一文搞懂Netty发送数据全流程 | 你想知道的细节全在这里
本系列Netty源码解析文章基于 4.1.56.Final版本
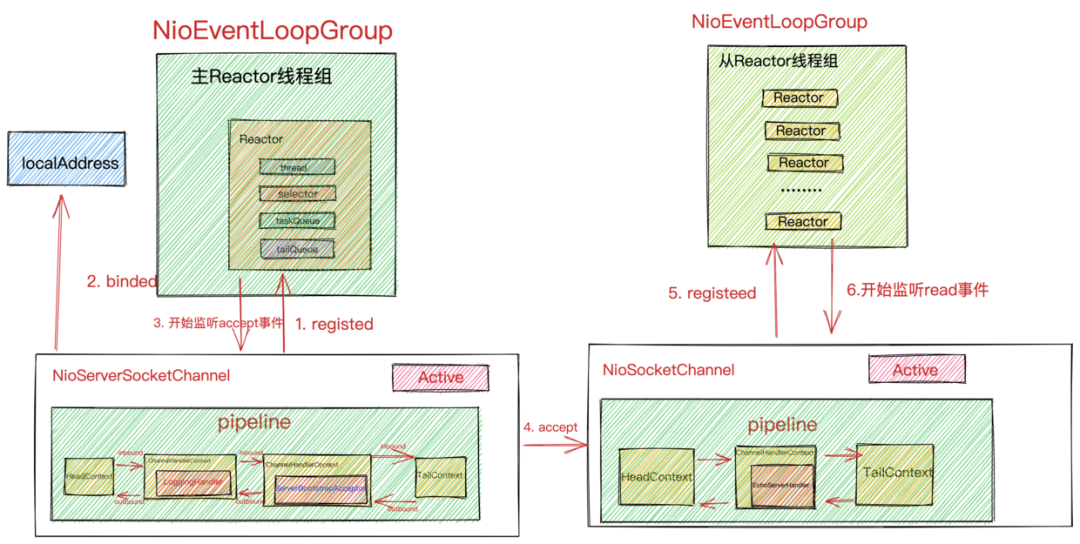
在[《Netty如何高效接收网络数据》] 一文中,我们介绍了 Netty 的 SubReactor 处理网络数据读取的完整过程,当 Netty 为我们读取了网络请求数据,并且我们在自己的业务线程中完成了业务处理后,就需要将业务处理结果返回给客户端了,那么本文我们就来介绍下 SubReactor 如何处理网络数据发送的整个过程。
我们都知道 Netty 是一款高性能的异步事件驱动的网络通讯框架,既然是网络通讯框架那么它主要做的事情就是:
- 接收客户端连接。
- 读取连接上的网络请求数据。
- 向连接发送网络响应数据。
前边系列文章在介绍[Netty的启动] 以及[接收连接] 的过程中,我们只看到 OP_ACCEPT 事件以及 OP_READ 事件的注册,并未看到 OP_WRITE 事件的注册。
- 那么在什么情况下 Netty 才会向 SubReactor 去注册 OP_WRITE 事件呢?
- Netty 又是怎么对写操作做到异步处理的呢?
本文笔者将会为大家一一揭晓这些谜底。我们还是以之前的 EchoServer 为例进行说明。
@Sharable
public class EchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
//此处的msg就是Netty在read loop中从NioSocketChannel中读取到的ByteBuffer
ctx.write(msg);
}
} 我们将在[《Netty如何高效接收网络数据》] 一文中读取到的 ByteBuffer (这里的 Object msg),直接发送回给客户端,用这个简单的例子来揭开 Netty 如何发送数据的序幕~~
在实际开发中,我们首先要通过解码器将读取到的 ByteBuffer 解码转换为我们的业务 Request 类,然后在业务线程中做业务处理,在通过编码器对业务 Response 类编码为 ByteBuffer ,最后利用 ChannelHandlerContext ctx 的引用发送响应数据。
本文我们只聚焦 Netty 写数据的过程,对于 Netty 编解码相关的内容,笔者会在后续的文章中专门介绍。
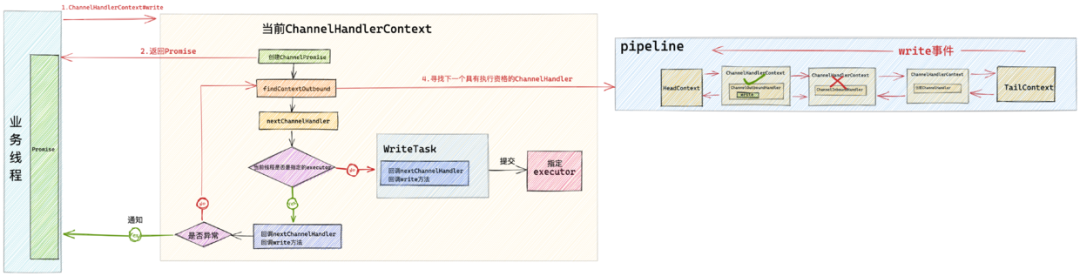
1 . ChannelHandlerContext
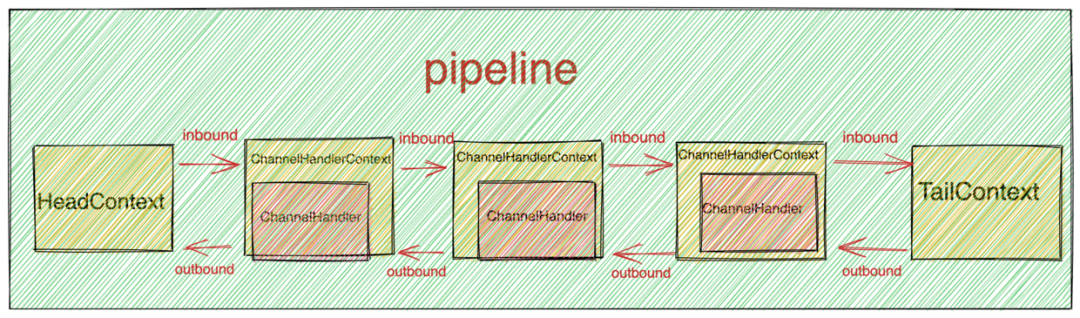
通过前面几篇文章的介绍,我们知道 Netty 会为每个 Channel 分配一个 pipeline ,pipeline 是一个双向链表的结构。Netty 中产生的 IO 异步事件会在这个 pipeline 中传播。
Netty 中的 IO 异步事件大体上分为两类:
- inbound事件:入站事件,比如前边介绍的 ChannelActive 事件, ChannelRead 事件,它们会从 pipeline 的头结点 HeadContext 开始一直向后传播。
- outbound事件:出站事件,比如本文中即将要介绍到的 write事件 以及 flush 事件,出站事件会从相反的方向从后往前传播直到 HeadContext 。最终会在 HeadContext 中完成出站事件的处理。
- 本例中用到的 channelHandlerContext.write() 会使 write 事件从当前 ChannelHandler 也就是这里的 EchoServerHandler 开始沿着 pipeline 向前传播。
- 而 channelHandlerContext.channel().write() 则会使 write 事件从 pipeline 的尾结点 TailContext 开始向前传播直到 HeadContext 。
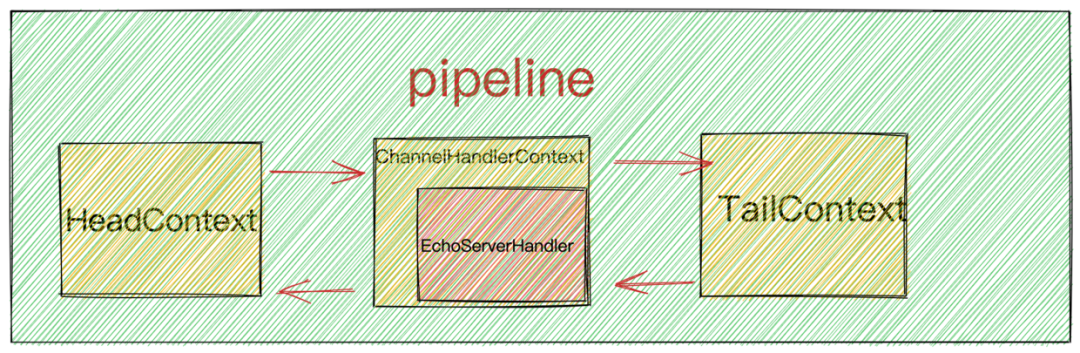
而 pipeline 这样一个双向链表数据结构中的类型正是 ChannelHandlerContext ,由 ChannelHandlerContext 包裹我们自定义的 IO 处理逻辑 ChannelHandler。
ChannelHandler 并不需要感知到它所处的 pipeline 中的上下文信息,只需要专心处理好 IO 逻辑即可,关于 pipeline 的上下文信息全部封装在 ChannelHandlerContext中。
ChannelHandler 在 Netty 中的作用只是负责处理 IO 逻辑,比如编码,解码。它并不会感知到它在 pipeline 中的位置,更不会感知和它相邻的两个 ChannelHandler。事实上 ChannelHandler也并不需要去关心这些,它唯一需要关注的就是处理所关心的异步事件
而 ChannelHandlerContext 中维护了 pipeline 这个双向链表中的 pre 以及 next 指针,这样可以方便的找到与其相邻的 ChannelHandler ,并可以过滤出一些符合执行条件的 ChannelHandler。正如它的命名一样, ChannelHandlerContext 正是起到了维护 ChannelHandler 上下文的一个作用。而 Netty 中的异步事件在 pipeline 中的传播靠的就是这个 ChannelHandlerContext 。
这样设计就使得 ChannelHandlerContext 和 ChannelHandler 的职责单一,各司其职,具有高度的可扩展性。
2 . write事件的传播
我们无论是在业务线程或者是在 SubReactor 线程中完成业务处理后,都需要通过 channelHandlerContext 的引用将 write事件在 pipeline 中进行传播。然后在 pipeline 中相应的 ChannelHandler 中监听 write 事件从而可以对 write事件进行自定义编排处理(比如我们常用的编码器),最终传播到 HeadContext 中执行发送数据的逻辑操作。
前边也提到 Netty 中有两个触发 write 事件传播的方法,它们的传播处理逻辑都是一样的,只不过它们在 pipeline 中的传播起点是不同的。
- channelHandlerContext.write() 方法会从当前 ChannelHandler 开始在 pipeline 中向前传播 write 事件直到 HeadContext。
- channelHandlerContext.channel().write() 方法则会从 pipeline 的尾结点 TailContext 开始在 pipeline 中向前传播 write 事件直到 HeadContext 。
在我们清楚了 write 事件的总体传播流程后,接下来就来看看在 write 事件传播的过程中Netty为我们作了些什么?这里我们以 channelHandlerContext.write() 方法为例说明。
3 . write方法发送数据
abstract class AbstractChannelHandlerContext implements ChannelHandlerContext, ResourceLeakHint {
@Override
public ChannelFuture write(Object msg) {
return write(msg, newPromise());
}
@Override
public ChannelFuture write(final Object msg, final ChannelPromise promise) {
write(msg, false, promise);
return promise;
}
}这里我们看到 Netty 的写操作是一个异步操作,当我们在业务线程中调用 channelHandlerContext.write() 后,Netty 会给我们返回一个 ChannelFuture,我们可以在这个 ChannelFutrue 中添加 ChannelFutureListener ,这样当 Netty 将我们要发送的数据发送到底层 Socket 中时,Netty 会通过 ChannelFutureListener 通知我们写入结果。
@Override
public void channelRead(final ChannelHandlerContext ctx, final Object msg) {
//此处的msg就是Netty在read loop中从NioSocketChannel中读取到的ByteBuffer
ChannelFuture future = ctx.write(msg);
future.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
Throwable cause = future.cause();
if (cause != null) {
处理异常情况
} else {
写入Socket成功后,Netty会通知到这里
}
}
});
}当异步事件在 pipeline 传播的过程中发生异常时,异步事件就会停止在 pipeline 中传播。所以我们在日常开发中,需要对写操作异常情况进行处理。
- 其中 inbound 类异步事件发生异常时,会触发exceptionCaught事件传播。exceptionCaught 事件本身也是一种 inbound 事件,传播方向会从当前发生异常的 ChannelHandler 开始一直向后传播直到 TailContext。
- 而 outbound 类异步事件发生异常时,则不会触发exceptionCaught事件传播。一般只是通知相关 ChannelFuture。但如果是 flush 事件在传播过程中发生异常,则会触发当前发生异常的 ChannelHandler 中 exceptionCaught 事件回调。
我们继续回归到写操作的主线上来~~~
private void write(Object msg, boolean flush, ChannelPromise promise) {
ObjectUtil.checkNotNull(msg, "msg");
................省略检查promise的有效性...............
//flush = true 表示channelHandler中调用的是writeAndFlush方法,这里需要找到pipeline中覆盖write或者flush方法的channelHandler
//flush = false 表示调用的是write方法,只需要找到pipeline中覆盖write方法的channelHandler
final AbstractChannelHandlerContext next = findContextOutbound(flush ?
(MASK_WRITE | MASK_FLUSH) : MASK_WRITE);
//用于检查内存泄露
final Object m = pipeline.touch(msg, next);
//获取pipeline中下一个要被执行的channelHandler的executor
EventExecutor executor = next.executor();
//确保OutBound事件由ChannelHandler指定的executor执行
if (executor.inEventLoop()) {
//如果当前线程正是channelHandler指定的executor则直接执行
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
//如果当前线程不是ChannelHandler指定的executor,则封装成异步任务提交给指定executor执行,注意这里的executor不一定是reactor线程。
final WriteTask task = WriteTask.newInstance(next, m, promise, flush);
if (!safeExecute(executor, task, promise, m, !flush)) {
task.cancel();
}
}
}write 事件要向前在 pipeline 中传播,就需要在 pipeline 上找到下一个具有执行资格的 ChannelHandler,因为位于当前 ChannelHandler 前边的可能是 ChannelInboundHandler 类型的也可能是 ChannelOutboundHandler 类型的 ChannelHandler ,或者有可能压根就不关心 write 事件的 ChannelHandler(没有实现write回调方法)。
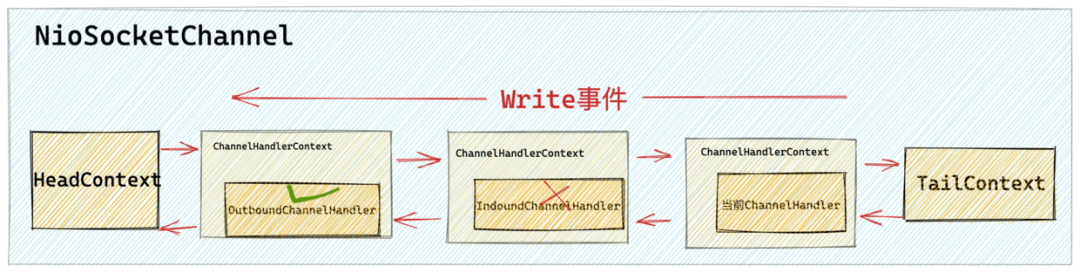
这里我们就需要通过 findContextOutbound 方法在当前 ChannelHandler 的前边找到 ChannelOutboundHandler 类型并且覆盖实现 write 回调方法的 ChannelHandler 作为下一个要执行的对象。
3.1 findContextOutbound
private AbstractChannelHandlerContext findContextOutbound(int mask) {
AbstractChannelHandlerContext ctx = this;
//获取当前ChannelHandler的executor
EventExecutor currentExecutor = executor();
do {
//获取前一个ChannelHandler
ctx = ctx.prev;
} while (skipContext(ctx, currentExecutor, mask, MASK_ONLY_OUTBOUND));
return ctx;
}
//判断前一个ChannelHandler是否具有响应Write事件的资格
private static boolean skipContext(
AbstractChannelHandlerContext ctx, EventExecutor currentExecutor, int mask, int onlyMask) {
return (ctx.executionMask & (onlyMask | mask)) == 0 ||
(ctx.executor() == currentExecutor && (ctx.executionMask & mask) == 0);
}findContextOutbound 方法接收的参数是一个掩码,这个掩码表示要向前查找具有什么样执行资格的 ChannelHandler。因为我们这里调用的是 ChannelHandlerContext 的 write 方法所以 flush = false,传递进来的掩码为 MASK_WRITE,表示我们要向前查找覆盖实现了 write 回调方法的 ChannelOutboundHandler。
3.1.1 掩码的巧妙应用
Netty 中将 ChannelHandler 覆盖实现的一些异步事件回调方法用 int 型的掩码来表示,这样我们就可以通过这个掩码来判断当前 ChannelHandler 具有什么样的执行资格。
final class ChannelHandlerMask {
....................省略......................
static final int MASK_CHANNEL_ACTIVE = 1 << 3;
static final int MASK_CHANNEL_READ = 1 << 5;
static final int MASK_CHANNEL_READ_COMPLETE = 1 << 6;
static final int MASK_WRITE = 1 << 15;
static final int MASK_FLUSH = 1 << 16;
//outbound事件掩码集合
static final int MASK_ONLY_OUTBOUND = MASK_BIND | MASK_CONNECT | MASK_DISCONNECT |
MASK_CLOSE | MASK_DEREGISTER | MASK_READ | MASK_WRITE | MASK_FLUSH;
....................省略......................
}在 ChannelHandler 被添加进 pipeline 的时候,Netty 会根据当前 ChannelHandler 的类型以及其覆盖实现的异步事件回调方法,通过 | 运算 向 ChannelHandlerContext#executionMask 字段添加该 ChannelHandler 的执行资格。
abstract class AbstractChannelHandlerContext implements ChannelHandlerContext, ResourceLeakHint {
//ChannelHandler执行资格掩码
private final int executionMask;
....................省略......................
}类似的掩码用法其实我们在前边的文章[?《一文聊透Netty核心引擎Reactor的运转架构》] 中也提到过,在 Channel 向对应的 Reactor 注册自己感兴趣的 IO 事件时,也是用到了一个 int 型的掩码 interestOps 来表示 Channel 感兴趣的 IO 事件集合。
@Override
protected void doBeginRead() throws Exception {
final SelectionKey selectionKey = this.selectionKey;
if (!selectionKey.isValid()) {
return;
}
readPending = true;
final int interestOps = selectionKey.interestOps();
/**
* 1:ServerSocketChannel 初始化时 readInterestOp设置的是OP_ACCEPT事件
* 2:SocketChannel 初始化时 readInterestOp设置的是OP_READ事件
* */
if ((interestOps & readInterestOp) == 0) {
//注册监听OP_ACCEPT或者OP_READ事件
selectionKey.interestOps(interestOps | readInterestOp);
}
}- 用 & 操作判断,某个事件是否在事件集合中:
(readyOps & SelectionKey.OP_CONNECT) != 0 - 用 | 操作向事件集合中添加事件:
interestOps | readInterestOp - 从事件集合中删除某个事件,是通过先将要删除事件取反 ~ ,然后在和事件集合做 & 操作:
ops &= ~SelectionKey.OP_CONNECT
这部分内容笔者会在下篇文章全面介绍 pipeline 的时候详细讲解,大家这里只需要知道这里的掩码就是表示一个执行资格的集合。当前 ChannelHandler 的执行资格存放在它的 ChannelHandlerContext 中的 executionMask 字段中。
3.1.2 向前查找具有执行资格的ChannelOutboundHandler
private AbstractChannelHandlerContext findContextOutbound(int mask) {
//当前ChannelHandler
AbstractChannelHandlerContext ctx = this;
//获取当前ChannelHandler的executor
EventExecutor currentExecutor = executor();
do {
//获取前一个ChannelHandler
ctx = ctx.prev;
} while (skipContext(ctx, currentExecutor, mask, MASK_ONLY_OUTBOUND));
return ctx;
}
//判断前一个ChannelHandler是否具有响应Write事件的资格
private static boolean skipContext(
AbstractChannelHandlerContext ctx, EventExecutor currentExecutor, int mask, int onlyMask) {
return (ctx.executionMask & (onlyMask | mask)) == 0 ||
(ctx.executor() == currentExecutor && (ctx.executionMask & mask) == 0);
}前边我们提到 ChannelHandlerContext 不仅封装了 ChannelHandler 的执行资格掩码还可以感知到当前 ChannelHandler 在 pipeline 中的位置,因为 ChannelHandlerContext 中维护了前驱指针 prev 以及后驱指针 next。
这里我们需要在 pipeline 中传播 write 事件,它是一种 outbound 事件,所以需要向前传播,这里通过 ChannelHandlerContext 的前驱指针 prev 拿到当前 ChannelHandler 在 pipeline 中的前一个节点。
ctx = ctx.prev;
通过 skipContext 方法判断前驱节点是否具有执行的资格。如果没有执行资格则跳过继续向前查找。如果具有执行资格则返回并响应 write 事件。
在 write 事件传播场景中,执行资格指的是前驱 ChannelHandler 是否是ChannelOutboundHandler 类型的,并且它是否覆盖实现了 write 事件回调方法。
public class EchoChannelHandler extends ChannelOutboundHandlerAdapter {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
super.write(ctx, msg, promise);
}
}3.1.3 skipContext
该方法主要用来判断当前 ChannelHandler 的前驱节点是否具有 mask 掩码中包含的事件响应资格。
方法参数中有两个比较重要的掩码:
int onlyMask:用来指定当前 ChannelHandler 需要符合的类型。其中MASK_ONLY_OUTBOUND 为 ChannelOutboundHandler 类型的掩码, MASK_ONLY_INBOUND 为 ChannelInboundHandler 类型的掩码。
final class ChannelHandlerMask {
//outbound事件的掩码集合
static final int MASK_ONLY_OUTBOUND = MASK_BIND | MASK_CONNECT | MASK_DISCONNECT |
MASK_CLOSE | MASK_DEREGISTER | MASK_READ | MASK_WRITE | MASK_FLUSH;
//inbound事件的掩码集合
static final int MASK_ONLY_INBOUND = MASK_CHANNEL_REGISTERED |
MASK_CHANNEL_UNREGISTERED | MASK_CHANNEL_ACTIVE | MASK_CHANNEL_INACTIVE | MASK_CHANNEL_READ |
MASK_CHANNEL_READ_COMPLETE | MASK_USER_EVENT_TRIGGERED | MASK_CHANNEL_WRITABILITY_CHANGED;
}比如本小节中我们是在介绍 write 事件的传播,那么就需要在当前ChannelHandler 前边首先是找到一个 ChannelOutboundHandler 类型的ChannelHandler。
ctx.executionMask & (onlyMask | mask)) == 0 用于判断前一个 ChannelHandler 是否为我们指定的 ChannelHandler 类型,在本小节中我们指定的是 onluMask = MASK_ONLY_OUTBOUND 即 ChannelOutboundHandler 类型。如果不是,这里就会直接跳过,继续在 pipeline 中向前查找。
int mask:用于指定前一个 ChannelHandler 需要实现的相关异步事件处理回调。在本小节中这里指定的是 MASK_WRITE ,即需要实现 write 回调方法。通过(ctx.executionMask & mask) == 0条件来判断前一个ChannelHandler 是否实现了 write 回调,如果没有实现这里就跳过,继续在 pipeline 中向前查找。
关于 skipContext 方法的详细介绍,笔者还会在下篇文章全面介绍 pipeline的时候再次进行介绍,这里大家只需要明白该方法的核心逻辑即可。
3.1.4 向前传播write事件
通过 findContextOutbound 方法我们在 pipeline 中找到了下一个具有执行资格的 ChannelHandler,这里指的是下一个 ChannelOutboundHandler 类型并且覆盖实现了 write 方法的 ChannelHandler。
Netty 紧接着会调用这个 nextChannelHandler 的 write 方法实现 write 事件在 pipeline 中的传播。
//获取下一个要被执行的channelHandler指定的executor
EventExecutor executor = next.executor();
//确保outbound事件的执行 是由 channelHandler指定的executor执行的
if (executor.inEventLoop()) {
//如果当前线程是指定的executor 则直接操作
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
//如果当前线程不是channelHandler指定的executor,则封装程异步任务 提交给指定的executor执行
final WriteTask task = WriteTask.newInstance(next, m, promise, flush);
if (!safeExecute(executor, task, promise, m, !flush)) {
task.cancel();
}
}在我们向 pipeline 添加 ChannelHandler 的时候可以通过ChannelPipeline#addLast(EventExecutorGroup,ChannelHandler......) 方法指定执行该 ChannelHandler 的executor。如果不特殊指定,那么执行该 ChannelHandler 的executor默认为该 Channel 绑定的 Reactor 线程。
执行 ChannelHandler 中异步事件回调方法的线程必须是 ChannelHandler 指定的executor。
所以这里首先我们需要获取在 findContextOutbound 方法查找出来的下一个符合执行条件的 ChannelHandler 指定的executor。
EventExecutor executor = next.executor()
并通过 executor.inEventLoop() 方法判断当前线程是否是该 ChannelHandler 指定的 executor。
如果是,那么我们直接在当前线程中执行 ChannelHandler 中的 write 方法。
如果不是,我们就需要将 ChannelHandler 对 write 事件的回调操作封装成异步任务 WriteTask 并提交给 ChannelHandler 指定的 executor 中,由 executor 负责执行。
这里需要注意的是这个 executor 并不一定是 channel 绑定的 reactor 线程。它可以是我们自定义的线程池,不过需要我们通过 ChannelPipeline#addLast 方法进行指定,如果我们不指定,默认情况下执行 ChannelHandler 的 executor 才是 channel 绑定的 reactor 线程。
这里Netty需要确保 outbound 事件是由 channelHandler 指定的 executor 执行的。
这里有些同学可能会有疑问,如果我们向pipieline添加ChannelHandler的时候,为每个ChannelHandler指定不同的executor时,Netty如果确保线程安全呢??
大家还记得pipeline中的结构吗?
outbound 事件在 pipeline 中的传播最终会传播到 HeadContext 中,之前的系列文章我们提到过,HeadContext 中封装了 Channel 的 Unsafe 类负责 Channel 底层的 IO 操作。而 HeadContext 指定的 executor 正是对应 channel 绑定的 reactor 线程。
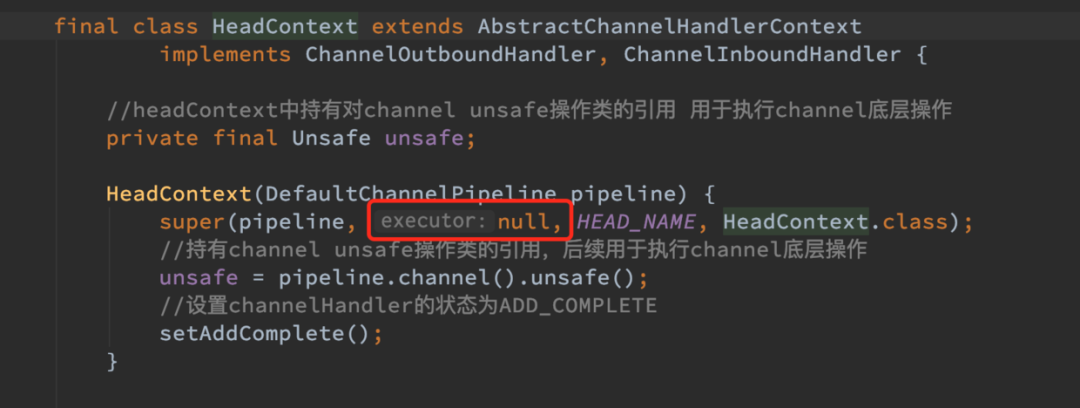
所以最终在 netty 内核中执行写操作的线程一定是 reactor 线程从而保证了线程安全性。
忘记这段内容的同学可以在回顾下[?《Reactor在Netty中的实现(创建篇)》] ,类似的套路我们在介绍 NioServerSocketChannel 进行 bind 绑定以及 register 注册的时候都介绍过,只不过这里将 executor 扩展到了自定义线程池的范围。
3.1.5 触发nextChannelHandler的write方法回调
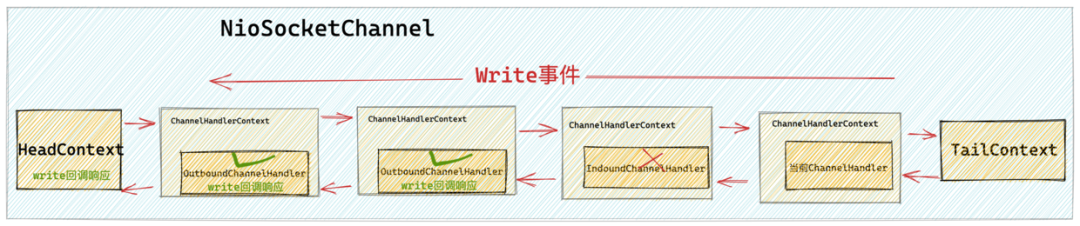
//如果当前线程是指定的executor 则直接操作
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}由于我们在示例 ChannelHandler 中调用的是 ChannelHandlerContext#write 方法,所以这里的 flush = false 。触发调用 nextChannelHandler 的 write 方法。
void invokeWrite(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
} else {
// 当前channelHandler虽然添加到pipeline中,但是并没有调用handlerAdded
// 所以不能调用当前channelHandler中的回调方法,只能继续向前传递write事件
write(msg, promise);
}
}这里首先需要通过 invokeHandler() 方法判断这个 nextChannelHandler 中的 handlerAdded 方法是否被回调过。因为 ChannelHandler 只有被正确的添加到对应的 ChannelHandlerContext 中并且准备好处理异步事件时, ChannelHandler#handlerAdded 方法才会被回调。
这一部分内容笔者会在下一篇文章中详细为大家介绍,这里大家只需要了解调用 invokeHandler() 方法的目的就是为了确定 ChannelHandler 是否被正确的初始化。
private boolean invokeHandler() {
// Store in local variable to reduce volatile reads.
int handlerState = this.handlerState;
return handlerState == ADD_COMPLETE || (!ordered && handlerState == ADD_PENDING);
}只有触发了 handlerAdded 回调,ChannelHandler 的状态才能变成 ADD_COMPLETE 。
如果 invokeHandler() 方法返回 false,那么我们就需要跳过这个nextChannelHandler,并调用 ChannelHandlerContext#write 方法继续向前传播 write 事件。
@Override
public ChannelFuture write(final Object msg, final ChannelPromise promise) {
//继续向前传播write事件,回到流程起点
write(msg, false, promise);
return promise;
}如果 invokeHandler() 返回 true ,说明这个 nextChannelHandler 已经在 pipeline 中被正确的初始化了,Netty 直接调用这个 ChannelHandler 的 write 方法,这样就实现了 write 事件从当前 ChannelHandler 传播到了nextChannelHandler。
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
//调用当前ChannelHandler中的write方法
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}这里我们看到在 write 事件的传播过程中如果发生异常,那么 write 事件就会停止在 pipeline 中传播,并通知注册的 ChannelFutureListener。
从本文示例的 pipeline 结构中我们可以看到,当在 EchoServerHandler 调用 ChannelHandlerContext#write 方法后,write 事件会在 pipeline 中向前传播到 HeadContext 中,而在 HeadContext 中才是 Netty 真正处理 write 事件的地方。
3.2 HeadContext
final class HeadContext extends AbstractChannelHandlerContext
implements ChannelOutboundHandler, ChannelInboundHandler {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) {
unsafe.write(msg, promise);
}
}write 事件最终会在 pipeline 中传播到 HeadContext 里并回调 HeadContext 的 write 方法。并在 write 回调中调用 channel 的 unsafe 类执行底层的 write 操作。这里正是 write 事件在 pipeline 中的传播终点。
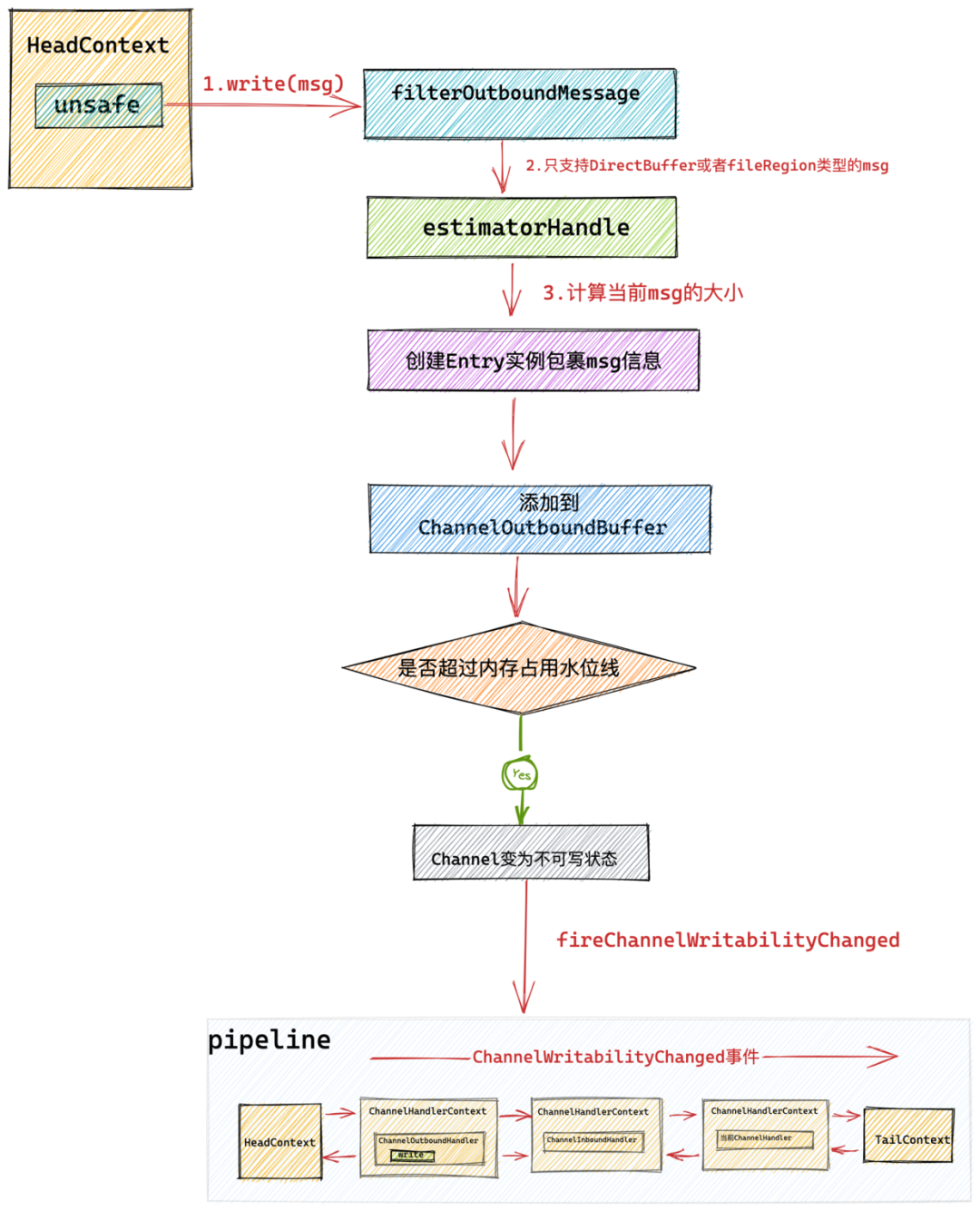
protected abstract class AbstractUnsafe implements Unsafe {
//待发送数据缓冲队列 Netty是全异步框架,所以这里需要一个缓冲队列来缓存用户需要发送的数据
private volatile ChannelOutboundBuffer outboundBuffer = new ChannelOutboundBuffer(AbstractChannel.this);
@Override
public final void write(Object msg, ChannelPromise promise) {
assertEventLoop();
//获取当前channel对应的待发送数据缓冲队列(支持用户异步写入的核心关键)
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
..........省略..................
int size;
try {
//过滤message类型 这里只会接受DirectBuffer或者fileRegion类型的msg
msg = filterOutboundMessage(msg);
//计算当前msg的大小
size = pipeline.estimatorHandle().size(msg);
if (size < 0) {
size = 0;
}
} catch (Throwable t) {
..........省略..................
}
//将msg 加入到Netty中的待写入数据缓冲队列ChannelOutboundBuffer中
outboundBuffer.addMessage(msg, size, promise);
}
}众所周知 Netty 是一个异步事件驱动的网络框架,在 Netty 中所有的 IO 操作全部都是异步的,当然也包括本小节介绍的 write 操作,为了保证异步执行 write 操作,Netty 定义了一个待发送数据缓冲队列 ChannelOutboundBuffer ,Netty 将这些用户需要发送的网络数据在写入到 Socket 之前,先放在 ChannelOutboundBuffer 中缓存。
每个客户端 NioSocketChannel 对应一个 ChannelOutboundBuffer 待发送数据缓冲队列
3.2.1 filterOutboundMessage
ChannelOutboundBuffer 只会接受 ByteBuffer 类型以及 FileRegion 类型的 msg 数据。
FileRegion 是Netty定义的用来通过零拷贝的方式网络传输文件数据。本文我们主要聚焦普通网络数据 ByteBuffer 的发送。
所以在将 msg 写入到 ChannelOutboundBuffer 之前,我们需要检查待写入 msg 的类型。确保是 ChannelOutboundBuffer 可接受的类型。
@Override
protected final Object filterOutboundMessage(Object msg) {
if (msg instanceof ByteBuf) {
ByteBuf buf = (ByteBuf) msg;
if (buf.isDirect()) {
return msg;
}
return newDirectBuffer(buf);
}
if (msg instanceof FileRegion) {
return msg;
}
throw new UnsupportedOperationException(
"unsupported message type: " + StringUtil.simpleClassName(msg) + EXPECTED_TYPES);
}在网络数据传输的过程中,Netty为了减少数据从 堆内内存 到 堆外内存 的拷贝以及缓解GC的压力,所以这里必须采用 DirectByteBuffer 使用堆外内存来存放网络发送数据。
3.2.2 estimatorHandle计算当前msg的大小
public class DefaultChannelPipeline implements ChannelPipeline {
//原子更新estimatorHandle字段
private static final AtomicReferenceFieldUpdater<DefaultChannelPipeline, MessageSizeEstimator.Handle> ESTIMATOR =
AtomicReferenceFieldUpdater.newUpdater(
DefaultChannelPipeline.class, MessageSizeEstimator.Handle.class, "estimatorHandle");
//计算要发送msg大小的handler
private volatile MessageSizeEstimator.Handle estimatorHandle;
final MessageSizeEstimator.Handle estimatorHandle() {
MessageSizeEstimator.Handle handle = estimatorHandle;
if (handle == null) {
handle = channel.config().getMessageSizeEstimator().newHandle();
if (!ESTIMATOR.compareAndSet(this, null, handle)) {
handle = estimatorHandle;
}
}
return handle;
}
}在 pipeline 中会有一个 estimatorHandle 专门用来计算待发送 ByteBuffer 的大小。这个 estimatorHandle 会在 pipeline 对应的 Channel 中的配置类创建的时候被初始化。
这里 estimatorHandle 的实际类型为DefaultMessageSizeEstimator#HandleImpl。
public final class DefaultMessageSizeEstimator implements MessageSizeEstimator {
private static final class HandleImpl implements Handle {
private final int unknownSize;
private HandleImpl(int unknownSize) {
this.unknownSize = unknownSize;
}
@Override
public int size(Object msg) {
if (msg instanceof ByteBuf) {
return ((ByteBuf) msg).readableBytes();
}
if (msg instanceof ByteBufHolder) {
return ((ByteBufHolder) msg).content().readableBytes();
}
if (msg instanceof FileRegion) {
return 0;
}
return unknownSize;
}
}这里我们看到 ByteBuffer 的大小即为 Buffer 中未读取的字节数 writerIndex - readerIndex 。
当我们验证了待写入数据 msg 的类型以及计算了 msg 的大小后,我们就可以通过 ChannelOutboundBuffer#addMessage方法将 msg 写入到ChannelOutboundBuffer(待发送数据缓冲队列)中。
write 事件处理的最终逻辑就是将待发送数据写入到 ChannelOutboundBuffer 中,下面我们就来看下这个 ChannelOutboundBuffer 内部结构到底是什么样子的?
3.3 ChannelOutboundBuffer
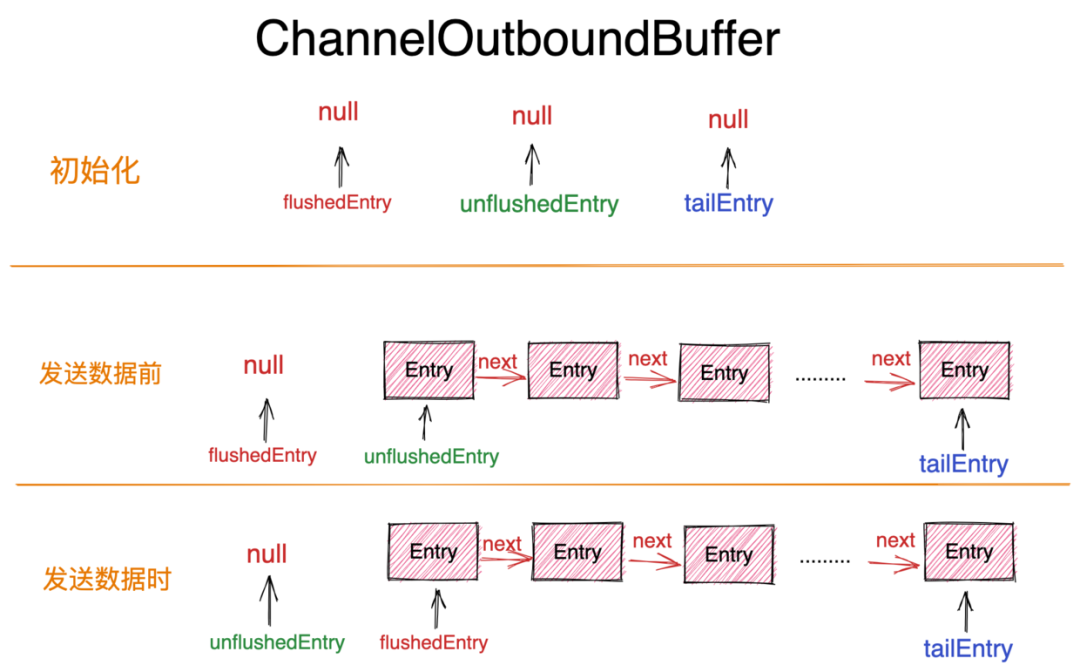
ChannelOutboundBuffer 其实是一个单链表结构的缓冲队列,链表中的节点类型为 Entry ,由于 ChannelOutboundBuffer 在 Netty 中的作用就是缓存应用程序待发送的网络数据,所以 Entry 中封装的就是待写入 Socket 中的网络发送数据相关的信息,以及 ChannelHandlerContext#write 方法中返回给用户的 ChannelPromise 。这样可以在数据写入Socket之后异步通知应用程序。
此外 ChannelOutboundBuffer 中还封装了三个重要的指针:
unflushedEntry:该指针指向 ChannelOutboundBuffer 中第一个待发送数据的 Entry。tailEntry:该指针指向 ChannelOutboundBuffer 中最后一个待发送数据的 Entry。通过 unflushedEntry 和 tailEntry 这两个指针,我们可以很方便的定位到待发送数据的 Entry 范围。flushedEntry:当我们通过 flush 操作需要将 ChannelOutboundBuffer 中缓存的待发送数据发送到 Socket 中时,flushedEntry 指针会指向 unflushedEntry 的位置,这样 flushedEntry 指针和 tailEntry 指针之间的 Entry 就是我们即将发送到 Socket 中的网络数据。
这三个指针在初始化的时候均为 null 。
3.3.1 Entry
Entry 作为 ChannelOutboundBuffer 链表结构中的节点元素类型,里边封装了待发送数据的各种信息,ChannelOutboundBuffer 其实就是对 Entry 结构的组织和操作。因此理解 Entry 结构是理解整个 ChannelOutboundBuffer 运作流程的基础。
下面我们就来看下 Entry 结构具体封装了哪些待发送数据的信息。
static final class Entry {
//Entry的对象池,用来创建和回收Entry对象
private static final ObjectPool<Entry> RECYCLER = ObjectPool.newPool(new ObjectCreator<Entry>() {
@Override
public Entry newObject(Handle<Entry> handle) {
return new Entry(handle);
}
});
//DefaultHandle用于回收对象
private final Handle<Entry> handle;
//ChannelOutboundBuffer下一个节点
Entry next;
//待发送数据
Object msg;
//msg 转换为 jdk nio 中的byteBuffer
ByteBuffer[] bufs;
ByteBuffer buf;
//异步write操作的future
ChannelPromise promise;
//已发送了多少
long progress;
//总共需要发送多少,不包含entry对象大小。
long total;
//pendingSize表示entry对象在堆中需要的内存总量 待发送数据大小 + entry对象本身在堆中占用内存大小(96)
int pendingSize;
//msg中包含了几个jdk nio bytebuffer
int count = -1;
//write操作是否被取消
boolean cancelled;
}我们看到Entry结构中一共有12个字段,其中1个静态字段和11个实例字段。
下面笔者就为大家介绍下这12个字段的含义及其作用,其中有些字段会在后面的场景中使用到,这里大家可能对有些字段理解起来比较模糊,不过没关系,这里能看懂多少是多少,不理解也没关系,这里介绍只是为了让大家混个眼熟,在后面流程的讲解中,笔者还会重新提到这些字段。
ObjectPool<Entry> RECYCLER:Entry 的对象池,负责创建管理 Entry 实例,由于 Netty 是一个网络框架,所以 IO 读写就成了它的核心操作,在一个支持高性能高吞吐的网络框架中,会有大量的 IO 读写操作,那么就会导致频繁的创建 Entry 对象。我们都知道,创建一个实例对象以及 GC 回收这些实例对象都是需要性能开销的,那么在大量频繁创建 Entry 对象的场景下,引入对象池来复用创建好的 Entry 对象实例可以抵消掉由频繁创建对象以及GC回收对象所带来的性能开销。
关于对象池的详细内容,感兴趣的同学可以回看下笔者的这篇文章[?《详解Recycler对象池的精妙设计与实现》]
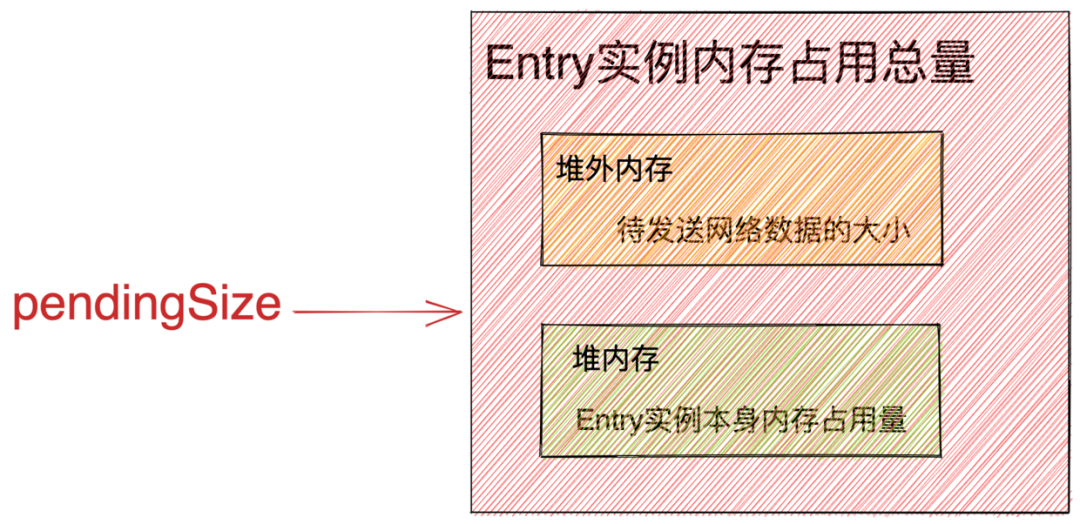
Handle<Entry> handle:默认实现类型为 DefaultHandle ,用于数据发送完毕后,对象池回收 Entry 对象。由对象池 RECYCLER 在创建 Entry 对象的时候传递进来。Entry next:ChannelOutboundBuffer 是一个单链表的结构,这里的 next 指针用于指向当前 Entry 节点的后继节点。Object msg:应用程序待发送的网络数据,这里 msg 的类型为 DirectByteBuffer 或者 FileRegion(用于通过零拷贝的方式网络传输文件)。ByteBuffer[] bufs:这里的 ByteBuffer 类型为 JDK NIO 原生的 ByteBuffer 类型,因为 Netty 最终发送数据是通过 JDK NIO 底层的 SocketChannel 进行发送,所以需要将 Netty 中实现的 ByteBuffer 类型转换为 JDK NIO ByteBuffer 类型。应用程序发送的 ByteBuffer 可能是一个也可能是多个,如果发送多个就用 ByteBuffer[] bufs 封装在 Entry 对象中,如果是一个就用 ByteBuffer buf 封装。int count:表示待发送数据 msg 中一共包含了多少个 ByteBuffer 需要发送。ChannelPromise promise:ChannelHandlerContext#write 异步写操作返回的 ChannelFuture。当 Netty 将待发送数据写入到 Socket 中时会通过这个 ChannelPromise 通知应用程序发送结果。long progress:表示当前的一个发送进度,已经发送了多少数据。long total:Entry中总共需要发送多少数据。注意:这个字段并不包含 Entry 对象的内存占用大小。只是表示待发送网络数据的大小。boolean cancelled:应用程序调用的 write 操作是否被取消。int pendingSize:表示待发送数据的内存占用总量。待发送数据在内存中的占用量分为两部分:- Entry对象中所封装的待发送网络数据大小。
- Entry对象本身在内存中的占用量。
3.3.2 pendingSize的作用
想象一下这样的一个场景,当由于网络拥塞或者 Netty 客户端负载很高导致网络数据的接收速度以及处理速度越来越慢,TCP 的滑动窗口不断缩小以减少网络数据的发送直到为 0,而 Netty 服务端却有大量频繁的写操作,不断的写入到 ChannelOutboundBuffer 中。
这样就导致了数据发送不出去但是 Netty 服务端又在不停的写数据,慢慢的就会撑爆 ChannelOutboundBuffer 导致OOM。这里主要指的是堆外内存的 OOM,因为 ChannelOutboundBuffer 中包裹的待发送数据全部存储在堆外内存中。
所以 Netty 就必须限制 ChannelOutboundBuffer 中的待发送数据的内存占用总量,不能让它无限增长。Netty 中定义了高低水位线用来表示 ChannelOutboundBuffer 中的待发送数据的内存占用量的上限和下限。注意:这里的内存既包括 JVM 堆内存占用也包括堆外内存占用。
- 当待发送数据的内存占用总量超过高水位线的时候,Netty 就会将 NioSocketChannel 的状态标记为不可写状态。否则就可能导致 OOM。
- 当待发送数据的内存占用总量低于低水位线的时候,Netty 会再次将 NioSocketChannel 的状态标记为可写状态。
那么我们用什么记录ChannelOutboundBuffer中的待发送数据的内存占用总量呢?
答案就是本小节要介绍的 pendingSize 字段。在谈到待发送数据的内存占用量时大部分同学普遍都会有一个误解就是只计算待发送数据的大小(msg中包含的字节数) 而忽略了 Entry 实例对象本身在内存中的占用量。
因为 Netty 会将待发送数据封装在 Entry 实例对象中,在大量频繁的写操作中会产生大量的 Entry 实例对象,所以 Entry 实例对象的内存占用是不可忽视的。
否则就会导致明明还没有到达高水位线,但是由于大量的 Entry 实例对象存在,从而发生OOM。
所以 pendingSize 的计算既要包含待发送数据的大小也要包含其 Entry 实例对象的内存占用大小,这样才能准确计算出 ChannelOutboundBuffer 中待发送数据的内存占用总量。
ChannelOutboundBuffer 中所有的 Entry 实例中的 pendingSize 之和就是待发送数据总的内存占用量。
public final class ChannelOutboundBuffer {
//ChannelOutboundBuffer中的待发送数据的内存占用总量
private volatile long totalPendingSize;
}3.3.3 高低水位线
上小节提到 Netty 为了防止 ChannelOutboundBuffer 中的待发送数据内存占用无限制的增长从而导致 OOM ,所以引入了高低水位线,作为待发送数据内存占用的上限和下限。
那么高低水位线具体设置多大呢 ? 我们来看一下 DefaultChannelConfig 中的配置。
public class DefaultChannelConfig implements ChannelConfig {
//ChannelOutboundBuffer中的高低水位线
private volatile WriteBufferWaterMark writeBufferWaterMark = WriteBufferWaterMark.DEFAULT;
}public final class WriteBufferWaterMark {
private static final int DEFAULT_LOW_WATER_MARK = 32 * 1024;
private static final int DEFAULT_HIGH_WATER_MARK = 64 * 1024;
public static final WriteBufferWaterMark DEFAULT =
new WriteBufferWaterMark(DEFAULT_LOW_WATER_MARK, DEFAULT_HIGH_WATER_MARK, false);
WriteBufferWaterMark(int low, int high, boolean validate) {
..........省略校验逻辑.........
this.low = low;
this.high = high;
}
}我们看到 ChannelOutboundBuffer 中的高水位线设置的大小为 64 KB,低水位线设置的是 32 KB。
这也就意味着每个 Channel 中的待发送数据如果超过 64 KB。Channel 的状态就会变为不可写状态。当内存占用量低于 32 KB时,Channel 的状态会再次变为可写状态。
3.3.4 Entry实例对象在JVM中占用内存大小
前边提到 pendingSize 的作用主要是记录当前待发送数据的内存占用总量从而可以预警 OOM 的发生。
待发送数据的内存占用分为:待发送数据 msg 的内存占用大小以及 Entry 对象本身在JVM中的内存占用。
那么 Entry 对象本身的内存占用我们该如何计算呢?
要想搞清楚这个问题,大家需要先了解一下 Java 对象内存布局的相关知识。关于这部分背景知识,笔者已经在 [?《一文聊透对象在JVM中的内存布局,以及内存对齐和压缩指针的原理及应用》] 这篇文章中给出了详尽的阐述,想深入了解这块的同学可以看下这篇文章。
这里笔者只从这篇文章中提炼一些关于计算 Java 对象占用内存大小相关的内容。
在关于 Java 对象内存布局这篇文章中我们提到,对于Java普通对象来说内存中的布局由:对象头 + 实例数据区 + Padding,这三部分组成。
其中对象头由存储对象运行时信息的 MarkWord 以及指向对象类型元信息的类型指针组成。
MarkWord 用来存放:hashcode,GC 分代年龄,锁状态标志,线程持有的锁,偏向线程 Id,偏向时间戳等。在 32 位操作系统和 64 位操作系统中 MarkWord 分别占用 4B 和 8B 大小的内存。
Java 对象头中的类型指针还有实例数据区的对象引用,在64 位系统中开启压缩指针的情况下(-XX:+UseCompressedOops)占用 4B 大小。在关闭压缩指针的情况下(-XX:-UseCompressedOops)占用 8B 大小。
实例数据区用于存储 Java 类中定义的实例字段,包括所有父类中的实例字段以及对象引用。
在实例数据区中对象字段之间的排列以及内存对齐需要遵循三个字段重排列规则:
规则1:如果一个字段占用X个字节,那么这个字段的偏移量OFFSET需要对齐至NX。规则2:在开启了压缩指针的 64 位 JVM 中,Java 类中的第一个字段的 OFFSET 需要对齐至4N,在关闭压缩指针的情况下类中第一个字段的OFFSET需要对齐至8N。规则3:JVM 默认分配字段的顺序为:long / double,int / float,short / char,byte / boolean,oops(Ordianry Object Point 引用类型指针),并且父类中定义的实例变量会出现在子类实例变量之前。当设置JVM参数-XX +CompactFields时(默认),占用内存小于 long / double 的字段会允许被插入到对象中第一个 long / double 字段之前的间隙中,以避免不必要的内存填充。
还有一个重要规则就是 Java 虚拟机堆中对象的起始地址需要对齐至 8 的倍数(可由JVM参数 -XX:ObjectAlignmentInBytes 控制,默认为 8 )。
在了解上述字段排列以及对象之间的内存对齐规则后,我们分别以开启压缩指针和关闭压缩指针两种情况,来对 Entry 对象的内存布局进行分析并计算对象占用内存大小。
static final class Entry {
.............省略static字段RECYCLER.........
//DefaultHandle用于回收对象
private final Handle<Entry> handle;
//ChannelOutboundBuffer下一个节点
Entry next;
//待发送数据
Object msg;
//msg 转换为 jdk nio 中的byteBuffer
ByteBuffer[] bufs;
ByteBuffer buf;
//异步write操作的future
ChannelPromise promise;
//已发送了多少
long progress;
//总共需要发送多少,不包含entry对象大小。
long total;
//pendingSize表示entry对象在堆中需要的内存总量 待发送数据大小 + entry对象本身在堆中占用内存大小(96)
int pendingSize;
//msg中包含了几个jdk nio bytebuffer
int count = -1;
//write操作是否被取消
boolean cancelled;
}我们看到 Entry 对象中一共有 11 个实例字段,其中 2 个 long 型字段,2 个 int 型字段,1 个 boolean 型字段,6 个对象引用。
默认情况下JVM参数 -XX +CompactFields 是开启的。
开启指针压缩 -XX:+UseCompressedOops
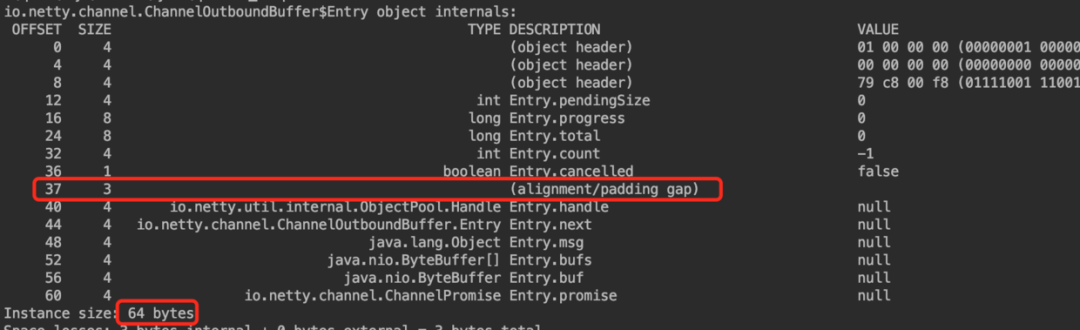
Entry 对象的内存布局中开头先是 8 个字节的 MarkWord,然后是 4 个字节的类型指针(开启压缩指针)。
在实例数据区中对象的排列规则需要符合规则3,也就是字段之间的排列顺序需要遵循 long > int > boolean > oop(对象引用)。
根据规则 3 Entry对象实例数据区第一个字段应该是 long progress,但根据规则1 long 型字段的 OFFSET 需要对齐至 8 的倍数,并且根据 规则2 在开启压缩指针的情况下,对象的第一个字段 OFFSET 需要对齐至 4 的倍数。所以字段long progress 的 OFFET = 16,这就必然导致了在对象头与字段 long progress 之间需要由 4 字节的字节填充(OFFET = 12处发生字节填充)。
但是 JVM 默认开启了 -XX +CompactFields,根据 规则3 占用内存小于 long / double 的字段会允许被插入到对象中第一个 long / double 字段之前的间隙中,以避免不必要的内存填充。
所以位于后边的字段 int pendingSize 插入到了 OFFET = 12 位置处,避免了不必要的字节填充。
在 Entry 对象的实例数据区中紧接着基础类型字段后面跟着的就是 6 个对象引用字段(开启压缩指针占用 4 个字节)。
大家一定注意到 OFFSET = 37 处本应该存放的是字段 private final Handle<Entry> handle 但是却被填充了 3 个字节。这是为什么呢?
根据字段重排列规则1:引用字段 private final Handle<Entry> handle 占用 4 个字节(开启压缩指针的情况),所以需要对齐至4的倍数。所以需要填充3个字节,使得引用字段 private final Handle<Entry> handle 位于 OFFSET = 40 处。
根据以上这些规则最终计算出来在开启压缩指针的情况下Entry对象在堆中占用内存大小为64字节
关闭指针压缩 -XX:-UseCompressedOops
在分析完 Entry 对象在开启压缩指针情况下的内存布局情况后,我想大家现在对前边介绍的字段重排列的三个规则理解更加清晰了,那么我们基于这个基础来分析下在关闭压缩指针的情况下 Entry 对象的内存布局。
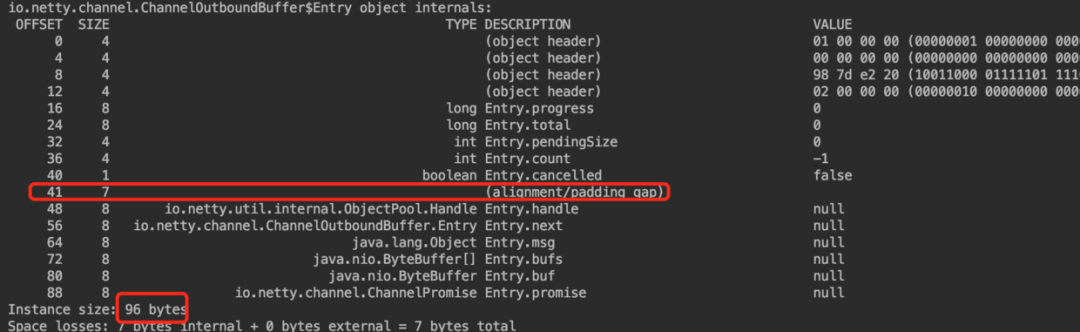
首先 Entry 对象在内存布局中的开头依然是由 8 个字节的 MarkWord 还有 8 个字节的类型指针(关闭压缩指针)组成的对象头。
我们看到在 OFFSET = 41 处发生了字节填充,原因是在关闭压缩指针的情况下,对象引用占用内存大小变为 8 个字节,根据规则1: 引用字段 private final Handle<Entry> handle 的 OFFET 需要对齐至 8 的倍数,所以需要在该引用字段之前填充 7 个字节,使得引用字段 private final Handle<Entry> handle 的OFFET = 48 。
综合字段重排列的三个规则最终计算出来在关闭压缩指针的情况下Entry对象在堆中占用内存大小为96字节
3.3.5 向ChannelOutboundBuffer中缓存待发送数据
在介绍完 ChannelOutboundBuffer 的基本结构之后,下面就来到了 Netty 处理 write 事件的最后一步,我们来看下用户的待发送数据是如何被添加进 ChannelOutboundBuffer 中的。
public void addMessage(Object msg, int size, ChannelPromise promise) {
Entry entry = Entry.newInstance(msg, size, total(msg), promise);
if (tailEntry == null) {
flushedEntry = null;
} else {
Entry tail = tailEntry;
tail.next = entry;
}
tailEntry = entry;
if (unflushedEntry == null) {
unflushedEntry = entry;
}
incrementPendingOutboundBytes(entry.pendingSize, false);
}3.3.5.1 创建Entry对象来封装待发送数据信息
通过前边的介绍我们了解到当用户调用 ctx.write(msg) 之后,write 事件开始在pipeline中从当前 ChannelHandler开始一直向前进行传播,最终在 HeadContext 中将待发送数据写入到 channel 对应的写缓冲区 ChannelOutboundBuffer 中。
而 ChannelOutboundBuffer 是由 Entry 结构组成的一个单链表,Entry 结构封装了用户待发送数据的各种信息。
这里首先我们需要为待发送数据创建 Entry 对象,而在[?《详解Recycler对象池的精妙设计与实现》] 一文中我们介绍对象池时,提到 Netty 作为一个高性能高吞吐的网络框架要面对海量的 IO 处理操作,这种场景下会频繁的创建大量的 Entry 对象,而对象的创建及其回收时需要性能开销的,尤其是在面对大量频繁的创建对象场景下,这种开销会进一步被放大,所以 Netty 引入了对象池来管理 Entry 对象实例从而避免 Entry 对象频繁创建以及 GC 带来的性能开销。
既然 Entry 对象已经被对象池接管,那么它在对象池外面是不能被直接创建的,其构造函数是私有类型,并提供一个静态方法 newInstance 供外部线程从对象池中获取 Entry 对象。这在[?《详解Recycler对象池的精妙设计与实现》] 一文中介绍池化对象的设计时也有提到过。
static final class Entry {
//静态变量引用类型地址 这个是在Klass Point(类型指针)中定义 8字节(开启指针压缩 为4字节)
private static final ObjectPool<Entry> RECYCLER = ObjectPool.newPool(new ObjectCreator<Entry>() {
@Override
public Entry newObject(Handle<Entry> handle) {
return new Entry(handle);
}
});
//Entry对象只能通过对象池获取,不可外部自行创建
private Entry(Handle<Entry> handle) {
this.handle = handle;
}
//不考虑指针压缩的大小 entry对象在堆中占用的内存大小为96
//如果开启指针压缩,entry对象在堆中占用的内存大小 会是64
static final int CHANNEL_OUTBOUND_BUFFER_ENTRY_OVERHEAD =
SystemPropertyUtil.getInt("io.netty.transport.outboundBufferEntrySizeOverhead", 96);
static Entry newInstance(Object msg, int size, long total, ChannelPromise promise) {
Entry entry = RECYCLER.get();
entry.msg = msg;
//待发数据数据大小 + entry对象大小
entry.pendingSize = size + CHANNEL_OUTBOUND_BUFFER_ENTRY_OVERHEAD;
entry.total = total;
entry.promise = promise;
return entry;
}
.......................省略................
}- 通过池化对象 Entry 中持有的对象池 RECYCLER ,从对象池中获取 Entry 对象实例。
- 将用户待发送数据 msg(DirectByteBuffer),待发送数据大小:total ,本次发送数据的 channelFuture,以及该 Entry 对象的 pendingSize 统统封装在 Entry 对象实例的相应字段中。
这里需要特殊说明一点的是关于 pendingSize 的计算方式,之前我们提到 pendingSize 中所计算的内存占用一共包含两部分:
- 待发送网络数据大小
- Entry 对象本身在内存中的占用量
而在《3.3.4 Entry实例对象在JVM中占用内存大小》小节中我们介绍到,Entry 对象在内存中的占用大小在开启压缩指针的情况下(-XX:+UseCompressedOops)占用 64 字节,在关闭压缩指针的情况下(-XX:-UseCompressedOops)占用 96 字节。
字段 CHANNEL_OUTBOUND_BUFFER_ENTRY_OVERHEAD 表示的就是 Entry 对象在内存中的占用大小,Netty这里默认是 96 字节,当然如果我们的应用程序开启了指针压缩,我们可以通过 JVM 启动参数 -D io.netty.transport.outboundBufferEntrySizeOverhead 指定为 64 字节。
3.3.5.2 将Entry对象添加进ChannelOutboundBuffer中
if (tailEntry == null) {
flushedEntry = null;
} else {
Entry tail = tailEntry;
tail.next = entry;
}
tailEntry = entry;
if (unflushedEntry == null) {
unflushedEntry = entry;
}在《3.3 ChannelOutboundBuffer》小节一开始,我们介绍了 ChannelOutboundBuffer 中最重要的三个指针,这里涉及到的两个指针分别是:
unflushedEntry:指向 ChannelOutboundBuffer 中第一个未被 flush 进 Socket 的待发送数据。用来指示 ChannelOutboundBuffer 的第一个节点。tailEntry:指向 ChannelOutboundBuffer 中最后一个节点。
通过 unflushedEntry 和 tailEntry 可以定位出待发送数据的范围。Channel 中的每一次 write 事件,最终都会将待发送数据插入到 ChannelOutboundBuffer 的尾结点处。
3.3.5.3 incrementPendingOutboundBytes
在将 Entry 对象添加进 ChannelOutboundBuffer 之后,就需要更新用于记录当前 ChannelOutboundBuffer 中关于待发送数据所占内存总量的水位线指示。
如果更新后的水位线超过了 Netty 指定的高水位线 DEFAULT_HIGH_WATER_MARK = 64 * 1024,则需要将当前 Channel 的状态设置为不可写,并在 pipeline 中传播 ChannelWritabilityChanged 事件,注意该事件是一个 inbound 事件。

public final class ChannelOutboundBuffer {
//ChannelOutboundBuffer中的待发送数据的内存占用总量 : 所有Entry对象本身所占用内存大小 + 所有待发送数据的大小
private volatile long totalPendingSize;
//水位线指针
private static final AtomicLongFieldUpdater<ChannelOutboundBuffer> TOTAL_PENDING_SIZE_UPDATER =
AtomicLongFieldUpdater.newUpdater(ChannelOutboundBuffer.class, "totalPendingSize");
private void incrementPendingOutboundBytes(long size, boolean invokeLater) {
if (size == 0) {
return;
}
//更新总共待写入数据的大小
long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, size);
//如果待写入的数据 大于 高水位线 64 * 1024 则设置当前channel为不可写 由用户自己决定是否继续写入
if (newWriteBufferSize > channel.config().getWriteBufferHighWaterMark()) {
//设置当前channel状态为不可写,并触发fireChannelWritabilityChanged事件
setUnwritable(invokeLater);
}
}
}volatile 关键字在 Java 内存模型中只能保证变量的可见性,以及禁止指令重排序。但无法保证多线程更新的原子性,这里我们可以通过AtomicLongFieldUpdater 来帮助 totalPendingSize 字段实现原子性的更新。
// 0表示channel可写,1表示channel不可写
private volatile int unwritable;
private static final AtomicIntegerFieldUpdater<ChannelOutboundBuffer> UNWRITABLE_UPDATER =
AtomicIntegerFieldUpdater.newUpdater(ChannelOutboundBuffer.class, "unwritable");
private void setUnwritable(boolean invokeLater) {
for (;;) {
final int oldValue = unwritable;
final int newValue = oldValue | 1;
if (UNWRITABLE_UPDATER.compareAndSet(this, oldValue, newValue)) {
if (oldValue == 0) {
//触发fireChannelWritabilityChanged事件 表示当前channel变为不可写
fireChannelWritabilityChanged(invokeLater);
}
break;
}
}
}当 ChannelOutboundBuffer 中的内存占用水位线 totalPendingSize 已经超过高水位线时,调用该方法将当前 Channel 的状态设置为不可写状态。
unwritable == 0 表示当前channel可写,unwritable == 1 表示当前channel不可写。
channel 可以通过调用 isWritable 方法来判断自身当前状态是否可写。
public boolean isWritable() {
return unwritable == 0;
}当 Channel 的状态是首次从可写状态变为不可写状态时,就会在 channel 对应的 pipeline 中传播 ChannelWritabilityChanged 事件。
private void fireChannelWritabilityChanged(boolean invokeLater) {
final ChannelPipeline pipeline = channel.pipeline();
if (invokeLater) {
Runnable task = fireChannelWritabilityChangedTask;
if (task == null) {
fireChannelWritabilityChangedTask = task = new Runnable() {
@Override
public void run() {
pipeline.fireChannelWritabilityChanged();
}
};
}
channel.eventLoop().execute(task);
} else {
pipeline.fireChannelWritabilityChanged();
}
}用户可以在自定义的 ChannelHandler 中实现 channelWritabilityChanged 事件回调方法,来针对 Channel 的可写状态变化做出不同的处理。
public class EchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelWritabilityChanged(ChannelHandlerContext ctx) throws Exception {
if (ctx.channel().isWritable()) {
...........当前channel可写.........
} else {
...........当前channel不可写.........
}
}
}到这里 write 事件在 pipeline 中的传播,笔者就为大家介绍完了,下面我们来看下另一个重要的 flush 事件的处理过程。
4 . flush
从前面 Netty 对 write 事件的处理过程中,我们可以看到当用户调用 ctx.write(msg) 方法之后,Netty 只是将用户要发送的数据临时写到 channel 对应的待发送缓冲队列 ChannelOutboundBuffer 中,然而并不会将数据写入 Socket 中。
而当一次 read 事件完成之后,我们会调用 ctx.flush() 方法将 ChannelOutboundBuffer 中的待发送数据写入 Socket 中的发送缓冲区中,从而将数据发送出去。
public class EchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelReadComplete(ChannelHandlerContext ctx) {
//本次OP_READ事件处理完毕
ctx.flush();
}
}4.1 flush事件的传播
flush 事件和 write 事件一样都是 oubound 事件,所以它们的传播方向都是从后往前在 pipeline 中传播。
触发 flush 事件传播的同样也有两个方法:
channelHandlerContext.flush():flush事件会从当前 channelHandler 开始在 pipeline 中向前传播直到 headContext。channelHandlerContext.channel().flush():flush 事件会从 pipeline 的尾结点 tailContext 处开始向前传播直到 headContext。
abstract class AbstractChannelHandlerContext implements ChannelHandlerContext, ResourceLeakHint {
@Override
public ChannelHandlerContext flush() {
//向前查找覆盖flush方法的Outbound类型的ChannelHandler
final AbstractChannelHandlerContext next = findContextOutbound(MASK_FLUSH);
//获取执行ChannelHandler的executor,在初始化pipeline的时候设置,默认为Reactor线程
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
next.invokeFlush();
} else {
Tasks tasks = next.invokeTasks;
if (tasks == null) {
next.invokeTasks = tasks = new Tasks(next);
}
safeExecute(executor, tasks.invokeFlushTask, channel().voidPromise(), null, false);
}
return this;
}
}这里的逻辑和 write 事件传播的逻辑基本一样,也是首先通过findContextOutbound(MASK_FLUSH) 方法从当前 ChannelHandler 开始从 pipeline 中向前查找出第一个 ChannelOutboundHandler 类型的并且实现 flush 事件回调方法的 ChannelHandler 。注意这里传入的执行资格掩码为 MASK_FLUSH。
执行ChannelHandler中事件回调方法的线程必须是通过pipeline#addLast(EventExecutorGroup group, ChannelHandler... handlers)为 ChannelHandler 指定的 executor。如果不指定,默认的 executor 为 channel 绑定的 reactor 线程。
如果当前线程不是 ChannelHandler 指定的 executor,则需要将 invokeFlush() 方法的调用封装成 Task 交给指定的 executor 执行。
4.1.1 触发nextChannelHandler的flush方法回调
private void invokeFlush() {
if (invokeHandler()) {
invokeFlush0();
} else {
//如果该ChannelHandler并没有加入到pipeline中则继续向前传递flush事件
flush();
}
}这里和 write 事件的相关处理一样,首先也是需要调用 invokeHandler() 方法来判断这个 nextChannelHandler 是否在 pipeline 中被正确的初始化。
如果 nextChannelHandler 中的 handlerAdded 方法并没有被回调过,那么这里就只能跳过 nextChannelHandler,并调用 ChannelHandlerContext#flush 方法继续向前传播flush事件。
如果 nextChannelHandler 中的 handlerAdded 方法已经被回调过,说明 nextChannelHandler 在 pipeline 中已经被正确的初始化好,则直接调用nextChannelHandler 的 flush 事件回调方法。
private void invokeFlush0() {
try {
((ChannelOutboundHandler) handler()).flush(this);
} catch (Throwable t) {
invokeExceptionCaught(t);
}
}这里有一点和 write 事件处理不同的是,当调用 nextChannelHandler 的 flush 回调出现异常的时候,会触发 nextChannelHandler 的 exceptionCaught 回调。
private void invokeExceptionCaught(final Throwable cause) {
if (invokeHandler()) {
try {
handler().exceptionCaught(this, cause);
} catch (Throwable error) {
if (logger.isDebugEnabled()) {
logger.debug(....相关日志打印......);
} else if (logger.isWarnEnabled()) {
logger.warn(...相关日志打印......));
}
}
} else {
fireExceptionCaught(cause);
}
}而其他 outbound 类事件比如 write 事件在传播的过程中发生异常,只是回调通知相关的 ChannelFuture。并不会触发 exceptionCaught 事件的传播。
4.2 flush事件的处理
最终flush事件会在pipeline中一直向前传播至HeadContext中,并在 HeadContext 里调用 channel 的 unsafe 类完成 flush 事件的最终处理逻辑。
final class HeadContext extends AbstractChannelHandlerContext {
@Override
public void flush(ChannelHandlerContext ctx) {
unsafe.flush();
}
}下面就真正到了 Netty 处理 flush 事件的地方。
protected abstract class AbstractUnsafe implements Unsafe {
@Override
public final void flush() {
assertEventLoop();
ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
//channel以关闭
if (outboundBuffer == null) {
return;
}
//将flushedEntry指针指向ChannelOutboundBuffer头结点,此时变为即将要flush进Socket的数据队列
outboundBuffer.addFlush();
//将待写数据写进Socket
flush0();
}
}4.2.1 ChannelOutboundBuffer#addFlush
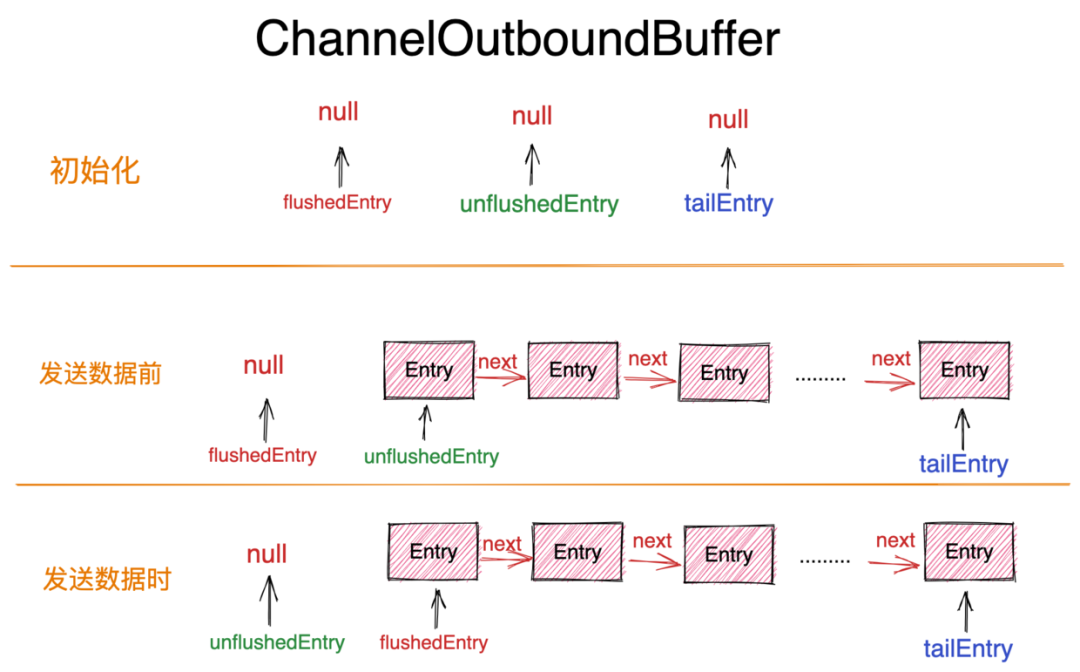
这里就到了真正要发送数据的时候了,在 addFlush 方法中会将 flushedEntry 指针指向 unflushedEntry 指针表示的第一个未被 flush 的 Entry 节点。并将 unflushedEntry 指针置为空,准备开始 flush 发送数据流程。
此时 ChannelOutboundBuffer 由待发送数据的缓冲队列变为了即将要 flush 进 Socket 的数据队列
这样在 flushedEntry 与 tailEntry 之间的 Entry 节点即为本次 flush 操作需要发送的数据范围。
public void addFlush() {
Entry entry = unflushedEntry;
if (entry != null) {
if (flushedEntry == null) {
flushedEntry = entry;
}
do {
flushed ++;
//如果当前entry对应的write操作被用户取消,则释放msg,并降低channelOutboundBuffer水位线
if (!entry.promise.setUncancellable()) {
int pending = entry.cancel();
decrementPendingOutboundBytes(pending, false, true);
}
entry = entry.next;
} while (entry != null);
// All flushed so reset unflushedEntry
unflushedEntry = null;
}
}在 flush 发送数据流程开始时,数据的发送流程就不能被取消了,在这之前我们都是可以通过 ChannelPromise 取消数据发送流程的。
所以这里需要对 ChannelOutboundBuffer 中所有 Entry 节点包裹的 ChannelPromise 设置为不可取消状态。
public interface Promise<V> extends Future<V> {
/**
* 设置当前future为不可取消状态
*
* 返回true的情况:
* 1:成功的将future设置为uncancellable
* 2:当future已经成功完成
*
* 返回false的情况:
* 1:future已经被取消,则不能在设置 uncancellable 状态
*
*/
boolean setUncancellable();
}如果这里的 setUncancellable() 方法返回 false 则说明在这之前用户已经将 ChannelPromise 取消掉了,接下来就需要调用 entry.cancel() 方法来释放为待发送数据 msg 分配的堆外内存。
static final class Entry {
//write操作是否被取消
boolean cancelled;
int cancel() {
if (!cancelled) {
cancelled = true;
int pSize = pendingSize;
// release message and replace with an empty buffer
ReferenceCountUtil.safeRelease(msg);
msg = Unpooled.EMPTY_BUFFER;
pendingSize = 0;
total = 0;
progress = 0;
bufs = null;
buf = null;
return pSize;
}
return 0;
}
}当 Entry 对象被取消后,就需要减少 ChannelOutboundBuffer 的内存占用总量的水位线 totalPendingSize。
private static final AtomicLongFieldUpdater<ChannelOutboundBuffer> TOTAL_PENDING_SIZE_UPDATER =
AtomicLongFieldUpdater.newUpdater(ChannelOutboundBuffer.class, "totalPendingSize");
//水位线指针.ChannelOutboundBuffer中的待发送数据的内存占用总量 : 所有Entry对象本身所占用内存大小 + 所有待发送数据的大小
private volatile long totalPendingSize;
private void decrementPendingOutboundBytes(long size, boolean invokeLater, boolean notifyWritability) {
if (size == 0) {
return;
}
long newWriteBufferSize = TOTAL_PENDING_SIZE_UPDATER.addAndGet(this, -size);
if (notifyWritability && newWriteBufferSize < channel.config().getWriteBufferLowWaterMark()) {
setWritable(invokeLater);
}
}当更新后的水位线低于低水位线 DEFAULT_LOW_WATER_MARK = 32 * 1024 时,就将当前 channel 设置为可写状态。
private void setWritable(boolean invokeLater) {
for (;;) {
final int oldValue = unwritable;
final int newValue = oldValue & ~1;
if (UNWRITABLE_UPDATER.compareAndSet(this, oldValue, newValue)) {
if (oldValue != 0 && newValue == 0) {
fireChannelWritabilityChanged(invokeLater);
}
break;
}
}
}当 Channel 的状态是第一次从不可写状态变为可写状态时,Netty 会在 pipeline 中再次触发 ChannelWritabilityChanged 事件的传播。
4.2.2 发送数据前的最后检查---flush0
flush0 方法这里主要做的事情就是检查当 channel 的状态是否正常,如果 channel 状态一切正常,则调用 doWrite 方法发送数据。
protected abstract class AbstractUnsafe implements Unsafe {
//是否正在进行flush操作
private boolean inFlush0;
protected void flush0() {
if (inFlush0) {
// Avoid re-entrance
return;
}
final ChannelOutboundBuffer outboundBuffer = this.outboundBuffer;
//channel已经关闭或者outboundBuffer为空
if (outboundBuffer == null || outboundBuffer.isEmpty()) {
return;
}
inFlush0 = true;
if (!isActive()) {
try {
if (!outboundBuffer.isEmpty()) {
if (isOpen()) {
//当前channel处于disConnected状态 通知promise 写入失败 并触发channelWritabilityChanged事件
outboundBuffer.failFlushed(new NotYetConnectedException(), true);
} else {
//当前channel处于关闭状态 通知promise 写入失败 但不触发channelWritabilityChanged事件
outboundBuffer.failFlushed(newClosedChannelException(initialCloseCause, "flush0()"), false);
}
}
} finally {
inFlush0 = false;
}
return;
}
try {
//写入Socket
doWrite(outboundBuffer);
} catch (Throwable t) {
handleWriteError(t);
} finally {
inFlush0 = false;
}
}
}outboundBuffer == null || outboundBuffer.isEmpty():如果 channel 已经关闭了或者对应写缓冲区中没有任何数据,那么就停止发送流程,直接 return。!isActive():如果当前channel处于非活跃状态,则需要调用outboundBuffer#failFlushed通知 ChannelOutboundBuffer 中所有待发送操作对应的 channelPromise 向用户线程报告发送失败。并将待发送数据 Entry 对象从 ChannelOutboundBuffer 中删除,并释放待发送数据空间,回收 Entry 对象实例。
还记得我们在[?《Netty如何高效接收网络连接》] 一文中提到过的 NioSocketChannel 的 active 状态有哪些条件吗??
@Override
public boolean isActive() {
SocketChannel ch = javaChannel();
return ch.isOpen() && ch.isConnected();
}NioSocketChannel 处于 active 状态的条件必须是当前 NioSocketChannel 是 open 的同时处于 connected 状态。
!isActive() && isOpen():说明当前 channel 处于 disConnected 状态,这时通知给用户 channelPromise 的异常类型为 NotYetConnectedException ,并释放所有待发送数据占用的堆外内存,如果此时内存占用量低于低水位线,则设置 channel 为可写状态,并触发 channelWritabilityChanged 事件。
当 channel 处于 disConnected 状态时,用户可以进行 write 操作但不能进行 flush 操作。
!isActive() && !isOpen():说明当前 channel 处于关闭状态,这时通知给用户 channelPromise 的异常类型为 newClosedChannelException ,因为 channel 已经关闭,所以这里并不会触发 channelWritabilityChanged 事件。- 当 channel 的这些异常状态校验通过之后,则调用 doWrite 方法将 ChannelOutboundBuffer 中的待发送数据写进底层 Socket 中。
4.2.2.1 ChannelOutboundBuffer#failFlushed
public final class ChannelOutboundBuffer {
private boolean inFail;
void failFlushed(Throwable cause, boolean notify) {
if (inFail) {
return;
}
try {
inFail = true;
for (;;) {
if (!remove0(cause, notify)) {
break;
}
}
} finally {
inFail = false;
}
}
}该方法用于在 Netty 在发送数据的时候,如果发现当前 channel 处于非活跃状态,则将 ChannelOutboundBuffer 中 flushedEntry 与tailEntry 之间的 Entry 对象节点全部删除,并释放发送数据占用的内存空间,同时回收 Entry 对象实例。
4.2.2.2 ChannelOutboundBuffer#remove0
private boolean remove0(Throwable cause, boolean notifyWritability) {
Entry e = flushedEntry;
if (e == null) {
//清空当前reactor线程缓存的所有待发送数据
clearNioBuffers();
return false;
}
Object msg = e.msg;
ChannelPromise promise = e.promise;
int size = e.pendingSize;
//从channelOutboundBuffer中删除该Entry节点
removeEntry(e);
if (!e.cancelled) {
// only release message, fail and decrement if it was not canceled before.
//释放msg所占用的内存空间
ReferenceCountUtil.safeRelease(msg);
//编辑promise发送失败,并通知相应的Lisener
safeFail(promise, cause);
//由于msg得到释放,所以需要降低channelOutboundBuffer中的内存占用水位线,并根据notifyWritability决定是否触发ChannelWritabilityChanged事件
decrementPendingOutboundBytes(size, false, notifyWritability);
}
// recycle the entry
//回收Entry实例对象
e.recycle();
return true;
}当一个 Entry 节点需要从 ChannelOutboundBuffer 中清除时,Netty 需要释放该 Entry 节点中包裹的发送数据 msg 所占用的内存空间。并标记对应的 promise 为失败同时通知对应的 listener ,由于 msg 得到释放,所以需要降低 channelOutboundBuffer 中的内存占用水位线,并根据 boolean notifyWritability 决定是否触发 ChannelWritabilityChanged 事件。最后需要将该 Entry 实例回收至 Recycler 对象池中。
5 . 终于开始真正地发送数据了!
来到这里我们就真正进入到了 Netty 发送数据的核心处理逻辑,在[?《Netty如何高效接收网络数据》] 一文中,笔者详细介绍了 Netty 读取数据的核心流程,Netty 会在一个 read loop 中不断循环读取 Socket 中的数据直到数据读取完毕或者读取次数已满 16 次,当循环读取了 16 次还没有读取完毕时,Netty 就不能在继续读了,因为 Netty 要保证 Reactor 线程可以均匀的处理注册在它上边的所有 Channel 中的 IO 事件。剩下未读取的数据等到下一次 read loop 在开始读取。
除此之外,在每次 read loop 开始之前,Netty 都会分配一个初始化大小为 2048 的 DirectByteBuffer 来装载从 Socket 中读取到的数据,当整个 read loop 结束时,会根据本次读取数据的总量来判断是否为该 DirectByteBuffer 进行扩容或者缩容,目的是在下一次 read loop 的时候可以为其分配一个容量大小合适的 DirectByteBuffer 。
其实 Netty 对发送数据的处理和对读取数据的处理核心逻辑都是一样的,这里大家可以将这两篇文章结合对比着看。
但发送数据的细节会多一些,也会更复杂一些,由于这块逻辑整体稍微比较复杂,所以我们接下来还是分模块进行解析:
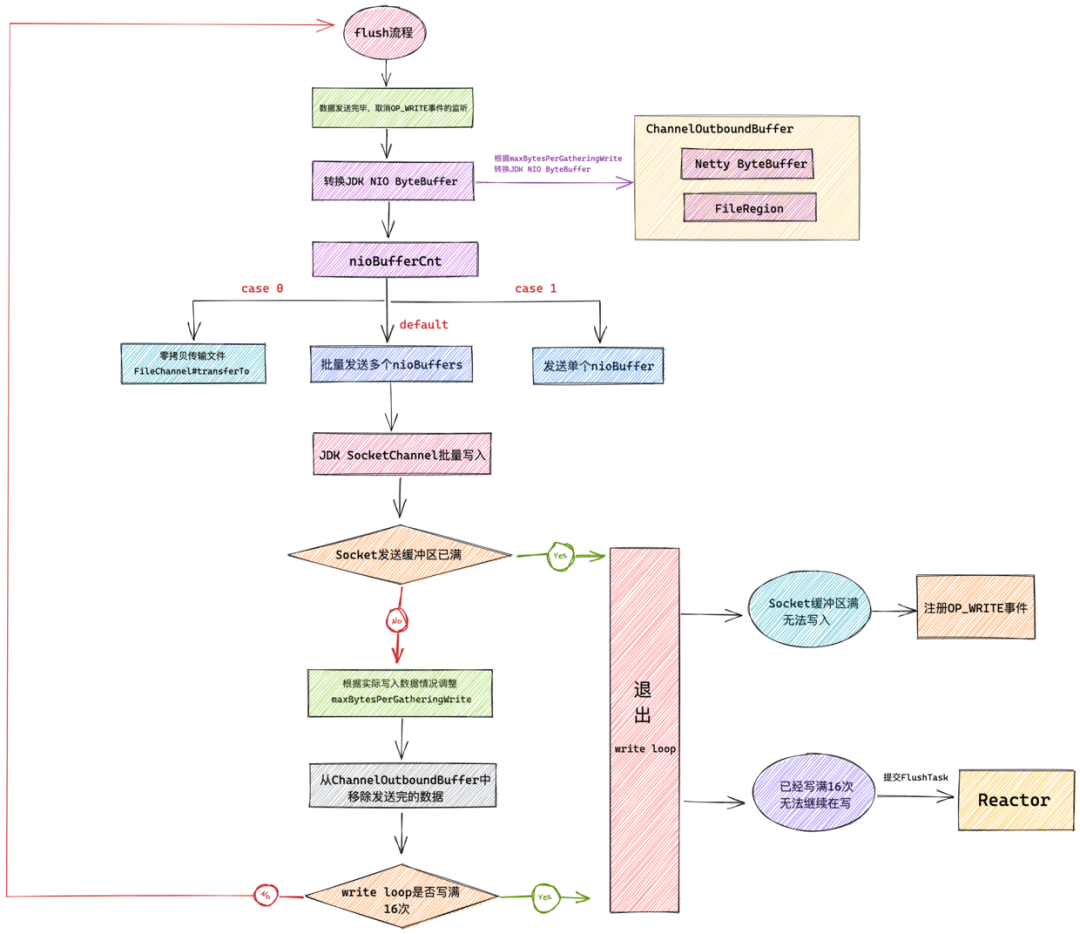
5.1 发送数据前的准备工作
@Override
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
//获取NioSocketChannel中封装的jdk nio底层socketChannel
SocketChannel ch = javaChannel();
//最大写入次数 默认为16 目的是为了保证SubReactor可以平均的处理注册其上的所有Channel
int writeSpinCount = config().getWriteSpinCount();
do {
if (in.isEmpty()) {
// 如果全部数据已经写完 则移除OP_WRITE事件并直接退出writeLoop
clearOpWrite();
return;
}
// SO_SNDBUF设置的发送缓冲区大小 * 2 作为 最大写入字节数 293976 = 146988 << 1
int maxBytesPerGatheringWrite = ((NioSocketChannelConfig) config).getMaxBytesPerGatheringWrite();
// 将ChannelOutboundBuffer中缓存的DirectBuffer转换成JDK NIO 的 ByteBuffer
ByteBuffer[] nioBuffers = in.nioBuffers(1024, maxBytesPerGatheringWrite);
// ChannelOutboundBuffer中总共的DirectBuffer数
int nioBufferCnt = in.nioBufferCount();
switch (nioBufferCnt) {
.........向底层jdk nio socketChannel发送数据.........
}
} while (writeSpinCount > 0);
............处理本轮write loop未写完的情况.......
}这部分内容为 Netty 开始发送数据之前的准备工作:
5.1.1 获取write loop最大发送循环次数
从当前 NioSocketChannel 的配置类 NioSocketChannelConfig 中获取 write loop 最大循环写入次数,默认为 16。但也可以通过下面的方式进行自定义设置。
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.......
.childOption(ChannelOption.WRITE_SPIN_COUNT,自定义数值)5.1.2 处理在一轮write loop中就发送完数据的情况
进入 write loop 之后首先需要判断当前 ChannelOutboundBuffer 中的数据是否已经写完了 in.isEmpty()) ,如果全部写完就需要清除当前 Channel 在 Reactor 上注册的 OP_WRITE 事件。
这里大家可能会有疑问,目前我们还没有注册 OP_WRITE 事件到 Reactor 上,为啥要清除呢?别着急,笔者会在后面为大家揭晓答案。
5.1.3 获取本次write loop 最大允许发送字节数
从 ChannelConfig 中获取本次 write loop 最大允许发送的字节数 maxBytesPerGatheringWrite 。初始值为 SO_SNDBUF大小 * 2 = 293976 = 146988 << 1,最小值为 2048。
private final class NioSocketChannelConfig extends DefaultSocketChannelConfig {
//293976 = 146988 << 1
//SO_SNDBUF设置的发送缓冲区大小 * 2 作为 最大写入字节数
//最小值为2048
private volatile int maxBytesPerGatheringWrite = Integer.MAX_VALUE;
private NioSocketChannelConfig(NioSocketChannel channel, Socket javaSocket) {
super(channel, javaSocket);
calculateMaxBytesPerGatheringWrite();
}
private void calculateMaxBytesPerGatheringWrite() {
// 293976 = 146988 << 1
// SO_SNDBUF设置的发送缓冲区大小 * 2 作为 最大写入字节数
int newSendBufferSize = getSendBufferSize() << 1;
if (newSendBufferSize > 0) {
setMaxBytesPerGatheringWrite(newSendBufferSize);
}
}
}
我们可以通过如下的方式自定义配置 Socket 发送缓冲区大小。
ServerBootstrap b = new ServerBootstrap();
b.group(bossGroup, workerGroup)
.......
.childOption(ChannelOption.SO_SNDBUF,自定义数值)5.1.4 将待发送数据转换成 JDK NIO ByteBuffer
由于最终 Netty 会调用 JDK NIO 的 SocketChannel 发送数据,所以这里需要首先将当前 Channel 中的写缓冲队列 ChannelOutboundBuffer 里存储的 DirectByteBuffer( Netty 中的 ByteBuffer 实现)转换成 JDK NIO 的 ByteBuffer 类型。最终将转换后的待发送数据存储在 ByteBuffer[] nioBuffers 数组中。这里通过调用 ChannelOutboundBuffer#nioBuffers 方法完成以上 ByteBuffer 类型的转换。
maxBytesPerGatheringWrite:表示本次 write loop 中最多从 ChannelOutboundBuffer 中转换 maxBytesPerGatheringWrite 个字节出来。也就是本次 write loop 最多能发送多少字节。1024: 本次 write loop 最多转换 1024 个 ByteBuffer( JDK NIO 实现)。也就是说本次 write loop 最多批量发送多少个 ByteBuffer 。
通过 ChannelOutboundBuffer#nioBufferCount() 获取本次 write loop 总共需要发送的 ByteBuffer 数量 nioBufferCnt 。注意这里已经变成了 JDK NIO 实现的 ByteBuffer 了。
详细的 ByteBuffer 类型转换过程,笔者会在专门讲解 Buffer 设计的时候为大家全面细致地讲解,这里我们还是主要聚焦于发送数据流程的主线。
当做完这些发送前的准备工作之后,接下来 Netty 就开始向 JDK NIO SocketChannel 发送这些已经转换好的 JDK NIO ByteBuffer 了。
5.2 向JDK NIO SocketChannel发送数据
@Override
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
SocketChannel ch = javaChannel();
int writeSpinCount = config().getWriteSpinCount();
do {
.........将待发送数据转换到JDK NIO ByteBuffer中.........
//本次write loop中需要发送的 JDK ByteBuffer个数
int nioBufferCnt = in.nioBufferCount();
switch (nioBufferCnt) {
case 0:
//这里主要是针对 网络传输文件数据 的处理 FileRegion
writeSpinCount -= doWrite0(in);
break;
case 1: {
.........处理单个NioByteBuffer发送的情况......
break;
}
default: {
.........批量处理多个NioByteBuffers发送的情况......
break;
}
}
} while (writeSpinCount > 0);
............处理本轮write loop未写完的情况.......
}这里大家可能对 nioBufferCnt == 0 的情况比较有疑惑,明明之前已经校验过ChannelOutboundBuffer 不为空了,为什么这里从 ChannelOutboundBuffer 中获取到的 nioBuffer 个数依然为 0 呢?
在前边我们介绍 Netty 对 write 事件的处理过程时提过, ChannelOutboundBuffer 中只支持 ByteBuf 类型和 FileRegion 类型,其中 ByteBuf 类型用于装载普通的发送数据,而 FileRegion 类型用于通过零拷贝的方式网络传输文件。
而这里 ChannelOutboundBuffer 虽然不为空,但是装载的 NioByteBuffer 个数却为 0 说明 ChannelOutboundBuffer 中装载的是 FileRegion 类型,当前正在进行网络文件的传输。
case 0 的分支主要就是用于处理网络文件传输的情况。
5.2.1 零拷贝发送网络文件
protected final int doWrite0(ChannelOutboundBuffer in) throws Exception {
Object msg = in.current();
if (msg == null) {
return 0;
}
return doWriteInternal(in, in.current());
}这里需要特别注意的是用于文件传输的方法 doWriteInternal 中的返回值,理解这些返回值的具体情况有助于我们理解后面 write loop 的逻辑走向。
private int doWriteInternal(ChannelOutboundBuffer in, Object msg) throws Exception {
if (msg instanceof ByteBuf) {
..............忽略............
} else if (msg instanceof FileRegion) {
FileRegion region = (FileRegion) msg;
//文件已经传输完毕
if (region.transferred() >= region.count()) {
in.remove();
return 0;
}
//零拷贝的方式传输文件
long localFlushedAmount = doWriteFileRegion(region);
if (localFlushedAmount > 0) {
in.progress(localFlushedAmount);
if (region.transferred() >= region.count()) {
in.remove();
}
return 1;
}
} else {
// Should not reach here.
throw new Error();
}
//走到这里表示 此时Socket已经写不进去了 退出writeLoop,注册OP_WRITE事件
return WRITE_STATUS_SNDBUF_FULL;
}最终会在 doWriteFileRegion 方法中通过 FileChannel#transferTo 方法底层用到的系统调用为 sendFile 实现零拷贝网络文件的传输。
public class NioSocketChannel extends AbstractNioByteChannel implements io.netty.channel.socket.SocketChannel {
@Override
protected long doWriteFileRegion(FileRegion region) throws Exception {
final long position = region.transferred();
return region.transferTo(javaChannel(), position);
}
}关于 Netty 中涉及到的零拷贝,笔者会有一篇专门的文章为大家讲解,本文的主题我们还是先聚焦于把发送流程的主线打通。
我们继续回到发送数据流程主线上来~~
case 0:
//这里主要是针对 网络传输文件数据 的处理 FileRegion
writeSpinCount -= doWrite0(in);
break;region.transferred() >= region.count():表示当前 FileRegion 中的文件数据已经传输完毕。那么在这种情况下本次 write loop 没有写入任何数据到 Socket ,所以返回 0 ,writeSpinCount - 0 意思就是本次 write loop 不算,继续循环。localFlushedAmount > 0:表示本 write loop 中写入了一些数据到 Socket 中,会有返回 1,writeSpinCount - 1 减少一次 write loop 次数。localFlushedAmount <= 0:表示当前 Socket 发送缓冲区已满,无法写入数据,那么就返回WRITE_STATUS_SNDBUF_FULL = Integer.MAX_VALUE。writeSpinCount - Integer.MAX_VALUE必然是负数,直接退出循环,向 Reactor 注册 OP_WRITE 事件并退出 flush 流程。等 Socket 发送缓冲区可写了,Reactor 会通知 channel 继续发送文件数据。记住这里,我们后面还会提到。
5.2.2 发送普通数据
剩下两个 case 1 和 default 分支主要就是处理 ByteBuffer 装载的普通数据发送逻辑。
其中 case 1 表示当前 Channel 的 ChannelOutboundBuffer 中只包含了一个 NioByteBuffer 的情况。
default 表示当前 Channel 的 ChannelOutboundBuffer 中包含了多个 NioByteBuffers 的情况。
@Override
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
SocketChannel ch = javaChannel();
int writeSpinCount = config().getWriteSpinCount();
do {
.........将待发送数据转换到JDK NIO ByteBuffer中.........
//本次write loop中需要发送的 JDK ByteBuffer个数
int nioBufferCnt = in.nioBufferCount();
switch (nioBufferCnt) {
case 0:
..........处理网络文件传输.........
case 1: {
ByteBuffer buffer = nioBuffers[0];
int attemptedBytes = buffer.remaining();
final int localWrittenBytes = ch.write(buffer);
if (localWrittenBytes <= 0) {
//如果当前Socket发送缓冲区满了写不进去了,则注册OP_WRITE事件,等待Socket发送缓冲区可写时 在写
// SubReactor在处理OP_WRITE事件时,直接调用flush方法
incompleteWrite(true);
return;
}
//根据当前实际写入情况调整 maxBytesPerGatheringWrite数值
adjustMaxBytesPerGatheringWrite(attemptedBytes, localWrittenBytes, maxBytesPerGatheringWrite);
//如果ChannelOutboundBuffer中的某个Entry被全部写入 则删除该Entry
// 如果Entry被写入了一部分 还有一部分未写入 则更新Entry中的readIndex 等待下次writeLoop继续写入
in.removeBytes(localWrittenBytes);
--writeSpinCount;
break;
}
default: {
// ChannelOutboundBuffer中总共待写入数据的字节数
long attemptedBytes = in.nioBufferSize();
//批量写入
final long localWrittenBytes = ch.write(nioBuffers, 0, nioBufferCnt);
if (localWrittenBytes <= 0) {
incompleteWrite(true);
return;
}
//根据实际写入情况调整一次写入数据大小的最大值
// maxBytesPerGatheringWrite决定每次可以从channelOutboundBuffer中获取多少发送数据
adjustMaxBytesPerGatheringWrite((int) attemptedBytes, (int) localWrittenBytes,
maxBytesPerGatheringWrite);
//移除全部写完的BUffer,如果只写了部分数据则更新buffer的readerIndex,下一个writeLoop写入
in.removeBytes(localWrittenBytes);
--writeSpinCount;
break;
}
}
} while (writeSpinCount > 0);
............处理本轮write loop未写完的情况.......
}case 1 和 default 这两个分支在处理发送数据时的逻辑是一样的,唯一的区别就是 case 1 是处理单个 NioByteBuffer 的发送,而 default 分支是批量处理多个 NioByteBuffers 的发送。
下面笔者就以经常被触发到的 default 分支为例来为大家讲述 Netty 在处理数据发送时的逻辑细节:
- 首先从当前 NioSocketChannel 中的 ChannelOutboundBuffer 中获取本次 write loop 需要发送的字节总量 attemptedBytes 。这个 nioBufferSize 是在前边介绍
ChannelOutboundBuffer#nioBuffers方法转换 JDK NIO ByteBuffer 类型时被计算出来的。 - 调用 JDK NIO 原生 SocketChannel 批量发送 nioBuffers 中的数据。并获取到本次 write loop 一共批量发送了多少字节 localWrittenBytes 。
/**
* @throws NotYetConnectedException
* If this channel is not yet connected
*/
public abstract long write(ByteBuffer[] srcs, int offset, int length)
throws IOException;3 . localWrittenBytes <= 0 表示当前 Socket 的写缓存区 SEND_BUF 已满,写不进数据了。那么就需要向当前 NioSocketChannel 对应的 Reactor 注册 OP_WRITE 事件,并停止当前 flush 流程。当 Socket 的写缓冲区有容量可写时,epoll 会通知 reactor 线程继续写入。
protected final void incompleteWrite(boolean setOpWrite) {
// Did not write completely.
if (setOpWrite) {
//这里处理还没写满16次 但是socket缓冲区已满写不进去的情况 注册write事件
//什么时候socket可写了, epoll会通知reactor线程继续写
setOpWrite();
} else {
...........目前还不需要关注这里.......
}
}向 Reactor 注册 OP_WRITE 事件:
protected final void setOpWrite() {
final SelectionKey key = selectionKey();
if (!key.isValid()) {
return;
}
final int interestOps = key.interestOps();
if ((interestOps & SelectionKey.OP_WRITE) == 0) {
key.interestOps(interestOps | SelectionKey.OP_WRITE);
}
}关于通过位运算来向 IO 事件集合 interestOps 添加监听 IO 事件的用法,在前边的文章中,笔者已经多次介绍过了,这里不再重复。
4 . 根据本次 write loop 向 Socket 写缓冲区写入数据的情况,来调整下次 write loop 最大写入字节数。maxBytesPerGatheringWrite 决定每次 write loop 可以从 channelOutboundBuffer 中最多获取多少发送数据。初始值为 SO_SNDBUF大小 * 2 = 293976 = 146988 << 1,最小值为 2048。
public static final int MAX_BYTES_PER_GATHERING_WRITE_ATTEMPTED_LOW_THRESHOLD = 4096;
private void adjustMaxBytesPerGatheringWrite(int attempted, int written, int oldMaxBytesPerGatheringWrite) {
if (attempted == written) {
if (attempted << 1 > oldMaxBytesPerGatheringWrite) {
((NioSocketChannelConfig) config).setMaxBytesPerGatheringWrite(attempted << 1);
}
} else if (attempted > MAX_BYTES_PER_GATHERING_WRITE_ATTEMPTED_LOW_THRESHOLD && written < attempted >>> 1) {
((NioSocketChannelConfig) config).setMaxBytesPerGatheringWrite(attempted >>> 1);
}
}由于操作系统会动态调整 SO_SNDBUF 的大小,所以这里 netty 也需要根据操作系统的动态调整做出相应的调整,目的是尽量多的去写入数据。
attempted == written 表示本次 write loop 尝试写入的数据能全部写入到 Socket 的写缓冲区中,那么下次 write loop 就应该尝试去写入更多的数据。
那么这里的更多具体是多少呢?
Netty 会将本次写入的数据量 written 扩大两倍,如果扩大两倍后的写入量大于本次 write loop 的最大限制写入量 maxBytesPerGatheringWrite,说明用户的写入需求很猛烈,Netty当然要满足这样的猛烈需求,那么就将当前 NioSocketChannelConfig 中的 maxBytesPerGatheringWrite 更新为本次 write loop 两倍的写入量大小。
在下次 write loop 写入数据的时候,就会尝试从 ChannelOutboundBuffer 中加载最多 written * 2 大小的字节数。
如果扩大两倍后的写入量依然小于等于本次 write loop 的最大限制写入量 maxBytesPerGatheringWrite,说明用户的写入需求还不是很猛烈,Netty 继续维持本次 maxBytesPerGatheringWrite 数值不变。
如果本次写入的数据还不及尝试写入数据的 1 / 2 :written < attempted >>> 1。说明当前 Socket 写缓冲区的可写容量不是很多了,下一次 write loop 就不要写这么多了尝试减少下次写入的量将下次 write loop 要写入的数据减小为 attempted 的1 / 2。当然也不能无限制的减小,最小值不能低于 2048。
这里可以结合笔者前边的文章[?《一文聊透ByteBuffer动态自适应扩缩容机制》] 中介绍到的 read loop 场景中的扩缩容一起对比着看。
read loop 中的扩缩容触发时机是在一个完整的 read loop 结束时候触发。而 write loop 中扩缩容的触发时机是在每次 write loop 发送完数据后,立即触发扩缩容判断。
5 . 当本次 write loop 批量发送完 ChannelOutboundBuffer 中的数据之后,最后调用in.removeBytes(localWrittenBytes) 从 ChannelOutboundBuffer 中移除全部写完的 Entry ,如果只发送了 Entry 的部分数据则更新 Entry 对象中封装的 DirectByteBuffer 的 readerIndex,等待下一次 write loop 写入。
到这里,write loop 中的发送数据的逻辑就介绍完了,接下来 Netty 会在 write loop 中循环地发送数据直到写满 16 次或者数据发送完毕。
还有一种退出 write loop 的情况就是当 Socket 中的写缓冲区满了,无法在写入时。Netty 会退出 write loop 并向 reactor 注册 OP_WRITE 事件。
但这其中还隐藏着一种情况就是如果 write loop 已经写满 16 次但还没写完数据并且此时 Socket 写缓冲区还没有满,还可以继续在写。那 Netty 会如何处理这种情况呢?
6 . 处理Socket可写但已经写满16次还没写完的情况
@Override
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
SocketChannel ch = javaChannel();
int writeSpinCount = config().getWriteSpinCount();
do {
.........将待发送数据转换到JDK NIO ByteBuffer中.........
int nioBufferCnt = in.nioBufferCount();
switch (nioBufferCnt) {
case 0:
//这里主要是针对 网络传输文件数据 的处理 FileRegion
writeSpinCount -= doWrite0(in);
break;
case 1: {
.....发送单个nioBuffer....
}
default: {
.....批量发送多个nioBuffers......
}
}
} while (writeSpinCount > 0);
//处理write loop结束 但数据还没写完的情况
incompleteWrite(writeSpinCount < 0);
}当 write loop 结束后,这时 writeSpinCount 的值会有两种情况:
writeSpinCount < 0:这种情况有点不好理解,我们在介绍 Netty 通过零拷贝的方式传输网络文件也就是这里的 case 0 分支逻辑时,详细介绍了 doWrite0 方法的几种返回值,当 Netty 在传输文件的过程中发现 Socket 缓冲区已满无法在继续写入数据时,会返回WRITE_STATUS_SNDBUF_FULL = Integer.MAX_VALUE,这就使得writeSpinCount的值 < 0。随后 break 掉 write loop 来到incompleteWrite(writeSpinCount < 0)方法中,最后会在 incompleteWrite 方法中向 reactor 注册 OP_WRITE 事件。当 Socket 缓冲区变得可写时,epoll 会通知 reactor 线程继续发送文件。
protected final void incompleteWrite(boolean setOpWrite) {
// Did not write completely.
if (setOpWrite) {
//这里处理还没写满16次 但是socket缓冲区已满写不进去的情况 注册write事件
// 什么时候socket可写了, epoll会通知reactor线程继续写
setOpWrite();
} else {
..............
}
}writeSpinCount == 0:这种情况很好理解,就是已经写满了 16 次,但是还没写完,同时 Socket 的写缓冲区未满,还可以继续写入。这种情况下即使 Socket 还可以继续写入,Netty 也不会再去写了,因为执行 flush 操作的是 reactor 线程,而 reactor 线程负责执行注册在它上边的所有 channel 的 IO 操作,Netty 不会允许 reactor 线程一直在一个 channel 上执行 IO 操作,reactor 线程的执行时间需要均匀的分配到每个 channel 上。所以这里 Netty 会停下,转而去处理其他 channel 上的 IO 事件。
那么还没写完的数据,Netty会如何处理呢?
protected final void incompleteWrite(boolean setOpWrite) {
// Did not write completely.
if (setOpWrite) {
//这里处理还没写满16次 但是socket缓冲区已满写不进去的情况 注册write事件
// 什么时候socket可写了, epoll会通知reactor线程继续写
setOpWrite();
} else {
//这里处理的是socket缓冲区依然可写,但是写了16次还没写完,这时就不能在写了,reactor线程需要处理其他channel上的io事件
//因为此时socket是可写的,必须清除op_write事件,否则会一直不停地被通知
clearOpWrite();
//如果本次writeLoop还没写完,则提交flushTask到reactor
eventLoop().execute(flushTask);
}这个方法的 if 分支逻辑,我们在介绍do {.....}while()循环体 write loop 中发送逻辑时已经提过,在 write loop 循环发送数据的过程中,如果发现 Socket 缓冲区已满,无法写入数据时( localWrittenBytes <= 0),则需要向 reactor 注册 OP_WRITE 事件,等到 Socket 缓冲区变为可写状态时,epoll 会通知 reactor 线程继续写入剩下的数据。
do {
.........将待发送数据转换到JDK NIO ByteBuffer中.........
int nioBufferCnt = in.nioBufferCount();
switch (nioBufferCnt) {
case 0:
writeSpinCount -= doWrite0(in);
break;
case 1: {
.....发送单个nioBuffer....
final int localWrittenBytes = ch.write(buffer);
if (localWrittenBytes <= 0) {
incompleteWrite(true);
return;
}
.................省略..............
break;
}
default: {
.....批量发送多个nioBuffers......
final long localWrittenBytes = ch.write(nioBuffers, 0, nioBufferCnt);
if (localWrittenBytes <= 0) {
incompleteWrite(true);
return;
}
.................省略..............
break;
}
}
} while (writeSpinCount > 0);注意 if 分支处理的情况是还没写满 16 次,但是 Socket 缓冲区已满,无法写入的情况。
而 else 分支正是处理我们这里正在讨论的情况即 Socket 缓冲区是可写的,但是已经写满 16 次,在本轮 write loop 中不能再继续写入的情况。
这时 Netty 会将 channel 中剩下的待写数据的 flush 操作封装程 flushTask,丢进 reactor 的普通任务队列中,等待 reactor 执行完其他 channel 上的 io 操作后在回过头来执行未写完的 flush 任务。
忘记 Reactor 整体运行逻辑的同学,可以在回看下笔者的这篇文章[?《一文聊透Netty核心引擎Reactor的运转架构》]
private final Runnable flushTask = new Runnable() {
@Override
public void run() {
((AbstractNioUnsafe) unsafe()).flush0();
}
};这里我们看到 flushTask 中的任务是直接再次调用 flush0 继续回到发送数据的逻辑流程中。
细心的同学可能会有疑问,为什么这里不在继续注册 OP_WRITE 事件而是通过向 reactor 提交一个 flushTask 来完成 channel 中剩下数据的写入呢?
原因是这里我们讲的 else 分支是用来处理 Socket 缓冲区未满还是可写的,但是由于用户本次要发送的数据太多,导致写了 16 次还没写完的情形。
既然当前 Socket 缓冲区是可写的,我们就不能注册 OP_WRITE 事件,否则这里一直会不停地收到 epoll 的通知。因为 JDK NIO Selector 默认的是 epoll 的水平触发。
忘记水平触发和边缘触发这两种 epoll 工作模式的同学,可以在回看下笔者的这篇文章[?《聊聊Netty那些事儿之从内核角度看IO模型》]
所以这里只能向 reactor 提交 flushTask 来继续完成剩下数据的写入,而不能注册 OP_WRITE 事件。
注意:只有当 Socket 缓冲区已满导致无法写入时,Netty 才会去注册 OP_WRITE 事件。这和我们之前介绍的 OP_ACCEPT 事件和 OP_READ 事件的注册时机是不同的。
这里大家可能还会有另一个疑问,就是为什么在向 reactor 提交 flushTask 之前需要清理 OP_WRITE 事件呢? 我们并没有注册 OP_WRITE 事件呀~~
protected final void incompleteWrite(boolean setOpWrite) {
if (setOpWrite) {
......省略......
} else {
clearOpWrite();
eventLoop().execute(flushTask);
}在为大家解答这个疑问之前,笔者先为大家介绍下 Netty 是如何处理 OP_WRITE 事件的,当大家明白了 OP_WRITE 事件的处理逻辑后,这个疑问就自然解开了。
7 . OP_WRITE事件的处理
在[?《一文聊透Netty核心引擎Reactor的运转架构》] 一文中,我们介绍过,当 Reactor 监听到 channel 上有 IO 事件发生后,最终会在 processSelectedKey 方法中处理 channel 上的 IO 事件,其中 OP_ACCEPT 事件和 OP_READ 事件的处理过程,笔者已经在之前的系列文章中介绍过了,这里我们聚焦于 OP_WRITE 事件的处理。
public final class NioEventLoop extends SingleThreadEventLoop {
private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe();
.............省略.......
try {
int readyOps = k.readyOps();
if ((readyOps & SelectionKey.OP_CONNECT) != 0) {
......处理connect事件......
}
if ((readyOps & SelectionKey.OP_WRITE) != 0) {
ch.unsafe().forceFlush();
}
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
........处理accept和read事件.........
}
} catch (CancelledKeyException ignored) {
unsafe.close(unsafe.voidPromise());
}
}
}这里我们看到当 OP_WRITE 事件发生后,Netty 直接调用 channel 的 forceFlush 方法。
@Override
public final void forceFlush() {
// directly call super.flush0() to force a flush now
super.flush0();
}其实 forceFlush 方法中并没有什么特殊的逻辑,直接调用 flush0 方法再次发起 flush 操作继续 channel 中剩下数据的写入。
@Override
protected void doWrite(ChannelOutboundBuffer in) throws Exception {
SocketChannel ch = javaChannel();
int writeSpinCount = config().getWriteSpinCount();
do {
if (in.isEmpty()) {
clearOpWrite();
return;
}
.........将待发送数据转换到JDK NIO ByteBuffer中.........
int nioBufferCnt = in.nioBufferCount();
switch (nioBufferCnt) {
case 0:
......传输网络文件........
case 1: {
.....发送单个nioBuffer....
}
default: {
.....批量发送多个nioBuffers......
}
}
} while (writeSpinCount > 0);
//处理write loop结束 但数据还没写完的情况
incompleteWrite(writeSpinCount < 0);
}注意这里的 clearOpWrite() 方法,由于 channel 上的 OP_WRITE 事件就绪,表明此时 Socket 缓冲区变为可写状态,从而 Reactor 线程再次来到了 flush 流程中。
当 ChannelOutboundBuffer 中的数据全部写完后 in.isEmpty() ,就需要清理 OP_WRITE 事件,因为此时 Socket 缓冲区是可写的,这种情况下当数据全部写完后,就需要取消对 OP_WRITE 事件的监听,否则 epoll 会不断的通知 Reactor。
同理在 incompleteWrite 方法的 else 分支也需要执行 clearOpWrite() 方法取消对 OP_WRITE 事件的监听。
protected final void incompleteWrite(boolean setOpWrite) {
if (setOpWrite) {
// 这里处理还没写满16次 但是socket缓冲区已满写不进去的情况 注册write事件
// 什么时候socket可写了, epoll会通知reactor线程继续写
setOpWrite();
} else {
// 必须清除OP_WRITE事件,此时Socket对应的缓冲区依然是可写的,只不过当前channel写够了16次,被SubReactor限制了。
// 这样SubReactor可以腾出手来处理其他channel上的IO事件。这里如果不清除OP_WRITE事件,则会一直被通知。
clearOpWrite();
//如果本次writeLoop还没写完,则提交flushTask到SubReactor
//释放SubReactor让其可以继续处理其他Channel上的IO事件
eventLoop().execute(flushTask);
}
}8 . writeAndFlush
在我们讲完了 write 事件和 flush 事件的处理过程之后,writeAndFlush 就变得很简单了,它就是把 write 和 flush 流程结合起来,先触发 write 事件然后在触发 flush 事件。
下面我们来看下 writeAndFlush 的具体逻辑处理:
public class EchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(final ChannelHandlerContext ctx, final Object msg) {
//此处的msg就是Netty在read loop中从NioSocketChannel中读取到ByteBuffer
ctx.writeAndFlush(msg);
}
}abstract class AbstractChannelHandlerContext implements ChannelHandlerContext, ResourceLeakHint {
@Override
public ChannelFuture writeAndFlush(Object msg) {
return writeAndFlush(msg, newPromise());
}
@Override
public ChannelFuture writeAndFlush(Object msg, ChannelPromise promise) {
write(msg, true, promise);
return promise;
}
}这里可以看到 writeAndFlush 方法的处理入口和 write 事件的处理入口是一样的。唯一不同的是入口处理函数 write 方法的 boolean flush 入参不同,在 writeAndFlush 的处理中 flush = true。
private void write(Object msg, boolean flush, ChannelPromise promise) {
ObjectUtil.checkNotNull(msg, "msg");
................省略检查promise的有效性...............
//flush = true 表示channelHandler中调用的是writeAndFlush方法,这里需要找到pipeline中覆盖write或者flush方法的channelHandler
//flush = false 表示调用的是write方法,只需要找到pipeline中覆盖write方法的channelHandler
final AbstractChannelHandlerContext next = findContextOutbound(flush ?
(MASK_WRITE | MASK_FLUSH) : MASK_WRITE);
//用于检查内存泄露
final Object m = pipeline.touch(msg, next);
//获取下一个要被执行的channelHandler的executor
EventExecutor executor = next.executor();
//确保OutBound事件由ChannelHandler指定的executor执行
if (executor.inEventLoop()) {
//如果当前线程正是channelHandler指定的executor则直接执行
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
//如果当前线程不是ChannelHandler指定的executor,则封装成异步任务提交给指定executor执行,注意这里的executor不一定是reactor线程。
final WriteTask task = WriteTask.newInstance(next, m, promise, flush);
if (!safeExecute(executor, task, promise, m, !flush)) {
task.cancel();
}
}
} 由于在 writeAndFlush 流程的处理中,flush 标志被设置为 true,所以这里有两个地方会和 write 事件的处理有所不同。
findContextOutbound( MASK_WRITE | MASK_FLUSH ):这里在 pipeline 中向前查找的 ChanneOutboundHandler 需要实现 write 方法或者 flush 方法。这里需要注意的是 write 方法和 flush 方法只需要实现其中一个即可满足查找条件。因为一般我们自定义 ChannelOutboundHandler 时,都会继承 ChannelOutboundHandlerAdapter 类,而在 ChannelInboundHandlerAdapter 类中对于这些 outbound 事件都会有默认的实现。
public class ChannelOutboundHandlerAdapter extends ChannelHandlerAdapter implements ChannelOutboundHandler {
@Skip
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
ctx.write(msg, promise);
}
@Skip
@Override
public void flush(ChannelHandlerContext ctx) throws Exception {
ctx.flush();
}
}这样在后面传播 write 事件或者 flush 事件的时候,我们通过上面逻辑找出的 ChannelOutboundHandler 中可能只实现了一个 flush 方法或者 write 方法。不过这样没关系,如果这里在传播 outbound 事件的过程中,发现找出的 ChannelOutboundHandler 中并没有实现对应的 outbound 事件回调函数,那么就直接调用在 ChannelOutboundHandlerAdapter 中的默认实现。
- 在向前传播 writeAndFlush 事件的时候会通过调用 ChannelHandlerContext 的 invokeWriteAndFlush 方法,先传播 write 事件 然后在传播 flush 事件。
void invokeWriteAndFlush(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
//向前传递write事件
invokeWrite0(msg, promise);
//向前传递flush事件
invokeFlush0();
} else {
writeAndFlush(msg, promise);
}
}
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
//调用当前ChannelHandler中的write方法
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
private void invokeFlush0() {
try {
((ChannelOutboundHandler) handler()).flush(this);
} catch (Throwable t) {
invokeExceptionCaught(t);
}
}
这里我们看到了 writeAndFlush 的核心处理逻辑,首先向前传播 write 事件,经过 write 事件的流程处理后,最后向前传播 flush 事件。
根据前边的介绍,这里在向前传播 write 事件的时候,可能查找出的 ChannelOutboundHandler 只是实现了 flush 方法,不过没关系,这里会直接调用 write 方法在 ChannelOutboundHandlerAdapter 父类中的默认实现。同理 flush 也是一样。
总结
到这里,Netty 处理数据发送的整个完整流程,笔者就为大家详细地介绍完了,可以看到 Netty 在处理读取数据和处理发送数据的过程中,虽然核心逻辑都差不多,但是发送数据的过程明显细节比较多,而且更加复杂一些。
这里笔者将读取数据和发送数据的不同之处总结如下几点供大家回忆对比:
-
在每次 read loop 之前,会分配一个大小固定的 diretByteBuffer 用来装载读取数据。每轮 read loop 完全结束之后,才会决定是否对下一轮的读取过程分配的 directByteBuffer 进行扩容或者缩容。
-
在每次 write loop 之前,都会获取本次 write loop 最大能够写入的字节数,根据这个最大写入字节数从 ChannelOutboundBuffer 中转换 JDK NIO ByteBuffer 。每次写入 Socket 之后都需要重新评估是否对这个最大写入字节数进行扩容或者缩容。
-
read loop 和 write loop 都被默认限定最多执行 16 次。
-
在一个完整的 read loop 中,如果还读取不完数据,直接退出。等到 reactor 线程执行完其他 channel 上的 IO 事件再来读取未读完的数据。
-
而在一个完整的 write loop 中,数据发送不完,则分两种情况。
-
Socket 缓冲区满无法在继续写入。这时就需要向 reactor 注册 OP_WRITE 事件。等 Socket 缓冲区变的可写时,epoll 通知 reactor 线程继续发送。
-
Socket 缓冲区可写,但是由于发送数据太多,导致虽然写满 16 次但依然没有写完。这时就直接向 reactor 丢一个 flushTask 进去,等到 reactor 线程执行完其他 channel 上的 IO 事件,在回过头来执行 flushTask。
-
OP_READ 事件的注册是在 NioSocketChannel 被注册到对应的 Reactor 中时就会注册。而 OP_WRITE 事件只会在 Socket 缓冲区满的时候才会被注册。当 Socket 缓冲区再次变得可写时,要记得取消 OP_WRITE 事件的监听。否则的话就会一直被通知。
好了,本文的全部内容就到这里了,我们下篇文章见~~~~