基于rancher的容器平台监控方案参考
大家好, 本篇为我在做公司容器化监控平台选型时的一些调研思路和资料记录,希望可以给到大家启发和帮助。
阅读本文,你可以了解到:
现阶段容器化方案总结
容器化监控曾经出现过的几种方案:
-
1/ Heapster[1] + ElasticSearch + Kibana
-
2/ Heapster[2] + influxdb + grafana
-
Heapster 通过 cAdvisor 组件收集 Node 和 容器的监控数据。kubernetes 1.13 彻底移除对 Heapster 的使用,Heapster 仓库也归档,不再更新维护。
-
3/ 基于 Prometheus 生态的监控方案;
站在2022这个时间点,Prometheus已是容器化监控的首选。各种资料对比显示它已经成为容器监控领域的标准。
基于 Prometheus的监控栈,主要有以下两套部署方案:
- 1、手动部署 Prometheus 的各种组件,需要部署的组件大致如下:
- alermanager
- n9e,v5 版本[3] 已全面改版支持 Promtheus 和 VictoriaMetric 作为存储,完全可以单独作为报警组件使用。
- 临时 prometheus
- 持久化 influxdb /VictorMetric
- node-exporter 采集 node 监控
- cAdvisor 容器级别的监控指标
- kube-state-metrics 采集 pod 相关监控指标
- 采集组件:
- 持久化存储组件:
- 报警组件:
- 手动部署可参考文档:https://docs.prometheus.cool/Kubernetes/Prometheus-Statefulsets-1/
- 2、使用kube-prometheus[4],基于 Prometheus Operator 来实现部署维护;
该存储库收集了 Kubernetes 清单、Grafana 仪表板和 Prometheus 规则以及文档和脚本,以使用 Prometheus Operator 提供易于操作的端到端 Kubernetes 集群监控与 Prometheus。
- 部署可参考文档:http://gitlab.bokecc.com/opgroup/dev/cc_dev_docs/blob/master/dev/container/k8s_operator.md
- k8s 官方 Operator 文档:https://kubernetes.io/zh/docs/concepts/extend-kubernetes/operator/
- Operator Hub 文档:https://operatorhub.io/
- Prometheus Operator 文档:https://prometheus-operator.dev/
Prometheus 方案详解
数据采集项
日常监控的采集项:
- 基础设施,cpu/mem/disk/net
- 业务信息,port/process/trace/link
- 自定义,特有指标。
容器需要采集或监控的数据指标:
- 基础设施,服务器节点(node 节点)健康情况
- k8s 基础组件健康情况
- k8s 整体资源的饱和度
- 自定义。
各指标对应采集方案和组件如下:
-
基础设置
-
node 主机信息 ---> node-exporter
-
各组件监控及资源使用情况、容器性能(如容器的 CPU、内存、文件和网络的使用情况),cAdvisor ---> state-metrics
-
业务信息:
-
容器健康状态,Probes ---> state-metrics
-
健康探测(link/trace)---> 外部探测(自建、阿里云)
-
自定义,---> 自己暴露 metrics 接口
数据存储
Prometheus 作为收集和临时存储使用,因为单点不具备扩容能力,不适合做持久化存储。
持久化存储,目前业界有三种种比较成熟的开源方案:
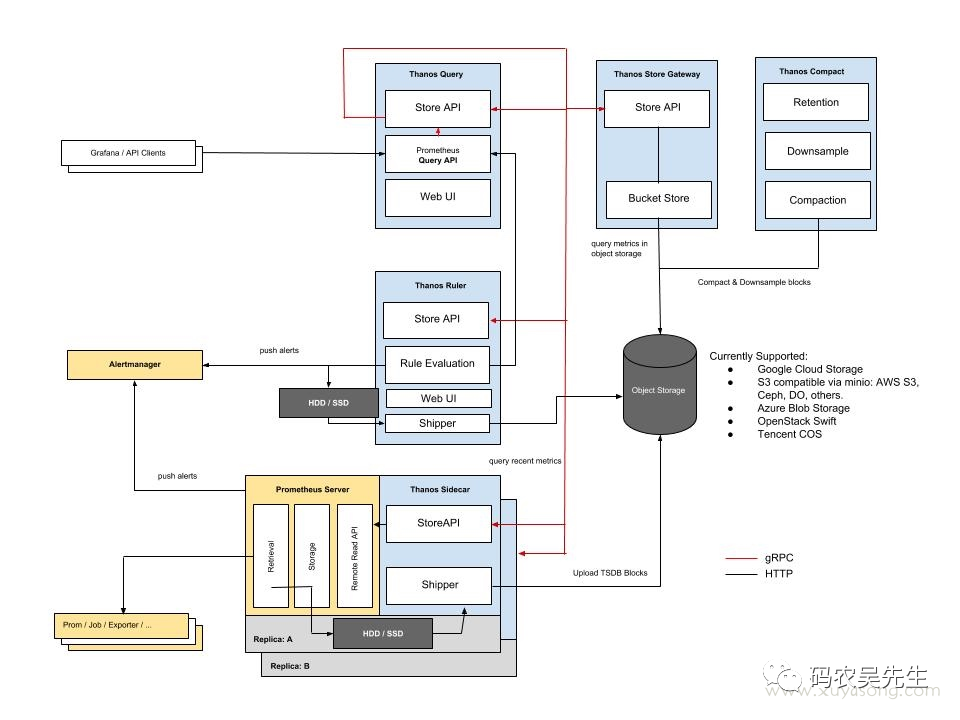
- Thanos[5] 架构
- Cortex[6] 架构

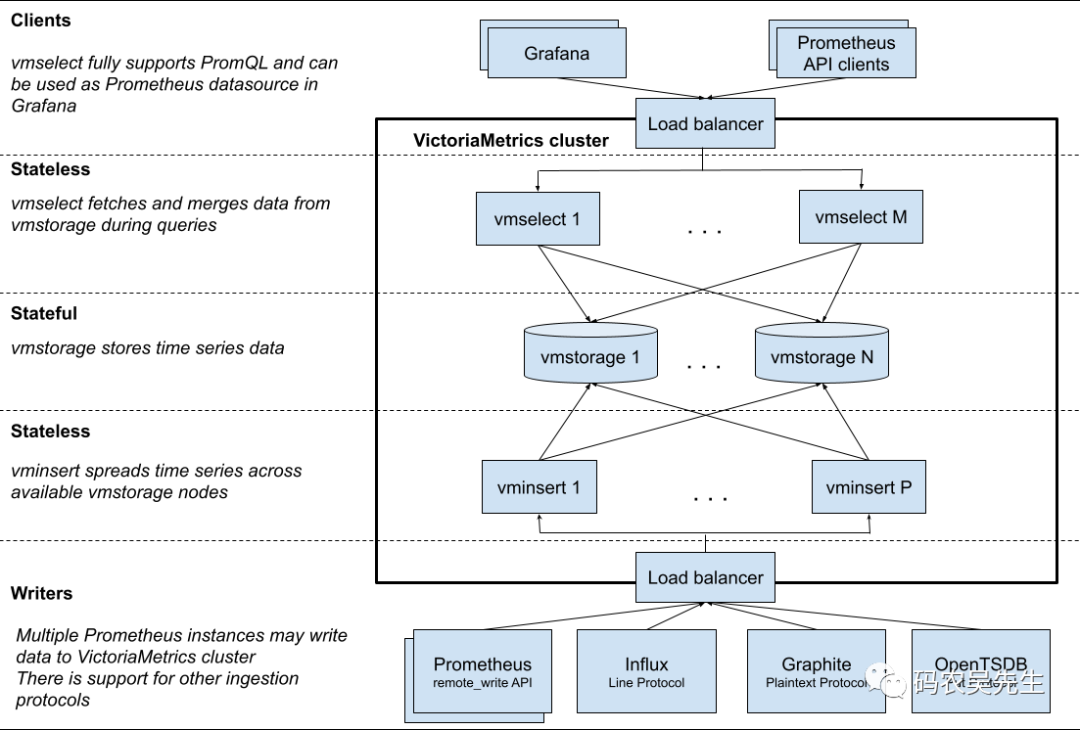
- VictoriaMetric[7] (只支持写,不支持读[8]) 架构
Thanos vs VictoriaMetric 两种方案对比,可参考文档:
- https://blog.csdn.net/alex_yangchuansheng/article/details/108271368
- https://github.com/VictoriaMetrics/VictoriaMetrics/wiki/FAQ#what-is-the-difference-between-victoriametrics-and-thanos
Cortex vs VictoriaMetric 对比:
- https://github.com/VictoriaMetrics/VictoriaMetrics/wiki/FAQ#what-is-the-difference-between-victoriametrics-and-cortex
总结下三种方案对比大致如下:
- 架构上:vm 组件少,架构简单,不依赖第三方组件。Thanos 最少可部署三个基础组件 Sidecar、Store Gateway、Query,需要外部对象存储。Cortex 基础组件:Nginx/gateway、Distributor、Ingester、Query,依赖第三方组件如 Consul、Memcache 等。
- 数据高可用上:vm 通过 Prometheus RemoteApi 实时推送数据,只可能会丢失几秒钟的数据,Prometheus v2.8.0+ 会从 WAL 中同步数据,理论上不会丢失数据。vm[9] 和 cortex[10] 都支持副本,保证集群节点有问题时,数据的可用性。Thanos 数据存储在对象存储,依赖对象存储的高可用性。
- 功能兼容性丰富度:都兼容 Prometheus PromQL / 多租户等。除了 Prometheus remote_write 协议之外,还接受多种流行数据摄取协议中的数据 - InfluxDB、OpenTSDB、Graphite、CSV、JSON、本机二进制文件。
- 性能:vm 查询走本地磁盘相对高效,vmselect 聚合多节点副本,实现去重。Cortex 经过其他大厂生产验证性能略逊于 vm, 参考这里[11]。Thanos 查询短时间的数据时,性能高,因为数据在 Prometheus 实例上,查询长时间的数据时,因为数据块在对象存储,受网络环境影响比较大。
报警方案
- alertmanager 技术栈方案;
- n9e v5.3.0[12] 支持了 openfalcon 数据结构的上报,这样使用老 openfalcon 作为监控的平台,就可以把数据汇报给 n9e 存储到 prometheus,统一做监控报警。
与现有监控结合
- n9e 提供了基于 PromQL 方式数据源的即使和自定义 dashboard 功能,且支持多集群。
- grafana
- 有默认值,可从 template 中查看。自定义修改认证方式可参考这里[13];
- 直接修改 helm 配置 values 文件,可对 grafana 做一些定制化的部署;
部署高可用
多 Prometheus 副本,接后端 VictoriaMetric 聚合去重查询。
总结
根据上边的记录分析,我相信大家心里应该有了自己的选择。技术选型除了目标技术栈本身,还需要根据自己业务架构和团队人员技术栈等其他因素综合考虑,所以选用符合自己业务架构和团队的便是最好的技术选型。
参考资料
[1]Heapster: https://github.com/kubernetes-retired/heapster
[2]Heapster: https://github.com/kubernetes-retired/heapster
[3]v5版本: https://n9e.github.io/
[4]kube-prometheus: https://github.com/prometheus-operator/kube-prometheus
[5]Thanos: https://thanos.io/v0.24/thanos/getting-started.md/
[6]Cortex: https://cortexmetrics.io/
[7]VictoriaMetric: https://docs.victoriametrics.com/
[8]只支持写,不支持读: https://prometheus.io/docs/operating/integrations/#remote-endpoints-and-storage
[9]vm: https://docs.victoriametrics.com/Cluster-VictoriaMetrics.html#replication-and-data-safety
[10]cortex: https://github.com/cortexproject/cortex/blob/fe56f1420099aa1bf1ce09316c186e05bddee879/docs/architecture.md#hashing
[11]这里: https://docs.victoriametrics.com/CaseStudies.html
[12]v5.3.0: https://github.com/didi/nightingale/releases/tag/v5.3.0
[13]这里: https://www.ancii.com/at6lje4j8/
[14]Prometheus Operator: https://prometheus-operator.dev/docs/prologue/introduction/
[15]Rancher 监控和报警: https://rancher.com/docs/rancher/v2.6/en/monitoring-alerting/
[16]Kubernetes主机和容器的监控方案: https://www.kubernetes.org.cn/2432.html
[17]云原生监控神器Prometheus: https://docs.prometheus.cool/
[18]高可用 Prometheus:Thanos 实践: http://www.xuyasong.com/?p=1925
[19]使用Victoriametrics作为prometheus高可用性长期存储方案-中文版: https://blog.csdn.net/weixin_26711867/article/details/108971299
[20]使用Victoriametrics作为prometheus高可用性长期存储方案-英文版: https://medium.com/miro-engineering/prometheus-high-availability-and-fault-tolerance-strategy-long-term-storage-with-victoriametrics-82f6f3f0409e
[21]thanos vs victoria: https://blog.csdn.net/alex_yangchuansheng/article/details/108271368
[22]victoriaMetric 存储机制: https://zhuanlan.zhihu.com/p/368912946