一文读懂eBPF|即时编译(JIT)实现原理
在《[eBPF实现原理] 》一文中,我们介绍了 eBPF 的实现原理,这篇文章我们主要介绍 eBPF 运行加速器 JIT(Just In Time)的实现原理。
什么是 JIT
JIT(Just In Time)的中文意思是 即时编译,主要为了解决虚拟机运行中间码时效率不高的问题。
在《[eBPF实现原理] 》一文中,我们介绍过 eBPF 是使用虚拟机来执行 eBPF 字节码的。但执行字节码是一个模拟 CPU 执行机器码的过程,所以比执行机器码的效率低很多。
我们来看看中间码与机器码执行的区别,如下图所示:

(图一 机器码执行过程)
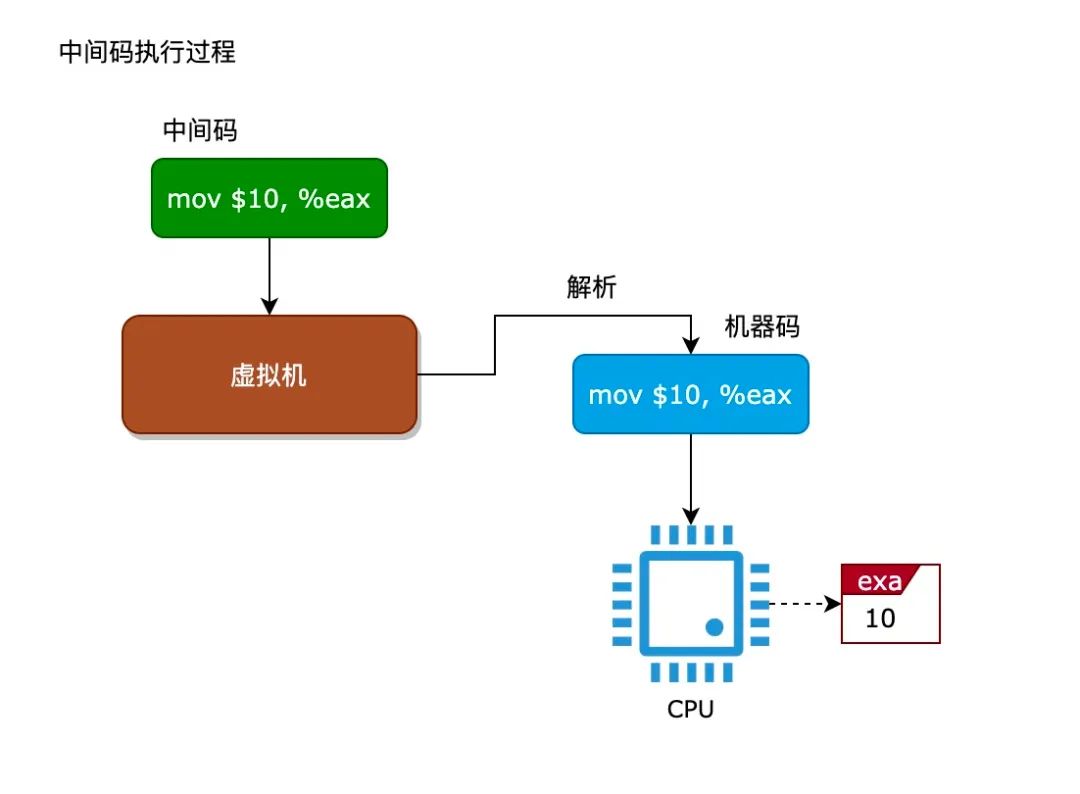
(图二 中间码执行过程)
从上图可以看出,执行中间码时,虚拟机需要将中间码解析成机器码来执行,而这个解析的过程就需要消耗更多的 CPU 时间。
eBPF 使用 JIT 技术来解决执行中间码效率不高的问题。JIT 技术就是在执行中间码前,先把中间码编译成对应的机器码,然后缓存起来,运行时直接通过执行机器码即可。这样就解决了每次执行中间码都需要解析的过程,如下图所示:
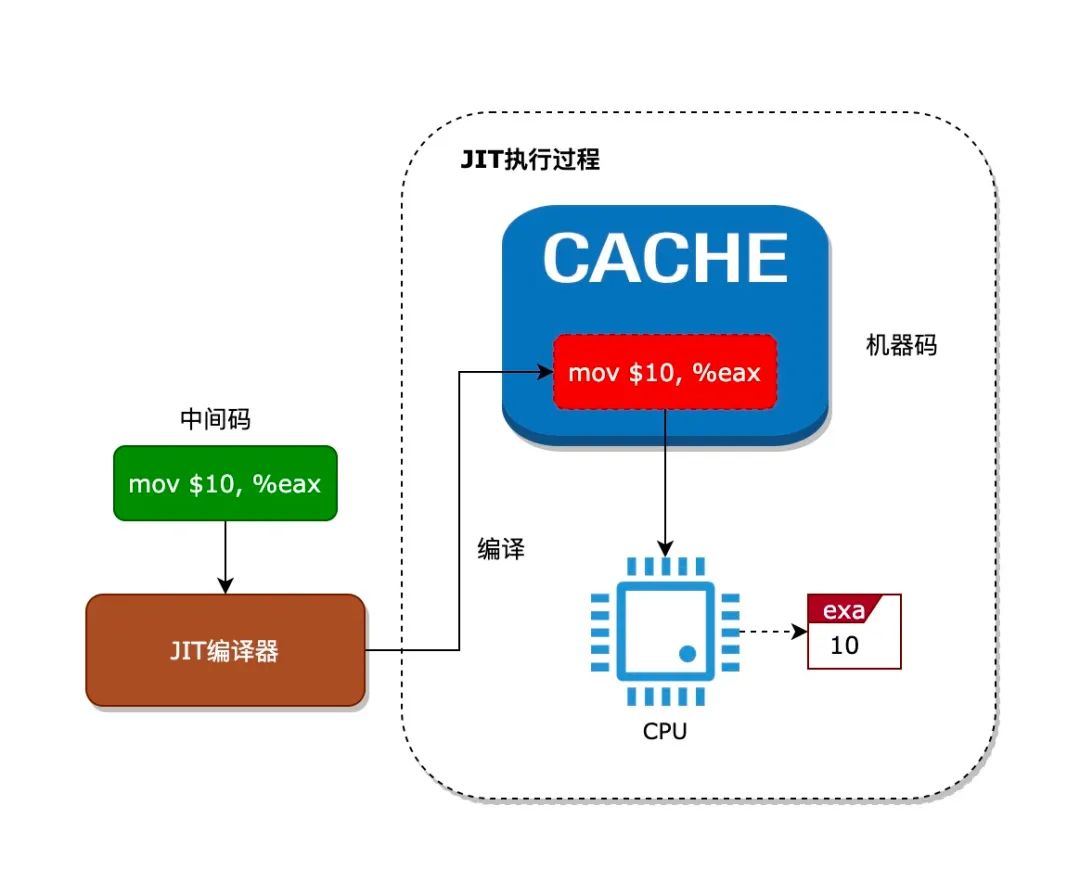
(图三 JIT执行过程)
eBPF JIT 实现原理
当 eBPF 字节码被加载到内核时,内核会根据是否开启了 JIT 功能选项,来决定是否将 eBPF 字节码编译成机器码。
由于不同架构 CPU 的指令集并不相同(也就是运行的机器码不相同),所以对于不同架构的 CPU,把 eBPF 字节码编译成机器码的过程并不相同。
本文以
x86架构的 CPU 进行分析,使用的内核版本是 3.18.1。
我们来看看内核是怎么将 eBPF 字节码编译成机器码的。
内核是通过 bpf_prog_load() 函数来加载 eBPF 字节码,如下所示:
static int bpf_prog_load(union bpf_attr *attr)
{
...
bpf_prog_select_runtime(prog);
...
}其中,bpf_prog_load() 会调用 bpf_prog_select_runtime() 函数来为 eBPF 选择一个运行时。
什么是 eBPF 的运行时?说白了就是使用虚拟机运行还是使用 JIT 运行。我们来看看 bpf_prog_select_runtime() 函数的实现:
void bpf_prog_select_runtime(struct bpf_prog *fp)
{
fp->bpf_func = (void *) __bpf_prog_run;
bpf_int_jit_compile(fp);
bpf_prog_lock_ro(fp);
}bpf_prog 结构用来保存 eBPF 程序的信息,其 bpf_func 字段用于指向 eBPF 字节码的执行函数。
bpf_prog_select_runtime() 函数首先会将其设置为 __bpf_prog_run() 函数,表示使用 __bpf_prog_run() 函数来执行 eBPF 字节码。
接着 bpf_prog_select_runtime() 函数会调用 bpf_int_jit_compile() 函数来判断是否需要将 eBPF 字节码编译成机器码,bpf_int_jit_compile() 函数的实现如下(x86 架构):
void bpf_int_jit_compile(struct bpf_prog *prog)
{
...
struct jit_context ctx = {};
u8 *image = NULL; // 用于保存 eBPF 字节码编译后的机器码
...
// 如果没有开启 JIT 功能, 那么不需要将 eBPF 字节码编译成机器码
if (!bpf_jit_enable)
return;
...
for (pass = 0; pass < 10; pass++) {
// 将 eBPF 字节码编译成本地机器码
proglen = do_jit(prog, addrs, image, oldproglen, &ctx);
...
}
if (bpf_jit_enable > 1) // 打印 eBPF 字节码编译后的机器码
bpf_jit_dump(prog->len, proglen, 0, image);
// 如果成功将 eBPF 字节码编译成本地机器码
if (image) {
...
// 那么将 eBPF 字节码执行函数设置成编译后的机器码
prog->bpf_func = (void *)image;
prog->jited = true;
}
...
}bpf_int_jit_compile() 函数首先会判断内核是否打开了 eBPF 的 JIT 功能(也就是 bpf_jit_enable 全局变量是否大于 0),如果没有开启,那么内核将不会对 eBPF 字节码进行 JIT 处理。
如果打开了 JIT 功能,那么 bpf_int_jit_compile() 函数将会调用 do_jit() 函数把 eBPF 字节码编译成本地机器码,然后将 bpf_prog 结构的 bpf_func 字段设置成编译后的字节码。
这样,当内核调用 bpf_func 字段指向的函数时,就能直接执行 eBPF 字节码编译后的机器码。
eBPF 字节码编译过程
我们来分析一下 do_jit() 函数的实现,如下所示(do_jit() 函数的实现有点儿复杂,所以这里只对其进行大概分析):
static int
do_jit(struct bpf_prog *bpf_prog, int *addrs, u8 *image,
int oldproglen, struct jit_context *ctx)
{
struct bpf_insn *insn = bpf_prog->insnsi;
int insn_cnt = bpf_prog->len;
bool seen_ld_abs = ctx->seen_ld_abs | (oldproglen == 0);
u8 temp[BPF_MAX_INSN_SIZE + BPF_INSN_SAFETY];
int i;
int proglen = 0;
u8 *prog = temp;
// 计算栈空间大小
int stacksize = MAX_BPF_STACK +
32 /* space for rbx, r13, r14, r15 */ +
8 /* space for skb_copy_bits() buffer */;
EMIT1(0x55); // 保存 %rbp 寄存器的值到栈:push %rbp
EMIT3(0x48, 0x89, 0xE5); // 把 %rsp 寄存器的值保存到 %rbp 寄存器中:mov %rbp, %rsp
// 申请栈空间指令:sub %rsp, stacksize
EMIT3_off32(0x48, 0x81, 0xEC, stacksize);
// 保存 %rbx 寄存器的值到栈
EMIT3_off32(0x48, 0x89, 0x9D, -stacksize);
// 保存 %r13 寄存器的值到栈
EMIT3_off32(0x4C, 0x89, 0xAD, -stacksize + 8);
// 保存 %r14 寄存器的值到栈
EMIT3_off32(0x4C, 0x89, 0xB5, -stacksize + 16);
// 保存 %r15 寄存器的值到栈
EMIT3_off32(0x4C, 0x89, 0xBD, -stacksize + 24);
EMIT2(0x31, 0xc0); /* 对 %eax 寄存器清零,相对于:xor %eax, %eax */
EMIT3(0x4D, 0x31, 0xED); /* 对 %r13 寄存器清零,相对于:xor %r13, %r13 */
...
// 遍历 eBPF 字节码,开始将 eBPF 字节码编译成本地机器码
for (i = 0; i < insn_cnt; i++, insn++) {
...
switch (insn->code) { // 通过一个 switch 语句来对 eBPF 字节码进行不同的编译过程
...
/* 编译:mov dst, src */
case BPF_ALU64 | BPF_MOV | BPF_X:
EMIT_mov(dst_reg, src_reg);
break;
...
}
ilen = prog - temp;
...
if (image) {
...
memcpy(image + proglen, temp, ilen);
}
proglen += ilen;
addrs[i] = proglen;
prog = temp;
}
return proglen;
}由于 eBPF 程序会被编译成一个函数调用,所以 do_jit() 函数首先会构建一个函数调用的环境,如:申请函数栈空间,把一些寄存器压栈等操作。
然后 do_jit() 函数会遍历 eBPF 字节码,并且对其进行编译成本地机器码。
例如对于 eBPF 的
BPF_ALU64|BPF_MOV|BPF_X字节码,内核会将其编译成mov %目标寄存器, %源寄存器指令的机器码,其他 eBPF 字节码的编译过程类似。
所以,当内核没有开启 JIT 功能时,将会使用 __bpf_prog_run() 函数来执行 eBPF 字节码。
而当内核开启了 JIT 功能时,内核首先会将 eBPF 字节码编译成本地机器码,然后直接执行机器码即可。
这样就加速了 eBPF 程序的执行效率。