从C++转向最受欢迎的Rust语言
在日常开发过程中,若长期使用C++语言,在初次使用Rust的过程中可能会碰到一些问题。本文尝试从C++的角度来说明在使用Rust时需要特别注意的一些地方,特别是其中的思维方式的转变(mind shift)。
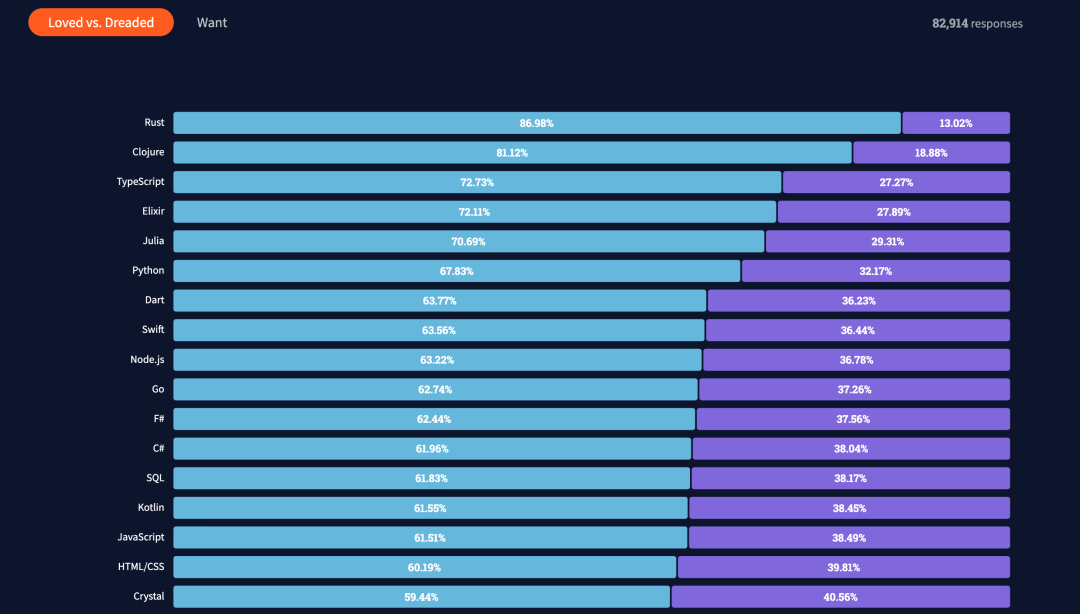
不久前 Stackoverflow 网站做了一项有八万多开发人员参与的调查问卷,在“大家最想学习的编程语言”选项中,Rust高居第一。
一、赋值的move语义
(一)C++ vs Rust
C++的赋值操作是copy语义,在不考虑优化的情况下,从语义的角度理解,赋值后内存中的某个对象即变成了两份。修改新的对象并不会对旧对象产生副作用。
而Rust对赋值操作有更加精细的控制,以下两条:
- 对于所有实现了Copy trait的类型来说,赋值采用了copy语义。
- 对于其它情况,采用move语义。
在Rust中直接使用编译器来保证了move语义,确保变量的值被移出后,不能被再使用,如下例:
fn main() {
let mut x = 5;
let rx0 = &mut x;
let rx1 = rx0;
println!("test {}", rx0);
}会产生编译错误:
error[E0382]: borrow of moved value: `rx0`
--> src/main.rs:5:25
|
3 | let rx0 = &mut x;
| --- move occurs because `rx0` has type `&mut i32`, which does not implement the `Copy` trait
4 | let rx1 = rx0;
| --- value moved here
5 | println!("test {}", rx0);
| ^^^ value borrowed here after move明确地说明了原因:变量在移动后又被使用了,在哪儿被使用,以及为什么采用了move语义。
而在C++中,可以通过禁用class的拷贝构造函数来达到禁止变量复制的目的。如以下代码是编译不通过的:
#include <memory>
using namespace std;
int main(int argc, const char* argv[]) {
auto int_p0 = unique_ptr<int>(new int);
auto int_p1 = int_p0;
*int_p0 = 5;
return 0;
}在clang++中会产生如下错误:
main.cc:8:10: error: call to implicitly-deleted copy constructor of 'std::__1::unique_ptr<int, std::__1::default_delete<int> >'
auto int_p1 = int_p0;
^ ~~~~~~
/opt/llvm/clang-10.0.1/bin/../include/c++/v1/memory:2513:3: note: copy constructor is implicitly deleted because 'unique_ptr<int, std::__1::default_delete<int> >' has a user-declared move constructor
unique_ptr(unique_ptr&& __u) _NOEXCEPT
^但是只需要将错误行改成如下代码即可以编译通过:
auto int_p1 = std::move(int_p0);
但后果是,程序在对*int_p0进行赋值时会产生coredump。这也是Rust所谓的内存安全性,即只要没有使用unsafe,编译器可以发现内存的错误访问,并拒绝通过编译。
(二)引**用&T与可变引用&mut T**
还是上面的例子,如果将其中的可变引用改成非可变引用(默认形式的引用),如下代码:
fn main() {
let x = 5;
let rx0 = &x;
let rx1 = rx0;
println!("test {}", rx0);
}可以通过编译。Rust的文档中有如下说明:
The following traits are implemented for all &T, regardless of the type of its referent:
Copy
Clone (Note that this will not defer to T’s Clone implementation if it exists!)
Deref
Borrow
Pointer
*&mut T references get all of the above except Copy and Clone
(to prevent creating multiple simultaneous mutable borrows),
plus the following, regardless of the type of its referent:
DerefMut
BorrowMut&mut T相较于&T少实现了Copy和Clone。因此,对于可变引用&mut T来说,赋值采用的是move语义,而对于普通引用&T来说采用的是copy语义,所以改成普通引用上面的程序就可以编译通过了。
这也是为什么可变引用也被称之为独占引用,因为每次对可变引用的赋值,都意味着旧变量的失效,这就确保了全局只会存在一份可变引用。
Rust在这里体现了语言设计的优雅:赋值操作的语义委托到了类型系统,通过定义基本的机制同时约束了自定义类型与内建类型的行为,在编译期完成检查,而不是需要开发去记忆各种特例。这在不了解语言的时候会产生学习曲线,但是一旦了解了其套路后(Thinking in Rust), 可以显著地降低编码过程中的心智负担。
二、Option与空指针
(一)enum与match
在C++中,对于可能存在或不存在的变量,惯常的作法之一是传入指针 (包括现代C++中智能指针shared_ptr和unique_ptr),在处理时,通过检查指针是否为空来判断变量是否存在。这是一种非常便利的做法,但是同样的,此方案在编译期无法做更多的检查,最终检查的责任交给了开发。
Rust对此问题主要使用了两个机制:枚举(enum)和模式匹配(match)。相比较C++的enum, Rust的enum更像是C++的union。是 ADT(algebraic data type)中sum types(tagged union)在Rust中的实现。在Rust中enum可能包括一组类型中的一个,如:
enum Message {
Quit,
Move {x: i32, y: i32},
Write (String),
}上面代码表示,一条消息(Message)可能有三种类型: Quit、Move和Write。当类型为Move或者Write时,还可以带上自己的特定的数据。当处理Message时,则会使用模式匹配机制取得具体类型进行处理:
match message {
Message::Quit => todo!(),
Message::Move { x, y } => todo!(),
Message::Write(info) => todo!(),
}为了避免在修改了enum的定义后,忘记在match中添加相应的处理,match会在编译期要求分支必须覆盖全部可能的情况。如在Message中新加入一项:
enum Message {
Quit,
Move {x: i32, y: i32},
Write (String),
Send (String), // 新加入
}再编译时会出现以下错误,提示开发将Send的处理加入match。
--> src/main.rs:9:11
|
1 | / enum Message {
2 | | Quit,
3 | | Move { x: i32, y: i32 },
4 | | Write(String),
5 | | Send(String),
| | ---- not covered
6 | | }
| |_- `Message` defined here
...
9 | match message {
| ^^^^^^^ pattern `Send(_)` not covered
|
= help: ensure that all possible cases are being handled, possibly by adding wildcards or more match arms
= note: the matched value is of type `Message`由此可见,在C++中,与其最相似的类型其实是C++17的std::variant,而match机制类似于std::visit。但Rust在这里做得更完善一些,体现在:
- 相同的子类型可以因为Tag的不同出现多次,如上面的Write和Send,子类型都是String。这是std::variant无法直接做到的,除非再封装一个结构。
- match会要求分支覆盖enum所有变体,std::visit也会在编译期检查完整的类型覆盖,但其中类型会考虑C++的隐式类型转换,使用时需要小心。
(二)Option
有了上面的预备知识,现在就可以来了解在Rust中是如何处理空悬指针的问题。先看一下Option的定义:
pub enum Option<T> {
/// No value
None,
/// Some value `T`
Some(T),
}在Rust中,对于可选的情景,会定义为该变量类型的Option。假设某函数提供从磁盘读取某个token,该token可能存在或者不存在,那么该函数的定义会是:
struct Token { /*...*/ };
fn load_token() -> Option<Token>;在使用的时候会采用如下代码:
let token = load_token(); // 此时 token 的类型是 Option<Token>
match token {
Some(token) => {
// 注意这里的 token 是由 Some(token) 这个 pattern 匹配出来的
// 已经覆盖了最外层的 token. 此时 token 的类型是 Token, 已经
// 确保存在。
todo!()
},
None => todo!()
}可以看到,对于返回Option
相较于使用指针来表达可选情形,Option
了解Haskell的同学可以发现,Option与Maybe如出一辙。事实上,Rust的类型系统,很大程度地受到了Haskell的影响,所以很多地方可以看到Haskell的影子也并不奇怪。学习Haskell对理解Rust也会很有帮助。
最后说明一下,在C++17中加入的std::optional实现了类似的功能。从接口上说还是像智能指针,使用前需要判断,否则对std::nullopt进行dereference还是会产生运行时故障。
三、迭代器Iterator
(一)Iterator在Rust中的地位
Iterator是Rust相对独特的功能。对于Rust来说,采用如下的方式去遍历数组是低效的:
let data = vec![1,2,3,4,5];
for i in 0..data.len() {
println!("{}", data[i]);
}因为向安全性的妥协,每次data[i]的操作都会进行边界检查,显然这种检查是不必要的,在性能敏感的场景中也是不可接受的。因此,在Rust中推荐的做法是:
for v in data {
println!("{}", v);
}使用迭代器的形式避免了最终取值时的再一次边界检查,同时也更加简洁。由此可见,以地道的Rust风格来说,遍历数组应该使用迭代器来完成,而不是通过遍历下标来进行索引。
对于现代C++ (C++11)来说,也提供了类似的语法方式进行容器遍历:
for (auto&& v: data) {
// do something for v
}(二)取得迭代器的三种形式
对于可以迭代的对象,以std::vec::Vec为例,通常会提供三种方式取得迭代器,如下:
- iter():取得元素的引用,即&T,非消耗性。
- iter_mut():取得元素的可变引用,即&mut T,非消耗性。
- into_iter():取得元素的所有权,即T,消耗性。
这里消耗性指的是在迭代完成之后,原来的容器是否还可以继续使用。对于into_iter()来说,在迭代过程中已经将容器中的所有元素所有权全部取得,所以最终容器不再持有任何对象,也同时被drop。因此称之为消耗性的。
(三)IntoIterator
对于一般的迭代形式:
for x in data {}
Rust期望data是一个实现了Iterator的对象。否则,会尝试使用IntoIterator将data转换成Iterator对象。所以对于data: Vec
for x in IntoIterator::into_iter(data) { }
这里for ... in语句使用IntoIterator::into_iter获取了目标对象的迭代器。因此,凡是实现了IntoIterator的类型均可以使用for ... in语句进行迭代。
以std::vec::Vec为例,分别为Vec
let mut data: Vec<i32> = Vec::from([1,2,3,4]);
// 取得引用
for v: &i32 in &data {}
// 取得可变引用
for v: &mut i32 in &mut data {}
// 取得所有权
for v: i32 in data {}(四)链式调用
在Rust的设计中,利用Adapter可以灵活而高效地通过Iterator来处理集合。
Adapter在Rust中指的是一类函数,它们接收一个Iterator并且返回一个Iterator。这样的接口规范使用可以通过链式调用的方式组合多个Adapter完成复杂的功能。常见的Adapter包括:map、filter以及filter_map等等。
除了Adapter,Rust也提供其它一些函数用于迭代器的最终处理。比如:
- count
用于计算元素的个数。
- collect
用于收集迭代器中的元素到某个实现了FromIterator的类型中去,比如Vec、VecDeque和String等等。
- reduce
使用某个函数对集合进行规约。类似地,也可以使用fold进行有初值的规约。
可以看到,针对迭代器,Rust提供了丰富的函数对其处理,具体可以参考文档。此种编码风格,与旧风格的C++很不一样,转到Rust后在需要对集合进行循环处理的场合,可以有意识地想想,能不能将逻辑写成迭代器的形式,通常可以得到更加简洁的代码,同时,如前面所说,也可能获得性能更高的代码。
最后提一下,C++社区也在积极的采纳此种代码风格,在C++20中,已经将ranges加入标准。其中提供的Range adaptors与Rust的Adapter的概念基本是一样的。如C++的样例代码:
auto const ints = {0,1,2,3,4,5};
auto even = [](int i) { return 0 == i % 2; };
auto square = [](int i) { return i * i; };
// "pipe" syntax of composing the views:
for (int i : ints | std::views::filter(even) | std::views::transform(square)) {
std::cout << i << ' ';
}写成Rust则是:
let ints = vec![0, 1, 2, 3, 4, 5];
let even = |i: &i32| 0 == *i % 2;
let square = |i: i32| i * i;
for i in ints.into_iter().filter(even).map(square) {
println!("{}", i);
}一、惰性求值-Laziness
最后需要提一下的是,对于使用链式调用的方式将各种Adapter组合的Iterator,其求值是惰性的。即,当写下如下代码时:
let v = vec![0,1,2,3,4,5];
v.iter().map(|i| println!("{}", i));其实并不会去调用println将数据输出。Rust文档的原文是:
This means that just creating an iterator doesn’t do a whole lot.
Nothing really happens until you call next即,只有调用迭代器的next方法,才会依次触发各级Iterator的求值。这样做的好处是:
(一)性能
考虑如下代码:
let v = vec![0,1,2,3,4,5,6,7,8,9];
let even = |i: &i32| 0 == *i % 2;
let square = |i: i32| i * i;
v.into_iter().filter(even).map(square).take(2);如果是eager evaluation,前两个Adapter,filter(even)和map(square)会分别先执行10次和5次,最后才是take(2)取到最开始的两个元素。如果这个数组的长度不是10,而100万,那么这里浪费的空间和时间将会是巨大的。同时也会影响响应时间,因为只有前面两步都处理完毕之后,才会进行到最后一步。
而采用lazy evaluation时,执行会由take(2).next()传导到map(square)再到filter(even), 最终不论数组的长度是多少,都只会调用filter(even)3次,map(square)2次。没有产生额外的开销。
(二)无限迭代
惰性求值的另一个好处是,使得无限迭代器成为了可能。考虑如下代码:
let number = 1..; // 这是一个无限迭代器
for n in number.filter(even).take(5) {
println!("{}", n)
}不会因为filter(even)的调用而陷入死循环。而是按需取用。使用此种方法,可以使用递推公式实现数列的迭代器, 并支持各种Adapter的组合:
pub struct Fib {
n0: u64,
n1: u64,
}
impl Default for Fib {
fn default() -> Self {
Self { n0: 0, n1: 1 }
}
}
impl Iterator for Fib {
type Item = u64;
fn next(&mut self) -> Option<Self::Item> {
let n = self.n0 + self.n1;
self.n0 = self.n1;
self.n1 = n;
Some(self.n0)
}
}
fn main() {
let fib = Fib::default();
let square = |i: u64| i * i;
for n in fib.map(square).take(10) {
println!("{}", n);
}
}五、总结
本文主要是记录自己从C++转向Rust碰到的一些问题,特别是记录两种语言在处理程序设计中基础问题的不同套路。这一篇主要介绍了三个主题:move语义、Option和Iterator。由于笔者写的Rust也不多,所以其中必然会有很多错误与不足,发出来与大家交流,希望大家包涵并不吝指教。
之后也会以同样的形式介绍其它主题,比如当前心里还想着要记录的有:错误处理、生命周期&借用、interior mutability等。接下来自己争取将后面的系列完成。