EggJS 渐进式开发
♀️编编拎重点:本文是蚂蚁集团前端工程师天猪的分享,带你了解 EggJS 的设计理念,以及在实际开发过程中,一段可复用代码是如何有生命力地持续演进,欢迎享用。
前言
本文摘抄自年前的一个分享的开场铺垫,主要介绍了 EggJS 的设计理念,并用一个完整的例子去阐述在实际开发过程中,一段可复用代码是如何有生命力地持续演进:应用内的一段逻辑 → 在应用内孵化插件雏形 → 独立插件 → 内置到自定义框架 。虽然有点老生常谈,但它是 EggJS 设计理念中核心的核心,最近在跟几个大厂沟通 Egg 3.0 的共建,需要基于此内容达成讨论的基础,因此有了本文。
应用
先通过一个简单的演示,快速了解下 EggJS 的应用开发侧体感是怎么样的。我们要实现一个简单的聚合接口,根据请求参数传递的 org 查询对应的 GitHub 组织的仓库列表。
初始化
先通过脚手架来初始化:
$ npm init egg --type=simple showcase
./showcase
├── app
│ ├── controller (控制器)
│ │ └── home.js
│ ├── serivce (业务逻辑)
│ │ └── github.js
│ └── router.js (路由)
├── config (配置)
│ ├── config.default.js
│ ├── config.prod.js
│ └── plugin.js
├── test (单测)
├── README.md
└── package.json路由及控制器
编写 Controller 控制器逻辑:
// app/controller/home.js
const { Controller } = require('egg');
class HomeController extends Controller {
async listReposByOrg() {
// 获取请求参数
const org = this.ctx.query.org || 'eggjs';
// 调用业务逻辑
const result = await this.ctx.service.github.listReposByOrg(org);
// 渲染数据
this.ctx.body = result;
}
}
module.exports = HomeController;编写路由映射:
// app/router.js
module.exports = app => {
// 注册路由
app.router.get('/api/repos', app.controller.home.listReposByOrg);
}业务逻辑
编写 Service 业务逻辑:
// app/service/github.js
const { Service } = require('egg');
class GithubService extends Service {
async listReposByOrg(org) {
const { ctx, config } = this;
// 读取配置
const { endpoint, pageCount } = config.github;
// 请求后端 API
const repos = await ctx.curl(`${endpoint}/orgs/${org}/repos`, {
data: { per_page: pageCount },
dataType: 'json',
});
// 响应数据
if (repos.status !== 200) return [];
return repos.data.reduce((arr, repo) => {
arr.push(repo.name);
return arr;
}, []);
}
}
module.exports = GithubService;配置文件
编写配置文件,这里我们有 2 个文件,一个是默认值,一个是正式环境的配置,会根据运行环境自动合并。
// config/config.default.js
exports.github = {
endpoint: 'https://api.github.com',
pageCount: 5,
};
// config/config.prod.js
exports.github = {
pageCount: 50, // 配置自动合并,线上环境
};运行效果
一般业务开发还要有对应的单元测试,非常重要,在 EggJS 里面写起来也非常的简单没有负担。不过限于篇幅,本文暂时跳过,直接运行来体验。
$ npm run dev
[master] egg started on http://127.0.0.1:7001 (2216ms)
$ curl localhost:7001/api/repos
["eslint-config-egg","egg","egg-bin","egg-mock","egg-logger"]
$ curl localhost:7001/api/repos\?org=vuejs
["vue","vue-router","vuejs.org","vue-touch","Discussion"]小结
- 我们实现了一个典型的 BFF 聚合场景:
解析请求参数 → 调用后端 API → 响应数据。 - 典型的 MVC 目录规范,Rails-like 的研发体验。
- 内置的多环境配置能力、日志能力、错误处理能力、常见的 Web 能力等等。
- 注意:这是一个使用 EggJS 的上层框架来开发一个业务应用的体验。

插件
插件是什么?
Middleware 的局限性:
- 定位是拦截用户请求,并在它前后做一些事情。
- 但实际情况下,很多功能与请求无关,如定时任务,初始化,Application 扩展。
- 功能之间的顺序不能简单的交给开发者,需要统一编排,管理。
Egg 插件:
- 插件是 Egg 的核心能力之一,是围绕某个功能组织的扩展集合,它跟应用目录结构几乎一样。
- 插件是能力沉淀的有效手段,让你团队的应用生态可以持续进化,它也是差异化的基础。
使用插件
回到我们的示例应用,我们希望把查询结果渲染成页面,此时则需要模板渲染能力。
先挑选插件并安装:
$ npm i --save egg-view-nunjucks
挂载插件以及配置:
// config/plugin.js
exports.nunjucks = {
enable: true,
package: 'egg-view-nunjucks',
};
// config/config.default.js
exports.view = {
defaultViewEngine: 'nunjucks',
mapping: {
'.tpl': 'nunjucks',
},
};修改控制器逻辑:
class HomeController extends Controller {
async listReposByOrg() {
const org = this.ctx.query.org || 'eggjs';
const result = await this.ctx.service.github.listReposByOrg(org);
// 渲染模板
await this.ctx.render('repos.tpl', { org, result });
}
}编写模板:
<!-- app/view/repos.tpl -->
<h1>{{ org }}</h1>
<ul>
{% for item in result %}
<li>{{ item }}</li>
{% endfor %}
</ul>打开浏览器访问,完美。
渐进式开发 - 插件雏形在 EggJS 里面,我们有一套渐进式的演进模式: 可复用代码片段 → 应用内部的插件雏形 → 独立插件 → 下沉到框架。
接着我们上面的 showcase,我们很容易意识到 GitHub 相关逻辑是可以复用的。
第一步我们把这部分的代码挪个窝,以便孵化:
$ ls
├── app
│ ├── controller
│ └── router.js
├── config
│ ├── config.default.js
│ └── plugin.js (插件配置)
│
├── plugin
│ └── egg-github (孵化插件)
│
├── test
├── README.md
└── package.json
$ ls ./plugin/egg-github
├── app
│ └── serivce
│ └── github.js
├── config
│ ├── config.default.js
│ └── config.prod.js
├── test
├── README.md
└── package.json如上,我们把 GitHub 相关的 Service 和 Config 挪到了一个独立目录。
然后再修改下应用的插件配置,通过相对路径来挂载插件:
// config/plugin.js
exports.github = {
enable: true,
path: path.join(__dirname, '../plugin/egg-github'),
};渐进式开发 - 独立插件 再迭代一段时间后,我们发现这个插件已经具备了基础的功能,此时就可以把它独立出来,让其他应用也能试用:
- 把
plugin/egg-github目录剪切出去,独立发布为一个 npm 包。 - 应用安装对应的 npm 依赖。
- 修改应用的插件配置,挂载该 npm 插件。
$ npm i --save egg-github
$ more config/plugin.js
exports.github = {
enable: true,
package: 'egg-github',
};小结
- 应用侧也可以编写对应的 config 来覆盖插件提供的配置值。
- 通过观察上面的操作,我们看到了一个插件的孵化之旅。
- 可以发现,整个演进过程,对应用来说,几乎是无痛的,仅仅是一两行配置的变化。
框架
框架是什么?
当你的团队所维护的应用数超过一定数量时,你是否会遇到:
- 每新建一个应用,都需要重复折腾插件和默认配置,而脚手架只能解决首次初始化问题。
- 修改一个默认配置后,希望所有应用都能更新。
- 希望给所有应用都新增一个插件。
Egg 的另一个核心能力就是上层框架机制,也是 Egg 的初心:帮助架构师孵化出适合特定团队业务场景的上层框架。
- 框架 是对适合 特定业务场景 的 最佳实践 的约束和封装。
- 便于统一团队的开发模式,一致的开发体验,一次性学习成本,也便于统一管控、升级、维护。
- 支持多层继承。
渐进式开发 - 自定义框架
继续我们的渐进式之旅,当我们沉淀出几个插件后,可以考虑把它们抽离出来,封装为一个上层框架,这里就叫它 yadan 吧。
- 框架跟应用的目录结构也几乎一样, 并支持多层继承。
- 应用逻辑下沉到框架,几乎无痛。

渐进式开发 - 自定义规范
除了常规的扩展外,在实际业务开发中,我们往往需要为团队定制一些新的目录规范。
譬如我们想增加一个约定:所有放置在 app/utils 目录下的文件,都会被自动挂载为 app.utils.*。
非常简单,只需一个配置:
// config/config.default.js
exports.customLoader = {
utils: {
directory: 'app/utils',
inject: 'app',
},
};差异化定制
类似于云原生里面的 no-vender-lock 机制,在不同场景下,底层的实现可能不一样,但我们希望在应用层的用法规范是一致的。
譬如:
- 模板渲染可以是 nunjucks 或 ejs,但应用层只需知道
ctx.render(),如 egg-view-nunjucks 和 egg-view-ejs 都是基于 egg-view 规范。 - 用户模型不一样,但用法都类似只需
ctx.user,如 egg-passport-* 系列插件。
我们可以在框架里面集成特定的插件,来实现针对特定团队场景的约定的差异化定制,又能减少用户的理解成本。
小结
详细操作也可以参见《如何为团队定制自己的 Node.js 框架?(基于 EggJS)》[1]
以上是自定义框架的演进过程,可以发现,对应用来说,几乎是无痛的,仅仅是一两行配置的变化。
每个企业内部,应该有一层面向企业开发者的 EggJS 上层框架,哪怕它很薄,那也是有价值的。
在阿里内部,我们甚至还有多层:
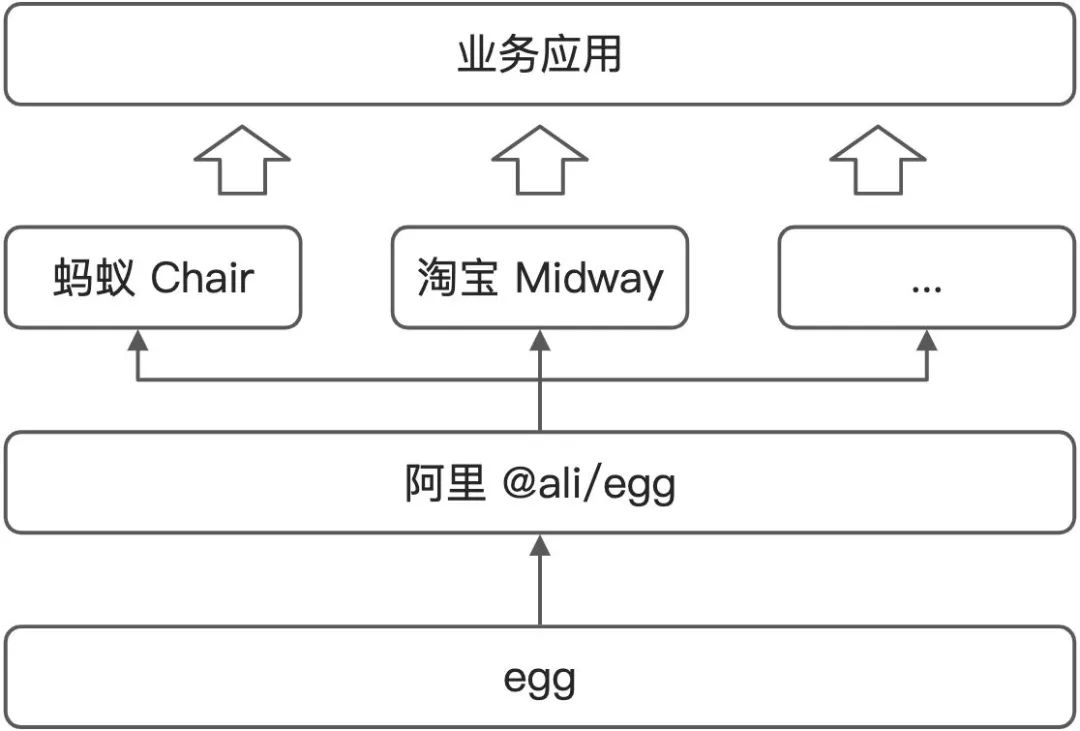
举个例子,我个人在框架这块其实有几个角色:
- Egg 框架的核心开发者:维护的 egg-core 是框架的框架,最核心的那点,它的目标用户是社区的高阶团队架构师。Egg 则是一个适合那个时代的 Web 场景的常见能力的上层框架,它的目标用户是社区的一般用户,开箱即用。
- 阿里泛集团的 Node.js 基础设施维护者:维护的 @ali/egg 框架 继承于 Egg,它定义了整个阿里巴巴经济体最基础的那部分能力合集,譬如我们早期的 rpc 能力,阿里特有的安全能力等等。它的目标用户是阿里各 BU 的前端架构师,帮他们来搭建各自的上层框架。
- 蚂蚁集团 Node.js 基础设施维护者:维护的 Chair 框架 继承于 @ali/egg,它定义了整个蚂蚁集团的能力合集,譬如我们的 antmq,sofarpc,drm,蚂蚁特有的 PaaS 等能力。目标用户是 蚂蚁的全栈工程师。
- 蚂蚁集团 Node.js Serverless 维护者:基于 Chair 之上,针对 Serverless 场景,定义了 中台、营销、小程序等等一些垂直场景,这里不同的点在于做减法,对 Chair 的很多能力进行简化(譬如原来给开发者 10 个配置,但现在在某场景下只开放 2 个),做了更强的约束(如中台场景账号体系集成 buc 体系,禁止开发者集成 alipay 登陆),和 PaaS 做了更强的配置代码化约定,等等。目标用户是 蚂蚁 的泛前端开发者。
最近也在字节、蔚来的同学在聊 Egg 3.0 共建时,也提到:> Egg 的定位一直都是『框架的框架』。
- 框架是多层的,每一层都有它的职责和定位,以及对应的目标用户(可能是架构师,也可能是一线用户)
- 面向架构师,我们需要给他提供灵活的定制能力。面向一线用户,我们需要给他的反而是强约束的开箱即用的能力。
我们在座的每个人,同时都兼顾好几个角色,要站在不同的角色的立场去思考它对应的那一层框架的边界定位,尽量不要混着想。站在每一层角色的立场,去考虑自己封装的这一层框架,面向是怎么样的用户,提供怎么样的能力以及约束。
写在最后
以上就是基于 EggJS 的完整的渐进式开发:应用内的一段逻辑 → 在应用内孵化插件雏形 → 独立插件 → 内置到自定义框架 整个演进过程,对应用来说,几乎是无痛的,同时我们的逻辑是有生命力的,可以不断的低成本下沉,完成闭环。
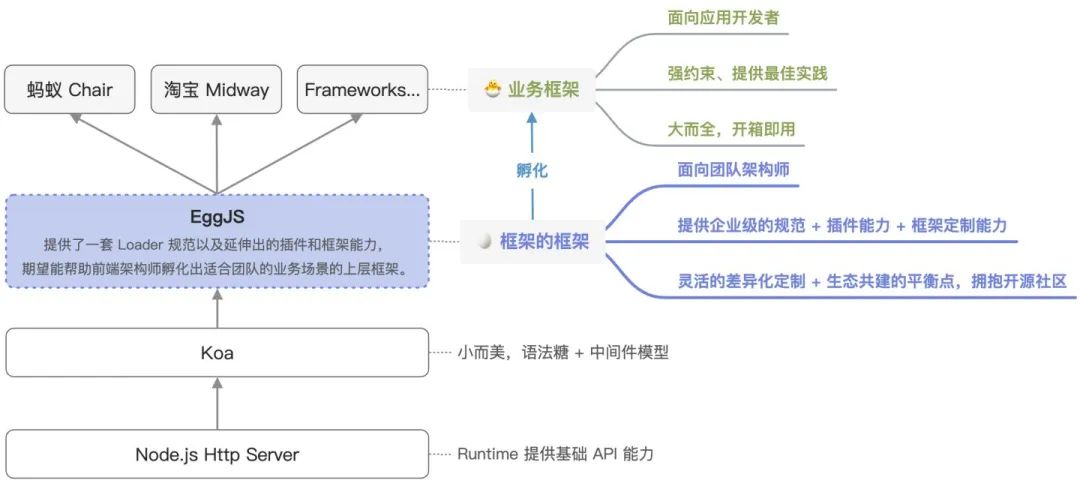
再回顾下我们的选择:
课题:企业级大规模应用场景下,如何既能在尽可能共建和不重复造轮子的情况下,保证灵活的差异化定制,并可持续治理及维护?
✅ 我们的选择是:做框架的框架,EggJS 提供了一套 Loader 规范以及延伸出的插件和框架能力,期望能帮助前端架构师孵化出适合团队的业务场景的上层框架。
综上,当下实际承载了我们设计思路的,是 egg 下层的的 egg-core 这个库,而不是 egg 这个更偏开箱即用的简单框架的库,在 egg 3.0 里面,我们会把 egg-core 做的更极致,更符合它的初心。
[1] https://zhuanlan.zhihu.com/p/154643011