Linux 存储系列|请描述一下文件的 io 栈?
坚持思考,就会很酷
请简单描述一下文件的 io 栈?
同事问到你,你能立马就讲个道道出来吗?这个问题可以往深入讲,也可往浅出讲。最主要的还是心里有把尺,要有整体的把握。
我们今天分三个小步走来分享这个问题的思考。
- 首先,要明确一条清晰的 IO 栈路线;
- 其次,要了解每一个途径地点的大致用途;
- 最后,可以深入了解内核调用的代码路线;
文件 IO 的内核路线
IO 从用户态走系统调用进到内核,内核的路径:VFS → 文件系统 → 块层 → SCSI 层 。这里提一点,Linux 的 “文件” 的概念已经升华了,一切皆文件,网络 IO 其实进到内核也是走 VFS 。
这条路径可以完全记到心里,更深入的细节可以后续基于这个框架去补充。那么接下来我们稍微了解下这 IO 路径途径的 4 个节点分别做哪些事情?
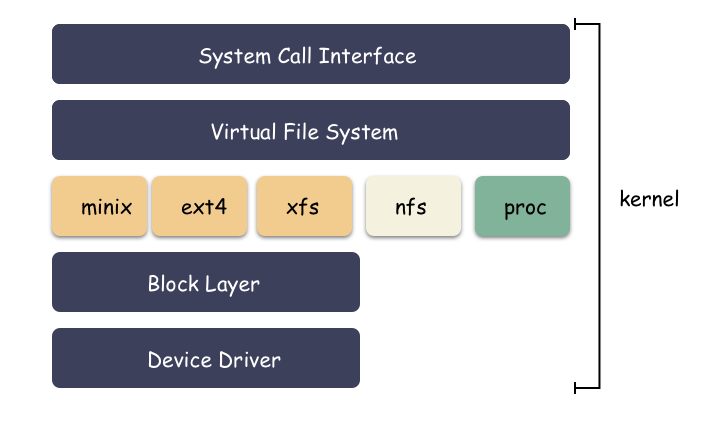
内核 IO 栈示意图
内核 IO 路线的节点
1 VFS 层
VFS ( Virtual File System 、Virtual FileSystem Switch )层是 Linux 针对文件概念封装的一层通用逻辑,它做的事情其实非常简单,就是把所有文件系统的共性的东西抽象出来,比如 file ,inode ,dentry 等结构体,针对这些结构体抽象出通用的 api 接口,然后具体的文件系统则只需要按照接口去实现这些接口即可,在 IO 下来的时候,VFS 层使用到文件所在的文件系统的对应接口。
它的作用:为上层抽象统一的操作界面,在 IO 路径上切换不同的文件系统。
假设现在你想要写个内核文件系统,那么只需要按照 Linux 预设的一些 api 接口,实现起来就行了。
2 文件系统
VFS 把 IO 给到具体的文件系统,文件系统主要做啥呢?
它的作用:对上抽象一个文件的概念,把数据按照策略存储到块设备上。
文件系统管理的是一个线性的空间(分区,块设备),而用户看到的却是文件的概念,这一层的转化就是文件系统来做的。它负责把用户的数据按照自己制定的规则存储到块设备上。比如是按照 4K 切块存,还是按照 1M 切块存储,这些都是文件系统自己说了算。
它这一层就是做了一层空间的映射转化,文件的虚拟空间到实际线性设备的映射。这层映射最关键的是 address_space 相关的接口来做。
3 块层
块层其实在真实的硬件之上又抽象了一层,屏蔽不同的硬件驱动,块设备看起来就是一个线性空间而已。块层主要还是 IO 调度策略的实现,尽可能收集批量 IO 聚合下发,让 IO 尽可能的顺序,合并 IO 请求减少 IO 次数等等;
划重点:块层主要做的是 IO 调度策略的一些优化。比如最出名的电梯算法就是在这里。
因为所有的 IO 都会汇聚下来,那么在块层做调度优化是最合适的。Linux 也允许用户自行配置这里的调度策略,比如 CFQ,Deadline,NOOP 等策略。
4 SCSI 层
SCSI 层这个就不用多说了,这个就是硬件的驱动而已,本质就是个翻译器。SCSI 层里面按照细分又会细分多层出来。它是给你的磁盘做最后一道程序,SCSI 层负责和磁盘硬件做转换,IO 交给它就能顺利的到达磁盘硬件。
5 IO 之旅小结
基本上梳理出上面的主干,这个问题就有解了。后续的就是工作中遇到了某些问题,再针对某个问题细化研究,去查资料,去看内核代码。
比如,这里抛出来一个问题:page cache 是怎么回事?
这个就要去文件系统层看一看了。
Page Cache 梳理
基于 Linux 版本 3.10
1 Page Cache 在哪一层?
page cache 是发生在文件系统这里。通常我们确保数据落盘有两种方式:
- Writeback 回刷数据的方式:write 调用 + sync 调用;
- Direct IO 直刷数据的方式;
在文件系统这一层,当处理完了一些自己的逻辑之后,需要把数据写到块层去,无论是直刷还是回刷的方式,都是用到 address_space_operations 里面实现的方法:
struct address_space_operations {
// 回刷的方式,走 Page Cache
int (*write_begin)(struct file *, struct address_space *mapping, loff_t pos, unsigned len, unsigned flags, struct page **pagep, void **fsdata);
int (*write_end)(struct file *, struct address_space *mapping, loff_t pos, unsigned len, unsigned copied, struct page *page, void *fsdata);
// 回刷的方式,走 Page Cache
int (*writepage)(struct page *page, struct writeback_control *wbc);
int (*readpage)(struct file *, struct page *);
int (*writepages)(struct address_space *, struct writeback_control *);
int (*readpages)(struct file *filp, struct address_space *mapping, struct list_head *pages, unsigned nr_pages);
void (*readahead)(struct readahead_control *);
// 直刷的方式
ssize_t (*direct_IO)(int, struct kiocb *, const struct iovec *iov, loff_t offset, unsigned long nr_segs);
// ...
};下面举一个最简单的栗子,比如 Minix 文件系统:
如果实现一个走 Page Cache 回刷功能的文件系统,那么至少要实现 .write_begin,.write_end,.write_page,.read_page 的接口。巧了,minix 就实现了这几个接口:
static const struct address_space_operations minix_apos = {
.readpage = minix_readpage,
.writepage = minix_writepage,
.write_begin = minix_write_begin,
.write_end = generic_write_end,
.bmap = minix_bmap,
};所以,从上面的实现来看,minix 是具备 buffer write 的能力的,当写一个数据的时候,调用栈是:
SYSCALL_DEFINE3(write)
vfs_write
.write = do_sync_write // minix 复用了公共的 write
generic_file_aio_write
generic_file_buffered_write
generic_perform_write // 重要函数!!用户的数据最终在 generic_perform_write 函数里写到了内存中,并且 IO 至此完成。简单说下 generic_perform_write ,它做这几件事情:
- 调用 minix_write_begin 分配出 page 内存,并且 page 对应到 buffer head,对应到底层块设备的地址;
- 把用户数据 copy 到 page 内存中,这样数据就从用户态到内核态了;
- 对应的 page 设置“脏”的标记,这样就能被识别到了;
文件系统怎么把 “文件” 的偏移翻译成块设备地址的偏移呢?
有一个非常重要的函数:minix_get_block 就是干这件事的。这个函数将在 minix_write_begin 里面被调用到。这个函数会创建一些 buffer head 的结构体出来,这些结构体将会对应到块的物理位置。page 和 buffer head 关联,所以自然 page 和块物理位置也确认了。
数据在 generic_perform_write 写到内存后,用户的 write 调用就完成了,这种在 Page 的内存的数据我们叫做脏数据(脏页),后面就是等待异步的回刷。
触发脏数据回刷的方式有多种:
- 时间久了,比如超过 30 秒的,那必须赶紧刷,因为夜长梦多;
- 量足够大了,比如脏页超过 100M 了,那必须赶紧刷,因为量越大,掉电丢数据的损失越大;
- 有人调用了 Sync ,那必须赶紧刷;
刷这些脏数据,内核是作为任务交给了 kworker 的线程去做。简单来讲就是这是 kworker 会去挑选块设备对应的的一些脏“文件”,把这些对应的 page 内存刷到磁盘。
很多人可能会疑惑,那回刷又是怎么实现的呢?
无论回刷的触发点是哪个,回刷的实现还是要回到文件系统,也就是文件系统提供的 .write_page 或者 .write_pages 的接口。比如 minix 实现了 minix_write_page 的接口。
回刷非常简单,因为 page 对应要写的地址已经在 minix_write_begin 的时候确定了(物理位置已经绑定好了)。所以只需要对应写下去就行了。
一点题外话,ext4 这个文件系统为了性能考虑,有一种 delay alloc 的选项,把物理位置的绑定不放在用户的路径( .write_begin ) ,而是放在异步回刷的时候 .write_pages 。
如果是 Direct IO 的方式,那么就简单一点:
SYSCALL_DEFINE3(write)
vfs_write
.write = do_sync_write // minix 复用了公共的 write
generic_file_aio_write
generic_file_direct_write // direct io 的重要函数
.direct_IO // 要具体文件系统支持direct IO 就不会走先写 page cache ,再异步回刷的方式了,它直接就把用户数据 copy 到内核,封装成块层需要的 IO 结构丢下去等结果即可。
但,并不是所有的文件系统都会实现 direct IO,比如 minix 就没有实现,ext2/ext3/ext4 等文件系统倒是实现了,感兴趣的可以去看 ext2_direct_IO 的实现。
总结
- IO 栈:VFS - 文件系统 - 块层 - SCSI 驱动层;
- VFS 负责通用的文件抽象语义,管理并切换文件系统;
- 文件系统负责抽象出“文件的概念”,维护“文件”数据到块层的位置映射,怎么摆放数据,怎么抽象文件都是文件系统说了算;
- 块层对底层硬件设备做一层统一的抽象,最重要的是做一些 IO 调度的策略。比如,尽可能收集批量 IO 聚合下发,让 IO 尽可能的顺序,合并 IO 请求减少 IO 次数等等;
- SCSI 层则是负责最后对硬件磁盘的对接,驱动层,本质就是个翻译器;
- 文件的 buffer write 要实现 .write_begin,.write_page 等接口,前者用于分配 page 并绑定块层物理空间,后者用户异步回刷的时候调用(注意,非常规的优化在回刷的时候才去绑定物理空间);
- 文件系统 .write_begin 调用分配物理位置的时候依赖于 get_block 的实现,物理位置分配好之后,page 会对应到特定的 buffer head 结构,buffer head 结构则对应到具体的块设备位置;
- direct IO 直接在用户路径上刷数据到磁盘,不走 PageCache 的逻辑,但并不是所有文件系统都会实现它;
后记
分享一点 IO 栈的知识脉络,希望对你有帮助。