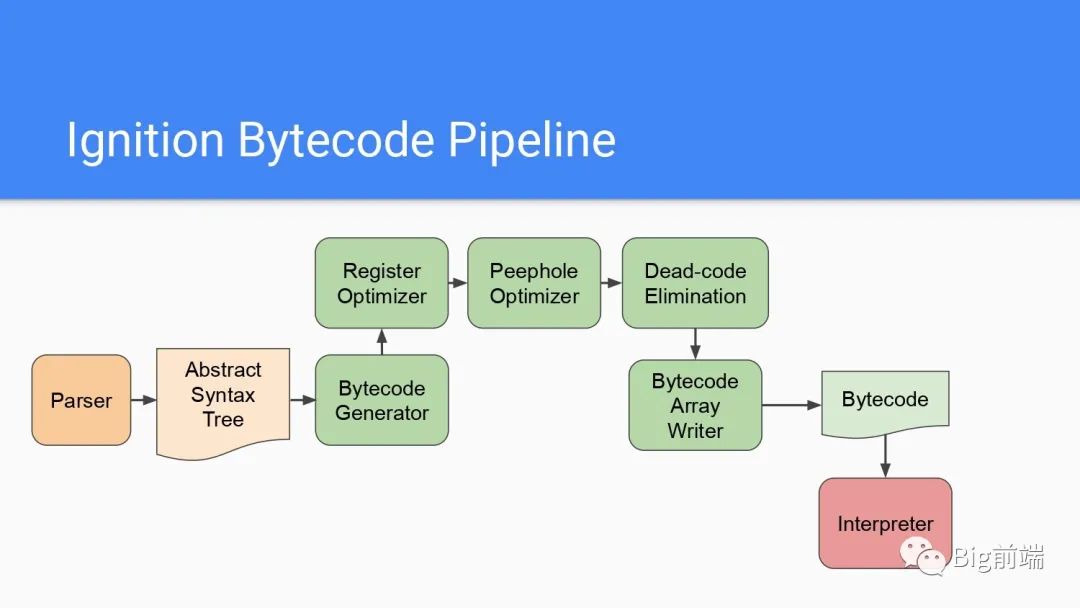 上面处理后通过Bytecode Array Writer重新写入给到Interpreter解释器(即前面说的Ignition)。
上面处理后通过Bytecode Array Writer重新写入给到Interpreter解释器(即前面说的Ignition)。
 解析器的效率比起编译是慢的,但是却不是你想象的那么慢。这并不是说C++慢,编译器非常擅长优化switch或go-to这种代码,编译就类似一个大的switch,把每一块扔进去执行一下翻译出来结果就好。问题在于要解析器与v8的其他部分进行交互,比如JITed functions,这会变得很慢。其次是无法与fast code-stubs进行互相操作。C++的调用与JS不一样,要将C++调用约定转化为JS调用约定,v8里有一大堆手写代码处理常见的快速路径被称为fast code-stubs,这些需要专门的jump去跳转到对应的逻辑,否则无法使用(会慢很多),这块是v8里手工编写的汇编代码,现在v8里有9个架构端口,对应不同操作系统不同的底层能力适配。
解析器的效率比起编译是慢的,但是却不是你想象的那么慢。这并不是说C++慢,编译器非常擅长优化switch或go-to这种代码,编译就类似一个大的switch,把每一块扔进去执行一下翻译出来结果就好。问题在于要解析器与v8的其他部分进行交互,比如JITed functions,这会变得很慢。其次是无法与fast code-stubs进行互相操作。C++的调用与JS不一样,要将C++调用约定转化为JS调用约定,v8里有一大堆手写代码处理常见的快速路径被称为fast code-stubs,这些需要专门的jump去跳转到对应的逻辑,否则无法使用(会慢很多),这块是v8里手工编写的汇编代码,现在v8里有9个架构端口,对应不同操作系统不同的底层能力适配。
我们有一个优化编译器TurboFan,它为每个架构生成快速代码,就像你手工编码的汇编,但是你写一次它就会为9个架构生成汇编代码,与现在代码相对轻松的相互操作。TurboFan在编译底层是作用在机器级的,也是最后一级的优化,因此我们仍然获得了优化低级指令调度的优势。
Eager Compilation
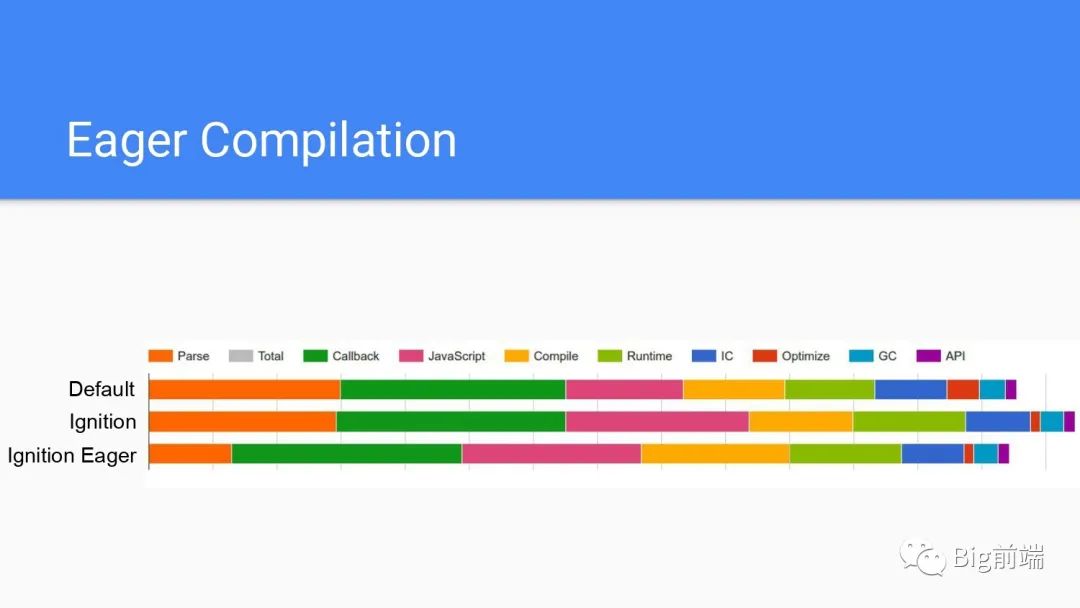 编译和解析实际上并没有那么快可以识别,上图是为典型的25个网站统计的图表,从前面两部分,即Default和Ignition两条可以看到现在花了更多的时间执行实际的JS代码,编译和解析部分基本差不多,这是用到了惰性编译方式。这种方式就是用到了才编译,对内存占用不会很多。但是如果是Eager的形式尽可能编译所有代码,虽然占用内存变大了,但是解析的时间大大减少了,是最快的配置模式。
编译和解析实际上并没有那么快可以识别,上图是为典型的25个网站统计的图表,从前面两部分,即Default和Ignition两条可以看到现在花了更多的时间执行实际的JS代码,编译和解析部分基本差不多,这是用到了惰性编译方式。这种方式就是用到了才编译,对内存占用不会很多。但是如果是Eager的形式尽可能编译所有代码,虽然占用内存变大了,但是解析的时间大大减少了,是最快的配置模式。
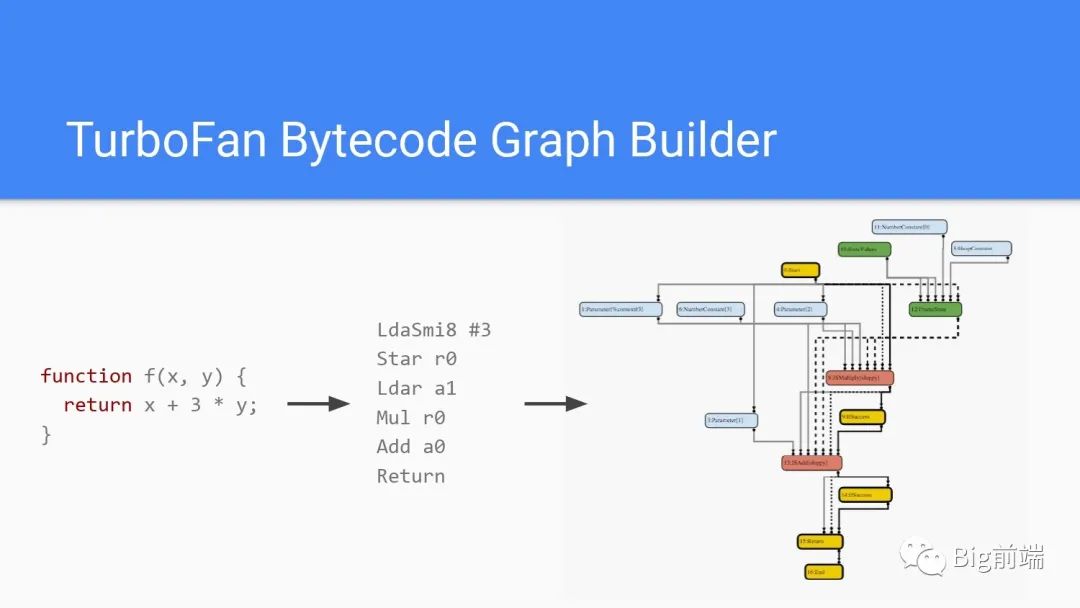 TurboFan对Ignition处理源代码生成的Bytecode字节码处理后生成上图右侧的图一样的结构
TurboFan对Ignition处理源代码生成的Bytecode字节码处理后生成上图右侧的图一样的结构
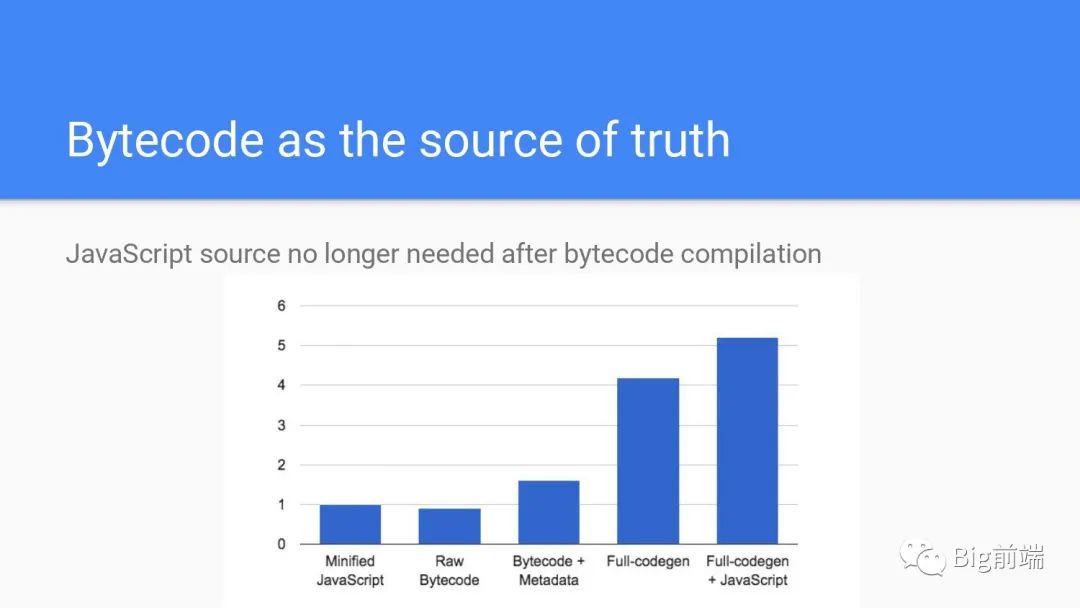 字节码编译后不再需要源代码,可以看到压缩后的源代码是1体积,机器编译的Raw Bytecode会小一点,但是需要额外的元数据方便debug源代码的位置,合并在一起如上图第三根柱状的样子,大约是原来的1.6倍体积。但是编译后你的源代码占用的内存就可以去掉了以节省这一部分的内存,代码被保留为字节码存下来。如果是全量编译的话会是之前压缩后源码的4倍体积,但是这里源代码无法丢弃,因为还需要解析,最终开销会是原来压缩过代码的5-6倍
字节码编译后不再需要源代码,可以看到压缩后的源代码是1体积,机器编译的Raw Bytecode会小一点,但是需要额外的元数据方便debug源代码的位置,合并在一起如上图第三根柱状的样子,大约是原来的1.6倍体积。但是编译后你的源代码占用的内存就可以去掉了以节省这一部分的内存,代码被保留为字节码存下来。如果是全量编译的话会是之前压缩后源码的4倍体积,但是这里源代码无法丢弃,因为还需要解析,最终开销会是原来压缩过代码的5-6倍
总结

- Ignition是V8里快速解析器
- 在低端设备可以立即减少内存占用
- 在高端设备可以在启动加速加快启动
- 更简单的编译器流水线为更多的新机会奠定基础
Q&A
- eval执行的时候发生了什么?
将字符串传递给解析器并从中生成代码,是单独解析的不会被优化,优化会重新生成AST
参考
- Youtube
- PPT
- 深入理解 JavaScript 的 V8 引擎