深入理解链表
链表是一种基本的线性表数据结构,它使用非连续的内存空间来存储一组数据。
内存模型
与数组的连续内存空间相比,链表中的每个元素是可以存储在内存中的任意位置的,它通过指针将一组零散的内存块串联起来使用。
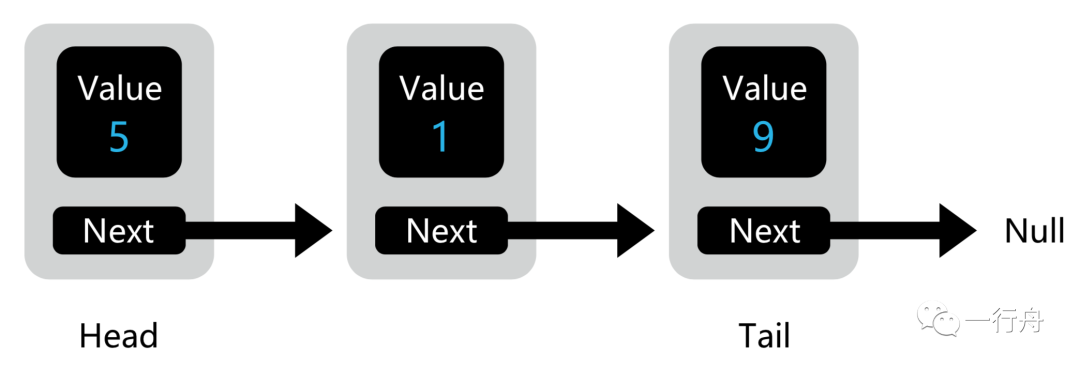
Next 是指针或引用类型,它存储的是所指对象的内存地址。正因为要存储下一个结点的内存地址,所以链表所需的整体内存空间要比数组的大。
时间复杂度
链表的这种灵活的内存存储结构,让它的插入和删除变得比较高效。
当要在特定位置插入新结点时,需要 2 次赋值操作,所以时间复杂度是 O(1)。
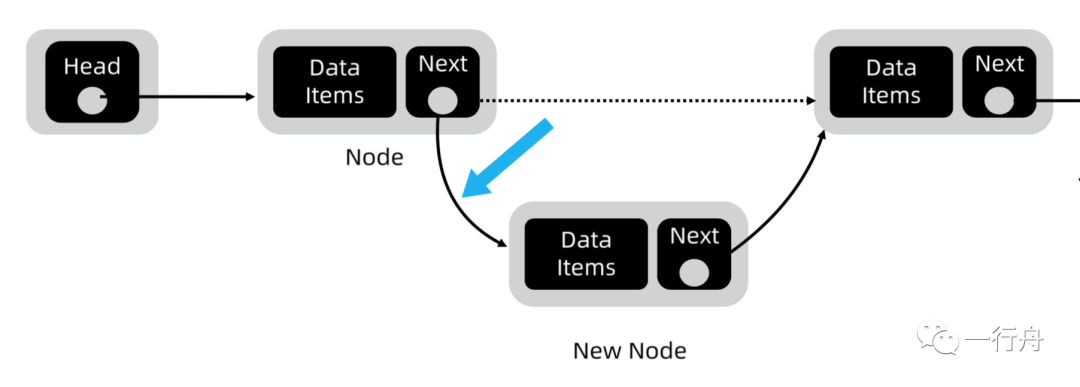
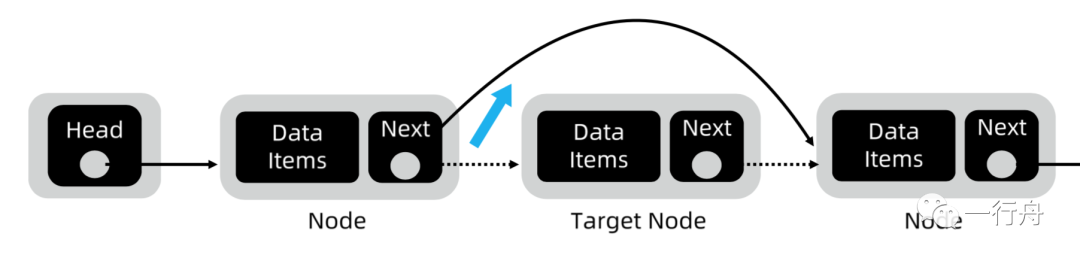
上一个结点 ~ 前驱结点 下一个结点 ~ 后继结点
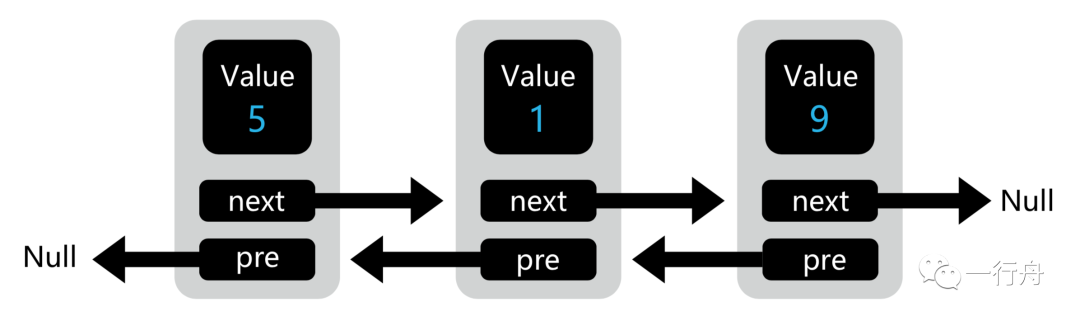
双向链表可以 O(1) 地找到前驱结点,正是这样的特点使得双向链表在某些情况下的插入和删除操作都要比单链表高效,比如在指定结点前插入一个新结点或删除特定结点。所以双向链表的应用也挺广泛的,比如 Java 里的 LinkedHashMap 容器,就是用双向链表这种数据结构实现的。
不过,无论是单链表还是双向链表,当要随机访问第 i 个元素时,都没有数组那么高效,由于内存空间的不连续致使它没法靠索引来直接寻址,只能从头开始遍历,所以时间复杂度是 O(n)。
| 链表的操作 | 时间复杂度 |
|---|---|
| 随机访问 | O(n) |
| 查询 | O(n) |
| 插入 | O(1) |
| 删除 | O(1) |
注意:这里是借时间复杂度来直观地理解特定数据结构的基本操作,重点是“特定数据结构”和“基本操作”。比如我们说链表可以 O(1) 地删除一个结点是指“删除”这一原子操作,倘若是删除单链表中的指定结点或是删除“值为X”的特定结点那链表还需要先 O(n) 地查询才能再 O(1) 地删除。
linked list double linked list
循环链表
除了上面介绍的单链表和双向链表之外,还有一种非常常见的链表结构,那就是循环链表。
- 单向循环链表
- 双向循环链表
循环链表的特点是从链尾又重新指回了链头,这非常适用于具有环型结构特点的数据,比如著名的约瑟夫问题。
实战
链表的理论虽然不难,但要写好链表的代码也是不容易的,因为这里到处都是指针操作和边界处理,稍不留神就容易出 bug。
1 . 警惕指针丢失和内存泄露
2 . 链表的边界条件处理
- 为空时?只包含一个结点时?只包含两个结点时?
- 操作头结点和尾结点时?
3 . 善用保护结点,即带头的链表
- eg.有序链表的合并, K个一组反转链表
- 可避免繁琐的判断,同时也提供了一个访问入口
- 但并不是所有链表都需要带此保护结点
数组 vs 链表
在实际开发中,需要根据具体情况来权衡,究竟是选数组还是链表。
1 . 数组更省内存,且不易产生内存碎片
- 链表要额外存储前驱/后继结点的内存地址
- 链表的频繁插入和删除会导致频繁的内存申请和释放,容易造成内存碎片
- eg. Java 有可能会导致频繁的垃圾回收
2 . 数组大小固定,而链表天然支持动态扩容
- 严格意义上的数组,大小是固定的
- 变长数组的动态扩容还会涉及到内存申请和数据搬移
3 . 结合具体场景
- 时间复杂度:随机访问/查询/插入/删除
- eg.CPU的缓存机制可以预读数组里的数据-访问效率会更高
总结
本文重点介绍了链表的原理,包括其内存模型和基本操作的时间复杂度(随机访问/查询/插入/删除),当然这些都是基于特定的链表结构展开的(单链表/双向链表/循环链表)。最后简要说明了下写链表代码的注意事项,以及在实际开发中选择数组还是链表的几个参考点。
-
原理
-
内存模型:通过指针将一组零散的内存块串联起来
-
时间复杂度:查询和随机访问 O(n), 插入和删除 O(1)
-
常见的链表结构:单链表, 双向链表, 循环链表
-
实战
-
写链表代码时的注意事项
-
数组 vs 链表
主要参考
- https://time.geekbang.org/column/article/41013
- https://u.geekbang.org/lesson/270?article=419797